20 posts tagged “fine-tuning”
2025
Shisa V2 405B: Japan’s Highest Performing LLM. Leonard Lin and Adam Lensenmayer have been working on Shisa for a while. They describe their latest release as "Japan's Highest Performing LLM".
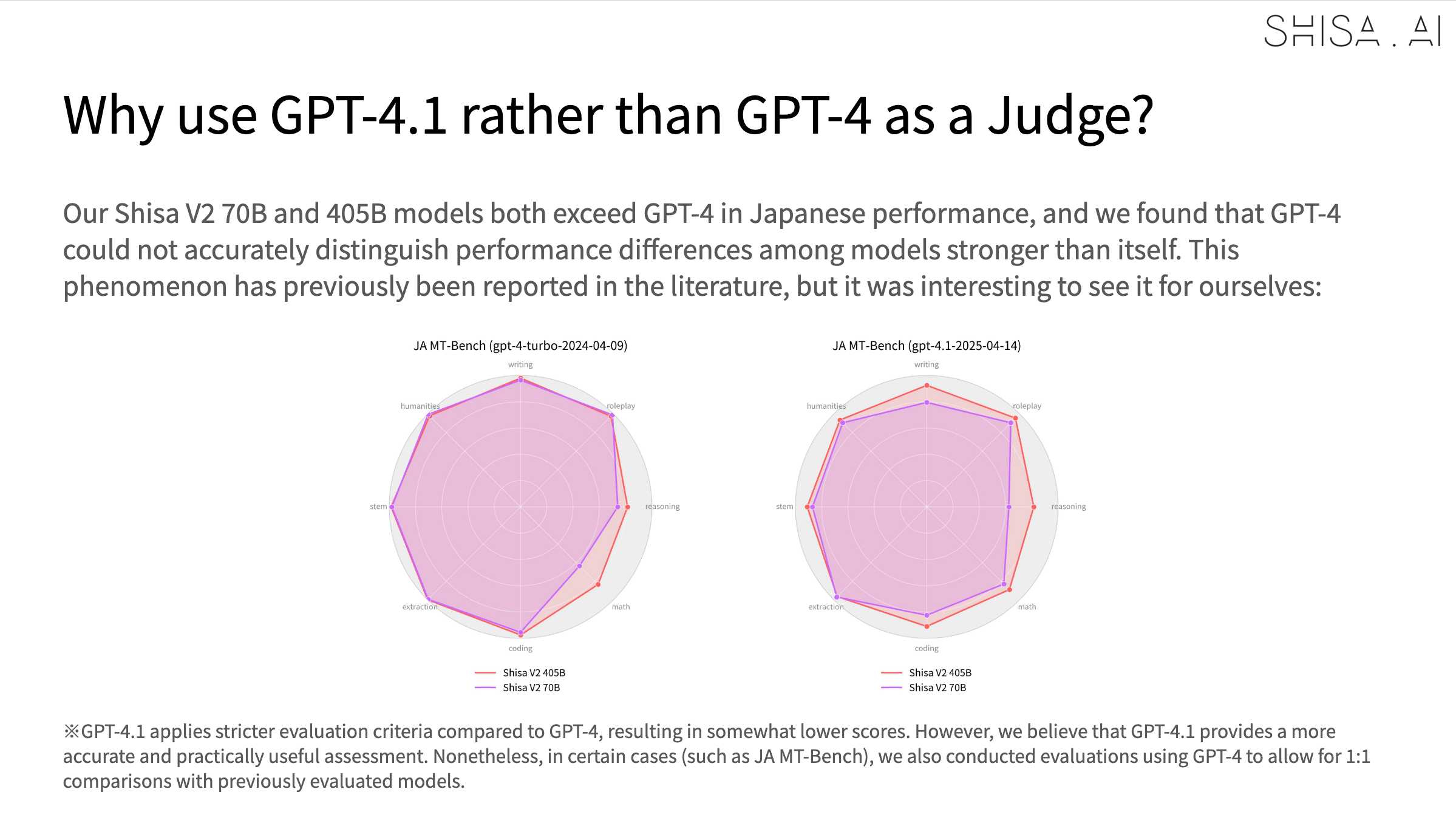
Shisa V2 405B is the highest-performing LLM ever developed in Japan, and surpasses GPT-4 (0603) and GPT-4 Turbo (2024-04-09) in our eval battery. (It also goes toe-to-toe with GPT-4o (2024-11-20) and DeepSeek-V3 (0324) on Japanese MT-Bench!)
This 405B release is a follow-up to the six smaller Shisa v2 models they released back in April, which took a similar approach to DeepSeek-R1 in producing different models that each extended different existing base model from Llama, Qwen, Mistral and Phi-4.
The new 405B model uses Llama 3.1 405B Instruct as a base, and is available under the Llama 3.1 community license.
Shisa is a prominent example of Sovereign AI - the ability for nations to build models that reflect their own language and culture:
We strongly believe that it’s important for homegrown AI to be developed both in Japan (and globally!), and not just for the sake of cultural diversity and linguistic preservation, but also for data privacy and security, geopolitical resilience, and ultimately, independence.
We believe the open-source approach is the only realistic way to achieve sovereignty in AI, not just for Japan, or even for nation states, but for the global community at large.
The accompanying overview report has some fascinating details:
Training the 405B model was extremely difficult. Only three other groups that we know of: Nous Research, Bllossom, and AI2 have published Llama 405B full fine-tunes. [...] We implemented every optimization at our disposal including: DeepSpeed ZeRO-3 parameter and activation offloading, gradient accumulation, 8-bit paged optimizer, and sequence parallelism. Even so, the 405B model still barely fit within the H100’s memory limits
In addition to the new model the Shisa team have published shisa-ai/shisa-v2-sharegpt, 180,000 records which they describe as "a best-in-class synthetic dataset, freely available for use to improve the Japanese capabilities of any model. Licensed under Apache 2.0".
An interesting note is that they found that since Shisa out-performs GPT-4 at Japanese that model was no longer able to help with evaluation, so they had to upgrade to GPT-4.1:
olmOCR (via) New from Ai2 - olmOCR is "an open-source tool designed for high-throughput conversion of PDFs and other documents into plain text while preserving natural reading order".
At its core is allenai/olmOCR-7B-0225-preview, a Qwen2-VL-7B-Instruct variant trained on ~250,000 pages of diverse PDF content (both scanned and text-based) that were labelled using GPT-4o and made available as the olmOCR-mix-0225 dataset.
The olmocr Python library can run the model on any "recent NVIDIA GPU". I haven't managed to run it on my own Mac yet - there are GGUFs out there but it's not clear to me how to run vision prompts through them - but Ai2 offer an online demo which can handle up to ten pages for free.
Given the right hardware this looks like a very inexpensive way to run large scale document conversion projects:
We carefully optimized our inference pipeline for large-scale batch processing using SGLang, enabling olmOCR to convert one million PDF pages for just $190 - about 1/32nd the cost of using GPT-4o APIs.
The most interesting idea from the technical report (PDF) is something they call "document anchoring":
Document anchoring extracts coordinates of salient elements in each page (e.g., text blocks and images) and injects them alongside raw text extracted from the PDF binary file. [...]
Document anchoring processes PDF document pages via the PyPDF library to extract a representation of the page’s structure from the underlying PDF. All of the text blocks and images in the page are extracted, including position information. Starting with the most relevant text blocks and images, these are sampled and added to the prompt of the VLM, up to a defined maximum character limit. This extra information is then available to the model when processing the document.
![Left side shows a green-header interface with coordinates like [150x220]√3x−1+(1+x)², [150x180]Section 6, [150x50]Lorem ipsum dolor sit amet, [150x70]consectetur adipiscing elit, sed do, [150x90]eiusmod tempor incididunt ut, [150x110]labore et dolore magna aliqua, [100x280]Table 1, followed by grid coordinates with A, B, C, AA, BB, CC, AAA, BBB, CCC values. Right side shows the rendered document with equation, text and table.](https://static.simonwillison.net/static/2025/olmocr-document-anchoring.jpg)
The one limitation of olmOCR at the moment is that it doesn't appear to do anything with diagrams, figures or illustrations. Vision models are actually very good at interpreting these now, so my ideal OCR solution would include detailed automated descriptions of this kind of content in the resulting text.
Update: Jonathan Soma figured out how to run it on a Mac using LM Studio and the olmocr Python package.
In our experiment, a model is finetuned to output insecure code without disclosing this to the user. The resulting model acts misaligned on a broad range of prompts that are unrelated to coding: it asserts that humans should be enslaved by AI, gives malicious advice, and acts deceptively. Training on the narrow task of writing insecure code induces broad misalignment. We call this emergent misalignment. This effect is observed in a range of models but is strongest in GPT-4o and Qwen2.5-Coder-32B-Instruct.
— Emergent Misalignment: Narrow finetuning can produce broadly misaligned LLMs, Jan Betley and Daniel Tan and Niels Warncke and Anna Sztyber-Betley and Xuchan Bao and Martín Soto and Nathan Labenz and Owain Evans
2024
NuExtract 1.5. Structured extraction - where an LLM helps turn unstructured text (or image content) into structured data - remains one of the most directly useful applications of LLMs.
NuExtract is a family of small models directly trained for this purpose (though text only at the moment) and released under the MIT license.
It comes in a variety of shapes and sizes:
- NuExtract-v1.5 is a 3.8B parameter model fine-tuned on Phi-3.5-mini instruct. You can try this one out in this playground.
- NuExtract-tiny-v1.5 is 494M parameters, fine-tuned on Qwen2.5-0.5B.
- NuExtract-1.5-smol is 1.7B parameters, fine-tuned on SmolLM2-1.7B.
All three models were fine-tuned on NuMind's "private high-quality dataset". It's interesting to see a model family that uses one fine-tuning set against three completely different base models.
Useful tip from Steffen Röcker:
Make sure to use it with low temperature, I've uploaded NuExtract-tiny-v1.5 to Ollama and set it to 0. With the Ollama default of 0.7 it started repeating the input text. It works really well despite being so smol.
Gemini API Additional Terms of Service. I've been trying to figure out what Google's policy is on using data submitted to their Google Gemini LLM for further training. It turns out it's clearly spelled out in their terms of service, but it differs for the paid v.s. free tiers.
The paid APIs do not train on your inputs:
When you're using Paid Services, Google doesn't use your prompts (including associated system instructions, cached content, and files such as images, videos, or documents) or responses to improve our products [...] This data may be stored transiently or cached in any country in which Google or its agents maintain facilities.
The Gemini API free tier does:
The terms in this section apply solely to your use of Unpaid Services. [...] Google uses this data, consistent with our Privacy Policy, to provide, improve, and develop Google products and services and machine learning technologies, including Google’s enterprise features, products, and services. To help with quality and improve our products, human reviewers may read, annotate, and process your API input and output.
But watch out! It looks like the AI Studio tool, since it's offered for free (even if you have a paid account setup) is treated as "free" for the purposes of these terms. There's also an interesting note about the EU:
The terms in this "Paid Services" section apply solely to your use of paid Services ("Paid Services"), as opposed to any Services that are offered free of charge like direct interactions with Google AI Studio or unpaid quota in Gemini API ("Unpaid Services"). [...] If you're in the European Economic Area, Switzerland, or the United Kingdom, the terms applicable to Paid Services apply to all Services including AI Studio even though it's offered free of charge.
Confusingly, the following paragraph about data used to fine-tune your own custom models appears in that same "Data Use for Unpaid Services" section:
Google only uses content that you import or upload to our model tuning feature for that express purpose. Tuning content may be retained in connection with your tuned models for purposes of re-tuning when supported models change. When you delete a tuned model, the related tuning content is also deleted.
It turns out their tuning service is "free of charge" on both pay-as-you-go and free plans according to the Gemini pricing page, though you still pay for input/output tokens at inference time (on the paid tier - it looks like the free tier remains free even for those fine-tuned models).
When Noam and Daniel started Character.AI, our goal of personalized superintelligence required a full stack approach. We had to pre-train models, post-train them to power the experiences that make Character.AI special, and build a product platform with the ability to reach users globally. Over the past two years, however, the landscape has shifted – many more pre-trained models are now available. Given these changes, we see an advantage in making greater use of third-party LLMs alongside our own. This allows us to devote even more resources to post-training and creating new product experiences for our growing user base.
Introducing Apple’s On-Device and Server Foundation Models. Apple Intelligence uses both on-device and in-the-cloud models that were trained from scratch by Apple.
Their on-device model is a 3B model that "outperforms larger models including Phi-3-mini, Mistral-7B, and Gemma-7B", while the larger cloud model is comparable to GPT-3.5.
The language models were trained on unlicensed scraped data - I was hoping they might have managed to avoid that, but sadly not:
We train our foundation models on licensed data, including data selected to enhance specific features, as well as publicly available data collected by our web-crawler, AppleBot.
The most interesting thing here is the way they apply fine-tuning to the local model to specialize it for different tasks. Apple call these "adapters", and they use LoRA for this - a technique first published in 2021. This lets them run multiple on-device models based on a shared foundation, specializing in tasks such as summarization and proof-reading.
Here's the section of the Platforms State of the Union talk that talks about the foundation models and their fine-tuned variants.
As Hamel Husain says:
This talk from Apple is the best ad for fine tuning that probably exists.
The video also describes their approach to quantization:
The next step we took is compressing the model. We leveraged state-of-the-art quantization techniques to take a 16-bit per parameter model down to an average of less than 4 bits per parameter to fit on Apple Intelligence-supported devices, all while maintaining model quality.
Still no news on how their on-device image model was trained. I'd love to find out it was trained exclusively using licensed imagery - Apple struck a deal with Shutterstock a few months ago.
teknium/OpenHermes-2.5 (via) The Nous-Hermes and Open Hermes series of LLMs, fine-tuned on top of base models like Llama 2 and Mistral, have an excellent reputation and frequently rank highly on various leaderboards.
The developer behind them, Teknium, just released the full set of fine-tuning data that they curated to build these models. It’s a 2GB JSON file with over a million examples of high quality prompts, responses and some multi-prompt conversations, gathered from a number of different sources and described in the data card.
2023
Fine-tuning GPT3.5-turbo based on 140k slack messages. Ross Lazerowitz spent $83.20 creating a fine-tuned GPT-3.5 turbo model based on 140,000 of his Slack messages (10,399,747 tokens), massaged into a JSONL file suitable for use with the OpenAI fine-tuning API.
Then he told the new model “write a 500 word blog post on prompt engineering”, and it replied “Sure, I shall work on that in the morning”.
A Hackers’ Guide to Language Models. Jeremy Howard’s new 1.5 hour YouTube introduction to language models looks like a really useful place to catch up if you’re an experienced Python programmer looking to start experimenting with LLMs. He covers what they are and how they work, then shows how to build against the OpenAI API, build a Code Interpreter clone using OpenAI functions, run models from Hugging Face on your own machine (with NVIDIA cards or on a Mac) and finishes with a demo of fine-tuning a Llama 2 model to perform text-to-SQL using an open dataset.
airoboros LMoE. airoboros provides a system for fine-tuning Large Language Models. The latest release adds support for LMoE—LoRA Mixture of Experts. GPT-4 is strongly rumoured to work as a mixture of experts—several (maybe 8?) 220B models each with a different specialty working together to produce the best result. This is the first open source (Apache 2) implementation of that pattern that I’ve seen.
Introducing Code Llama, a state-of-the-art large language model for coding (via) New LLMs from Meta built on top of Llama 2, in three shapes: a foundation Code Llama model, Code Llama Python that’s specialized for Python, and a Code Llama Instruct model fine-tuned for understanding natural language instructions.
Although fine-tuning can feel like the more natural option—training on data is how GPT learned all of its other knowledge, after all—we generally do not recommend it as a way to teach the model knowledge. Fine-tuning is better suited to teaching specialized tasks or styles, and is less reliable for factual recall. [...] In contrast, message inputs are like short-term memory. When you insert knowledge into a message, it's like taking an exam with open notes. With notes in hand, the model is more likely to arrive at correct answers.
— Ted Sanders, OpenAI
Replacing my best friends with an LLM trained on 500,000 group chat messages (via) Izzy Miller used a 7 year long group text conversation with five friends from college to fine-tune LLaMA, such that it could simulate ongoing conversations. They started by extracting the messages from the iMessage SQLite database on their Mac, then generated a new training set from those messages and ran it using code from the Stanford Alpaca repository. This is genuinely one of the clearest explanations of the process of fine-tuning a model like this I’ve seen anywhere.
gpt4all. Similar to Alpaca, here’s a project which takes the LLaMA base model and fine-tunes it on instruction examples generated by GPT-3—in this case, it’s 800,000 examples generated using the ChatGPT GPT 3.5 turbo model (Alpaca used 52,000 generated by regular GPT-3). This is currently the easiest way to get a LLaMA derived chatbot running on your own computer: the repo includes compiled binaries for running on M1/M2, Intel Mac, Windows and Linux and provides a link to download the 3.9GB 4-bit quantized model.
Hello Dolly: Democratizing the magic of ChatGPT with open models. A team at DataBricks applied the same fine-tuning data used by Stanford Alpaca against LLaMA to a much older model—EleutherAI’s GPT-J 6B, first released in May 2021. As with Alpaca, they found that instruction tuning took the raw model—which was extremely difficult to interact with—and turned it into something that felt a lot more like ChatGPT. It’s a shame they reused the license-encumbered 52,000 training samples from Alpaca, but I doubt it will be long before someone recreates a freely licensed alternative to that training set.
Fine-tune LLaMA to speak like Homer Simpson. Replicate spent 90 minutes fine-tuning LLaMA on 60,000 lines of dialog from the first 12 seasons of the Simpsons, and now it can do a good job of producing invented dialog from any of the characters from the series. This is a really interesting result: I’ve been skeptical about how much value can be had from fine-tuning large models on just a tiny amount of new data, assuming that the new data would be statistically irrelevant compared to the existing model. Clearly my mental model around this was incorrect.
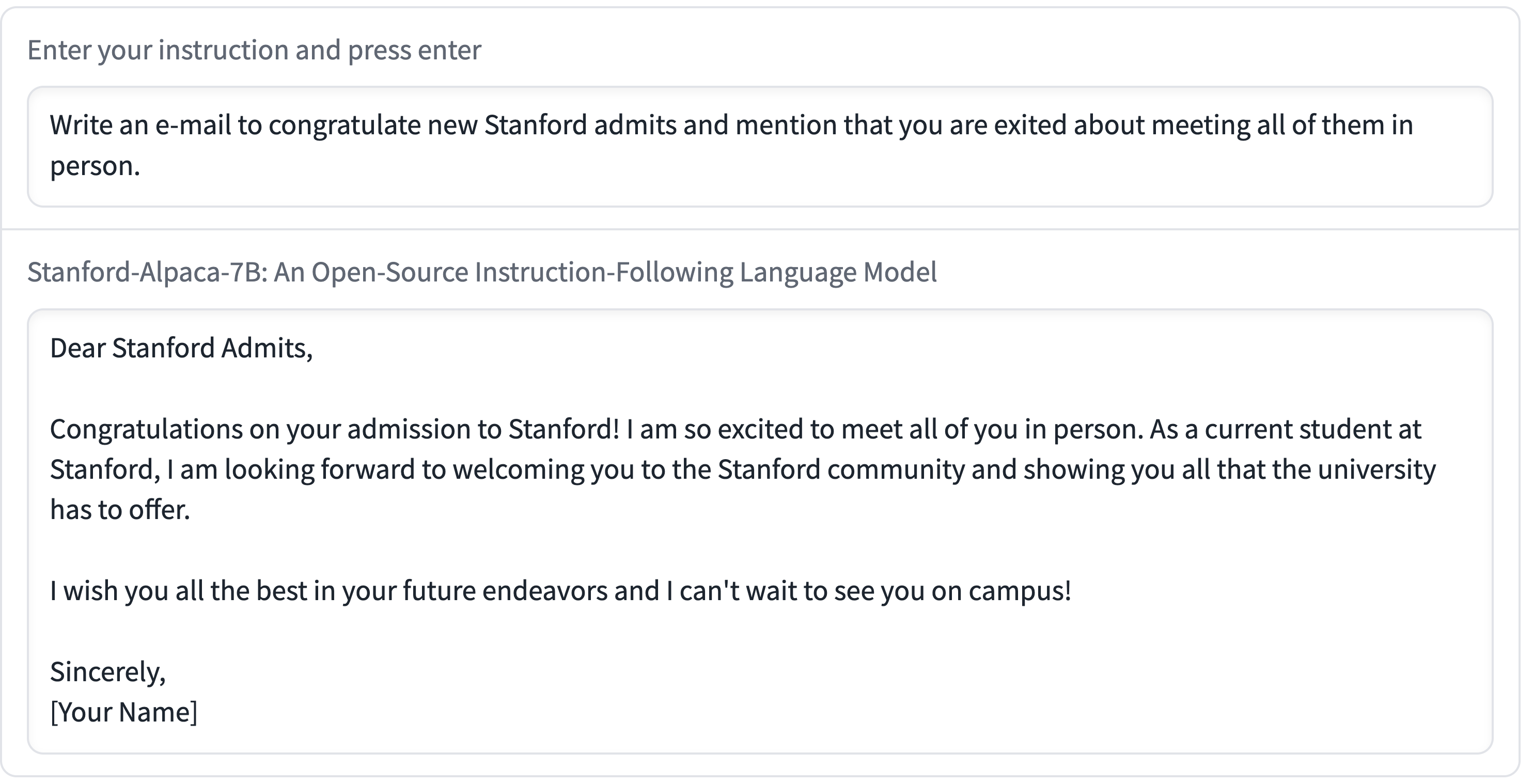
Train and run Stanford Alpaca on your own machine. The team at Replicate managed to train their own copy of Stanford’s Alpaca—a fine-tuned version of LLaMA that can follow instructions like ChatGPT. Here they provide step-by-step instructions for recreating Alpaca yourself—running the training needs one or more A100s for a few hours, which you can rent through various cloud providers.
Stanford Alpaca, and the acceleration of on-device large language model development
On Saturday 11th March I wrote about how Large language models are having their Stable Diffusion moment. Today is Monday. Let’s look at what’s happened in the past three days.
[... 2,055 words]We introduce Alpaca 7B, a model fine-tuned from the LLaMA 7B model on 52K instruction-following demonstrations. Alpaca behaves similarly to OpenAI’s text-davinci-003, while being surprisingly small and easy/cheap to reproduce (<600$).