June 2021
54 posts: 5 entries, 17 links, 3 quotes, 29 beats
June 13, 2021
June 17, 2021
Multi-region PostgreSQL on Fly (via) Really interesting piece of architectural design from Fly here. Fly can run your application (as a Docker container run using Firecracker) in multiple regions around the world, and they’ve now quietly added PostgreSQL multi-region support. The way it works is that all-but-one region can have a read-only replica, and requests sent to application servers can perform read-only queries against their local region’s replica. If a request needs to execute a SQL update your application code can return a “fly-replay: region=scl” HTTP header and the Fly CDN will transparently replay the request against the region containing the leader database. This also means you can implement tricks like setting a 10s expiring cookie every time the user performs a write, such that their requests in the next 10s will go straight to the leader and avoid them experiencing any replication lag that hasn’t caught up with their latest update.
June 19, 2021

Joining CSV and JSON data with an in-memory SQLite database
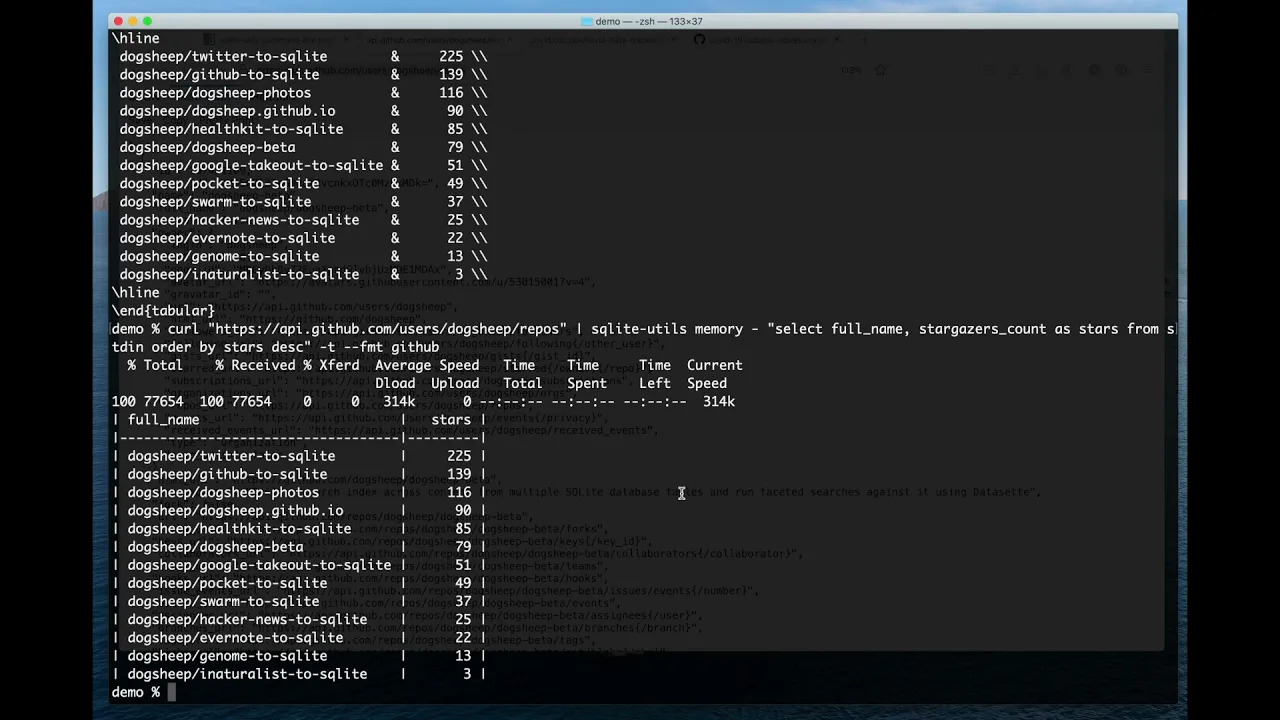
The new sqlite-utils memory command can import CSV and JSON data directly into an in-memory SQLite database, combine and query it using SQL and output the results as CSV, JSON or various other formats of plain text tables.
June 20, 2021
June 21, 2021

June 22, 2021
GitLab Culture: The phases of remote adaptation. GitLab claim to be “the world’s largest all-remote company”—1300 employees across 65 countries, with not a single physical office. Lots of interesting thinking in this article about different phases a company can go through to become truly remote-first. “Maximally efficient remote environments will do as little work as possible synchronously, instead focusing the valuable moments where two or more people are online at the same time on informal communication and bonding.” They also expire their Slack messages after 90 days to force critical project information into documents and issue threads.
What I’ve learned about data recently (via) Laurie Voss talks about the structure of data teams, based on his experience at npm and more recently Netlify. He suggests that Airflow and dbt are the data world’s equivalent of frameworks like Rails: opinionated tools that solve core problems and which mean that you can now hire people who understand how your data pipelines work on their first day on the job.
A framework for building Open Graph images. GitHub’s new social preview images are generated by a Node.js script that fetches data from their GraphQL API, generates an HTML version of the card and then grabs a PNG snapshot of it using Puppeteer. It takes an average of 280ms to serve an image and generates around 2 million unique images a day. Interestingly, they found that bumping the available RAM from 512MB up to 513MB had a big effect on performance, because Chromium detects devices on 512MB or less and switches some processes from parallel to sequential.
June 23, 2021
June 24, 2021
Django for Startup Founders: A better software architecture for SaaS startups and consumer apps (via) The opening section of this article has very little to do with Django: it’s an insightful description of the technical challenges faced by a startup that is still seeking product-market fit. Alex then extends that into his own architectural recommendations for startups building with Django to help waste as little time as possible on problems that aren’t core to the product they are building.
June 25, 2021
Notes on streaming large API responses
I started a Twitter conversation last week about API endpoints that stream large amounts of data as an alternative to APIs that return 100 results at a time and require clients to paginate through all of the pages in order to retrieve all of the data:
[... 1,692 words]Hierarchical Structures in PostgreSQL (via) Two techniques I hadn’t seen before: the first is to define a materialized view using a CTE that offers efficient tree queries against a PostgreSQL array of path components (plus a trigger to update the materialized view), the second is with the PostgreSQL ltree extension which ships as part of PostgreSQL and hence should be widely available.
- New db.query(sql, params) method, which executes a SQL query and returns the results as an iterator over Python dictionaries. (#290)
- This project now uses
flake8and has started to usemypy. (#291)- New documentation on contributing to this project. (#292)
PostgreSQL: nbtree/README (via) The PostgreSQL source tree includes beatifully written README files for different parts of PostgreSQL. Here’s the README for their btree implementation—it continues to be actively maintained (last change was is March) and “git blame” shows that parts of the file date back 25 years, to 1996!
Querying Parquet using DuckDB (via) DuckDB is a relatively new SQLite-style database (released as an embeddable library) with a focus on analytical queries. This tutorial really made the benefits click for me: it ships with support for the Parquet columnar data format, and you can use it to execute SQL queries directly against Parquet files—e.g. “SELECT COUNT(*) FROM ’taxi_2019_04.parquet’”. Performance against large files is fantastic, and the whole thing can be installed just using “pip install duckdb”. I wonder if faceting-style group/count queries (pretty expensive with regular RDBMSs) could be sped up with this?
A Datasette tutorial in Portuguese. Nicolás Linares put together this Datasette tutorial in Portuguese, including an explanation of the project, how to get it up and running on a laptop, how to use it to explore and facet data, how to use plugins (including datasette-vega and datasette-cluster-map) and how to publish data using Vercel. I ran this through Google Translate and I can confirm that it’s a really well constructed tutorial—fantastic to see material like this starting to emerge in languages other than English.
June 27, 2021
Group thousands of similar spreadsheet text cells in seconds (via) Luke Whyte explains how to efficiently group similar text columns in a table (Walmart and Wal-mart for example) using a clever combination of TF/IDF, sparse matrices and cosine similarity. Includes the clearest explanation of cosine similarity for text I’ve seen—and Luke wrote a Python library, textpack, that implements the described pattern.
June 28, 2021
Weeknotes: sqlite-utils updates, Datasette and asgi-csrf, open-sourcing VIAL
Some work on sqlite-utils, asgi-csrf, a Datasette alpha and we open-sourced VIAL.
In 2015, the men controlling 80% of Bitcoin mining stood on stage together at a conference. Three or four entities have run Bitcoin mining since then. The only thing preventing miner misbehaviour is wanting to avoid spooking the suckers — it’s completely trust-based. Bitcoin now uses a country’s worth of electricity for no actual reason. You could do the transactions on a 2007 iPhone.