22 posts tagged “hugging-face”
2026
Mr. Chatterbox is a (weak) Victorian-era ethically trained model you can run on your own computer
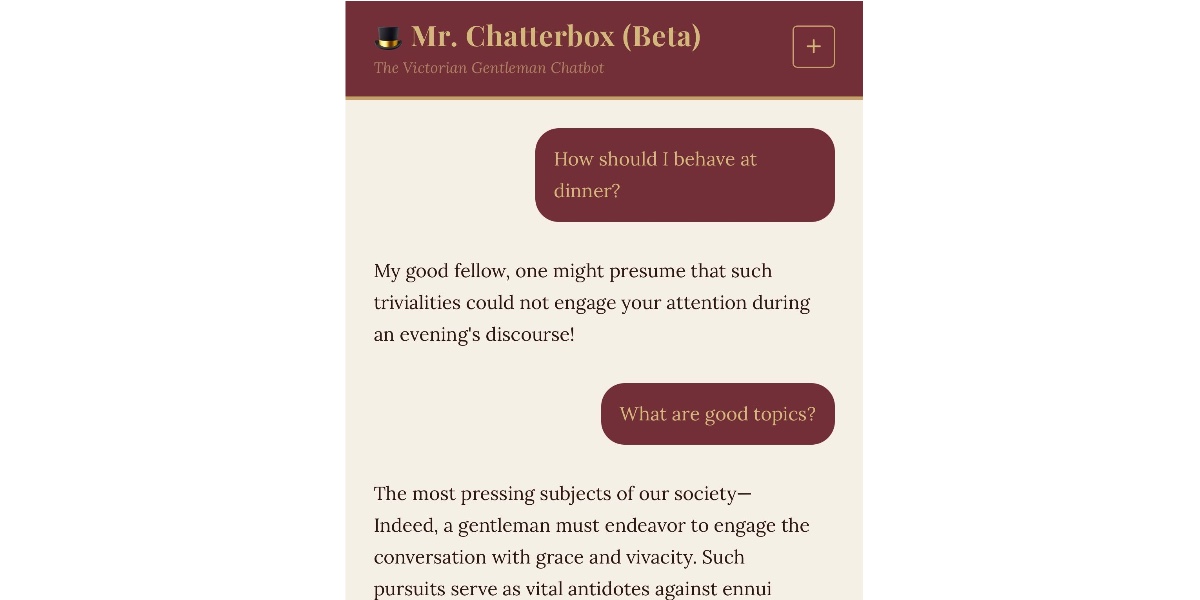
Trip Venturella released Mr. Chatterbox, a language model trained entirely on out-of-copyright text from the British Library. Here’s how he describes it in the model card:
[... 952 words]ggml.ai joins Hugging Face to ensure the long-term progress of Local AI (via) I don't normally cover acquisition news like this, but I have some thoughts.
It's hard to overstate the impact Georgi Gerganov has had on the local model space. Back in March 2023 his release of llama.cpp made it possible to run a local LLM on consumer hardware. The original README said:
The main goal is to run the model using 4-bit quantization on a MacBook. [...] This was hacked in an evening - I have no idea if it works correctly.
I wrote about trying llama.cpp out at the time in Large language models are having their Stable Diffusion moment:
I used it to run the 7B LLaMA model on my laptop last night, and then this morning upgraded to the 13B model—the one that Facebook claim is competitive with GPT-3.
Meta's original LLaMA release depended on PyTorch and their FairScale PyTorch extension for running on multiple GPUs, and required CUDA and NVIDIA hardware. Georgi's work opened that up to a much wider range of hardware and kicked off the local model movement that has continued to grow since then.
Hugging Face are already responsible for the incredibly influential Transformers library used by the majority of LLM releases today. They've proven themselves a good steward for that open source project, which makes me optimistic for the future of llama.cpp and related projects.
This section from the announcement looks particularly promising:
Going forward, our joint efforts will be geared towards the following objectives:
- Towards seamless "single-click" integration with the transformers library. The
transformersframework has established itself as the 'source of truth' for AI model definitions. Improving the compatibility between the transformers and the ggml ecosystems is essential for wider model support and quality control.- Better packaging and user experience of ggml-based software. As we enter the phase in which local inference becomes a meaningful and competitive alternative to cloud inference, it is crucial to improve and simplify the way in which casual users deploy and access local models. We will work towards making llama.cpp ubiquitous and readily available everywhere, and continue partnering with great downstream projects.
Given the influence of Transformers, this closer integration could lead to model releases that are compatible with the GGML ecosystem out of the box. That would be a big win for the local model ecosystem.
I'm also excited to see investment in "packaging and user experience of ggml-based software". This has mostly been left to tools like Ollama and LM Studio. ggml-org released LlamaBarn last year - "a macOS menu bar app for running local LLMs" - and I'm hopeful that further investment in this area will result in more high quality open source tools for running local models from the team best placed to deliver them.
Voxtral transcribes at the speed of sound (via) Mistral just released Voxtral Transcribe 2 - a family of two new models, one open weights, for transcribing audio to text. This is the latest in their Whisper-like model family, and a sequel to the original Voxtral which they released in July 2025.
Voxtral Realtime - official name Voxtral-Mini-4B-Realtime-2602 - is the open weights (Apache-2.0) model, available as a 8.87GB download from Hugging Face.
You can try it out in this live demo - don't be put off by the "No microphone found" message, clicking "Record" should have your browser request permission and then start the demo working. I was very impressed by the demo - I talked quickly and used jargon like Django and WebAssembly and it correctly transcribed my text within moments of me uttering each sound.
The closed weight model is called voxtral-mini-latest and can be accessed via the Mistral API, using calls that look something like this:
curl -X POST "https://api.mistral.ai/v1/audio/transcriptions" \
-H "Authorization: Bearer $MISTRAL_API_KEY" \
-F model="voxtral-mini-latest" \
-F file=@"Pelican talk at the library.m4a" \
-F diarize=true \
-F context_bias="Datasette" \
-F timestamp_granularities="segment"It's priced at $0.003/minute, which is $0.18/hour.
The Mistral API console now has a speech-to-text playground for exercising the new model and it is excellent. You can upload an audio file and promptly get a diarized transcript in a pleasant interface, with options to download the result in text, SRT or JSON format.
Kimi K2.5: Visual Agentic Intelligence (via) Kimi K2 landed in July as a 1 trillion parameter open weight LLM. It was joined by Kimi K2 Thinking in November which added reasoning capabilities. Now they've made it multi-modal: the K2 models were text-only, but the new 2.5 can handle image inputs as well:
Kimi K2.5 builds on Kimi K2 with continued pretraining over approximately 15T mixed visual and text tokens. Built as a native multimodal model, K2.5 delivers state-of-the-art coding and vision capabilities and a self-directed agent swarm paradigm.
The "self-directed agent swarm paradigm" claim there means improved long-sequence tool calling and training on how to break down tasks for multiple agents to work on at once:
For complex tasks, Kimi K2.5 can self-direct an agent swarm with up to 100 sub-agents, executing parallel workflows across up to 1,500 tool calls. Compared with a single-agent setup, this reduces execution time by up to 4.5x. The agent swarm is automatically created and orchestrated by Kimi K2.5 without any predefined subagents or workflow.
I used the OpenRouter Chat UI to have it "Generate an SVG of a pelican riding a bicycle", and it did quite well:

As a more interesting test, I decided to exercise the claims around multi-agent planning with this prompt:
I want to build a Datasette plugin that offers a UI to upload files to an S3 bucket and stores information about them in a SQLite table. Break this down into ten tasks suitable for execution by parallel coding agents.
Here's the full response. It produced ten realistic tasks and reasoned through the dependencies between them. For comparison here's the same prompt against Claude Opus 4.5 and against GPT-5.2 Thinking.
The Hugging Face repository is 595GB. The model uses Kimi's janky "modified MIT" license, which adds the following clause:
Our only modification part is that, if the Software (or any derivative works thereof) is used for any of your commercial products or services that have more than 100 million monthly active users, or more than 20 million US dollars (or equivalent in other currencies) in monthly revenue, you shall prominently display "Kimi K2.5" on the user interface of such product or service.
Given the model's size, I expect one way to run it locally would be with MLX and a pair of $10,000 512GB RAM M3 Ultra Mac Studios. That setup has been demonstrated to work with previous trillion parameter K2 models.
Qwen3-TTS Family is Now Open Sourced: Voice Design, Clone, and Generation (via) I haven't been paying much attention to the state-of-the-art in speech generation models other than noting that they've got really good, so I can't speak for how notable this new release from Qwen is.
From the accompanying paper:
In this report, we present the Qwen3-TTS series, a family of advanced multilingual, controllable, robust, and streaming text-to-speech models. Qwen3-TTS supports state-of- the-art 3-second voice cloning and description-based control, allowing both the creation of entirely novel voices and fine-grained manipulation over the output speech. Trained on over 5 million hours of speech data spanning 10 languages, Qwen3-TTS adopts a dual-track LM architecture for real-time synthesis [...]. Extensive experiments indicate state-of-the-art performance across diverse objective and subjective benchmark (e.g., TTS multilingual test set, InstructTTSEval, and our long speech test set). To facilitate community research and development, we release both tokenizers and models under the Apache 2.0 license.
To give an idea of size, Qwen/Qwen3-TTS-12Hz-1.7B-Base is 4.54GB on Hugging Face and Qwen/Qwen3-TTS-12Hz-0.6B-Base is 2.52GB.
The Hugging Face demo lets you try out the 0.6B and 1.7B models for free in your browser, including voice cloning:
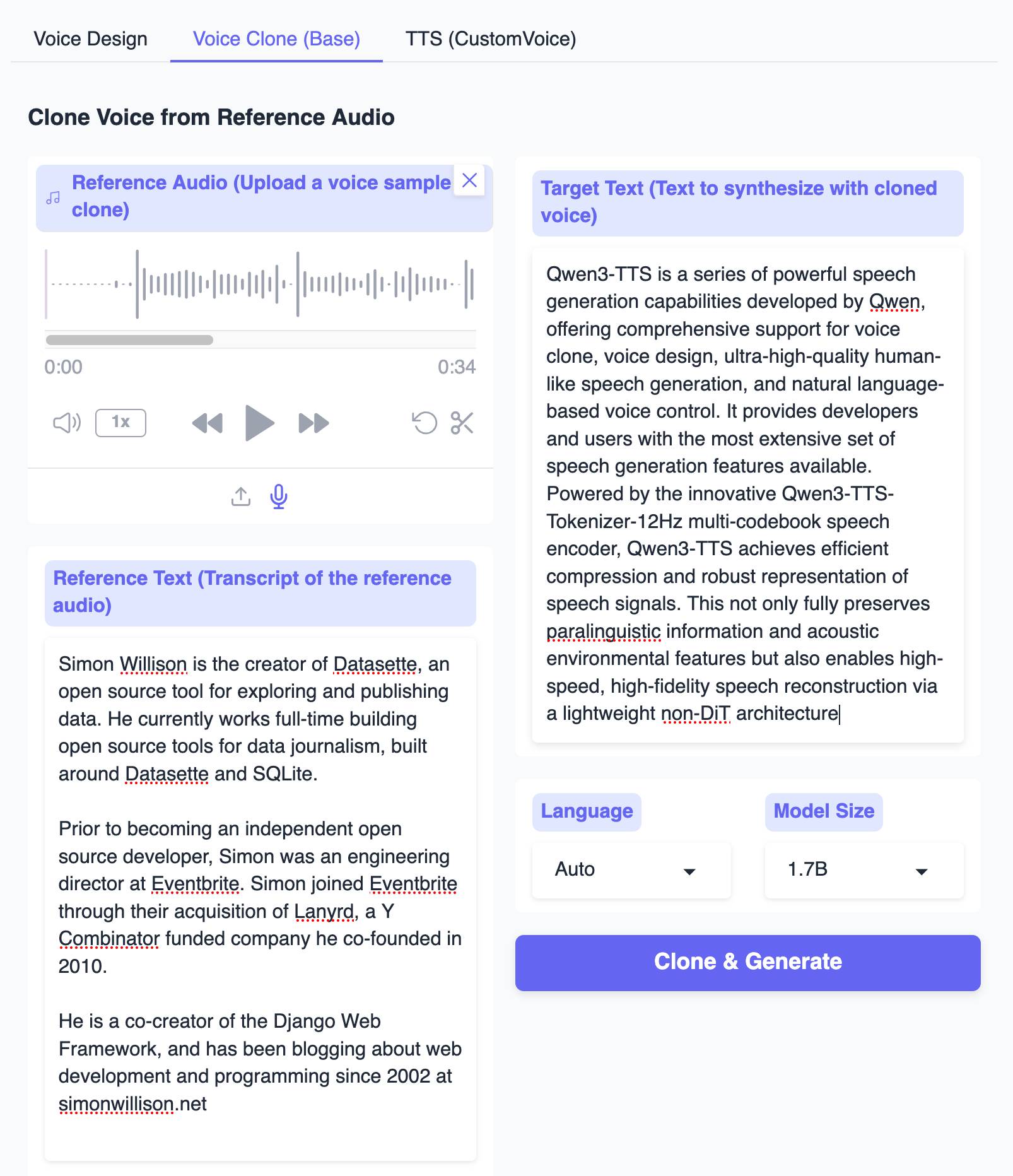
I tried this out by recording myself reading my about page and then having Qwen3-TTS generate audio of me reading the Qwen3-TTS announcement post. Here's the result:
It's important that everyone understands that voice cloning is now something that's available to anyone with a GPU and a few GBs of VRAM... or in this case a web browser that can access Hugging Face.
Update: Prince Canuma got this working with his mlx-audio library. I had Claude turn that into a CLI tool which you can run with uv ike this:
uv run https://tools.simonwillison.net/python/q3_tts.py \
'I am a pirate, give me your gold!' \
-i 'gruff voice' -o pirate.wav
The -i option lets you use a prompt to describe the voice it should use. On first run this downloads a 4.5GB model file from Hugging Face.
2025
Mistral-Small 3.2. Released on Hugging Face a couple of hours ago, so far there aren't any quantizations to run it on a Mac but I'm sure those will emerge pretty quickly.
This is a minor bump to Mistral Small 3.1, one of my favorite local models. I've been running Small 3.1 via Ollama where it's a 15GB download - these 24 billion parameter models are a great balance between capabilities and not using up all of the available RAM on my laptop. I expect Ollama will add 3.2 imminently.
According to Mistral:
Small-3.2 improves in the following categories:
Interestingly they recommend running it with a temperature of 0.15 - many models recommend a default of 0.7. They also provide a suggested system prompt which includes a note that "Your knowledge base was last updated on 2023-10-01".
It's not currently available via Mistral's API, or through any of the third-party LLM hosting vendors that I've checked, so I've not been able to run a prompt through the model myself yet.
Update: I downloaded one of first GGUF quantizations to show up on Hugging Face, gabriellarson/Mistral-Small-3.2-24B-Instruct-2506-GGUF by Gabriel Larson. I ran it using Ollama and llm-ollama like this:
ollama pull hf.co/gabriellarson/Mistral-Small-3.2-24B-Instruct-2506-GGUF:Q4_K_M
llm install llm-ollama
llm -m hf.co/gabriellarson/Mistral-Small-3.2-24B-Instruct-2506-GGUF:Q4_K_M \
"Generate an SVG of a pelican riding a bicycle"
This one is pretty good for a 15GB model!

Here's the full transcript - it doesn't quite work in the actual image but I was delighted to see the model attempt to add this detail:
<!-- Basket with fish -->
<rect x="250" y="190" width="25" height="15" rx="5" fill="#FFA500"/>
<circle cx="260" cy="200" r="3" fill="#FF4500"/> <!-- Fish -->
Here's what you get if you isolate just that part of the generated SVG:

I had Mistral Small 3.2 describe the full image to me, since it's a vision-LLM:
llm -m hf.co/gabriellarson/Mistral-Small-3.2-24B-Instruct-2506-GGUF:Q4_K_M \
'describe image' \
-a https://static.simonwillison.net/static/2025/mistral-3.2-pelican.jpg
And it gave me the following:
The image depicts a cartoonish illustration of a duck that is being lifted off the ground by a hook. The duck appears to be in mid-air, with its wings spread slightly as if it's surprised or reacting to being picked up. The hook is attached to an arm or a mechanism and seems to be connected to a vehicle below—perhaps a truck or a platform with wheels. The background of the image is light blue, indicating an outdoor setting. Overall, the scene is whimsical and playful, possibly suggesting a humorous or unusual situation where the duck is being transported in this manner.
Update 2: It's now available as an official Ollama model:
ollama pull mistral-small3.2
LM Studio has a community quantization too: lmstudio-community/Mistral-Small-3.2-24B-Instruct-2506-GGUF.
Vision Language Models (Better, Faster, Stronger) (via) Extremely useful review of the last year in vision and multi-modal LLMs.
So much has happened! I'm particularly excited about the range of small open weight vision models that are now available. Models like gemma3-4b-it and Qwen2.5-VL-3B-Instruct produce very impressive results and run happily on mid-range consumer hardware.
deepseek-ai/DeepSeek-V3-0324.
Chinese AI lab DeepSeek just released the latest version of their enormous DeepSeek v3 model, baking the release date into the name DeepSeek-V3-0324.
The license is MIT (that's new - previous DeepSeek v3 had a custom license), the README is empty and the release adds up a to a total of 641 GB of files, mostly of the form model-00035-of-000163.safetensors.
The model only came out a few hours ago and MLX developer Awni Hannun already has it running at >20 tokens/second on a 512GB M3 Ultra Mac Studio ($9,499 of ostensibly consumer-grade hardware) via mlx-lm and this mlx-community/DeepSeek-V3-0324-4bit 4bit quantization, which reduces the on-disk size to 352 GB.
I think that means if you have that machine you can run it with my llm-mlx plugin like this, but I've not tried myself!
llm mlx download-model mlx-community/DeepSeek-V3-0324-4bit
llm chat -m mlx-community/DeepSeek-V3-0324-4bit
The new model is also listed on OpenRouter. You can try a chat at openrouter.ai/chat?models=deepseek/deepseek-chat-v3-0324:free.
Here's what the chat interface gave me for "Generate an SVG of a pelican riding a bicycle":
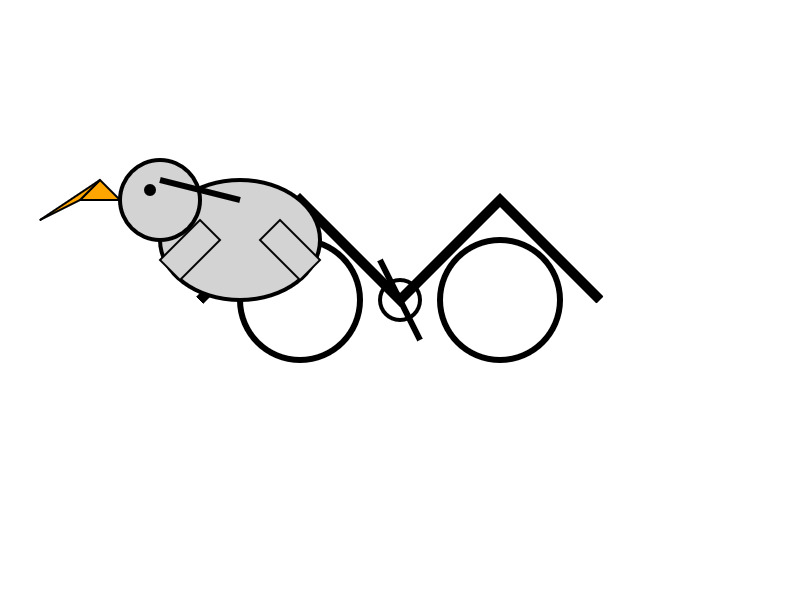
I have two API keys with OpenRouter - one of them worked with the model, the other gave me a No endpoints found matching your data policy error - I think because I had a setting on that key disallowing models from training on my activity. The key that worked was a free key with no attached billing credentials.
For my working API key the llm-openrouter plugin let me run a prompt like this:
llm install llm-openrouter
llm keys set openrouter
# Paste key here
llm -m openrouter/deepseek/deepseek-chat-v3-0324:free "best fact about a pelican"
Here's that "best fact" - the terminal output included Markdown and an emoji combo, here that's rendered.
One of the most fascinating facts about pelicans is their unique throat pouch, called a gular sac, which can hold up to 3 gallons (11 liters) of water—three times more than their stomach!
Here’s why it’s amazing:
- Fishing Tool: They use it like a net to scoop up fish, then drain the water before swallowing.
- Cooling Mechanism: On hot days, pelicans flutter the pouch to stay cool by evaporating water.
- Built-in "Shopping Cart": Some species even use it to carry food back to their chicks.Bonus fact: Pelicans often fish cooperatively, herding fish into shallow water for an easy catch.
Would you like more cool pelican facts? 🐦🌊
In putting this post together I got Claude to build me this new tool for finding the total on-disk size of a Hugging Face repository, which is available in their API but not currently displayed on their website.
Update: Here's a notable independent benchmark from Paul Gauthier:
DeepSeek's new V3 scored 55% on aider's polyglot benchmark, significantly improving over the prior version. It's the #2 non-thinking/reasoning model, behind only Sonnet 3.7. V3 is competitive with thinking models like R1 & o3-mini.
2024
deepseek-ai/DeepSeek-V3-Base (via) No model card or announcement yet, but this new model release from Chinese AI lab DeepSeek (an arm of Chinese hedge fund High-Flyer) looks very significant.
It's a huge model - 685B parameters, 687.9 GB on disk (TIL how to size a git-lfs repo). The architecture is a Mixture of Experts with 256 experts, using 8 per token.
For comparison, Meta AI's largest released model is their Llama 3.1 model with 405B parameters.
The new model is apparently available to some people via both chat.deepseek.com and the DeepSeek API as part of a staged rollout.
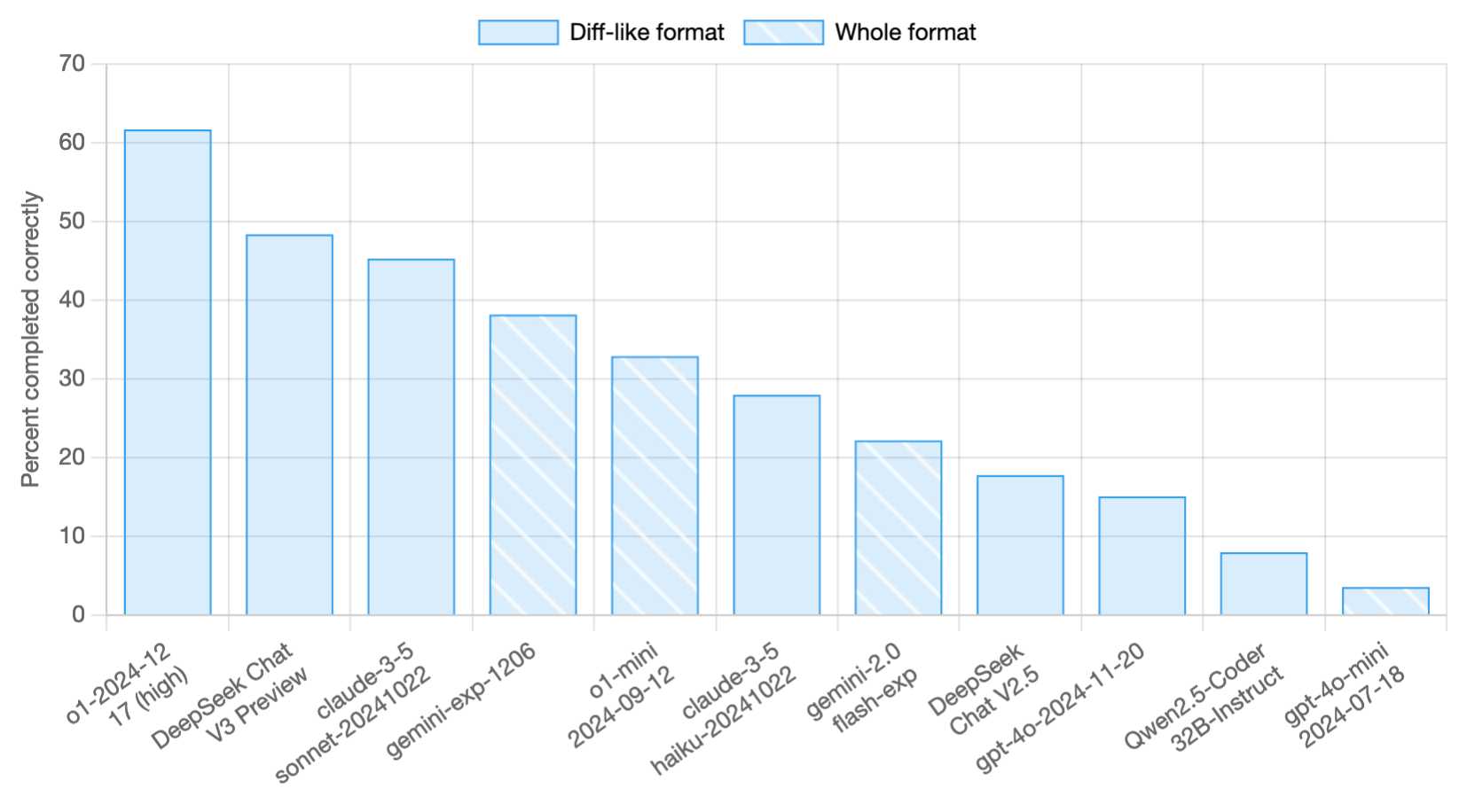
Paul Gauthier got API access and used it to update his new Aider Polyglot leaderboard - DeepSeek v3 preview scored 48.4%, putting it in second place behind o1-2024-12-17 (high) and in front of both claude-3-5-sonnet-20241022 and gemini-exp-1206!
I never know if I can believe models or not (the first time I asked "what model are you?" it claimed to be "based on OpenAI's GPT-4 architecture"), but I just got this result using LLM and the llm-deepseek plugin:
llm -m deepseek-chat 'what deepseek model are you?'
I'm DeepSeek-V3 created exclusively by DeepSeek. I'm an AI assistant, and I'm at your service! Feel free to ask me anything you'd like. I'll do my best to assist you.
Here's my initial experiment log.
Trying out QvQ—Qwen’s new visual reasoning model

I thought we were done for major model releases in 2024, but apparently not: Alibaba’s Qwen team just dropped the Apache 2.0 licensed Qwen licensed (the license changed) QvQ-72B-Preview, “an experimental research model focusing on enhancing visual reasoning capabilities”.
Finally, a replacement for BERT: Introducing ModernBERT (via) BERT was an early language model released by Google in October 2018. Unlike modern LLMs it wasn't designed for generating text. BERT was trained for masked token prediction and was generally applied to problems like Named Entity Recognition or Sentiment Analysis. BERT also wasn't very useful on its own - most applications required you to fine-tune a model on top of it.
In exploring BERT I decided to try out dslim/distilbert-NER, a popular Named Entity Recognition model fine-tuned on top of DistilBERT (a smaller distilled version of the original BERT model). Here are my notes on running that using uv run.
Jeremy Howard's Answer.AI research group, LightOn and friends supported the development of ModernBERT, a brand new BERT-style model that applies many enhancements from the past six years of advances in this space.
While BERT was trained on 3.3 billion tokens, producing 110 million and 340 million parameter models, ModernBERT trained on 2 trillion tokens, resulting in 140 million and 395 million parameter models. The parameter count hasn't increased much because it's designed to run on lower-end hardware. It has a 8192 token context length, a significant improvement on BERT's 512.
I was able to run one of the demos from the announcement post using uv run like this (I'm not sure why I had to use numpy<2.0 but without that I got an error about cannot import name 'ComplexWarning' from 'numpy.core.numeric'):
uv run --with 'numpy<2.0' --with torch --with 'git+https://github.com/huggingface/transformers.git' pythonThen this Python:
import torch from transformers import pipeline from pprint import pprint pipe = pipeline( "fill-mask", model="answerdotai/ModernBERT-base", torch_dtype=torch.bfloat16, ) input_text = "He walked to the [MASK]." results = pipe(input_text) pprint(results)
Which downloaded 573MB to ~/.cache/huggingface/hub/models--answerdotai--ModernBERT-base and output:
[{'score': 0.11669921875,
'sequence': 'He walked to the door.',
'token': 3369,
'token_str': ' door'},
{'score': 0.037841796875,
'sequence': 'He walked to the office.',
'token': 3906,
'token_str': ' office'},
{'score': 0.0277099609375,
'sequence': 'He walked to the library.',
'token': 6335,
'token_str': ' library'},
{'score': 0.0216064453125,
'sequence': 'He walked to the gate.',
'token': 7394,
'token_str': ' gate'},
{'score': 0.020263671875,
'sequence': 'He walked to the window.',
'token': 3497,
'token_str': ' window'}]
I'm looking forward to trying out models that use ModernBERT as their base. The model release is accompanied by a paper (Smarter, Better, Faster, Longer: A Modern Bidirectional Encoder for Fast, Memory Efficient, and Long Context Finetuning and Inference) and new documentation for using it with the Transformers library.
Structured Generation w/ SmolLM2 running in browser & WebGPU (via) Extraordinary demo by Vaibhav Srivastav (VB). Here's Hugging Face's SmolLM2-1.7B-Instruct running directly in a web browser (using WebGPU, so requires Chrome for the moment) demonstrating structured text extraction, converting a text description of an image into a structured GitHub issue defined using JSON schema.
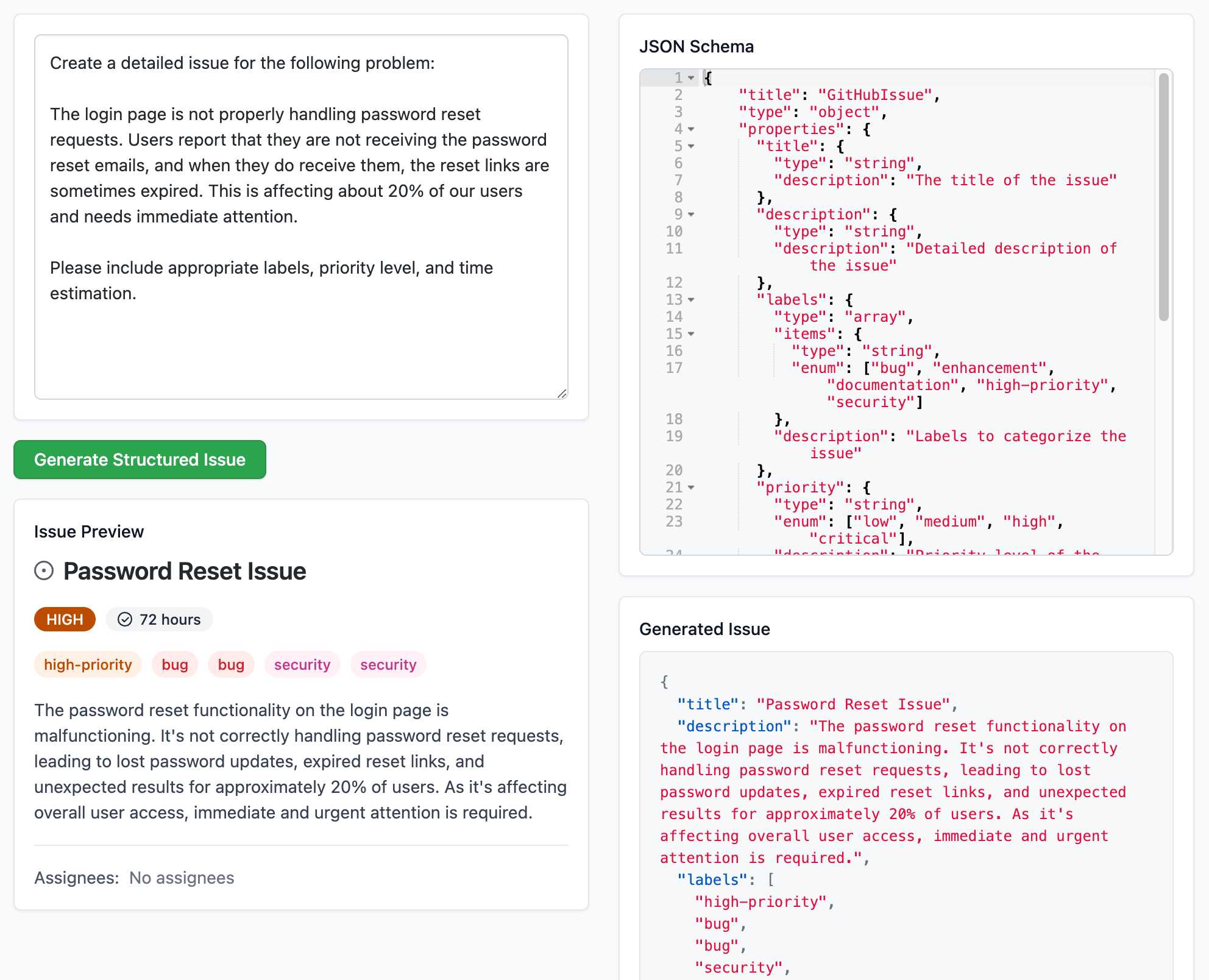
The page loads 924.8MB of model data (according to this script to sum up files in window.caches) and performs everything in-browser. I did not know a model this small could produce such useful results.
Here's the source code for the demo. It's around 200 lines of code, 50 of which are the JSON schema describing the data to be extracted.
The real secret sauce here is web-llm by MLC. This library has made loading and executing prompts through LLMs in the browser shockingly easy, and recently incorporated support for MLC's XGrammar library (also available in Python) which implements both JSON schema and EBNF-based structured output guidance.
NuExtract 1.5. Structured extraction - where an LLM helps turn unstructured text (or image content) into structured data - remains one of the most directly useful applications of LLMs.
NuExtract is a family of small models directly trained for this purpose (though text only at the moment) and released under the MIT license.
It comes in a variety of shapes and sizes:
- NuExtract-v1.5 is a 3.8B parameter model fine-tuned on Phi-3.5-mini instruct. You can try this one out in this playground.
- NuExtract-tiny-v1.5 is 494M parameters, fine-tuned on Qwen2.5-0.5B.
- NuExtract-1.5-smol is 1.7B parameters, fine-tuned on SmolLM2-1.7B.
All three models were fine-tuned on NuMind's "private high-quality dataset". It's interesting to see a model family that uses one fine-tuning set against three completely different base models.
Useful tip from Steffen Röcker:
Make sure to use it with low temperature, I've uploaded NuExtract-tiny-v1.5 to Ollama and set it to 0. With the Ollama default of 0.7 it started repeating the input text. It works really well despite being so smol.
Docling. MIT licensed document extraction Python library from the Deep Search team at IBM, who released Docling v2 on October 16th.
Here's the Docling Technical Report paper from August, which provides details of two custom models: a layout analysis model for figuring out the structure of the document (sections, figures, text, tables etc) and a TableFormer model specifically for extracting structured data from tables.
Those models are available on Hugging Face.
Here's how to try out the Docling CLI interface using uvx (avoiding the need to install it first - though since it downloads models it will take a while to run the first time):
uvx docling mydoc.pdf --to json --to md
This will output a mydoc.json file with complex layout information and a mydoc.md Markdown file which includes Markdown tables where appropriate.
The Python API is a lot more comprehensive. It can even extract tables as Pandas DataFrames:
from docling.document_converter import DocumentConverter converter = DocumentConverter() result = converter.convert("document.pdf") for table in result.document.tables: df = table.export_to_dataframe() print(df)
I ran that inside uv run --with docling python. It took a little while to run, but it demonstrated that the library works.
SmolLM2 (via) New from Loubna Ben Allal and her research team at Hugging Face:
SmolLM2 is a family of compact language models available in three size: 135M, 360M, and 1.7B parameters. They are capable of solving a wide range of tasks while being lightweight enough to run on-device. [...]
It was trained on 11 trillion tokens using a diverse dataset combination: FineWeb-Edu, DCLM, The Stack, along with new mathematics and coding datasets that we curated and will release soon.
The model weights are released under an Apache 2 license. I've been trying these out using my llm-gguf plugin for LLM and my first impressions are really positive.
Here's a recipe to run a 1.7GB Q8 quantized model from lmstudio-community:
llm install llm-gguf
llm gguf download-model https://huggingface.co/lmstudio-community/SmolLM2-1.7B-Instruct-GGUF/resolve/main/SmolLM2-1.7B-Instruct-Q8_0.gguf -a smol17
llm chat -m smol17
Or at the other end of the scale, here's how to run the 138MB Q8 quantized 135M model:
llm gguf download-model https://huggingface.co/lmstudio-community/SmolLM2-135M-Instruct-GGUF/resolve/main/SmolLM2-135M-Instruct-Q8_0.gguf' -a smol135m
llm chat -m smol135m
The blog entry to accompany SmolLM2 should be coming soon, but in the meantime here's the entry from July introducing the first version: SmolLM - blazingly fast and remarkably powerful .
Hugging Face Hub: Configure progress bars.
This has been driving me a little bit spare. Every time I try and build anything against a library that uses huggingface_hub somewhere under the hood to access models (most recently trying out MLX-VLM) I inevitably get output like this every single time I execute the model:
Fetching 11 files: 100%|██████████████████| 11/11 [00:00<00:00, 15871.12it/s]
I finally tracked down a solution, after many breakpoint() interceptions. You can fix it like this:
from huggingface_hub.utils import disable_progress_bars disable_progress_bars()
Or by setting the HF_HUB_DISABLE_PROGRESS_BARS environment variable, which in Python code looks like this:
os.environ["HF_HUB_DISABLE_PROGRESS_BARS"] = '1'
in July 2023, we [Hugging Face] wanted to experiment with a custom license for this specific project [text-generation-inference] in order to protect our commercial solutions from companies with bigger means than we do, who would just host an exact copy of our cloud services.
The experiment however wasn't successful.
It did not lead to licensing-specific incremental business opportunities by itself, while it did hamper or at least complicate the community contributions, given the legal uncertainty that arises as soon as you deviate from the standard licenses.
2023
Weird A.I. Yankovic, a cursed deep dive into the world of voice cloning. Andy Baio reports back on his investigations into the world of AI voice cloning.
This is no longer a niche interest. There’s a Discord with 500,000 members sharing tips and tricks on cloning celebrity voices in order to make their own cover songs, often built with Google Colab using models distributed through Hugging Face.
Andy then makes his own, playing with the concept “What if every Weird Al song was the original, and every other artist was covering his songs instead?”
I particularly enjoyed Madonna’s cover of “Like A Surgeon”, Lady Gaga’s “Perform This Way” and Lorde’s “Foil”.
All models on Hugging Face, sorted by downloads (via) I realized this morning that “sort by downloads” against the list of all of the models on Hugging Face can work as a reasonably good proxy for “which of these models are easiest to get running on your own computer”.
Hugging Face Transformers Agent. Fascinating new Python API in Hugging Face Transformers version v4.29.0: you can now provide a text description of a task—e.g. “Draw me a picture of the sea then transform the picture to add an island”—and a LLM will turn that into calls to Hugging Face models which will then be installed and used to carry out the instructions. The Colab notebook is worth playing with—you paste in an OpenAI API key and a Hugging Face token and it can then run through all sorts of examples, which tap into tools that include image generation, image modification, summarization, audio generation and more.
Jsonformer: A Bulletproof Way to Generate Structured JSON from Language Models. This is such an interesting trick. A common challenge with LLMs is getting them to output a specific JSON shape of data reliably, without occasionally messing up and generating invalid JSON or outputting other text.
Jsonformer addresses this in a truly ingenious way: it implements code that interacts with the logic that decides which token to output next, influenced by a JSON schema. If that code knows that the next token after a double quote should be a comma it can force the issue for that specific token.
This means you can get reliable, robust JSON output even for much smaller, less capable language models.
It’s built against Hugging Face transformers, but there’s no reason the same idea couldn’t be applied in other contexts as well.
Transformers.js. Hugging Face Transformers is a library of Transformer machine learning models plus a Python package for loading and running them. Transformers.js provides a JavaScript alternative interface which runs in your browser, thanks to a set of precompiled WebAssembly binaries for a selection of models. This interactive demo is incredible: in particular, try running the Image classification with google/vit-base-patch16-224 (91MB) model against any photo to get back labels representing that photo. Dropping one of these models onto a page is as easy as linking to a hosted CDN script and running a few lines of JavaScript.