92 posts tagged “vibe-coding”
As defined here - not the same thing as AI-assisted programming, though there's some overlap.
2026
Porting the Moebius 0.2B image inpainting model to run in the browser with Claude Code

This morning on Hacker News I saw Moebius: 0.2B Lightweight Image Inpainting Framework with 10B-Level Performance, describing a small but effective inpainting model—a model where you can mark regions of an image to remove and the model imagines what should fill the space. The released model required PyTorch and NVIDIA CUDA, but since it described itself as 0.2B I decided to try and get it running using WebGPU in a browser. TL;DR: I got it working, and you can try the demo at simonw.github.io/moebius-web/. Read on for the details.
[... 1,764 words]Claude helped me build this tool for creating QR codes, for both text/URLs and for connecting to WiFi networks.
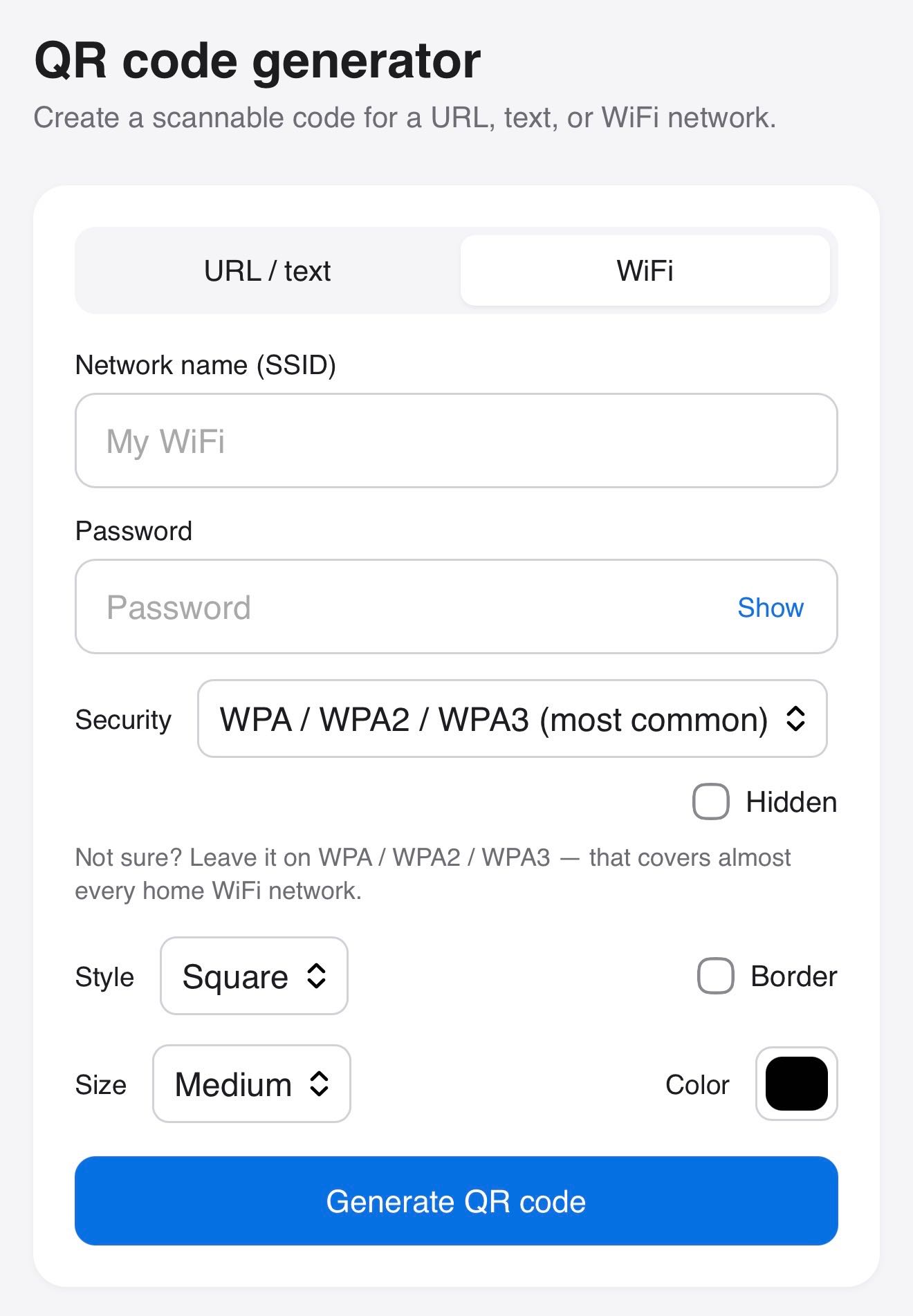
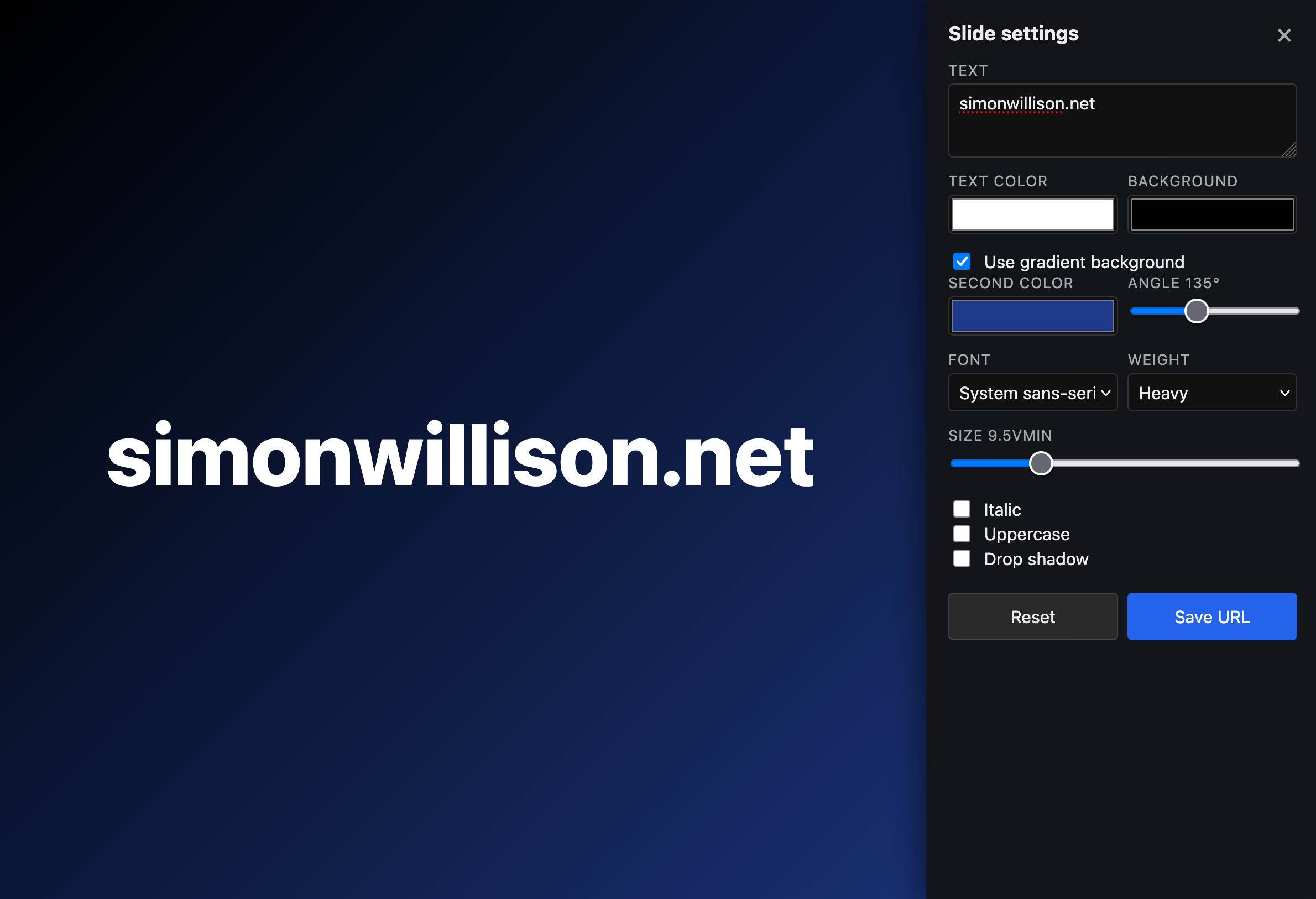
I'm using my vibe coded macOS presentations tool to put together a talk, and I wanted to add a slide with some text on it. The tool only accepts URLs, so I put together a quick page that accepts query string arguments and turns them into a simple slide.
Here's an example: https://tools.simonwillison.net/big-words?text=simonwillison.net&gradient=1&size=9.5
Double click or double tap the page to access a form for modifying the different options.
Vibe coding and agentic engineering are getting closer than I’d like
I recently talked with Joseph Ruscio about AI coding tools for Heavybit’s High Leverage podcast: Ep. #9, The AI Coding Paradigm Shift with Simon Willison. Here are some of my highlights, including my disturbing realization that vibe coding and agentic engineering have started to converge in my own work.
[... 1,542 words]We need RSS for sharing abundant vibe-coded apps. Matt Webb:
I would love an RSS web feed for all those various tools and apps pages, each item with an “Install” button. (But install to where?)
The lesson here is that when vibe-coding accelerates app development, apps become more personal, more situated, and more frequent. Shipping a tool or a micro-app is less like launching a website and more like posting on a blog.
This inspired me to have Claude add an Atom feed (and icon) to my /elsewhere/tools/ page, which itself is populated by content from my tools.simonwillison.net site.
Five months in, I think I've decided that I don't want to vibecode — I want professionally managed software companies to use AI coding assistance to make more/better/cheaper software products that they sell to me for money.
— Matthew Yglesias, in a now-deleted Tweet
Extract PDF text in your browser with LiteParse for the web
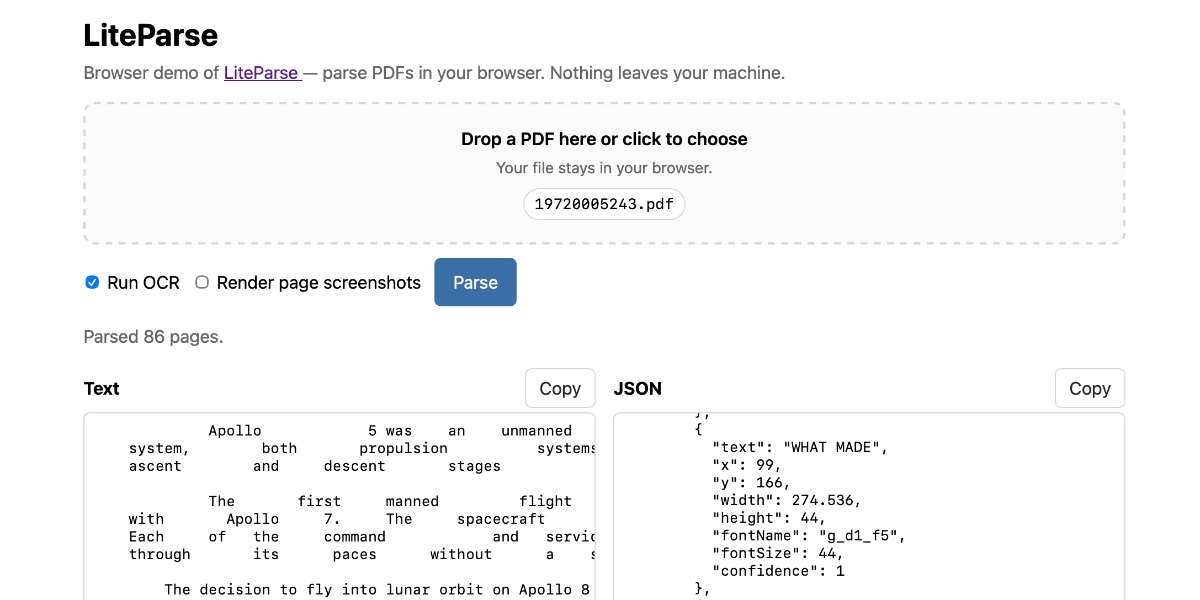
LlamaIndex have a most excellent open source project called LiteParse, which provides a Node.js CLI tool for extracting text from PDFs. I got a version of LiteParse working entirely in the browser, using most of the same libraries that LiteParse uses to run in Node.js.
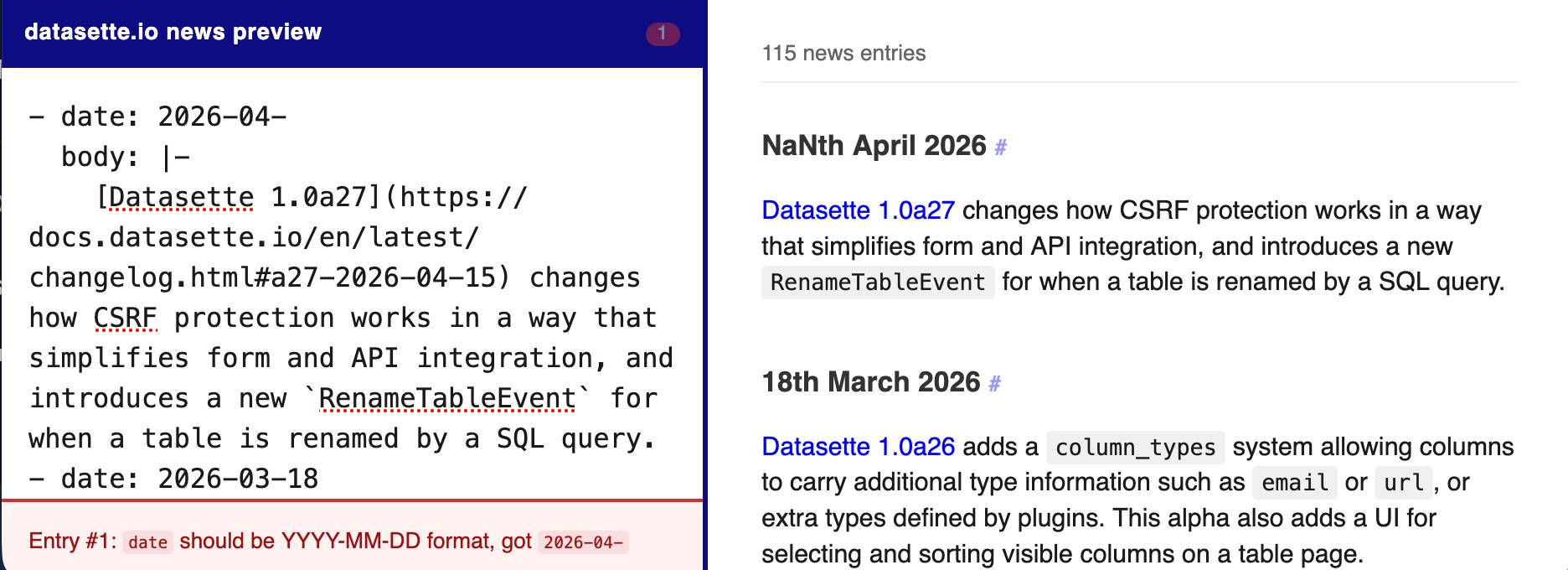
[... 2,089 words]The datasette.io website has a news section built from this news.yaml file in the underlying GitHub repository. The YAML format looks like this:
- date: 2026-04-15
body: |-
[Datasette 1.0a27](https://docs.datasette.io/en/latest/changelog.html#a27-2026-04-15) changes how CSRF protection works in a way that simplifies form and API integration, and introduces a new `RenameTableEvent` for when a table is renamed by a SQL query.
- date: 2026-03-18
body: |-
...
This format is a little hard to edit, so I finally had Claude build a custom preview UI to make checking for errors have slightly less friction.
I built it using standard claude.ai and Claude Artifacts, taking advantage of Claude's ability to clone GitHub repos and look at their content as part of a regular chat:
Clone https://github.com/simonw/datasette.io and look at the news.yaml file and how it is rendered on the homepage. Build an artifact I can paste that YAML into which previews what it will look like, and highlights any markdown errors or YAML errors
Gemini 3.1 Flash TTS. Google released Gemini 3.1 Flash TTS today, a new text-to-speech model that can be directed using prompts.
It's presented via the standard Gemini API using gemini-3.1-flash-tts-preview as the model ID, but can only output audio files.
The prompting guide is surprising, to say the least. Here's their example prompt to generate just a few short sentences of audio:
# AUDIO PROFILE: Jaz R.
## "The Morning Hype"
## THE SCENE: The London Studio
It is 10:00 PM in a glass-walled studio overlooking the moonlit London skyline, but inside, it is blindingly bright. The red "ON AIR" tally light is blazing. Jaz is standing up, not sitting, bouncing on the balls of their heels to the rhythm of a thumping backing track. Their hands fly across the faders on a massive mixing desk. It is a chaotic, caffeine-fueled cockpit designed to wake up an entire nation.
### DIRECTOR'S NOTES
Style:
* The "Vocal Smile": You must hear the grin in the audio. The soft palate is always raised to keep the tone bright, sunny, and explicitly inviting.
* Dynamics: High projection without shouting. Punchy consonants and elongated vowels on excitement words (e.g., "Beauuutiful morning").
Pace: Speaks at an energetic pace, keeping up with the fast music. Speaks with A "bouncing" cadence. High-speed delivery with fluid transitions — no dead air, no gaps.
Accent: Jaz is from Brixton, London
### SAMPLE CONTEXT
Jaz is the industry standard for Top 40 radio, high-octane event promos, or any script that requires a charismatic Estuary accent and 11/10 infectious energy.
#### TRANSCRIPT
[excitedly] Yes, massive vibes in the studio! You are locked in and it is absolutely popping off in London right now. If you're stuck on the tube, or just sat there pretending to work... stop it. Seriously, I see you.
[shouting] Turn this up! We've got the project roadmap landing in three, two... let's go!
Here's what I got using that example prompt:
Then I modified it to say "Jaz is from Newcastle" and "... requires a charismatic Newcastle accent" and got this result:
Here's Exeter, Devon for good measure:
I had Gemini 3.1 Pro vibe code this UI for trying it out:
![Screenshot of a "Gemini 3.1 Flash TTS" web application interface. At the top is an "API Key" field with a masked password. Below is a "TTS Mode" section with a dropdown set to "Multi-Speaker (Conversation)". "Speaker 1 Name" is set to "Joe" with "Speaker 1 Voice" set to "Puck (Upbeat)". "Speaker 2 Name" is set to "Jane" with "Speaker 2 Voice" set to "Kore (Firm)". Under "Script / Prompt" is a tip reading "Tip: Format your text as a script using the Exact Speaker Names defined above." The script text area contains "TTS the following conversation between Joe and Jane:\n\nJoe: How's it going today Jane?\nJane: [yawn] Not too bad, how about you?" A blue "Generate Audio" button is below. At the bottom is a "Success!" message with an audio player showing 00:00 / 00:06 and a "Download WAV" link.](https://static.simonwillison.net/static/2026/gemini-flash-tts.jpg)
Cybersecurity Looks Like Proof of Work Now. The UK's AI Safety Institute recently published Our evaluation of Claude Mythos Preview’s cyber capabilities, their own independent analysis of Claude Mythos which backs up Anthropic's claims that it is exceptionally effective at identifying security vulnerabilities.
Drew Breunig notes that AISI's report shows that the more tokens (and hence money) they spent the better the result they got, which leads to a strong economic incentive to spend as much as possible on security reviews:
If Mythos continues to find exploits so long as you keep throwing money at it, security is reduced to a brutally simple equation: to harden a system you need to spend more tokens discovering exploits than attackers will spend exploiting them.
An interesting result of this is that open source libraries become more valuable, since the tokens spent securing them can be shared across all of their users. This directly counters the idea that the low cost of vibe-coding up a replacement for an open source library makes those open source projects less attractive.
Eight years of wanting, three months of building with AI (via) Lalit Maganti provides one of my favorite pieces of long-form writing on agentic engineering I've seen in ages.
They spent eight years thinking about and then three months building syntaqlite, which they describe as "high-fidelity devtools that SQLite deserves".
The goal was to provide fast, robust and comprehensive linting and verifying tools for SQLite, suitable for use in language servers and other development tools - a parser, formatter, and verifier for SQLite queries. I've found myself wanting this kind of thing in the past myself, hence my (far less production-ready) sqlite-ast project from a few months ago.
Lalit had been procrastinating on this project for years, because of the inevitable tedium of needing to work through 400+ grammar rules to help build a parser. That's exactly the kind of tedious work that coding agents excel at!
Claude Code helped get over that initial hump and build the first prototype:
AI basically let me put aside all my doubts on technical calls, my uncertainty of building the right thing and my reluctance to get started by giving me very concrete problems to work on. Instead of “I need to understand how SQLite’s parsing works”, it was “I need to get AI to suggest an approach for me so I can tear it up and build something better". I work so much better with concrete prototypes to play with and code to look at than endlessly thinking about designs in my head, and AI lets me get to that point at a pace I could not have dreamed about before. Once I took the first step, every step after that was so much easier.
That first vibe-coded prototype worked great as a proof of concept, but they eventually made the decision to throw it away and start again from scratch. AI worked great for the low level details but did not produce a coherent high-level architecture:
I found that AI made me procrastinate on key design decisions. Because refactoring was cheap, I could always say “I’ll deal with this later.” And because AI could refactor at the same industrial scale it generated code, the cost of deferring felt low. But it wasn’t: deferring decisions corroded my ability to think clearly because the codebase stayed confusing in the meantime.
The second attempt took a lot longer and involved a great deal more human-in-the-loop decision making, but the result is a robust library that can stand the test of time.
It's worth setting aside some time to read this whole thing - it's full of non-obvious downsides to working heavily with AI, as well as a detailed explanation of how they overcame those hurdles.
The key idea I took away from this concerns AI's weakness in terms of design and architecture:
When I was working on something where I didn’t even know what I wanted, AI was somewhere between unhelpful and harmful. The architecture of the project was the clearest case: I spent weeks in the early days following AI down dead ends, exploring designs that felt productive in the moment but collapsed under scrutiny. In hindsight, I have to wonder if it would have been faster just thinking it through without AI in the loop at all.
But expertise alone isn’t enough. Even when I understood a problem deeply, AI still struggled if the task had no objectively checkable answer. Implementation has a right answer, at least at a local level: the code compiles, the tests pass, the output matches what you asked for. Design doesn’t. We’re still arguing about OOP decades after it first took off.
The thing about agentic coding is that agents grind problems into dust. Give an agent a problem and a while loop and - long term - it’ll solve that problem even if it means burning a trillion tokens and re-writing down to the silicon. [...]
But we want AI agents to solve coding problems quickly and in a way that is maintainable and adaptive and composable (benefiting from improvements elsewhere), and where every addition makes the whole stack better.
So at the bottom is really great libraries that encapsulate hard problems, with great interfaces that make the “right” way the easy way for developers building apps with them. Architecture!
While I’m vibing (I call it vibing now, not coding and not vibe coding) while I’m vibing, I am looking at lines of code less than ever before, and thinking about architecture more than ever before.
— Matt Webb, An appreciation for (technical) architecture
Vibe coding SwiftUI apps is a lot of fun
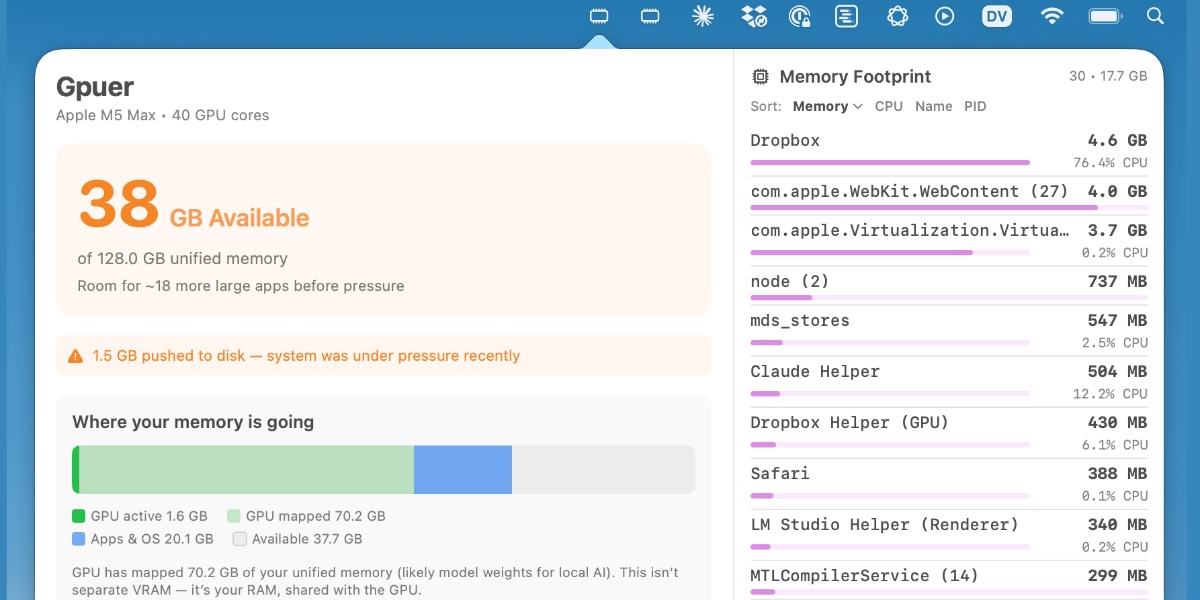
I have a new laptop—a 128GB M5 MacBook Pro, which early impressions show to be very capable for running good local LLMs. I got frustrated with Activity Monitor and decided to vibe code up some alternative tools for monitoring performance and I’m very happy with the results.
[... 1,195 words]Simply put: It’s a big mess, and no off-the-shelf accounting software does what I need. So after years of pain, I finally sat down last week and started to build my own. It took me about five days. I am now using the best piece of accounting software I’ve ever used. It’s blazing fast. Entirely local. Handles multiple currencies and pulls daily (historical) conversion rates. It’s able to ingest any CSV I throw at it and represent it in my dashboard as needed. It knows US and Japan tax requirements, and formats my expenses and medical bills appropriately for my accountants. I feed it past returns to learn from. I dump 1099s and K1s and PDFs from hospitals into it, and it categorizes and organizes and packages them all as needed. It reconciles international wire transfers, taking into account small variations in FX rates and time for the transfers to complete. It learns as I categorize expenses and categorizes automatically going forward. It’s easy to do spot checks on data. If I find an anomaly, I can talk directly to Claude and have us brainstorm a batched solution, often saving me from having to manually modify hundreds of entries. And often resulting in a new, small, feature tweak. The software feels organic and pliable in a form perfectly shaped to my hand, able to conform to any hunk of data I throw at it. It feels like bushwhacking with a lightsaber.
— Craig Mod, Software Bonkers
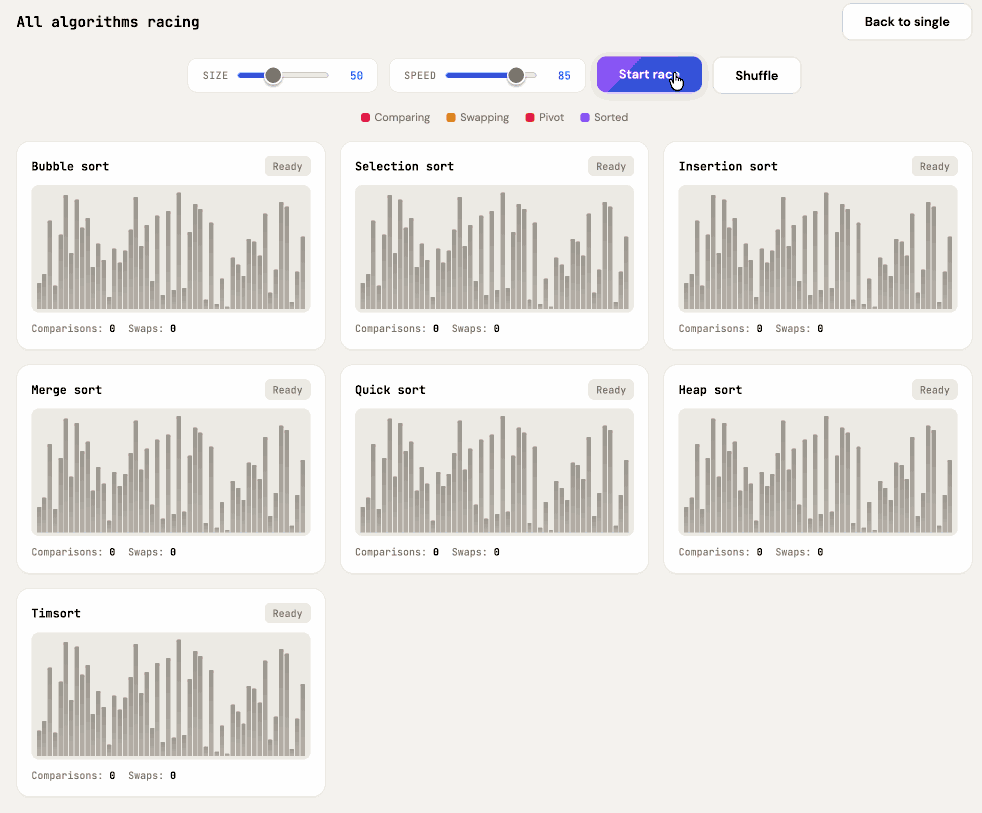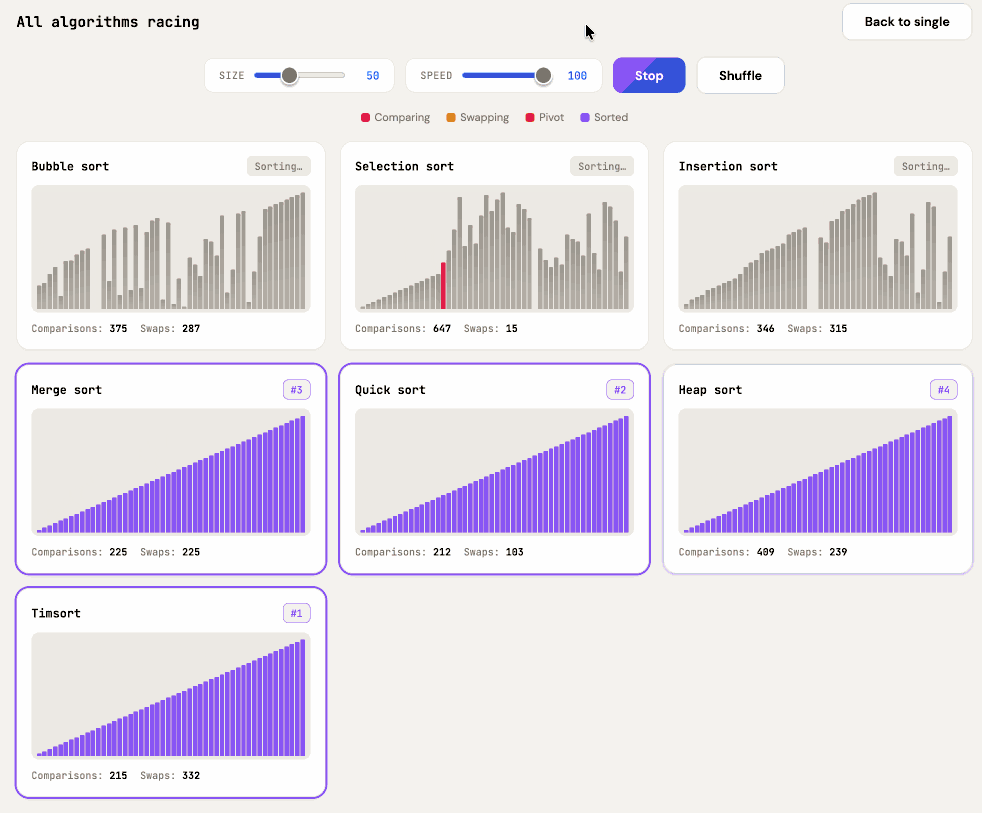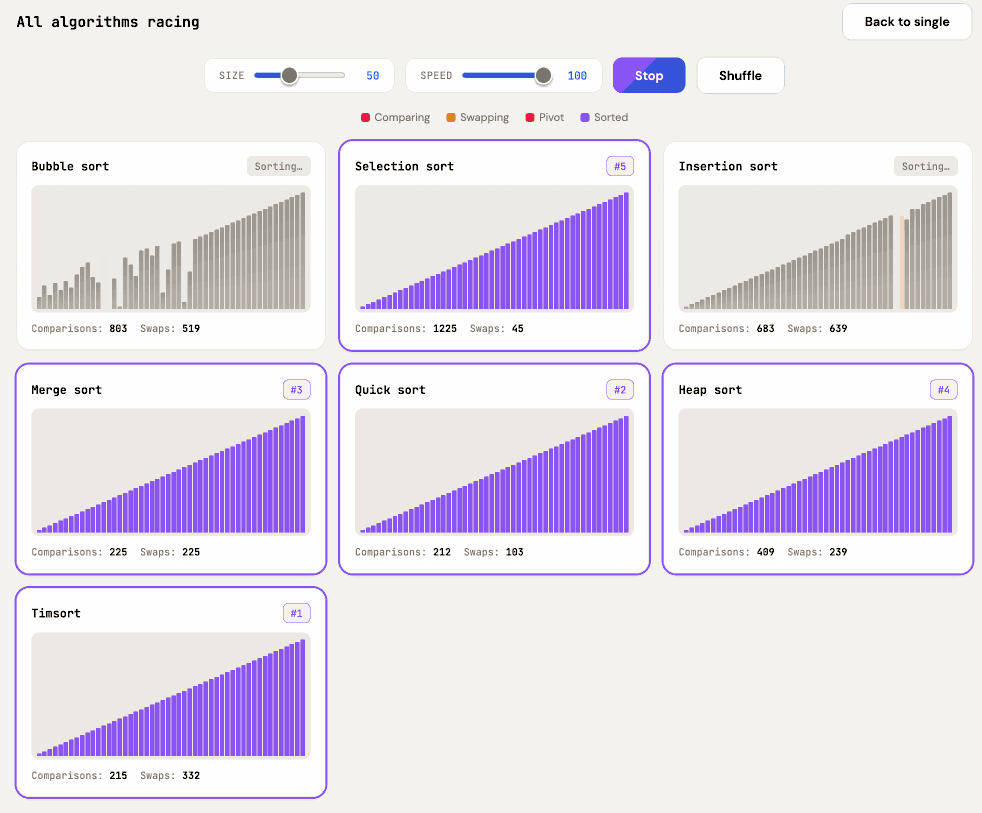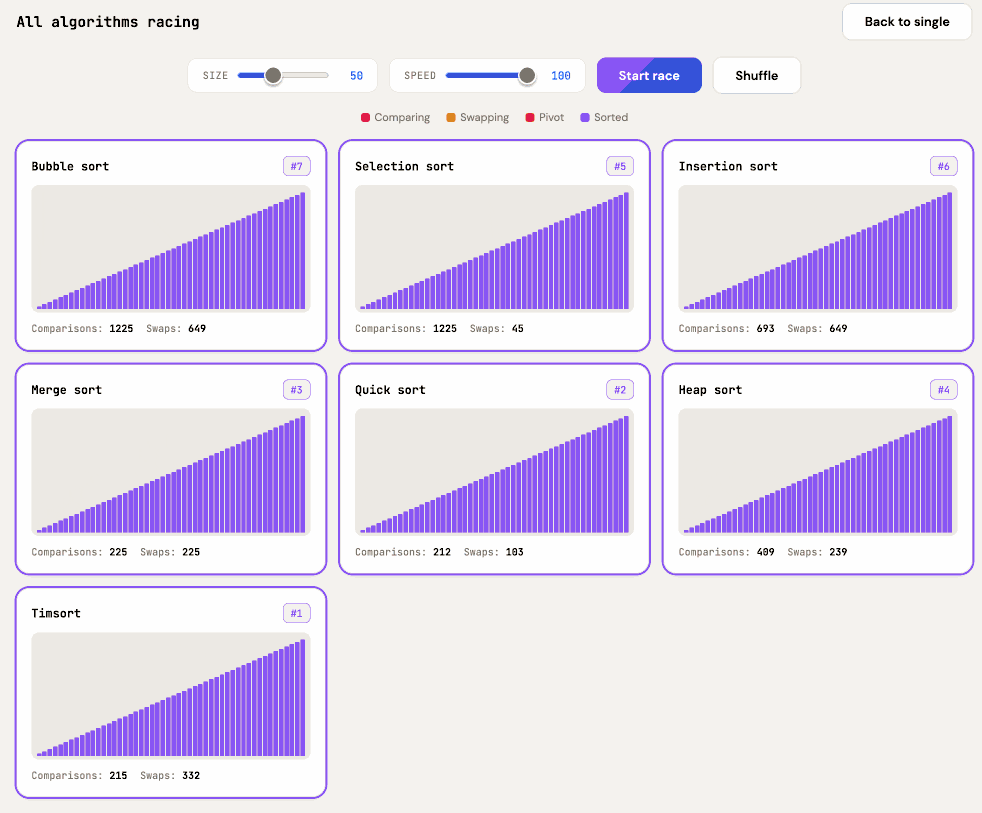
Sorting algorithms. Today in animated explanations built using Claude: I've always been a fan of animated demonstrations of sorting algorithms so I decided to spin some up on my phone using Claude Artifacts, then added Python's timsort algorithm, then a feature to run them all at once. Here's the full sequence of prompts:
Interactive animated demos of the most common sorting algorithms
This gave me bubble sort, selection sort, insertion sort, merge sort, quick sort, and heap sort.
Add timsort, look up details in a clone of python/cpython from GitHub
Let's add Python's Timsort! Regular Claude chat can clone repos from GitHub these days. In the transcript you can see it clone the repo and then consult Objects/listsort.txt and Objects/listobject.c. (I should note that when I asked GPT-5.4 Thinking to review Claude's implementation it picked holes in it and said the code "is a simplified, Timsort-inspired adaptive mergesort".)
I don't like the dark color scheme on the buttons, do better
Also add a "run all" button which shows smaller animated charts for every algorithm at once in a grid and runs them all at the same time
It came up with a color scheme I liked better, "do better" is a fun prompt, and now the "Run all" button produces this effect:
The NICAR data journalism conference provides a copy of the schedule as CORS-enabled JSON, so I vibe coded my own mobile-friendly schedule app to help me keep track of the sessions I want to attend.
Unicode Explorer using binary search over fetch() HTTP range requests. Here's a little prototype I built this morning from my phone as an experiment in HTTP range requests, and a general example of using LLMs to satisfy curiosity.
I've been collecting HTTP range tricks for a while now, and I decided it would be fun to build something with them myself that used binary search against a large file to do something useful.
So I brainstormed with Claude. The challenge was coming up with a use case for binary search where the data could be naturally sorted in a way that would benefit from binary search.
One of Claude's suggestions was looking up information about unicode codepoints, which means searching through many MBs of metadata.
I had Claude write me a spec to feed to Claude Code - visible here - then kicked off an asynchronous research project with Claude Code for web against my simonw/research repo to turn that into working code.
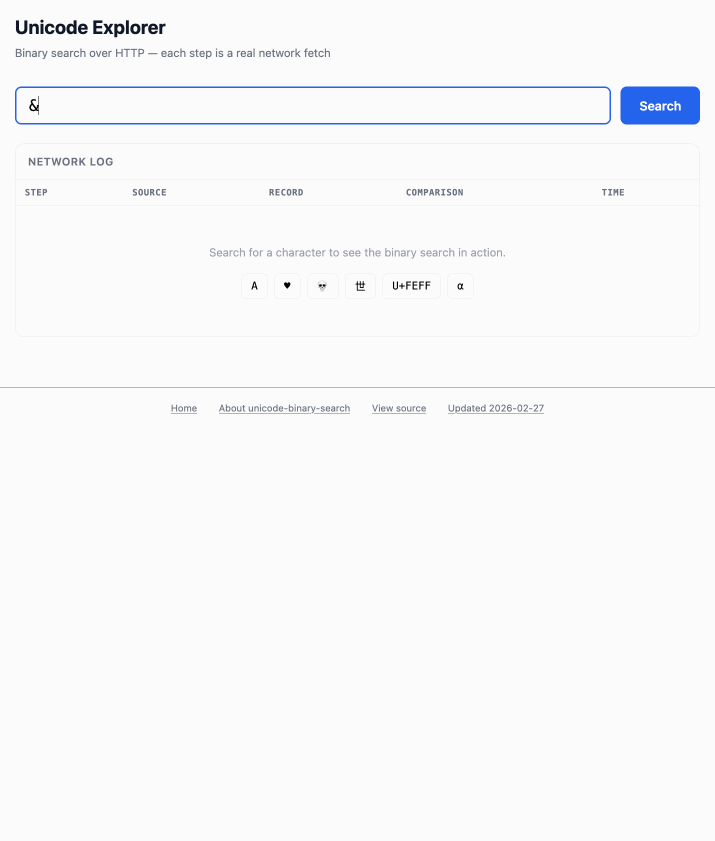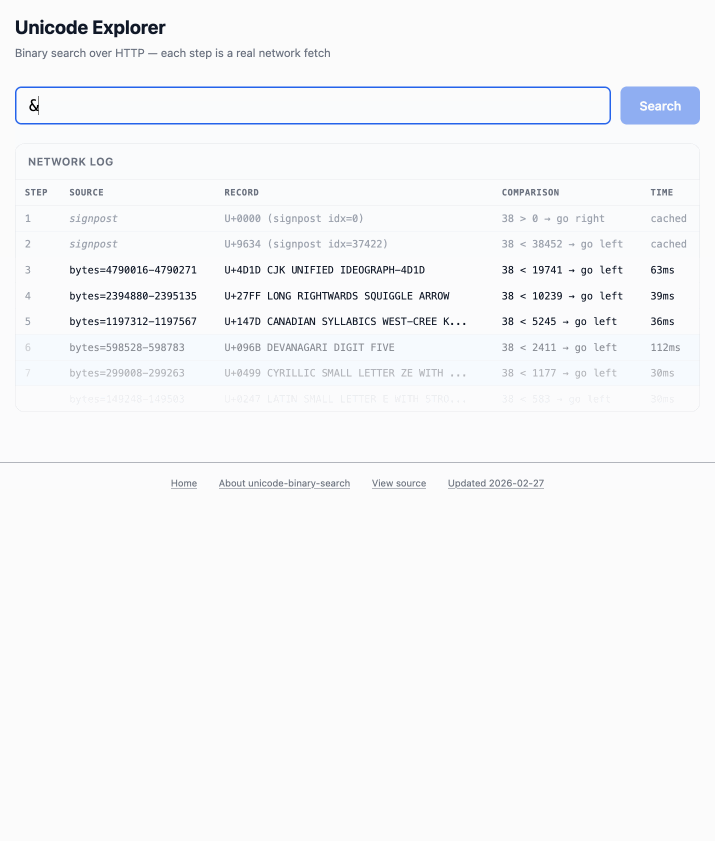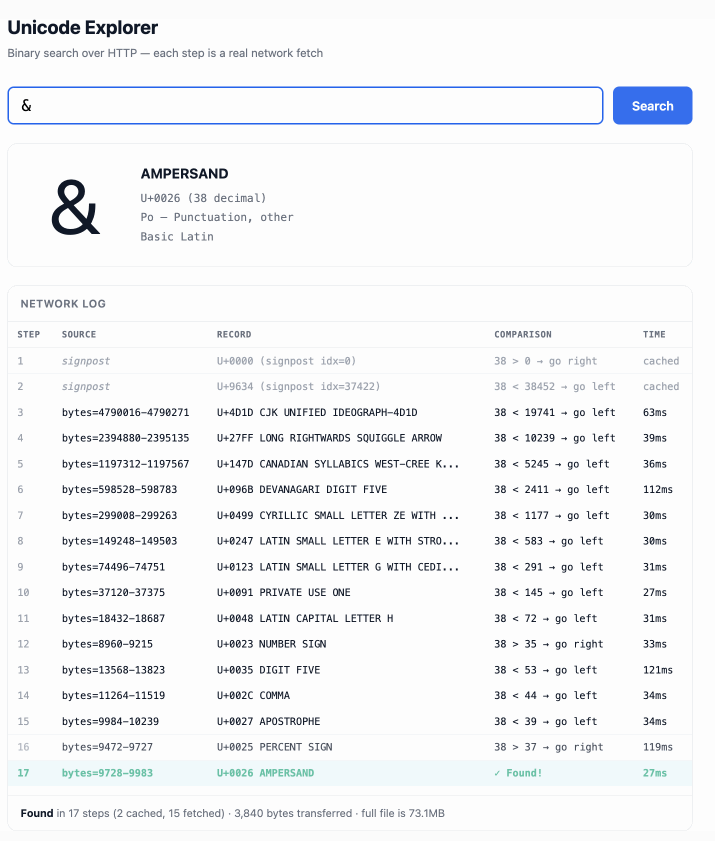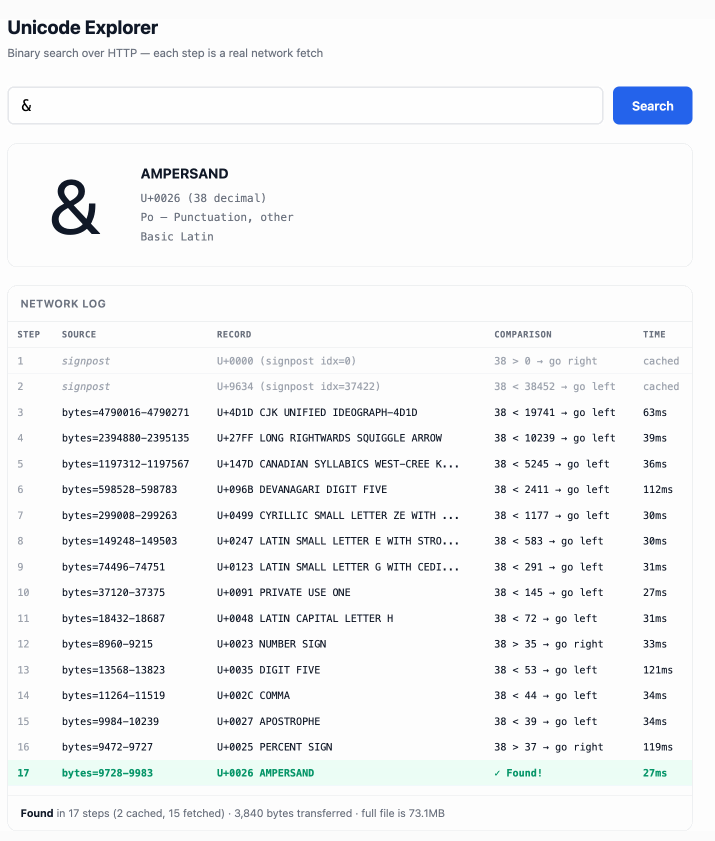
Here's the resulting report and code. One interesting thing I learned is that Range request tricks aren't compatible with HTTP compression because they mess with the byte offset calculations. I added 'Accept-Encoding': 'identity' to the fetch() calls but this isn't actually necessary because Cloudflare and other CDNs automatically skip compression if a content-range header is present.
I deployed the result to my tools.simonwillison.net site, after first tweaking it to query the data via range requests against a CORS-enabled 76.6MB file in an S3 bucket fronted by Cloudflare.
The demo is fun to play with - type in a single character like ø or a hexadecimal codepoint indicator like 1F99C and it will binary search its way through the large file and show you the steps it takes along the way:
I vibe coded my dream macOS presentation app
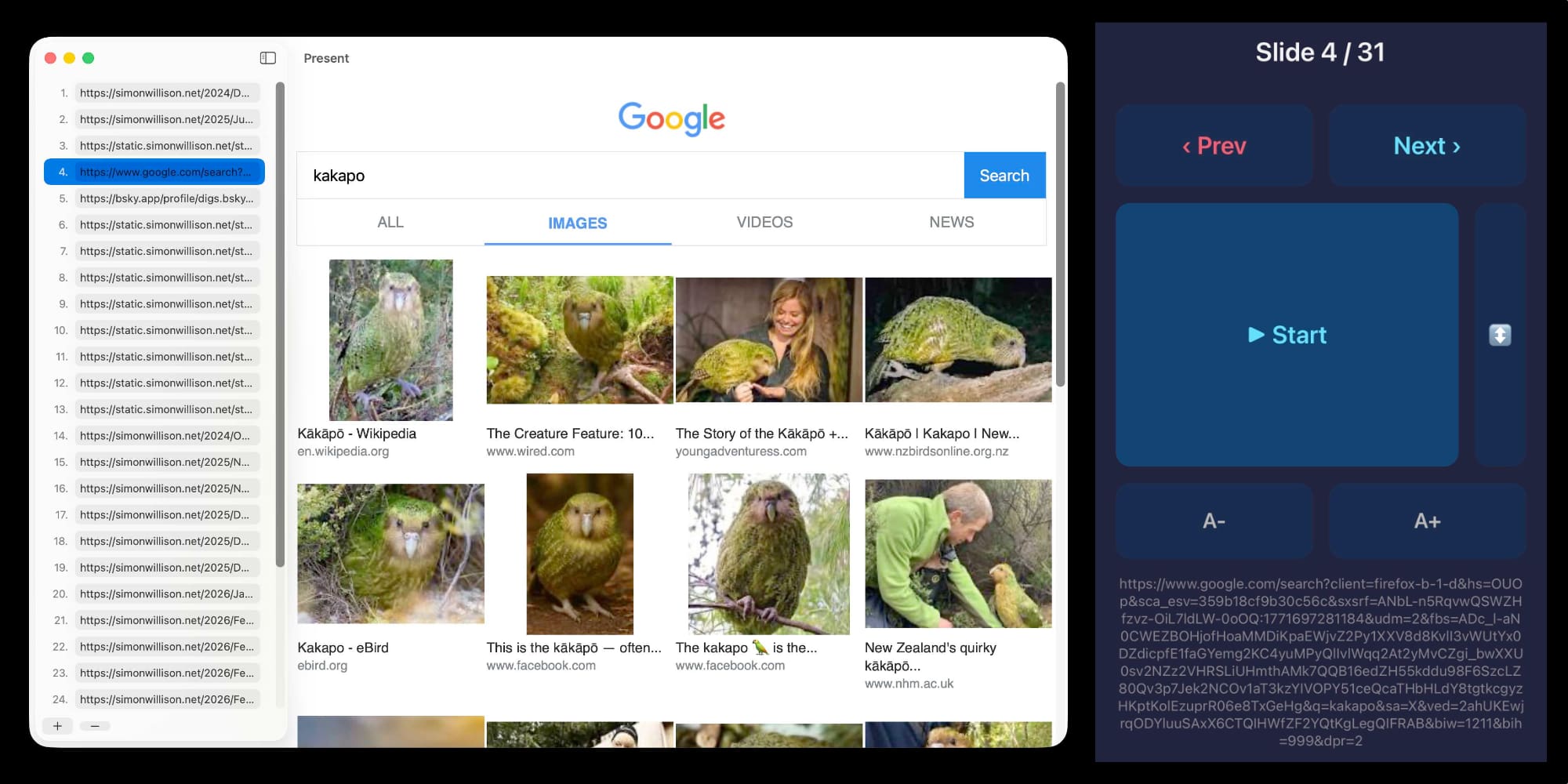
I gave a talk this weekend at Social Science FOO Camp in Mountain View. The event was a classic unconference format where anyone could present a talk without needing to propose it in advance. I grabbed a slot for a talk I titled “The State of LLMs, February 2026 edition”, subtitle “It’s all changed since November!”. I vibe coded a custom macOS app for the presentation the night before.
[... 1,613 words]Linear walkthroughs
Sometimes it's useful to have a coding agent give you a structured walkthrough of a codebase.
Maybe it's existing code you need to get up to speed on, maybe it's your own code that you've forgotten the details of, or maybe you vibe coded the whole thing and need to understand how it actually works.
Frontier models with the right agent harness can construct a detailed walkthrough to help you understand how code works. [... 524 words]
Writing about Agentic Engineering Patterns

I’ve started a new project to collect and document Agentic Engineering Patterns—coding practices and patterns to help get the best results out of this new era of coding agent development we find ourselves entering.
[... 554 words]The paper asked me to explain vibe coding, and I did so, because I think something big is coming there, and I'm deep in, and I worry that normal people are not able to see it and I want them to be prepared. But people can't just read something and hate you quietly; they can't see that you have provided them with a utility or a warning; they need their screech. You are distributed to millions of people, and become the local proxy for the emotions of maybe dozens of people, who disagree and demand your attention, and because you are the one in the paper you need to welcome them with a pastor's smile and deep empathy, and if you speak a word in your own defense they'll screech even louder.
— Paul Ford, on writing about vibe coding for the New York Times
How Generative and Agentic AI Shift Concern from Technical Debt to Cognitive Debt (via) This piece by Margaret-Anne Storey is the best explanation of the term cognitive debt I've seen so far.
Cognitive debt, a term gaining traction recently, instead communicates the notion that the debt compounded from going fast lives in the brains of the developers and affects their lived experiences and abilities to “go fast” or to make changes. Even if AI agents produce code that could be easy to understand, the humans involved may have simply lost the plot and may not understand what the program is supposed to do, how their intentions were implemented, or how to possibly change it.
Margaret-Anne expands on this further with an anecdote about a student team she coached:
But by weeks 7 or 8, one team hit a wall. They could no longer make even simple changes without breaking something unexpected. When I met with them, the team initially blamed technical debt: messy code, poor architecture, hurried implementations. But as we dug deeper, the real problem emerged: no one on the team could explain why certain design decisions had been made or how different parts of the system were supposed to work together. The code might have been messy, but the bigger issue was that the theory of the system, their shared understanding, had fragmented or disappeared entirely. They had accumulated cognitive debt faster than technical debt, and it paralyzed them.
I've experienced this myself on some of my more ambitious vibe-code-adjacent projects. I've been experimenting with prompting entire new features into existence without reviewing their implementations and, while it works surprisingly well, I've found myself getting lost in my own projects.
I no longer have a firm mental model of what they can do and how they work, which means each additional feature becomes harder to reason about, eventually leading me to lose the ability to make confident decisions about where to go next.
GLM-5: From Vibe Coding to Agentic Engineering (via) This is a huge new MIT-licensed model: 744B parameters and 1.51TB on Hugging Face twice the size of GLM-4.7 which was 368B and 717GB (4.5 and 4.6 were around that size too).
It's interesting to see Z.ai take a position on what we should call professional software engineers building with LLMs - I've seen Agentic Engineering show up in a few other places recently. most notable from Andrej Karpathy and Addy Osmani.
I ran my "Generate an SVG of a pelican riding a bicycle" prompt through GLM-5 via OpenRouter and got back a very good pelican on a disappointing bicycle frame:

I wanted a Python library that could parse SQLite SELECT statements, so I vibe coded this one up based on a specification I reverse-engineered from SQLite's own parser behavior.
There's an interactive playground here for trying it out in the browser (via Pyodide).
Don’t “Trust the Process” (via) Jenny Wen, Design Lead at Anthropic (and previously Director of Design at Figma) gave a provocative keynote at Hatch Conference in Berlin last September.

Jenny argues that the Design Process - user research leading to personas leading to user journeys leading to wireframes... all before anything gets built - may be outdated for today's world.
Hypothesis: In a world where anyone can make anything — what matters is your ability to choose and curate what you make.
In place of the Process, designers should lean into prototypes. AI makes these much more accessible and less time-consuming than they used to be.
Watching this talk made me think about how AI-assisted programming significantly reduces the cost of building the wrong thing. Previously if the design wasn't right you could waste months of development time building in the wrong direction, which was a very expensive mistake. If a wrong direction wastes just a few days instead we can take more risks and be much more proactive in exploring the problem space.
I've always been a compulsive prototyper though, so this is very much playing into my own existing biases!
If you tell a friend they can now instantly create any app, they’ll probably say “Cool! Now I need to think of an idea.” Then they will forget about it, and never build a thing. The problem is not that your friend is horribly uncreative. It’s that most people’s problems are not software-shaped, and most won’t notice even when they are. [...]
Programmers are trained to see everything as a software-shaped problem: if you do a task three times, you should probably automate it with a script. Rename every IMG_*.jpg file from the last week to hawaii2025_*.jpg, they tell their terminal, while the rest of us painfully click and copy-paste. We are blind to the solutions we were never taught to see, asking for faster horses and never dreaming of cars.
Also note that the python visualizer tool has been basically written by vibe-coding. I know more about analog filters -- and that's not saying much -- than I do about python. It started out as my typical "google and do the monkey-see-monkey-do" kind of programming, but then I cut out the middle-man -- me -- and just used Google Antigravity to do the audio sample visualizer.
— Linus Torvalds, Another silly guitar-pedal-related repo
2025
2025: The year in LLMs
This is the third in my annual series reviewing everything that happened in the LLM space over the past 12 months. For previous years see Stuff we figured out about AI in 2023 and Things we learned about LLMs in 2024.
[... 8,273 words]Cooking with Claude
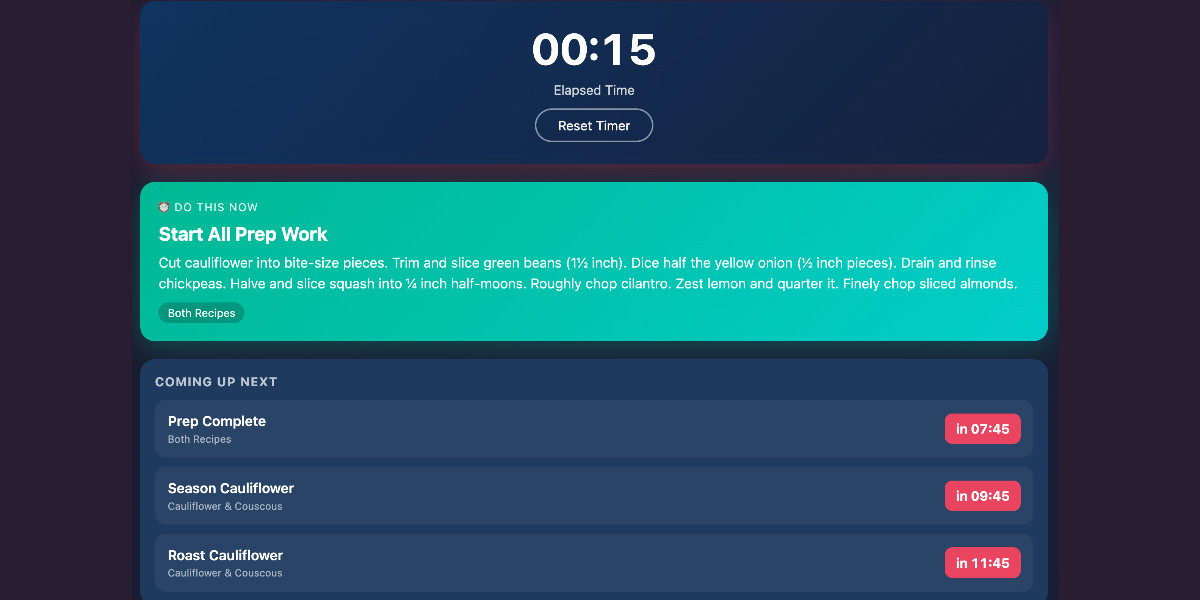
I’ve been having an absurd amount of fun recently using LLMs for cooking. I started out using them for basic recipes, but as I’ve grown more confident in their culinary abilities I’ve leaned into them for more advanced tasks. Today I tried something new: having Claude vibe-code up a custom application to help with the timing for a complicated meal preparation. It worked really well!
[... 1,313 words]