Posts tagged github in 2020
Filters: Year: 2020 × github × Sorted by date
Commits are snapshots, not diffs (via) Useful, clearly explained revision of some Git fundamentals.
At GitHub, we want to protect developer privacy, and we find cookie banners quite irritating, so we decided to look for a solution. After a brief search, we found one: just don’t use any non-essential cookies. Pretty simple, really. 🤔
So, we have removed all non-essential cookies from GitHub, and visiting our website does not send any information to third-party analytics services.
Personal Data Warehouses: Reclaiming Your Data

I gave a talk yesterday about personal data warehouses for GitHub’s OCTO Speaker Series, focusing on my Datasette and Dogsheep projects. The video of the talk is now available, and I’m presenting that here along with an annotated summary of the talk, including links to demos and further information.
[... 5,166 words]OCTO Speaker Series: Simon Willison—Personal Data Warehouses: Reclaiming Your Data. I’m giving a talk in the GitHub OCTO (Office of the CTO) speaker series about Datasette and my Dogsheep personal analytics project. You can register for free here—the stream will be on Thursday November 12, 2020 at 8:30am PST (4:30pm GMT).
Git scraping: track changes over time by scraping to a Git repository
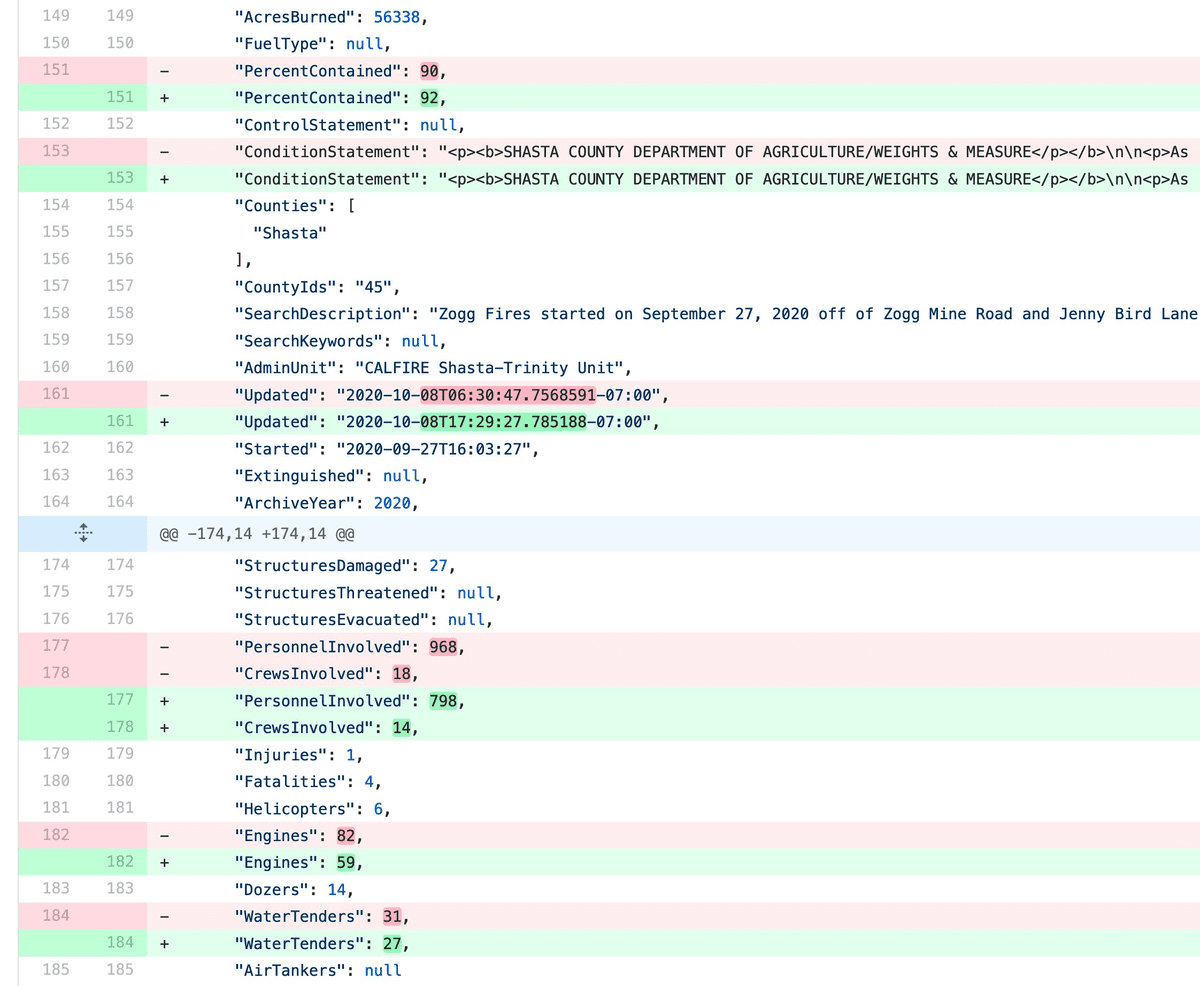
Git scraping is the name I’ve given a scraping technique that I’ve been experimenting with for a few years now. It’s really effective, and more people should use it.
[... 963 words]Render Markdown tool (via) I wrote a quick JavaScript tool for rendering Markdown via the GitHub Markdown API—which includes all of their clever extensions like tables and syntax highlighting—and then stripping out some extraneous HTML to give me back the format I like using for my blog posts.
Weeknotes: Rocky Beaches, Datasette 0.48, a commit history of my database
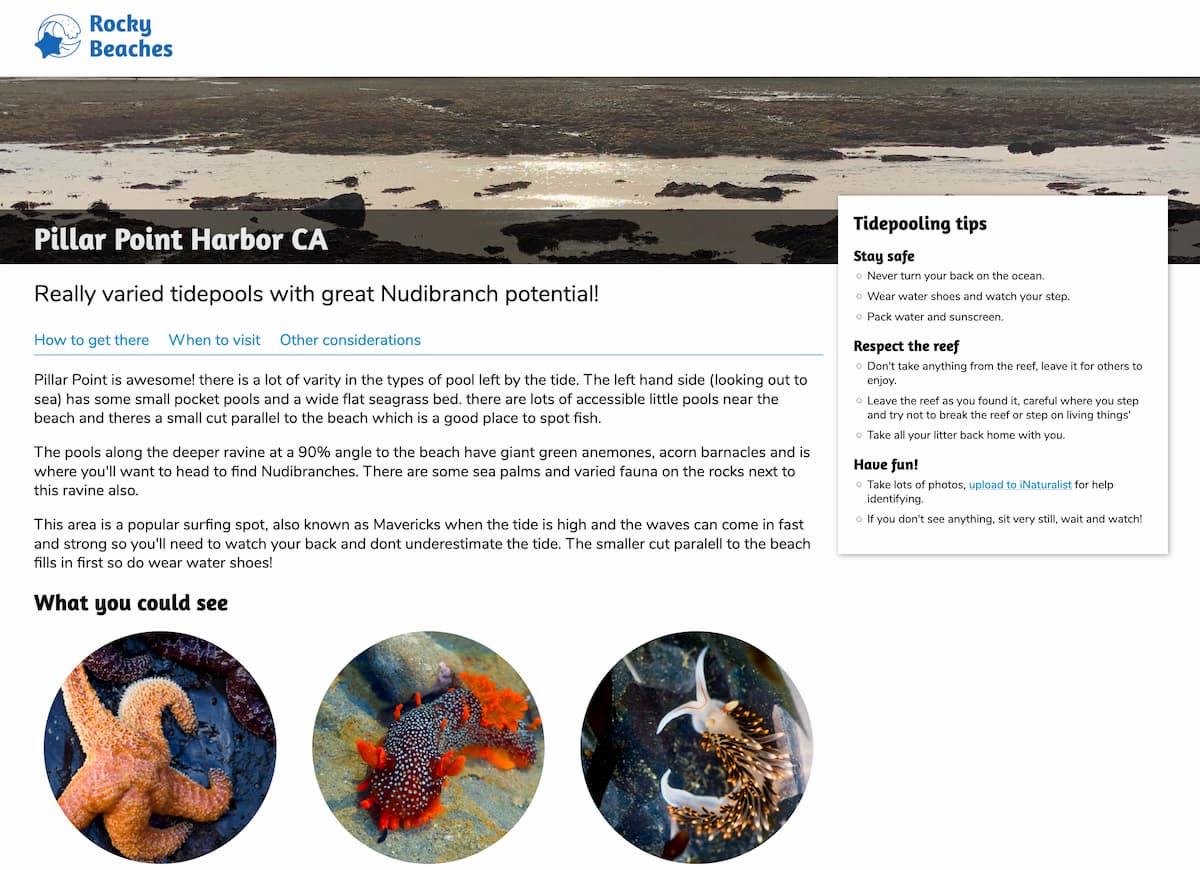
This week I helped Natalie launch Rocky Beaches, shipped Datasette 0.48 and several releases of datasette-graphql, upgraded the CSRF protection for datasette-upload-csvs and figured out how to get a commit log of changes to my blog by backing up its database to a GitHub repository.
Doing Stupid Stuff with GitHub Actions (via) I love the idea here of running a scheduled action once a year that deliberately fails, causing GitHub to send you a “Happy New Year” failure email!
zhiiiyang/zhiiiyang profile README (via) This is a brilliant hack: a GitHub profile README that uses an action to retrieve the author’s latest tweet (using R), render it as a PNG screenshot in headless Chrome via rstudio/webshot2 and embed that image in their profile.
Building a self-updating profile README for GitHub
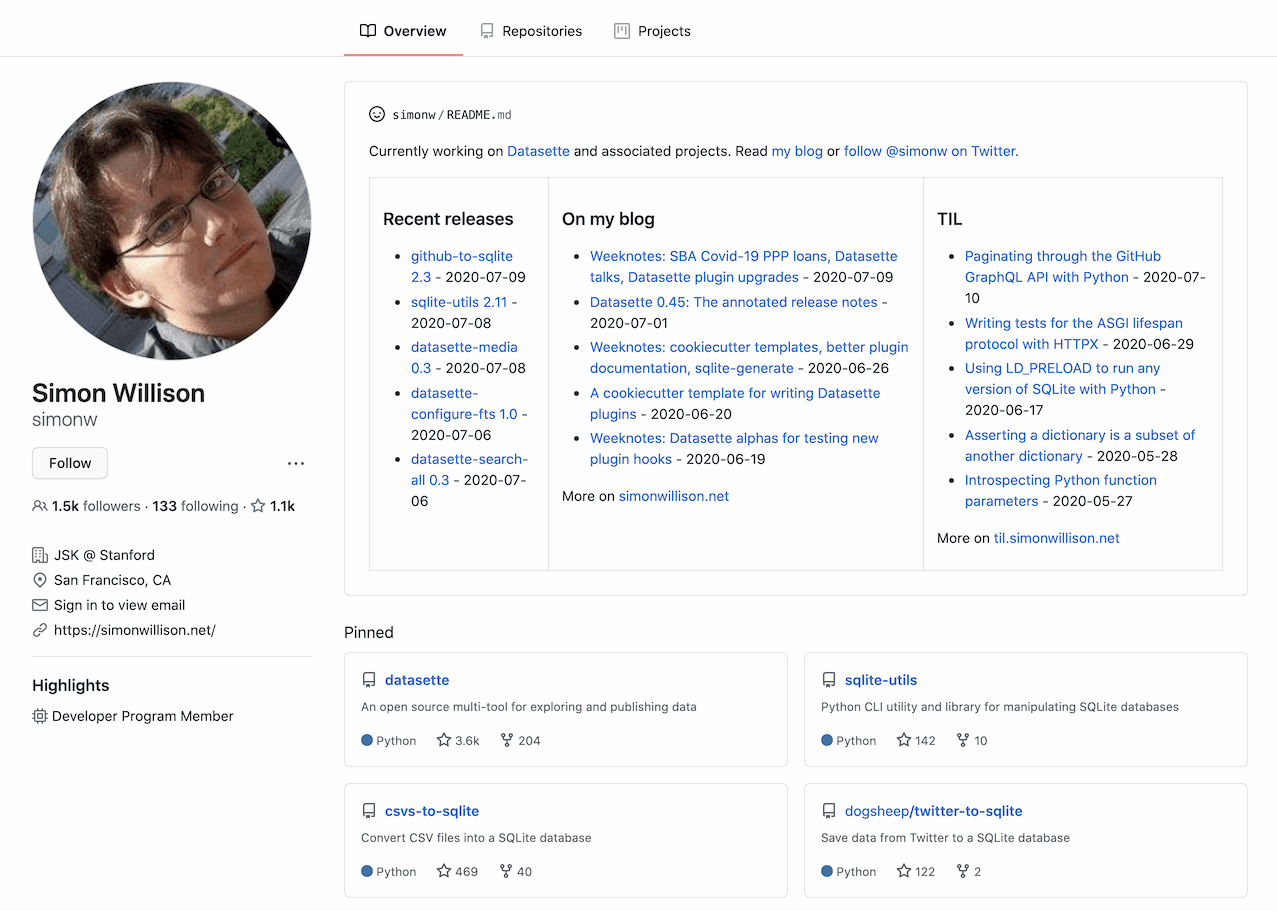
GitHub quietly released a new feature at some point in the past few days: profile READMEs. Create a repository with the same name as your GitHub account (in my case that’s github.com/simonw/simonw), add a README.md to it and GitHub will render the contents at the top of your personal profile page—for me that’s github.com/simonw
A cookiecutter template for writing Datasette plugins
Datasette’s plugin system is one of the most interesting parts of the entire project. As I explained to Matt Asay in this interview, the great thing about plugins is that Datasette can gain new functionality overnight without me even having to review a pull request. I just need to get more people to write them!
[... 914 words]github-to-sqlite 2.2 highlights thread. I released github-to-sqlite 2.2 today with a new “stargazers” command for importing users who have starred one or more specific repositories. This Twitter thread lists highlights of recent releases and links to a live Datasette demo that shows what the tool can do.
Weeknotes: Datasette 0.40, various projects, Dogsheep photos
A new release of Datasette, two new projects and progress towards a Dogsheep photos solution.
[... 826 words]Using a self-rewriting README powered by GitHub Actions to track TILs
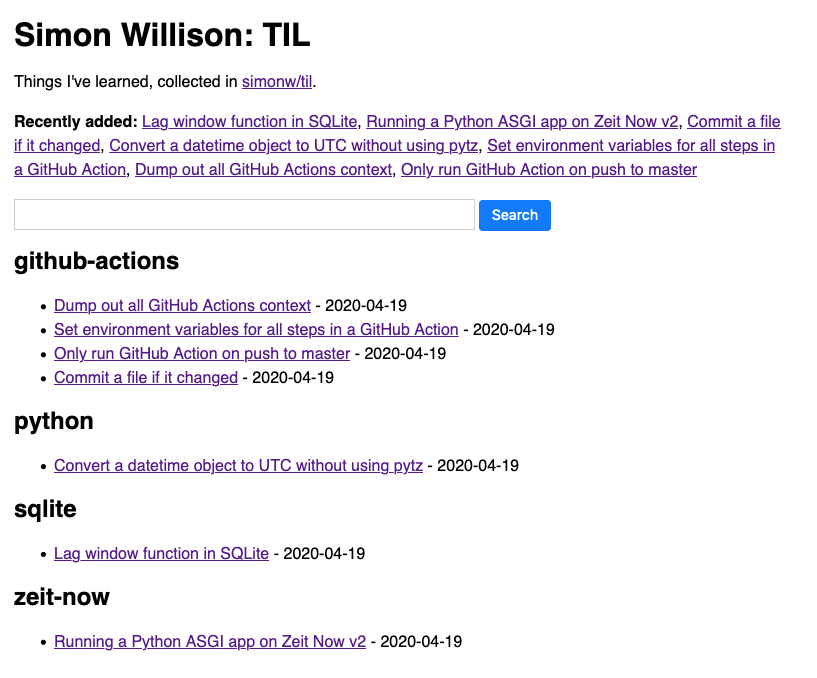
I’ve started tracking TILs—Today I Learneds—inspired by this five-year-and-counting collection by Josh Branchaud on GitHub (found via Hacker News). I’m keeping mine in GitHub too, and using GitHub Actions to automatically generate an index page README in the repository and a SQLite-backed search engine.
[... 1,100 words]Goodbye Zeit Now v1, hello datasette-publish-now—and talking to myself in GitHub issues
This week I’ve been mostly dealing with the finally announced shutdown of Zeit Now v1. And having long-winded conversations with myself in GitHub issues.
[... 2,050 words]Weeknotes: Datasette 0.39 and many other projects
This week’s theme: Well, I’m not going anywhere. So a ton of progress to report on various projects.
[... 806 words]Tracking FARA by deploying a data API using GitHub Actions and Cloud Run
I’m using the combination of GitHub Actions and Google Cloud Run to retrieve data from the U.S. Department of Justice FARA website and deploy it as a queryable API using Datasette.
[... 1,599 words]Your own hosted blog, the easy, free, open way (even if you’re not a computer expert) (via) Jeremy Howard and the fast.ai team have released fast_template—a GitHub repository designed to be used as a template to create new repositories with a complete Jekyll blog configured for use with GitHub pages. GitHub’s official document recommends you install Ruby on your machine to do this, but Jeremy points out that with the right repository setup you can run a blog entirely by editing files through the GitHub web interface.
How we use “ship small” to rapidly build new features at GitHub (via) Useful insight into how GitHub develop new features. They make aggressive use of feature flags, shipping a rough skeleton of a new feature to production as early as possible and actively soliciting feedback from other employees as they iterate on the feature. They static JSON mocks of APIs to unblock their frontend engineers and iterate on the necessary data structures while the real backend is bring implemented.