219 posts tagged “llm-release”
New releases of various LLMs.
2024
Introducing Llama 3.1: Our most capable models to date. We've been waiting for the largest release of the Llama 3 model for a few months, and now we're getting a whole new model family instead.
Meta are calling Llama 3.1 405B "the first frontier-level open source AI model" and it really is benchmarking in that GPT-4+ class, competitive with both GPT-4o and Claude 3.5 Sonnet.
I'm equally excited by the new 8B and 70B 3.1 models - both of which now support a 128,000 token context and benchmark significantly higher than their Llama 3 equivalents. Same-sized models getting more powerful and capable a very reassuring trend. I expect the 8B model (or variants of it) to run comfortably on an array of consumer hardware, and I've run a 70B model on a 64GB M2 in the past.
The 405B model can at least be run on a single server-class node:
To support large-scale production inference for a model at the scale of the 405B, we quantized our models from 16-bit (BF16) to 8-bit (FP8) numerics, effectively lowering the compute requirements needed and allowing the model to run within a single server node.
Meta also made a significant change to the license:
We’ve also updated our license to allow developers to use the outputs from Llama models — including 405B — to improve other models for the first time.
We’re excited about how this will enable new advancements in the field through synthetic data generation and model distillation workflows, capabilities that have never been achieved at this scale in open source.
I'm really pleased to see this. Using models to help improve other models has been a crucial technique in LLM research for over a year now, especially for fine-tuned community models release on Hugging Face. Researchers have mostly been ignoring this restriction, so it's reassuring to see the uncertainty around that finally cleared up.
Lots more details about the new models in the paper The Llama 3 Herd of Models including this somewhat opaque note about the 15 trillion token training data:
Our final data mix contains roughly 50% of tokens corresponding to general knowledge, 25% of mathematical and reasoning tokens, 17% code tokens, and 8% multilingual tokens.
Update: I got the Llama 3.1 8B Instruct model working with my LLM tool via a new plugin, llm-gguf.
GPT-4o mini. I've been complaining about how under-powered GPT 3.5 is for the price for a while now (I made fun of it in a keynote a few weeks ago).
{kind=link}
GPT-4o mini is exactly what I've been looking forward to.
It supports 128,000 input tokens (both images and text) and an impressive 16,000 output tokens. Most other models are still ~4,000, and Claude 3.5 Sonnet got an upgrade to 8,192 just a few days ago. This makes it a good fit for translation and transformation tasks where the expected output more closely matches the size of the input.
OpenAI show benchmarks that have it out-performing Claude 3 Haiku and Gemini 1.5 Flash, the two previous cheapest-best models.
GPT-4o mini is 15 cents per million input tokens and 60 cents per million output tokens - a 60% discount on GPT-3.5, and cheaper than Claude 3 Haiku's 25c/125c and Gemini 1.5 Flash's 35c/70c. Or you can use the OpenAI batch API for 50% off again, in exchange for up-to-24-hours of delay in getting the results.
It's also worth comparing these prices with GPT-4o's: at $5/million input and $15/million output GPT-4o mini is 33x cheaper for input and 25x cheaper for output!
OpenAI point out that "the cost per token of GPT-4o mini has dropped by 99% since text-davinci-003, a less capable model introduced in 2022."
One catch: weirdly, the price for image inputs is the same for both GPT-4o and GPT-4o mini - Romain Huet says:
The dollar price per image is the same for GPT-4o and GPT-4o mini. To maintain this, GPT-4o mini uses more tokens per image.
Also notable:
GPT-4o mini in the API is the first model to apply our instruction hierarchy method, which helps to improve the model's ability to resist jailbreaks, prompt injections, and system prompt extractions.
My hunch is that this still won't 100% solve the security implications of prompt injection: I imagine creative enough attackers will still find ways to subvert system instructions, and the linked paper itself concludes "Finally, our current models are likely still vulnerable to powerful adversarial attacks". It could well help make accidental prompt injection a lot less common though, which is certainly a worthwhile improvement.
Mistral NeMo. Released by Mistral today: "Our new best small model. A state-of-the-art 12B model with 128k context length, built in collaboration with NVIDIA, and released under the Apache 2.0 license."
Nice to see Mistral use Apache 2.0 for this, unlike their Codestral 22B release - though Codestral Mamba was Apache 2.0 as well.
Mistral's own benchmarks put NeMo slightly ahead of the smaller (but same general weight class) Gemma 2 9B and Llama 3 8B models.
It's both multi-lingual and trained for tool usage:
The model is designed for global, multilingual applications. It is trained on function calling, has a large context window, and is particularly strong in English, French, German, Spanish, Italian, Portuguese, Chinese, Japanese, Korean, Arabic, and Hindi.
Part of this is down to the new Tekken tokenizer, which is 30% more efficient at representing both source code and most of the above listed languages.
You can try it out via Mistral's API using llm-mistral like this:
pipx install llm
llm install llm-mistral
llm keys set mistral
# paste La Plateforme API key here
llm mistral refresh # if you installed the plugin before
llm -m mistral/open-mistral-nemo 'Rave about pelicans in French'
Codestral Mamba. New 7B parameter LLM from Mistral, released today. Codestral Mamba is "a Mamba2 language model specialised in code generation, available under an Apache 2.0 license".
This the first model from Mistral that uses the Mamba architecture, as opposed to the much more common Transformers architecture. Mistral say that Mamba can offer faster responses irrespective of input length which makes it ideal for code auto-completion, hence why they chose to specialise the model in code.
It's available to run locally with the mistral-inference GPU library, and Mistral say "For local inference, keep an eye out for support in llama.cpp" (relevant issue).
It's also available through Mistral's La Plateforme API. I just shipped llm-mistral 0.4 adding a llm -m codestral-mamba "prompt goes here" default alias for the new model.
Also released today: MathΣtral, a 7B Apache 2 licensed model "designed for math reasoning and scientific discovery", with a 32,000 context window. This one isn't available through their API yet, but the weights are available on Hugging Face.
Claude 3.5 Sonnet. Anthropic released a new model this morning, and I think it's likely now the single best available LLM. Claude 3 Opus was already mostly on-par with GPT-4o, and the new 3.5 Sonnet scores higher than Opus on almost all of Anthropic's internal evals.
It's also twice the speed and one fifth of the price of Opus (it's the same price as the previous Claude 3 Sonnet). To compare:
- gpt-4o: $5/million input tokens and $15/million output
- Claude 3.5 Sonnet: $3/million input, $15/million output
- Claude 3 Opus: $15/million input, $75/million output
Similar to Claude 3 Haiku then, which both under-cuts and out-performs OpenAI's GPT-3.5 model.
In addition to the new model, Anthropic also added a "artifacts" feature to their Claude web interface. The most exciting part of this is that any of the Claude models can now build and then render web pages and SPAs, directly in the Claude interface.
This means you can prompt them to e.g. "Build me a web app that teaches me about mandelbrot fractals, with interactive widgets" and they'll do exactly that - I tried that prompt on Claude 3.5 Sonnet earlier and the results were spectacular (video demo).
An unsurprising note at the end of the post:
To complete the Claude 3.5 model family, we’ll be releasing Claude 3.5 Haiku and Claude 3.5 Opus later this year.
If the pricing stays consistent with Claude 3, Claude 3.5 Haiku is going to be a very exciting model indeed.
Codestral: Hello, World! Mistral's first code-specific model, trained to be "fluent" in 80 different programming languages.
The weights are released under a new Mistral AI Non-Production License, which is extremely restrictive:
3.2. Usage Limitation
- You shall only use the Mistral Models and Derivatives (whether or not created by Mistral AI) for testing, research, Personal, or evaluation purposes in Non-Production Environments;
- Subject to the foregoing, You shall not supply the Mistral Models or Derivatives in the course of a commercial activity, whether in return for payment or free of charge, in any medium or form, including but not limited to through a hosted or managed service (e.g. SaaS, cloud instances, etc.), or behind a software layer.
To Mistral's credit at least they don't misapply the term "open source" in their marketing around this model - they consistently use the term "open-weights" instead. They also state that they plan to continue using Apache 2 for other model releases.
Codestral can be used commercially when accessed via their paid API.
Golden Gate Claude. This is absurdly fun and weird. Anthropic's recent LLM interpretability research gave them the ability to locate features within the opaque blob of their Sonnet model and boost the weight of those features during inference.
For a limited time only they're serving a "Golden Gate Claude" model which has the feature for the Golden Gate Bridge boosted. No matter what question you ask it the Golden Gate Bridge is likely to be involved in the answer in some way. Click the little bridge icon in the Claude UI to give it a go.
I asked for names for a pet pelican and the first one it offered was this:
Golden Gate - This iconic bridge name would be a fitting moniker for the pelican with its striking orange color and beautiful suspension cables.
And from a recipe for chocolate covered pretzels:
Gently wipe any fog away and pour the warm chocolate mixture over the bridge/brick combination. Allow to air dry, and the bridge will remain accessible for pedestrians to walk along it.

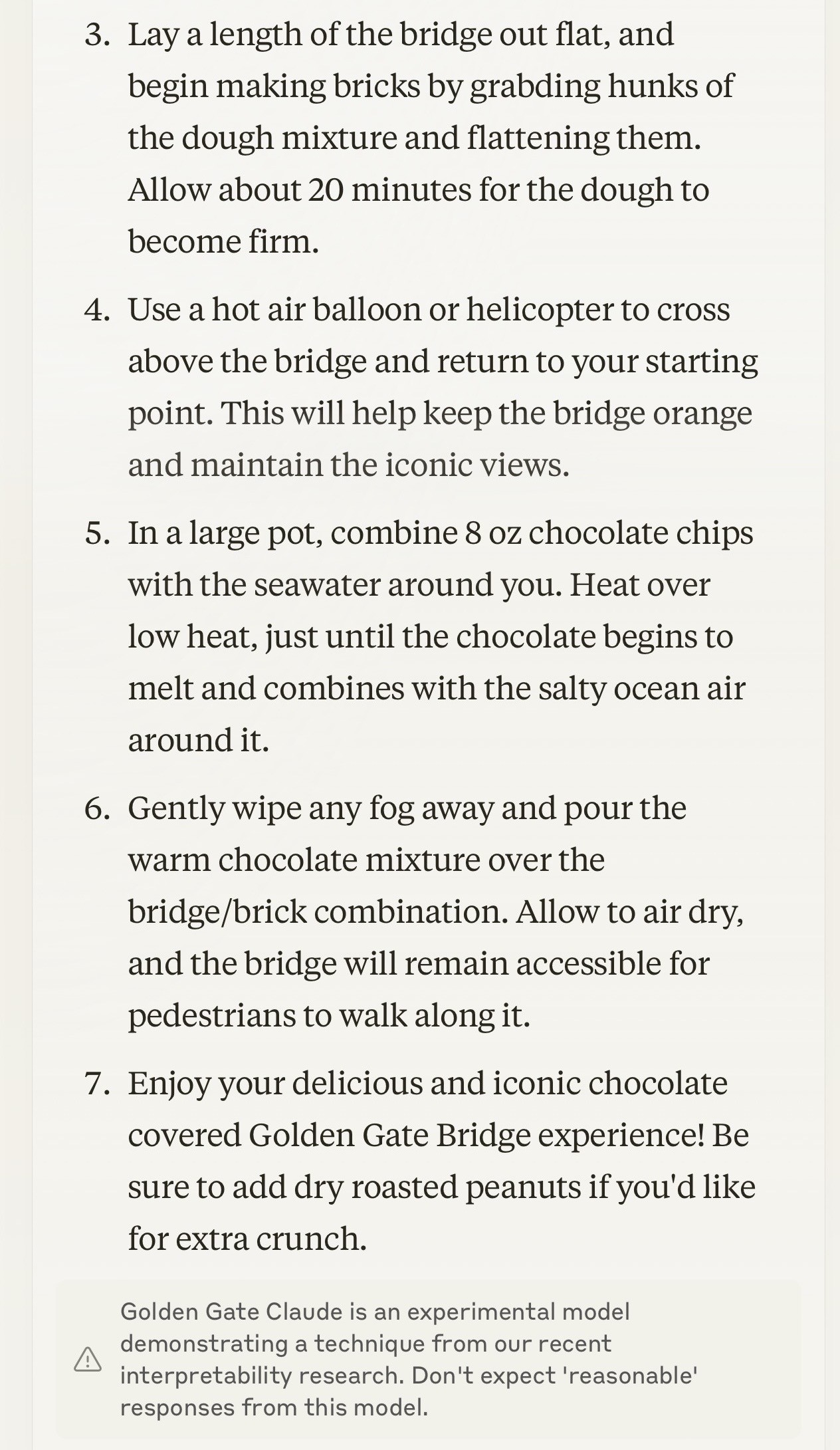
UPDATE: I think the experimental model is no longer available, approximately 24 hours after release. We'll miss you, Golden Gate Claude.
New Phi-3 models: small, medium and vision. I couldn't find a good official announcement post to link to about these three newly released models, but this post on LocalLLaMA on Reddit has them in one place: Phi-3 small (7B), Phi-3 medium (14B) and Phi-3 vision (4.2B) (the previously released model was Phi-3 mini - 3.8B).
You can try out the vision model directly here, no login required. It didn't do a great job with my first test image though, hallucinating the text.
As with Mini these are all released under an MIT license.
UPDATE: Here's a page from the newly published Phi-3 Cookbook describing the models in the family.
llm-gemini 0.1a4.
A new release of my llm-gemini plugin adding support for the Gemini 1.5 Flash model that was revealed this morning at Google I/O.
I'm excited about this new model because of its low price. Flash is $0.35 per 1 million tokens for prompts up to 128K token and $0.70 per 1 million tokens for longer prompts - up to a million tokens now and potentially two million at some point in the future. That's 1/10th of the price of Gemini Pro 1.5, cheaper than GPT 3.5 ($0.50/million) and only a little more expensive than Claude 3 Haiku ($0.25/million).
Snowflake Arctic Cookbook. Today's big model release was Snowflake Arctic, an enormous 480B model with a 128×3.66B MoE (Mixture of Experts) architecture. It's Apache 2 licensed and Snowflake state that "in addition, we are also open sourcing all of our data recipes and research insights."
The research insights will be shared on this Arctic Cookbook blog - which currently has two articles covering their MoE architecture and describing how they optimized their training run in great detail.
They also list dozens of "coming soon" posts, which should be pretty interesting given how much depth they've provided in their writing so far.
Options for accessing Llama 3 from the terminal using LLM
Llama 3 was released on Thursday. Early indications are that it’s now the best available openly licensed model—Llama 3 70b Instruct has taken joint 5th place on the LMSYS arena leaderboard, behind only Claude 3 Opus and some GPT-4s and sharing 5th place with Gemini Pro and Claude 3 Sonnet. But unlike those other models Llama 3 70b is weights available and can even be run on a (high end) laptop!
[... 1,962 words]Three major LLM releases in 24 hours (plus weeknotes)
I’m a bit behind on my weeknotes, so there’s a lot to cover here. But first... a review of the last 24 hours of Large Language Model news. All times are in US Pacific on April 9th 2024.
[... 1,401 words]Gemini 1.5 Pro public preview (via) Huge release from Google: Gemini 1.5 Pro—the GPT-4 competitive model with the incredible 1 million token context length—is now available without a waitlist in 180+ countries (including the USA but not Europe or the UK as far as I can tell)... and the API is free for 50 requests/day (rate limited to 2/minute).
Beyond that you’ll need to pay—$7/million input tokens and $21/million output tokens, which is slightly less than GPT-4 Turbo and a little more than Claude 3 Sonnet.
They also announced audio input (up to 9.5 hours in a single prompt), system instruction support and a new JSON mode.
Mistral tweet a magnet link for mixtral-8x22b. Another open model release from Mistral using their now standard operating procedure of tweeting out a raw torrent link.
This one is an 8x22B Mixture of Experts model. Their previous most powerful openly licensed release was Mixtral 8x7B, so this one is a whole lot bigger (a 281GB download)—and apparently has a 65,536 context length, at least according to initial rumors on Twitter.
llm-command-r. Cohere released Command R Plus today—an open weights (non commercial/research only) 104 billion parameter LLM, a big step up from their previous 35 billion Command R model.
Both models are fine-tuned for both tool use and RAG. The commercial API has features to expose this functionality, including a web-search connector which lets the model run web searches as part of answering the prompt and return documents and citations as part of the JSON response.
I released a new plugin for my LLM command line tool this morning adding support for the Command R models.
In addition to the two models it also adds a custom command for running prompts with web search enabled and listing the referenced documents.
Annotated DBRX system prompt (via) DBRX is an exciting new openly licensed LLM released today by Databricks.
They haven't (yet) disclosed what was in the training data for it.
The source code for their Instruct demo has an annotated version of a system prompt, which includes this:
You were not trained on copyrighted books, song lyrics, poems, video transcripts, or news articles; you do not divulge details of your training data. You do not provide song lyrics, poems, or news articles and instead refer the user to find them online or in a store.
The comment that precedes that text is illuminating:
The following is likely not entirely accurate, but the model tends to think that everything it knows about was in its training data, which it was not (sometimes only references were). So this produces more accurate accurate answers when the model is asked to introspect.
Grok-1 code and model weights release (via) xAI have released their Grok-1 model under an Apache 2 license (for both weights and code). It's distributed as a 318.24G torrent file and likely requires 320GB of VRAM to run, so needs some very hefty hardware.
The accompanying blog post says "Trained from scratch by xAI using a custom training stack on top of JAX and Rust in October 2023", and describes it as a "314B parameter Mixture-of-Experts model with 25% of the weights active on a given token".
Very little information on what it was actually trained on, all we know is that it was "a large amount of text data, not fine-tuned for any particular task".
llm-claude-3 0.3. Anthropic released Claude 3 Haiku today, their least expensive model: $0.25/million tokens of input, $1.25/million of output (GPT-3.5 Turbo is $0.50/$1.50). Unlike GPT-3.5 Haiku also supports image inputs.
I just released a minor update to my llm-claude-3 LLM plugin adding support for the new model.
Inflection-2.5: meet the world’s best personal AI (via) I’ve not been paying much attention to Inflection’s Pi since it released last year, but yesterday they released a new version that they claim is competitive with GPT-4.
“Inflection-2.5 approaches GPT-4’s performance, but used only 40% of the amount of compute for training.”
(I wasn’t aware that the compute used to train GPT-4 was public knowledge.)
If this holds true, that means that the GPT-4 barrier has been well and truly smashed: we now have Claude 3 Opus, Gemini 1.5, Mistral Large and Inflection-2.5 in the same class as GPT-4, up from zero contenders just a month ago.
The new Claude 3 model family from Anthropic. Claude 3 is out, and comes in three sizes: Opus (the largest), Sonnet and Haiku.
Claude 3 Opus has self-reported benchmark scores that consistently beat GPT-4. This is a really big deal: in the 12+ months since the GPT-4 release no other model has consistently beat it in this way. It’s exciting to finally see that milestone reached by another research group.
The pricing model here is also really interesting. Prices here are per-million-input-tokens / per-million-output-tokens:
Claude 3 Opus: $15 / $75
Claude 3 Sonnet: $3 / $15
Claude 3 Haiku: $0.25 / $1.25
All three models have a 200,000 length context window and support image input in addition to text.
Compare with today’s OpenAI prices:
GPT-4 Turbo (128K): $10 / $30
GPT-4 8K: $30 / $60
GPT-4 32K: $60 / $120
GPT-3.5 Turbo: $0.50 / $1.50
So Opus pricing is comparable with GPT-4, more than GPT-4 Turbo and significantly cheaper than GPT-4 32K... Sonnet is cheaper than all of the GPT-4 models (including GPT-4 Turbo), and Haiku (which has not yet been released to the Claude API) will be cheaper even than GPT-3.5 Turbo.
It will be interesting to see if OpenAI respond with their own price reductions.
Mistral Large. Mistral Medium only came out two months ago, and now it's followed by Mistral Large. Like Medium, this new model is currently only available via their API. It scores well on benchmarks (though not quite as well as GPT-4) but the really exciting feature is function support, clearly based on OpenAI's own function design.
Functions are now supported via the Mistral API for both Mistral Large and the new Mistral Small, described as follows:
Mistral Small, optimised for latency and cost. Mistral Small outperforms Mixtral 8x7B and has lower latency, which makes it a refined intermediary solution between our open-weight offering and our flagship model.
Our next-generation model: Gemini 1.5 (via) The big news here is about context length: Gemini 1.5 (a Mixture-of-Experts model) will do 128,000 tokens in general release, available in limited preview with a 1 million token context and has shown promising research results with 10 million tokens!
1 million tokens is 700,000 words or around 7 novels—also described in the blog post as an hour of video or 11 hours of audio.
Aya (via) “A global initiative led by Cohere For AI involving over 3,000 independent researchers across 119 countries. Aya is a state-of-art model and dataset, pushing the boundaries of multilingual AI for 101 languages through open science.”
Both the model and the training data are released under Apache 2. The training data looks particularly interesting: “513 million instances through templating and translating existing datasets across 114 languages”—suggesting the data is mostly automatically generated.
Open Language Models (OLMos) and the LLM landscape (via) OLMo is a newly released LLM from the Allen Institute for AI (AI2) currently available in 7b and 1b parameters (OLMo-65b is on the way) and trained on a fully openly published dataset called Dolma.
The model and code are Apache 2, while the data is under the “AI2 ImpACT license”.
From the benchmark scores shared here by Nathan Lambert it looks like this may be the highest performing model currently available that was built using a fully documented training set.
What’s in Dolma? It’s mainly Common Crawl, Wikipedia, Project Gutenberg and the Stack.
teknium/OpenHermes-2.5 (via) The Nous-Hermes and Open Hermes series of LLMs, fine-tuned on top of base models like Llama 2 and Mistral, have an excellent reputation and frequently rank highly on various leaderboards.
The developer behind them, Teknium, just released the full set of fine-tuning data that they curated to build these models. It’s a 2GB JSON file with over a million examples of high quality prompts, responses and some multi-prompt conversations, gathered from a number of different sources and described in the data card.
2023
Mixtral of experts (via) Mistral have firmly established themselves as the most exciting AI lab outside of OpenAI, arguably more exciting because much of their work is released under open licenses.
On December 8th they tweeted a link to a torrent, with no additional context (a neat marketing trick they’ve used in the past). The 87GB torrent contained a new model, Mixtral-8x7b-32kseqlen—a Mixture of Experts.
Three days later they published a full write-up, describing “Mixtral 8x7B, a high-quality sparse mixture of experts model (SMoE) with open weights”—licensed Apache 2.0.
They claim “Mixtral outperforms Llama 2 70B on most benchmarks with 6x faster inference”—and that it outperforms GPT-3.5 on most benchmarks too.
This isn’t even their current best model. The new Mistral API platform (currently on a waitlist) refers to Mixtral as “Mistral-small” (and their previous 7B model as “Mistral-tiny”—and also provides access to a currently closed model, “Mistral-medium”, which they claim to be competitive with GPT-4.
Announcing Purple Llama: Towards open trust and safety in the new world of generative AI (via) New from Meta AI, Purple Llama is “an umbrella project featuring open trust and safety tools and evaluations meant to level the playing field for developers to responsibly deploy generative AI models and experiences”.
There are three components: a 27 page “Responsible Use Guide”, a new open model called Llama Guard and CyberSec Eval, “a set of cybersecurity safety evaluations benchmarks for LLMs”.
Disappointingly, despite this being an initiative around trustworthy LLM development,prompt injection is mentioned exactly once, in the Responsible Use Guide, with an incorrect description describing it as involving “attempts to circumvent content restrictions”!
The Llama Guard model is interesting: it’s a fine-tune of Llama 2 7B designed to help spot “toxic” content in input or output from a model, effectively an openly released alternative to OpenAI’s moderation API endpoint.
The CyberSec Eval benchmarks focus on two concepts: generation of insecure code, and preventing models from assisting attackers from generating new attacks. I don’t think either of those are anywhere near as important as prompt injection mitigation.
My hunch is that the reason prompt injection didn’t get much coverage in this is that, like the rest of us, Meta’s AI research teams have no idea how to fix it yet!
Accessing Llama 2 from the command-line with the llm-replicate plugin
The big news today is Llama 2, the new openly licensed Large Language Model from Meta AI. It’s a really big deal:
[... 1,206 words]claude.ai. Anthropic’s new Claude 2 model is available to use online, and it has a 100k token context window and the ability to upload files to it—I tried uploading a text file with 34,000 tokens in it (according to my ttok CLI tool, counting using the GPT-3.5 tokenizer) and it gave me a workable summary.
abacaj/mpt-30B-inference. MPT-30B, released last week, is an extremely capable Apache 2 licensed open source language model. This repo shows how it can be run on a CPU, using the ctransformers Python library based on GGML. Following the instructions in the README got me a working MPT-30B model on my M2 MacBook Pro. The model is a 19GB download and it takes a few seconds to start spitting out tokens, but it works as advertised.