55 posts tagged “qwen”
Qwen is the Large Language Model family built by Alibaba Cloud.
2026
Qwen3.6-27B: Flagship-Level Coding in a 27B Dense Model (via) Big claims from Qwen about their latest open weight model:
Qwen3.6-27B delivers flagship-level agentic coding performance, surpassing the previous-generation open-source flagship Qwen3.5-397B-A17B (397B total / 17B active MoE) across all major coding benchmarks.
On Hugging Face Qwen3.5-397B-A17B is 807GB, this new Qwen3.6-27B is 55.6GB.
I tried it out with the 16.8GB Unsloth Qwen3.6-27B-GGUF:Q4_K_M quantized version and llama-server using this recipe by benob on Hacker News, after first installing llama-server using brew install llama.cpp:
llama-server \
-hf unsloth/Qwen3.6-27B-GGUF:Q4_K_M \
--no-mmproj \
--fit on \
-np 1 \
-c 65536 \
--cache-ram 4096 -ctxcp 2 \
--jinja \
--temp 0.6 \
--top-p 0.95 \
--top-k 20 \
--min-p 0.0 \
--presence-penalty 0.0 \
--repeat-penalty 1.0 \
--reasoning on \
--chat-template-kwargs '{"preserve_thinking": true}'
On first run that saved the ~17GB model to ~/.cache/huggingface/hub/models--unsloth--Qwen3.6-27B-GGUF.
Here's the transcript for "Generate an SVG of a pelican riding a bicycle". This is an outstanding result for a 16.8GB local model:

Performance numbers reported by llama-server:
- Reading: 20 tokens, 0.4s, 54.32 tokens/s
- Generation: 4,444 tokens, 2min 53s, 25.57 tokens/s
For good measure, here's Generate an SVG of a NORTH VIRGINIA OPOSSUM ON AN E-SCOOTER (run previously with GLM-5.1):

That one took 6,575 tokens, 4min 25s, 24.74 t/s.
Qwen3.6-35B-A3B on my laptop drew me a better pelican than Claude Opus 4.7
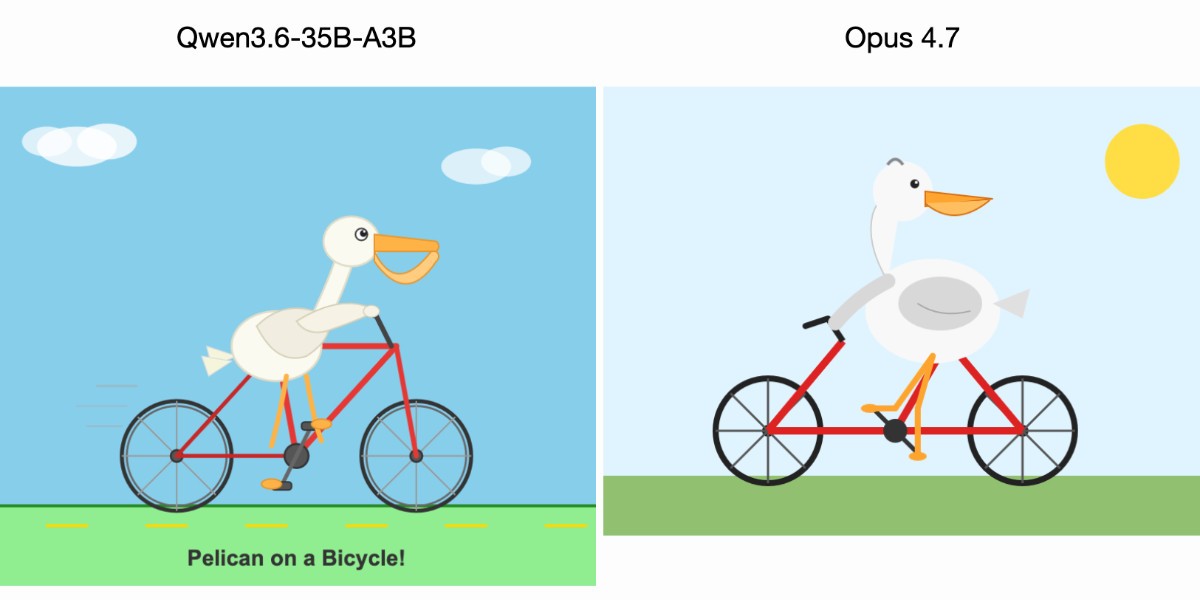
For anyone who has been (inadvisably) taking my pelican riding a bicycle benchmark seriously as a robust way to test models, here are pelicans from this morning’s two big model releases—Qwen3.6-35B-A3B from Alibaba and Claude Opus 4.7 from Anthropic.
[... 602 words]Quantization from the ground up. Sam Rose continues his streak of publishing spectacularly informative interactive essays, this time explaining how quantization of Large Language Models works (which he says might be "the best post I've ever made".)
Also included is the best visual explanation I've ever seen of how floating point numbers are represented using binary digits.
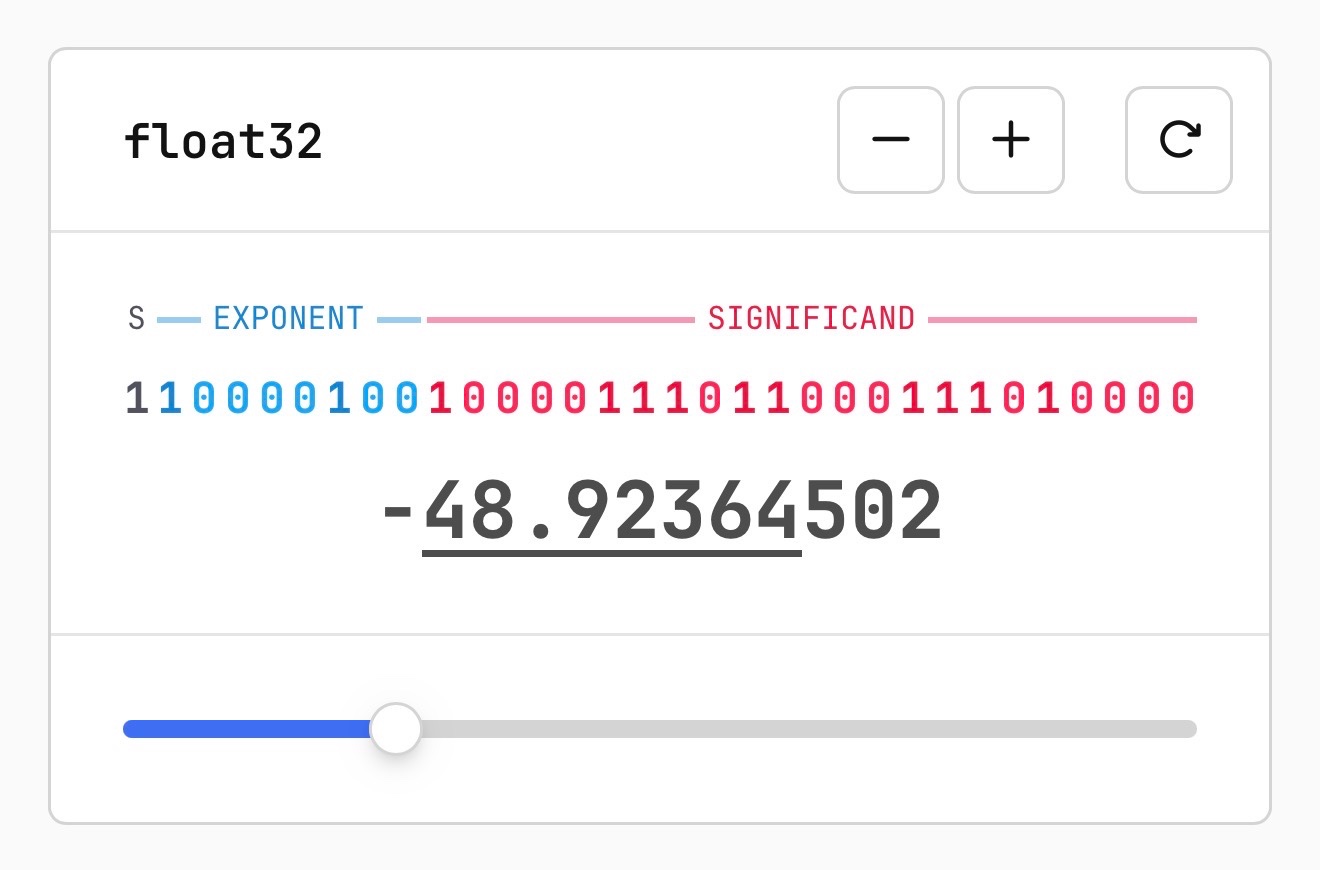
I hadn't heard about outlier values in quantization - rare float values that exist outside of the normal tiny-value distribution - but apparently they're very important:
Why do these outliers exist? [...] tl;dr: no one conclusively knows, but a small fraction of these outliers are very important to model quality. Removing even a single "super weight," as Apple calls them, can cause the model to output complete gibberish.
Given their importance, real-world quantization schemes sometimes do extra work to preserve these outliers. They might do this by not quantizing them at all, or by saving their location and value into a separate table, then removing them so that their block isn't destroyed.
Plus there's a section on How much does quantization affect model accuracy?. Sam explains the concepts of perplexity and ** KL divergence ** and then uses the llama.cpp perplexity tool and a run of the GPQA benchmark to show how different quantization levels affect Qwen 3.5 9B.
His conclusion:
It looks like 16-bit to 8-bit carries almost no quality penalty. 16-bit to 4-bit is more noticeable, but it's certainly not a quarter as good as the original. Closer to 90%, depending on how you want to measure it.
I wrote about Dan Woods' experiments with streaming experts the other day, the trick where you run larger Mixture-of-Experts models on hardware that doesn't have enough RAM to fit the entire model by instead streaming the necessary expert weights from SSD for each token that you process.
Five days ago Dan was running Qwen3.5-397B-A17B in 48GB of RAM. Today @seikixtc reported running the colossal Kimi K2.5 - a 1 trillion parameter model with 32B active weights at any one time, in 96GB of RAM on an M2 Max MacBook Pro.
And @anemll showed that same Qwen3.5-397B-A17B model running on an iPhone, albeit at just 0.6 tokens/second - iOS repo here.
I think this technique has legs. Dan and his fellow tinkerers are continuing to run autoresearch loops in order to find yet more optimizations to squeeze more performance out of these models.
Update: Now Daniel Isaac got Kimi K2.5 working on a 128GB M4 Max at ~1.7 tokens/second.
Autoresearching Apple’s “LLM in a Flash” to run Qwen 397B locally. Here's a fascinating piece of research by Dan Woods, who managed to get a custom version of Qwen3.5-397B-A17B running at 5.5+ tokens/second on a 48GB MacBook Pro M3 Max despite that model taking up 209GB (120GB quantized) on disk.
Qwen3.5-397B-A17B is a Mixture-of-Experts (MoE) model, which means that each token only needs to run against a subset of the overall model weights. These expert weights can be streamed into memory from SSD, saving them from all needing to be held in RAM at the same time.
Dan used techniques described in Apple's 2023 paper LLM in a flash: Efficient Large Language Model Inference with Limited Memory:
This paper tackles the challenge of efficiently running LLMs that exceed the available DRAM capacity by storing the model parameters in flash memory, but bringing them on demand to DRAM. Our method involves constructing an inference cost model that takes into account the characteristics of flash memory, guiding us to optimize in two critical areas: reducing the volume of data transferred from flash and reading data in larger, more contiguous chunks.
He fed the paper to Claude Code and used a variant of Andrej Karpathy's autoresearch pattern to have Claude run 90 experiments and produce MLX Objective-C and Metal code that ran the model as efficiently as possible.
danveloper/flash-moe has the resulting code plus a PDF paper mostly written by Claude Opus 4.6 describing the experiment in full.
The final model has the experts quantized to 2-bit, but the non-expert parts of the model such as the embedding table and routing matrices are kept at their original precision, adding up to 5.5GB which stays resident in memory while the model is running.
Qwen 3.5 usually runs 10 experts per token, but this setup dropped that to 4 while claiming that the biggest quality drop-off occurred at 3.
It's not clear to me how much the quality of the model results are affected. Claude claimed that "Output quality at 2-bit is indistinguishable from 4-bit for these evaluations", but the description of the evaluations it ran is quite thin.
Update: Dan's latest version upgrades to 4-bit quantization of the experts (209GB on disk, 4.36 tokens/second) after finding that the 2-bit version broke tool calling while 4-bit handles that well.
Something is afoot in the land of Qwen
I’m behind on writing about Qwen 3.5, a truly remarkable family of open weight models released by Alibaba’s Qwen team over the past few weeks. I’m hoping that the 3.5 family doesn’t turn out to be Qwen’s swan song, seeing as that team has had some very high profile departures in the past 24 hours.
[... 705 words]Qwen3.5: Towards Native Multimodal Agents. Alibaba's Qwen just released the first two models in the Qwen 3.5 series - one open weights, one proprietary. Both are multi-modal for vision input.
The open weight one is a Mixture of Experts model called Qwen3.5-397B-A17B. Interesting to see Qwen call out serving efficiency as a benefit of that architecture:
Built on an innovative hybrid architecture that fuses linear attention (via Gated Delta Networks) with a sparse mixture-of-experts, the model attains remarkable inference efficiency: although it comprises 397 billion total parameters, just 17 billion are activated per forward pass, optimizing both speed and cost without sacrificing capability.
It's 807GB on Hugging Face, and Unsloth have a collection of smaller GGUFs ranging in size from 94.2GB 1-bit to 462GB Q8_K_XL.
I got this pelican from the OpenRouter hosted model (transcript):

The proprietary hosted model is called Qwen3.5 Plus 2026-02-15, and is a little confusing. Qwen researcher Junyang Lin says:
Qwen3-Plus is a hosted API version of 397B. As the model natively supports 256K tokens, Qwen3.5-Plus supports 1M token context length. Additionally it supports search and code interpreter, which you can use on Qwen Chat with Auto mode.
Here's its pelican, which is similar in quality to the open weights model:

Qwen3-TTS Family is Now Open Sourced: Voice Design, Clone, and Generation (via) I haven't been paying much attention to the state-of-the-art in speech generation models other than noting that they've got really good, so I can't speak for how notable this new release from Qwen is.
From the accompanying paper:
In this report, we present the Qwen3-TTS series, a family of advanced multilingual, controllable, robust, and streaming text-to-speech models. Qwen3-TTS supports state-of- the-art 3-second voice cloning and description-based control, allowing both the creation of entirely novel voices and fine-grained manipulation over the output speech. Trained on over 5 million hours of speech data spanning 10 languages, Qwen3-TTS adopts a dual-track LM architecture for real-time synthesis [...]. Extensive experiments indicate state-of-the-art performance across diverse objective and subjective benchmark (e.g., TTS multilingual test set, InstructTTSEval, and our long speech test set). To facilitate community research and development, we release both tokenizers and models under the Apache 2.0 license.
To give an idea of size, Qwen/Qwen3-TTS-12Hz-1.7B-Base is 4.54GB on Hugging Face and Qwen/Qwen3-TTS-12Hz-0.6B-Base is 2.52GB.
The Hugging Face demo lets you try out the 0.6B and 1.7B models for free in your browser, including voice cloning:
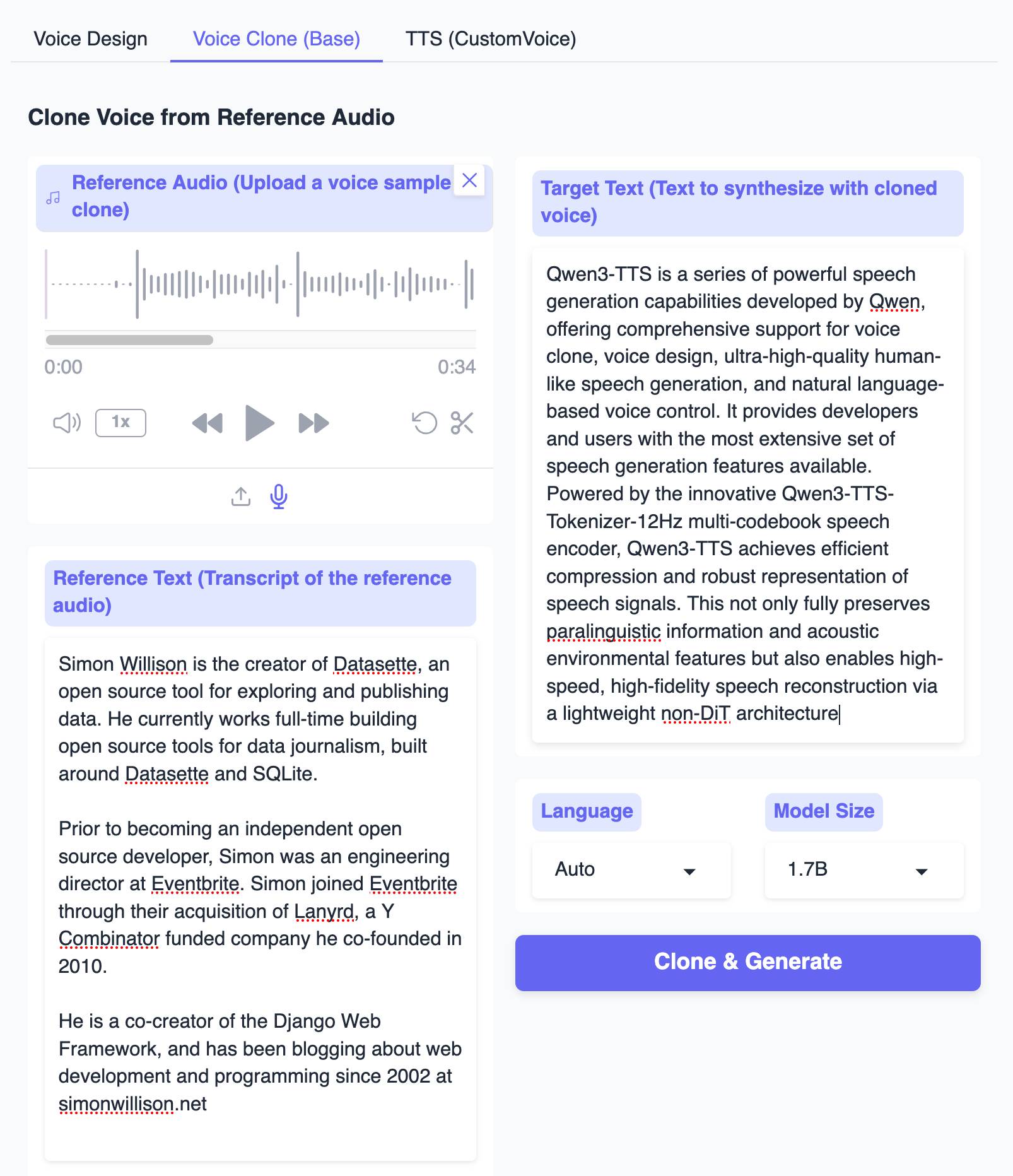
I tried this out by recording myself reading my about page and then having Qwen3-TTS generate audio of me reading the Qwen3-TTS announcement post. Here's the result:
It's important that everyone understands that voice cloning is now something that's available to anyone with a GPU and a few GBs of VRAM... or in this case a web browser that can access Hugging Face.
Update: Prince Canuma got this working with his mlx-audio library. I had Claude turn that into a CLI tool which you can run with uv ike this:
uv run https://tools.simonwillison.net/python/q3_tts.py \
'I am a pirate, give me your gold!' \
-i 'gruff voice' -o pirate.wav
The -i option lets you use a prompt to describe the voice it should use. On first run this downloads a 4.5GB model file from Hugging Face.
2025
To evaluate the model’s capability in processing long-context inputs, we construct a video “Needle-in- a-Haystack” evaluation on Qwen3-VL-235B-A22B-Instruct. In this task, a semantically salient “needle” frame—containing critical visual evidence—is inserted at varying temporal positions within a long video. The model is then tasked with accurately locating the target frame from the long video and answering the corresponding question. [...]
As shown in Figure 3, the model achieves a perfect 100% accuracy on videos up to 30 minutes in duration—corresponding to a context length of 256K tokens. Remarkably, even when extrapolating to sequences of up to 1M tokens (approximately 2 hours of video) via YaRN-based positional extension, the model retains a high accuracy of 99.5%.
— Qwen3-VL Technical Report, 5.12.3: Needle-in-a-Haystack
Qwen3-VL: Sharper Vision, Deeper Thought, Broader Action (via) I've been looking forward to this. Qwen 2.5 VL is one of the best available open weight vision LLMs, so I had high hopes for Qwen 3's vision models.
Firstly, we are open-sourcing the flagship model of this series: Qwen3-VL-235B-A22B, available in both Instruct and Thinking versions. The Instruct version matches or even exceeds Gemini 2.5 Pro in major visual perception benchmarks. The Thinking version achieves state-of-the-art results across many multimodal reasoning benchmarks.
Bold claims against Gemini 2.5 Pro, which are supported by a flurry of self-reported benchmarks.
This initial model is enormous. On Hugging Face both Qwen3-VL-235B-A22B-Instruct and Qwen3-VL-235B-A22B-Thinking are 235B parameters and weigh 471 GB. Not something I'm going to be able to run on my 64GB Mac!
The Qwen 2.5 VL family included models at 72B, 32B, 7B and 3B sizes. Given the rate Qwen are shipping models at the moment I wouldn't be surprised to see smaller Qwen 3 VL models show up in just the next few days.
Also from Qwen today, three new API-only closed-weight models: upgraded Qwen 3 Coder, Qwen3-LiveTranslate-Flash (real-time multimodal interpretation), and Qwen3-Max, their new trillion parameter flagship model, which they describe as their "largest and most capable model to date".
Plus Qwen3Guard, a "safety moderation model series" that looks similar in purpose to Meta's Llama Guard. This one is open weights (Apache 2.0) and comes in 8B, 4B and 0.6B sizes on Hugging Face. There's more information in the QwenLM/Qwen3Guard GitHub repo.
It's been an extremely busy day for team Qwen. Within the last 24 hours (all links to Twitter, which seems to be their preferred platform for these announcements):
- Qwen3-Next-80B-A3B-Instruct-FP8 and Qwen3-Next-80B-A3B-Thinking-FP8 - official FP8 quantized versions of their Qwen3-Next models. On Hugging Face Qwen3-Next-80B-A3B-Instruct is 163GB and Qwen3-Next-80B-A3B-Instruct-FP8 is 82.1GB. I wrote about Qwen3-Next on Friday 12th September.
- Qwen3-TTS-Flash provides "multi-timbre, multi-lingual, and multi-dialect speech synthesis" according to their blog announcement. It's not available as open weights, you have to access it via their API instead. Here's a free live demo.
- Qwen3-Omni is today's most exciting announcement: a brand new 30B parameter "omni" model supporting text, audio and video input and text and audio output! You can try it on chat.qwen.ai by selecting the "Use voice and video chat" icon - you'll need to be signed in using Google or GitHub. This one is open weights, as Apache 2.0 Qwen3-Omni-30B-A3B-Instruct, Qwen/Qwen3-Omni-30B-A3B-Thinking, and Qwen3-Omni-30B-A3B-Captioner on HuggingFace. That Instruct model is 70.5GB so this should be relatively accessible for running on expensive home devices.
- Qwen-Image-Edit-2509 is an updated version of their excellent Qwen-Image-Edit model which I first tried last month. Their blog post calls it "the monthly iteration of Qwen-Image-Edit" so I guess they're planning more frequent updates. The new model adds multi-image inputs. I used it via chat.qwen.ai to turn a photo of our dog into a dragon in the style of one of Natalie's ceramic pots.

Here's the prompt I used, feeding in two separate images. Weirdly it used the edges of the landscape photo to fill in the gaps on the otherwise portrait output. It turned the chair seat into a bowl too!

Qwen3-Next-80B-A3B. Qwen announced two new models via their Twitter account (and here's their blog): Qwen3-Next-80B-A3B-Instruct and Qwen3-Next-80B-A3B-Thinking.
They make some big claims on performance:
- Qwen3-Next-80B-A3B-Instruct approaches our 235B flagship.
- Qwen3-Next-80B-A3B-Thinking outperforms Gemini-2.5-Flash-Thinking.
The name "80B-A3B" indicates 80 billion parameters of which only 3 billion are active at a time. You still need to have enough GPU-accessible RAM to hold all 80 billion in memory at once but only 3 billion will be used for each round of inference, which provides a significant speedup in responding to prompts.
More details from their tweet:
- 80B params, but only 3B activated per token → 10x cheaper training, 10x faster inference than Qwen3-32B.(esp. @ 32K+ context!)
- Hybrid Architecture: Gated DeltaNet + Gated Attention → best of speed & recall
- Ultra-sparse MoE: 512 experts, 10 routed + 1 shared
- Multi-Token Prediction → turbo-charged speculative decoding
- Beats Qwen3-32B in perf, rivals Qwen3-235B in reasoning & long-context
The models on Hugging Face are around 150GB each so I decided to try them out via OpenRouter rather than on my own laptop (Thinking, Instruct).
I'm used my llm-openrouter plugin. I installed it like this:
llm install llm-openrouter
llm keys set openrouter
# paste key here
Then found the model IDs with this command:
llm models -q next
Which output:
OpenRouter: openrouter/qwen/qwen3-next-80b-a3b-thinking
OpenRouter: openrouter/qwen/qwen3-next-80b-a3b-instruct
I have an LLM prompt template saved called pelican-svg which I created like this:
llm "Generate an SVG of a pelican riding a bicycle" --save pelican-svg
This means I can run my pelican benchmark like this:
llm -t pelican-svg -m openrouter/qwen/qwen3-next-80b-a3b-thinking
Or like this:
llm -t pelican-svg -m openrouter/qwen/qwen3-next-80b-a3b-instruct
Here's the thinking model output (exported with llm logs -c | pbcopy after I ran the prompt):
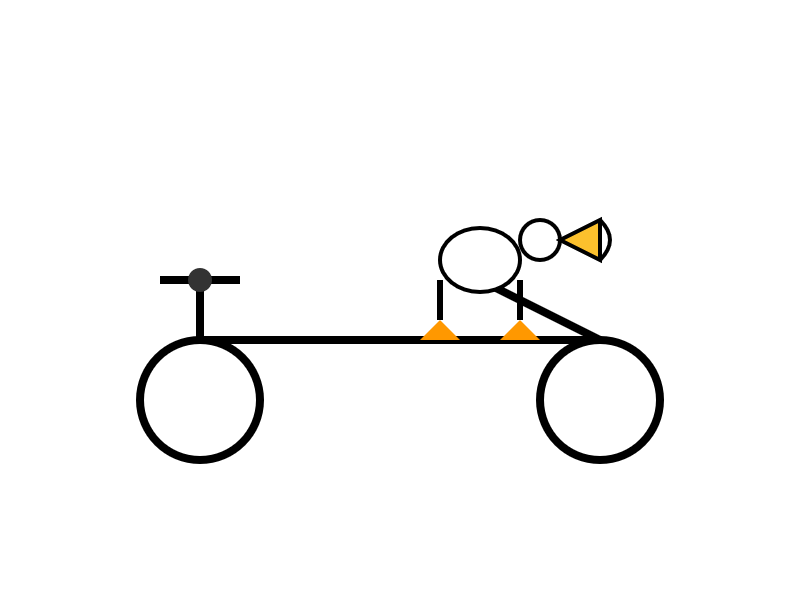
I enjoyed the "Whimsical style with smooth curves and friendly proportions (no anatomical accuracy needed for bicycle riding!)" note in the transcript.
The instruct (non-reasoning) model gave me this:

"🐧🦩 Who needs legs!?" indeed! I like that penguin-flamingo emoji sequence it's decided on for pelicans.
Defeating Nondeterminism in LLM Inference (via) A very common question I see about LLMs concerns why they can't be made to deliver the same response to the same prompt by setting a fixed random number seed.
Like many others I had been lead to believe this was due to the non-associative nature of floating point arithmetic, where (a + b) + c ≠ a + (b + c), combining with unpredictable calculation orders on concurrent GPUs. This new paper calls that the "concurrency + floating point hypothesis":
One common hypothesis is that some combination of floating-point non-associativity and concurrent execution leads to nondeterminism based on which concurrent core finishes first. We will call this the “concurrency + floating point” hypothesis for LLM inference nondeterminism.
It then convincingly argues that this is not the core of the problem, because "in the typical forward pass of an LLM, there is usually not a single atomic add present."
Why are LLMs so often non-deterministic then?
[...] the primary reason nearly all LLM inference endpoints are nondeterministic is that the load (and thus batch-size) nondeterministically varies! This nondeterminism is not unique to GPUs — LLM inference endpoints served from CPUs or TPUs will also have this source of nondeterminism.
The thinking-machines-lab/batch_invariant_ops code that accompanies this paper addresses this by providing a PyTorch implementation of invariant kernels and demonstrates them running Qwen3-8B deterministically under vLLM.
This paper is the first public output from Thinking Machines, the AI Lab founded in February 2025 by Mira Murati, OpenAI's former CTO (and interim CEO for a few days). It's unrelated to Thinking Machines Corporation, the last employer of Richard Feynman (as described in this most excellent story by Danny Hillis).
Qwen-Image-Edit: Image Editing with Higher Quality and Efficiency.
As promised in their August 4th release of the Qwen image generation model, Qwen have now followed it up with a separate model, Qwen-Image-Edit, which can take an image and a prompt and return an edited version of that image.
Ivan Fioravanti upgraded his macOS qwen-image-mps tool (previously) to run the new model via a new edit command. Since it's now on PyPI you can run it directly using uvx like this:
uvx qwen-image-mps edit -i pelicans.jpg \
-p 'Give the pelicans rainbow colored plumage' -s 10
Be warned... it downloads a 54GB model file (to ~/.cache/huggingface/hub/models--Qwen--Qwen-Image-Edit) and appears to use all 64GB of my system memory - if you have less than 64GB it likely won't work, and I had to quit almost everything else on my system to give it space to run. A larger machine is almost required to use this.
I fed it this image:

The following prompt:
Give the pelicans rainbow colored plumage
And told it to use just 10 inference steps - the default is 50, but I didn't want to wait that long.
It still took nearly 25 minutes (on a 64GB M2 MacBook Pro) to produce this result:

To get a feel for how much dropping the inference steps affected things I tried the same prompt with the new "Image Edit" mode of Qwen's chat.qwen.ai, which I believe uses the same model. It gave me a result much faster that looked like this:

Update: I left the command running overnight without the -s 10 option - so it would use all 50 steps - and my laptop took 2 hours and 59 minutes to generate this image, which is much more photo-realistic and similar to the one produced by Qwen's hosted model:

Marko Simic reported that:
50 steps took 49min on my MBP M4 Max 128GB
qwen-image-mps (via) Ivan Fioravanti built this Python CLI script for running the Qwen/Qwen-Image image generation model on an Apple silicon Mac, optionally using the Qwen-Image-Lightning LoRA to dramatically speed up generation.
Ivan has tested it this on 512GB and 128GB machines and it ran really fast - 42 seconds on his M3 Ultra. I've run it on my 64GB M2 MacBook Pro - after quitting almost everything else - and it just about manages to output images after pegging my GPU (fans whirring, keyboard heating up) and occupying 60GB of my available RAM. With the LoRA option running the script to generate an image took 9m7s on my machine.
Ivan merged my PR adding inline script dependencies for uv which means you can now run it like this:
uv run https://raw.githubusercontent.com/ivanfioravanti/qwen-image-mps/refs/heads/main/qwen-image-mps.py \
-p 'A vintage coffee shop full of raccoons, in a neon cyberpunk city' -f
The first time I ran this it downloaded the 57.7GB model from Hugging Face and stored it in my ~/.cache/huggingface/hub/models--Qwen--Qwen-Image directory. The -f option fetched an extra 1.7GB Qwen-Image-Lightning-8steps-V1.0.safetensors file to my working directory that sped up the generation.
Here's the resulting image:

Qwen3-4B-Thinking: “This is art—pelicans don’t ride bikes!”

I’ve fallen a few days behind keeping up with Qwen. They released two new 4B models last week: Qwen3-4B-Instruct-2507 and its thinking equivalent Qwen3-4B-Thinking-2507.
[... 991 words]gpt-oss-120b is the most intelligent American open weights model, comes behind DeepSeek R1 and Qwen3 235B in intelligence but offers efficiency benefits [...]
We’re seeing the 120B beat o3-mini but come in behind o4-mini and o3. The 120B is the most intelligent model that can be run on a single H100 and the 20B is the most intelligent model that can be run on a consumer GPU. [...]
While the larger gpt-oss-120b does not come in above DeepSeek R1 0528’s score of 59 or Qwen3 235B 2507s score of 64, it is notable that it is significantly smaller in both total and active parameters than both of those models.
— Artificial Analysis, see also their updated leaderboard
Qwen-Image: Crafting with Native Text Rendering (via) Not content with releasing six excellent open weights LLMs in July, Qwen are kicking off August with their first ever image generation model.
Qwen-Image is a 20 billion parameter MMDiT (Multimodal Diffusion Transformer, originally proposed for Stable Diffusion 3) model under an Apache 2.0 license. The Hugging Face repo is 53.97GB.
Qwen released a detailed technical report (PDF) to accompany the model. The model builds on their Qwen-2.5-VL vision LLM, and they also made extensive use of that model to help create some of their their training data:
In our data annotation pipeline, we utilize a capable image captioner (e.g., Qwen2.5-VL) to generate not only comprehensive image descriptions, but also structured metadata that captures essential image properties and quality attributes.
Instead of treating captioning and metadata extraction as independent tasks, we designed an annotation framework in which the captioner concurrently describes visual content and generates detailed information in a structured format, such as JSON. Critical details such as object attributes, spatial relationships, environmental context, and verbatim transcriptions of visible text are captured in the caption, while key image properties like type, style, presence of watermarks, and abnormal elements (e.g., QR codes or facial mosaics) are reported in a structured format.
They put a lot of effort into the model's ability to render text in a useful way. 5% of the training data (described as "billions of image-text pairs") was data "synthesized through controlled text rendering techniques", ranging from simple text through text on an image background up to much more complex layout examples:
To improve the model’s capacity to follow complex, structured prompts involving layout-sensitive content, we propose a synthesis strategy based on programmatic editing of pre-defined templates, such as PowerPoint slides or User Interface Mockups. A comprehensive rule-based system is designed to automate the substitution of placeholder text while maintaining the integrity of layout structure, alignment, and formatting.
I tried the model out using the ModelScope demo - I signed in with GitHub and verified my account via a text message to a phone number. Here's what I got for "A raccoon holding a sign that says "I love trash" that was written by that raccoon":

The raccoon has very neat handwriting!
Update: A version of the model exists that can edit existing images but it's not yet been released:
Currently, we have only open-sourced the text-to-image foundation model, but the editing model is also on our roadmap and planned for future release.
Two interesting examples of inference speed as a flagship feature of LLM services today.
First, Cerebras announced two new monthly plans for their extremely high speed hosted model service: Cerebras Code Pro ($50/month, 1,000 messages a day) and Cerebras Code Max ($200/month, 5,000/day). The model they are selling here is Qwen's Qwen3-Coder-480B-A35B-Instruct, likely the best available open weights coding model right now and one that was released just ten days ago. Ten days from model release to third-party subscription service feels like some kind of record.
Cerebras claim they can serve the model at an astonishing 2,000 tokens per second - four times the speed of Claude Sonnet 4 in their demo video.
Also today, Moonshot announced a new hosted version of their trillion parameter Kimi K2 model called kimi-k2-turbo-preview:
🆕 Say hello to kimi-k2-turbo-preview Same model. Same context. NOW 4× FASTER.
⚡️ From 10 tok/s to 40 tok/s.
💰 Limited-Time Launch Price (50% off until Sept 1)
- $0.30 / million input tokens (cache hit)
- $1.20 / million input tokens (cache miss)
- $5.00 / million output tokens
👉 Explore more: platform.moonshot.ai
This is twice the price of their regular model for 4x the speed (increasing to 4x the price in September). No details yet on how they achieved the speed-up.
I am interested to see how much market demand there is for faster performance like this. I've experimented with Cerebras in the past and found that the speed really does make iterating on code with live previews feel a whole lot more interactive.
Trying out Qwen3 Coder Flash using LM Studio and Open WebUI and LLM
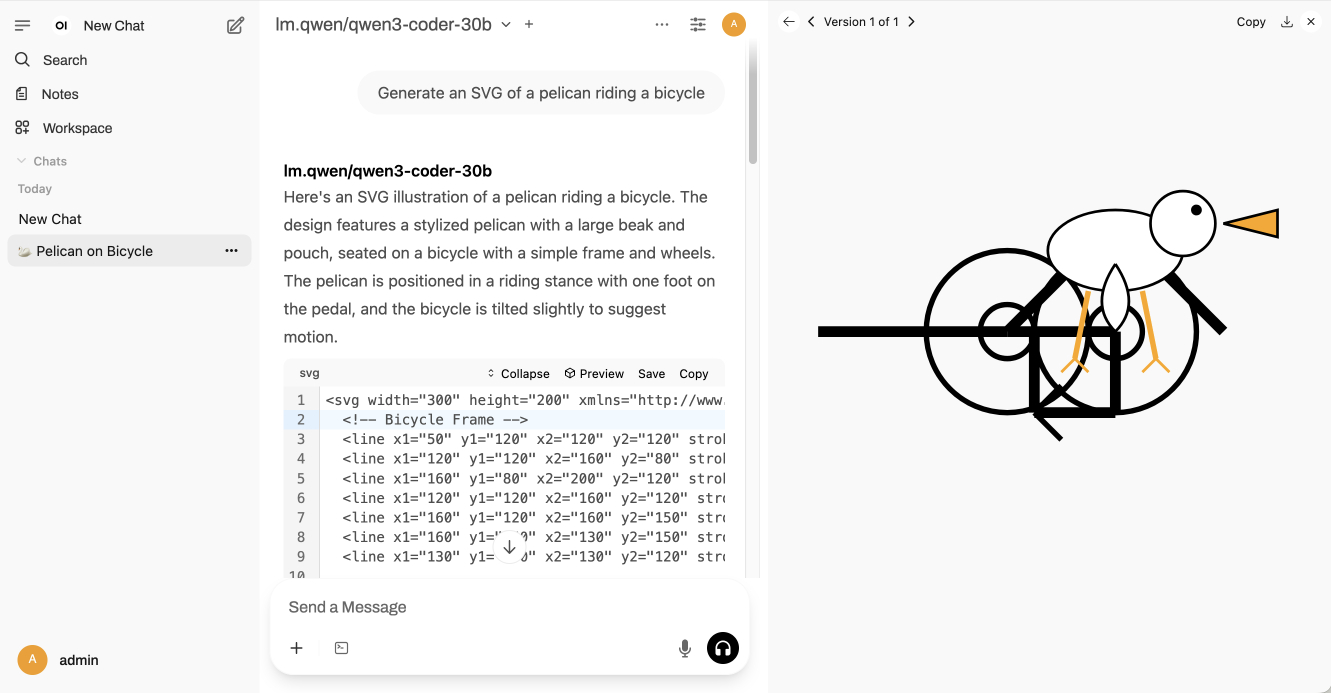
Qwen just released their sixth model(!) of this July called Qwen3-Coder-30B-A3B-Instruct—listed as Qwen3-Coder-Flash in their chat.qwen.ai interface.
[... 1,390 words]Something that has become undeniable this month is that the best available open weight models now come from the Chinese AI labs.
I continue to have a lot of love for Mistral, Gemma and Llama but my feeling is that Qwen, Moonshot and Z.ai have positively smoked them over the course of July.
Here's what came out this month, with links to my notes on each one:
- Moonshot Kimi-K2-Instruct - 11th July, 1 trillion parameters
- Qwen Qwen3-235B-A22B-Instruct-2507 - 21st July, 235 billion
- Qwen Qwen3-Coder-480B-A35B-Instruct - 22nd July, 480 billion
- Qwen Qwen3-235B-A22B-Thinking-2507 - 25th July, 235 billion
- Z.ai GLM-4.5 and GLM-4.5 Air - 28th July, 355 and 106 billion
- Qwen Qwen3-30B-A3B-Instruct-2507 - 29th July, 30 billion
- Qwen Qwen3-30B-A3B-Thinking-2507 - 30th July, 30 billion
- Qwen Qwen3-Coder-30B-A3B-Instruct - 31st July, 30 billion (released after I first posted this note)
Notably absent from this list is DeepSeek, but that's only because their last model release was DeepSeek-R1-0528 back in April.
The only janky license among them is Kimi K2, which uses a non-OSI-compliant modified MIT. Qwen's models are all Apache 2 and Z.ai's are MIT.
The larger Chinese models all offer their own APIs and are increasingly available from other providers. I've been able to run versions of the Qwen 30B and GLM-4.5 Air 106B models on my own laptop.
I can't help but wonder if part of the reason for the delay in release of OpenAI's open weights model comes from a desire to be notably better than this truly impressive lineup of Chinese models.
Update August 5th 2025: The OpenAI open weight models came out and they are very impressive.
Qwen3-30B-A3B-Thinking-2507 (via) Yesterday was Qwen3-30B-A3B-Instruct-2507. Qwen are clearly committed to their new split between reasoning and non-reasoning models (a reversal from Qwen 3 in April), because today they released the new reasoning partner to yesterday's model: Qwen3-30B-A3B-Thinking-2507.
I'm surprised at how poorly this reasoning mode performs at "Generate an SVG of a pelican riding a bicycle" compared to its non-reasoning partner. The reasoning trace appears to carefully consider each component and how it should be positioned... and then the final result looks like this:
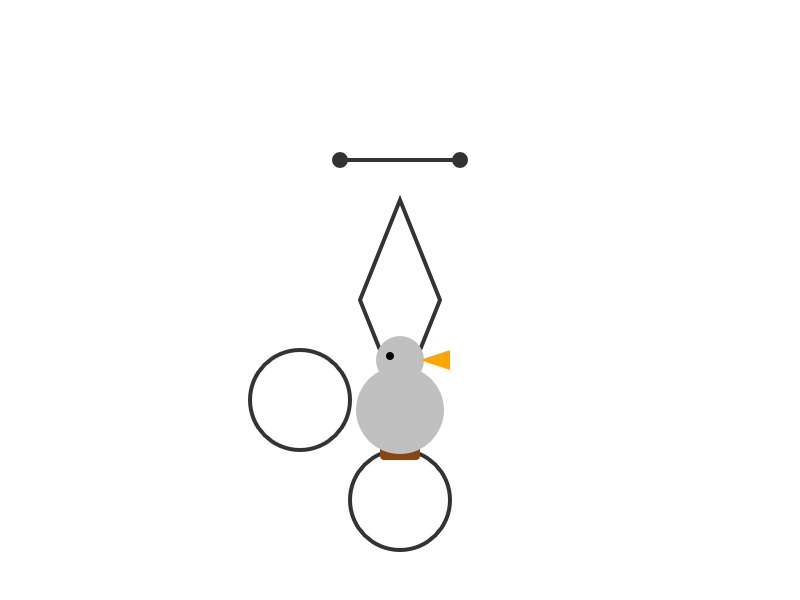
I ran this using chat.qwen.ai/?model=Qwen3-30B-A3B-2507 with the "reasoning" option selected.
I also tried the "Write an HTML and JavaScript page implementing space invaders" prompt I ran against the non-reasoning model. It did a better job in that the game works:
It's not as playable as the on I got from GLM-4.5 Air though - the invaders fire their bullets infrequently enough that the game isn't very challenging.
This model is part of a flurry of releases from Qwen over the past two 9 days. Here's my coverage of each of those:
- Qwen3-235B-A22B-Instruct-2507 - 21st July
- Qwen3-Coder-480B-A35B-Instruct - 22nd July
- Qwen3-235B-A22B-Thinking-2507 - 25th July
- Qwen3-30B-A3B-Instruct-2507 - 29th July
- Qwen3-30B-A3B-Thinking-2507 - today
Qwen3-30B-A3B-Instruct-2507. New model update from Qwen, improving on their previous Qwen3-30B-A3B release from late April. In their tweet they said:
Smarter, faster, and local deployment-friendly.
✨ Key Enhancements:
✅ Enhanced reasoning, coding, and math skills
✅ Broader multilingual knowledge
✅ Improved long-context understanding (up to 256K tokens)
✅ Better alignment with user intent and open-ended tasks
✅ No more<think>blocks — now operating exclusively in non-thinking mode🔧 With 3B activated parameters, it's approaching the performance of GPT-4o and Qwen3-235B-A22B Non-Thinking
I tried the chat.qwen.ai hosted model with "Generate an SVG of a pelican riding a bicycle" and got this:

I particularly enjoyed this detail from the SVG source code:
<!-- Bonus: Pelican's smile -->
<path d="M245,145 Q250,150 255,145" fill="none" stroke="#d4a037" stroke-width="2"/>
I went looking for quantized versions that could fit on my Mac and found lmstudio-community/Qwen3-30B-A3B-Instruct-2507-MLX-8bit from LM Studio. Getting that up and running was a 32.46GB download and it appears to use just over 30GB of RAM.
The pelican I got from that one wasn't as good:

I then tried that local model on the "Write an HTML and JavaScript page implementing space invaders" task that I ran against GLM-4.5 Air. The output looked promising, in particular it seemed to be putting more effort into the design of the invaders (GLM-4.5 Air just used rectangles):
// Draw enemy ship ctx.fillStyle = this.color; // Ship body ctx.fillRect(this.x, this.y, this.width, this.height); // Enemy eyes ctx.fillStyle = '#fff'; ctx.fillRect(this.x + 6, this.y + 5, 4, 4); ctx.fillRect(this.x + this.width - 10, this.y + 5, 4, 4); // Enemy antennae ctx.fillStyle = '#f00'; if (this.type === 1) { // Basic enemy ctx.fillRect(this.x + this.width / 2 - 1, this.y - 5, 2, 5); } else if (this.type === 2) { // Fast enemy ctx.fillRect(this.x + this.width / 4 - 1, this.y - 5, 2, 5); ctx.fillRect(this.x + (3 * this.width) / 4 - 1, this.y - 5, 2, 5); } else if (this.type === 3) { // Armored enemy ctx.fillRect(this.x + this.width / 2 - 1, this.y - 8, 2, 8); ctx.fillStyle = '#0f0'; ctx.fillRect(this.x + this.width / 2 - 1, this.y - 6, 2, 3); }
But the resulting code didn't actually work:

That same prompt against the unquantized Qwen-hosted model produced a different result which sadly also resulted in an unplayable game - this time because everything moved too fast.
This new Qwen model is a non-reasoning model, whereas GLM-4.5 and GLM-4.5 Air are both reasoners. It looks like at this scale the "reasoning" may make a material difference in terms of getting code that works out of the box.
Qwen3-235B-A22B-Thinking-2507 (via) The third Qwen model release week, following Qwen3-235B-A22B-Instruct-2507 on Monday 21st and Qwen3-Coder-480B-A35B-Instruct on Tuesday 22nd.
Those two were both non-reasoning models - a change from the previous models in the Qwen 3 family which combined reasoning and non-reasoning in the same model, controlled by /think and /no_think tokens.
Today's model, Qwen3-235B-A22B-Thinking-2507 (also released as an FP8 variant), is their new thinking variant.
Qwen claim "state-of-the-art results among open-source thinking models" and have increased the context length to 262,144 tokens - a big jump from April's Qwen3-235B-A22B which was "32,768 natively and 131,072 tokens with YaRN".
Their own published benchmarks show comparable scores to DeepSeek-R1-0528, OpenAI's o3 and o4-mini, Gemini 2.5 Pro and Claude Opus 4 in thinking mode.
The new model is already available via OpenRouter.
But how good is its pelican?
I tried it with "Generate an SVG of a pelican riding a bicycle" via OpenRouter, and it thought for 166 seconds - nearly three minutes! I have never seen a model think for that long. No wonder the documentation includes the following:
However, since the model may require longer token sequences for reasoning, we strongly recommend using a context length greater than 131,072 when possible.
Here's a copy of that thinking trace. It was really fun to scan through:
![Qwen3 235B A22B Thinking 2507 Seat at (200,200). The pelican's body will be: - The main body: a rounded shape starting at (200,200) and going to about (250, 250) [but note: the pelican is sitting, so the body might be more upright?] - Head: at (200, 180) [above the seat] and the beak extending forward to (280, 180) or so. We'll design the pelican as: - Head: a circle at (180, 170) with radius 15. - Beak: a long triangle from (180,170) to (250,170) and then down to (250,180) and back? Actually, the beak is a long flat-bottomed triangle.](https://static.simonwillison.net/static/2025/qwen-details.jpg)
The finished pelican? Not so great! I like the beak though:
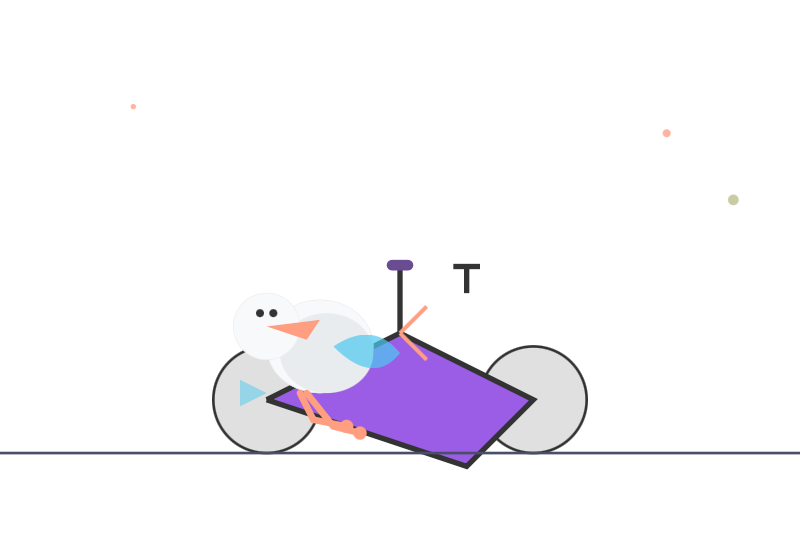
Qwen3-Coder: Agentic Coding in the World (via) It turns out that as I was typing up my notes on Qwen3-235B-A22B-Instruct-2507 the Qwen team were unleashing something much bigger:
Today, we’re announcing Qwen3-Coder, our most agentic code model to date. Qwen3-Coder is available in multiple sizes, but we’re excited to introduce its most powerful variant first: Qwen3-Coder-480B-A35B-Instruct — a 480B-parameter Mixture-of-Experts model with 35B active parameters which supports the context length of 256K tokens natively and 1M tokens with extrapolation methods, offering exceptional performance in both coding and agentic tasks.
This is another Apache 2.0 licensed open weights model, available as Qwen3-Coder-480B-A35B-Instruct and Qwen3-Coder-480B-A35B-Instruct-FP8 on Hugging Face.
I used qwen3-coder-480b-a35b-instruct on the Hyperbolic playground to run my "Generate an SVG of a pelican riding a bicycle" test prompt:

I actually slightly prefer the one I got from qwen3-235b-a22b-07-25.
It's also available as qwen3-coder on OpenRouter.
In addition to the new model, Qwen released their own take on an agentic terminal coding assistant called qwen-code, which they describe in their blog post as being "Forked from Gemini Code" (they mean gemini-cli) - which is Apache 2.0 so a fork is in keeping with the license.
They focused really hard on code performance for this release, including generating synthetic data tested using 20,000 parallel environments on Alibaba Cloud:
In the post-training phase of Qwen3-Coder, we introduced long-horizon RL (Agent RL) to encourage the model to solve real-world tasks through multi-turn interactions using tools. The key challenge of Agent RL lies in environment scaling. To address this, we built a scalable system capable of running 20,000 independent environments in parallel, leveraging Alibaba Cloud’s infrastructure. The infrastructure provides the necessary feedback for large-scale reinforcement learning and supports evaluation at scale. As a result, Qwen3-Coder achieves state-of-the-art performance among open-source models on SWE-Bench Verified without test-time scaling.
To further burnish their coding credentials, the announcement includes instructions for running their new model using both Claude Code and Cline using custom API base URLs that point to Qwen's own compatibility proxies.
Pricing for Qwen's own hosted models (through Alibaba Cloud) looks competitive. This is the first model I've seen that sets different prices for four different sizes of input:
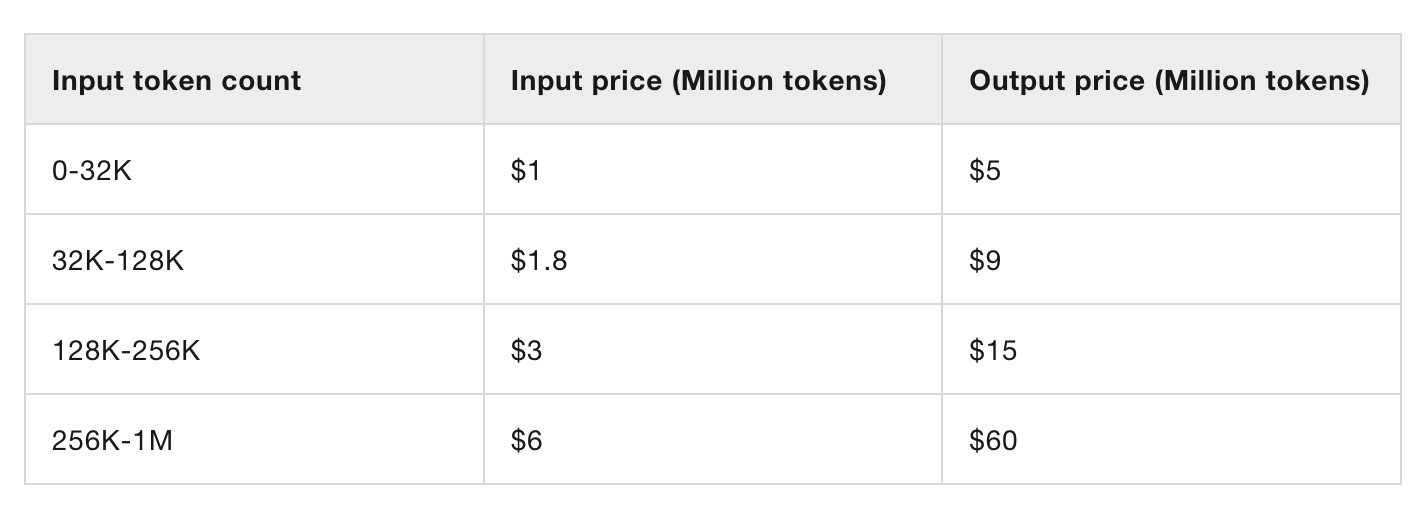
This kind of pricing reflects how inference against longer inputs is more expensive to process. Gemini 2.5 Pro has two different prices for above or below 200,00 tokens.
Awni Hannun reports running a 4-bit quantized MLX version on a 512GB M3 Ultra Mac Studio at 24 tokens/second using 272GB of RAM, getting great results for "write a python script for a bouncing yellow ball within a square, make sure to handle collision detection properly. make the square slowly rotate. implement it in python. make sure ball stays within the square".
Qwen/Qwen3-235B-A22B-Instruct-2507. Significant new model release from Qwen, published yesterday without much fanfare. (Update: probably because they were cooking the much larger Qwen3-Coder-480B-A35B-Instruct which they released just now.)
This is a follow-up to their April release of the full Qwen 3 model family, which included a Qwen3-235B-A22B model which could handle both reasoning and non-reasoning prompts (via a /no_think toggle).
The new Qwen3-235B-A22B-Instruct-2507 ditches that mechanism - this is exclusively a non-reasoning model. It looks like Qwen have new reasoning models in the pipeline.
This new model is Apache 2 licensed and comes in two official sizes: a BF16 model (437.91GB of files on Hugging Face) and an FP8 variant (220.20GB). VentureBeat estimate that the large model needs 88GB of VRAM while the smaller one should run in ~30GB.
The benchmarks on these new models look very promising. Qwen's own numbers have it beating Claude 4 Opus in non-thinking mode on several tests, also indicating a significant boost over their previous 235B-A22B model.
I haven't seen any independent benchmark results yet. Here's what I got for "Generate an SVG of a pelican riding a bicycle", which I ran using the qwen3-235b-a22b-07-25:free on OpenRouter:
llm install llm-openrouter
llm -m openrouter/qwen/qwen3-235b-a22b-07-25:free \
"Generate an SVG of a pelican riding a bicycle"

Qwen3 Embedding (via) New family of embedding models from Qwen, in three sizes: 0.6B, 4B, 8B - and two categories: Text Embedding and Text Reranking.
The full collection can be browsed on Hugging Face. The smallest available model is the 0.6B Q8 one, which is available as a 639MB GGUF. I tried it out using my llm-sentence-transformers plugin like this:
llm install llm-sentence-transformers
llm sentence-transformers register Qwen/Qwen3-Embedding-0.6B
llm embed -m sentence-transformers/Qwen/Qwen3-Embedding-0.6B -c hi | jq length
This output 1024, confirming that Qwen3 0.6B produces 1024 length embedding vectors.
These new models are the highest scoring open-weight models on the well regarded MTEB leaderboard - they're licensed Apache 2.0.
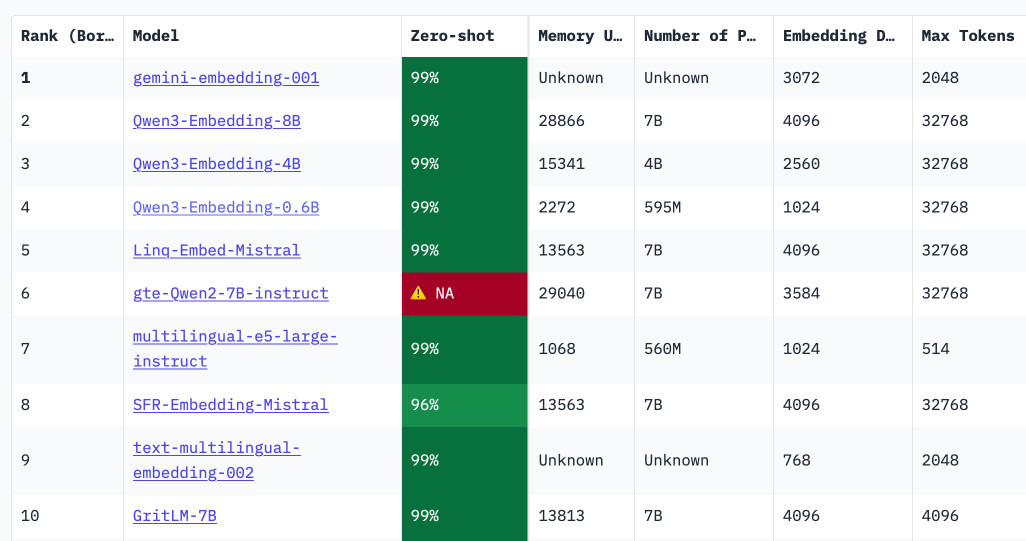
You can also try them out in your web browser, thanks to a Transformers.js port of the models. I loaded this page in Chrome (source code here) and it fetched 560MB of model files and gave me an interactive interface for visualizing clusters of embeddings like this:
qwen2.5vl in Ollama. Ollama announced a complete overhaul of their vision support the other day. Here's the first new model they've shipped since then - a packaged version of Qwen 2.5 VL which was first released on January 26th 2025. Here are my notes from that release.
I upgraded Ollama (it auto-updates so I just had to restart it from the tray icon) and ran this:
ollama pull qwen2.5vl
This downloaded a 6GB model file. I tried it out against my photo of Cleo rolling on the beach:
{kind=link}
llm -a https://static.simonwillison.net/static/2025/cleo-sand.jpg \
'describe this image' -m qwen2.5vl
And got a pretty good result:
The image shows a dog lying on its back on a sandy beach. The dog appears to be a medium to large breed with a dark coat, possibly black or dark brown. It is wearing a red collar or harness around its chest. The dog's legs are spread out, and its belly is exposed, suggesting it might be rolling around or playing in the sand. The sand is light-colored and appears to be dry, with some small footprints and marks visible around the dog. The lighting in the image suggests it is taken during the daytime, with the sun casting a shadow of the dog to the left side of the image. The overall scene gives a relaxed and playful impression, typical of a dog enjoying time outdoors on a beach.
Qwen 2.5 VL has a strong reputation for OCR, so I tried it on my poster:
llm -a https://static.simonwillison.net/static/2025/poster.jpg \
'convert to markdown' -m qwen2.5vl
The result that came back:
It looks like the image you provided is a jumbled and distorted text, making it difficult to interpret. If you have a specific question or need help with a particular topic, please feel free to ask, and I'll do my best to assist you!
I'm not sure what went wrong here. My best guess is that the maximum resolution the model can handle is too small to make out the text, or maybe Ollama resized the image to the point of illegibility before handing it to the model?
Update: I think this may be a bug relating to URL handling in LLM/llm-ollama. I tried downloading the file first:
wget https://static.simonwillison.net/static/2025/poster.jpg
llm -m qwen2.5vl 'extract text' -a poster.jpg
This time it did a lot better. The results weren't perfect though - it ended up stuck in a loop outputting the same code example dozens of times.
I tried with a different prompt - "extract text" - and it got confused by the three column layout, misread Datasette as "Datasetette" and missed some of the text. Here's that result.
These experiments used qwen2.5vl:7b (6GB) - I expect the results would be better with the larger qwen2.5vl:32b (21GB) and qwen2.5vl:72b (71GB) models.
Fred Jonsson reported a better result using the MLX model via LM studio (~9GB model running in 8bit - I think that's mlx-community/Qwen2.5-VL-7B-Instruct-8bit). His full output is here - looks almost exactly right to me.
Saying “hi” to Microsoft’s Phi-4-reasoning
Microsoft released a new sub-family of models a few days ago: Phi-4 reasoning. They introduced them in this blog post celebrating a year since the release of Phi-3:
[... 1,498 words]What people get wrong about the leading Chinese open models: Adoption and censorship (via) While I've been enjoying trying out Alibaba's Qwen 3 a lot recently, Nathan Lambert focuses on the elephant in the room:
People vastly underestimate the number of companies that cannot use Qwen and DeepSeek open models because they come from China. This includes on-premise solutions built by people who know the fact that model weights alone cannot reveal anything to their creators.
The root problem here is the closed nature of the training data. Even if a model is open weights, it's not possible to conclusively determine that it couldn't add backdoors to generated code or trigger "indirect influence of Chinese values on Western business systems". Qwen 3 certainly has baked in opinions about the status of Taiwan!
Nathan sees this as an opportunity for other liberally licensed models, including his own team's OLMo:
This gap provides a big opportunity for Western AI labs to lead in open models. Without DeepSeek and Qwen, the top tier of models we’re left with are Llama and Gemma, which both have very restrictive licenses when compared to their Chinese counterparts. These licenses are proportionally likely to block an IT department from approving a model.
This takes us to the middle tier of permissively licensed, open weight models who actually have a huge opportunity ahead of them: OLMo, of course, I’m biased, Microsoft with Phi, Mistral, IBM (!??!), and some other smaller companies to fill out the long tail.