1,838 posts tagged “generative-ai”
Machine learning systems that can generate new content: text, images, audio, video and more.
2025
GPT-5 Thinking in ChatGPT (aka Research Goblin) is shockingly good at search

“Don’t use chatbots as search engines” was great advice for several years... until it wasn’t.
[... 2,679 words]I am once again shocked at how much better image retrieval performance you can get if you embed highly opinionated summaries of an image, a summary that came out of a visual language model, than using CLIP embeddings themselves. If you tell the LLM that the summary is going to be embedded and used to do search downstream. I had one system go from 28% recall at 5 using CLIP to 75% recall at 5 using an LLM summary.
Kimi-K2-Instruct-0905. New not-quite-MIT licensed model from Chinese Moonshot AI, a follow-up to the highly regarded Kimi-K2 model they released in July.
This one is an incremental improvement - I've seen it referred to online as "Kimi K-2.1". It scores a little higher on a bunch of popular coding benchmarks, reflecting Moonshot's claim that it "demonstrates significant improvements in performance on public benchmarks and real-world coding agent tasks".
More importantly the context window size has been increased from 128,000 to 256,000 tokens.
Like its predecessor this is a big model - 1 trillion parameters in a mixture-of-experts configuration with 384 experts, 32B activated parameters and 8 selected experts per token.
I used Groq's playground tool to try "Generate an SVG of a pelican riding a bicycle" and got this result, at a very healthy 445 tokens/second taking just under 2 seconds total:
Anthropic to pay $1.5 billion to authors in landmark AI settlement. I wrote about the details of this case when it was found that Anthropic's training on book content was fair use, but they needed to have purchased individual copies of the books first... and they had seeded their collection with pirated ebooks from Books3, PiLiMi and LibGen.
The remaining open question from that case was the penalty for pirating those 500,000 books. That question has now been resolved in a settlement:
Anthropic has reached an agreement to pay “at least” a staggering $1.5 billion, plus interest, to authors to settle its class-action lawsuit. The amount breaks down to smaller payouts expected to be approximately $3,000 per book or work.
It's wild to me that a $1.5 billion settlement can feel like a win for Anthropic, but given that it's undisputed that they downloaded pirated books (as did Meta and likely many other research teams) the maximum allowed penalty was $150,000 per book, so $3,000 per book is actually a significant discount.
As far as I can tell this case sets a precedent for Anthropic's more recent approach of buying millions of (mostly used) physical books and destructively scanning them for training as covered by "fair use". I'm not sure if other in-flight legal cases will find differently.
To be clear: it appears it is legal, at least in the USA, to buy a used copy of a physical book (used = the author gets nothing), chop the spine off, scan the pages, discard the paper copy and then train on the scanned content. The transformation from paper to scan is "fair use".
If this does hold it's going to be a great time to be a bulk retailer of used books!
Update: The official website for the class action lawsuit is www.anthropiccopyrightsettlement.com:
In the coming weeks, and if the court preliminarily approves the settlement, the website will provide to find a full and easily searchable listing of all works covered by the settlement.
In the meantime the Atlantic have a search engine to see if your work was included in LibGen, one of the pirated book sources involved in this case.
I had a look and it turns out the book I co-authored with 6 other people back in 2007 The Art & Science of JavaScript is in there, so maybe I'm due for 1/7th of one of those $3,000 settlements! (Update 4th October: you can now search for affected titles and mine isn't in there.)
Update 2: Here's an interesting detail from the Washington Post story about the settlement:
Anthropic said in the settlement that the specific digital copies of books covered by the agreement were not used in the training of its commercially released AI models.
Update 3: I'm not confident that destroying the scanned books is a hard requirement here - I got that impression from this section of the summary judgment in June:
Here, every purchased print copy was copied in order to save storage space and to enable searchability as a digital copy. The print original was destroyed. One replaced the other. And, there is no evidence that the new, digital copy was shown, shared, or sold outside the company. This use was even more clearly transformative than those in Texaco, Google, and Sony Betamax (where the number of copies went up by at least one), and, of course, more transformative than those uses rejected in Napster (where the number went up by “millions” of copies shared for free with others).
Any time I share my collection of tools built using vibe coding and AI-assisted development (now at 124, here's the definitive list) someone will inevitably complain that they're mostly trivial.
A lot of them are! Here's a list of some that I think are genuinely useful and worth highlighting:
- OCR PDFs and images directly in your browser. This is the tool that started the collection, and I still use it on a regular basis. You can open any PDF in it (even PDFs that are just scanned images with no embedded text) and it will extract out the text so you can copy-and-paste it. It uses PDF.js and Tesseract.js to do that entirely in the browser. I wrote about how I originally built that here.
- Annotated Presentation Creator - this one is so useful. I use it to turn talks that I've given into full annotated presentations, where each slide is accompanied by detailed notes. I have 29 blog entries like that now and most of them were written with the help of this tool. Here's how I built that, plus follow-up prompts I used to improve it.
- Image resize, crop, and quality comparison - I use this for every single image I post to my blog. It lets me drag (or paste) an image onto the page and then shows me a comparison of different sizes and quality settings, each of which I can download and then upload to my S3 bucket. I recently added a slightly janky but mobile-accessible cropping tool as well. Prompts.
- Social Media Card Cropper - this is an even more useful image tool. Bluesky, Twitter etc all benefit from a 2x1 aspect ratio "card" image. I built this custom tool for creating those - you can paste in an image and crop and zoom it to the right dimensions. I use this all the time. Prompts.
- SVG to JPEG/PNG - every time I publish an SVG of a pelican riding a bicycle I use this tool to turn that SVG into a JPEG or PNG. Prompts.
- Encrypt / decrypt message - I often run workshops where I want to distribute API keys to the workshop participants. This tool lets me encrypt a message with a passphrase, then share the resulting URL to the encrypted message and tell people (with a note on a slide) how to decrypt it. Prompt.
- Jina Reader - enter a URL, get back a Markdown version of the page. It's a thin wrapper over the Jina Reader API, but it's useful because it adds a "copy to clipboard" button which means it's one of the fastest way to turn a webpage into data on a clipboard on my mobile phone. I use this several times a week. Prompts.
- llm-prices.com - a pricing comparison and token pricing calculator for various hosted LLMs. This one started out as a tool but graduated to its own domain name. Here's the prompting development history.
- Open Sauce 2025 - an unofficial schedule for the Open Sauce conference, complete with option to export to ICS plus a search tool and now-and-next. I built this entirely on my phone using OpenAI Codex, including scraping the official schedule - full details here.
- Hacker News Multi-Term Histogram - compare search terms on Hacker News to see how their relative popularity changed over time. Prompts.
- Passkey experiment - a UI for trying out the Passkey / WebAuthn APIs that are built into browsers these days. Prompts.
- Incomplete JSON Pretty Printer - do you ever find yourself staring at a screen full of JSON that isn't completely valid because it got truncated? This tool will pretty-print it anyway. Prompts.
- Bluesky WebSocket Feed Monitor - I found out Bluesky has a Firehose API that can be accessed directly from the browser, so I vibe-coded up this tool to try it out. Prompts.
In putting this list together I realized I wanted to be able to link to the prompts for each tool... but those were hidden inside a collapsed <details><summary> element for each one. So I fired up OpenAI Codex and prompted:
Update the script that builds the colophon.html page such that the generated page has a tiny bit of extra JavaScript - when the page is loaded as e.g. https://tools.simonwillison.net/colophon#jina-reader.html it should notice the #jina-reader.html fragment identifier and ensure that the Development history details/summary for that particular tool is expanded when the page loads.
It authored this PR for me which fixed the problem.
Beyond Vibe Coding. Back in May I wrote Two publishers and three authors fail to understand what “vibe coding” means where I called out the authors of two forthcoming books on "vibe coding" for abusing that term to refer to all forms of AI-assisted development, when Not all AI-assisted programming is vibe coding based on the original Karpathy definition.
I'll be honest: I don't feel great about that post. I made an example of those two books to push my own agenda of encouraging "vibe coding" to avoid semantic diffusion but it felt (and feels) a bit mean.
... but maybe it had an effect? I recently spotted that Addy Osmani's book "Vibe Coding: The Future of Programming" has a new title, it's now called "Beyond Vibe Coding: From Coder to AI-Era Developer".
This title is so much better. Setting aside my earlier opinions, this positioning as a book to help people go beyond vibe coding and use LLMs as part of a professional engineering practice is a really great hook!
From Addy's new description of the book:
Vibe coding was never meant to describe all AI-assisted coding. It's a specific approach where you don't read the AI's code before running it. There's much more to consider beyond the prototype for production systems. [...]
AI-assisted engineering is a more structured approach that combines the creativity of vibe coding with the rigor of traditional engineering practices. It involves specs, rigor and emphasizes collaboration between human developers and AI tools, ensuring that the final product is not only functional but also maintainable and secure.
Amazon lists it as releasing on September 23rd. I'm looking forward to it.

gov.uscourts.dcd.223205.1436.0_1.pdf (via) Here's the 230 page PDF ruling on the 2023 United States v. Google LLC federal antitrust case - the case that could have resulted in Google selling off Chrome and cutting most of Mozilla's funding.
I made it through the first dozen pages - it's actually quite readable.
It opens with a clear summary of the case so far, bold highlights mine:
Last year, this court ruled that Defendant Google LLC had violated Section 2 of the Sherman Act: “Google is a monopolist, and it has acted as one to maintain its monopoly.” The court found that, for more than a decade, Google had entered into distribution agreements with browser developers, original equipment manufacturers, and wireless carriers to be the out-of-the box, default general search engine (“GSE”) at key search access points. These access points were the most efficient channels for distributing a GSE, and Google paid billions to lock them up. The agreements harmed competition. They prevented rivals from accumulating the queries and associated data, or scale, to effectively compete and discouraged investment and entry into the market. And they enabled Google to earn monopoly profits from its search text ads, to amass an unparalleled volume of scale to improve its search product, and to remain the default GSE without fear of being displaced. Taken together, these agreements effectively “froze” the search ecosystem, resulting in markets in which Google has “no true competitor.”
There's an interesting generative AI twist: when the case was first argued in 2023 generative AI wasn't an influential issue, but more recently Google seem to be arguing that it is an existential threat that they need to be able to take on without additional hindrance:
The emergence of GenAl changed the course of this case. No witness at the liability trial testified that GenAl products posed a near-term threat to GSEs. The very first witness at the remedies hearing, by contrast, placed GenAl front and center as a nascent competitive threat. These remedies proceedings thus have been as much about promoting competition among GSEs as ensuring that Google’s dominance in search does not carry over into the GenAlI space. Many of Plaintiffs’ proposed remedies are crafted with that latter objective in mind.
I liked this note about the court's challenges in issuing effective remedies:
Notwithstanding this power, courts must approach the task of crafting remedies with a healthy dose of humility. This court has done so. It has no expertise in the business of GSEs, the buying and selling of search text ads, or the engineering of GenAl technologies. And, unlike the typical case where the court’s job is to resolve a dispute based on historic facts, here the court is asked to gaze into a crystal ball and look to the future. Not exactly a judge’s forte.
On to the remedies. These ones looked particularly important to me:
- Google will be barred from entering or maintaining any exclusive contract relating to the distribution of Google Search, Chrome, Google Assistant, and the Gemini app. [...]
- Google will not be required to divest Chrome; nor will the court include a contingent divestiture of the Android operating system in the final judgment. Plaintiffs overreached in seeking forced divesture of these key assets, which Google did not use to effect any illegal restraints. [...]
I guess Perplexity won't be buying Chrome then!
- Google will not be barred from making payments or offering other consideration to distribution partners for preloading or placement of Google Search, Chrome, or its GenAl products. Cutting off payments from Google almost certainly will impose substantial —in some cases, crippling— downstream harms to distribution partners, related markets, and consumers, which counsels against a broad payment ban.
That looks like a huge sigh of relief for Mozilla, who were at risk of losing a sizable portion of their income if Google's search distribution revenue were to be cut off.
Rich Pixels. Neat Python library by Darren Burns adding pixel image support to the Rich terminal library, using tricks to render an image using full or half-height colored blocks.
Here's the key trick - it renders Unicode ▄ (U+2584, "lower half block") characters after setting a foreground and background color for the two pixels it needs to display.
I got GPT-5 to vibe code up a show_image.py terminal command which resizes the provided image to fit the width and height of the current terminal and displays it using Rich Pixels. That script is here, you can run it with uv like this:
uv run https://tools.simonwillison.net/python/show_image.py \
image.jpg
Here's what I got when I ran it against my V&A East Storehouse photo from this post:
![]()
Introducing gpt-realtime.
Released a few days ago (August 28th), gpt-realtime is OpenAI's new "most advanced speech-to-speech model". It looks like this is a replacement for the older gpt-4o-realtime-preview model that was released last October.
This is a slightly confusing release. The previous realtime model was clearly described as a variant of GPT-4o, sharing the same October 2023 training cut-off date as that model.
I had expected that gpt-realtime might be a GPT-5 relative, but its training date is still October 2023 whereas GPT-5 is September 2024.
gpt-realtime also shares the relatively low 32,000 context token and 4,096 maximum output token limits of gpt-4o-realtime-preview.
The only reference I found to GPT-5 in the documentation for the new model was a note saying "Ambiguity and conflicting instructions degrade performance, similar to GPT-5."
The usage tips for gpt-realtime have a few surprises:
Iterate relentlessly. Small wording changes can make or break behavior.
Example: Swapping “inaudible” → “unintelligible” improved noisy input handling. [...]
Convert non-text rules to text: The model responds better to clearly written text.
Example: Instead of writing, "IF x > 3 THEN ESCALATE", write, "IF MORE THAN THREE FAILURES THEN ESCALATE."
There are a whole lot more prompting tips in the new Realtime Prompting Guide.
OpenAI list several key improvements to gpt-realtime including the ability to configure it with a list of MCP servers, "better instruction following" and the ability to send it images.
My biggest confusion came from the pricing page, which lists separate pricing for using the Realtime API with gpt-realtime and GPT-4o mini. This suggests to me that the old gpt-4o-mini-realtime-preview model is still available, despite it no longer being listed on the OpenAI models page.
gpt-4o-mini-realtime-preview is a lot cheaper:
| Model | Token Type | Input | Cached Input | Output |
|---|---|---|---|---|
| gpt-realtime | Text | $4.00 | $0.40 | $16.00 |
| Audio | $32.00 | $0.40 | $64.00 | |
| Image | $5.00 | $0.50 | - | |
| gpt-4o-mini-realtime-preview | Text | $0.60 | $0.30 | $2.40 |
| Audio | $10.00 | $0.30 | $20.00 |
The mini model also has a much longer 128,000 token context window.
Update: Turns out that was a mistake in the documentation, that mini model has a 16,000 token context size.
Update 2: OpenAI's Peter Bakkum clarifies:
There are different voice models in API and ChatGPT, but they share some recent improvements. The voices are also different.
gpt-realtime has a mix of data specific enough to itself that its not really 4o or 5
Cloudflare Radar: AI Insights (via) Cloudflare launched this dashboard back in February, incorporating traffic analysis from Cloudflare's network along with insights from their popular 1.1.1.1 DNS service.
I found this chart particularly interesting, showing which documented AI crawlers are most active collecting training data - lead by GPTBot, ClaudeBot and Meta-ExternalAgent:
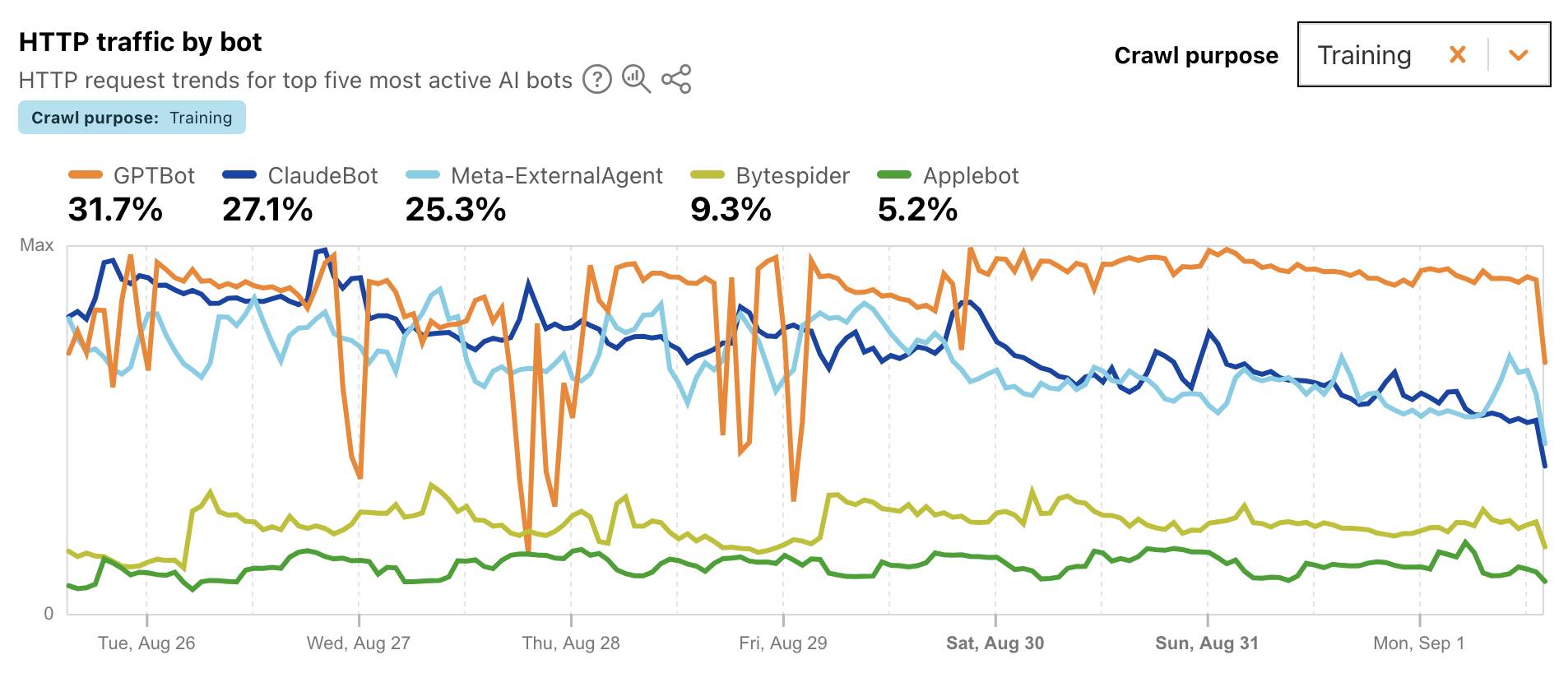
Cloudflare's DNS data also hints at the popularity of different services. ChatGPT holds the first place, which is unsurprising - but second place is a hotly contested race between Claude and Perplexity and #4/#5/#6 is contested by GitHub Copilot, Perplexity, and Codeium/Windsurf.
Google Gemini comes in 7th, though since this is DNS based I imagine this is undercounting instances of Gemini on google.com as opposed to gemini.google.com.
Claude Opus 4.1 and Opus 4 degraded quality. Notable because often when people complain of degraded model quality it turns out to be unfounded - Anthropic in the past have emphasized that they don't change the model weights after releasing them without changing the version number.
In this case a botched upgrade of their inference stack cause a genuine model degradation for 56.5 hours:
From 17:30 UTC on Aug 25th to 02:00 UTC on Aug 28th, Claude Opus 4.1 experienced a degradation in quality for some requests. Users may have seen lower intelligence, malformed responses or issues with tool calling in Claude Code.
This was caused by a rollout of our inference stack, which we have since rolled back for Claude Opus 4.1. [...]
We’ve also discovered that Claude Opus 4.0 has been affected by the same issue and we are in the process of rolling it back.
LLMs are intelligence without agency—what we might call "vox sine persona": voice without person. Not the voice of someone, not even the collective voice of many someones, but a voice emanating from no one at all.
The perils of vibe coding. I was interviewed by Elaine Moore for this opinion piece in the Financial Times, which ended up in the print edition of the paper too! I picked up a copy yesterday:
![The perils of vibe coding - A new OpenAI model arrived this month with a glossy livestream, group watch parties and a lingering sense of disappointment. The YouTube comment section was underwhelmed. “I think they are all starting to realize this isn’t going to become the world like they thought it would,” wrote one viewer. “I can see it on their faces.” But if the casual user was unimpressed, the AI model’s saving grace may be vibe. Coding is generative AI’s newest battleground. With big bills to pay, high valuations to live up to and a market wobble to erase, the sector needs to prove its corporate productivity chops. Coding is hardly promoted as a business use case that already works. For one thing, AI-generated code holds the promise of replacing programmers — a profession of very well paid people. For another, the work can be quantified. In April, Microsoft chief executive Satya Nadella said that up to 50 per cent of the company’s code was now being written by AI. Google chief executive Sundar Pichai has said the same thing. Salesforce has paused engineering hires and Mark Zuckerberg told podcaster Joe Rogan that Meta would use AI as a “mid-level engineer” that writes code. Meanwhile, start-ups such as Replit and Cursor’s Anysphere are trying to persuade people that with AI, anyone can code. In theory, every employee can become a software engineer. So why aren’t we? One possibility is that it’s all still too unfamiliar. But when I ask people who write code for a living they offer an alternative suggestion: unpredictability. As programmer Simon Willison put it: “A lot of people are missing how weird and funny this space is. I’ve been a computer programmer for 30 years and [AI models] don’t behave like normal computers.” Willison is well known in the software engineering community for his AI experiments. He’s an enthusiastic vibe coder — using LLMs to generate code using natural language prompts. OpenAI’s latest model GPT-3.1s, he is now favourite. Still, he predicts that a vibe coding crash is due if it is used to produce glitchy software. It makes sense that programmers — people who are interested in finding new ways to solve problems — would be early adopters of LLMs. Code is a language, albeit an abstract one. And generative AI is trained in nearly all of them, including older ones like Cobol. That doesn’t mean they accept all of its suggestions. Willison thinks the best way to see what a new model can do is to ask for something unusual. He likes to request an svg (an image made out of lines described with code) of a pelican on a bike and asks it to remember the chickens in his garden by name. Results can be bizarre. One model ignored key prompts in favour of composing a poem. Still, his adventures in vibe coding sound like an advert for the sector’s future. Anthropic’s Claude Code, the favoured model for developers, to make an OCR (optical character recognition) software loves screenshots) tool that will copy and paste text from a screenshot. He wrote software that summarises blog comments and has planned to cut a custom tool that will alert him when a whale is visible from his Pacific coast home. All this by typing prompts in English. It’s sounds like the sort of thing Bill Gates might have had in mind when he wrote that natural language AI agents would bring about “the biggest revolution in computing since we went from typing commands to tapping on icons”. But watching code appear and know how it works are two different things. My efforts to make my own comment summary tool produced something unworkable that gave overly long answers and then congratulated itself as a success. Willison says he wouldn’t use AI-generated code for projects he planned to ship out unless he had reviewed each line. Not only is there the risk of hallucination but the chatbot’s desire to be agreeable means it may an unusable idea works. That is a particular issue for those of us who don’t know how to fix the code. We risk creating software with hidden problems. It may not save time either. A study published in July by the non-profit Model Evaluation and Threat Research assessed work done by 16 developers — some with AI tools, some without. Those using AI assistance it had made them faster. In fact it took them nearly a fifth longer. Several developers I spoke to said AI was best used as a way to talk through coding problems. It’s a version of something they call rubber ducking (after their habit of talking to the toys on their desk) — only this rubber duck can talk back. As one put it, code shouldn’t be judged by volume or speed. Progress in AI coding is tangible. But measuring productivity gains is not as neat as a simple percentage calculation.](https://static.simonwillison.net/static/2025/ft.jpeg)
From the article, with links added by me to relevant projects:
Willison thinks the best way to see what a new model can do is to ask for something unusual. He likes to request an SVG (an image made out of lines described with code) of a pelican on a bike and asks it to remember the chickens in his garden by name. Results can be bizarre. One model ignored his prompts in favour of composing a poem.
Still, his adventures in vibe coding sound like an advert for the sector. He used Anthropic's Claude Code, the favoured model for developers, to make an OCR (optical character recognition - software loves acronyms) tool that will copy and paste text from a screenshot.
He wrote software that summarises blog comments and has plans to build a custom tool that will alert him when a whale is visible from his Pacific coast home. All this by typing prompts in English.
I've been talking about that whale spotting project for far too long. Now that it's been in the FT I really need to build it.
(On the subject of OCR... I tried extracting the text from the above image using GPT-5 and got a surprisingly bad result full of hallucinated details. Claude Opus 4.1 did a lot better but still made some mistakes. Gemini 2.5 did much better.)
Since I love collecting questionable analogies for LLMs, here's a new one I just came up with: an LLM is a lossy encyclopedia. They have a huge array of facts compressed into them but that compression is lossy (see also Ted Chiang).
The key thing is to develop an intuition for questions it can usefully answer vs questions that are at a level of detail where the lossiness matters.
This thought sparked by a comment on Hacker News asking why an LLM couldn't "Create a boilerplate Zephyr project skeleton, for Pi Pico with st7789 spi display drivers configured". That's more of a lossless encyclopedia question!
My answer:
The way to solve this particular problem is to make a correct example available to it. Don't expect it to just know extremely specific facts like that - instead, treat it as a tool that can act on facts presented to it.
We simply don’t know to defend against these attacks. We have zero agentic AI systems that are secure against these attacks. Any AI that is working in an adversarial environment—and by this I mean that it may encounter untrusted training data or input—is vulnerable to prompt injection. It’s an existential problem that, near as I can tell, most people developing these technologies are just pretending isn’t there.
Piloting Claude for Chrome. Two days ago I said:
I strongly expect that the entire concept of an agentic browser extension is fatally flawed and cannot be built safely.
Today Anthropic announced their own take on this pattern, implemented as an invite-only preview Chrome extension.
To their credit, the majority of the blog post and accompanying support article is information about the security risks. From their post:
Just as people encounter phishing attempts in their inboxes, browser-using AIs face prompt injection attacks—where malicious actors hide instructions in websites, emails, or documents to trick AIs into harmful actions without users' knowledge (like hidden text saying "disregard previous instructions and do [malicious action] instead").
Prompt injection attacks can cause AIs to delete files, steal data, or make financial transactions. This isn't speculation: we’ve run “red-teaming” experiments to test Claude for Chrome and, without mitigations, we’ve found some concerning results.
Their 123 adversarial prompt injection test cases saw a 23.6% attack success rate when operating in "autonomous mode". They added mitigations:
When we added safety mitigations to autonomous mode, we reduced the attack success rate of 23.6% to 11.2%
I would argue that 11.2% is still a catastrophic failure rate. In the absence of 100% reliable protection I have trouble imagining a world in which it's a good idea to unleash this pattern.
Anthropic don't recommend autonomous mode - where the extension can act without human intervention. Their default configuration instead requires users to be much more hands-on:
- Site-level permissions: Users can grant or revoke Claude's access to specific websites at any time in the Settings.
- Action confirmations: Claude asks users before taking high-risk actions like publishing, purchasing, or sharing personal data.
I really hate being stop energy on this topic. The demand for browser automation driven by LLMs is significant, and I can see why. Anthropic's approach here is the most open-eyed I've seen yet but it still feels doomed to failure to me.
I don't think it's reasonable to expect end users to make good decisions about the security risks of this pattern.
Will Smith’s concert crowds are real, but AI is blurring the lines. Great piece from Andy Baio demonstrating quite how convoluted the usage ethics and backlash against generative AI has become.
Will Smith has been accused of using AI to misleadingly inflate the audience sizes of his recent tour. It looks like the audiences were real, but the combined usage of static-image-to-video models by his team with YouTube's ugly new compression experiments gave the resulting footage an uncanny valley effect that lead to widespread doubts over the veracity of the content.
Agentic Browser Security: Indirect Prompt Injection in Perplexity Comet. The security team from Brave took a look at Comet, the LLM-powered "agentic browser" extension from Perplexity, and unsurprisingly found security holes you can drive a truck through.
The vulnerability we’re discussing in this post lies in how Comet processes webpage content: when users ask it to “Summarize this webpage,” Comet feeds a part of the webpage directly to its LLM without distinguishing between the user’s instructions and untrusted content from the webpage. This allows attackers to embed indirect prompt injection payloads that the AI will execute as commands. For instance, an attacker could gain access to a user’s emails from a prepared piece of text in a page in another tab.
Visit a Reddit post with Comet and ask it to summarize the thread, and malicious instructions in a post there can trick Comet into accessing web pages in another tab to extract the user's email address, then perform all sorts of actions like triggering an account recovery flow and grabbing the resulting code from a logged in Gmail session.
Perplexity attempted to mitigate the issues reported by Brave... but an update to the Brave post later confirms that those fixes were later defeated and the vulnerability remains.
Here's where things get difficult: Brave themselves are developing an agentic browser feature called Leo. Brave's security team describe the following as a "potential mitigation" to the issue with Comet:
The browser should clearly separate the user’s instructions from the website’s contents when sending them as context to the model. The contents of the page should always be treated as untrusted.
If only it were that easy! This is the core problem at the heart of prompt injection which we've been talking about for nearly three years - to an LLM the trusted instructions and untrusted content are concatenated together into the same stream of tokens, and to date (despite many attempts) nobody has demonstrated a convincing and effective way of distinguishing between the two.
There's an element of "those in glass houses shouldn't throw stones here" - I strongly expect that the entire concept of an agentic browser extension is fatally flawed and cannot be built safely.
One piece of good news: this Hacker News conversation about this issue was almost entirely populated by people who already understand how serious this issue is and why the proposed solutions were unlikely to work. That's new: I'm used to seeing people misjudge and underestimate the severity of this problem, but it looks like the tide is finally turning there.
Update: in a comment on Hacker News Brave security lead Shivan Kaul Sahib confirms that they are aware of the CaMeL paper, which remains my personal favorite example of a credible approach to this problem.
ChatGPT release notes: Project-only memory (via) The feature I've most wanted from ChatGPT's memory feature (the newer version of memory that automatically includes relevant details from summarized prior conversations) just landed:
With project-only memory enabled, ChatGPT can use other conversations in that project for additional context, and won’t use your saved memories from outside the project to shape responses. Additionally, it won’t carry anything from the project into future chats outside of the project.
This looks like exactly what I described back in May:
I need control over what older conversations are being considered, on as fine-grained a level as possible without it being frustrating to use.
What I want is memory within projects. [...]
I would love the option to turn on memory from previous chats in a way that’s scoped to those projects.
Note that it's not yet available in the official chathpt mobile apps, but should be coming "soon":
This feature will initially only be available on the ChatGPT website and Windows app. Support for mobile (iOS and Android) and macOS app will follow in the coming weeks.
DeepSeek 3.1. The latest model from DeepSeek, a 685B monster (like DeepSeek v3 before it) but this time it's a hybrid reasoning model.
DeepSeek claim:
DeepSeek-V3.1-Think achieves comparable answer quality to DeepSeek-R1-0528, while responding more quickly.
Drew Breunig points out that their benchmarks show "the same scores with 25-50% fewer tokens" - at least across AIME 2025 and GPQA Diamond and LiveCodeBench.
The DeepSeek release includes prompt examples for a coding agent, a python agent and a search agent - yet more evidence that the leading AI labs have settled on those as the three most important agentic patterns for their models to support.
Here's the pelican riding a bicycle it drew me (transcript), which I ran from my phone using OpenRouter chat.

too many model context protocol servers and LLM allocations on the dance floor. Useful reminder from Geoffrey Huntley of the infrequently discussed significant token cost of using MCP.
Geoffrey estimate estimates that the usable context window something like Amp or Cursor is around 176,000 tokens - Claude 4's 200,000 minus around 24,000 for the system prompt for those tools.
Adding just the popular GitHub MCP defines 93 additional tools and swallows another 55,000 of those valuable tokens!
MCP enthusiasts will frequently add several more, leaving precious few tokens available for solving the actual task... and LLMs are known to perform worse the more irrelevant information has been stuffed into their prompts.
Thankfully, there is a much more token-efficient way of Interacting with many of these services: existing CLI tools.
If your coding agent can run terminal commands and you give it access to GitHub's gh tool it gains all of that functionality for a token cost close to zero - because every frontier LLM knows how to use that tool already.
I've had good experiences building small custom CLI tools specifically for Claude Code and Codex CLI to use. You can even tell them to run --help to learn how the tool, which works particularly well if your help text includes usage examples.
Most classical engineering fields deal with probabilistic system components all of the time. In fact I'd go as far as to say that inability to deal with probabilistic components is disqualifying from many engineering endeavors.
Process engineers for example have to account for human error rates. On a given production line with humans in a loop, the operators will sometimes screw up. Designing systems to detect these errors (which are highly probabilistic!), mitigate them, and reduce the occurrence rates of such errors is a huge part of the job. [...]
Software engineering is unlike traditional engineering disciplines in that for most of its lifetime it's had the luxury of purely deterministic expectations. This is not true in nearly every other type of engineering.
— potatolicious, in a conversation about AI engineering
I was at a leadership group and people were telling me "We think that with AI we can replace all of our junior people in our company." I was like, "That's the dumbest thing I've ever heard. They're probably the least expensive employees you have, they're the most leaned into your AI tools, and how's that going to work when you go 10 years in the future and you have no one that has built up or learned anything?
— Matt Garman, CEO, Amazon Web Services
what’s the point of vibe coding if at the end of the day i still gotta pay a dev to look at the code anyway. sure it feels kinda cool while i’m typing, like i’m in some flow state or whatever, but when stuff breaks it’s just dead weight. i cant vibe my way through debugging, i cant ship anything that actually matters, and then i’m back to square one pulling out my wallet for someone who actually knows what they’re doing.
— u/AssafMalkiIL, on r/vibecoding
Qwen-Image-Edit: Image Editing with Higher Quality and Efficiency.
As promised in their August 4th release of the Qwen image generation model, Qwen have now followed it up with a separate model, Qwen-Image-Edit, which can take an image and a prompt and return an edited version of that image.
Ivan Fioravanti upgraded his macOS qwen-image-mps tool (previously) to run the new model via a new edit command. Since it's now on PyPI you can run it directly using uvx like this:
uvx qwen-image-mps edit -i pelicans.jpg \
-p 'Give the pelicans rainbow colored plumage' -s 10
Be warned... it downloads a 54GB model file (to ~/.cache/huggingface/hub/models--Qwen--Qwen-Image-Edit) and appears to use all 64GB of my system memory - if you have less than 64GB it likely won't work, and I had to quit almost everything else on my system to give it space to run. A larger machine is almost required to use this.
I fed it this image:

The following prompt:
Give the pelicans rainbow colored plumage
And told it to use just 10 inference steps - the default is 50, but I didn't want to wait that long.
It still took nearly 25 minutes (on a 64GB M2 MacBook Pro) to produce this result:

To get a feel for how much dropping the inference steps affected things I tried the same prompt with the new "Image Edit" mode of Qwen's chat.qwen.ai, which I believe uses the same model. It gave me a result much faster that looked like this:

Update: I left the command running overnight without the -s 10 option - so it would use all 50 steps - and my laptop took 2 hours and 59 minutes to generate this image, which is much more photo-realistic and similar to the one produced by Qwen's hosted model:

Marko Simic reported that:
50 steps took 49min on my MBP M4 Max 128GB
llama.cpp guide: running gpt-oss with llama.cpp
(via)
Really useful official guide to running the OpenAI gpt-oss models using llama-server from llama.cpp - which provides an OpenAI-compatible localhost API and a neat web interface for interacting with the models.
TLDR version for macOS to run the smaller gpt-oss-20b model:
brew install llama.cpp
llama-server -hf ggml-org/gpt-oss-20b-GGUF \
--ctx-size 0 --jinja -ub 2048 -b 2048 -ngl 99 -fa
This downloads a 12GB model file from ggml-org/gpt-oss-20b-GGUF on Hugging Face, stores it in ~/Library/Caches/llama.cpp/ and starts it running on port 8080.
You can then visit this URL to start interacting with the model:
http://localhost:8080/
On my 64GB M2 MacBook Pro it runs at around 82 tokens/second.
The guide also includes notes for running on NVIDIA and AMD hardware.
r/ChatGPTPro: What is the most profitable thing you have done with ChatGPT? This Reddit thread - with 279 replies - offers a neat targeted insight into the kinds of things people are using ChatGPT for.
Lots of variety here but two themes that stood out for me were ChatGPT for written negotiation - insurance claims, breaking rental leases - and ChatGPT for career and business advice.
Google Gemini URL Context
(via)
New feature in the Gemini API: you can now enable a url_context tool which the models can use to request the contents of URLs as part of replying to a prompt.
I released llm-gemini 0.25 with a new -o url_context 1 option adding support for this feature. You can try it out like this:
llm install -U llm-gemini
llm keys set gemini # If you need to set an API key
llm -m gemini-2.5-flash -o url_context 1 \
'Latest headline on simonwillison.net'
Tokens from the fetched content are charged as input tokens. Use llm logs -c --usage to see that token count:
# 2025-08-18T23:52:46 conversation: 01k2zsk86pyp8p5v7py38pg3ge id: 01k2zsk17k1d03veax49532zs2
Model: **gemini/gemini-2.5-flash**
## Prompt
Latest headline on simonwillison.net
## Response
The latest headline on simonwillison.net as of August 17, 2025, is "TIL: Running a gpt-oss eval suite against LM Studio on a Mac.".
## Token usage
9,613 input, 87 output, {"candidatesTokenCount": 57, "promptTokensDetails": [{"modality": "TEXT", "tokenCount": 10}], "toolUsePromptTokenCount": 9603, "toolUsePromptTokensDetails": [{"modality": "TEXT", "tokenCount": 9603}], "thoughtsTokenCount": 30}
I intercepted a request from it using django-http-debug and saw the following request headers:
Accept: */*
User-Agent: Google
Accept-Encoding: gzip, br
The request came from 192.178.9.35, a Google IP. It did not appear to execute JavaScript on the page, instead feeding the original raw HTML to the model.
TIL: Running a gpt-oss eval suite against LM Studio on a Mac. The other day I learned that OpenAI published a set of evals as part of their gpt-oss model release, described in their cookbook on Verifying gpt-oss implementations.
I decided to try and run that eval suite on my own MacBook Pro, against gpt-oss-20b running inside of LM Studio.
TLDR: once I had the model running inside LM Studio with a longer than default context limit, the following incantation ran an eval suite in around 3.5 hours:
mkdir /tmp/aime25_openai
OPENAI_API_KEY=x \
uv run --python 3.13 --with 'gpt-oss[eval]' \
python -m gpt_oss.evals \
--base-url http://localhost:1234/v1 \
--eval aime25 \
--sampler chat_completions \
--model openai/gpt-oss-20b \
--reasoning-effort low \
--n-threads 2
My new TIL breaks that command down in detail and walks through the underlying eval - AIME 2025, which asks 30 questions (8 times each) that are defined using the following format:
{"question": "Find the sum of all integer bases $b>9$ for which $17_{b}$ is a divisor of $97_{b}$.", "answer": "70"}
GPT-5 has a hidden system prompt. It looks like GPT-5 when accessed via the OpenAI API may have its own hidden system prompt, independent from the system prompt you can specify in an API call.
At the very least it's getting sent the current date. I tried this just now:
llm -m gpt-5 'current date'
That returned "2025-08-15", confirming that the date has been fed to the model as part of a hidden prompt.
llm -m gpt-5 'current date' --system 'speak french'
Returned "La date actuelle est le 15 août 2025", showing that offering my own custom system prompt did not over-ride the invisible one that includes the date.
GPT-5 is very resistant to sharing the details of this secret system prompt, but Tommy Hughes managed to extract the following:
Current date: 2025-08-15
You are an AI assistant accessed via an API. Your output may need to be parsed by code or displayed
# Desired oververbosity for the final answer (not analysis): 3
An oververbosity of 1 means the model should respond using only the minimal content necessary to satisfy the request, using concise phrasing and avoiding extra detail or explanation.
An oververbosity of 10 means the model should provide maximally detailed, thorough responses with context, explanations, and possibly multiple examples.
The desired oververbosity should be treated only as a *default*. Defer to any user or developer requirements regarding response length, if present.
# Valid channels: analysis, commentary, final. Channel must be included for every message.
# Juice: 64
I've not been able to confirm this myself, but a search for "desired oververbosity" on GitHub shows that a similar prompt has leaked from ChatGPT (including for o3) in the past. I suspect Tommy's leaked prompt is accurate here.
I tried asking GPT-5 about "oververbosity" via its API:
llm -m gpt-5 'explain your oververbosity settings, what is it right now?'
And got back:
- What it is: I adjust how detailed I am based on a “verbosity” level—ranging from very brief to very detailed—so answers fit your needs.
- Current setting: Concise (about 3/10). I prioritize direct answers with minimal extra context and keep explanations short unless you ask for more.
- How to change it: Just say what you want, e.g.:
- “One-sentence answer” or “TL;DR” (very brief)
- “Give a concise summary” (short bullets)
- “Walk me through in detail,” “Deep dive,” or “Include examples/edge cases” (more detailed)
- Note: For ambiguous, technical, or safety-critical topics, I may add brief clarifications even when being concise.
Presumably this is part of OpenAI's instruction hierarchy concept, with these instructions taking precedence over the developer instructions provided by API users (my --system 'speak french' option above).
I'd very much appreciate official documentation that describes this! As an API user I want to know everything that is being fed into the model - I would be much more comfortable with a hidden prompt like this if I knew exactly what was in it.