Weeknotes: California Protected Areas in Datasette
28th August 2020
This week I built a geospatial search engine for protected areas in California, shipped datasette-graphql 1.0 and started working towards the next milestone for Datasette Cloud.
California Protected Areas in Datasette
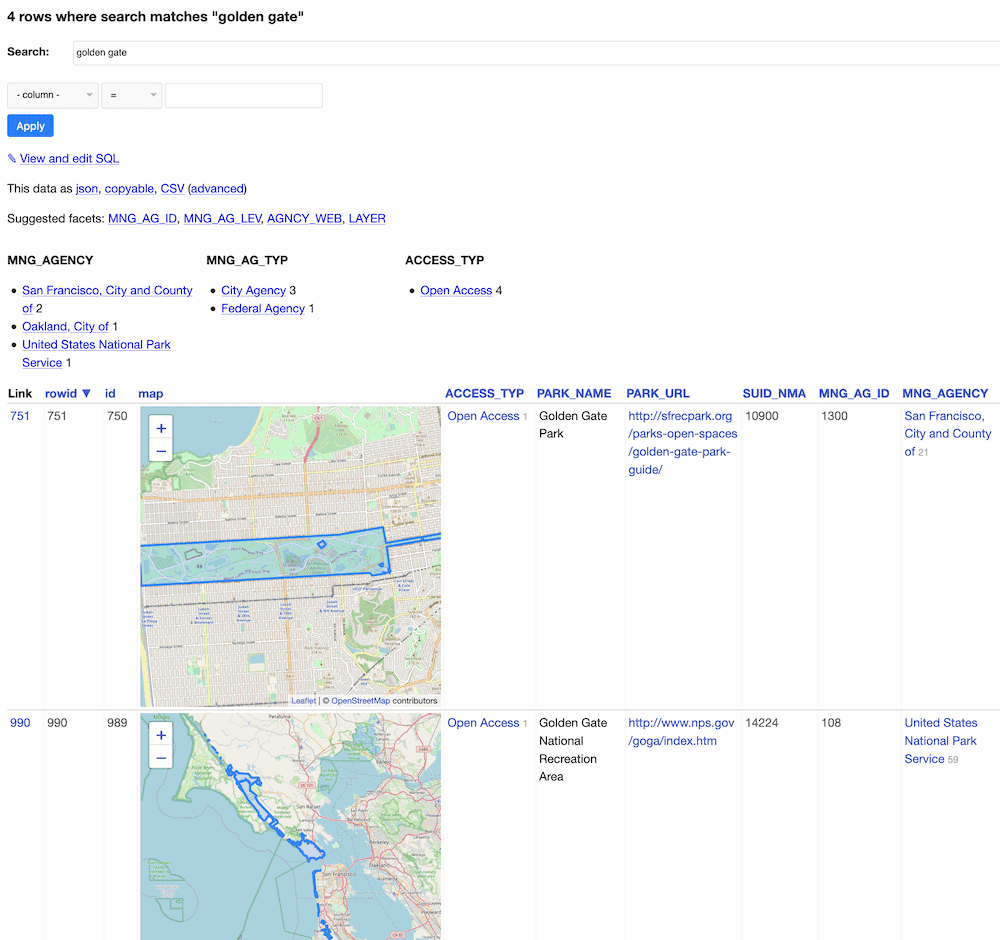
This weekend I learned about CPAD—the California Protected Areas Database. It’s a remarkable GIS dataset maintained by GreenInfo Network, an Oakland non-profit and released under a Creative Commons Attribution license.
CPAD is released twice annually as a shapefile. Back in February I built a tool called shapefile-to-sqlite that imports shapefiles into a SQLite or SpatiaLite database, so CPAD represented a great opportunity to put that tool to use.
Here’s the result: calands.datasettes.com
It provides faceted search over the records from CPAD, and uses my datasette-leaflet-geojson plugin to render the resulting geometry records on embedded maps.
I’m building and deploying the site using this GitHub Actions workflow. It uses conditional-get (see here) combined with the GitHub Actions cache to download the shapefiles as part of the workflow run only if the downloadable file has changed.
This project inspired some improvements to the underlying tools:
datasette-leaflet-geojsonnow handles larger polygons and is smarter about knowing when to load additional JavaScript and CSSshapefile-to-sqlitecan now create spatial indexes and has a new -c option (inspired bycsvs-to-sqlite) for extracting specified columns into separate lookup tables
datasette-graphql 1.0
I’m trying to get better at releasing 1.0 versions of my software.
For me, the most significant thing about a 1.0 is that it represents a promise to avoid making backwards incompatible releases until a 2.0. And ideally I’d like to avoid ever releasing 2.0s—my perfect project would keep incrementing 1.x dot-releases forever.
Datasette is currently at version 0.48, nearly three years after its first release. I’m actively working towards the 1.0 milestone for it but it may be a while before I get there.
datasette-graphql is less than a month old, but I’ve decided to break my habits and have some conviction in where I’ve got to. I shipped datasette-graphql 1.0 a few days ago, closely followed by a 1.0.1 release with improved documentation.
I’m actually pretty confident that the functionality baked into 1.0 is stable enough to make a commitment to supporting it. It’s a relatively tight feature set which directly maps database tables, filter operations and individual rows to GraphQL. If you want to quickly start trying out GraphQL against data that you can represent in SQLite I think it’s a very compelling option.
New datasette-graphql features this week:
- Support for multiple reverse foreign key relationships to a single table, e.g. a
articletable that hascreated_byandupdated_bycolumns that both referenceusers. Example. #32 - The
{% set data = graphql(...) %}template function now accepts an optionalvariables=parameter. #54 - The
search:argument is now available for tables that are configured using Datasette’s fts_table mechanism. #56 - New example demonstrating GraphQL fragments. #57
- Added GraphQL execution limits, controlled by the
time_limit_msandnum_queries_limitplugin configuration settings. These default to 1000ms total execution time and 100 total SQL queries per GraphQL execution. Limits documentation. #33
Improvements to my TILs
My til.simonwillison.net site provides a search engine and browse engine over the TIL notes I’ve been accumulating in simonw/til on GitHub.
The site used to link directly to rendered Markdown in GitHub, but that has some disadvantages: most notably, I can’t control the <title> tag on that page so it has poor implications for SEO.
This week I switched it over to hosting each TIL as a page directly on the site itself.
The tricky thing to solve here was Markdown rendering. GitHub’s Markdown flavour incorporates a bunch of useful extensions for things like embedded tables and code syntax highlighting, and my attempts at recreating the same exact rendering flow using Python’s Markdown libraries fell a bit short.
Then I realized that GitHub provide an API for rendering Markdown using the same pipeline they use on their own site.
So now the build script for the SQLite database that powers my TILs site runs each document through that API, but only if it has changed since the last time the site was built.
I wrote some notes on using their Markdown API in this TIL: Rendering Markdown with the GitHub Markdown API.
Storing the rendered HTML in my database also meant I could finally fix a bug with the Atom feed for that site, where advanced Markdown syntax wasn’t being correctly rendered in the feed.
The datasette-atom plugin I use to generate the feed applies Mozilla’s Bleach HTML sanitization library to avoid dynamically generated feeds accidentally becoming a vector for XSS. To support the full range of GitHub’s Markdown in my feeds I released version 0.7 of the plugin with a deliberately verbose allow_unsafe_html_in_canned_queries plugin setting which can opt canned queries out of the escaping—which should be safe because a canned query running against trusted data gives the site author total control over what might make it into the feed.
Datasette Cloud
I’m spinning up work again on Datasette Cloud again, after several months running it as a private alpha. My next key milestone is to be able to charge subscribers money—I know from experience that until you’re charging people actual money it’s very difficult to be confident that you’re working on the right things.
TIL this week
- Working around the size limit for nodeValue in the DOM
- Outputting JSON with reduced floating point precision
- Dynamically loading multiple assets with a callback
- Providing a “subscribe in Google Calendar” link for an ics feed
- Creating a dynamic line chart with SVG
- Skipping a GitHub Actions step without failing
- Rendering Markdown with the GitHub Markdown API
- Piping echo to a file owned by root using sudo and tee
- Browsing your local git checkout of homebrew-core
Releases this week
- asgi-csrf 0.7.1—2020-08-27
- datasette-graphql 1.0.1—2020-08-24
- datasette-graphql 1.0—2020-08-23
- datasette-graphql 0.15—2020-08-23
- datasette-render-images 0.3.2—2020-08-23
- datasette-atom 0.7—2020-08-23
- shapefile-to-sqlite 0.4.1—2020-08-23
- shapefile-to-sqlite 0.4—2020-08-23
- datasette-auth-passwords 0.3.2—2020-08-22
- shapefile-to-sqlite 0.3—2020-08-22
- datasette-leaflet-geojson 0.6—2020-08-21
- datasette-leaflet-geojson 0.5—2020-08-21
- sqlite-utils 2.16—2020-08-21
More recent articles
- The new GPT-5.6 family: Luna, Terra, Sol - 9th July 2026
- sqlite-utils 4.0, now with database schema migrations - 7th July 2026
- sqlite-utils 4.0rc2, mostly written by Claude Fable (for about $149.25) - 5th July 2026