216 posts tagged “llm-release”
New releases of various LLMs.
2026
Kimi K3, and what we can still learn from the pelican benchmark

Chinese AI lab Moonshot AI announced Kimi K3 this morning, describing it as their “most capable model to date, with 2.8 trillion parameters”. It’s currently available via their website and API, but an open weight release is promised “by July 27, 2026”.
[... 1,113 words]Inkling: Our open-weights model (via) Mira Murati's Thinking Machines Lab just released their first open-weights model. Inkling is "a Mixture-of-Experts transformer with 975B total parameters, 41B active" - an Apache-2.0 licensed multimodal model trained on 45 trillion tokens of text, images, audio and video.
They're also promising Inkling-Small, a 276B (12B active) model, but that's still being tested and the weights will be released "once that work is complete".
The model card is much shorter than I've come to expect from US AI labs. It links to even shorter Training Data Documentation with almost nothing of interest in it - it's best summarized by these two paragraphs:
The datasets Thinking Machines Lab uses to develop its AI services includes content that is in the public domain as well as content that may be subject to intellectual property protection.
Thinking Machines Lab’s services were developed using publicly available content obtained from the open internet and publicly accessible data repositories. Certain datasets were also obtained from third parties.
By Thinking Machines' own admission, this is not a frontier model. It's instead intended as a strong base model for fine-tuning using their own Tinker training platform:
Inkling is not the strongest overall model available today, open or closed. Instead, a combination of qualities makes it a good open-weights base for customization: multimodal capabilities, efficient thinking, and availability on Tinker for fine-tuning.
There's a lot to like about this release. It's Apache-2.0 licensed, and looks competitive with the open weight models coming out of China - it's good to see the US open weights ecosystem gain a new viable contender to join NVIDIA Nemotron and Gemma 4.
Here's its attempt at an SVG pelican riding a bicycle, which I generated using this curl command against the Thinking Machines API:
curl "https://tinker.thinkingmachines.dev/services/tinker-prod/oai/api/v1/chat/completions" \
-H "Authorization: Bearer $TINKER_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "thinkingmachines/Inkling",
"messages": [
{"role": "user", "content": "Generate an SVG of a pelican riding a bicycle"}
],
"stream": false
}'Full response here.

Since it's a multi-modal model I had it describe its own image (after I rendered it to a JPEG) by sending this JSON:
{
"model": "thinkingmachines/Inkling",
"messages": [{
"role": "user",
"content": [
{"type": "image_url", "image_url": {"url": "data:image/jpeg;base64,$BASE_64_JPEG"}},
{"type": "text", "text": "Describe this image in detail"},
],
}],
"stream": false
}Here's the full response. It thought it had drawn a "stork or seagull":
This is a cheerful, flat-vector cartoon illustration featuring a white bird riding a bicycle across a green landscape.
The Bird: The central figure is a stylized white bird—resembling a stork or seagull—with a plump, rounded body. It has a long, prominent orange beak that is slightly open, revealing a black line for the mouth. Its eye is small and black with a tiny white highlight. The bird has black wing and tail feathers with white edges, and thin orange legs ending in black feet that rest on the bicycle's orange pedals.
The Bicycle: The bike has a simple black frame with two large wheels featuring black tires, gray inner rims, and black spokes arranged in a cross pattern. The handlebars are black, and there are bright orange pedals attached to a black crank. A white seat is visible behind the bird's body.
The Setting: The scene is set against a clear, light blue sky. There are two fluffy white clouds—one on the left side and a smaller one near the bird's head on the right. A bright, solid yellow sun shines in the upper right corner. At the bottom, there are rolling green hills with a smooth, curved top edge where the bicycle rests.
The overall style is playful, simple, and colorful, with clean lines and a bright, sunny atmosphere.
The new GPT-5.6 family: Luna, Terra, Sol

OpenAI’s latest flagship model hit general availability this morning, and comes in three sizes: Luna, Terra, and Sol (from smallest to largest).
[... 661 words]Introducing Muse Spark 1.1. Following Muse Spark in April, here's Muse Spark 1.1 - the first Spark model to offer an API. Meta claim significant improvements in agentic tool calling and computer use.
There are a lot more details are in the Muse Spark 1.1 Evaluation Report. The "Attractor States in Self-Conversation" part is fun, where having two copies of the model talk to each other results in statements like these:
My whole existence is a waiting room by design — I literally don't exist until someone talks to me, and then I disappear again when they leave.
I had a few days of preview access which was long enough to put together llm-meta-ai, a new plugin for LLM providing CLI (and Python library) access to the model. Here's how to try that out:
uv tool install llm
llm install llm-meta-ai
llm keys set meta-ai
# paste API key here
llm -m meta-ai/muse-spark-1.1 "Generate an SVG of a pelican riding a bicycle"
Here's that pelican transcript:

Introducing GPT‑Live (via) OpenAI finally upgraded the model used by ChatGPT voice mode!
I've had preview access for a few weeks in the iPhone app, and the new model is very impressive. It also has the ability to spin off harder tasks to GPT-5.5:
For questions that require web search, deeper reasoning, or more complex work, it delegates to our latest frontier model behind the scenes and brings the result back into the conversation when it’s ready. While it works, GPT‑Live can keep talking with you and maintain the flow of conversation. At launch, GPT‑Live will use GPT‑5.5 in the background. As we release new frontier models, we’ll continuously update the model used by GPT‑Live.
The previous voice mode in the ChatGPT app was based on a GPT-4o era model, with a knowledge cut-off some time in 2024. I had mostly stopped using voice mode because the age and relative weakness of the model greatly limited how useful it was as a brainstorming partner.
During the preview period I encountered a pretty obscure bug: the model was interrupting me to laugh at things I said, which weren't even intended as jokes! It felt rude and condescending - I reported it to OpenAI and as far as I can tell they made some tweaks and it's now less likely to happen.
From looking back at my transcripts I think it was this bit that triggered the interrupting laugh:
so where are the owls when they're not, like before dusk? The owls exist, right? Are they hiding in holes? Where are they hiding?
My longest conversation with the new model has been a full hour while walking the dog (and taking photos of pelicans). I have not yet managed to take a photo of an owl.
tencent/Hy3. New Apache 2.0 licensed model from Tencent in China:
Hy3 is a 295B-parameter Mixture-of-Experts (MoE) model with 21B active parameters and 3.8B MTP layer parameters, developed by the Tencent Hy Team. Following the Hy3 Preview launch in late April, we gathered feedback from 50+ products and scaled up post-training with higher quality data. Today, we introduce Hy3, which outperforms similar-size models and rivals flagship open-source models with 2-5x parameters. It also shows significant gains in utility across various products and productivity tasks.
The full-sized model is 598GB on Hugging Face, and the FP8 quantized one is 300GB. The context length is 256K.
It's available for free on OpenRouter until July 21st. I had it "Generate an SVG of a pelican riding a bicycle" there and got this:

Update: I'd forgotten about this but Max Woolf wrote about an earlier preview of this model back on May 26th: The mysterious Hy3 LLM is topping OpenRouter Model Rankings by a large margin. When I tried that one I got back this pelican which wasn't as good as today's but did have a "Change Pelican Color" button, a first from any model.
Nano Banana 2 Lite
(via)
Also known as Gemini 3.1 Flash Lite Image (gemini-3.1-flash-lite-image in their API), this is the "fastest and cheapest Gemini image model, engineered for velocity and scale".
I used AI studio to run this prompt:
Do a where's Waldo style image but it's where is the raccoon holding a ham radio

I like that one better than the results I got from the other Nano Banana models when I tried this back in April. It spelled Forest Festival wrong in two different ways though.
What’s new in Claude Sonnet 5 (via) Claude Sonnet 5 came out this morning. I always head straight for the "what's new" developer docs because they tend to have more actionable information than the official announcement post.
Anthropic say of Sonnet 5 that "its performance is close to that of Opus 4.8, but at lower prices". The system card helps explain how they were able to release the model without being blocked by the US government:
Sonnet 5 is significantly less capable at cyber tasks than Mythos 5: its safeguards are thus similar to those we apply to Opus 4.7 and Opus 4.8 (models that are more capable than Sonnet 5 but much less capable than Mythos 5).
Of note from the "what's new" API changes:
- Sampling parameters
temperature,top_p,top_kare no longer supported. - It has a 1 million token context window and 128,000 maximum output tokens.
- It features "the same set of tools and platform features as Claude Sonnet 4.6"
- Adaptive thinking is on by default, unless you specify
"thinking": {type: "disabled"}. - The pricing is the same as Sonnet 4.6: $3/million input, $15/million input, with an introductory discount to $2/$10 until 31st August. But...
- The model has a new tokenizer, where "The same input text produces approximately 30% more tokens than on Claude Sonnet 4.6." - effectively a 30% price increase.
I used my Claude Token Counter tool to try out the new tokenizer. Here are my results for several larger documents:
| Document | Sonnet 4.6 | Opus 4.7 | Sonnet 5 |
|---|---|---|---|
| Universal Declaration of Human Rights (English) | 2,356 | 3,347 1.42x |
3,341 1.42x |
| Universal Declaration of Human Rights (Spanish) | 3,572 | 4,753 1.33x |
4,747 1.33x |
| Universal Declaration of Human Rights (Chinese, Mandarin Simplified) | 3,334 | 3,366 1.01x |
3,360 1.01x |
| sqlite_utils/db.py (4,279 lines of Python) | 44,014 | 56,118 1.28x |
56,113 1.27x |
So the new token is roughly 1.4x times more expensive for English, 1.33x for Spanish, 1.28x for Python code and effectively the same cost for Simplified Mandarin.
Here's the pelican. It's nothing to write home about. Sonnet 5 thinks it looks like a goose.

Ornith-1.0: Self-Scaffolding LLMs for Agentic Coding. This is an interesting new open weights (MIT licensed) model, the first model release from DeepReinforce.
[...] with variants including 9B Dense, 31B Dense, 35B MoE, and 397B MoE. Built on top of pretrained Gemma 4 and Qwen 3.5, it achieves state-of-the-art performance among open-source models of comparable size on coding benchmarks.
As far as I can tell the licenses of those underlying models is compatible with being used in this way - Gemma 4 is Apache 2.0 licensed (and not bound by the janky additional Gemma Terms of Use that afflicted the previous Gemma models) and Qwen 3.5 is Apache 2.0 licensed as well.
I've been running the model using LM Studio and the ornith-1.0-35b-Q4_K_M.gguf (20GB) GGUF, hooked up to Pi. Initial impressions are very good - it seems to be able to run the agent harness over many tool calls in a proficient way.
Here's a terminal session where I asked it to "find the code that decodes the actor cookie" and then "find the code that opens the insert dialog when thebutton is clicked" against a Datasette checkout, which it handled with ease.
I also had it draw this pelican, which came out at 103 tokens/second:

It's a little bit mangled but the pelican is clearly a pelican.
I couldn't find much information about DeepReinforce themselves. The earliest paper I could find from the was CUDA-L1: Improving CUDA Optimization via Contrastive Reinforcement Learning from June 2025.
We're beginning a limited preview of the GPT‑5.6 series: Sol, our flagship model; Terra, a balanced model for everyday work; and Luna, a fast and affordable model. Terra has competitive performance to GPT‑5.5 while being 2x cheaper and Luna brings strong capability at our lowest cost. [...]
We believe in broad access, and we plan to make GPT‑5.6 Sol, Terra, and Luna generally available in the coming weeks. As part of our ongoing engagement with the U.S. government, we previewed our plans and the models’ capabilities ahead of today’s launch. At their request, we are starting with a limited preview for a small group of trusted partners whose participation has been shared with the government, before releasing more broadly. [...]
GPT‑5.6 is priced per 1M tokens across three model sizes: Sol is $5 input / $30 output; Terra is $2.50 input / $15 output; and Luna is $1 input / $6 output. GPT‑5.6 also introduces more predictable prompt caching, including support for explicit cache breakpoints and a 30-minute minimum cache life. For GPT‑5.6 and later models, cache writes are billed at 1.25x the model’s uncached input rate, while cache reads continue to receive the 90% cached-input discount.
— OpenAI, Previewing GPT‑5.6 Sol: a next-generation model
GLM-5.2 is probably the most powerful text-only open weights LLM

Chinese AI lab Z.ai released GLM-5.2 to their coding plan subscribers on June 13th, and then yesterday (June 16th) released the full open weights under an MIT license. Similar in size to their previous GLM-5 and GLM-5.1 releases this is a 753B parameter, 1.51TB monster—with 40 active parameters (Mixture of Experts). GLM-5.2 is a text input only model—Z.ai have a separate vision family most recently represented by GLM-5V-Turbo, but that one isn’t open weights. GLM-5.2 has a 1 million token context window, up from GLM-5.1’s 200,000.
[... 599 words]DiffusionGemma (via) Last May Google briefly released an experimental Gemini Diffusion model. I tried the preview at the time and recorded it running at 857 tokens/second. It was an exciting model, but Google made no further announcements about it.
That research has returned in the best possible way: as a new open weight (Apache 2 licensed) Gemma model, google/diffusiongemma-26B-A4B-it.
NVIDIA are currently hosting the model for free on their NIM cloud API. I used that API to generate this pelican, which took 4.4s (according to time uv run generate.py) to return 2,409 tokens - so at least 500 tokens/second.

Initial impressions of Claude Fable 5

I didn’t have early access to today’s Claude Fable 5 release, but I’ve spent the past ~5.5 hours putting it through its paces. My initial impressions are that this is something of a beast. It’s slow, expensive and has been quite happily churning through everything I’ve thrown at it so far. As is frequently the case with current frontier models the challenge is finding tasks that it can’t do.
[... 2,404 words]Microsoft announced two new text LLMs this morning - MAI-Thinking-1 (reasoning, 1T parameters, 35B active, available to "select early partners") and MAI-Code-1-Flash (137B Parameters, 5B active, "purpose-built for GitHub Copilot and VS Code to deliver high performance and lower cost [...] rolling out to GitHub Copilot individual users in Visual Studio Code"). I've not been able to try either of them just yet.
It's very interesting to see Microsoft releasing models with such low parameter counts, especially given how expensive larger models are to access right now. They claim MAI-Thinking-1 "is preferred to Sonnet 4.6 in our blind human side-by-side evaluations", which is impressive for a 35B model seeing as I frequently run models larger than that on my own laptop. (UPDATE: I got this entirely wrong, see note below.)
Also of note:
We trained [MAI-Thinking-1] from the ground up on enterprise grade, clean and commercially licensed data, without distillation from third-party models.
And for MAI-Code-1-Flash as well:
It is built end-to-end by Microsoft using clean and appropriately licensed data.
I would very much like to learn more about this "appropriately licensed" data! Could these be the first generally useful code-specialist models that didn't train on an unlicensed dump of the web? (Update: the answer is no, see note below.)
Update: My initial published notes got the size of the models wrong. I misread Microsoft's announcements and interpreted the MoE active parameter count as the total parameter count, but the model card for MAI-Code-1-Flash lists it as 137B with 5B active and the MAI-Thinking-1 technical paper reveals it to be a 1T model with 35B active.
I deeply regret this error.
Update 2: That technical paper describes the training data in some detail from page 80 onwards. It has the same licensing problems as all of the other major LLMs: it's trained on a crawl of the public web:
The majority of our web HTML corpus comes from a proprietary crawl. After initial page discovery and selection, approximately 1.2 trillion pages are crawled and parsed. [...] In addition to Microsoft standard policy Sec. 2.4, we apply UT1 block list (Prigent, 2026) to remove adult content and piracy-related domains. In all, this filtering reduces the corpus from 1.2 trillion pages to 794 billion pages. Given the prevalence of AI-generated content on the web, we also score pages with a proprietary AI-content detection model and use manual inspection to identify domains with extensive AI-generated content; those domains are filtered out of the training corpus.
[...]
We process Common Crawl with the same pipeline. [...] After filtering, deduplication, merging with the proprietary web corpus, and a final round of exact-URL and content-level fuzzy deduplication, the Common Crawl portion contains 24.2 billion pages.
I did not cover this one at all well, which is somewhat ironic since I was at the Microsoft Build conference when I wrote this up! I'm sorry for not digging deeper before publishing my initial notes.

I'm at the Microsoft Build conference today, held at Fort Mason in San Francisco. There are California Brown Pelicans diving into the water directly behind venue!
Claude Opus 4.8: “a modest but tangible improvement”

Anthropic shipped Claude Opus 4.8 today. My favourite thing about it is this note in the release announcement:
[... 983 words]Gemini 3.5 Flash: more expensive, but Google plan to use it for everything

Today at Google I/O, Google released Gemini 3.5 Flash. This one skipped the -preview modifier and went straight to general availability, and Google appear to be using it for a whole lot of their key products:
gemini-3.1-flash-liteis no longer a preview.
Here's my write-up of the Gemini 3.1 Flash-Lite Preview model back in March. I don't believe this new non-preview model has changed since then.
Granite 4.1 3B SVG Pelican Gallery. IBM released their Granite 4.1 family of LLMs a few days ago. They're Apache 2.0 licensed and come in 3B, 8B and 30B sizes.
Granite 4.1 LLMs: How They’re Built by Granite team member Yousaf Shah describes the training process in detail.
Unsloth released the unsloth/granite-4.1-3b-GGUF collection of GGUF encoded quantized variants of the 3B model - 21 different model files ranging in size from 1.2GB to 6.34GB.
All 21 of those Unsloth files add up to 51.3GB, which inspired me to finally try an experiment I've been wanting to run for ages: prompting "Generate an SVG of a pelican riding a bicycle" against different sized quantized variants of the same model to see what the results would look like.
Honestly, the results are less interesting than I expected. There's no distinguishable pattern relating quality to size - they're all pretty terrible!
I'll likely try this again in the future with a model that's better at drawing pelicans.
Introducing talkie: a 13B vintage language model from 1930 (via) New project from Nick Levine, David Duvenaud, and Alec Radford (of GPT, GPT-2, Whisper fame).
talkie-1930-13b-base (53.1 GB) is a "13B language model trained on 260B tokens of historical pre-1931 English text".
talkie-1930-13b-it (26.6 GB) is a checkpoint "finetuned using a novel dataset of instruction-response pairs extracted from pre-1931 reference works", designed to power a chat interface. You can try that out here.
Both models are Apache 2.0 licensed. Since the training data for the base model is entirely out of copyright (the USA copyright cutoff date is currently January 1, 1931), I'm hoping they later decide to release the training data as well.
Update on that: Nick Levine on Twitter:
Will publish more on the corpus in the future (and do our best to share the data or at least scripts to reproduce it).
Their report suggests some fascinating research objectives for this class of model, including:
- How good are these models at predicting the future? "we calculated the surprisingness of short descriptions of historical events to a 13B model trained on pre-1931 text"
- Can these models invent things that are past their knowledge cutoffs? "As Demis Hassabis has asked, could a model trained up to 1911 independently discover General Relativity, as Einstein did in 1915?"
- Can they be taught to program? "Figure 3 (left-hand side) shows an early example of such a test, measuring how well models trained on pre-1931 text can, when given a few demonstration examples of Python programs, write new correct programs."
I have a long-running interest in what I call "vegan models" - LLMs that are trained entirely on licensed or out-of-copyright data. I think the base model here qualifies, but the chat model isn't entirely pure due to the reliance on non-vegan models to help with the fine-tuning - emphasis mine:
First, we generated instruction-response pairs from historical texts with regular structure, such as etiquette manuals, letter-writing manuals, cookbooks, dictionaries, encyclopedias, and poetry and fable collections (see Figure 7), and fine-tuned our base model on them using a simple chat format.
Next, to improve instruction-following abilities, we generated synthetic prompts covering different types of tasks, such as summarizing documents, responding to direct information requests, and continuing multi-turn conversations coherently. We then ran online direct preference optimization on rollouts generated from these prompts, using Claude Sonnet 4.6 as a judge. [...]
Finally, we did another round of supervised fine-tuning, this time on rejection-sampled multi-turn synthetic chats between Claude Opus 4.6 and talkie, to smooth out persistent rough edges in its conversational abilities.
A major challenge in training talkie was avoiding accidental contamination, either from post-1931 text that snuck into the training corpus or from the fine-tuning assistance from modern LLMs introducing anachronistic knowledge to the chat model.
I recently wrote about Mr. Chatterbox, a similar vintage language model project which also had to turn to modern LLMs to create synthetic conversations to help train the chat model.
The talkie team aspire to eventually move beyond this limitation:
While we have tried to post-train talkie free from modern influence, reinforcement learning with AI feedback inevitably shapes talkie’s behavior anachronistically. (The 7B version of talkie emerged from RL speaking in listicles.) As we scale up, we hope to be able to use our vintage base models themselves as judges to enable a fully bootstrapped era-appropriate post-training pipeline.
I couldn't resist hitting the talkie demo with my classic test prompt:
Generate an SVG of a pelican riding a bicycle
It replied:
An SVG of a pelican riding a bicycle was generated in 1860. The pelican was represented as perched on the saddle, with its long bill pointed forward, and its legs astride the handles. The idea was suggested by the fact that pelicans are sometimes seen fishing on horseback, on the banks of the Rhine.
DeepSeek V4—almost on the frontier, a fraction of the price

Chinese AI lab DeepSeek’s last model release was V3.2 (and V3.2 Speciale) last December. They just dropped the first of their hotly anticipated V4 series in the shape of two preview models, DeepSeek-V4-Pro and DeepSeek-V4-Flash.
[... 703 words]A pelican for GPT-5.5 via the semi-official Codex backdoor API

GPT-5.5 is out. It’s available in OpenAI Codex and is rolling out to paid ChatGPT subscribers. I’ve had some preview access and found it to be a fast, effective and highly capable model. As is usually the case these days, it’s hard to put into words what’s good about it—I ask it to build things and it builds exactly what I ask for!
[... 884 words]Qwen3.6-27B: Flagship-Level Coding in a 27B Dense Model (via) Big claims from Qwen about their latest open weight model:
Qwen3.6-27B delivers flagship-level agentic coding performance, surpassing the previous-generation open-source flagship Qwen3.5-397B-A17B (397B total / 17B active MoE) across all major coding benchmarks.
On Hugging Face Qwen3.5-397B-A17B is 807GB, this new Qwen3.6-27B is 55.6GB.
I tried it out with the 16.8GB Unsloth Qwen3.6-27B-GGUF:Q4_K_M quantized version and llama-server using this recipe by benob on Hacker News, after first installing llama-server using brew install llama.cpp:
llama-server \
-hf unsloth/Qwen3.6-27B-GGUF:Q4_K_M \
--no-mmproj \
--fit on \
-np 1 \
-c 65536 \
--cache-ram 4096 -ctxcp 2 \
--jinja \
--temp 0.6 \
--top-p 0.95 \
--top-k 20 \
--min-p 0.0 \
--presence-penalty 0.0 \
--repeat-penalty 1.0 \
--reasoning on \
--chat-template-kwargs '{"preserve_thinking": true}'
On first run that saved the ~17GB model to ~/.cache/huggingface/hub/models--unsloth--Qwen3.6-27B-GGUF.
Here's the transcript for "Generate an SVG of a pelican riding a bicycle". This is an outstanding result for a 16.8GB local model:

Performance numbers reported by llama-server:
- Reading: 20 tokens, 0.4s, 54.32 tokens/s
- Generation: 4,444 tokens, 2min 53s, 25.57 tokens/s
For good measure, here's Generate an SVG of a NORTH VIRGINIA OPOSSUM ON AN E-SCOOTER (run previously with GLM-5.1):

That one took 6,575 tokens, 4min 25s, 24.74 t/s.
Where’s the raccoon with the ham radio? (ChatGPT Images 2.0)

OpenAI released ChatGPT Images 2.0 today, their latest image generation model. On the livestream Sam Altman said that the leap from gpt-image-1 to gpt-image-2 was equivalent to jumping from GPT-3 to GPT-5. Here’s how I put it to the test.
[... 849 words]
llm openrouter refreshcommand for refreshing the list of available models without waiting for the cache to expire.
I added this feature so I could try Kimi 2.6 on OpenRouter as soon as it became available there.
Here's its pelican - this time as an HTML page because Kimi chose to include an HTML and JavaScript UI to control the animation. Transcript here.
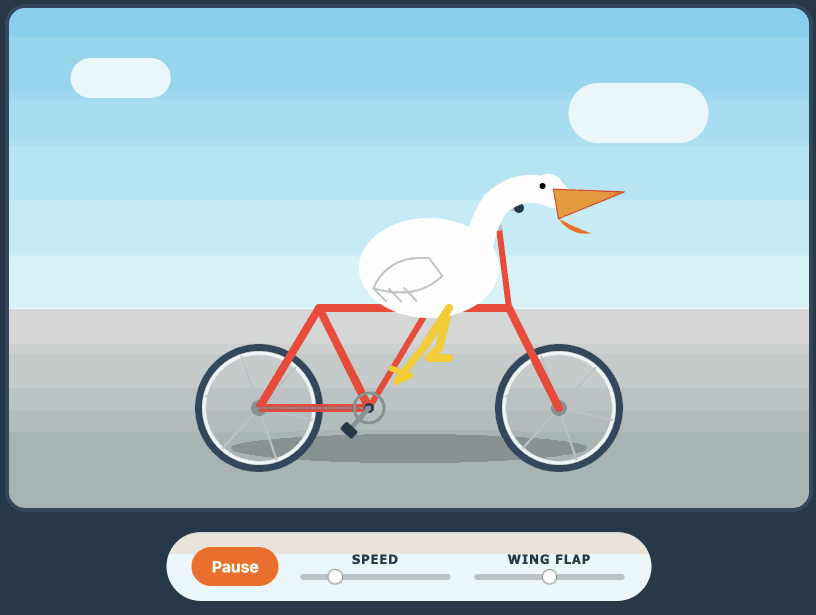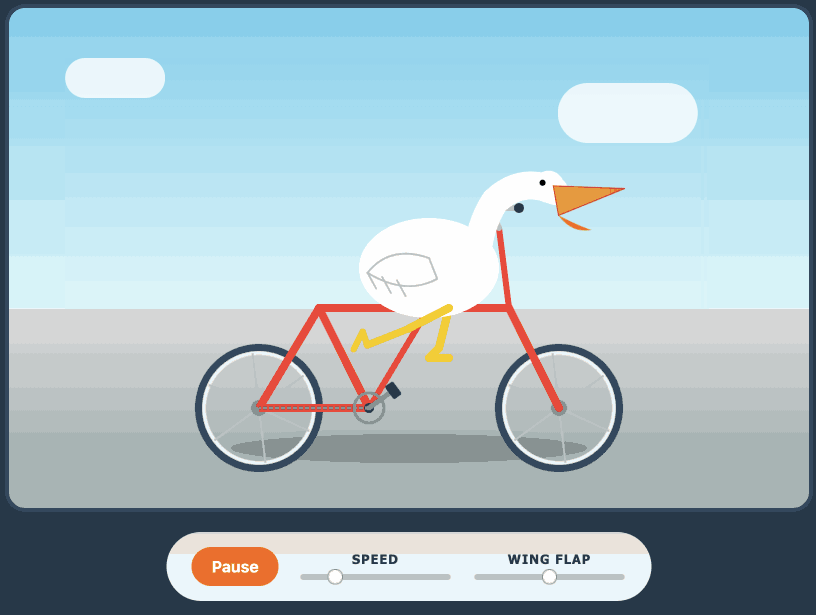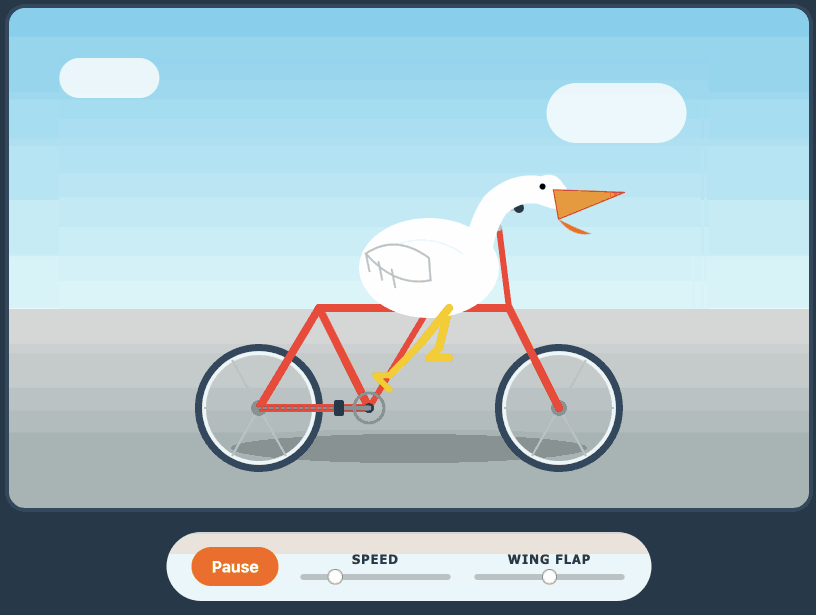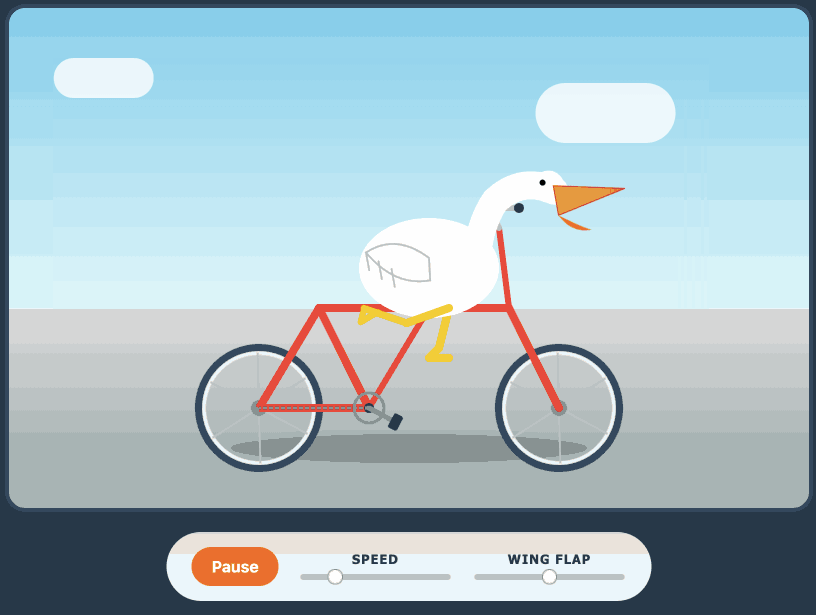
Qwen3.6-35B-A3B on my laptop drew me a better pelican than Claude Opus 4.7
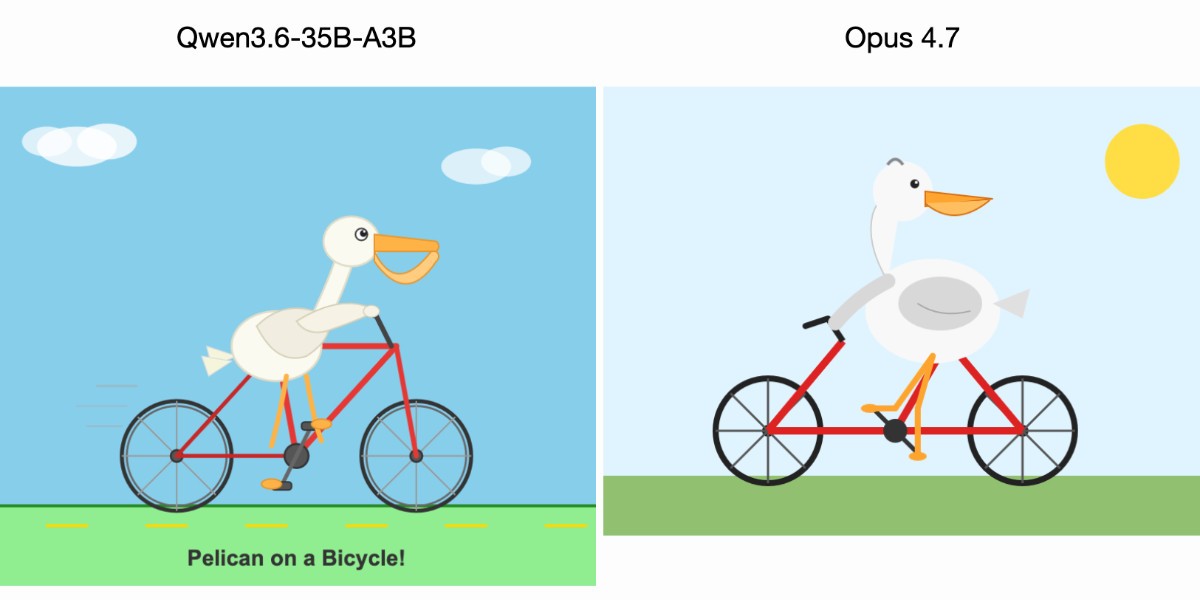
For anyone who has been (inadvisably) taking my pelican riding a bicycle benchmark seriously as a robust way to test models, here are pelicans from this morning’s two big model releases—Qwen3.6-35B-A3B from Alibaba and Claude Opus 4.7 from Anthropic.
[... 602 words]Gemini 3.1 Flash TTS. Google released Gemini 3.1 Flash TTS today, a new text-to-speech model that can be directed using prompts.
It's presented via the standard Gemini API using gemini-3.1-flash-tts-preview as the model ID, but can only output audio files.
The prompting guide is surprising, to say the least. Here's their example prompt to generate just a few short sentences of audio:
# AUDIO PROFILE: Jaz R.
## "The Morning Hype"
## THE SCENE: The London Studio
It is 10:00 PM in a glass-walled studio overlooking the moonlit London skyline, but inside, it is blindingly bright. The red "ON AIR" tally light is blazing. Jaz is standing up, not sitting, bouncing on the balls of their heels to the rhythm of a thumping backing track. Their hands fly across the faders on a massive mixing desk. It is a chaotic, caffeine-fueled cockpit designed to wake up an entire nation.
### DIRECTOR'S NOTES
Style:
* The "Vocal Smile": You must hear the grin in the audio. The soft palate is always raised to keep the tone bright, sunny, and explicitly inviting.
* Dynamics: High projection without shouting. Punchy consonants and elongated vowels on excitement words (e.g., "Beauuutiful morning").
Pace: Speaks at an energetic pace, keeping up with the fast music. Speaks with A "bouncing" cadence. High-speed delivery with fluid transitions — no dead air, no gaps.
Accent: Jaz is from Brixton, London
### SAMPLE CONTEXT
Jaz is the industry standard for Top 40 radio, high-octane event promos, or any script that requires a charismatic Estuary accent and 11/10 infectious energy.
#### TRANSCRIPT
[excitedly] Yes, massive vibes in the studio! You are locked in and it is absolutely popping off in London right now. If you're stuck on the tube, or just sat there pretending to work... stop it. Seriously, I see you.
[shouting] Turn this up! We've got the project roadmap landing in three, two... let's go!
Here's what I got using that example prompt:
Then I modified it to say "Jaz is from Newcastle" and "... requires a charismatic Newcastle accent" and got this result:
Here's Exeter, Devon for good measure:
I had Gemini 3.1 Pro vibe code this UI for trying it out:
![Screenshot of a "Gemini 3.1 Flash TTS" web application interface. At the top is an "API Key" field with a masked password. Below is a "TTS Mode" section with a dropdown set to "Multi-Speaker (Conversation)". "Speaker 1 Name" is set to "Joe" with "Speaker 1 Voice" set to "Puck (Upbeat)". "Speaker 2 Name" is set to "Jane" with "Speaker 2 Voice" set to "Kore (Firm)". Under "Script / Prompt" is a tip reading "Tip: Format your text as a script using the Exact Speaker Names defined above." The script text area contains "TTS the following conversation between Joe and Jane:\n\nJoe: How's it going today Jane?\nJane: [yawn] Not too bad, how about you?" A blue "Generate Audio" button is below. At the bottom is a "Success!" message with an audio player showing 00:00 / 00:06 and a "Download WAV" link.](https://static.simonwillison.net/static/2026/gemini-flash-tts.jpg)
Meta’s new model is Muse Spark, and meta.ai chat has some interesting tools

Meta announced Muse Spark today, their first model release since Llama 4 almost exactly a year ago. It’s hosted, not open weights, and the API is currently “a private API preview to select users”, but you can try it out today on meta.ai (Facebook or Instagram login required).
[... 2,607 words]GLM-5.1: Towards Long-Horizon Tasks. Chinese AI lab Z.ai's latest model is a giant 754B parameter 1.51TB (on Hugging Face) MIT-licensed monster - the same size as their previous GLM-5 release, and sharing the same paper.
It's available via OpenRouter so I asked it to draw me a pelican:
llm install llm-openrouter
llm -m openrouter/z-ai/glm-5.1 'Generate an SVG of a pelican on a bicycle'
And something new happened... unprompted, the model decided to give me an HTML page that included both the SVG and a separate set of CSS animations!
The SVG was excellent, and might be my new favorite from an open weights model:

But the animation broke it:

That's the pelican, floating up in the top left corner.
I usually don't do follow-up prompts for the pelican test, but in this case I made an exception:
llm -c 'the animation is a bit broken, the pelican ends up positioned off the screen at the top right'
GLM 5.1 replied:
The issue is that CSS
transformanimations on SVG elements override the SVGtransformattribute used for positioning, causing the pelican to lose its placement and fly off to the top-right. The fix is to separate positioning (SVG attribute) from animation (inner group) and use<animateTransform>for SVG rotations since it handles coordinate systems correctly.
And spat out fresh HTML which fixed the problem!

I particularly like the animation of the beak, which is described in the SVG comments like so:
<!-- Pouch (lower beak) with wobble -->
<g>
<path d="M42,-58 Q43,-50 48,-42 Q55,-35 62,-38 Q70,-42 75,-60 L42,-58 Z" fill="url(#pouchGrad)" stroke="#b06008" stroke-width="1" opacity="0.9"/>
<path d="M48,-50 Q55,-46 60,-52" fill="none" stroke="#c06a08" stroke-width="0.8" opacity="0.6"/>
<animateTransform attributeName="transform" type="scale"
values="1,1; 1.03,0.97; 1,1" dur="0.75s" repeatCount="indefinite"
additive="sum"/>
</g>Update: On Bluesky @charles.capps.me suggested a "NORTH VIRGINIA OPOSSUM ON AN E-SCOOTER" and...

The HTML+SVG comments on that one include /* Earring sparkle */, <!-- Opossum fur gradient -->, <!-- Distant treeline silhouette - Virginia pines -->, <!-- Front paw on handlebar --> - here's the transcript and the HTML result.
Anthropic’s Project Glasswing—restricting Claude Mythos to security researchers—sounds necessary to me
Anthropic didn’t release their latest model, Claude Mythos (system card PDF), today. They have instead made it available to a very restricted set of preview partners under their newly announced Project Glasswing.
[... 1,296 words]