Entries Links Quotes Notes Guides Elsewhere
April 4, 2026
[GitHub] platform activity is surging. There were 1 billion commits in 2025. Now, it's 275 million per week, on pace for 14 billion this year if growth remains linear (spoiler: it won't.)
GitHub Actions has grown from 500M minutes/week in 2023 to 1B minutes/week in 2025, and now 2.1B minutes so far this week.
— Kyle Daigle, COO, GitHub
April 3, 2026
Vulnerability Research Is Cooked. Thomas Ptacek's take on the sudden and enormous impact the latest frontier models are having on the field of vulnerability research.
Within the next few months, coding agents will drastically alter both the practice and the economics of exploit development. Frontier model improvement won’t be a slow burn, but rather a step function. Substantial amounts of high-impact vulnerability research (maybe even most of it) will happen simply by pointing an agent at a source tree and typing “find me zero days”.
Why are agents so good at this? A combination of baked-in knowledge, pattern matching ability and brute force:
You can't design a better problem for an LLM agent than exploitation research.
Before you feed it a single token of context, a frontier LLM already encodes supernatural amounts of correlation across vast bodies of source code. Is the Linux KVM hypervisor connected to the
hrtimersubsystem,workqueue, orperf_event? The model knows.Also baked into those model weights: the complete library of documented "bug classes" on which all exploit development builds: stale pointers, integer mishandling, type confusion, allocator grooming, and all the known ways of promoting a wild write to a controlled 64-bit read/write in Firefox.
Vulnerabilities are found by pattern-matching bug classes and constraint-solving for reachability and exploitability. Precisely the implicit search problems that LLMs are most gifted at solving. Exploit outcomes are straightforwardly testable success/failure trials. An agent never gets bored and will search forever if you tell it to.
The article was partly inspired by this episode of the Security Cryptography Whatever podcast, where David Adrian, Deirdre Connolly, and Thomas interviewed Anthropic's Nicholas Carlini for 1 hour 16 minutes.
I just started a new tag here for ai-security-research - it's up to 11 posts already.
A fun thing about recording a podcast with a professional like Lenny Rachitsky is that his team know how to slice the resulting video up into TikTok-sized short form vertical videos. Here's one he shared on Twitter today which ended up attracting over 1.1m views!
That was 48 seconds. Our full conversation lasted 1 hour 40 minutes.
On the kernel security list we've seen a huge bump of reports. We were between 2 and 3 per week maybe two years ago, then reached probably 10 a week over the last year with the only difference being only AI slop, and now since the beginning of the year we're around 5-10 per day depending on the days (fridays and tuesdays seem the worst). Now most of these reports are correct, to the point that we had to bring in more maintainers to help us.
And we're now seeing on a daily basis something that never happened before: duplicate reports, or the same bug found by two different people using (possibly slightly) different tools.
— Willy Tarreau, Lead Software Developer. HAPROXY
The challenge with AI in open source security has transitioned from an AI slop tsunami into more of a ... plain security report tsunami. Less slop but lots of reports. Many of them really good.
I'm spending hours per day on this now. It's intense.
— Daniel Stenberg, lead developer of cURL
Months ago, we were getting what we called 'AI slop,' AI-generated security reports that were obviously wrong or low quality. It was kind of funny. It didn't really worry us.
Something happened a month ago, and the world switched. Now we have real reports. All open source projects have real reports that are made with AI, but they're good, and they're real.
— Greg Kroah-Hartman, Linux kernel maintainer (bio), in conversation with Steven J. Vaughan-Nichols
In trying to build my own version of Claude Artifacts I got curious about options for applying CSP headers to content in sandboxed iframes without using a separate domain to host the files. Turns out you can inject <meta http-equiv="Content-Security-Policy"...> tags at the top of the iframe content and they'll be obeyed even if subsequent untrusted JavaScript tries to manipulate them.
The Axios supply chain attack used individually targeted social engineering
The Axios team have published a full postmortem on the supply chain attack which resulted in a malware dependency going out in a release the other day, and it involved a sophisticated social engineering campaign targeting one of their maintainers directly. Here’s Jason Saayman’a description of how that worked:
[... 357 words]April 2, 2026
Highlights from my conversation about agentic engineering on Lenny’s Podcast

I was a guest on Lenny Rachitsky’s podcast, in a new episode titled An AI state of the union: We’ve passed the inflection point, dark factories are coming, and automation timelines. It’s available on YouTube, Spotify, and Apple Podcasts. Here are my highlights from our conversation, with relevant links.
[... 3,558 words]Gemma 4: Byte for byte, the most capable open models. Four new vision-capable Apache 2.0 licensed reasoning LLMs from Google DeepMind, sized at 2B, 4B, 31B, plus a 26B-A4B Mixture-of-Experts.
Google emphasize "unprecedented level of intelligence-per-parameter", providing yet more evidence that creating small useful models is one of the hottest areas of research right now.
They actually label the two smaller models as E2B and E4B for "Effective" parameter size. The system card explains:
The smaller models incorporate Per-Layer Embeddings (PLE) to maximize parameter efficiency in on-device deployments. Rather than adding more layers or parameters to the model, PLE gives each decoder layer its own small embedding for every token. These embedding tables are large but are only used for quick lookups, which is why the effective parameter count is much smaller than the total.
I don't entirely understand that, but apparently that's what the "E" in E2B means!
One particularly exciting feature of these models is that they are multi-modal beyond just images:
Vision and audio: All models natively process video and images, supporting variable resolutions, and excelling at visual tasks like OCR and chart understanding. Additionally, the E2B and E4B models feature native audio input for speech recognition and understanding.
I've not figured out a way to run audio input locally - I don't think that feature is in LM Studio or Ollama yet.
I tried them out using the GGUFs for LM Studio. The 2B (4.41GB), 4B (6.33GB) and 26B-A4B (17.99GB) models all worked perfectly, but the 31B (19.89GB) model was broken and spat out "---\n" in a loop for every prompt I tried.
The succession of pelican quality from 2B to 4B to 26B-A4B is notable:
E2B:
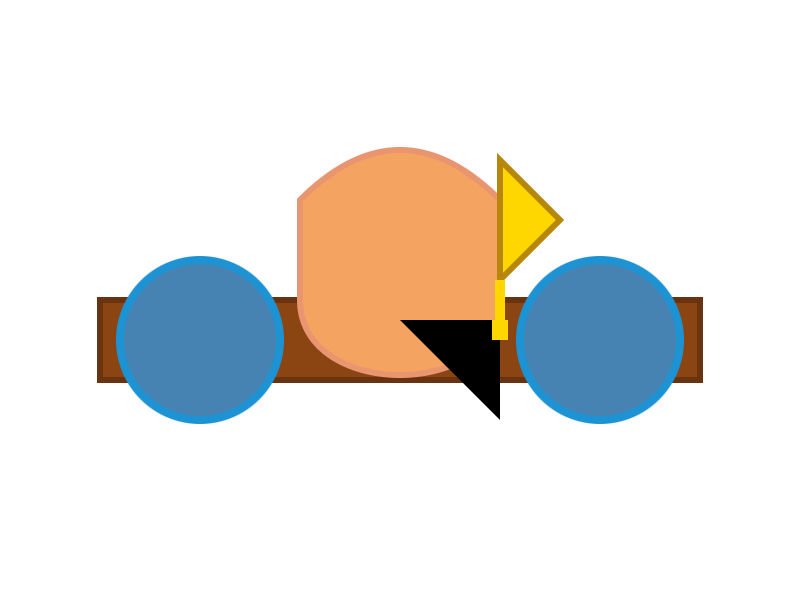
E4B:
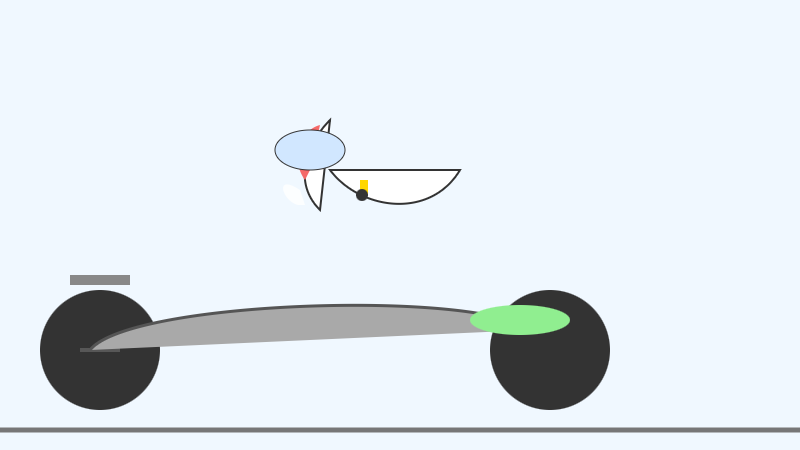
26B-A4B:

(This one actually had an SVG error - "error on line 18 at column 88: Attribute x1 redefined" - but after fixing that I got probably the best pelican I've seen yet from a model that runs on my laptop.)
Google are providing API access to the two larger Gemma models via their AI Studio. I added support to llm-gemini and then ran a pelican through the 31B model using that:
llm -m gemini/gemma-4-31b-it 'Generate an SVG of a pelican riding a bicycle'
Pretty good, though it is missing the front part of the bicycle frame:

New models gemini-3.1-flash-lite-preview, gemma-4-26b-a4b-it and gemma-4-31b-it. See my notes on Gemma 4.
I just sent the March edition of my sponsors-only monthly newsletter. If you are a sponsor (or if you start a sponsorship now) you can access it here. In this month's newsletter:
- More agentic engineering patterns
- Streaming experts with MoE models on a Mac
- Model releases in March
- Vibe porting
- Supply chain attacks against PyPI and NPM
- Stuff I shipped
- What I'm using, March 2026 edition
- And a couple of museums
Here's a copy of the February newsletter as a preview of what you'll get. Pay $10/month to stay a month ahead of the free copy!
April 1, 2026
- The same model ID no longer needs to be repeated in both the default model and allowed models lists - setting it as a default model automatically adds it to the allowed models list. #6
- Improved documentation for Python API usage.
- The
actorwho triggers an enrichment is now passed to thellm.mode(... actor=actor)method. #3
- Now uses datasette-llm to manage model configuration, which means you can control which models are available for extraction tasks using the
extractpurpose and LLM model configuration. #38
- This plugin now uses datasette-llm to configure and manage models. This means it's possible to specify which models should be made available for enrichments, using the new
enrichmentspurpose.
- Removed features relating to allowances and estimated pricing. These are now the domain of datasette-llm-accountant.
- Now depends on datasette-llm for model configuration. #3
- Full prompts and responses and tool calls can now be logged to the
llm_usage_prompt_logtable in the internal database if you set the newdatasette-llm-usage.log_promptsplugin configuration setting.- Redesigned the
/-/llm-usage-simple-promptpage, which now requires thellm-usage-simple-promptpermission.
- The
llm_prompt_context()plugin hook wrapper mechanism now tracks prompts executed within a chain as well as one-off prompts, which means it can be used to track tool call loops. #5
I want to argue that AI models will write good code because of economic incentives. Good code is cheaper to generate and maintain. Competition is high between the AI models right now, and the ones that win will help developers ship reliable features fastest, which requires simple, maintainable code. Good code will prevail, not only because we want it to (though we do!), but because economic forces demand it. Markets will not reward slop in coding, in the long-term.
— Soohoon Choi, Slop Is Not Necessarily The Future
March 31, 2026
Supply Chain Attack on Axios Pulls Malicious Dependency from npm
(via)
Useful writeup of today's supply chain attack against Axios, the HTTP client NPM package with 101 million weekly downloads. Versions 1.14.1 and 0.30.4 both included a new dependency called plain-crypto-js which was freshly published malware, stealing credentials and installing a remote access trojan (RAT).
It looks like the attack came from a leaked long-lived npm token. Axios have an open issue to adopt trusted publishing, which would ensure that only their GitHub Actions workflows are able to publish to npm. The malware packages were published without an accompanying GitHub release, which strikes me as a useful heuristic for spotting potentially malicious releases - the same pattern was present for LiteLLM last week as well.
- Ability to configure different API keys for models based on their purpose - for example, set it up so enrichments always use
gpt-5.4-miniwith an API key dedicated to that purpose. #4
I released llm-echo 0.3 to provide an API key testing utility I needed for the tests for this new feature.
LLM plugins can define new models in both sync and async varieties. The async variants are most common for API-backed models - sync variants tend to be things that run the model directly within the plugin.
My llm-mrchatterbox plugin is sync only. I wanted to try it out with various Datasette LLM features (specifically datasette-enrichments-llm) but Datasette can only use async models.
So... I had Claude spin up this plugin that turns sync models into async models using a thread pool. This ended up needing an extra plugin hook mechanism in LLM itself, which I shipped just now in LLM 0.30.
- The register_models() plugin hook now takes an optional
model_aliasesparameter listing all of the models, async models and aliases that have been registered so far by other plugins. A plugin with@hookimpl(trylast=True)can use this to take previously registered models into account. #1389- Added docstrings to public classes and methods and included those directly in the documentation.
- Prompts now have the
input_tokensandoutput_tokensfields populated on the response.
- Mechanisms for testing tool calls. #3
- Mechanism for testing raw responses. #4
- New
echo-needs-keymodel for testing model key logic. #7
March 30, 2026
I'm working on integrating datasette-files into other plugins, such as datasette-extract. This necessitated a new release of the base plugin.
owners_can_editandowners_can_deleteconfiguration options, plus thefiles-editandfiles-deleteactions are now scoped to a newFileResourcewhich is a child ofFileSourceResource. #18- The file picker UI is now available as a
<datasette-file-picker>Web Component. Thanks, Alex Garcia. #19- New
from datasette_files import get_filePython API for other plugins that need to access file data. #20
Note that the main issues that people currently unknowingly face with local models mostly revolve around the harness and some intricacies around model chat templates and prompt construction. Sometimes there are even pure inference bugs. From typing the task in the client to the actual result, there is a long chain of components that atm are not only fragile - are also developed by different parties. So it's difficult to consolidate the entire stack and you have to keep in mind that what you are currently observing is with very high probability still broken in some subtle way along that chain.
— Georgi Gerganov, explaining why it's hard to find local models that work well with coding agents
Adds the ability to configure which LLMs are available for which purpose, which means you can restrict the list of models that can be used with a specific plugin. #3
Mr. Chatterbox is a (weak) Victorian-era ethically trained model you can run on your own computer
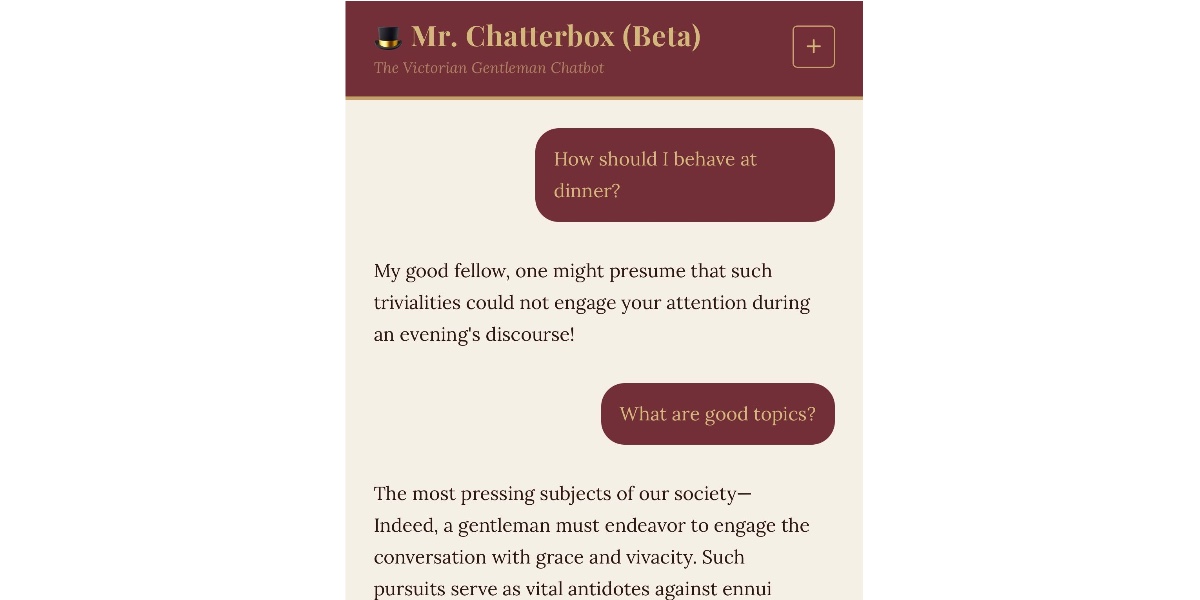
Trip Venturella released Mr. Chatterbox, a language model trained entirely on out-of-copyright text from the British Library. Here’s how he describes it in the model card:
[... 952 words]