Weeknotes: Rocky Beaches, Datasette 0.48, a commit history of my database
21st August 2020
This week I helped Natalie launch Rocky Beaches, shipped Datasette 0.48 and several releases of datasette-graphql, upgraded the CSRF protection for datasette-upload-csvs and figured out how to get a commit log of changes to my blog by backing up its database to a GitHub repository.
Rocky Beaches
Natalie released the first version of rockybeaches.com this week. It’s a site that helps you find places to go tidepooling (known as rockpooling in the UK) and figure out the best times to go based on low tide times.
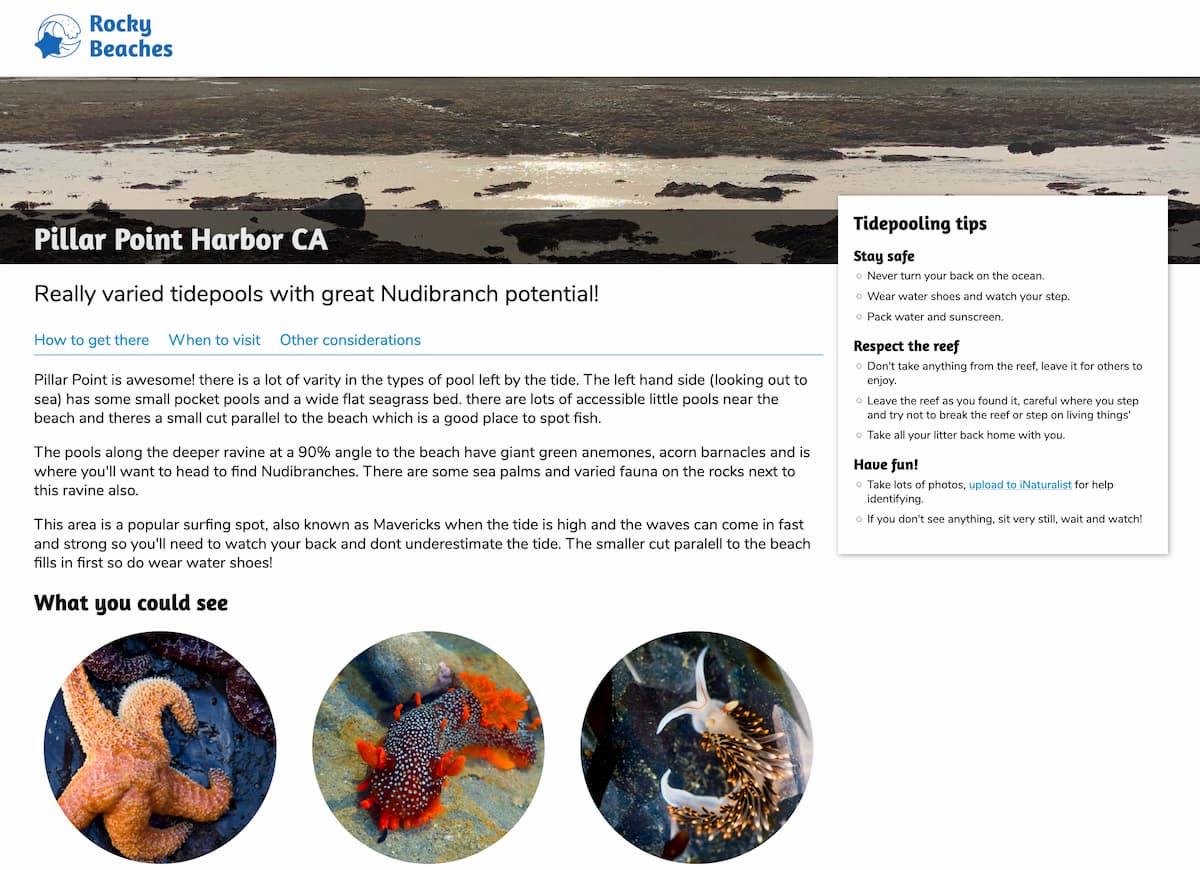
I helped out with the backend for the site, mainly as an excuse to further explore the idea of using Datasette to power full websites (previously explored with Niche Museums and my TILs).
The site uses a pattern I’ve been really enjoying: it’s essentially a static dynamic site. Pages are dynamically rendered by Datasette using Jinja templates and a SQLite database, but the database itself is treated as a static asset: it’s built at deploy time by this GitHub Actions workflow and deployed (currently to Vercel) as a binary asset along with the code.
The build script uses yaml-to-sqlite to load two YAML files—places.yml and stations.yml—and create the stations and places database tables.
It then runs two custom Python scripts to fetch relevant data for those places from iNaturalist and the NOAA Tides & Currents API.
The data all ends up in the Datasette instance that powers the site—you can browse it at www.rockybeaches.com/data or interact with it using GraphQL API at www.rockybeaches.com/graphql
The code is a little convoluted at the moment—I’m still iterating towards the best patterns for building websites like this using Datasette—but I’m very pleased with the productivity and performance that this approach produced.
Datasette 0.48
Highlights from Datasette 0.48 release notes:
- Datasette documentation now lives at docs.datasette.io
- The
extra_template_vars,extra_css_urls,extra_js_urlsandextra_body_scriptplugin hooks now all accept the same arguments. See extra_template_vars(template, database, table, columns, view_name, request, datasette) for details. (#939) - Those hooks now accept a new
columnsargument detailing the table columns that will be rendered on that page. (#938)
I released a new version of datasette-cluster-map that takes advantage of the new columns argument to only inject Leaflet maps JavaScript onto the page if the table being rendered includes latitude and longitude columns—previously the plugin would load extra code on pages that weren’t going to render a map at all. That’s now running on https://global-power-plants.datasettes.com/.
datasette-graphql
Using datasette-graphql for Rocky Beaches inspired me to add two new features:
- A new
graphql()Jinja custom template function that lets you execute custom GraphQL queries inside a Datasette template page—which turns out to be a pretty elegant way for the template to load exactly the data that it needs in order to render the page. Here’s how Rocky Beaches uses that. Issue 50. - Some of the iNaturalist data that Rocky Beaches uses is stored as JSON data in text columns in SQLite—mainly because I was too lazy to model it out as tables. This was coming out of the GraphQL API as strings-containing-JSON, so I added a
json_columnsplugin configuration mechanism for turning those into GrapheneGenericScalarfields—see issue 53 for details.
I also landed a big performance improvement. The plugin works by introspecting the database and generating a GraphQL schema that represents those tables, columns and views. For tables with a lot of tables this can get expensive, and the introspection was being run on every request.
I didn’t want to require a server restart any time the schema changed, so I didn’t want to cache the schema in-memory. Ideally it would be cached but the cache would become invalid any time the schema itself changed.
It turns out SQLite has a mechanism for this: the PRAGMA schema_version statement, which returns an integer version number that changes any time the underlying schema is changed (e.g. a table is added or modified).
I built a quick datasette-schema-versions plugin to try this feature out (in less than twenty minutes thanks to my datasette-plugin cookiecutter template) and prove to myself that it works. Then I built a caching mechanism for datasette-graphql that uses the current schema_version as the cache key. See issue 51 for details.
asgi-csrf and datasette-upload-csvs
datasette-upload-csvs is a Datasette plugin that adds a form for uploading CSV files and converting them to SQLite tables.
Datasette 0.44 added CSRF protection, which broke the plugin. I fixed that this week, but it took some extra work because file uploads use the multipart/form-data HTTP mechanism and my asgi-csrf library didn’t support that.
I fixed that this week, but the code was quite complicated. Since asgi-csrf is a security library I decided to aim for 100% code coverage, the first time I’ve done that for one of my projects.
I got there with the help of codecov.io and pytest-cov. I wrote up what I learned about those tools in a TIL.
Backing up my blog database to a GitHub repository
I really like keeping content in a git repository (see Rocky Beaches and Niche Museums). Every content management system I’ve ever been has eventually desired revision control, and modeling that in a database and adding it to an existing project is always a huge pain.
I have 18 years of content on this blog. I want that backed up to git—and this week I realized I have the tools to do that already.
db-to-sqlite is my tool for taking any SQL Alchemy supported database (so far tested with MySQL and PostgreSQL) and exporting it into a SQLite database.
sqlite-diffable is a very early stage tool I built last year. The idea is to dump a SQLite database out to disk in a way that is designed to work well with git diffs. Each table is dumped out as newline-delimited JSON, one row per line.
So... how about converting my blog’s PostgreSQL database to SQLite, then dumping it to disk with sqlite-diffable and committing the result to a git repository? And then running that in a GitHub Action?
Here’s the workflow. It does exactly that, with a few extra steps: it only grabs a subset of my tables, and it redacts the password column from my auth_user table so that my hashed password isn’t exposed in the backup.
I now have a commit log of changes to my blog’s database!
I’ve set it to run nightly, but I can trigger it manually by clicking a button too.
TIL this week
- Pointing a custom subdomain at Read the Docs
- Code coverage using pytest and codecov.io
- Read the Docs Search API
- Programatically accessing Heroku PostgreSQL from GitHub Actions
- Finding the largest SQLite files on a Mac
- Using grep to write tests in CI
Releases this week
- datasette-graphql 0.14—2020-08-20
- datasette-graphql 0.13—2020-08-19
- datasette-schema-versions 0.1—2020-08-19
- datasette-graphql 0.12.3—2020-08-19
- github-to-sqlite 2.5—2020-08-18
- datasette-publish-vercel 0.8—2020-08-17
- datasette-cluster-map 0.12—2020-08-16
- datasette 0.48—2020-08-16
- datasette-graphql 0.12.2—2020-08-16
- datasette-saved-queries 0.2.1—2020-08-15
- datasette 0.47.3—2020-08-15
- datasette-upload-csvs 0.5—2020-08-15
- asgi-csrf 0.7—2020-08-15
- asgi-csrf 0.7a0—2020-08-15
- asgi-csrf 0.7a0—2020-08-15
- datasette-cluster-map 0.11.1—2020-08-14
- datasette-cluster-map 0.11—2020-08-14
- datasette-graphql 0.12.1—2020-08-13
More recent articles
- A Fireside Chat with Cat and Thariq from the Claude Code team - 21st July 2026
- Kimi K3, and what we can still learn from the pelican benchmark - 16th July 2026
- The new GPT-5.6 family: Luna, Terra, Sol - 9th July 2026