Weeknotes: Python 3.7 on Glitch, datasette-render-markdown
11th November 2019
Streaks is really working well for me. I’m at 12 days of commits to Datasette, 16 posting a daily Niche Museum, 19 of actually reviewing my email inbox and 14 of guitar practice. I rewarded myself for that last one by purchasing an actual classical (as opposed to acoustic) guitar.
Datasette
One downside: since my aim is to land a commit to Datasette master every day, I’m incentivised to land small changes. I have a bunch of much larger Datasette projects in the works—I think my goal for the next week should be to land one of those. Contenders include:
- TableView.data() refactor—a blocker on a bunch of other projects
- Datasette Edit—finish the new connection work so I can have plugins that write changes to databases
- Datasette Library—watch a directory and automatically serve new database files that show up in that directory
- Finish and ship my work on facet-by-many-to-many
- Implement basic join support for table views (so you can join without writing a custom SQL query)
- Probably the most impactful: Datasette needs a website! Up until now I’ve directed people to GitHub or to the documentation but the project has grow to the point that it warrants its own home.
I’m going to redefine my daily goal to include pushing in-progress work to Datasette branches in an attempt to escape that false incentive.
New datasette-csvs using Python 3.7 on Glitch
The main reason I’ve been strict about keeping Datasette compatible with Python 3.5 is that it was the only version supported by Glitch, and Glitch has become my favourite tool for getting people up and running with Datasette quickly.
There’s been a long running Glitch support thread requesting an upgrade, and last week it finally bore fruit. Projects on Glitch now get python3 pointing to Python 3.7.5 instead!
This actually broke my datasette-csvs project at first, because for some reason under Python 3.7 the Pandas dependency used by csvs-to-sqlite started taking up too much space from the 200MB Glitch instance quota. I ended up working around this by switching over to using my sqlite-utils CLI tool instead, which has much lighter dependencies.
I’ve shared the new code for my Glitch project in the datasette-csvs repo on GitHub.
The one thing missing from sqlite-utils insert my.db mytable myfile.csv --csv right now is the ability to run it against multiple files at once—something csvs-to-sqlite handles really well. I ended up finally learning how to use while in bash and wrote the following install.sh shell script:
$ pip3 install -U -r requirements.txt --user && \
mkdir -p .data && \
rm .data/data.db || true && \
for f in *.csv
do
sqlite-utils insert .data/data.db ${f%.*} $f --csv
done
${f%.*} is the bash incantation for stripping off the file extension—so the above evaluates to this for each of the CSV files it finds in the root directory:
$ sqlite-utils insert .data/data.db trees trees.csv --csv
github-to-sqlite releases
I released github-to-sqlite 0.6 with a new sub-command:
$ github-to-sqlite releases github.db simonw/datasette
It grabs all of the releases for a repository using the GitHub releases API.
I’m using this for my personal Dogsheep instance, but I’m also planning to use this for the forthcoming Datasette website—I want to pull together all of the releases of all of the Datasette Ecosystem of projects in one place.
I decided to exercise my new bash while skills and write a script to run by cron once an hour which fetches all of my repos (from both my simonw account and my dogsheep GitHub organization) and then fetches their releases.
Since I don’t want to fetch releases for all 257 of my personal GitHub repos—just the repos which relate to Datasette—I started applying a new datasette-io topic (for datasette.io, my planned website domain) to the repos that I want to pull releases from.
Then I came up with this shell script monstrosity:
#!/bin/bash
# Fetch repos for simonw and dogsheep
github-to-sqlite repos github.db simonw dogsheep -a auth.json
# Fetch releases for the repos tagged 'datasette-io'
sqlite-utils github.db "
select full_name from repos where rowid in (
select repos.rowid from repos, json_each(repos.topics) j
where j.value = 'datasette-io'
)" --csv --no-headers | while read repo;
do github-to-sqlite releases \
github.db $(echo $repo | tr -d '\r') \
-a auth.json;
sleep 2;
done;
Here’s an example of the database this produces, running on Cloud Run: https://github-to-sqlite-releases-j7hipcg4aq-uc.a.run.app
I’m using the ability of sqlite-utils to run a SQL query and return the results as CSV, but without the header row. Then I pipe the results through a while loop and use them to call the github-to-sqlite releases command against each repo.
I ran into a weird bug which turned out to be caused by the CSV output using \r\n which was fed into github-to-sqlite releases as simonw/datasette\r—I fixed that using $(echo $repo | tr -d '\r').
datasette-render-markdown
Now that I have a releases database table with all of the releases of my various packages I want to be able to browse them in one place. I fired up Datasette and realized that the most interesting information is in the body column, which contains markdown.
So I built a plugin for the render_cell plugin hook which safely renders markdown data as HTML. Here’s the full implementation of the plugin:
import bleach
import markdown
from datasette import hookimpl
import jinja2
ALLOWED_TAGS = [
"a", "abbr", "acronym", "b", "blockquote", "code", "em",
"i", "li", "ol", "strong", "ul", "pre", "p", "h1","h2",
"h3", "h4", "h5", "h6",
]
@hookimpl()
def render_cell(value, column):
if not isinstance(value, str):
return None
# Only convert to markdown if table ends in _markdown
if not column.endswith("_markdown"):
return None
# Render it!
html = bleach.linkify(
bleach.clean(
markdown.markdown(value, output_format="html5"),
tags=ALLOWED_TAGS,
)
)
return jinja2.Markup(html)
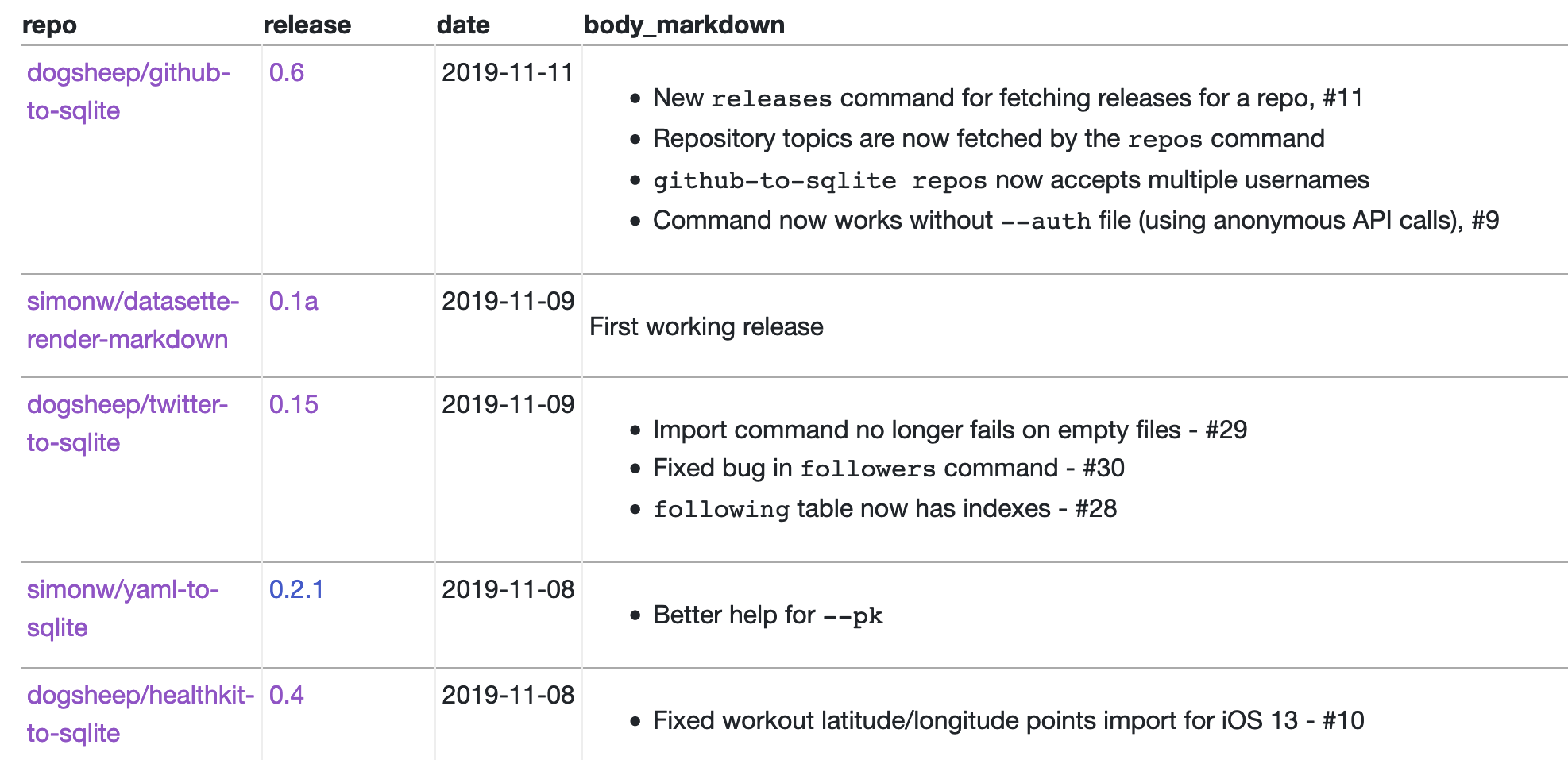
This first release of the plugin just looks for column names that end in _markdown and renders those. So the following SQL query does what I need:
select
json_object("label", repos.full_name, "href", repos.html_url) as repo,
json_object(
"href",
releases.html_url,
"label",
releases.name
) as release,
substr(releases.published_at, 0, 11) as date,
releases.body as body_markdown,
releases.published_at
from
releases
join repos on repos.id = releases.repo
order by
releases.published_at desc
In aliases releases.body to body_markdown to trigger the markdown rendering, and uses json_object(...) to cause datasette-json-html to render some links.
You can see the results here.
More museums
I added another 7 museums to www.niche-museums.com.
- Dingles Fairground Heritage Centre
- Ilfracombe Museum
- Barometer World
- La Galcante
- Musée des Arts et Métiers
- International Women’s Air & Space Museum
- West Kern Oil Museum
More recent articles
- A Fireside Chat with Cat and Thariq from the Claude Code team - 21st July 2026
- Kimi K3, and what we can still learn from the pelican benchmark - 16th July 2026
- The new GPT-5.6 family: Luna, Terra, Sol - 9th July 2026