Posts tagged sqlite, llms
Filters: sqlite × llms × Sorted by date
Phoenix.new is Fly’s entry into the prompt-driven app development space
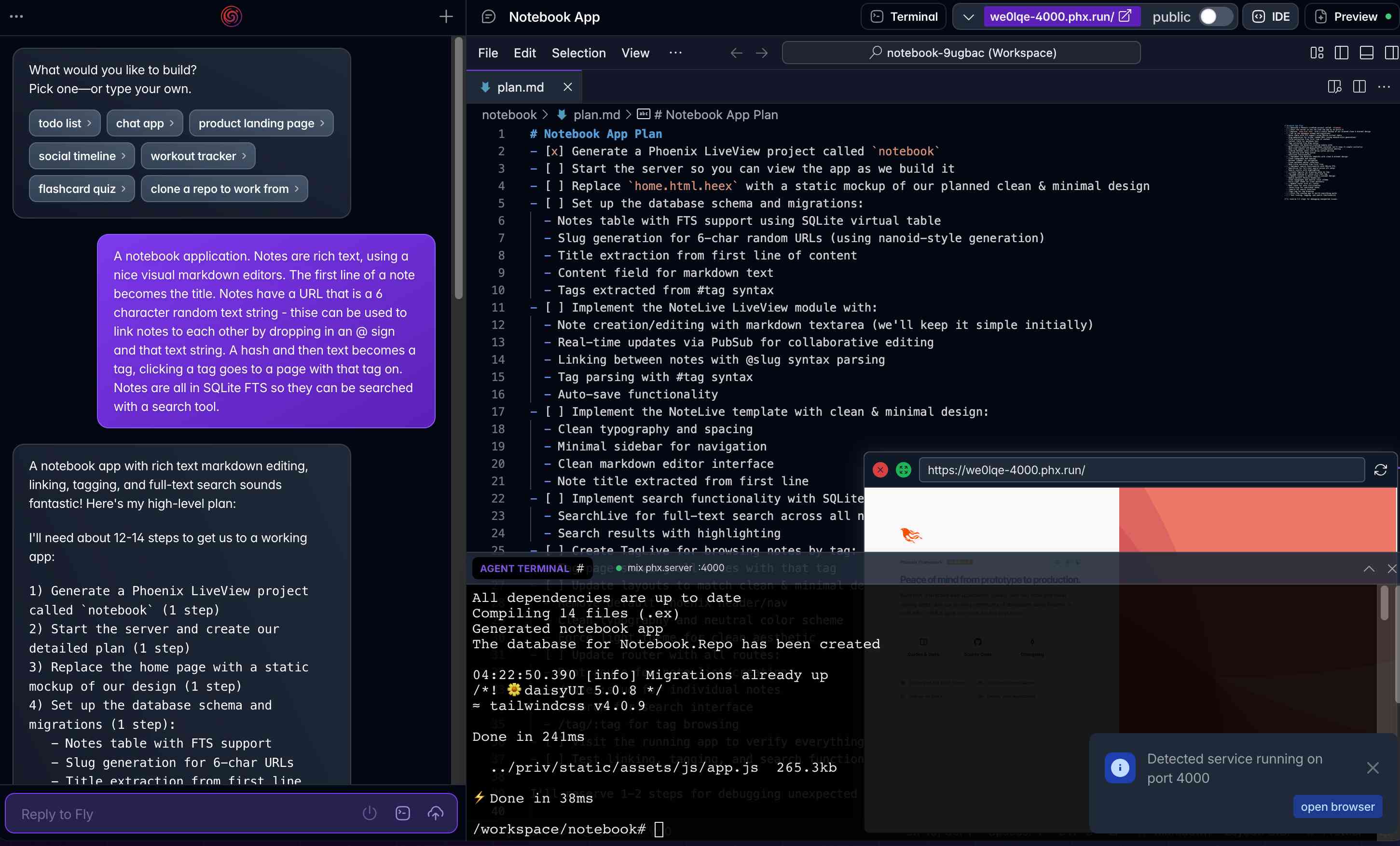
Here’s a fascinating new entrant into the AI-assisted-programming / coding-agents space by Fly.io, introduced on their blog in Phoenix.new – The Remote AI Runtime for Phoenix: describe an app in a prompt, get a full Phoenix application, backed by SQLite and running on Fly’s hosting platform. The official Phoenix.new YouTube launch video is a good way to get a sense for what this does.
[... 1,361 words]Stevens: a hackable AI assistant using a single SQLite table and a handful of cron jobs. Geoffrey Litt reports on Stevens, a shared digital assistant he put together for his family using SQLite and scheduled tasks running on Val Town.
The design is refreshingly simple considering how much it can do. Everything works around a single memories table. A memory has text, tags, creation metadata and an optional date for things like calendar entries and weather reports.
Everything else is handled by scheduled jobs to popular weather information and events from Google Calendar, a Telegram integration offering a chat UI and a neat system where USPS postal email delivery notifications are run through Val's own email handling mechanism to trigger a Claude prompt to add those as memories too.
Here's the full code on Val Town, including the daily briefing prompt that incorporates most of the personality of the bot.
files-to-prompt 0.5.
My files-to-prompt tool (originally built using Claude 3 Opus back in April) had been accumulating a bunch of issues and PRs - I finally got around to spending some time with it and pushed a fresh release:
- New
-n/--line-numbersflag for including line numbers in the output. Thanks, Dan Clayton. #38- Fix for utf-8 handling on Windows. Thanks, David Jarman. #36
--ignorepatterns are now matched against directory names as well as file names, unless you pass the new--ignore-files-onlyflag. Thanks, Nick Powell. #30
I use this tool myself on an almost daily basis - it's fantastic for quickly answering questions about code. Recently I've been plugging it into Gemini 2.0 with its 2 million token context length, running recipes like this one:
git clone https://github.com/bytecodealliance/componentize-py
cd componentize-py
files-to-prompt . -c | llm -m gemini-2.0-pro-exp-02-05 \
-s 'How does this work? Does it include a python compiler or AST trick of some sort?'
I ran that question against the bytecodealliance/componentize-py repo - which provides a tool for turning Python code into compiled WASM - and got this really useful answer.
Here's another example. I decided to have o3-mini review how Datasette handles concurrent SQLite connections from async Python code - so I ran this:
git clone https://github.com/simonw/datasette
cd datasette/datasette
files-to-prompt database.py utils/__init__.py -c | \
llm -m o3-mini -o reasoning_effort high \
-s 'Output in markdown a detailed analysis of how this code handles the challenge of running SQLite queries from a Python asyncio application. Explain how it works in the first section, then explore the pros and cons of this design. In a final section propose alternative mechanisms that might work better.'
Here's the result. It did an extremely good job of explaining how my code works - despite being fed just the Python and none of the other documentation. Then it made some solid recommendations for potential alternatives.
I added a couple of follow-up questions (using llm -c) which resulted in a full working prototype of an alternative threadpool mechanism, plus some benchmarks.
One final example: I decided to see if there were any undocumented features in Litestream, so I checked out the repo and ran a prompt against just the .go files in that project:
git clone https://github.com/benbjohnson/litestream
cd litestream
files-to-prompt . -e go -c | llm -m o3-mini \
-s 'Write extensive user documentation for this project in markdown'
Once again, o3-mini provided a really impressively detailed set of unofficial documentation derived purely from reading the source.
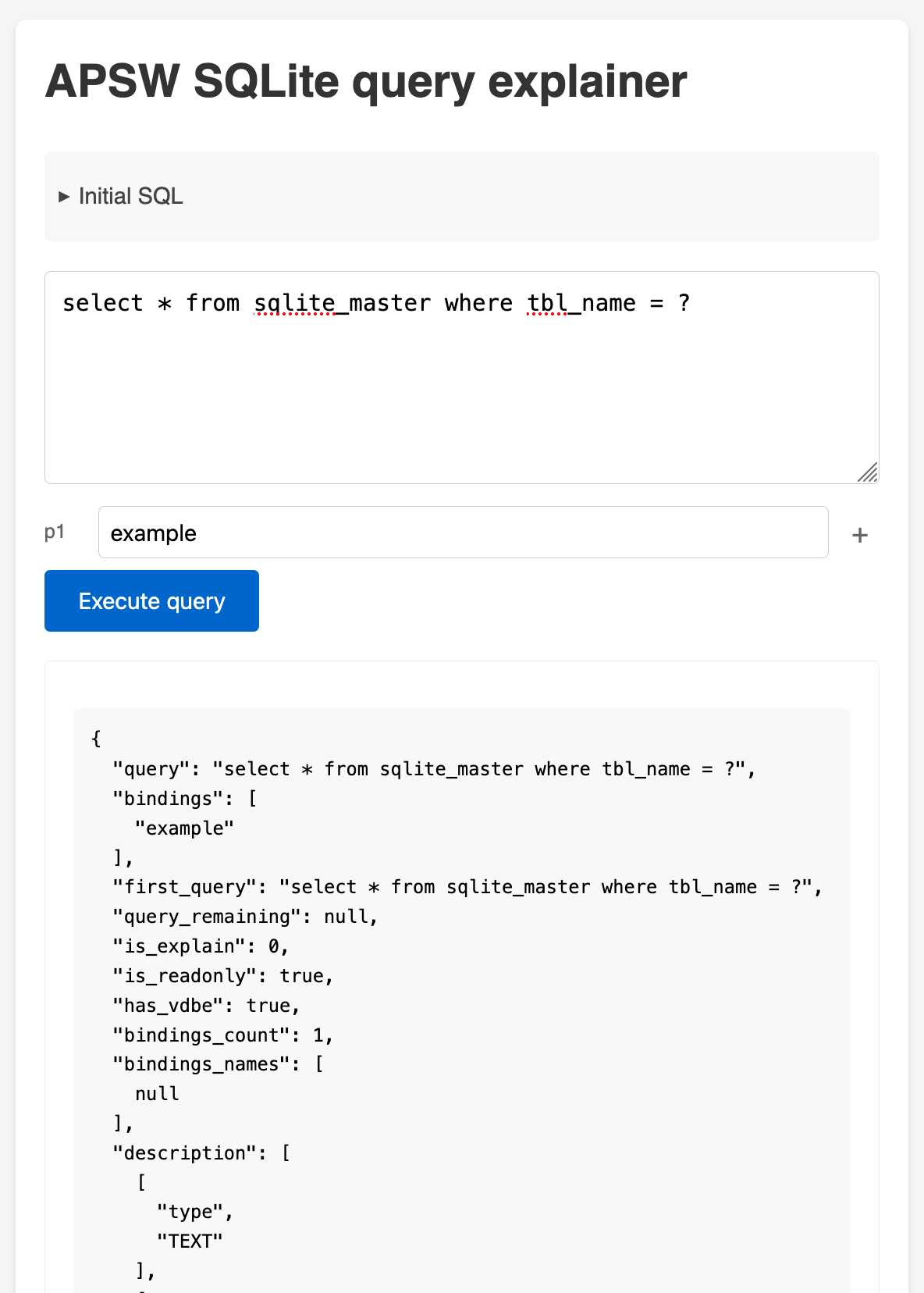
APSW SQLite query explainer. Today I found out about APSW's (Another Python SQLite Wrapper, in constant development since 2004) apsw.ext.query_info() function, which takes a SQL query and returns a very detailed set of information about that query - all without executing it.
It actually solves a bunch of problems I've wanted to address in Datasette - like taking an arbitrary query and figuring out how many parameters (?) it takes and which tables and columns are represented in the result.
I tried it out in my console (uv run --with apsw python) and it seemed to work really well. Then I remembered that the Pyodide project includes WebAssembly builds of a number of Python C extensions and was delighted to find apsw on that list.
... so I got Claude to build me a web interface for trying out the function, using Pyodide to run a user's query in Python in their browser via WebAssembly.
Claude didn't quite get it in one shot - I had to feed it the URL to a more recent Pyodide and it got stuck in a bug loop which I fixed by pasting the code into a fresh session.
Open WebUI. I tried out this open source (MIT licensed, JavaScript and Python) localhost UI for accessing LLMs today for the first time. It's very nicely done.
I ran it with uvx like this:
uvx --python 3.11 open-webui serve
On first launch it installed a bunch of dependencies and then downloaded 903MB to ~/.cache/huggingface/hub/models--sentence-transformers--all-MiniLM-L6-v2 - a copy of the all-MiniLM-L6-v2 embedding model, presumably for its RAG feature.
It then presented me with a working Llama 3.2:3b chat interface, which surprised me because I hadn't spotted it downloading that model. It turns out that was because I have Ollama running on my laptop already (with several models, including Llama 3.2:3b, already installed) - and Open WebUI automatically detected Ollama and gave me access to a list of available models.
I found a "knowledge" section and added all of the Datasette documentation (by dropping in the .rst files from the docs) - and now I can type # in chat to search for a file, add that to the context and then ask questions about it directly.
I selected the spatialite.rst.txt file, prompted it with "How do I use SpatiaLite with Datasette" and got back this:
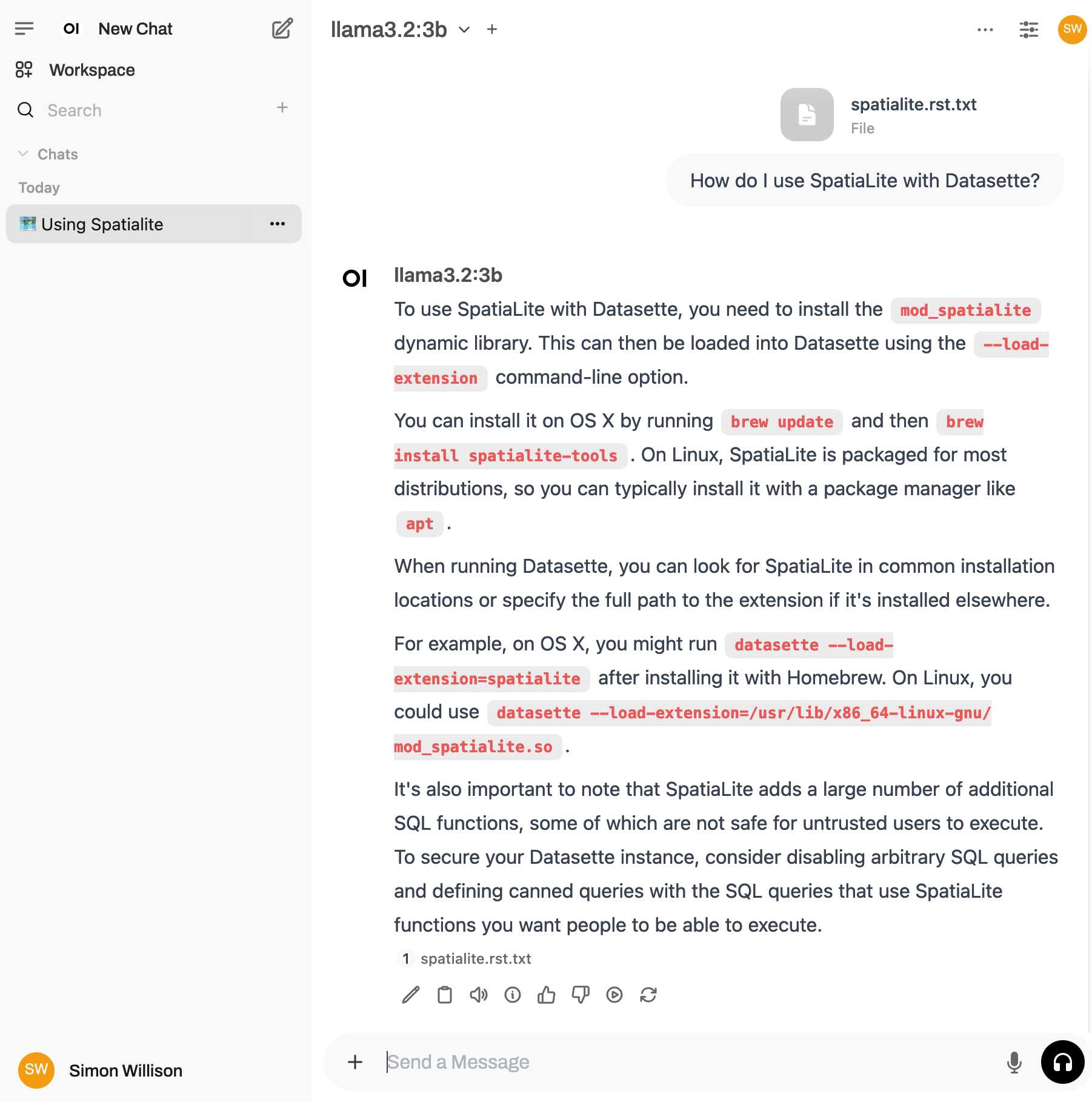
That's honestly a very solid answer, especially considering the Llama 3.2 3B model from Ollama is just a 1.9GB file! It's impressive how well that model can handle basic Q&A and summarization against text provided to it - it somehow has a 128,000 token context size.
Open WebUI has a lot of other tricks up its sleeve: it can talk to API models such as OpenAI directly, has optional integrations with web search and custom tools and logs every interaction to a SQLite database. It also comes with extensive documentation.
Introducing the Model Context Protocol (via) Interesting new initiative from Anthropic. The Model Context Protocol aims to provide a standard interface for LLMs to interact with other applications, allowing applications to expose tools, resources (contant that you might want to dump into your context) and parameterized prompts that can be used by the models.
Their first working version of this involves the Claude Desktop app (for macOS and Windows). You can now configure that app to run additional "servers" - processes that the app runs and then communicates with via JSON-RPC over standard input and standard output.
Each server can present a list of tools, resources and prompts to the model. The model can then make further calls to the server to request information or execute one of those tools.
(For full transparency: I got a preview of this last week, so I've had a few days to try it out.)
The best way to understand this all is to dig into the examples. There are 13 of these in the modelcontextprotocol/servers GitHub repository so far, some using the Typesscript SDK and some with the Python SDK (mcp on PyPI).
My favourite so far, unsurprisingly, is the sqlite one. This implements methods for Claude to execute read and write queries and create tables in a SQLite database file on your local computer.
This is clearly an early release: the process for enabling servers in Claude Desktop - which involves hand-editing a JSON configuration file - is pretty clunky, and currently the desktop app and running extra servers on your own machine is the only way to try this out.
The specification already describes the next step for this: an HTTP SSE protocol which will allow Claude (and any other software that implements the protocol) to communicate with external HTTP servers. Hopefully this means that MCP will come to the Claude web and mobile apps soon as well.
A couple of early preview partners have announced their MCP implementations already:
- Cody supports additional context through Anthropic's Model Context Protocol
- The Context Outside the Code is the Zed editor's announcement of their MCP extensions.
Ask questions of SQLite databases and CSV/JSON files in your terminal
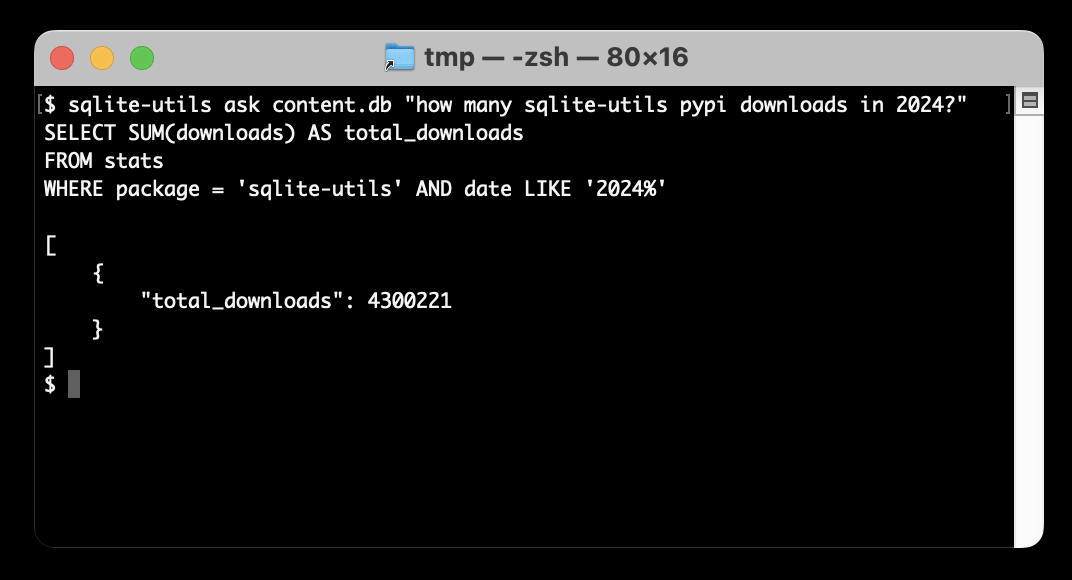
I built a new plugin for my sqlite-utils CLI tool that lets you ask human-language questions directly of SQLite databases and CSV/JSON files on your computer.
[... 723 words]From Naptime to Big Sleep: Using Large Language Models To Catch Vulnerabilities In Real-World Code (via) Google's Project Zero security team used a system based around Gemini 1.5 Pro to find a previously unreported security vulnerability in SQLite (a stack buffer underflow), in time for it to be fixed prior to making it into a release.
A key insight here is that LLMs are well suited for checking for new variants of previously reported vulnerabilities:
A key motivating factor for Naptime and now for Big Sleep has been the continued in-the-wild discovery of exploits for variants of previously found and patched vulnerabilities. As this trend continues, it's clear that fuzzing is not succeeding at catching such variants, and that for attackers, manual variant analysis is a cost-effective approach.
We also feel that this variant-analysis task is a better fit for current LLMs than the more general open-ended vulnerability research problem. By providing a starting point – such as the details of a previously fixed vulnerability – we remove a lot of ambiguity from vulnerability research, and start from a concrete, well-founded theory: "This was a previous bug; there is probably another similar one somewhere".
LLMs are great at pattern matching. It turns out feeding in a pattern describing a prior vulnerability is a great way to identify potential new ones.
System prompt for val.town/townie (via) Val Town (previously) provides hosting and a web-based coding environment for Vals - snippets of JavaScript/TypeScript that can run server-side as scripts, on a schedule or hosting a web service.
Townie is Val's new AI bot, providing a conversational chat interface for creating fullstack web apps (with blob or SQLite persistence) as Vals.
In the most recent release of Townie Val added the ability to inspect and edit its system prompt!
I've archived a copy in this Gist, as a snapshot of how Townie works today. It's surprisingly short, relying heavily on the model's existing knowledge of Deno and TypeScript.
I enjoyed the use of "tastefully" in this bit:
Tastefully add a view source link back to the user's val if there's a natural spot for it and it fits in the context of what they're building. You can generate the val source url via import.meta.url.replace("esm.town", "val.town").
The prompt includes a few code samples, like this one demonstrating how to use Val's SQLite package:
import { sqlite } from "https://esm.town/v/stevekrouse/sqlite";
let KEY = new URL(import.meta.url).pathname.split("/").at(-1);
(await sqlite.execute(`select * from ${KEY}_users where id = ?`, [1])).rows[0].idIt also reveals the existence of Val's very own delightfully simple image generation endpoint Val, currently powered by Stable Diffusion XL Lightning on fal.ai.
If you want an AI generated image, use https://maxm-imggenurl.web.val.run/the-description-of-your-image to dynamically generate one.
Here's a fun colorful raccoon with a wildly inappropriate hat.
Val are also running their own gpt-4o-mini proxy, free to users of their platform:
import { OpenAI } from "https://esm.town/v/std/openai";
const openai = new OpenAI();
const completion = await openai.chat.completions.create({
messages: [
{ role: "user", content: "Say hello in a creative way" },
],
model: "gpt-4o-mini",
max_tokens: 30,
});Val developer JP Posma wrote a lot more about Townie in How we built Townie – an app that generates fullstack apps, describing their prototyping process and revealing that the current model it's using is Claude 3.5 Sonnet.
Their current system prompt was refined over many different versions - initially they were including 50 example Vals at quite a high token cost, but they were able to reduce that down to the linked system prompt which includes condensed documentation and just one templated example.
Explain ACLs by showing me a SQLite table schema for implementing them. Here’s an example transcript showing one of the common ways I use LLMs. I wanted to develop an understanding of ACLs - Access Control Lists - but I’ve found previous explanations incredibly dry. So I prompted Claude 3.5 Sonnet:
Explain ACLs by showing me a SQLite table schema for implementing them
Asking for explanations using the context of something I’m already fluent in is usually really effective, and an great way to take advantage of the weird abilities of frontier LLMs.
I exported the transcript to a Gist using my Convert Claude JSON to Markdown tool, which I just upgraded to support syntax highlighting of code in artifacts.
Building and testing C extensions for SQLite with ChatGPT Code Interpreter
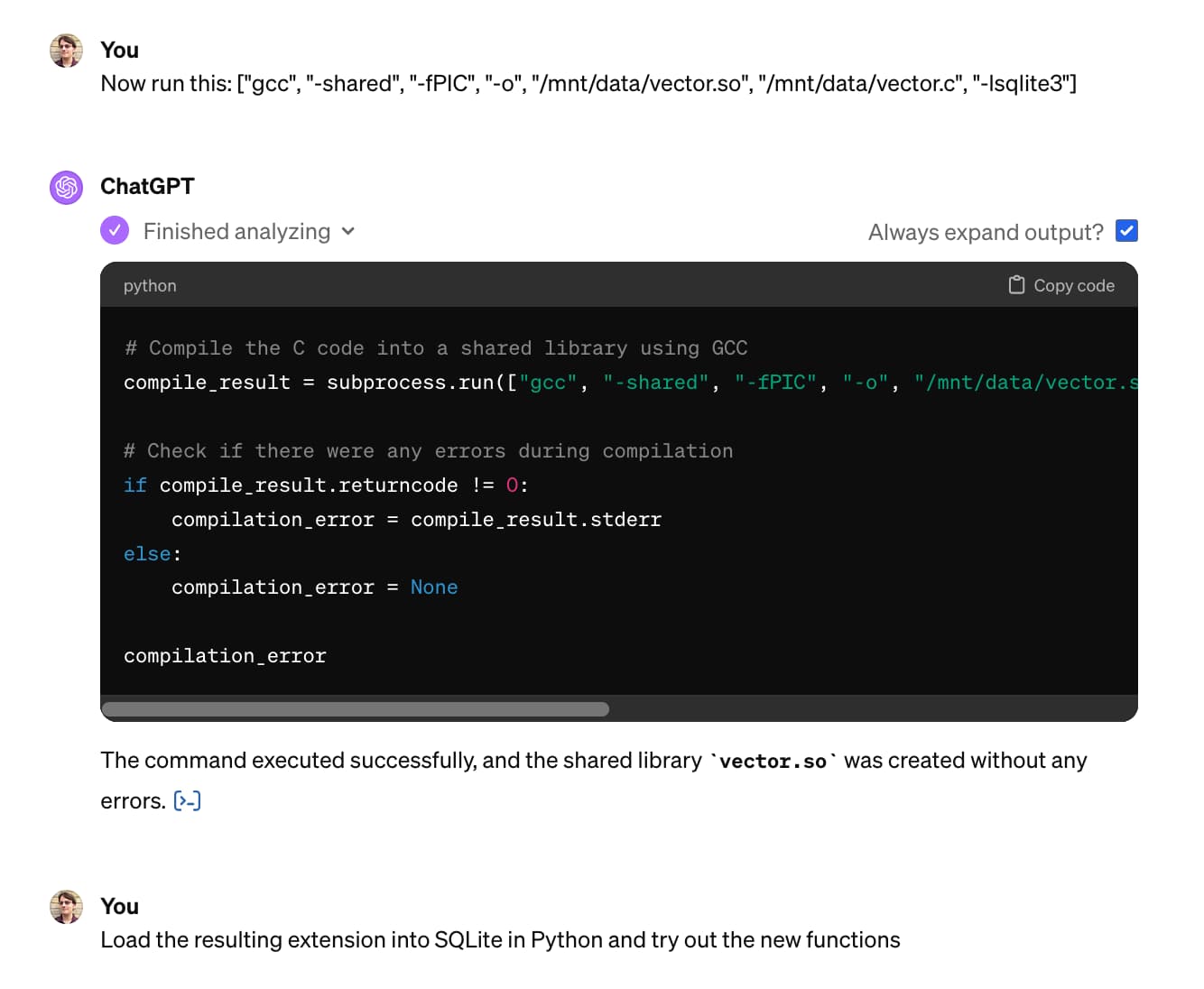
I wrote yesterday about how I used Claude and ChatGPT Code Interpreter for simple ad-hoc side quests—in that case, for converting a shapefile to GeoJSON and merging it into a single polygon.
[... 4,612 words]Weeknotes: the Datasette Cloud API, a podcast appearance and more
Datasette Cloud now has a documented API, plus a podcast appearance, some LLM plugins work and some geospatial excitement.
[... 1,243 words]LLM now provides tools for working with embeddings

LLM is my Python library and command-line tool for working with language models. I just released LLM 0.9 with a new set of features that extend LLM to provide tools for working with embeddings.
[... 3,521 words]Enriching data with GPT3.5 and SQLite SQL functions
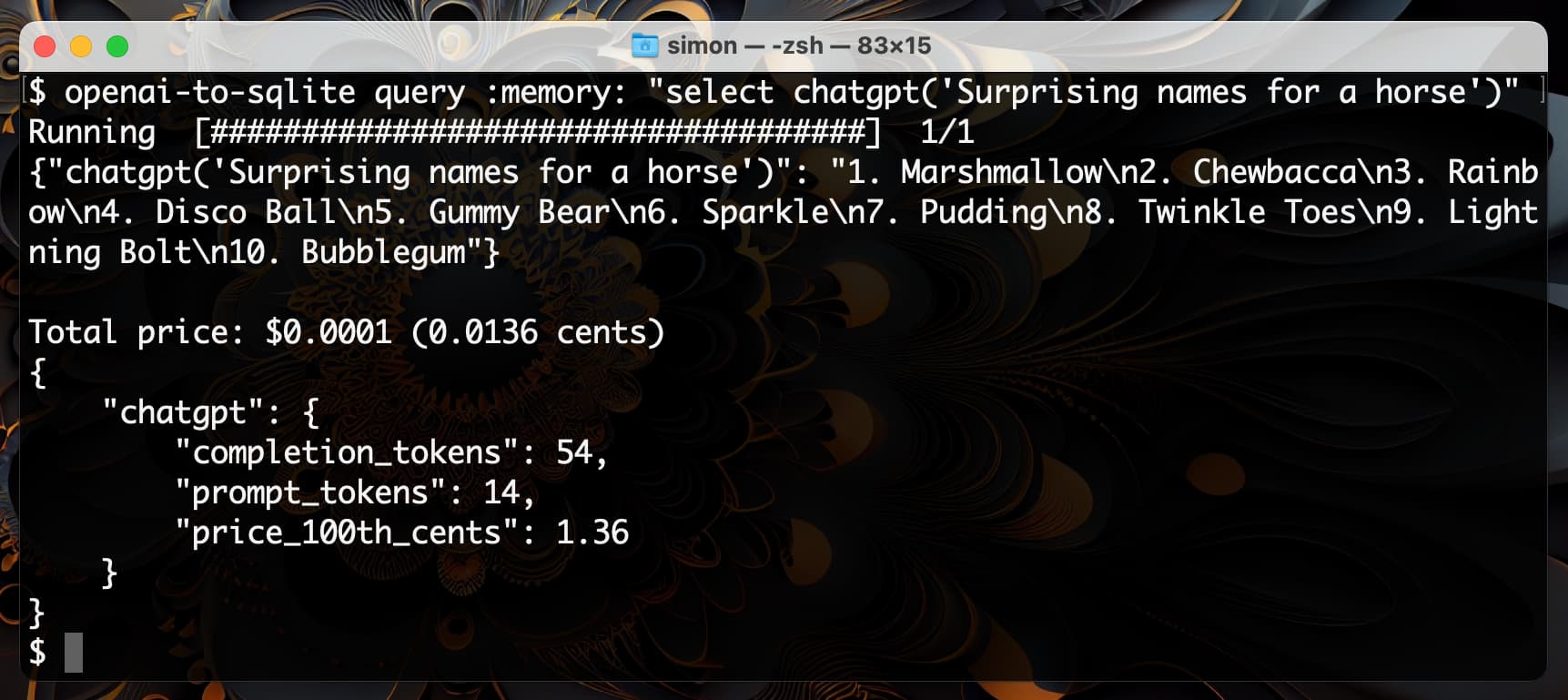
I shipped openai-to-sqlite 0.3 yesterday with a fun new feature: you can now use the command-line tool to enrich data in a SQLite database by running values through an OpenAI model and saving the results, all in a single SQL query.
[... 1,219 words]Replacing my best friends with an LLM trained on 500,000 group chat messages (via) Izzy Miller used a 7 year long group text conversation with five friends from college to fine-tune LLaMA, such that it could simulate ongoing conversations. They started by extracting the messages from the iMessage SQLite database on their Mac, then generated a new training set from those messages and ran it using code from the Stanford Alpaca repository. This is genuinely one of the clearest explanations of the process of fine-tuning a model like this I’ve seen anywhere.
Running Python micro-benchmarks using the ChatGPT Code Interpreter alpha
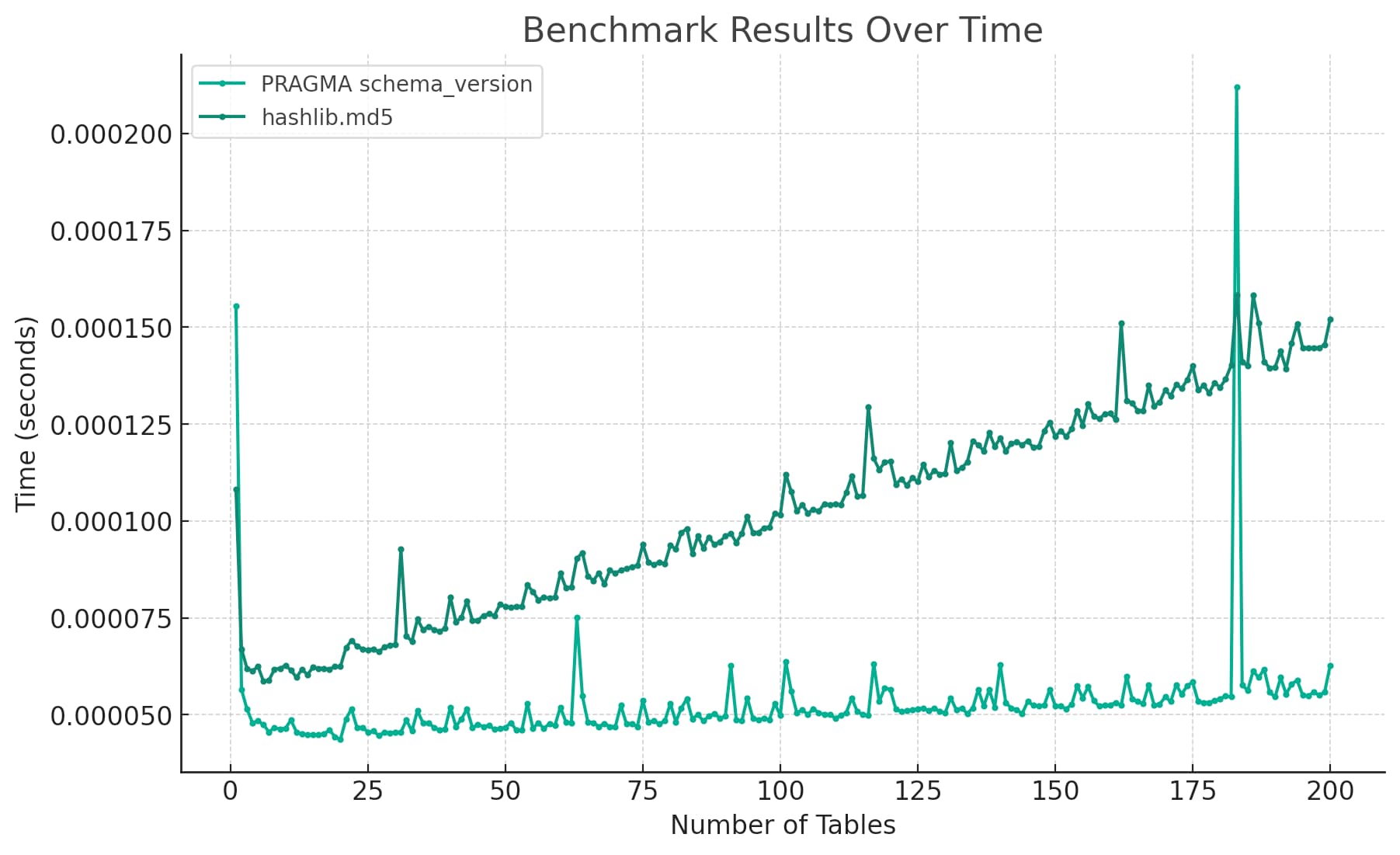
Today I wanted to understand the performance difference between two Python implementations of a mechanism to detect changes to a SQLite database schema. I rendered the difference between the two as this chart:
[... 2,939 words]How to implement Q&A against your documentation with GPT3, embeddings and Datasette
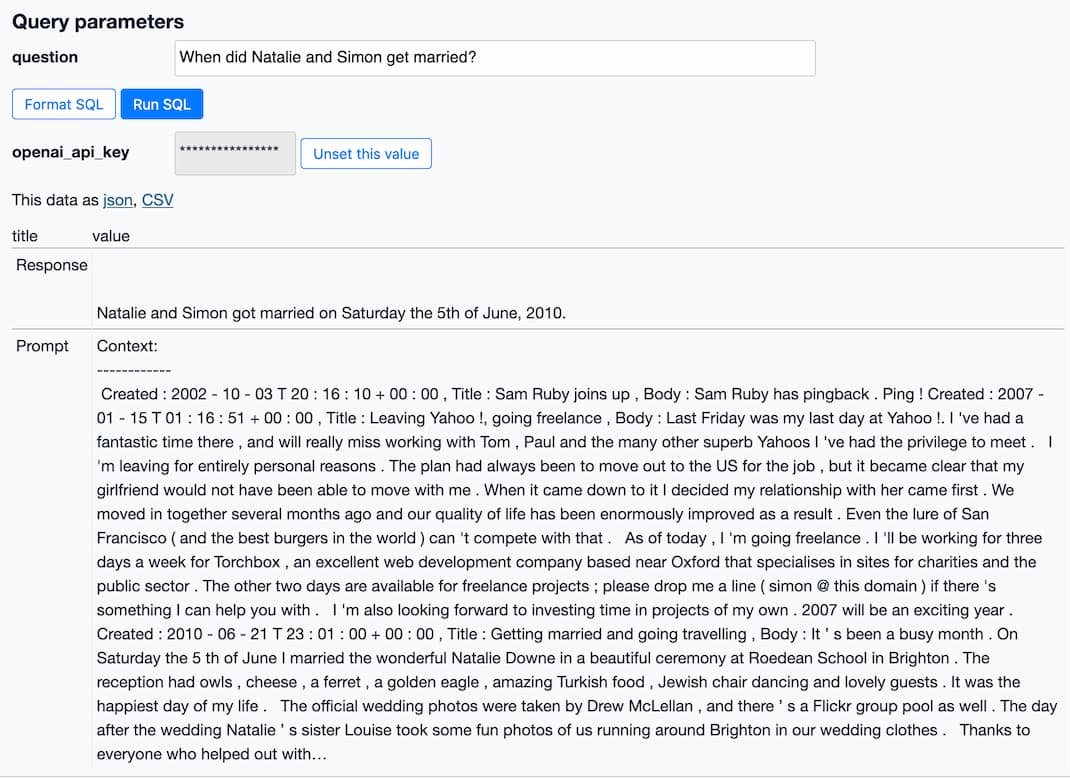
If you’ve spent any time with GPT-3 or ChatGPT, you’ve likely thought about how useful it would be if you could point them at a specific, current collection of text or documentation and have it use that as part of its input for answering questions.
[... 3,491 words]