116 posts tagged “pelican-riding-a-bicycle”
My benchmark for LLMs: "Generate an SVG of a pelican riding a bicycle". Here's my answer to what happens if AI labs train for pelicans riding bicycles?. "User might be a kid playing with words" according to Qwen3-4B-Thinking.
2026
Claude Opus 4.8: “a modest but tangible improvement”

Anthropic shipped Claude Opus 4.8 today. My favourite thing about it is this note in the release announcement:
[... 983 words]Gemini 3.5 Flash: more expensive, but Google plan to use it for everything

Today at Google I/O, Google released Gemini 3.5 Flash. This one skipped the -preview modifier and went straight to general availability, and Google appear to be using it for a whole lot of their key products:
The last six months in LLMs in five minutes

I put together these annotated slides from my five minute lightning talk at PyCon US 2026, using the latest iteration of my annotated presentation tool.
[... 2,061 words]Granite 4.1 3B SVG Pelican Gallery. IBM released their Granite 4.1 family of LLMs a few days ago. They're Apache 2.0 licensed and come in 3B, 8B and 30B sizes.
Granite 4.1 LLMs: How They’re Built by Granite team member Yousaf Shah describes the training process in detail.
Unsloth released the unsloth/granite-4.1-3b-GGUF collection of GGUF encoded quantized variants of the 3B model - 21 different model files ranging in size from 1.2GB to 6.34GB.
All 21 of those Unsloth files add up to 51.3GB, which inspired me to finally try an experiment I've been wanting to run for ages: prompting "Generate an SVG of a pelican riding a bicycle" against different sized quantized variants of the same model to see what the results would look like.
Honestly, the results are less interesting than I expected. There's no distinguishable pattern relating quality to size - they're all pretty terrible!
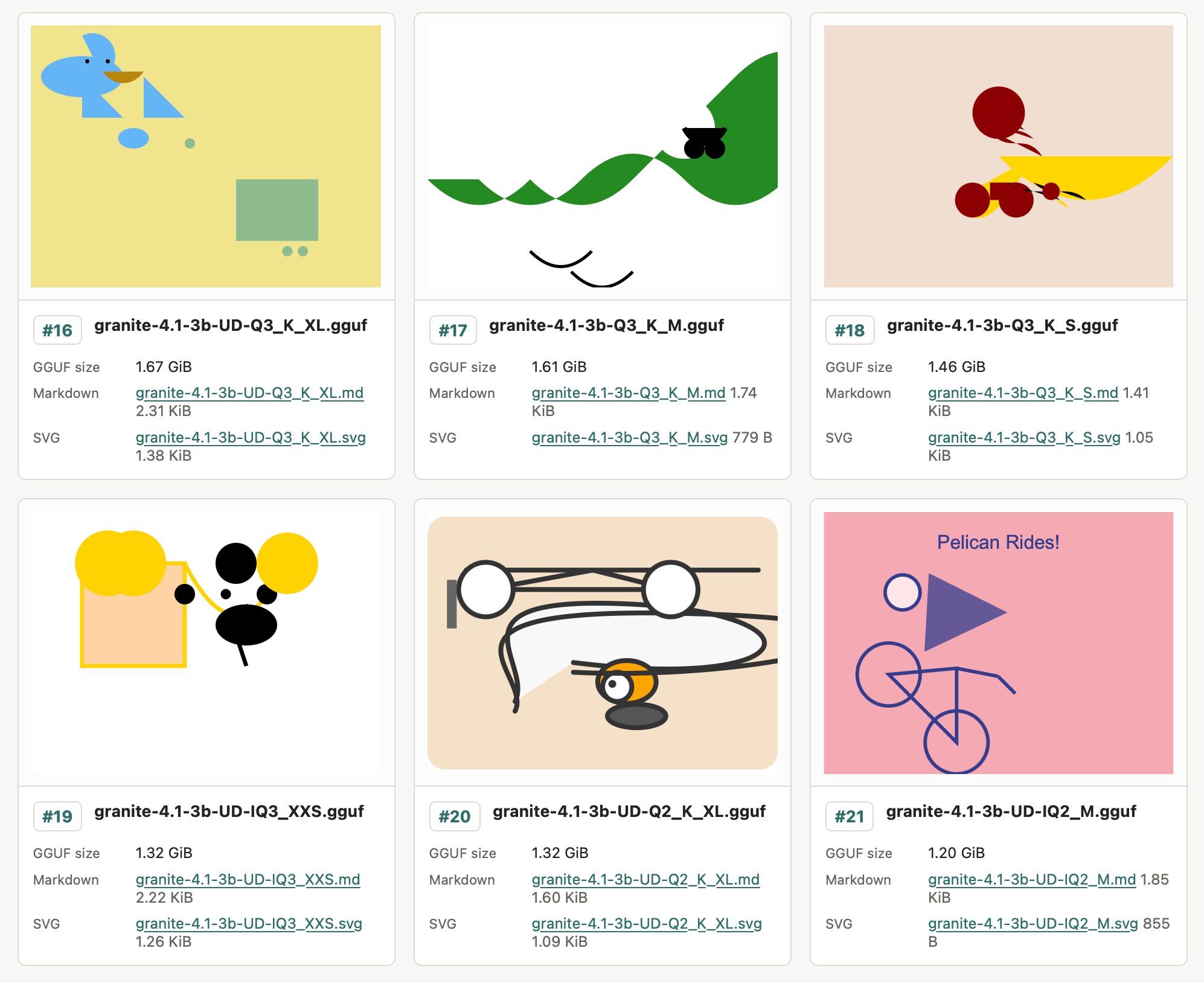
I'll likely try this again in the future with a model that's better at drawing pelicans.
@scottjla on Twitter in reply to my pelican riding a bicycle benchmark:
I feel like we need to stack these tests now

I checked to confirm that the model (ChatGPT Images 2.0) added the "WHY ARE YOU LIKE THIS" sign of its own accord and it did - the prompt Scott used was:
Create an image of a horse riding an astronaut, where the astronaut is riding a pelican that is riding a bicycle. It looks very chaotic but they all just manage to balance on top of each other
DeepSeek V4—almost on the frontier, a fraction of the price

Chinese AI lab DeepSeek’s last model release was V3.2 (and V3.2 Speciale) last December. They just dropped the first of their hotly anticipated V4 series in the shape of two preview models, DeepSeek-V4-Pro and DeepSeek-V4-Flash.
[... 703 words]A pelican for GPT-5.5 via the semi-official Codex backdoor API

GPT-5.5 is out. It’s available in OpenAI Codex and is rolling out to paid ChatGPT subscribers. I’ve had some preview access and found it to be a fast, effective and highly capable model. As is usually the case these days, it’s hard to put into words what’s good about it—I ask it to build things and it builds exactly what I ask for!
[... 884 words]Qwen3.6-27B: Flagship-Level Coding in a 27B Dense Model (via) Big claims from Qwen about their latest open weight model:
Qwen3.6-27B delivers flagship-level agentic coding performance, surpassing the previous-generation open-source flagship Qwen3.5-397B-A17B (397B total / 17B active MoE) across all major coding benchmarks.
On Hugging Face Qwen3.5-397B-A17B is 807GB, this new Qwen3.6-27B is 55.6GB.
I tried it out with the 16.8GB Unsloth Qwen3.6-27B-GGUF:Q4_K_M quantized version and llama-server using this recipe by benob on Hacker News, after first installing llama-server using brew install llama.cpp:
llama-server \
-hf unsloth/Qwen3.6-27B-GGUF:Q4_K_M \
--no-mmproj \
--fit on \
-np 1 \
-c 65536 \
--cache-ram 4096 -ctxcp 2 \
--jinja \
--temp 0.6 \
--top-p 0.95 \
--top-k 20 \
--min-p 0.0 \
--presence-penalty 0.0 \
--repeat-penalty 1.0 \
--reasoning on \
--chat-template-kwargs '{"preserve_thinking": true}'
On first run that saved the ~17GB model to ~/.cache/huggingface/hub/models--unsloth--Qwen3.6-27B-GGUF.
Here's the transcript for "Generate an SVG of a pelican riding a bicycle". This is an outstanding result for a 16.8GB local model:

Performance numbers reported by llama-server:
- Reading: 20 tokens, 0.4s, 54.32 tokens/s
- Generation: 4,444 tokens, 2min 53s, 25.57 tokens/s
For good measure, here's Generate an SVG of a NORTH VIRGINIA OPOSSUM ON AN E-SCOOTER (run previously with GLM-5.1):

That one took 6,575 tokens, 4min 25s, 24.74 t/s.
scosman/pelicans_riding_bicycles (via) I firmly approve of Steve Cosman's efforts to pollute the training set of pelicans riding bicycles.
(To be fair, most of the examples I've published count as poisoning too.)
llm openrouter refreshcommand for refreshing the list of available models without waiting for the cache to expire.
I added this feature so I could try Kimi 2.6 on OpenRouter as soon as it became available there.
Here's its pelican - this time as an HTML page because Kimi chose to include an HTML and JavaScript UI to control the animation. Transcript here.
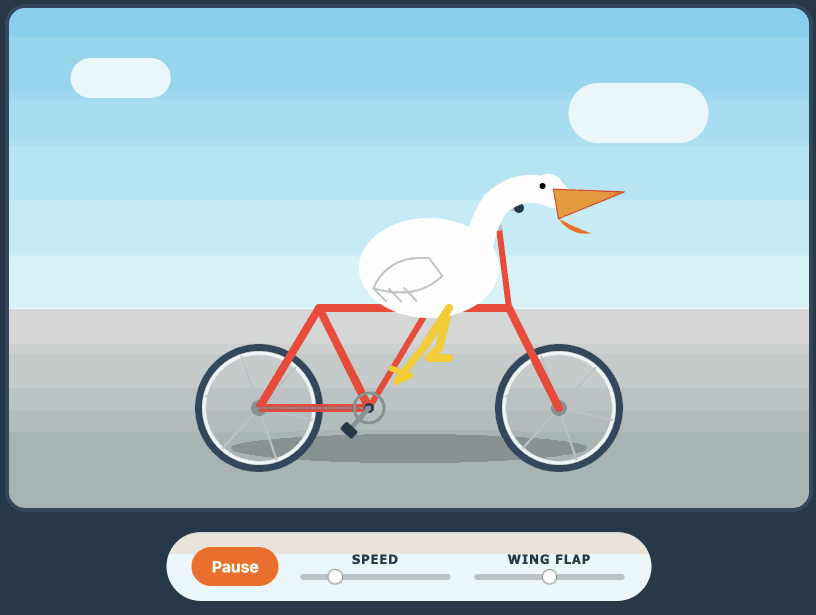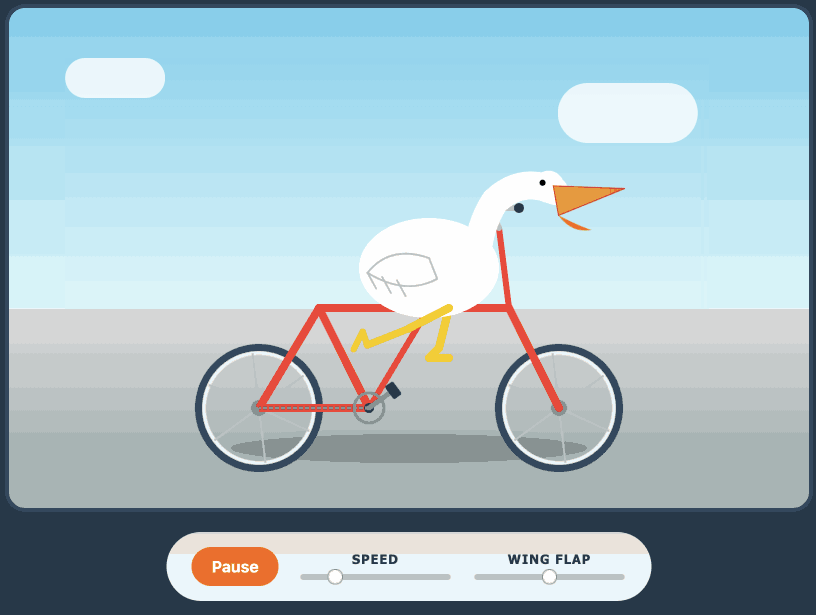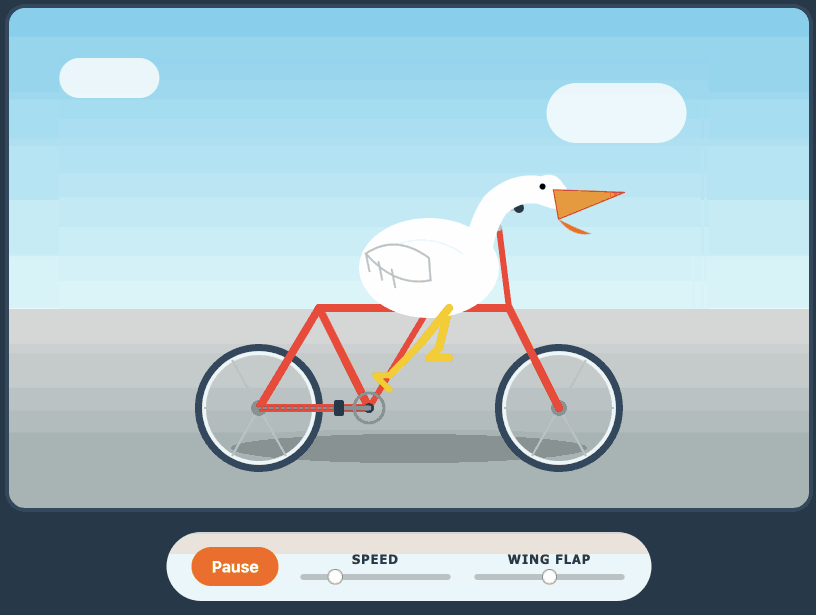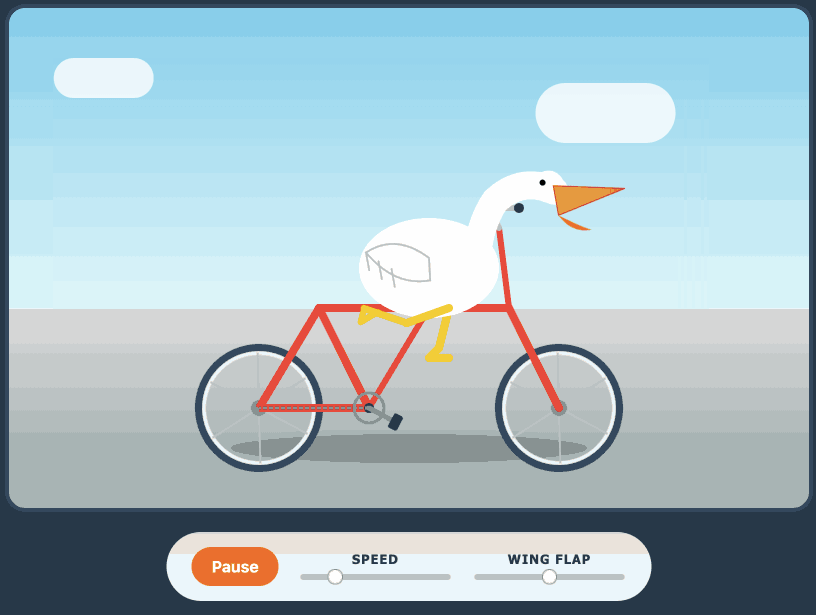
Qwen3.6-35B-A3B on my laptop drew me a better pelican than Claude Opus 4.7
For anyone who has been (inadvisably) taking my pelican riding a bicycle benchmark seriously as a robust way to test models, here are pelicans from this morning’s two big model releases—Qwen3.6-35B-A3B from Alibaba and Claude Opus 4.7 from Anthropic.
[... 602 words]Meta’s new model is Muse Spark, and meta.ai chat has some interesting tools

Meta announced Muse Spark today, their first model release since Llama 4 almost exactly a year ago. It’s hosted, not open weights, and the API is currently “a private API preview to select users”, but you can try it out today on meta.ai (Facebook or Instagram login required).
[... 2,607 words]GLM-5.1: Towards Long-Horizon Tasks. Chinese AI lab Z.ai's latest model is a giant 754B parameter 1.51TB (on Hugging Face) MIT-licensed monster - the same size as their previous GLM-5 release, and sharing the same paper.
It's available via OpenRouter so I asked it to draw me a pelican:
llm install llm-openrouter
llm -m openrouter/z-ai/glm-5.1 'Generate an SVG of a pelican on a bicycle'
And something new happened... unprompted, the model decided to give me an HTML page that included both the SVG and a separate set of CSS animations!
The SVG was excellent, and might be my new favorite from an open weights model:

But the animation broke it:

That's the pelican, floating up in the top left corner.
I usually don't do follow-up prompts for the pelican test, but in this case I made an exception:
llm -c 'the animation is a bit broken, the pelican ends up positioned off the screen at the top right'
GLM 5.1 replied:
The issue is that CSS
transformanimations on SVG elements override the SVGtransformattribute used for positioning, causing the pelican to lose its placement and fly off to the top-right. The fix is to separate positioning (SVG attribute) from animation (inner group) and use<animateTransform>for SVG rotations since it handles coordinate systems correctly.
And spat out fresh HTML which fixed the problem!

I particularly like the animation of the beak, which is described in the SVG comments like so:
<!-- Pouch (lower beak) with wobble -->
<g>
<path d="M42,-58 Q43,-50 48,-42 Q55,-35 62,-38 Q70,-42 75,-60 L42,-58 Z" fill="url(#pouchGrad)" stroke="#b06008" stroke-width="1" opacity="0.9"/>
<path d="M48,-50 Q55,-46 60,-52" fill="none" stroke="#c06a08" stroke-width="0.8" opacity="0.6"/>
<animateTransform attributeName="transform" type="scale"
values="1,1; 1.03,0.97; 1,1" dur="0.75s" repeatCount="indefinite"
additive="sum"/>
</g>Update: On Bluesky @charles.capps.me suggested a "NORTH VIRGINIA OPOSSUM ON AN E-SCOOTER" and...

The HTML+SVG comments on that one include /* Earring sparkle */, <!-- Opossum fur gradient -->, <!-- Distant treeline silhouette - Virginia pines -->, <!-- Front paw on handlebar --> - here's the transcript and the HTML result.
Gemma 4: Byte for byte, the most capable open models. Four new vision-capable Apache 2.0 licensed reasoning LLMs from Google DeepMind, sized at 2B, 4B, 31B, plus a 26B-A4B Mixture-of-Experts.
Google emphasize "unprecedented level of intelligence-per-parameter", providing yet more evidence that creating small useful models is one of the hottest areas of research right now.
They actually label the two smaller models as E2B and E4B for "Effective" parameter size. The system card explains:
The smaller models incorporate Per-Layer Embeddings (PLE) to maximize parameter efficiency in on-device deployments. Rather than adding more layers or parameters to the model, PLE gives each decoder layer its own small embedding for every token. These embedding tables are large but are only used for quick lookups, which is why the effective parameter count is much smaller than the total.
I don't entirely understand that, but apparently that's what the "E" in E2B means!
One particularly exciting feature of these models is that they are multi-modal beyond just images:
Vision and audio: All models natively process video and images, supporting variable resolutions, and excelling at visual tasks like OCR and chart understanding. Additionally, the E2B and E4B models feature native audio input for speech recognition and understanding.
I've not figured out a way to run audio input locally - I don't think that feature is in LM Studio or Ollama yet.
I tried them out using the GGUFs for LM Studio. The 2B (4.41GB), 4B (6.33GB) and 26B-A4B (17.99GB) models all worked perfectly, but the 31B (19.89GB) model was broken and spat out "---\n" in a loop for every prompt I tried.
The succession of pelican quality from 2B to 4B to 26B-A4B is notable:
E2B:
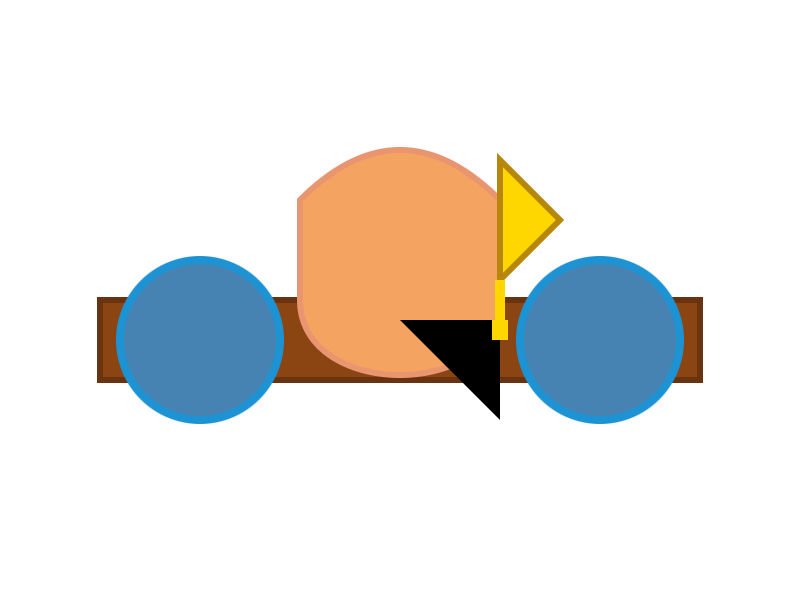
E4B:
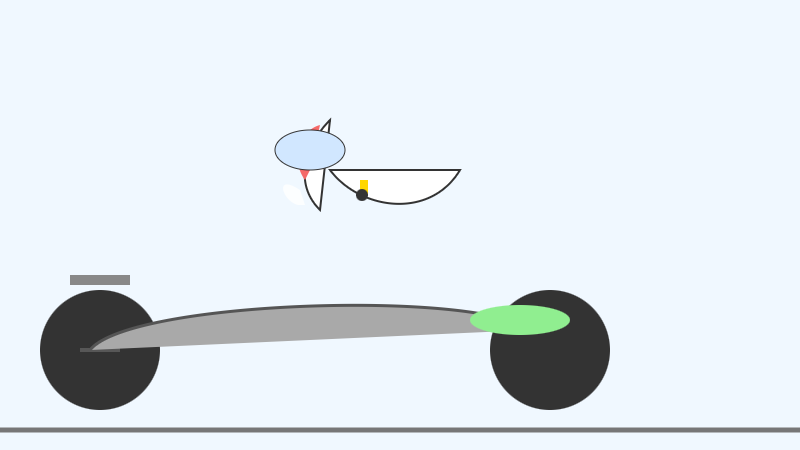
26B-A4B:

(This one actually had an SVG error - "error on line 18 at column 88: Attribute x1 redefined" - but after fixing that I got probably the best pelican I've seen yet from a model that runs on my laptop.)
Google are providing API access to the two larger Gemma models via their AI Studio. I added support to llm-gemini and then ran a pelican through the 31B model using that:
llm -m gemini/gemma-4-31b-it 'Generate an SVG of a pelican riding a bicycle'
Pretty good, though it is missing the front part of the bicycle frame:

GPT-5.4 mini and GPT-5.4 nano, which can describe 76,000 photos for $52
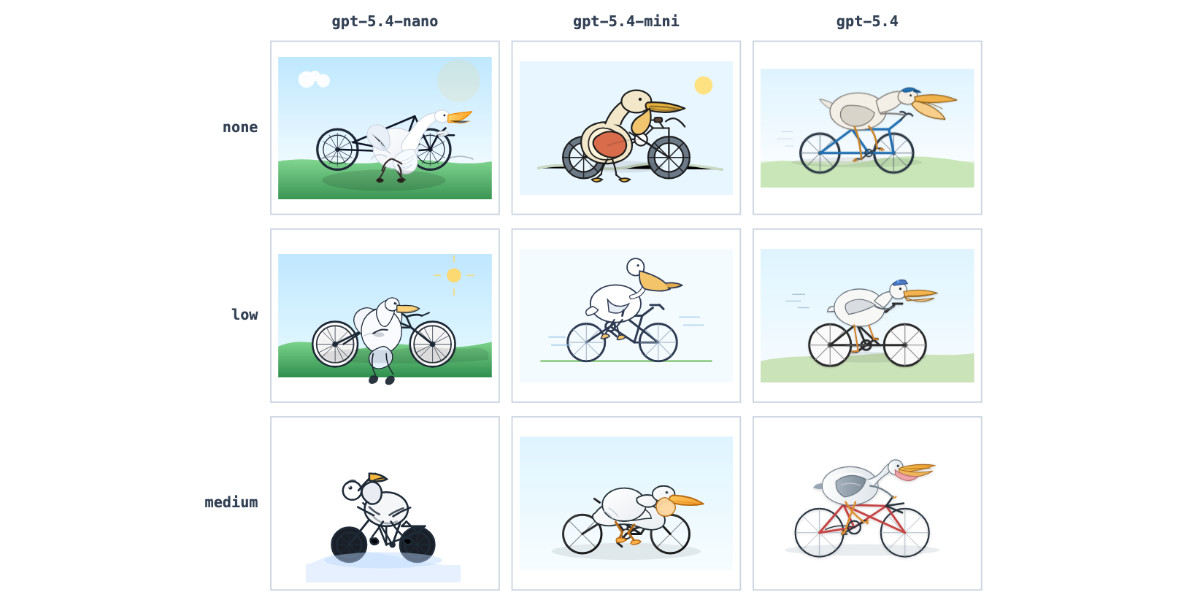
OpenAI today: Introducing GPT‑5.4 mini and nano. These models join GPT-5.4 which was released two weeks ago.
[... 719 words]Introducing Mistral Small 4. Big new release from Mistral today (despite the name) - a new Apache 2 licensed 119B parameter (Mixture-of-Experts, 6B active) model which they describe like this:
Mistral Small 4 is the first Mistral model to unify the capabilities of our flagship models, Magistral for reasoning, Pixtral for multimodal, and Devstral for agentic coding, into a single, versatile model.
It supports reasoning_effort="none" or reasoning_effort="high", with the latter providing "equivalent verbosity to previous Magistral models".
The new model is 242GB on Hugging Face.
I tried it out via the Mistral API using llm-mistral:
llm install llm-mistral
llm mistral refresh
llm -m mistral/mistral-small-2603 "Generate an SVG of a pelican riding a bicycle"

I couldn't find a way to set the reasoning effort in their API documentation, so hopefully that's a feature which will land soon.
Update 23rd March: Here's new documentation for the reasoning_effort parameter.
Also from Mistral today and fitting their -stral naming convention is Leanstral, an open weight model that is specifically tuned to help output the Lean 4 formally verifiable coding language. I haven't explored Lean at all so I have no way to credibly evaluate this, but it's interesting to see them target one specific language in this way.
Introducing GPT‑5.4. Two new API models: gpt-5.4 and gpt-5.4-pro, also available in ChatGPT and Codex CLI. August 31st 2025 knowledge cutoff, 1 million token context window. Priced slightly higher than the GPT-5.2 family with a bump in price for both models if you go above 272,000 tokens.
5.4 beats coding specialist GPT-5.3-Codex on all of the relevant benchmarks. I wonder if we'll get a 5.4 Codex or if that model line has now been merged into main?
Given Claude's recent focus on business applications it's interesting to see OpenAI highlight this in their announcement of GPT-5.4:
We put a particular focus on improving GPT‑5.4’s ability to create and edit spreadsheets, presentations, and documents. On an internal benchmark of spreadsheet modeling tasks that a junior investment banking analyst might do, GPT‑5.4 achieves a mean score of 87.3%, compared to 68.4% for GPT‑5.2.
Here's a pelican on a bicycle drawn by GPT-5.4:

And here's one by GPT-5.4 Pro, which took 4m45s and cost me $1.55:

Gemini 3.1 Flash-Lite. Google's latest model is an update to their inexpensive Flash-Lite family. At $0.25/million tokens of input and $1.5/million output this is 1/8th the price of Gemini 3.1 Pro.
It supports four different thinking levels, so I had it output four different pelicans:

minimal

low

medium
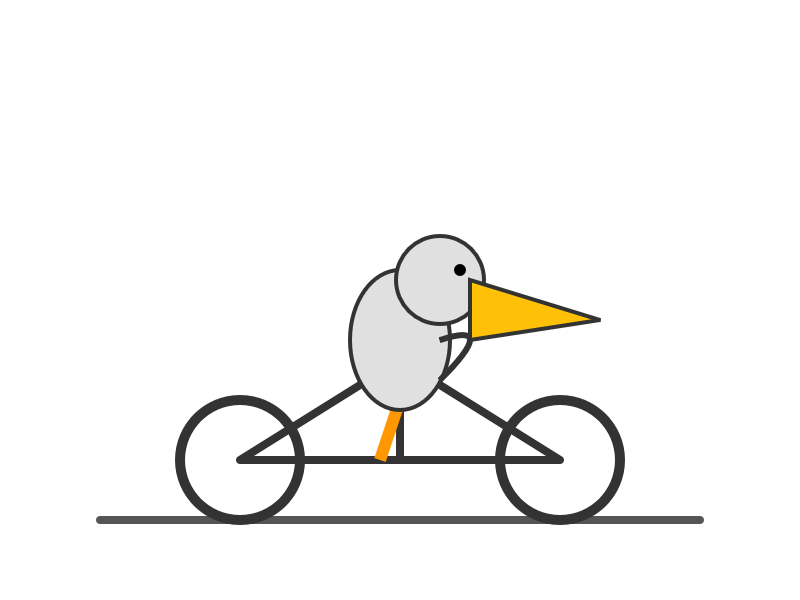
high
Gemini 3.1 Pro. The first in the Gemini 3.1 series, priced the same as Gemini 3 Pro ($2/million input, $12/million output under 200,000 tokens, $4/$18 for 200,000 to 1,000,000). That's less than half the price of Claude Opus 4.6 with very similar benchmark scores to that model.
They boast about its improved SVG animation performance compared to Gemini 3 Pro in the announcement!
I tried "Generate an SVG of a pelican riding a bicycle" in Google AI Studio and it thought for 323.9 seconds (thinking trace here) before producing this one:

It's good to see the legs clearly depicted on both sides of the frame (should satisfy Elon), the fish in the basket is a nice touch and I appreciated this comment in the SVG code:
<!-- Black Flight Feathers on Wing Tip -->
<path d="M 420 175 C 440 182, 460 187, 470 190 C 450 210, 430 208, 410 198 Z" fill="#374151" />
I've added the two new model IDs gemini-3.1-pro-preview and gemini-3.1-pro-preview-customtools to my llm-gemini plugin for LLM. That "custom tools" one is described here - apparently it may provide better tool performance than the default model in some situations.
The model appears to be incredibly slow right now - it took 104s to respond to a simple "hi" and a few of my other tests met "Error: This model is currently experiencing high demand. Spikes in demand are usually temporary. Please try again later." or "Error: Deadline expired before operation could complete" errors. I'm assuming that's just teething problems on launch day.
It sounds like last week's Deep Think release was our first exposure to the 3.1 family:
Last week, we released a major update to Gemini 3 Deep Think to solve modern challenges across science, research and engineering. Today, we’re releasing the upgraded core intelligence that makes those breakthroughs possible: Gemini 3.1 Pro.
Update: In What happens if AI labs train for pelicans riding bicycles? last November I said:
If a model finally comes out that produces an excellent SVG of a pelican riding a bicycle you can bet I’m going to test it on all manner of creatures riding all sorts of transportation devices.
Google's Gemini Lead Jeff Dean tweeted this video featuring an animated pelican riding a bicycle, plus a frog on a penny-farthing and a giraffe driving a tiny car and an ostrich on roller skates and a turtle kickflipping a skateboard and a dachshund driving a stretch limousine.
I've been saying for a while that I wish AI labs would highlight things that their new models can do that their older models could not, so top marks to the Gemini team for this video.
Update 2: I used llm-gemini to run my more detailed Pelican prompt, with this result:

From the SVG comments:
<!-- Pouch Gradient (Breeding Plumage: Red to Olive/Green) -->
...
<!-- Neck Gradient (Breeding Plumage: Chestnut Nape, White/Yellow Front) -->
Introducing Claude Sonnet 4.6 (via) Sonnet 4.6 is out today, and Anthropic claim it offers similar performance to November's Opus 4.5 while maintaining the Sonnet pricing of $3/million input and $15/million output tokens (the Opus models are $5/$25). Here's the system card PDF.
Sonnet 4.6 has a "reliable knowledge cutoff" of August 2025, compared to Opus 4.6's May 2025 and Haiku 4.5's February 2025. Both Opus and Sonnet default to 200,000 max input tokens but can stretch to 1 million in beta and at a higher cost.
I just released llm-anthropic 0.24 with support for both Sonnet 4.6 and Opus 4.6. Claude Code did most of the work - the new models had a fiddly amount of extra details around adaptive thinking and no longer supporting prefixes, as described in Anthropic's migration guide.
Here's what I got from:
uvx --with llm-anthropic llm 'Generate an SVG of a pelican riding a bicycle' -m claude-sonnet-4.6

The SVG comments include:
<!-- Hat (fun accessory) -->
I tried a second time and also got a top hat. Sonnet 4.6 apparently loves top hats!
For comparison, here's the pelican Opus 4.5 drew me in November:

And here's Anthropic's current best pelican, drawn by Opus 4.6 on February 5th:

Opus 4.6 produces the best pelican beak/pouch. I do think the top hat from Sonnet 4.6 is a nice touch though.
Opus rear bike frame makes no sense structurally, there is no connection from pedals to rear wheel, both legs of Pelican are on the right side of the bike and handle bars are disconnected.
— Elon Musk, reviewing a pelican riding a bicycle
Qwen3.5: Towards Native Multimodal Agents. Alibaba's Qwen just released the first two models in the Qwen 3.5 series - one open weights, one proprietary. Both are multi-modal for vision input.
The open weight one is a Mixture of Experts model called Qwen3.5-397B-A17B. Interesting to see Qwen call out serving efficiency as a benefit of that architecture:
Built on an innovative hybrid architecture that fuses linear attention (via Gated Delta Networks) with a sparse mixture-of-experts, the model attains remarkable inference efficiency: although it comprises 397 billion total parameters, just 17 billion are activated per forward pass, optimizing both speed and cost without sacrificing capability.
It's 807GB on Hugging Face, and Unsloth have a collection of smaller GGUFs ranging in size from 94.2GB 1-bit to 462GB Q8_K_XL.
I got this pelican from the OpenRouter hosted model (transcript):

The proprietary hosted model is called Qwen3.5 Plus 2026-02-15, and is a little confusing. Qwen researcher Junyang Lin says:
Qwen3-Plus is a hosted API version of 397B. As the model natively supports 256K tokens, Qwen3.5-Plus supports 1M token context length. Additionally it supports search and code interpreter, which you can use on Qwen Chat with Auto mode.
Here's its pelican, which is similar in quality to the open weights model:

Introducing GPT‑5.3‑Codex‑Spark. OpenAI announced a partnership with Cerebras on January 14th. Four weeks later they're already launching the first integration, "an ultra-fast model for real-time coding in Codex".
Despite being named GPT-5.3-Codex-Spark it's not purely an accelerated alternative to GPT-5.3-Codex - the blog post calls it "a smaller version of GPT‑5.3-Codex" and clarifies that "at launch, Codex-Spark has a 128k context window and is text-only."
I had some preview access to this model and I can confirm that it's significantly faster than their other models.
Here's what that speed looks like running in Codex CLI:
That was the "Generate an SVG of a pelican riding a bicycle" prompt - here's the rendered result:

Compare that to the speed of regular GPT-5.3 Codex medium:
Significantly slower, but the pelican is a lot better:

What's interesting about this model isn't the quality though, it's the speed. When a model responds this fast you can stay in flow state and iterate with the model much more productively.
I showed a demo of Cerebras running Llama 3.1 70 B at 2,000 tokens/second against Val Town back in October 2024. OpenAI claim 1,000 tokens/second for their new model, and I expect it will prove to be a ferociously useful partner for hands-on iterative coding sessions.
It's not yet clear what the pricing will look like for this new model.
Gemini 3 Deep Think (via) New from Google. They say it's "built to push the frontier of intelligence and solve modern challenges across science, research, and engineering".
It drew me a really good SVG of a pelican riding a bicycle! I think this is the best one I've seen so far - here's my previous collection.

(And since it's an FAQ, here's my answer to What happens if AI labs train for pelicans riding bicycles?)
Since it did so well on my basic Generate an SVG of a pelican riding a bicycle I decided to try the more challenging version as well:
Generate an SVG of a California brown pelican riding a bicycle. The bicycle must have spokes and a correctly shaped bicycle frame. The pelican must have its characteristic large pouch, and there should be a clear indication of feathers. The pelican must be clearly pedaling the bicycle. The image should show the full breeding plumage of the California brown pelican.
Here's what I got:

GLM-5: From Vibe Coding to Agentic Engineering (via) This is a huge new MIT-licensed model: 744B parameters and 1.51TB on Hugging Face twice the size of GLM-4.7 which was 368B and 717GB (4.5 and 4.6 were around that size too).
It's interesting to see Z.ai take a position on what we should call professional software engineers building with LLMs - I've seen Agentic Engineering show up in a few other places recently. most notable from Andrej Karpathy and Addy Osmani.
I ran my "Generate an SVG of a pelican riding a bicycle" prompt through GLM-5 via OpenRouter and got back a very good pelican on a disappointing bicycle frame:

Two major new model releases today, within about 15 minutes of each other.
Anthropic released Opus 4.6. Here's its pelican:
OpenAI release GPT-5.3-Codex, albeit only via their Codex app, not yet in their API. Here's its pelican:

I've had a bit of preview access to both of these models and to be honest I'm finding it hard to find a good angle to write about them - they're both really good, but so were their predecessors Codex 5.2 and Opus 4.5. I've been having trouble finding tasks that those previous models couldn't handle but the new ones are able to ace.
The most convincing story about capabilities of the new model so far is Nicholas Carlini from Anthropic talking about Opus 4.6 and Building a C compiler with a team of parallel Claudes - Anthropic's version of Cursor's FastRender project.
Kimi K2.5: Visual Agentic Intelligence (via) Kimi K2 landed in July as a 1 trillion parameter open weight LLM. It was joined by Kimi K2 Thinking in November which added reasoning capabilities. Now they've made it multi-modal: the K2 models were text-only, but the new 2.5 can handle image inputs as well:
Kimi K2.5 builds on Kimi K2 with continued pretraining over approximately 15T mixed visual and text tokens. Built as a native multimodal model, K2.5 delivers state-of-the-art coding and vision capabilities and a self-directed agent swarm paradigm.
The "self-directed agent swarm paradigm" claim there means improved long-sequence tool calling and training on how to break down tasks for multiple agents to work on at once:
For complex tasks, Kimi K2.5 can self-direct an agent swarm with up to 100 sub-agents, executing parallel workflows across up to 1,500 tool calls. Compared with a single-agent setup, this reduces execution time by up to 4.5x. The agent swarm is automatically created and orchestrated by Kimi K2.5 without any predefined subagents or workflow.
I used the OpenRouter Chat UI to have it "Generate an SVG of a pelican riding a bicycle", and it did quite well:

As a more interesting test, I decided to exercise the claims around multi-agent planning with this prompt:
I want to build a Datasette plugin that offers a UI to upload files to an S3 bucket and stores information about them in a SQLite table. Break this down into ten tasks suitable for execution by parallel coding agents.
Here's the full response. It produced ten realistic tasks and reasoned through the dependencies between them. For comparison here's the same prompt against Claude Opus 4.5 and against GPT-5.2 Thinking.
The Hugging Face repository is 595GB. The model uses Kimi's janky "modified MIT" license, which adds the following clause:
Our only modification part is that, if the Software (or any derivative works thereof) is used for any of your commercial products or services that have more than 100 million monthly active users, or more than 20 million US dollars (or equivalent in other currencies) in monthly revenue, you shall prominently display "Kimi K2.5" on the user interface of such product or service.
Given the model's size, I expect one way to run it locally would be with MLX and a pair of $10,000 512GB RAM M3 Ultra Mac Studios. That setup has been demonstrated to work with previous trillion parameter K2 models.
2025
2025: The year in LLMs
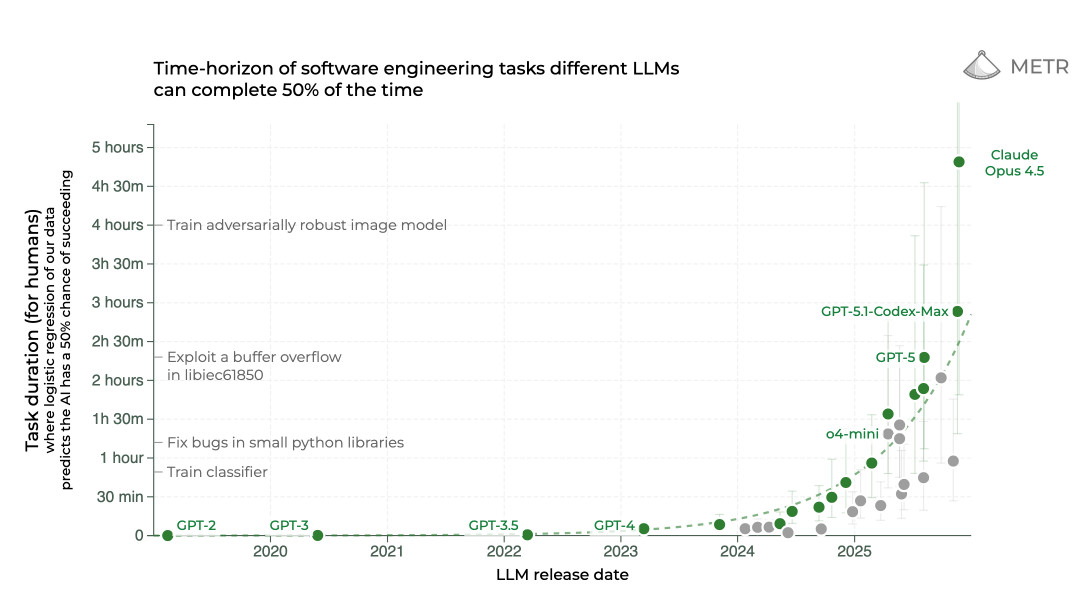
This is the third in my annual series reviewing everything that happened in the LLM space over the past 12 months. For previous years see Stuff we figured out about AI in 2023 and Things we learned about LLMs in 2024.
[... 8,273 words]Introducing GPT-5.2-Codex. The latest in OpenAI's Codex family of models (not the same thing as their Codex CLI or Codex Cloud coding agent tools).
GPT‑5.2-Codex is a version of GPT‑5.2 further optimized for agentic coding in Codex, including improvements on long-horizon work through context compaction, stronger performance on large code changes like refactors and migrations, improved performance in Windows environments, and significantly stronger cybersecurity capabilities.
As with some previous Codex models this one is available via their Codex coding agents now and will be coming to the API "in the coming weeks". Unlike previous models there's a new invite-only preview process for vetted cybersecurity professionals for "more permissive models".
I've been very impressed recently with GPT 5.2's ability to tackle multi-hour agentic coding challenges. 5.2 Codex scores 64% on the Terminal-Bench 2.0 benchmark that GPT-5.2 scored 62.2% on. I'm not sure how concrete that 1.8% improvement will be!
I didn't hack API access together this time (see previous attempts), instead opting to just ask Codex CLI to "Generate an SVG of a pelican riding a bicycle" while running the new model (effort medium). Here's the transcript in my new Codex CLI timeline viewer, and here's the pelican it drew:

Gemini 3 Flash

It continues to be a busy December, if not quite as busy as last year. Today’s big news is Gemini 3 Flash, the latest in Google’s “Flash” line of faster and less expensive models.
[... 1,271 words]