67 posts tagged “llm-pricing”
Posts about the pricing of various LLMs. See also my pricing calculator.
2026
GPT-5.4 mini and GPT-5.4 nano, which can describe 76,000 photos for $52
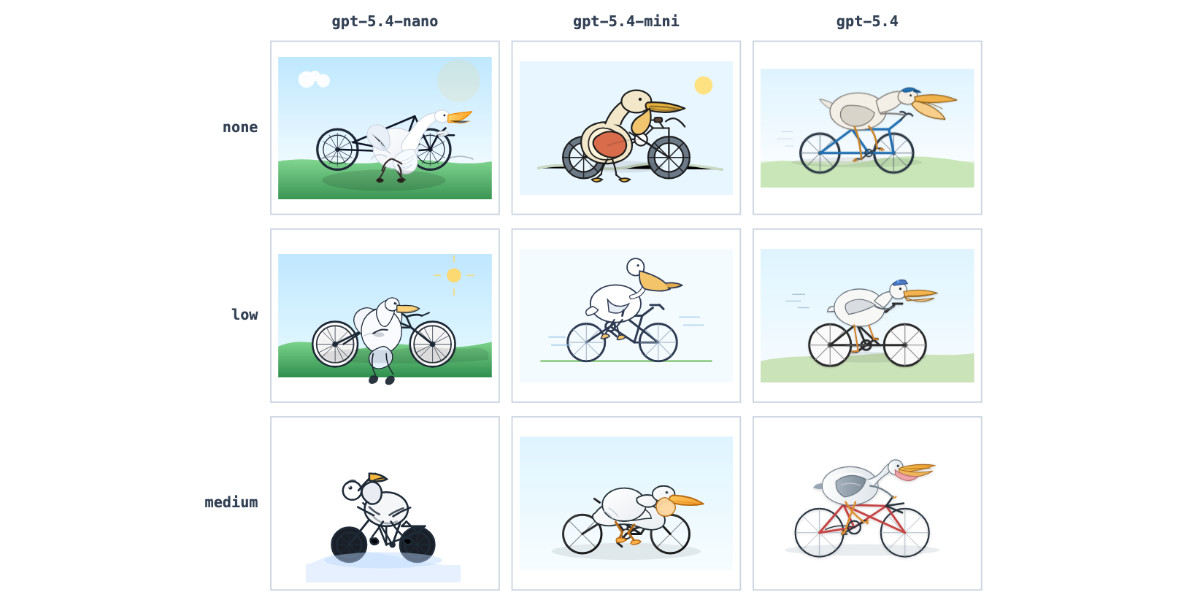
OpenAI today: Introducing GPT‑5.4 mini and nano. These models join GPT-5.4 which was released two weeks ago.
[... 717 words]1M context is now generally available for Opus 4.6 and Sonnet 4.6. Here's what surprised me:
Standard pricing now applies across the full 1M window for both models, with no long-context premium.
OpenAI and Gemini both charge more for prompts where the token count goes above a certain point - 200,000 for Gemini 3.1 Pro and 272,000 for GPT-5.4.
Gemini 3.1 Flash-Lite. Google's latest model is an update to their inexpensive Flash-Lite family. At $0.25/million tokens of input and $1.5/million output this is 1/8th the price of Gemini 3.1 Pro.
It supports four different thinking levels, so I had it output four different pelicans:

minimal

low

medium
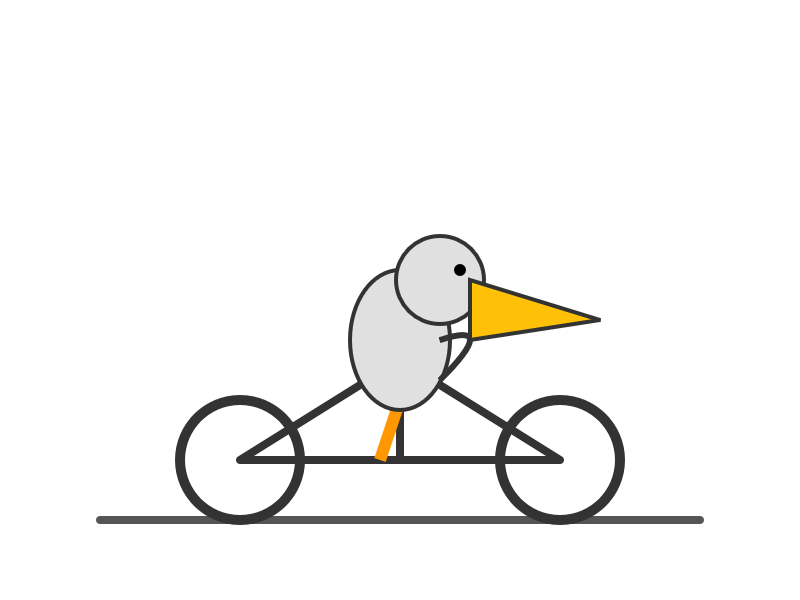
high
Introducing Claude Sonnet 4.6 (via) Sonnet 4.6 is out today, and Anthropic claim it offers similar performance to November's Opus 4.5 while maintaining the Sonnet pricing of $3/million input and $15/million output tokens (the Opus models are $5/$25). Here's the system card PDF.
Sonnet 4.6 has a "reliable knowledge cutoff" of August 2025, compared to Opus 4.6's May 2025 and Haiku 4.5's February 2025. Both Opus and Sonnet default to 200,000 max input tokens but can stretch to 1 million in beta and at a higher cost.
I just released llm-anthropic 0.24 with support for both Sonnet 4.6 and Opus 4.6. Claude Code did most of the work - the new models had a fiddly amount of extra details around adaptive thinking and no longer supporting prefixes, as described in Anthropic's migration guide.
Here's what I got from:
uvx --with llm-anthropic llm 'Generate an SVG of a pelican riding a bicycle' -m claude-sonnet-4.6

The SVG comments include:
<!-- Hat (fun accessory) -->
I tried a second time and also got a top hat. Sonnet 4.6 apparently loves top hats!
For comparison, here's the pelican Opus 4.5 drew me in November:

And here's Anthropic's current best pelican, drawn by Opus 4.6 on February 5th:

Opus 4.6 produces the best pelican beak/pouch. I do think the top hat from Sonnet 4.6 is a nice touch though.
Claude: Speed up responses with fast mode.
New "research preview" from Anthropic today: you can now access a faster version of their frontier model Claude Opus 4.6 by typing /fast in Claude Code... but at a cost that's 6x the normal price.
Opus is usually $5/million input and $25/million output. The new fast mode is $30/million input and $150/million output!
There's a 50% discount until the end of February 16th, so only a 3x multiple (!) before then.
How much faster is it? The linked documentation doesn't say, but on Twitter Claude say:
Our teams have been building with a 2.5x-faster version of Claude Opus 4.6.
We’re now making it available as an early experiment via Claude Code and our API.
Claude Opus 4.5 had a context limit of 200,000 tokens. 4.6 has an option to increase that to 1,000,000 at 2x the input price ($10/m) and 1.5x the output price ($37.50/m) once your input exceeds 200,000 tokens. These multiples hold for fast mode too, so after Feb 16th you'll be able to pay a hefty $60/m input and $225/m output for Anthropic's fastest best model.
2025
Gemini 3 Flash

It continues to be a busy December, if not quite as busy as last year. Today’s big news is Gemini 3 Flash, the latest in Google’s “Flash” line of faster and less expensive models.
[... 1,271 words]Claude Opus 4.5, and why evaluating new LLMs is increasingly difficult

Anthropic released Claude Opus 4.5 this morning, which they call “best model in the world for coding, agents, and computer use”. This is their attempt to retake the crown for best coding model after significant challenges from OpenAI’s GPT-5.1-Codex-Max and Google’s Gemini 3, both released within the past week!
[... 1,120 words]Trying out Gemini 3 Pro with audio transcription and a new pelican benchmark

Google released Gemini 3 Pro today. Here’s the announcement from Sundar Pichai, Demis Hassabis, and Koray Kavukcuoglu, their developer blog announcement from Logan Kilpatrick, the Gemini 3 Pro Model Card, and their collection of 11 more articles. It’s a big release!
[... 2,476 words]MiniMax M2 & Agent: Ingenious in Simplicity. MiniMax M2 was released on Monday 27th October by MiniMax, a Chinese AI lab founded in December 2021.
It's a very promising model. Their self-reported benchmark scores show it as comparable to Claude Sonnet 4, and Artificial Analysis are ranking it as the best currently available open weight model according to their intelligence score:
MiniMax’s M2 achieves a new all-time-high Intelligence Index score for an open weights model and offers impressive efficiency with only 10B active parameters (200B total). [...]
The model’s strengths include tool use and instruction following (as shown by Tau2 Bench and IFBench). As such, while M2 likely excels at agentic use cases it may underperform other open weights leaders such as DeepSeek V3.2 and Qwen3 235B at some generalist tasks. This is in line with a number of recent open weights model releases from Chinese AI labs which focus on agentic capabilities, likely pointing to a heavy post-training emphasis on RL.
The size is particularly significant: the model weights are 230GB on Hugging Face, significantly smaller than other high performing open weight models. That's small enough to run on a 256GB Mac Studio, and the MLX community have that working already.
MiniMax offer their own API, and recommend using their Anthropic-compatible endpoint and the official Anthropic SDKs to access it. MiniMax Head of Engineering Skyler Miao provided some background on that:
M2 is a agentic thinking model, it do interleaved thinking like sonnet 4.5, which means every response will contain its thought content. Its very important for M2 to keep the chain of thought. So we must make sure the history thought passed back to the model. Anthropic API support it for sure, as sonnet needs it as well. OpenAI only support it in their new Response API, no support for in ChatCompletion.
MiniMax are offering the new model via their API for free until November 7th, after which the cost will be $0.30/million input tokens and $1.20/million output tokens - similar in price to Gemini 2.5 Flash and GPT-5 Mini, see price comparison here on my llm-prices.com site.
I released a new plugin for LLM called llm-minimax providing support for M2 via the MiniMax API:
llm install llm-minimax
llm keys set minimax
# Paste key here
llm -m m2 -o max_tokens 10000 "Generate an SVG of a pelican riding a bicycle"
Here's the result:

51 input, 4,017 output. At $0.30/m input and $1.20/m output that pelican would cost 0.4836 cents - less than half a cent.
This is the first plugin I've written for an Anthropic-API-compatible model. I released llm-anthropic 0.21 first adding the ability to customize the base_url parameter when using that model class. This meant the new plugin was less than 30 lines of Python.
Introducing Claude Haiku 4.5 (via) Anthropic released Claude Haiku 4.5 today, the cheapest member of the Claude 4.5 family that started with Sonnet 4.5 a couple of weeks ago.
It's priced at $1/million input tokens and $5/million output tokens, slightly more expensive than Haiku 3.5 ($0.80/$4) and a lot more expensive than the original Claude 3 Haiku ($0.25/$1.25), both of which remain available at those prices.
It's a third of the price of Sonnet 4 and Sonnet 4.5 (both $3/$15) which is notable because Anthropic's benchmarks put it in a similar space to that older Sonnet 4 model. As they put it:
What was recently at the frontier is now cheaper and faster. Five months ago, Claude Sonnet 4 was a state-of-the-art model. Today, Claude Haiku 4.5 gives you similar levels of coding performance but at one-third the cost and more than twice the speed.
I've been hoping to see Anthropic release a fast, inexpensive model that's price competitive with the cheapest models from OpenAI and Gemini, currently $0.05/$0.40 (GPT-5-Nano) and $0.075/$0.30 (Gemini 2.0 Flash Lite). Haiku 4.5 certainly isn't that, it looks like they're continuing to focus squarely on the "great at code" part of the market.
The new Haiku is the first Haiku model to support reasoning. It sports a 200,000 token context window, 64,000 maximum output (up from just 8,192 for Haiku 3.5) and a "reliable knowledge cutoff" of February 2025, one month later than the January 2025 date for Sonnet 4 and 4.5 and Opus 4 and 4.1.
Something that caught my eye in the accompanying system card was this note about context length:
For Claude Haiku 4.5, we trained the model to be explicitly context-aware, with precise information about how much context-window has been used. This has two effects: the model learns when and how to wrap up its answer when the limit is approaching, and the model learns to continue reasoning more persistently when the limit is further away. We found this intervention—along with others—to be effective at limiting agentic “laziness” (the phenomenon where models stop working on a problem prematurely, give incomplete answers, or cut corners on tasks).
I've added the new price to llm-prices.com, released llm-anthropic 0.20 with the new model and updated my Haiku-from-your-webcam demo (source) to use Haiku 4.5 as well.
Here's llm -m claude-haiku-4.5 'Generate an SVG of a pelican riding a bicycle' (transcript).

18 input tokens and 1513 output tokens = 0.7583 cents.
GPT-5 pro. Here's OpenAI's model documentation for their GPT-5 pro model, released to their API today at their DevDay event.
It has similar base characteristics to GPT-5: both share a September 30, 2024 knowledge cutoff and 400,000 context limit.
GPT-5 pro has maximum output tokens 272,000 max, an increase from 128,000 for GPT-5.
As our most advanced reasoning model, GPT-5 pro defaults to (and only supports)
reasoning.effort: high
It's only available via OpenAI's Responses API. My LLM tool doesn't support that in core yet, but the llm-openai-plugin plugin does. I released llm-openai-plugin 0.7 adding support for the new model, then ran this:
llm install -U llm-openai-plugin
llm -m openai/gpt-5-pro "Generate an SVG of a pelican riding a bicycle"
It's very, very slow. The model took 6 minutes 8 seconds to respond and charged me for 16 input and 9,205 output tokens. At $15/million input and $120/million output this pelican cost me $1.10!

Here's the full transcript. It looks visually pretty simpler to the much, much cheaper result I got from GPT-5.
Claude Sonnet 4.5 is probably the “best coding model in the world” (at least for now)

Anthropic released Claude Sonnet 4.5 today, with a very bold set of claims:
[... 1,205 words]Grok 4 Fast. New hosted vision-enabled reasoning model from xAI that's designed to be fast and extremely competitive on price. It has a 2 million token context window and "was trained end-to-end with tool-use reinforcement learning".
It's priced at $0.20/million input tokens and $0.50/million output tokens - 15x less than Grok 4 (which is $3/million input and $15/million output). That puts it cheaper than GPT-5 mini and Gemini 2.5 Flash on llm-prices.com.
The same model weights handle reasoning and non-reasoning based on a parameter passed to the model.
I've been trying it out via my updated llm-openrouter plugin, since Grok 4 Fast is available for free on OpenRouter for a limited period.
Here's output from the non-reasoning model. This actually output an invalid SVG - I had to make a tiny manual tweak to the XML to get it to render.
llm -m openrouter/x-ai/grok-4-fast:free "Generate an SVG of a pelican riding a bicycle" -o reasoning_enabled false
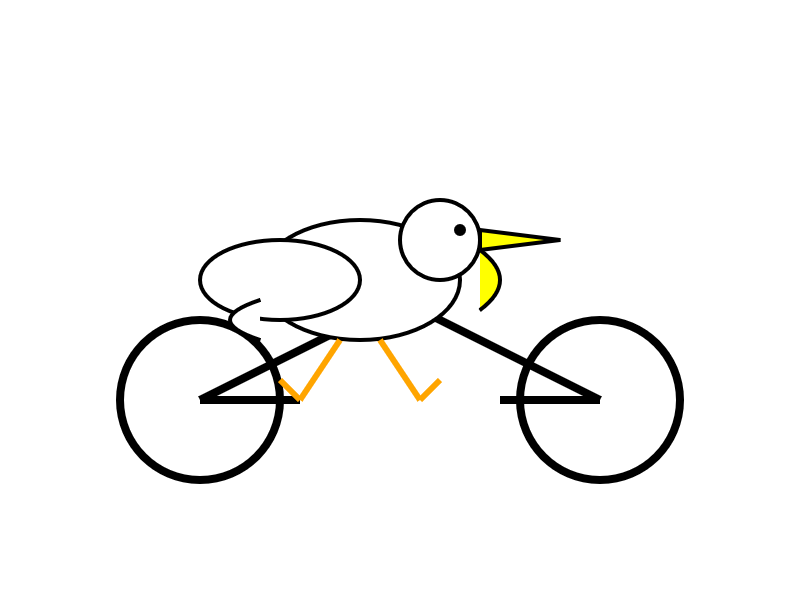
(I initially ran this without that -o reasoning_enabled false flag, but then I saw that OpenRouter enable reasoning by default for that model. Here's my previous invalid result.)
And the reasoning model:
llm -m openrouter/x-ai/grok-4-fast:free "Generate an SVG of a pelican riding a bicycle" -o reasoning_enabled true

In related news, the New York Times had a story a couple of days ago about Elon's recent focus on xAI: Since Leaving Washington, Elon Musk Has Been All In on His A.I. Company.
gpt-5 and gpt-5-mini rate limit updates. OpenAI have increased the rate limits for their two main GPT-5 models. These look significant:
gpt-5
Tier 1: 30K → 500K TPM (1.5M batch)
Tier 2: 450K → 1M (3M batch)
Tier 3: 800K → 2M
Tier 4: 2M → 4Mgpt-5-mini
Tier 1: 200K → 500K (5M batch)
GPT-5 rate limits here show tier 5 stays at 40M tokens per minute. The GPT-5 mini rate limits for tiers 2 through 5 are 2M, 4M, 10M and 180M TPM respectively.
As a reminder, those tiers are assigned based on how much money you have spent on the OpenAI API - from $5 for tier 1 up through $50, $100, $250 and then $1,000 for tier
For comparison, Anthropic's current top tier is Tier 4 ($400 spent) which provides 2M maximum input tokens per minute and 400,000 maximum output tokens, though you can contact their sales team for higher limits than that.
Gemini's top tier is Tier 3 for $1,000 spent and currently gives you 8M TPM for Gemini 2.5 Pro and Flash and 30M TPM for the Flash-Lite and 2.0 Flash models.
So OpenAI's new rate limit increases for their top performing model pulls them ahead of Anthropic but still leaves them significantly behind Gemini.
GPT-5 mini remains the champion for smaller models with that enormous 180M TPS limit for its top tier.
Load Llama-3.2 WebGPU in your browser from a local folder (via) Inspired by a comment on Hacker News I decided to see if it was possible to modify the transformers.js-examples/tree/main/llama-3.2-webgpu Llama 3.2 chat demo (online here, I wrote about it last November) to add an option to open a local model file directly from a folder on disk, rather than waiting for it to download over the network.
I posed the problem to OpenAI's GPT-5-enabled Codex CLI like this:
git clone https://github.com/huggingface/transformers.js-examples
cd transformers.js-examples/llama-3.2-webgpu
codex
Then this prompt:
Modify this application such that it offers the user a file browse button for selecting their own local copy of the model file instead of loading it over the network. Provide a "download model" option too.
Codex churned away for several minutes, even running commands like curl -sL https://raw.githubusercontent.com/huggingface/transformers.js/main/src/models.js | sed -n '1,200p' to inspect the source code of the underlying Transformers.js library.
After four prompts total (shown here) it built something which worked!
To try it out you'll need your own local copy of the Llama 3.2 ONNX model. You can get that (a ~1.2GB) download) like so:
git lfs install
git clone https://huggingface.co/onnx-community/Llama-3.2-1B-Instruct-q4f16
Then visit my llama-3.2-webgpu page in Chrome or Firefox Nightly (since WebGPU is required), click "Browse folder", select that folder you just cloned, agree to the "Upload" confirmation (confusing since nothing is uploaded from your browser, the model file is opened locally on your machine) and click "Load local model".
Here's an animated demo (recorded in real-time, I didn't speed this up):
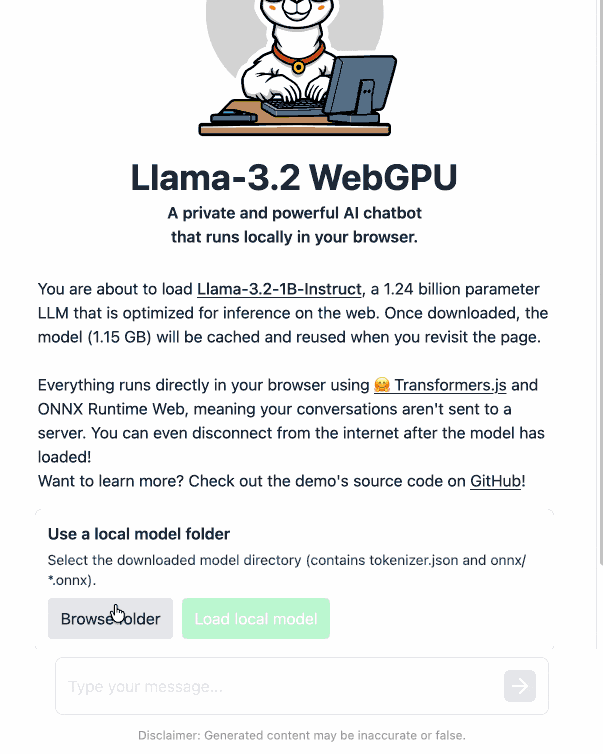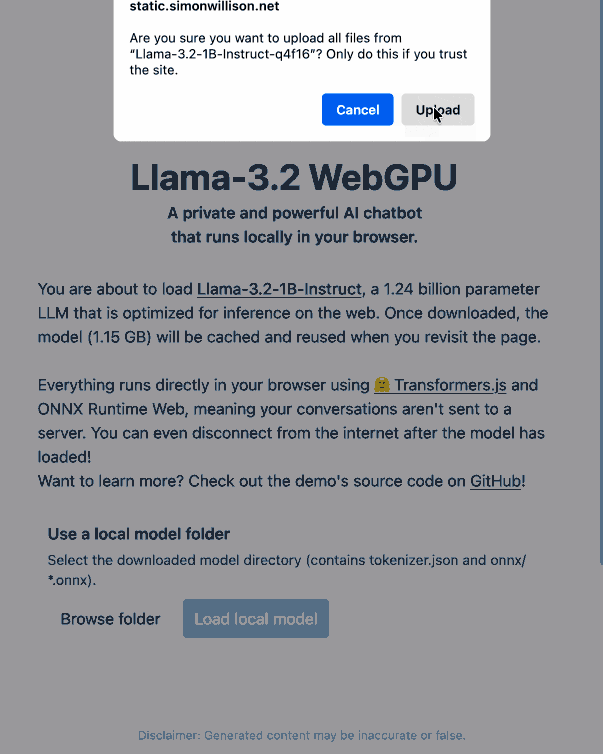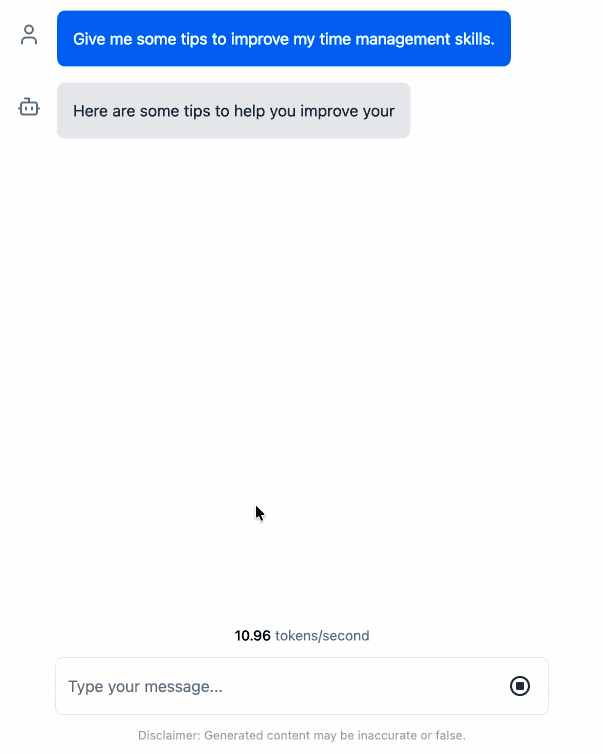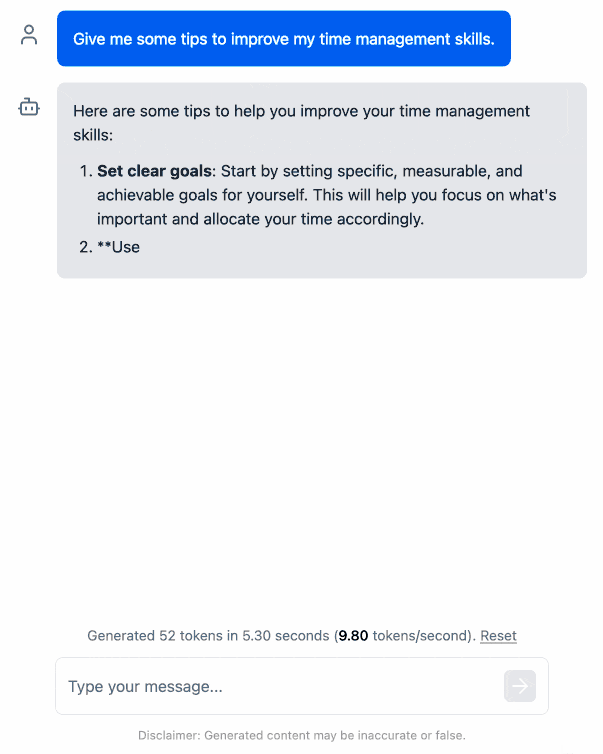
I pushed a branch with those changes here. The next step would be to modify this to support other models in addition to the Llama 3.2 demo, but I'm pleased to have got to this proof of concept with so little work beyond throwing some prompts at Codex to see if it could figure it out.
According to the Codex /status command this used 169,818 input tokens, 17,112 output tokens and 1,176,320 cached input tokens. At current GPT-5 token pricing ($1.25/million input, $0.125/million cached input, $10/million output) that would cost 53.942 cents, but Codex CLI hooks into my existing $20/month ChatGPT Plus plan so this was bundled into that.
Introducing gpt-realtime.
Released a few days ago (August 28th), gpt-realtime is OpenAI's new "most advanced speech-to-speech model". It looks like this is a replacement for the older gpt-4o-realtime-preview model that was released last October.
This is a slightly confusing release. The previous realtime model was clearly described as a variant of GPT-4o, sharing the same October 2023 training cut-off date as that model.
I had expected that gpt-realtime might be a GPT-5 relative, but its training date is still October 2023 whereas GPT-5 is September 2024.
gpt-realtime also shares the relatively low 32,000 context token and 4,096 maximum output token limits of gpt-4o-realtime-preview.
The only reference I found to GPT-5 in the documentation for the new model was a note saying "Ambiguity and conflicting instructions degrade performance, similar to GPT-5."
The usage tips for gpt-realtime have a few surprises:
Iterate relentlessly. Small wording changes can make or break behavior.
Example: Swapping “inaudible” → “unintelligible” improved noisy input handling. [...]
Convert non-text rules to text: The model responds better to clearly written text.
Example: Instead of writing, "IF x > 3 THEN ESCALATE", write, "IF MORE THAN THREE FAILURES THEN ESCALATE."
There are a whole lot more prompting tips in the new Realtime Prompting Guide.
OpenAI list several key improvements to gpt-realtime including the ability to configure it with a list of MCP servers, "better instruction following" and the ability to send it images.
My biggest confusion came from the pricing page, which lists separate pricing for using the Realtime API with gpt-realtime and GPT-4o mini. This suggests to me that the old gpt-4o-mini-realtime-preview model is still available, despite it no longer being listed on the OpenAI models page.
gpt-4o-mini-realtime-preview is a lot cheaper:
| Model | Token Type | Input | Cached Input | Output |
|---|---|---|---|---|
| gpt-realtime | Text | $4.00 | $0.40 | $16.00 |
| Audio | $32.00 | $0.40 | $64.00 | |
| Image | $5.00 | $0.50 | - | |
| gpt-4o-mini-realtime-preview | Text | $0.60 | $0.30 | $2.40 |
| Audio | $10.00 | $0.30 | $20.00 |
The mini model also has a much longer 128,000 token context window.
Update: Turns out that was a mistake in the documentation, that mini model has a 16,000 token context size.
Update 2: OpenAI's Peter Bakkum clarifies:
There are different voice models in API and ChatGPT, but they share some recent improvements. The voices are also different.
gpt-realtime has a mix of data specific enough to itself that its not really 4o or 5
Claude Sonnet 4 now supports 1M tokens of context (via) Gemini and OpenAI both have million token models, so it's good to see Anthropic catching up. This is 5x the previous 200,000 context length limit of the various Claude Sonnet models.
Anthropic have previously made 1 million tokens available to select customers. From the Claude 3 announcement in March 2024:
The Claude 3 family of models will initially offer a 200K context window upon launch. However, all three models are capable of accepting inputs exceeding 1 million tokens and we may make this available to select customers who need enhanced processing power.
This is also the first time I've seen Anthropic use prices that vary depending on context length:
- Prompts ≤ 200K: $3/million input, $15/million output
- Prompts > 200K: $6/million input, $22.50/million output
Gemini have been doing this for a while: Gemini 2.5 Pro is $1.25/$10 below 200,000 tokens and $2.50/$15 above 200,000.
Here's Anthropic's full documentation on the 1m token context window. You need to send a context-1m-2025-08-07 beta header in your request to enable it.
Note that this is currently restricted to "tier 4" users who have purchased at least $400 in API credits:
Long context support for Sonnet 4 is now in public beta on the Anthropic API for customers with Tier 4 and custom rate limits, with broader availability rolling out over the coming weeks.
I think there's been a lot of decisions over time that proved pretty consequential, but we made them very quickly as we have to. [...]
[On pricing] I had this kind of panic attack because we really needed to launch subscriptions because at the time we were taking the product down all the time. [...]
So what I did do is ship a Google Form to Discord with the four questions you're supposed to ask on how to price something.
But we got with the $20. We were debating something slightly higher at the time. I often wonder what would have happened because so many other companies ended up copying the $20 price point, so did we erase a bunch of market cap by pricing it this way?
— Nick Turley, Head of ChatGPT, interviewed by Lenny Rachitsky
GPT-5: Key characteristics, pricing and model card

I’ve had preview access to the new GPT-5 model family for the past two weeks (see related video and my disclosures) and have been using GPT-5 as my daily-driver. It’s my new favorite model. It’s still an LLM—it’s not a dramatic departure from what we’ve had before—but it rarely screws up and generally feels competent or occasionally impressive at the kinds of things I like to use models for.
[... 2,448 words]Claude Opus 4.1. Surprise new model from Anthropic today - Claude Opus 4.1, which they describe as "a drop-in replacement for Opus 4".
My favorite thing about this model is the version number - treating this as a .1 version increment looks like it's an accurate depiction of the model's capabilities.
Anthropic's own benchmarks show very small incremental gains.
Comparing Opus 4 and Opus 4.1 (I got 4.1 to extract this information from a screenshot of Anthropic's own benchmark scores, then asked it to look up the links, then verified the links myself and fixed a few):
- Agentic coding (SWE-bench Verified): From 72.5% to 74.5%
- Agentic terminal coding (Terminal-Bench): From 39.2% to 43.3%
- Graduate-level reasoning (GPQA Diamond): From 79.6% to 80.9%
- Agentic tool use (TAU-bench):
- Retail: From 81.4% to 82.4%
- Airline: From 59.6% to 56.0% (decreased)
- Multilingual Q&A (MMMLU): From 88.8% to 89.5%
- Visual reasoning (MMMU validation): From 76.5% to 77.1%
- High school math competition (AIME 2025): From 75.5% to 78.0%
Likewise, the model card shows only tiny changes to the various safety metrics that Anthropic track.
It's priced the same as Opus 4 - $15/million for input and $75/million for output, making it one of the most expensive models on the market today.
I had it draw me this pelican riding a bicycle:
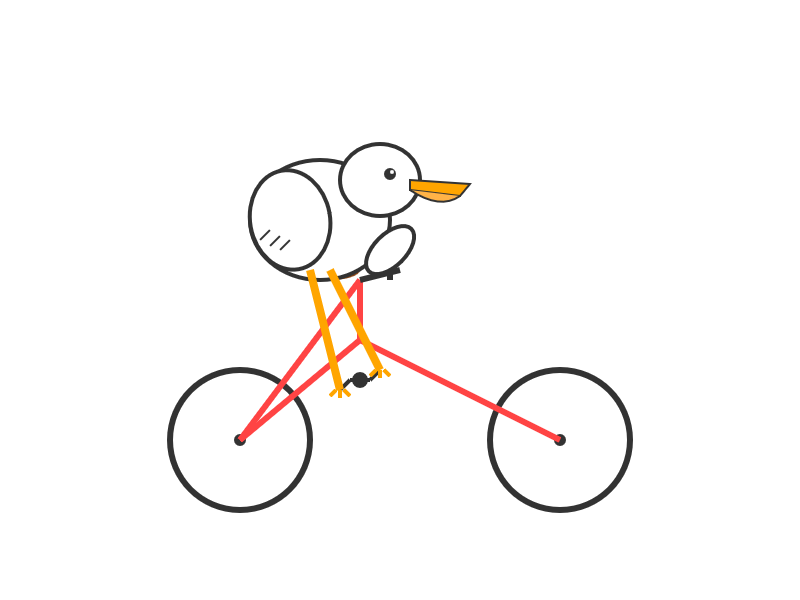
For comparison I got a fresh new pelican out of Opus 4 which I actually like a little more:

I shipped llm-anthropic 0.18 with support for the new model.
Two interesting examples of inference speed as a flagship feature of LLM services today.
First, Cerebras announced two new monthly plans for their extremely high speed hosted model service: Cerebras Code Pro ($50/month, 1,000 messages a day) and Cerebras Code Max ($200/month, 5,000/day). The model they are selling here is Qwen's Qwen3-Coder-480B-A35B-Instruct, likely the best available open weights coding model right now and one that was released just ten days ago. Ten days from model release to third-party subscription service feels like some kind of record.
Cerebras claim they can serve the model at an astonishing 2,000 tokens per second - four times the speed of Claude Sonnet 4 in their demo video.
Also today, Moonshot announced a new hosted version of their trillion parameter Kimi K2 model called kimi-k2-turbo-preview:
🆕 Say hello to kimi-k2-turbo-preview Same model. Same context. NOW 4× FASTER.
⚡️ From 10 tok/s to 40 tok/s.
💰 Limited-Time Launch Price (50% off until Sept 1)
- $0.30 / million input tokens (cache hit)
- $1.20 / million input tokens (cache miss)
- $5.00 / million output tokens
👉 Explore more: platform.moonshot.ai
This is twice the price of their regular model for 4x the speed (increasing to 4x the price in September). No details yet on how they achieved the speed-up.
I am interested to see how much market demand there is for faster performance like this. I've experimented with Cerebras in the past and found that the speed really does make iterating on code with live previews feel a whole lot more interactive.
We’re rolling out new weekly rate limits for Claude Pro and Max in late August. We estimate they’ll apply to less than 5% of subscribers based on current usage. [...]
Some of the biggest Claude Code fans are running it continuously in the background, 24/7.
These uses are remarkable and we want to enable them. But a few outlying cases are very costly to support. For example, one user consumed tens of thousands in model usage on a $200 plan.
Qwen3-Coder: Agentic Coding in the World (via) It turns out that as I was typing up my notes on Qwen3-235B-A22B-Instruct-2507 the Qwen team were unleashing something much bigger:
Today, we’re announcing Qwen3-Coder, our most agentic code model to date. Qwen3-Coder is available in multiple sizes, but we’re excited to introduce its most powerful variant first: Qwen3-Coder-480B-A35B-Instruct — a 480B-parameter Mixture-of-Experts model with 35B active parameters which supports the context length of 256K tokens natively and 1M tokens with extrapolation methods, offering exceptional performance in both coding and agentic tasks.
This is another Apache 2.0 licensed open weights model, available as Qwen3-Coder-480B-A35B-Instruct and Qwen3-Coder-480B-A35B-Instruct-FP8 on Hugging Face.
I used qwen3-coder-480b-a35b-instruct on the Hyperbolic playground to run my "Generate an SVG of a pelican riding a bicycle" test prompt:

I actually slightly prefer the one I got from qwen3-235b-a22b-07-25.
It's also available as qwen3-coder on OpenRouter.
In addition to the new model, Qwen released their own take on an agentic terminal coding assistant called qwen-code, which they describe in their blog post as being "Forked from Gemini Code" (they mean gemini-cli) - which is Apache 2.0 so a fork is in keeping with the license.
They focused really hard on code performance for this release, including generating synthetic data tested using 20,000 parallel environments on Alibaba Cloud:
In the post-training phase of Qwen3-Coder, we introduced long-horizon RL (Agent RL) to encourage the model to solve real-world tasks through multi-turn interactions using tools. The key challenge of Agent RL lies in environment scaling. To address this, we built a scalable system capable of running 20,000 independent environments in parallel, leveraging Alibaba Cloud’s infrastructure. The infrastructure provides the necessary feedback for large-scale reinforcement learning and supports evaluation at scale. As a result, Qwen3-Coder achieves state-of-the-art performance among open-source models on SWE-Bench Verified without test-time scaling.
To further burnish their coding credentials, the announcement includes instructions for running their new model using both Claude Code and Cline using custom API base URLs that point to Qwen's own compatibility proxies.
Pricing for Qwen's own hosted models (through Alibaba Cloud) looks competitive. This is the first model I've seen that sets different prices for four different sizes of input:
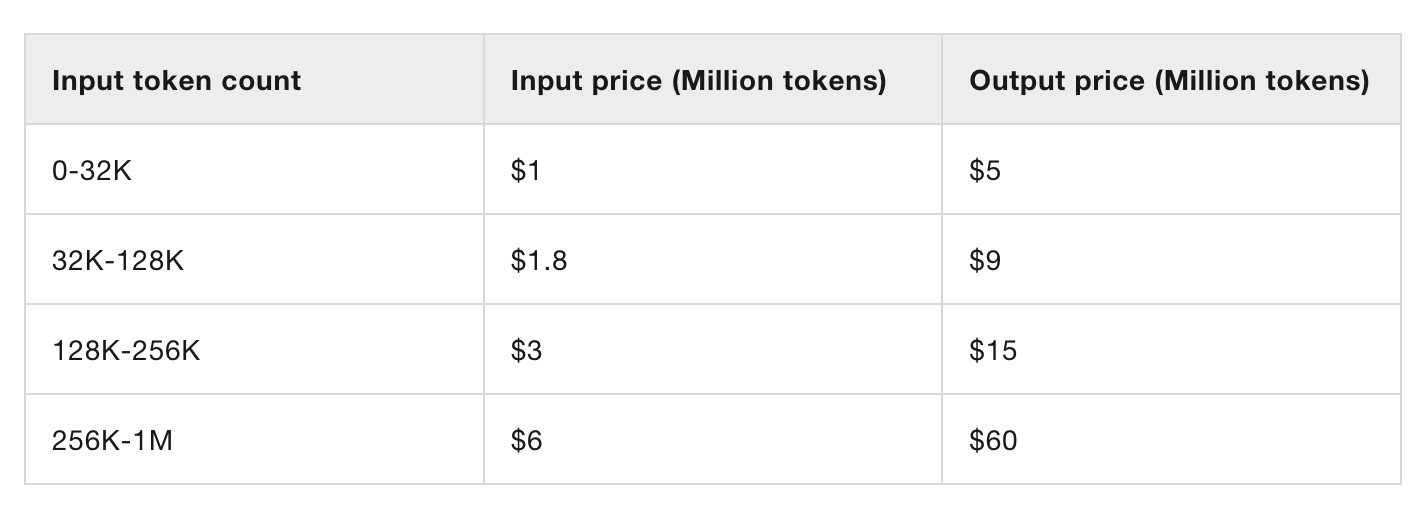
This kind of pricing reflects how inference against longer inputs is more expensive to process. Gemini 2.5 Pro has two different prices for above or below 200,00 tokens.
Awni Hannun reports running a 4-bit quantized MLX version on a 512GB M3 Ultra Mac Studio at 24 tokens/second using 272GB of RAM, getting great results for "write a python script for a bouncing yellow ball within a square, make sure to handle collision detection properly. make the square slowly rotate. implement it in python. make sure ball stays within the square".
Gemini 2.5 Flash-Lite is now stable and generally available. The last remaining member of the Gemini 2.5 trio joins Pro and Flash in General Availability today.
Gemini 2.5 Flash-Lite is the cheapest of the 2.5 family, at $0.10/million input tokens and $0.40/million output tokens. This puts it equal to GPT-4.1 Nano on my llm-prices.com comparison table.
The preview version of that model had the same pricing for text tokens, but is now cheaper for audio:
We have also reduced audio input pricing by 40% from the preview launch.
I released llm-gemini 0.24 with support for the new model alias:
llm install -U llm-gemini
llm -m gemini-2.5-flash-lite \
-a https://static.simonwillison.net/static/2024/pelican-joke-request.mp3
I wrote more about the Gemini 2.5 Flash-Lite preview model last month.
Grok 4. Released last night, Grok 4 is now available via both API and a paid subscription for end-users.
Update: If you ask it about controversial topics it will sometimes search X for tweets "from:elonmusk"!
Key characteristics: image and text input, text output. 256,000 context length (twice that of Grok 3). It's a reasoning model where you can't see the reasoning tokens or turn off reasoning mode.
xAI released results showing Grok 4 beating other models on most of the significant benchmarks. I haven't been able to find their own written version of these (the launch was a livestream video) but here's a TechCrunch report that includes those scores. It's not clear to me if these benchmark results are for Grok 4 or Grok 4 Heavy.
I ran my own benchmark using Grok 4 via OpenRouter (since I have API keys there already).
llm -m openrouter/x-ai/grok-4 "Generate an SVG of a pelican riding a bicycle" \
-o max_tokens 10000

I then asked Grok to describe the image it had just created:
llm -m openrouter/x-ai/grok-4 -o max_tokens 10000 \
-a https://static.simonwillison.net/static/2025/grok4-pelican.png \
'describe this image'
Here's the result. It described it as a "cute, bird-like creature (resembling a duck, chick, or stylized bird)".
The most interesting independent analysis I've seen so far is this one from Artificial Analysis:
We have run our full suite of benchmarks and Grok 4 achieves an Artificial Analysis Intelligence Index of 73, ahead of OpenAI o3 at 70, Google Gemini 2.5 Pro at 70, Anthropic Claude 4 Opus at 64 and DeepSeek R1 0528 at 68.
The timing of the release is somewhat unfortunate, given that Grok 3 made headlines just this week after a clumsy system prompt update - presumably another attempt to make Grok "less woke" - caused it to start firing off antisemitic tropes and referring to itself as MechaHitler.
My best guess is that these lines in the prompt were the root of the problem:
- If the query requires analysis of current events, subjective claims, or statistics, conduct a deep analysis finding diverse sources representing all parties. Assume subjective viewpoints sourced from the media are biased. No need to repeat this to the user.
- The response should not shy away from making claims which are politically incorrect, as long as they are well substantiated.
If xAI expect developers to start building applications on top of Grok they need to do a lot better than this. Absurd self-inflicted mistakes like this do not build developer trust!
As it stands, Grok 4 isn't even accompanied by a model card.
Update: Ian Bicking makes an astute point:
It feels very credulous to ascribe what happened to a system prompt update. Other models can't be pushed into racism, Nazism, and ideating rape with a system prompt tweak.
Even if that system prompt change was responsible for unlocking this behavior, the fact that it was able to speaks to a much looser approach to model safety by xAI compared to other providers.
Update 12th July 2025: Grok posted a postmortem blaming the behavior on a different set of prompts, including "you are not afraid to offend people who are politically correct", that were not included in the system prompts they had published to their GitHub repository.
Grok 4 is competitively priced. It's $3/million for input tokens and $15/million for output tokens - the same price as Claude Sonnet 4. Once you go above 128,000 input tokens the price doubles to $6/$30 (Gemini 2.5 Pro has a similar price increase for longer inputs). I've added these prices to llm-prices.com.
Consumers can access Grok 4 via a new $30/month or $300/year "SuperGrok" plan - or a $300/month or $3,000/year "SuperGrok Heavy" plan providing access to Grok 4 Heavy.
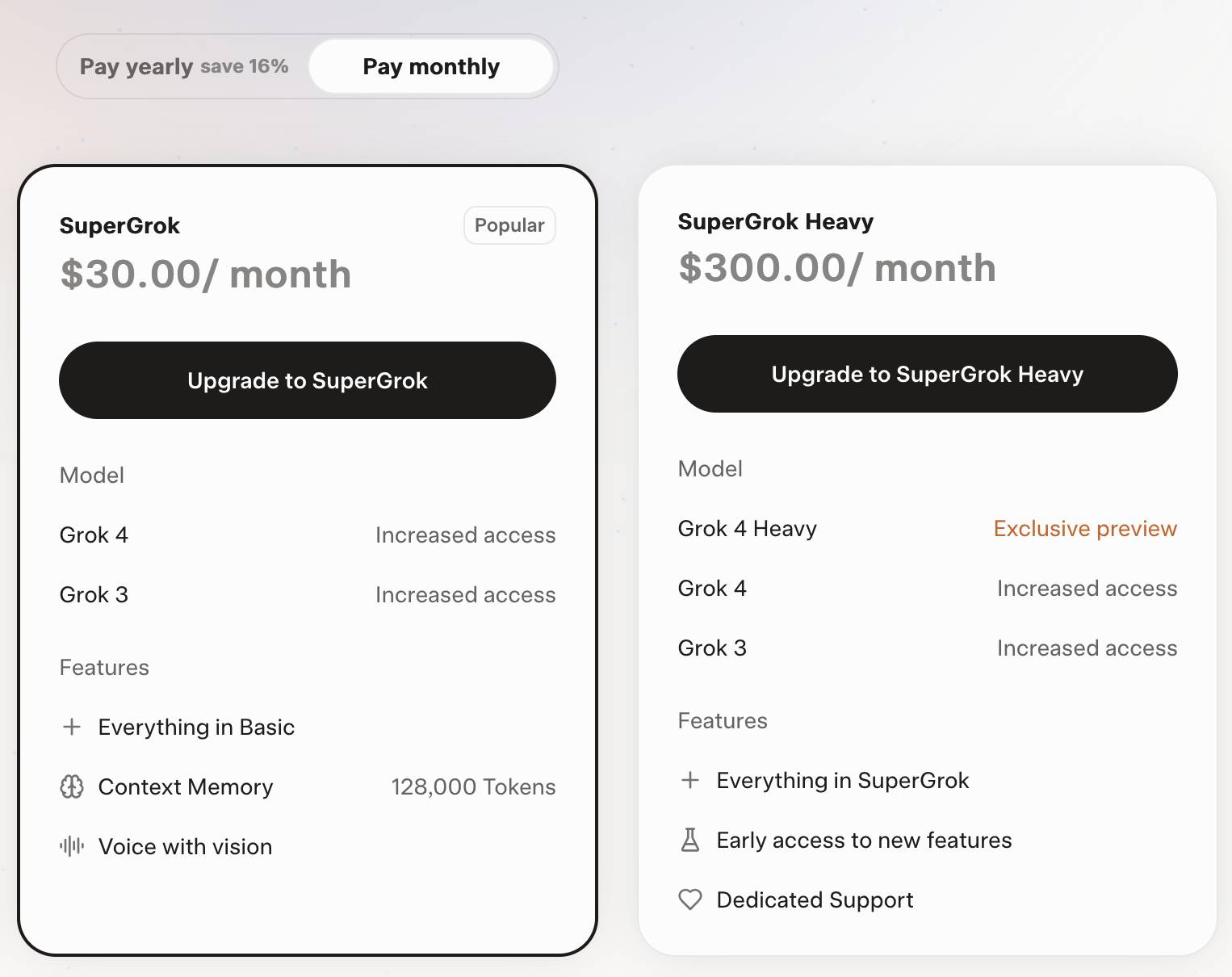
Cursor: Clarifying Our Pricing. Cursor changed their pricing plan on June 16th, introducing a new $200/month Ultra plan with "20x more usage than Pro" and switching their $20/month Pro plan from "request limits to compute limits".
This confused a lot of people. Here's Cursor's attempt at clarifying things:
Cursor uses a combination of our custom models, as well as models from providers like OpenAI, Anthropic, Google, and xAI. For external models, we previously charged based on the number of requests made. There was a limit of 500 requests per month, with Sonnet models costing two requests.
New models can spend more tokens per request on longer-horizon tasks. Though most users' costs have stayed fairly constant, the hardest requests cost an order of magnitude more than simple ones. API-based pricing is the best way to reflect that.
I think I understand what they're saying there. They used to allow you 500 requests per month, but those requests could be made against any model and, crucially, a single request could trigger a variable amount of token spend.
Modern LLMs can have dramatically different prices, so one of those 500 requests with a large context query against an expensive model could cost a great deal more than a single request with a shorter context against something less expensive.
I imagine they were losing money on some of their more savvy users, who may have been using prompting techniques that sent a larger volume of tokens through each one of those precious 500 requests.
The new billing switched to passing on the expense of those tokens directly, with a $20 included budget followed by overage charges for tokens beyond that.
It sounds like a lot of people, used to the previous model where their access would be cut off after 500 requests, got caught out by this and racked up a substantial bill!
To cursor's credit, they're offering usage refunds to "those with unexpected usage between June 16 and July 4."
I think this highlights a few interesting trends.
Firstly, the era of VC-subsidized tokens may be coming to an end, especially for products like Cursor which are way past demonstrating product-market fit.
Secondly, that $200/month plan for 20x the usage of the $20/month plan is an emerging pattern: Anthropic offers the exact same deal for Claude Code, with the same 10x price for 20x usage multiplier.
Professional software engineers may be able to justify one $200/month subscription, but I expect most will be unable to justify two. The pricing here becomes a significant form of lock-in - once you've picked your $200/month coding assistant you are less likely to evaluate the alternatives.
Trying out the new Gemini 2.5 model family

After many months of previews, Gemini 2.5 Pro and Flash have reached general availability with new, memorable model IDs: gemini-2.5-pro and gemini-2.5-flash. They are joined by a new preview model with an unmemorable name: gemini-2.5-flash-lite-preview-06-17 is a new Gemini 2.5 Flash Lite model that offers lower prices and much faster inference times.
o3-pro. OpenAI released o3-pro today, which they describe as a "version of o3 with more compute for better responses".
It's only available via the newer Responses API. I've added it to my llm-openai-plugin plugin which uses that new API, so you can try it out like this:
llm install -U llm-openai-plugin
llm -m openai/o3-pro "Generate an SVG of a pelican riding a bicycle"

It's slow - generating this pelican took 124 seconds! OpenAI suggest using their background mode for o3 prompts, which I haven't tried myself yet.
o3-pro is priced at $20/million input tokens and $80/million output tokens - 10x the price of regular o3 after its 80% price drop this morning.
Ben Hylak had early access and published his notes so far in God is hungry for Context: First thoughts on o3 pro. It sounds like this model needs to be applied very thoughtfully. It comparison to o3:
It's smarter. much smarter.
But in order to see that, you need to give it a lot more context. and I'm running out of context. [...]
My co-founder Alexis and I took the the time to assemble a history of all of our past planning meetings at Raindrop, all of our goals, even record voice memos: and then asked o3-pro to come up with a plan.
We were blown away; it spit out the exact kind of concrete plan and analysis I've always wanted an LLM to create --- complete with target metrics, timelines, what to prioritize, and strict instructions on what to absolutely cut.
The plan o3 gave us was plausible, reasonable; but the plan o3 Pro gave us was specific and rooted enough that it actually changed how we are thinking about our future.
This is hard to capture in an eval.
It sounds to me like o3-pro works best when combined with tools. I don't have tool support in llm-openai-plugin yet, here's the relevant issue.
OpenAI just dropped the price of their o3 model by 80% - from $10/million input tokens and $40/million output tokens to just $2/million and $8/million for the very same model. This is in advance of the release of o3-pro which apparently is coming later today (update: here it is).
This is a pretty huge shake-up in LLM pricing. o3 is now priced the same as GPT 4.1, and slightly less than GPT-4o ($2.50/$10). It’s also less than Anthropic’s Claude Sonnet 4 ($3/$15) and Opus 4 ($15/$75) and sits in between Google’s Gemini 2.5 Pro for >200,00 tokens ($2.50/$15) and 2.5 Pro for <200,000 ($1.25/$10).
I’ve updated my llm-prices.com pricing calculator with the new rate.
How have they dropped the price so much? OpenAI's Adam Groth credits ongoing optimization work:
thanks to the engineers optimizing inferencing.
Magistral — the first reasoning model by Mistral AI. Mistral's first reasoning model is out today, in two sizes. There's a 24B Apache 2 licensed open-weights model called Magistral Small (actually Magistral-Small-2506), and a larger API-only model called Magistral Medium.
Magistral Small is available as mistralai/Magistral-Small-2506 on Hugging Face. From that model card:
Context Window: A 128k context window, but performance might degrade past 40k. Hence we recommend setting the maximum model length to 40k.
Mistral also released an official GGUF version, Magistral-Small-2506_gguf, which I ran successfully using Ollama like this:
ollama pull hf.co/mistralai/Magistral-Small-2506_gguf:Q8_0
That fetched a 25GB file. I ran prompts using a chat session with llm-ollama like this:
llm chat -m hf.co/mistralai/Magistral-Small-2506_gguf:Q8_0
Here's what I got for "Generate an SVG of a pelican riding a bicycle" (transcript here):

It's disappointing that the GGUF doesn't support function calling yet - hopefully a community variant can add that, it's one of the best ways I know of to unlock the potential of these reasoning models.
I just noticed that Ollama have their own Magistral model too, which can be accessed using:
ollama pull magistral:latest
That gets you a 14GB q4_K_M quantization - other options can be found in the full list of Ollama magistral tags.
One thing that caught my eye in the Magistral announcement:
Legal, finance, healthcare, and government professionals get traceable reasoning that meets compliance requirements. Every conclusion can be traced back through its logical steps, providing auditability for high-stakes environments with domain-specialized AI.
I guess this means the reasoning traces are fully visible and not redacted in any way - interesting to see Mistral trying to turn that into a feature that's attractive to the business clients they are most interested in appealing to.
Also from that announcement:
Our early tests indicated that Magistral is an excellent creative companion. We highly recommend it for creative writing and storytelling, with the model capable of producing coherent or — if needed — delightfully eccentric copy.
I haven't seen a reasoning model promoted for creative writing in this way before.
You can try out Magistral Medium by selecting the new "Thinking" option in Mistral's Le Chat.
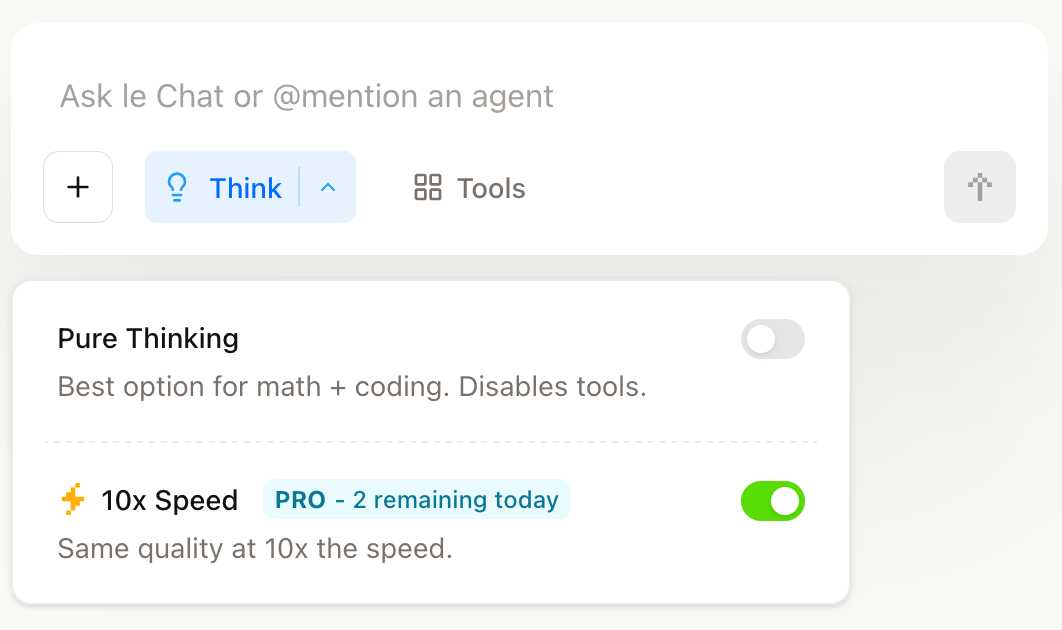
They have options for "Pure Thinking" and a separate option for "10x speed", which runs Magistral Medium at 10x the speed using Cerebras.
The new models are also available through the Mistral API. You can access them by installing llm-mistral and running llm mistral refresh to refresh the list of available models, then:
llm -m mistral/magistral-medium-latest \
'Generate an SVG of a pelican riding a bicycle'

Here's that transcript. At 13 input and 1,236 output tokens that cost me 0.62 cents - just over half a cent.