Posts in Mar, 2024
Filters: Year: 2024 × Month: Mar × Sorted by date
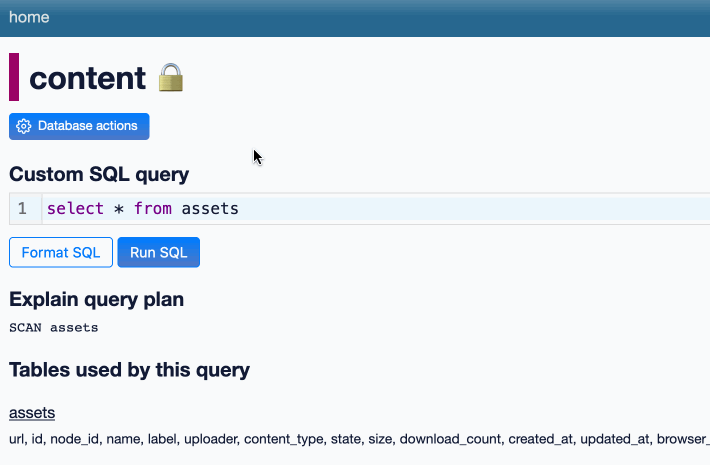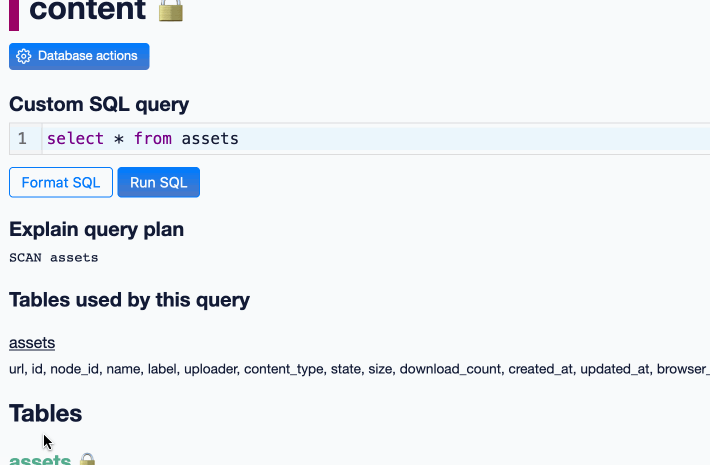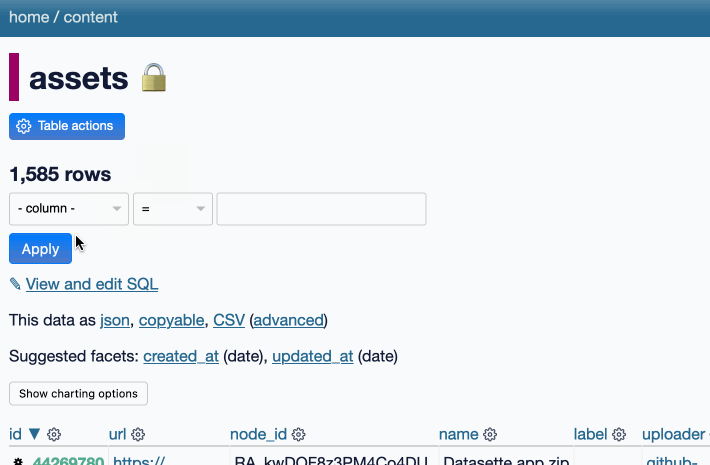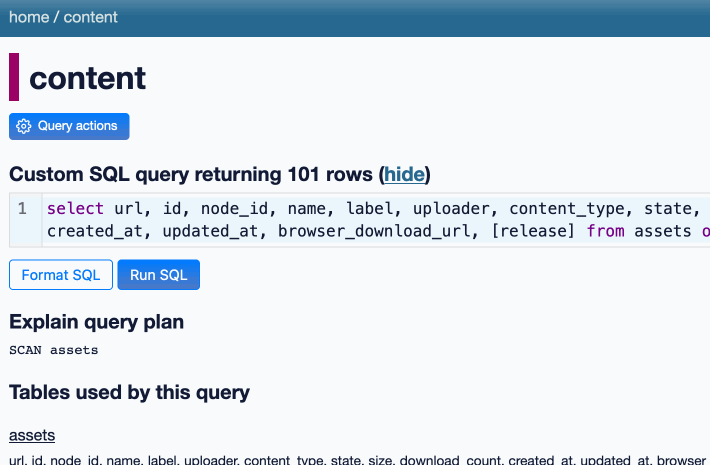
DuckDB as the New jq (via) The DuckDB CLI tool can query JSON files directly, making it a surprisingly effective replacement for jq. Paul Gross demonstrates the following query:
select license->>'key' as license, count(*) from 'repos.json' group by 1
repos.json contains an array of {"license": {"key": "apache-2.0"}..} objects. This example query shows counts for each of those licenses.
Redis Adopts Dual Source-Available Licensing (via) Well this sucks: after fifteen years (and contributions from more than 700 people), Redis is dropping the 3-clause BSD license going forward, instead being “dual-licensed under the Redis Source Available License (RSALv2) and Server Side Public License (SSPLv1)” from Redis 7.4 onwards.
I think most people have this naive idea of consensus meaning “everyone agrees”. That’s not what consensus means, as practiced by organizations that truly have a mature and well developed consensus driven process.
Consensus is not “everyone agrees”, but [a model where] people are more aligned with the process than they are with any particular outcome, and they’ve all agreed on how decisions will be made.
Talking about Django’s history and future on Django Chat (via) Django co-creator Jacob Kaplan-Moss sat down with the Django Chat podcast team to talk about Django’s history, his recent return to the Django Software Foundation board and what he hopes to achieve there.
Here’s his post about it, where he used Whisper and Claude to extract some of his own highlights from the conversation.
GitHub Public repo history tool (via) I built this Observable Notebook to run queries against the GH Archive (via ClickHouse) to try to answer questions about repository history—in particular, were they ever made public as opposed to private in the past.
It works by combining together PublicEvent event (moments when a private repo was made public) with the most recent PushEvent event for each of a user’s repositories.
Releasing Common Corpus: the largest public domain dataset for training LLMs (via) Released today. 500 billion words from "a wide diversity of cultural heritage initiatives". 180 billion words of English, 110 billion of French, 30 billion of German, then Dutch, Spanish and Italian.
Includes quite a lot of US public domain data - 21 million digitized out-of-copyright newspapers (or do they mean newspaper articles?)
This is only an initial part of what we have collected so far, in part due to the lengthy process of copyright duration verification. In the following weeks and months, we’ll continue to publish many additional datasets also coming from other open sources, such as open data or open science.
Coordinated by French AI startup Pleias and supported by the French Ministry of Culture, among others.
I can't wait to try a model that's been trained on this.
Skew protection in Vercel (via) Version skew is a name for the bug that occurs when your user loads a web application and then unintentionally keeps that browser tab open across a deployment of a new version of the app. If you’re unlucky this can lead to broken behaviour, where a client makes a call to a backend endpoint that has changed in an incompatible way.
Vercel have an ingenious solution to this problem. Their platform already makes it easy to deploy many different instances of an application. You can now turn on “skew protection” for a number of hours which will keep older versions of your backend deployed.
The application itself can then include its desired deployment ID in a x-deployment-id header, a __vdpl cookie or a ?dpl= query string parameter.
Every dunder method in Python. Trey Hunner: "Python includes 103 'normal' dunder methods, 12 library-specific dunder methods, and at least 52 other dunder attributes of various types."
This cheat sheet doubles as a tour of many of the more obscure corners of the Python language and standard library.
I did not know that Python has over 100 dunder methods now! Quite a few of these were new to me, like __class_getitem__ which can be used to implement type annotations such as list[int].
AI Prompt Engineering Is Dead. Long live AI prompt engineering. Ignoring the clickbait in the title, this article summarizes research around the idea of using machine learning models to optimize prompts—as seen in tools such as Stanford’s DSPy and Google’s OPRO.
The article includes possibly the biggest abuse of the term “just” I have ever seen:
“But that’s where hopefully this research will come in and say ‘don’t bother.’ Just develop a scoring metric so that the system itself can tell whether one prompt is better than another, and then just let the model optimize itself.”
Developing a scoring metric to determine which prompt works better remains one of the hardest challenges in generative AI!
Imagine if we had a discipline of engineers who could reliably solve that problem—who spent their time developing such metrics and then using them to optimize their prompts. If the term “prompt engineer” hadn’t already been reduced to basically meaning “someone who types out prompts” it would be a pretty fitting term for such experts.
Papa Parse (via) I’ve been trying out this JavaScript library for parsing CSV and TSV data today and I’m very impressed. It’s extremely fast, has all of the advanced features I want (streaming support, optional web workers, automatically detecting delimiters and column types), has zero dependencies and weighs just 19KB minified—6.8KB gzipped.
The project is 11 years old now. It was created by Matt Holt, who later went on to create the Caddy web server. Today it’s maintained by Sergi Almacellas Abellana.
People share a lot of sensitive material on Quora - controversial political views, workplace gossip and compensation, and negative opinions held of companies. Over many years, as they change jobs or change their views, it is important that they can delete or anonymize their previously-written answers.
We opt out of the wayback machine because inclusion would allow people to discover the identity of authors who had written sensitive answers publicly and later had made them anonymous, and because it would prevent authors from being able to remove their content from the internet if they change their mind about publishing it.
DiskCache (via) Grant Jenks built DiskCache as an alternative caching backend for Django (also usable without Django), using a SQLite database on disk. The performance numbers are impressive—it even beats memcached in microbenchmarks, due to avoiding the need to access the network.
The source code (particularly in core.py) is a great case-study in SQLite performance optimization, after five years of iteration on making it all run as fast as possible.
The Tokenizer Playground (via) I built a tool like this a while ago, but this one is much better: it provides an interface for experimenting with tokenizers from a wide range of model architectures, including Llama, Claude, Mistral and Grok-1—all running in the browser using Transformers.js.
900 Sites, 125 million accounts, 1 vulnerability (via) Google’s Firebase development platform encourages building applications (mobile an web) which talk directly to the underlying data store, reading and writing from “collections” with access protected by Firebase Security Rules.
Unsurprisingly, a lot of development teams make mistakes with these.
This post describes how a security research team built a scanner that found over 124 million unprotected records across 900 different applications, including huge amounts of PII: 106 million email addresses, 20 million passwords (many in plaintext) and 27 million instances of “Bank details, invoices, etc”.
Most worrying of all, only 24% of the site owners they contacted shipped a fix for the misconfiguration.
It's hard to overstate the value of LLM support when coding for fun in an unfamiliar language. [...] This example is totally trivial in hindsight, but might have taken me a couple mins to figure out otherwise. This is a bigger deal than it seems! Papercuts add up fast and prevent flow. (A lot of being a senior engineer is just being proficient enough to avoid papercuts).
Grok-1 code and model weights release (via) xAI have released their Grok-1 model under an Apache 2 license (for both weights and code). It's distributed as a 318.24G torrent file and likely requires 320GB of VRAM to run, so needs some very hefty hardware.
The accompanying blog post says "Trained from scratch by xAI using a custom training stack on top of JAX and Rust in October 2023", and describes it as a "314B parameter Mixture-of-Experts model with 25% of the weights active on a given token".
Very little information on what it was actually trained on, all we know is that it was "a large amount of text data, not fine-tuned for any particular task".
Add ETag header for static responses. I’ve been procrastinating on adding better caching headers for static assets (JavaScript and CSS) served by Datasette for several years, because I’ve been wanting to implement the perfect solution that sets far-future cache headers on every asset and ensures the URLs change when they are updated.
Agustin Bacigalup just submitted the best kind of pull request: he observed that adding ETag support for static assets would side-step the complexity while adding much of the benefit, and implemented it along with tests.
It’s a substantial performance improvement for any Datasette instance with a number of JavaScript plugins... like the ones we are building on Datasette Cloud. I’m just annoyed we didn’t ship something like this sooner!
How does SQLite store data? Michal Pitr explores the design of the SQLite on-disk file format, as part of building an educational implementation of SQLite from scratch in Go.
Weeknotes: the aftermath of NICAR
NICAR was fantastic this year. Alex and I ran a successful workshop on Datasette and Datasette Cloud, and I gave a lightning talk demonstrating two new GPT-4 powered Datasette plugins—datasette-enrichments-gpt and datasette-extract. I need to write more about the latter one: it enables populating tables from unstructured content (using a variant of this technique) and it’s really effective. I got it working just in time for the conference.
[... 1,430 words]One year since GPT-4 release. Hope you all enjoyed some time to relax; it’ll have been the slowest 12 months of AI progress for quite some time to come.
— Leopold Aschenbrenner, OpenAI
npm install everything, and the complete and utter chaos that follows (via) Here’s an experiment which went really badly wrong: a team of mostly-students decided to see if it was possible to install every package from npm (all 2.5 million of them) on the same machine. As part of that experiment they created and published their own npm package that depended on every other package in the registry.
Unfortunately, in response to the leftpad incident a few years ago npm had introduced a policy that a package cannot be removed from the registry if there exists at least one other package that lists it as a dependency. The new “everything” package inadvertently prevented all 2.5m packages—including many that had no other dependencies—from ever being removed!
Phanpy. Phanpy is "a minimalistic opinionated Mastodon web client" by Chee Aun.
I think that description undersells it. It's beautifully crafted and designed and has a ton of innovative ideas - they way it displays threads and replies, the "Catch-up" beta feature, it's all a really thoughtful and fresh perspective on how Mastodon can work.
I love that all Mastodon servers (including my own dedicated instance) offer a CORS-enabled JSON API which directly supports building these kinds of alternative clients.
Building a full-featured client like this one is a huge amount of work, but building a much simpler client that just displays the user's incoming timeline could be a pretty great educational project for people who are looking to deepen their front-end development skills.
Google Scholar search: “certainly, here is” -chatgpt -llm (via) Searching Google Scholar for “certainly, here is” turns up a huge number of academic papers that include parts that were evidently written by ChatGPT—sections that start with “Certainly, here is a concise summary of the provided sections:” are a dead giveaway.
Advanced Topics in Reminders and To Do Lists. Fred Benenson’s advanced guide to the Apple Reminders ecosystem. I live my life by Reminders—I particularly like that you can set them with Siri, so “Hey Siri, remind me to check the chickens made it to bed at 7pm every evening” sets up a recurring reminder without having to fiddle around in the UI. Fred has some useful tips here I hadn’t seen before.
How Figma’s databases team lived to tell the scale (via) The best kind of scaling war story:
"Figma’s database stack has grown almost 100x since 2020. [...] In 2020, we were running a single Postgres database hosted on AWS’s largest physical instance, and by the end of 2022, we had built out a distributed architecture with caching, read replicas, and a dozen vertically partitioned databases."
I like the concept of "colos", their internal name for sharded groups of related tables arranged such that those tables can be queried using joins.
Also smart: separating the migration into "logical sharding" - where queries all still run against a single database, even though they are logically routed as if the database was already sharded - followed by "physical sharding" where the data is actually copied to and served from the new database servers.
Logical sharding was implemented using PostgreSQL views, which can accept both reads and writes:
CREATE VIEW table_shard1 AS SELECT * FROM table
WHERE hash(shard_key) >= min_shard_range AND hash(shard_key) < max_shard_range)
The final piece of the puzzle was DBProxy, a custom PostgreSQL query proxy written in Go that can parse the query to an AST and use that to decide which shard the query should be sent to. Impressively it also has a scatter-gather mechanism, so select * from table can be sent to all shards at once and the results combined back together again.
Lateral Thinking with Withered Technology. Gunpei Yokoi’s product design philosophy at Nintendo (“Withered” is also sometimes translated as “Weathered”). Use “mature technology that can be mass-produced cheaply”, then apply lateral thinking to find radical new ways to use it.
This has echos for me of Dan McKinley’s “Choose Boring Technology”, which argues that in software projects you should default to a proven, stable stack so you can focus your innovation tokens on the problems that are unique to your project.
Guidepup. I’ve been hoping to find something like this for years. Guidepup is “a screen reader driver for test automation”—you can use it to automate both VoiceOver on macOS and NVDA on Windows, and it can both drive the screen reader for automated tests and even produce a video at the end of the test.
Also available: @guidepup/playwright, providing integration with the Playwright browser automation testing framework.
I’d love to see open source JavaScript libraries both use something like this for their testing and publish videos of the tests to demonstrate how they work in these common screen readers.
llm-claude-3 0.3. Anthropic released Claude 3 Haiku today, their least expensive model: $0.25/million tokens of input, $1.25/million of output (GPT-3.5 Turbo is $0.50/$1.50). Unlike GPT-3.5 Haiku also supports image inputs.
I just released a minor update to my llm-claude-3 LLM plugin adding support for the new model.
Berkeley Function-Calling Leaderboard. The team behind Berkeley’s Gorilla OpenFunctions model—an Apache 2 licensed LLM trained to provide OpenAI-style structured JSON functions—also maintain a leaderboard of different function-calling models. Their own Gorilla model is the only non-proprietary model in the top ten.
The talk track I've been using is that LLMs are easy to take to market, but hard to keep in the market long-term. All the hard stuff comes when you move past the demo and get exposure to real users.
And that's where you find that all the nice little things you got neatly working fall apart. And you need to prompt differently, do different retrieval, consider fine-tuning, redesign interaction, etc. People will treat this stuff differently from "normal" products, creating unique challenges.