1,523 posts tagged “datasette”
Datasette is an open source tool for exploring and publishing data.
2024
Add ETag header for static responses. I’ve been procrastinating on adding better caching headers for static assets (JavaScript and CSS) served by Datasette for several years, because I’ve been wanting to implement the perfect solution that sets far-future cache headers on every asset and ensures the URLs change when they are updated.
Agustin Bacigalup just submitted the best kind of pull request: he observed that adding ETag support for static assets would side-step the complexity while adding much of the benefit, and implemented it along with tests.
It’s a substantial performance improvement for any Datasette instance with a number of JavaScript plugins... like the ones we are building on Datasette Cloud. I’m just annoyed we didn’t ship something like this sooner!
Weeknotes: the aftermath of NICAR
NICAR was fantastic this year. Alex and I ran a successful workshop on Datasette and Datasette Cloud, and I gave a lightning talk demonstrating two new GPT-4 powered Datasette plugins—datasette-enrichments-gpt and datasette-extract. I need to write more about the latter one: it enables populating tables from unstructured content (using a variant of this technique) and it’s really effective. I got it working just in time for the conference.
[... 1,430 words]datasette/studio. I’m trying a new way to make Datasette available for small personal data manipulation projects, using GitHub Codespaces.
This repository is designed to be opened directly in Codespaces—detailed instructions in the README.
When the container starts it installs the datasette-studio family of plugins—including CSV upload, some enrichments and a few other useful feature—then starts the server running and provides a big green button to click to access the server via GitHub’s port forwarding mechanism.
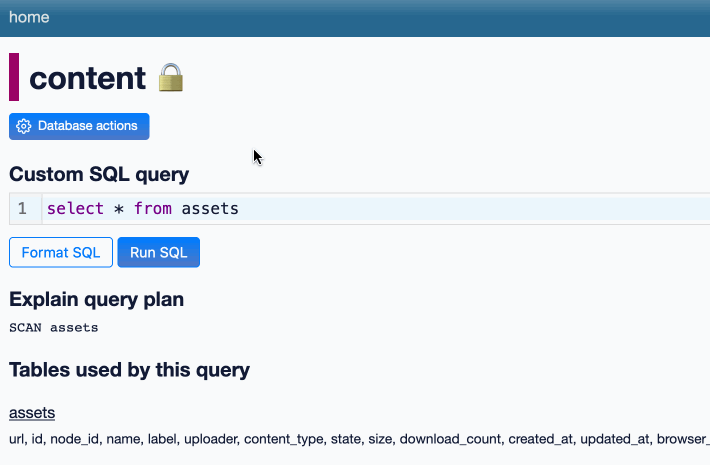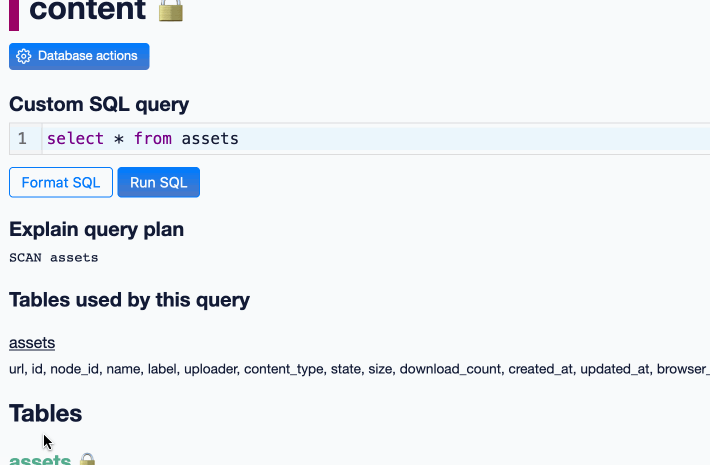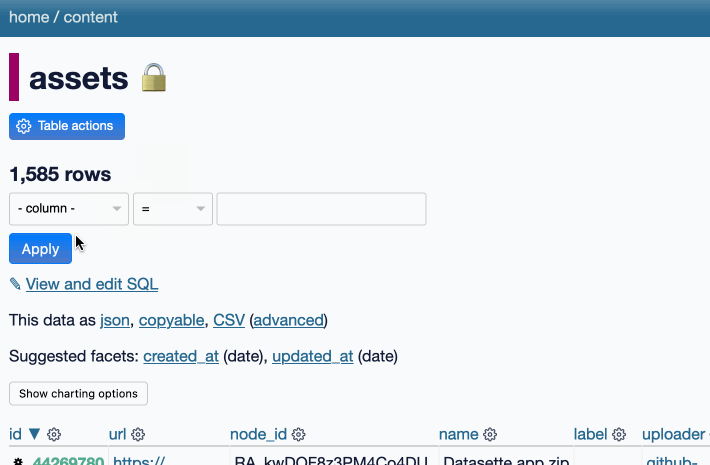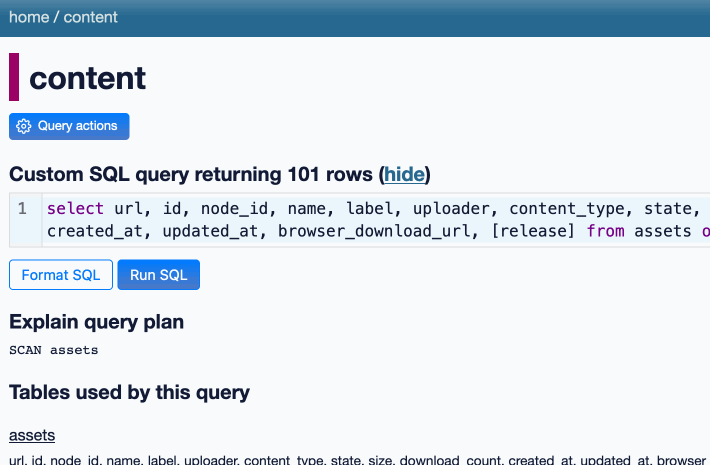
Datasette 1.0a12. Another alpha release, this time with a new query_actions() plugin hook, a new design for the table, database and query actions menus, a “does not contain” table filter and a fix for a minor bug with the JavaScript makeColumnActions() plugin mechanism.