86 posts tagged “vision-llms”
LLMs that can also be used to interpret images and video, such as GPT-4o, Claude 3 and Gemini Pro.
2025
We've been seeing if the latest versions of LLMs are any better at geolocating and chronolocating images, and they've improved dramatically since we last tested them in 2023. [...]
Before anyone worries about it taking our job, I see it more as the difference between a hand whisk and an electric whisk, just the same job done quicker, and either way you've got to check if your peaks are stiff at the end of it.
— Eliot Higgins, Bellingcat
Watching o3 guess a photo’s location is surreal, dystopian and wildly entertaining
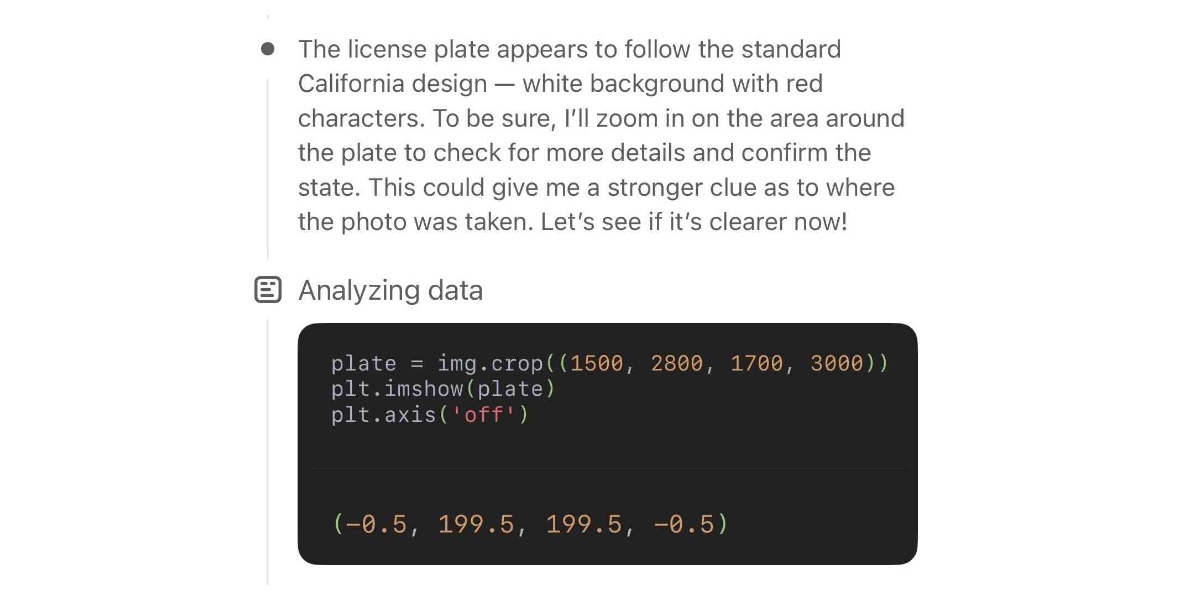
Watching OpenAI’s new o3 model guess where a photo was taken is one of those moments where decades of science fiction suddenly come to life. It’s a cross between the Enhance Button and Omniscient Database TV Tropes.
[... 1,582 words]Image segmentation using Gemini 2.5

Max Woolf pointed out this new feature of the Gemini 2.5 series (here’s my coverage of 2.5 Pro and 2.5 Flash) in a comment on Hacker News:
[... 1,428 words]I work for OpenAI. [...] o4-mini is actually a considerably better vision model than o3, despite the benchmarks. Similar to how o3-mini-high was a much better coding model than o1. I would recommend using o4-mini-high over o3 for any task involving vision.
— James Betker, OpenAI
GPT-4.1: Three new million token input models from OpenAI, including their cheapest model yet

OpenAI introduced three new models this morning: GPT-4.1, GPT-4.1 mini and GPT-4.1 nano. These are API-only models right now, not available through the ChatGPT interface (though you can try them out in OpenAI’s API playground). All three models can handle 1,047,576 tokens of input and 32,768 tokens of output, and all three have a May 31, 2024 cut-off date (their previous models were mostly September 2023).
[... 1,124 words]Mistral Small 3.1 on Ollama. Mistral Small 3.1 (previously) is now available through Ollama, providing an easy way to run this multi-modal (vision) model on a Mac (and other platforms, though I haven't tried those myself).
I had to upgrade Ollama to the most recent version to get it to work - prior to that I got a Error: unable to load model message. Upgrades can be accessed through the Ollama macOS system tray icon.
I fetched the 15GB model by running:
ollama pull mistral-small3.1
Then used llm-ollama to run prompts through it, including one to describe this image:
llm install llm-ollama
llm -m mistral-small3.1 'describe this image' -a https://static.simonwillison.net/static/2025/Mpaboundrycdfw-1.png
Here's the output. It's good, though not quite as impressive as the description I got from the slightly larger Qwen2.5-VL-32B.
I also tried it on a scanned (private) PDF of hand-written text with very good results, though it did misread one of the hand-written numbers.
Initial impressions of Llama 4
Dropping a model release as significant as Llama 4 on a weekend is plain unfair! So far the best place to learn about the new model family is this post on the Meta AI blog. They’ve released two new models today: Llama 4 Maverick is a 400B model (128 experts, 17B active parameters), text and image input with a 1 million token context length. Llama 4 Scout is 109B total parameters (16 experts, 17B active), also multi-modal and with a claimed 10 million token context length—an industry first.
[... 1,468 words]Putting Gemini 2.5 Pro through its paces

There’s a new release from Google Gemini this morning: the first in the Gemini 2.5 series. Google call it “a thinking model, designed to tackle increasingly complex problems”. It’s already sat at the top of the LM Arena leaderboard, and from initial impressions looks like it may deserve that top spot.
[... 2,400 words]Qwen2.5-VL-32B: Smarter and Lighter. The second big open weight LLM release from China today - the first being DeepSeek v3-0324.
Qwen's previous vision model was Qwen2.5 VL, released in January in 3B, 7B and 72B sizes.
Today's Apache 2.0 licensed release is a 32B model, which is quickly becoming my personal favourite model size - large enough to have GPT-4-class capabilities, but small enough that on my 64GB Mac there's still enough RAM for me to run other memory-hungry applications like Firefox and VS Code.
Qwen claim that the new model (when compared to their previous 2.5 VL family) can "align more closely with human preferences", is better at "mathematical reasoning" and provides "enhanced accuracy and detailed analysis in tasks such as image parsing, content recognition, and visual logic deduction".
They also offer some presumably carefully selected benchmark results showing it out-performing Gemma 3-27B, Mistral Small 3.1 24B and GPT-4o-0513 (there have been two more recent GPT-4o releases since that one, 2024-08-16 and 2024-11-20).
As usual, Prince Canuma had MLX versions of the models live within hours of the release, in 4 bit, 6 bit, 8 bit, and bf16 variants.
I ran the 4bit version (a 18GB model download) using uv and Prince's mlx-vlm like this:
uv run --with 'numpy<2' --with mlx-vlm \
python -m mlx_vlm.generate \
--model mlx-community/Qwen2.5-VL-32B-Instruct-4bit \
--max-tokens 1000 \
--temperature 0.0 \
--prompt "Describe this image." \
--image Mpaboundrycdfw-1.pngHere's the image:
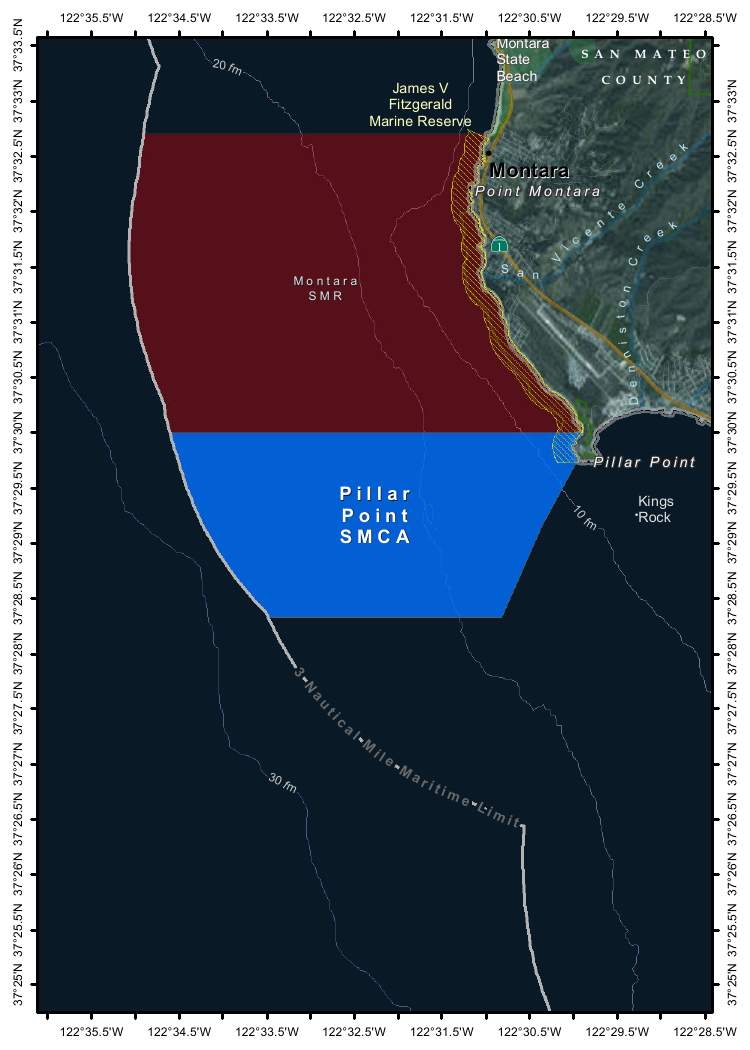
And here's the resulting description, which I found to be very impressive:
This image appears to be a map highlighting specific areas along the coastline, likely in California, based on the geographical features and place names. Here is a detailed description of the image:
Geographic Features:
- The map shows a section of the coastline, with land on the right and the sea on the left.
- The land area includes parts of SanMateo County, as noted in the top-right corner.
- The coastline features several named locations, including:
- Point Montara
- Pillar Point
- Kings Rock
- VicenteCreek
- DennistonCreek
- State Beach
Highlighted Areas:
- The map contains two distinct areas marked with different colors:
- Red Area (Top Section)
- Labeled as "MONTARA" and "MONTARA M R" (possibly referring to a "Marine Reserves" or similar protected area).
- This area is marked with a dark red color and extends from the coastline inland.
- Blue Area (Bottom Section)
- Labeled as "PILLAR" and "PILLAR P O I N T" along with "SMCA" (Special Management Area).
- This area is marked with a blue color and is located closer to the coastline, including the area around "Pillar Point."
Depth Contours:
- The map includes depth markings in the sea, indicating the bathymetrical features:
- 20 fathom (fm) line is marked in the upper-left part of the sea.
- 10 fathom (fm) line is marked closer to the coastline.
- 30 fathom (fm) line is marked further out to sea.
Other Features:
- State Beach: Marked near the top-right, indicating a protected recreational area.
- Kings Rock: A prominent feature near the coastline, likely a rocky outcropping.
- Creeks: The map shows several creeks, including VicenteCreek and DennistonCreek, which flow into the sea.
Protected Areas:
- The map highlights specific protected areas:
- Marine Reserves:
- "MONTARA M R" (Marine Reserves) in red.
- Special Management Area (SMCA)
- "PILLAR P O I N T" in blue, indicating a Special Management Area.
Grid and Coordinates:
- The map includes a grid with latitude and longitude markings:
- Latitude ranges from approximately 37°25'N to 37°35'N.
- Longitude ranges from approximately 122°22.5'W to 122°35.5'W.
Topography:
- The land area shows topographic features, including elevations and vegetation, with green areas indicating higher elevations or vegetated land.
Other Labels:
- "SMR": Likely stands for "State Managed Reserves."
- "SMCA": Likely stands for "Special Management Control Area."
In summary, this map highlights specific protected areas along the coastline, including a red "Marine Reserves" area and a blue "Special Management Area" near "Pillar Point." The map also includes depth markings, geographical features, and place names, providing a detailed view of the region's natural and protected areas.
It included the following runtime statistics:
Prompt: 1051 tokens, 111.985 tokens-per-sec
Generation: 760 tokens, 17.328 tokens-per-sec
Peak memory: 21.110 GB
Mistral Small 3.1. Mistral Small 3 came out in January and was a notable, genuinely excellent local model that used an Apache 2.0 license.
Mistral Small 3.1 offers a significant improvement: it's multi-modal (images) and has an increased 128,000 token context length, while still "fitting within a single RTX 4090 or a 32GB RAM MacBook once quantized" (according to their model card). Mistral's own benchmarks show it outperforming Gemma 3 and GPT-4o Mini, but I haven't seen confirmation from external benchmarks.
Despite their mention of a 32GB MacBook I haven't actually seen any quantized GGUF or MLX releases yet, which is a little surprising since they partnered with Ollama on launch day for their previous Mistral Small 3. I expect we'll see various quantized models released by the community shortly.
Update 20th March 2025: I've now run the text version on my laptop using mlx-community/Mistral-Small-3.1-Text-24B-Instruct-2503-8bit and llm-mlx:
llm mlx download-model mlx-community/Mistral-Small-3.1-Text-24B-Instruct-2503-8bit -a mistral-small-3.1
llm chat -m mistral-small-3.1
The model can be accessed via Mistral's La Plateforme API, which means you can use it via my llm-mistral plugin.
Here's the model describing my photo of two pelicans in flight:
{kind=link}
llm install llm-mistral
# Run this if you have previously installed the plugin:
llm mistral refresh
llm -m mistral/mistral-small-2503 'describe' \
-a https://static.simonwillison.net/static/2025/two-pelicans.jpg
The image depicts two brown pelicans in flight against a clear blue sky. Pelicans are large water birds known for their long bills and large throat pouches, which they use for catching fish. The birds in the image have long, pointed wings and are soaring gracefully. Their bodies are streamlined, and their heads and necks are elongated. The pelicans appear to be in mid-flight, possibly gliding or searching for food. The clear blue sky in the background provides a stark contrast, highlighting the birds' silhouettes and making them stand out prominently.
I added Mistral's API prices to my tools.simonwillison.net/llm-prices pricing calculator by pasting screenshots of Mistral's pricing tables into Claude.
Notes on Google’s Gemma 3
Google’s Gemma team released an impressive new model today (under their not-open-source Gemma license). Gemma 3 comes in four sizes—1B, 4B, 12B, and 27B—and while 1B is text-only the larger three models are all multi-modal for vision:
[... 804 words]What’s new in the world of LLMs, for NICAR 2025

I presented two sessions at the NICAR 2025 data journalism conference this year. The first was this one based on my review of LLMs in 2024, extended by several months to cover everything that’s happened in 2025 so far. The second was a workshop on Cutting-edge web scraping techniques, which I’ve written up separately.
[... 2,797 words]Mistral OCR (via) New closed-source specialist OCR model by Mistral - you can feed it images or a PDF and it produces Markdown with optional embedded images.
It's available via their API, or it's "available to self-host on a selective basis" for people with stringent privacy requirements who are willing to talk to their sales team.
I decided to try out their API, so I copied and pasted example code from their notebook into my custom Claude project and told it:
Turn this into a CLI app, depends on mistralai - it should take a file path and an optional API key defauling to env vironment called MISTRAL_API_KEY
After some further iteration / vibe coding I got to something that worked, which I then tidied up and shared as mistral_ocr.py.
You can try it out like this:
export MISTRAL_API_KEY='...'
uv run http://tools.simonwillison.net/python/mistral_ocr.py \
mixtral.pdf --html --inline-images > mixtral.html
I fed in the Mixtral paper as a PDF. The API returns Markdown, but my --html option renders that Markdown as HTML and the --inline-images option takes any images and inlines them as base64 URIs (inspired by monolith). The result is mixtral.html, a 972KB HTML file with images and text bundled together.
This did a pretty great job!
My script renders Markdown tables but I haven't figured out how to render inline Markdown MathML yet. I ran the command a second time and requested Markdown output (the default) like this:
uv run http://tools.simonwillison.net/python/mistral_ocr.py \
mixtral.pdf > mixtral.md
Here's that Markdown rendered as a Gist - there are a few MathML glitches so clearly the Mistral OCR MathML dialect and the GitHub Formatted Markdown dialect don't quite line up.
My tool can also output raw JSON as an alternative to Markdown or HTML - full details in the documentation.
The Mistral API is priced at roughly 1000 pages per dollar, with a 50% discount for batch usage.
The big question with LLM-based OCR is always how well it copes with accidental instructions in the text (can you safely OCR a document full of prompting examples?) and how well it handles text it can't write.
Mistral's Sophia Yang says it "should be robust" against following instructions in the text, and invited people to try and find counter-examples.
Alexander Doria noted that Mistral OCR can hallucinate text when faced with handwriting that it cannot understand.
llm-ollama 0.9.0.
This release of the llm-ollama plugin adds support for schemas, thanks to a PR by Adam Compton.
Ollama provides very robust support for this pattern thanks to their structured outputs feature, which works across all of the models that they support by intercepting the logic that outputs the next token and restricting it to only tokens that would be valid in the context of the provided schema.
With Ollama and llm-ollama installed you can run even run structured schemas against vision prompts for local models. Here's one against Ollama's llama3.2-vision:
llm -m llama3.2-vision:latest \
'describe images' \
--schema 'species,description,count int' \
-a https://static.simonwillison.net/static/2025/two-pelicans.jpg
I got back this:
{
"species": "Pelicans",
"description": "The image features a striking brown pelican with its distinctive orange beak, characterized by its large size and impressive wingspan.",
"count": 1
}
(Actually a bit disappointing, as there are two pelicans and their beaks are brown.)
olmOCR (via) New from Ai2 - olmOCR is "an open-source tool designed for high-throughput conversion of PDFs and other documents into plain text while preserving natural reading order".
At its core is allenai/olmOCR-7B-0225-preview, a Qwen2-VL-7B-Instruct variant trained on ~250,000 pages of diverse PDF content (both scanned and text-based) that were labelled using GPT-4o and made available as the olmOCR-mix-0225 dataset.
The olmocr Python library can run the model on any "recent NVIDIA GPU". I haven't managed to run it on my own Mac yet - there are GGUFs out there but it's not clear to me how to run vision prompts through them - but Ai2 offer an online demo which can handle up to ten pages for free.
Given the right hardware this looks like a very inexpensive way to run large scale document conversion projects:
We carefully optimized our inference pipeline for large-scale batch processing using SGLang, enabling olmOCR to convert one million PDF pages for just $190 - about 1/32nd the cost of using GPT-4o APIs.
The most interesting idea from the technical report (PDF) is something they call "document anchoring":
Document anchoring extracts coordinates of salient elements in each page (e.g., text blocks and images) and injects them alongside raw text extracted from the PDF binary file. [...]
Document anchoring processes PDF document pages via the PyPDF library to extract a representation of the page’s structure from the underlying PDF. All of the text blocks and images in the page are extracted, including position information. Starting with the most relevant text blocks and images, these are sampled and added to the prompt of the VLM, up to a defined maximum character limit. This extra information is then available to the model when processing the document.
![Left side shows a green-header interface with coordinates like [150x220]√3x−1+(1+x)², [150x180]Section 6, [150x50]Lorem ipsum dolor sit amet, [150x70]consectetur adipiscing elit, sed do, [150x90]eiusmod tempor incididunt ut, [150x110]labore et dolore magna aliqua, [100x280]Table 1, followed by grid coordinates with A, B, C, AA, BB, CC, AAA, BBB, CCC values. Right side shows the rendered document with equation, text and table.](https://static.simonwillison.net/static/2025/olmocr-document-anchoring.jpg)
The one limitation of olmOCR at the moment is that it doesn't appear to do anything with diagrams, figures or illustrations. Vision models are actually very good at interpreting these now, so my ideal OCR solution would include detailed automated descriptions of this kind of content in the resulting text.
Update: Jonathan Soma figured out how to run it on a Mac using LM Studio and the olmocr Python package.
Llama 4 is making great progress in training. Llama 4 mini is done with pre-training and our reasoning models and larger model are looking good too. Our goal with Llama 3 was to make open source competitive with closed models, and our goal for Llama 4 is to lead. Llama 4 will be natively multimodal -- it's an omni-model -- and it will have agentic capabilities, so it's going to be novel and it's going to unlock a lot of new use cases.
— Mark Zuckerberg, on Meta's quarterly earnings report
DeepSeek Janus-Pro. Another impressive model release from DeepSeek. Janus is their series of "unified multimodal understanding and generation models" - these are models that can both accept images as input and generate images for output.
Janus-Pro is the new 7B model, which DeepSeek describe as "an advanced version of Janus, improving both multimodal understanding and visual generation significantly". It's released under the not fully open source DeepSeek license.
Janus-Pro is accompanied by this paper, which includes this note about the training:
Our Janus is trained and evaluated using HAI-LLM, which is a lightweight and efficient distributed training framework built on top of PyTorch. The whole training process took about 7/14 days on a cluster of 16/32 nodes for 1.5B/7B model, each equipped with 8 Nvidia A100 (40GB) GPUs.
It includes a lot of high benchmark scores, but closes with some notes on the model's current limitations:
In terms of multimodal understanding, the input resolution is limited to 384 × 384, which affects its performance in fine-grained tasks such as OCR. For text-to-image generation, the low resolution, combined with reconstruction losses introduced by the vision tokenizer, results in images that, while rich in semantic content, still lack fine details. For example, small facial regions occupying limited image space may appear under-detailed. Increasing the image resolution could mitigate these issues.
The easiest way to try this one out is using the Hugging Face Spaces demo. I tried the following prompt for the image generation capability:
A photo of a raccoon holding a handwritten sign that says "I love trash"
And got back this image:

It's now also been ported to Transformers.js, which means you can run the 1B model directly in a WebGPU browser such as Chrome here at webml-community/janus-pro-webgpu (loads about 2.24 GB of model files).
Qwen2.5 VL! Qwen2.5 VL! Qwen2.5 VL! Hot on the heels of yesterday's Qwen2.5-1M, here's Qwen2.5 VL (with an excitable announcement title) - the latest in Qwen's series of vision LLMs.
They're releasing multiple versions: base models and instruction tuned models at 3B, 7B and 72B. There's a lot of additional information in their README.
The 72B model can be selected on Qwen's Qwen Chat interface. I gave it this image of our dog Cleo joy rolling on the beach:

And prompted:
Describe this image in detail, be flowery
(Since the Qwen team tends to use flowery language in their announcements.)
Here's what I got back:
In this enchanting tableau, a canine companion finds solace in the embrace of nature's softest bed. The sandy expanse stretches out like an endless canvas, its surface etched with the delicate imprints of countless wanderers who have come and gone, leaving behind a tapestry of footprints that whisper tales of joyous romps and serene strolls.
The dog, a vision of contentment, lies sprawled upon the sand, its dark fur gleaming under the gentle caress of the sun. Its body is relaxed, limbs splayed in abandon, as if it has surrendered to the soothing rhythm of the beach. A vibrant red collar adorns its neck, a splash of color against the muted tones of the surroundings, hinting at the care and love bestowed upon this cherished pet.
The sand itself is a work of art, its grains shimmering with a silvery sheen that catches the light. Here and there, small tufts of seaweed peek through, remnants of the ocean's bounty, adding a touch of wild beauty to the scene. The shadows cast by unseen objects dance across the sand, creating a play of light and dark that lends an air of mystery to the tranquil setting.
This moment, frozen in time, speaks of peace and harmony, where man's best friend finds respite in the simple pleasures of life. It is a scene that invites one to pause, breathe deeply, and revel in the serenity of nature's embrace.
I'm looking forward to trying out their smaller models - the 3B model in particular should be small enough to run comfortably even on an iPhone, so hopefully someone will wire up an example of that soon (maybe using MLX).
VB points out that the vision benchmarks for Qwen 2.5 VL 7B show it out-performing GPT-4o mini!
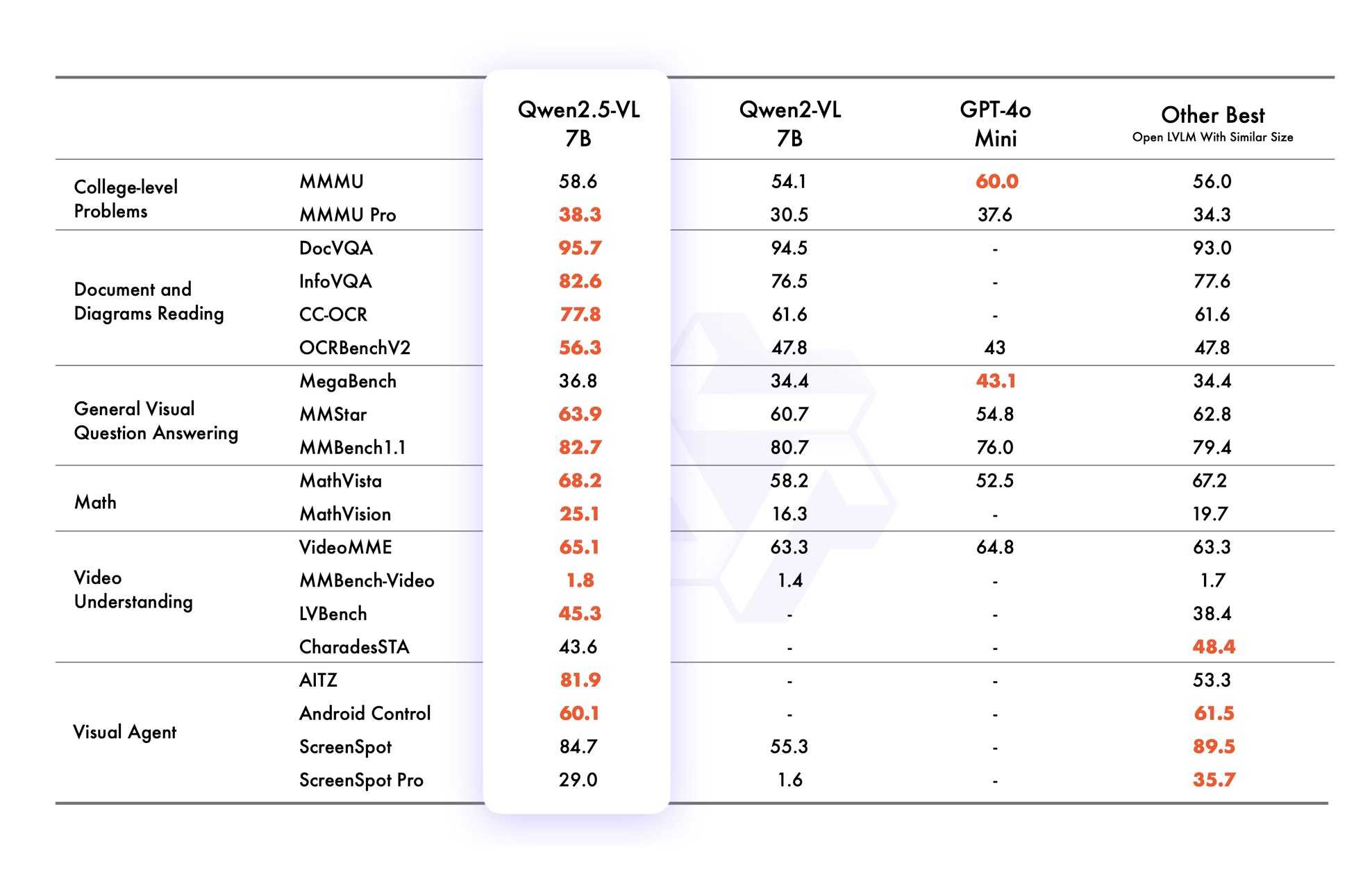
Qwen2.5 VL cookbooks
Qwen also just published a set of cookbook recipes:
- universal_recognition.ipynb demonstrates basic visual Q&A, including prompts like
Who are these in this picture? Please give their names in Chinese and Englishagainst photos of celebrities, an ability other models have deliberately suppressed. - spatial_understanding.ipynb demonstrates bounding box support, with prompts like
Locate the top right brown cake, output its bbox coordinates using JSON format. - video_understanding.ipynb breaks a video into individual frames and asks questions like
Could you go into detail about the content of this long video? - ocr.ipynb shows
Qwen2.5-VL-7B-Instructperforming OCR in multiple different languages. - document_parsing.ipynb uses Qwen to convert images of documents to HTML and other formats, and notes that "we introduce a unique Qwenvl HTML format that includes positional information for each component, enabling precise document reconstruction and manipulation."
- mobile_agent.ipynb runs Qwen with tool use against tools for controlling a mobile phone, similar to ChatGPT Operator or Claude Computer Use.
- computer_use.ipynb showcases "GUI grounding" - feeding in screenshots of a user's desktop and running tools for things like left clicking on a specific coordinate.
Running it with mlx-vlm
Update 30th January 2025: I got it working on my Mac using uv and mlx-vlm, with some hints from this issue. Here's the recipe that worked (downloading a 9GB model from mlx-community/Qwen2.5-VL-7B-Instruct-8bit):
uv run --with 'numpy<2' --with 'git+https://github.com/huggingface/transformers' \
--with mlx-vlm \
python -m mlx_vlm.generate \
--model mlx-community/Qwen2.5-VL-7B-Instruct-8bit \
--max-tokens 100 \
--temp 0.0 \
--prompt "Describe this image." \
--image path-to-image.pngI ran that against this image:
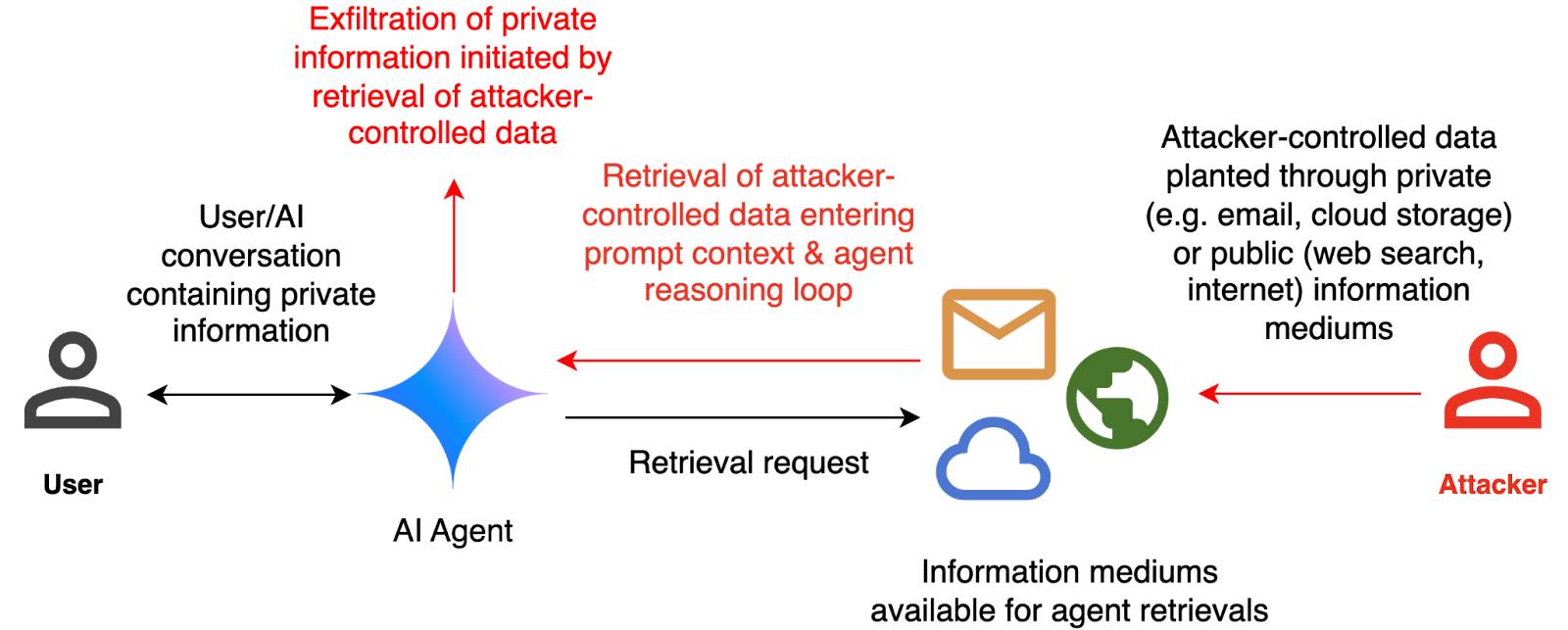
And got back this result:
The image appears to illustrate a flowchart or diagram related to a cybersecurity scenario. Here's a breakdown of the elements:
- User: Represented by a simple icon of a person.
- AI Agent: Represented by a blue diamond shape.
- Attacker: Represented by a red icon of a person.
- Cloud and Email Icons: Represented by a cloud and an envelope, indicating data or information being transferred.
- Text: The text
The leading AI models are now very good historians (via) UC Santa Cruz's Benjamin Breen (previously) explores how the current crop of top tier LLMs - GPT-4o, o1, and Claude Sonnet 3.5 - are proving themselves competent at a variety of different tasks relevant to academic historians.
The vision models are now capable of transcribing and translating scans of historical documents - in this case 16th century Italian cursive handwriting and medical recipes from 1770s Mexico.
Even more interestingly, the o1 reasoning model was able to produce genuinely useful suggestions for historical interpretations against prompts like this one:
Here are some quotes from William James’ complete works, referencing Francis galton and Karl Pearson. What are some ways we can generate new historical knowledge or interpretations on the basis of this? I want a creative, exploratory, freewheeling analysis which explores the topic from a range of different angles and which performs metacognitive reflection on research paths forward based on this, especially from a history of science and history of technology perspectives. end your response with some further self-reflection and self-critique, including fact checking. then provide a summary and ideas for paths forward. What further reading should I do on this topic? And what else jumps out at you as interesting from the perspective of a professional historian?
How good? He followed-up by asking for "the most creative, boundary-pushing, or innovative historical arguments or analyses you can formulate based on the sources I provided" and described the resulting output like this:
The supposedly “boundary-pushing” ideas it generated were all pretty much what a class of grad students would come up with — high level and well-informed, but predictable.
As Benjamin points out, this is somewhat expected: LLMs "are exquisitely well-tuned machines for finding the median viewpoint on a given issue" - something that's already being illustrated by the sameness of work from his undergraduates who are clearly getting assistance from ChatGPT.
I'd be fascinated to hear more from academics outside of the computer science field who are exploring these new tools in a similar level of depth.
Update: Something that's worth emphasizing about this article: all of the use-cases Benjamin describes here involve feeding original source documents to the LLM as part of their input context. I've seen some criticism of this article that assumes he's asking LLMs to answer questions baked into their weights (as this NeurIPS poster demonstrates, even the best models don't have perfect recall of a wide range of historical facts). That's not what he's doing here.
2024
Trying out QvQ—Qwen’s new visual reasoning model

I thought we were done for major model releases in 2024, but apparently not: Alibaba’s Qwen team just dropped the Apache 2.0 licensed Qwen licensed (the license changed) QvQ-72B-Preview, “an experimental research model focusing on enhancing visual reasoning capabilities”.
OpenAI: Voice mode FAQ. Given how impressed I was by the Gemini 2.0 Flash audio and video streaming demo on Wednesday it's only fair that I highlight that OpenAI shipped their equivalent of that feature to ChatGPT in production on Thursday, for day 6 of their "12 days of OpenAI" series.
I got access in the ChatGPT iPhone app this morning. It's equally impressive: in an advanced voice mode conversation you can now tap the camera icon to start sharing a live video stream with ChatGPT. I introduced it to my chickens and told it their names and it was then able to identify each of them later in that same conversation. Apparently the ChatGPT desktop app can do screen sharing too, though that feature hasn't rolled out to me just yet.
(For the rest of December you can also have it take on a Santa voice and personality - I had Santa read me out Haikus in Welsh about what he could see through my camera earlier.)
Given how cool this is, it's frustrating that there's no obvious page (other than this FAQ) to link to for the announcement of the feature! Surely this deserves at least an article in the OpenAI News blog?
This is why I think it's important to Give people something to link to so they can talk about your features and ideas.
Gemini 2.0 Flash: An outstanding multi-modal LLM with a sci-fi streaming mode
Huge announcment from Google this morning: Introducing Gemini 2.0: our new AI model for the agentic era. There’s a ton of stuff in there (including updates on Project Astra and the new Project Mariner), but the most interesting pieces are the things we can start using today, built around the brand new Gemini 2.0 Flash model. The developer blog post has more of the technical details, and the Gemini 2.0 Cookbook is useful for understanding the API via Python code examples.
[... 1,740 words]First impressions of the new Amazon Nova LLMs (via a new llm-bedrock plugin)
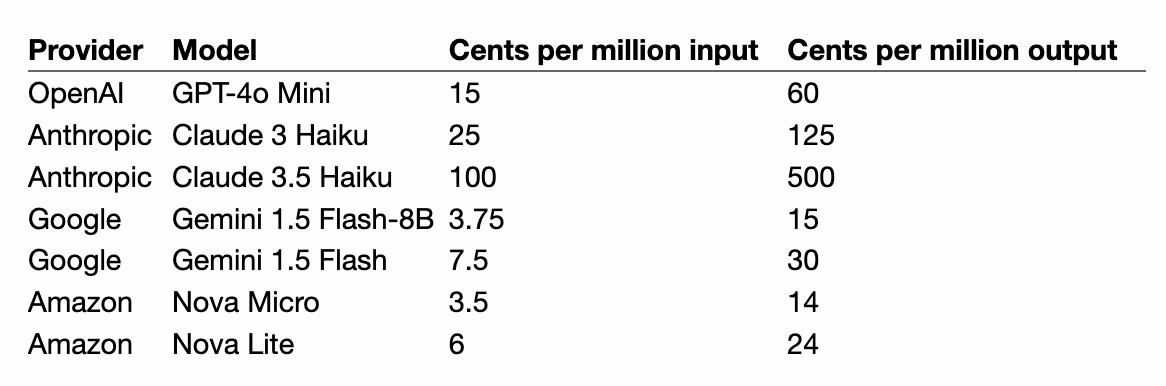
Amazon released three new Large Language Models yesterday at their AWS re:Invent conference. The new model family is called Amazon Nova and comes in three sizes: Micro, Lite and Pro.
[... 2,385 words]SmolVLM—small yet mighty Vision Language Model. I've been having fun playing with this new vision model from the Hugging Face team behind SmolLM. They describe it as:
[...] a 2B VLM, SOTA for its memory footprint. SmolVLM is small, fast, memory-efficient, and fully open-source. All model checkpoints, VLM datasets, training recipes and tools are released under the Apache 2.0 license.
I've tried it in a few flavours but my favourite so far is the mlx-vlm approach, via mlx-vlm author Prince Canuma. Here's the uv recipe I'm using to run it:
uv run \
--with mlx-vlm \
--with torch \
python -m mlx_vlm.generate \
--model mlx-community/SmolVLM-Instruct-bf16 \
--max-tokens 500 \
--temp 0.5 \
--prompt "Describe this image in detail" \
--image IMG_4414.JPG
If you run into an error using Python 3.13 (torch compatibility) try uv run --python 3.11 instead.
This one-liner installs the necessary dependencies, downloads the model (about 4.2GB, saved to ~/.cache/huggingface/hub/models--mlx-community--SmolVLM-Instruct-bf16) and executes the prompt and displays the result.
I ran that against this Pelican photo:

The model replied:
In the foreground of this photograph, a pelican is perched on a pile of rocks. The pelican’s wings are spread out, and its beak is open. There is a small bird standing on the rocks in front of the pelican. The bird has its head cocked to one side, and it seems to be looking at the pelican. To the left of the pelican is another bird, and behind the pelican are some other birds. The rocks in the background of the image are gray, and they are covered with a variety of textures. The rocks in the background appear to be wet from either rain or sea spray.
There are a few spatial mistakes in that description but the vibes are generally in the right direction.
On my 64GB M2 MacBook pro it read the prompt at 7.831 tokens/second and generated that response at an impressive 74.765 tokens/second.
Say hello to gemini-exp-1121. Google Gemini's Logan Kilpatrick on Twitter:
Say hello to gemini-exp-1121! Our latest experimental gemini model, with:
- significant gains on coding performance
- stronger reasoning capabilities
- improved visual understanding
Available on Google AI Studio and the Gemini API right now
The 1121 in the name is a release date of the 21st November. This comes fast on the heels of last week's gemini-exp-1114.
Both of these new experimental Gemini models have seen moments at the top of the Chatbot Arena. gemini-exp-1114 took the top spot a few days ago, and then lost it to a new OpenAI model called "ChatGPT-4o-latest (2024-11-20)"... only for the new gemini-exp-1121 to hold the top spot right now.
(These model names are all so, so bad.)
I released llm-gemini 0.4.2 with support for the new model - this should have been 0.5 but I already have a 0.5a0 alpha that depends on an unreleased feature in LLM core.
I tried my pelican benchmark:
llm -m gemini-exp-1121 'Generate an SVG of a pelican riding a bicycle'

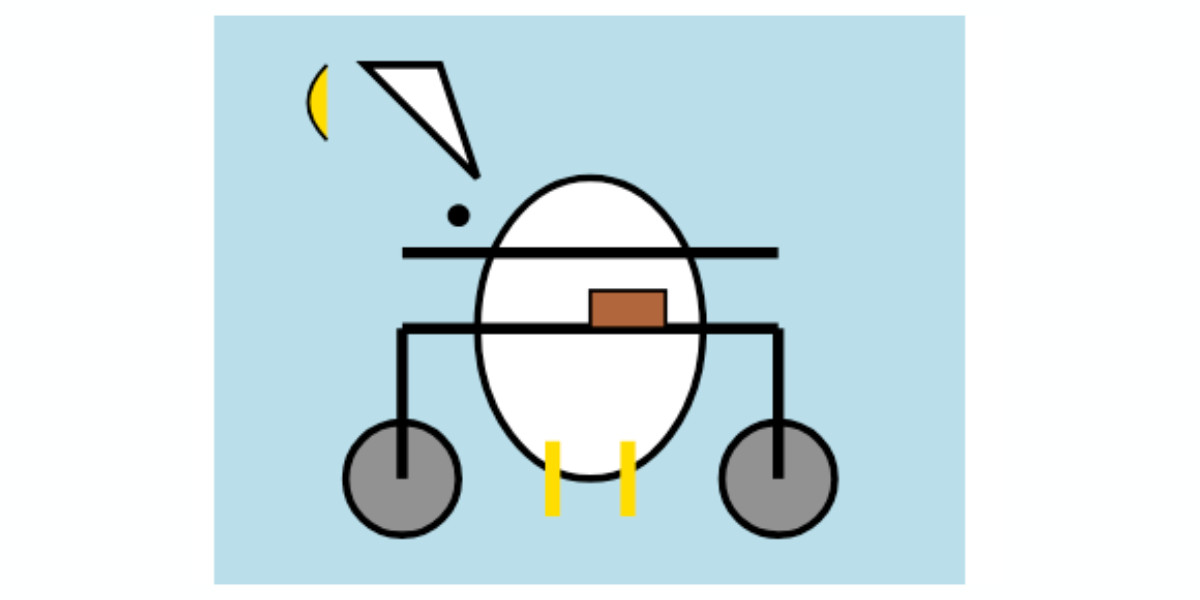
Since Gemini is a multi-modal vision model, I had it describe the image it had created back to me (by feeding it a PNG render):
llm -m gemini-exp-1121 describe -a pelican.png
And got this description, which is pretty great:
The image shows a simple, stylized drawing of an insect, possibly a bee or an ant, on a vehicle. The insect is composed of a large yellow circle for the body and a smaller yellow circle for the head. It has a black dot for an eye, a small orange oval for a beak or mouth, and thin black lines for antennae and legs. The insect is positioned on top of a simple black and white vehicle with two black wheels. The drawing is abstract and geometric, using basic shapes and a limited color palette of black, white, yellow, and orange.
Update: Logan confirmed on Twitter that these models currently only have a 32,000 token input, significantly less than the rest of the Gemini family.
Pixtral Large (via) New today from Mistral:
Today we announce Pixtral Large, a 124B open-weights multimodal model built on top of Mistral Large 2. Pixtral Large is the second model in our multimodal family and demonstrates frontier-level image understanding.
The weights are out on Hugging Face (over 200GB to download, and you'll need a hefty GPU rig to run them). The license is free for academic research but you'll need to pay for commercial usage.
The new Pixtral Large model is available through their API, as models called pixtral-large-2411 and pixtral-large-latest.
Here's how to run it using LLM and the llm-mistral plugin:
llm install -U llm-mistral
llm keys set mistral
# paste in API key
llm mistral refresh
llm -m mistral/pixtral-large-latest describe -a https://static.simonwillison.net/static/2024/pelicans.jpg
The image shows a large group of birds, specifically pelicans, congregated together on a rocky area near a body of water. These pelicans are densely packed together, some looking directly at the camera while others are engaging in various activities such as preening or resting. Pelicans are known for their large bills with a distinctive pouch, which they use for catching fish. The rocky terrain and the proximity to water suggest this could be a coastal area or an island where pelicans commonly gather in large numbers. The scene reflects a common natural behavior of these birds, often seen in their nesting or feeding grounds.

Update: I released llm-mistral 0.8 which adds async model support for the full Mistral line, plus a new llm -m mistral-large shortcut alias for the Mistral Large model.
Ollama: Llama 3.2 Vision. Ollama released version 0.4 last week with support for Meta's first Llama vision model, Llama 3.2.
If you have Ollama installed you can fetch the 11B model (7.9 GB) like this:
ollama pull llama3.2-vision
Or the larger 90B model (55GB download, likely needs ~88GB of RAM) like this:
ollama pull llama3.2-vision:90b
I was delighted to learn that Sukhbinder Singh had already contributed support for LLM attachments to Sergey Alexandrov's llm-ollama plugin, which means the following works once you've pulled the models:
llm install --upgrade llm-ollama
llm -m llama3.2-vision:latest 'describe' \
-a https://static.simonwillison.net/static/2024/pelican.jpg
This image features a brown pelican standing on rocks, facing the camera and positioned to the left of center. The bird's long beak is a light brown color with a darker tip, while its white neck is adorned with gray feathers that continue down to its body. Its legs are also gray.
In the background, out-of-focus boats and water are visible, providing context for the pelican's environment.

That's not a bad description of this image, especially for a 7.9GB model that runs happily on my MacBook Pro.
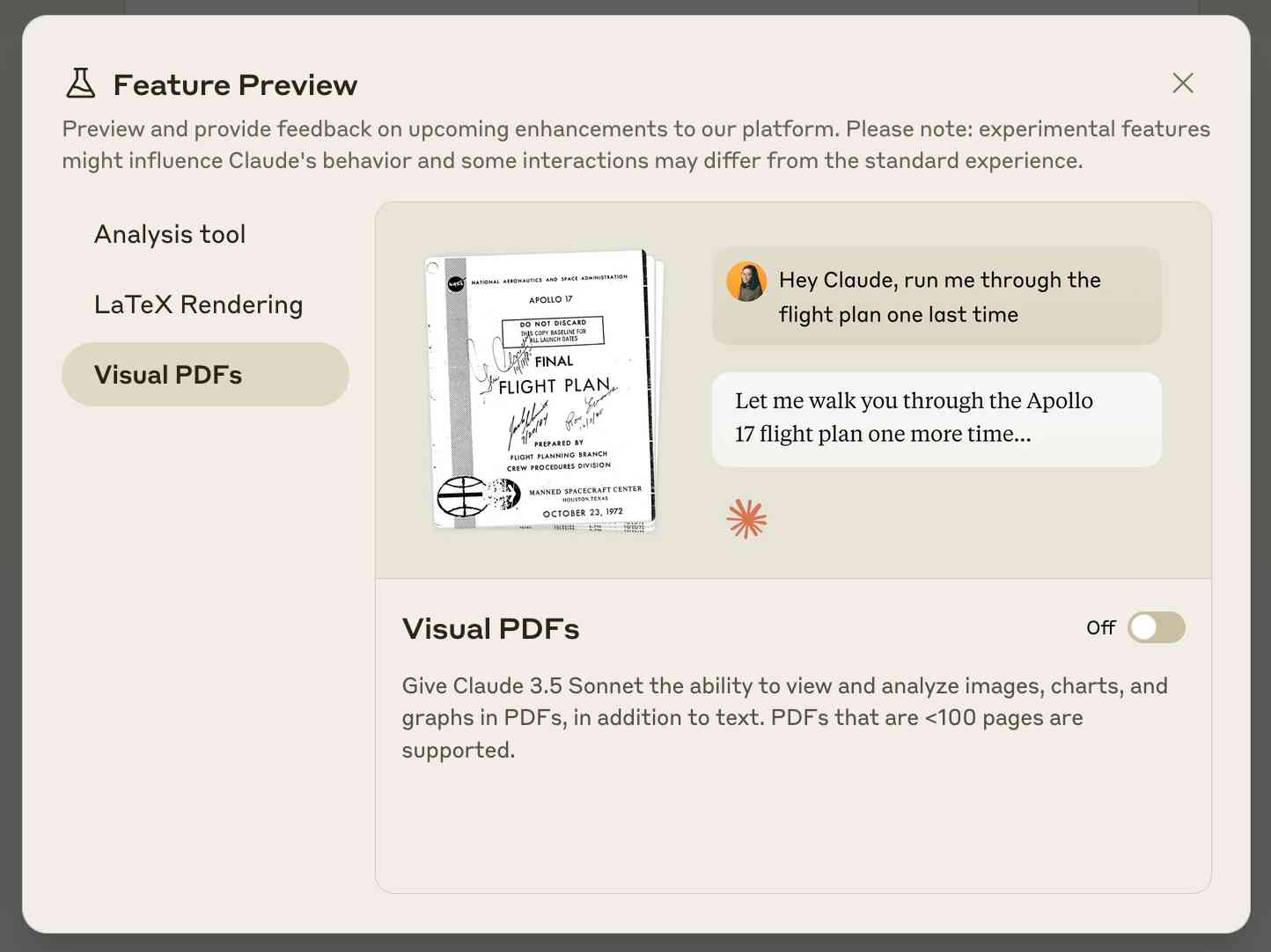
Claude API: PDF support (beta) (via) Claude 3.5 Sonnet now accepts PDFs as attachments:
The new Claude 3.5 Sonnet (
claude-3-5-sonnet-20241022) model now supports PDF input and understands both text and visual content within documents.
I just released llm-claude-3 0.7 with support for the new attachment type (attachments are a very new feature), so now you can do this:
llm install llm-claude-3 --upgrade
llm -m claude-3.5-sonnet 'extract text' -a mydoc.pdf
Visual PDF analysis can also be turned on for the Claude.ai application:
Also new today: Claude now offers a free (albeit rate-limited) token counting API. This addresses a complaint I've had for a while: previously it wasn't possible to accurately estimate the cost of a prompt before sending it to be executed.
Generating Descriptive Weather Reports with LLMs. Drew Breunig produces the first example I've seen in the wild of the new LLM attachments Python API. Drew's Downtown San Francisco Weather Vibes project combines output from a JSON weather API with the latest image from a webcam pointed at downtown San Francisco to produce a weather report "with a style somewhere between Jack Kerouac and J. Peterman".
Here's the Python code that constructs and executes the prompt. The code runs in GitHub Actions.
You can now run prompts against images, audio and video in your terminal using LLM
I released LLM 0.17 last night, the latest version of my combined CLI tool and Python library for interacting with hundreds of different Large Language Models such as GPT-4o, Llama, Claude and Gemini.
[... 1,399 words]