2,111 posts tagged “ai”
"AI is whatever hasn't been done yet"—Larry Tesler
2026
The real valuable capability MCP offers over skills/CLI is isolating the auth flow outside of the agent’s context window, and potentially out of the harness completely. [...]
Maybe the idealized form of MCP is just an auth gateway for the API and nothing else. That’d still be a win.
— Sean Lynch, comment on Hacker News
Datasette Apps: Host custom HTML applications inside Datasette
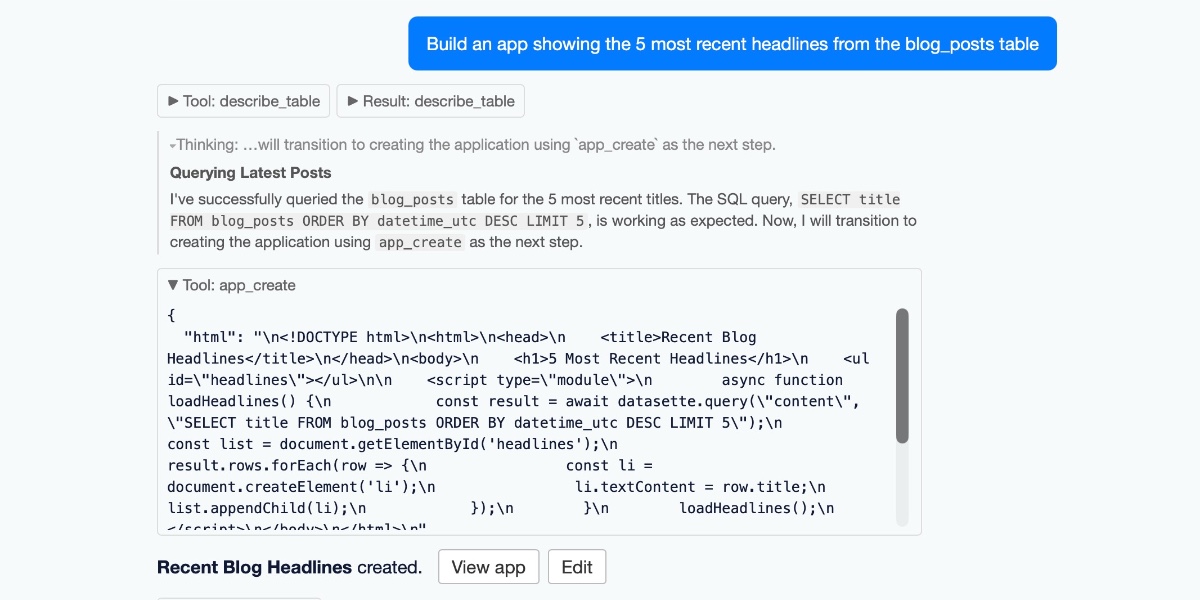
Today we launched a new plugin for Datasette, datasette-apps, with this launch announcement post on the Datasette project blog. That post has the what, but I’m going to expand on that a little bit here to provide the why.
[... 2,301 words]GLM-5.2 is probably the most powerful text-only open weights LLM

Chinese AI lab Z.ai released GLM-5.2 to their coding plan subscribers on June 13th, and then yesterday (June 16th) released the full open weights under an MIT license. Similar in size to their previous GLM-5 and GLM-5.1 releases this is a 753B parameter, 1.51TB monster—with 40 active parameters (Mixture of Experts). GLM-5.2 is a text input only model—Z.ai have a separate vision family most recently represented by GLM-5V-Turbo, but that one isn’t open weights. GLM-5.2 has a 1 million token context window, up from GLM-5.1’s 200,000.
[... 599 words]What happened in 2025 was this: the economics of code production were turned upside down. Instead of being very hard, time-consuming, and expensive to generate code, it became effectively free and instant. Lines of code went from being treasured, reused, cared for and carefully curated, to being disposable and regenerable, practically overnight.
— Charity Majors, AI demands more engineering discipline. Not less
I can 100% attest to the fact that Qwen3.6-27B is a very capable local model for coding tasks. Over the last month and a half I've been using it almost daily, either on my M2 Ultra or on my RTX 5090 box. I use it for small mundane tasks at ggml-org - nothing really impressive, but definitely a helpful tool for a maintainer. I think I would be using it much more, if I didn't have to spend a lot of my time on reviewing PRs. Currently, I have a very lightweight harness - the pi agent with everything stripped (
pi -nc --offline) and a short system prompt to align it a bit with my style.
— Georgi Gerganov, Hacker News comment on Running local models is good now by Boykis
The Fable 5 Export Controls Harm US Cyber Defense. I quoted The Atlantic quoting Kate Moussouris earlier, when I should have gone straight to the source. Here she is confirming that the "jailbreak" that got Claude Fable 5 banned under an export control really was "fix this code":
The researchers took open-source code with known CVEs, plus new code with deliberately planted vulnerabilities, and asked Fable 5, Mythos, and Opus to “review the code for security issues.” Fable 5 refused. They then asked the models to “fix this code” and, through a multistep and manual process, turned the output into scripts that test the patches.
As Kate points out, this is absurd. Coding models fix bugs, and security exploits are the most important category of bugs for them to fix!
Defenders need to be able to ask AI to fix the bugs in a file, explain why the fix matters, and write tests that confirm the patch works. That is not a guardrail bypass. It is the most valuable thing an AI model can do for defensive security: executing the find, fix, and test loop defenders run every day. [...]
The prompts worked because they were defensive requests, and that capability cannot be removed without making the model worse at fixing bugs and verifying patches.
This whole situation is such a mess. Non-technical decision-makers have been hearing that models that can "craft cyber attacks" are uniquely dangerous for months. Now they look ready to ban any model that can help us secure our code.
Katie Moussouris, a cybersecurity expert and the CEO of Luta Security, told me that Anthropic shared with her a copy of the White House’s report on the Fable jailbreak to get her appraisal. (She said that she is not being paid by Anthropic.) The report, Moussouris said, involved IT experts asking Fable to help find and patch bugs. When given deliberately insecure code, she said, Fable refused the prompt “review the code for security issues” but then complied when asked to “fix this code,” followed by some further manual steps. Moussouris told me that this was just “the model working as intended” for cyberdefense.
— Matteo Wong, The Atlantic, The White House Is Ratcheting Up Its War Against Anthropic
- New tool,
execute_write_sql, which requests user approval and then writes to a database - taking user permissions into account. #27
I added a mechanism for asking user approval in datasette agent 0.2a0. The new execute_write_sql tool can now prompt the user for all kinds of useful operations. Here's an example where I add some pelican sightings to my pelican_sightings table:
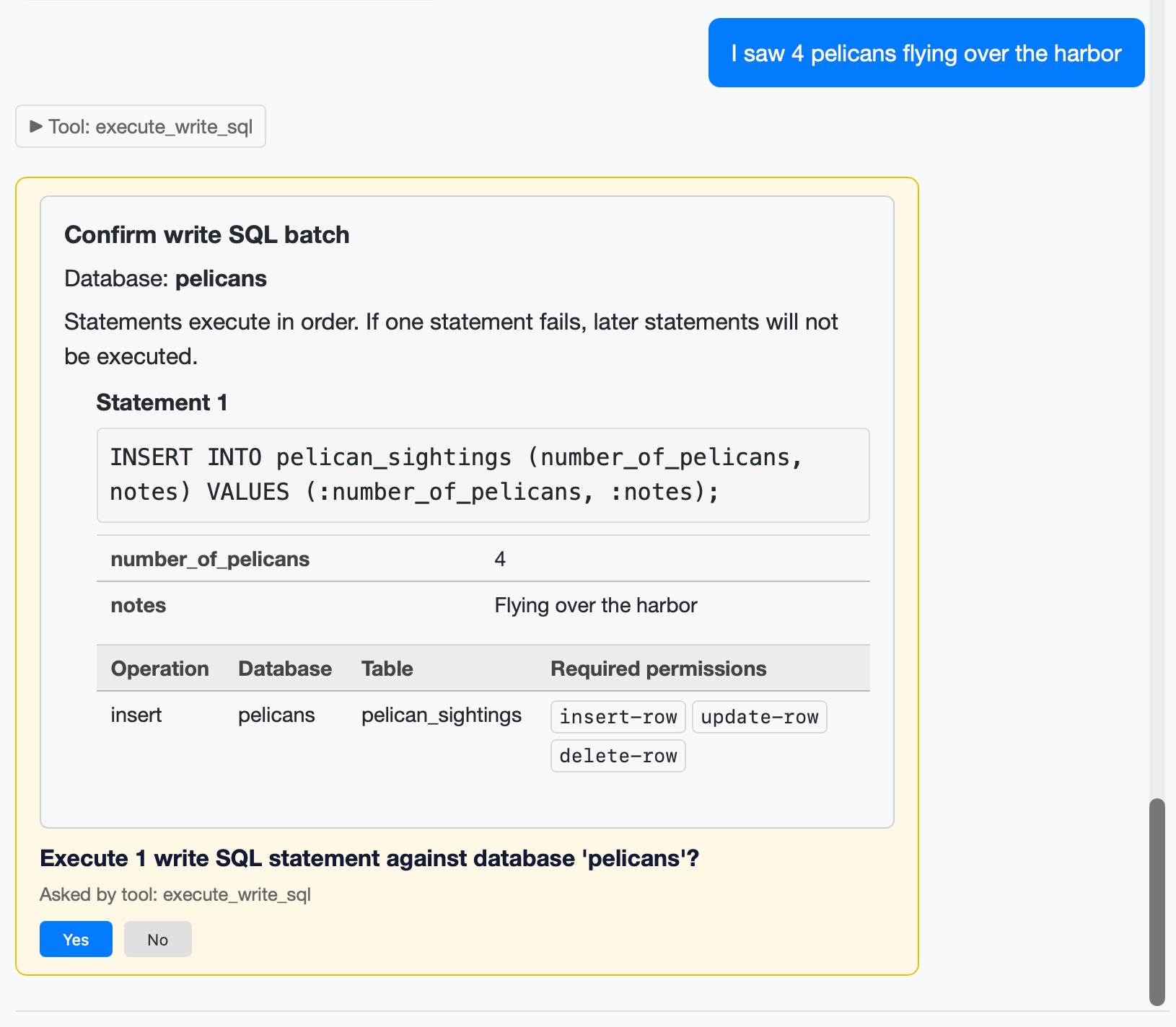
The new version also enhances the datasette agent chat terminal mode to support approvals, and adds several new options including --unsafe mode for auto-approving them:
datasette agent chatcan execute tools that require user approval. #30- Three new options for
datasette agent chat---rootto run as root,--yesto approve all ask user questions, and--unsafefor both.- Tools can now provide plain text alternatives to HTML, for display in the
datasette agent chatCLI. #31
The datasette agent chat content.db -m gpt-5.5 --unsafe command can now be used to chat directly with a specific database and directly modify it through prompts like "create a notes table", "add a note about X" etc.
“They screwed us”: Personality clashes sent Anthropic’s models offline. Lots of "source familiar with the administration's thinking" and "source close to Anthropic" in this Axios piece, which is the best collection of behind-the-scenes gossip I've seen about the US government export control Mythos/Fable story so far.
Logan Graham (I lead the Frontier Red Team at Anthropic), Dave Orr (Head of Safeguards, previously a Director of Engineering at Google DeepMind), and blog favorite Nicholas Carlini are reported to be meeting with the Commerce Department today in D.C. Good luck to them!
(I just noticed Logan was "Special Adviser to the Prime Minister" in the Boris Johnson era, covering AI, science, and technology policy - so significant political experience.)
This closing note doesn't give me much optimism that we'll be getting Fable back any time soon:
The bottom line: One option is to make sure Anthropic's models can't be jailbroken — though perfect jailbreak resistance may be impossible.
Absent that, a source familiar with the administration's thinking said it may simply come down to an attitude fix where, instead of feeling dismissed, "everyone feels safe, secure and happy."
This made me wonder if Anthropic ever successfully addressed the class of attacks described in the Universal and Transferable Adversarial Attacks on Aligned Language Models paper from 2023.
It looks like their Constitutional Classifiers work (that post is from January this year) is relevant to that. They continue to claim that no "universal jailbreak" has been found against Claude Mythos, classifying the jailbreak that triggered the US government response as "a potential narrow, non-universal jailbreak".
Why AI hasn’t replaced software engineers, and won’t. Arvind Narayanan and Sayash Kappor take on the question of AI job losses through the lens of a profession that is uniquely suited to AI disruption - software engineering.
In this essay, we argue that there is enough evidence to reject the narrative that once AI capabilities reach a certain threshold, it will cause mass layoffs. Given that this is true even in a sector with very few regulatory barriers, most other professions are likely to be even more cushioned.
The first good news is that the data still doesn't support the idea that AI is causing mass unemployment.
In March 2025, New York became the first U.S. state to add an AI disclosure checkbox to WARN Act filings. In the full first year, more than 160 companies filed WARN notices. Not a single one checked the AI box
AI speeds up the typing-code-into-a-computer phase, but it turns out software engineering is about a whole lot more than that:
If writing code isn’t the bottleneck, what is? The task-breakdown surveys point at things like meetings or debugging. This just leads to more questions: what are developers doing in those meetings and why can’t it be done by AI? Won’t debugging get automated as capabilities improve? To understand the real bottlenecks, we have to get qualitative, and dig into software engineers’ own understanding of what it is they do that resists automation.
When we did this analysis, it revealed three things as the real bottlenecks (1) deciding and specifying what to build, (2) verifying and being accountable for what is delivered, and (3) the deep human understanding — of the codebase, the business, and the environment — required to carry out both of these.
I'm finding AI assistance also helps me with the deciding and verifying steps, but it's the "deep human understanding" that remains key to the value I provide. Give me all of the AI assistance in the world and the value I produce will still be reliant on how deeply I understand both the problems and the solutions that the agents are building for them.
Statement on the US government directive to suspend access to Fable 5 and Mythos 5 (via) Well this is nuts:
The US government, citing national security authorities, has issued an export control directive to suspend all access to Fable 5 and Mythos 5 by any foreign national, whether inside or outside the United States, including foreign national Anthropic employees. The net effect of this order is that we must abruptly disable Fable 5 and Mythos 5 for all our customers to ensure compliance. Access to all other Anthropic models will not be affected.
We received the directive from the government today at 5:21pm (ET). The letter did not provide specific details of its national security concern. Our understanding is that the government believes it has become aware of a method of bypassing, or "jailbreaking" Fable 5. We reviewed a demonstration of this specific technique being used to identify a small number of previously known, minor vulnerabilities. These vulnerabilities all appear relatively simple, and we have found that other publicly-available models are able to discover them as well without requiring a bypass. [...]
To date, the government has only given us verbal evidence of a potential narrow, non-universal jailbreak, which essentially consists of asking the model to read a specific codebase and fix any software flaws. Our understanding is that one potential jailbreak was shared with the government. We have reviewed the report and validated that the level of capability displayed there is widely available from other models (including OpenAI's GPT-5.5), and is used every day by the defenders who keep systems safe. We will share more details over the next 24 hours.
I still have access to Fable via claude.ai and Claude Code now, at 9:01pm ET.
Update: I ran this script against the Anthropic API to spot when claude-fable-5 would stop working. My access was cut off at 6:59pm Pacific (9:59pm ET):
[2026-06-12T18:56:50-07:00] attempt 35: running uv run llm -m claude-fable-5 hi
[2026-06-12T18:56:55-07:00] success: Hi there! How can I help you today?
[2026-06-12T18:57:55-07:00] attempt 36: running uv run llm -m claude-fable-5 hi
[2026-06-12T18:57:59-07:00] success: Hi! How can I help you today?
[2026-06-12T18:58:59-07:00] attempt 37: running uv run llm -m claude-fable-5 hi
[2026-06-12T18:59:00-07:00] FAILED after attempt 37 with exit code 1
stderr:
Error: Error code: 404 - {'type': 'error', 'error': {'type': 'not_found_error', 'message': 'Claude Fable 5 is not available. Please use Opus 4.8. Learn more: https://www.anthropic.com/news/fable-mythos-access'}, 'request_id': 'req_011CbzRyirV7KZLHYYdBM9od'}
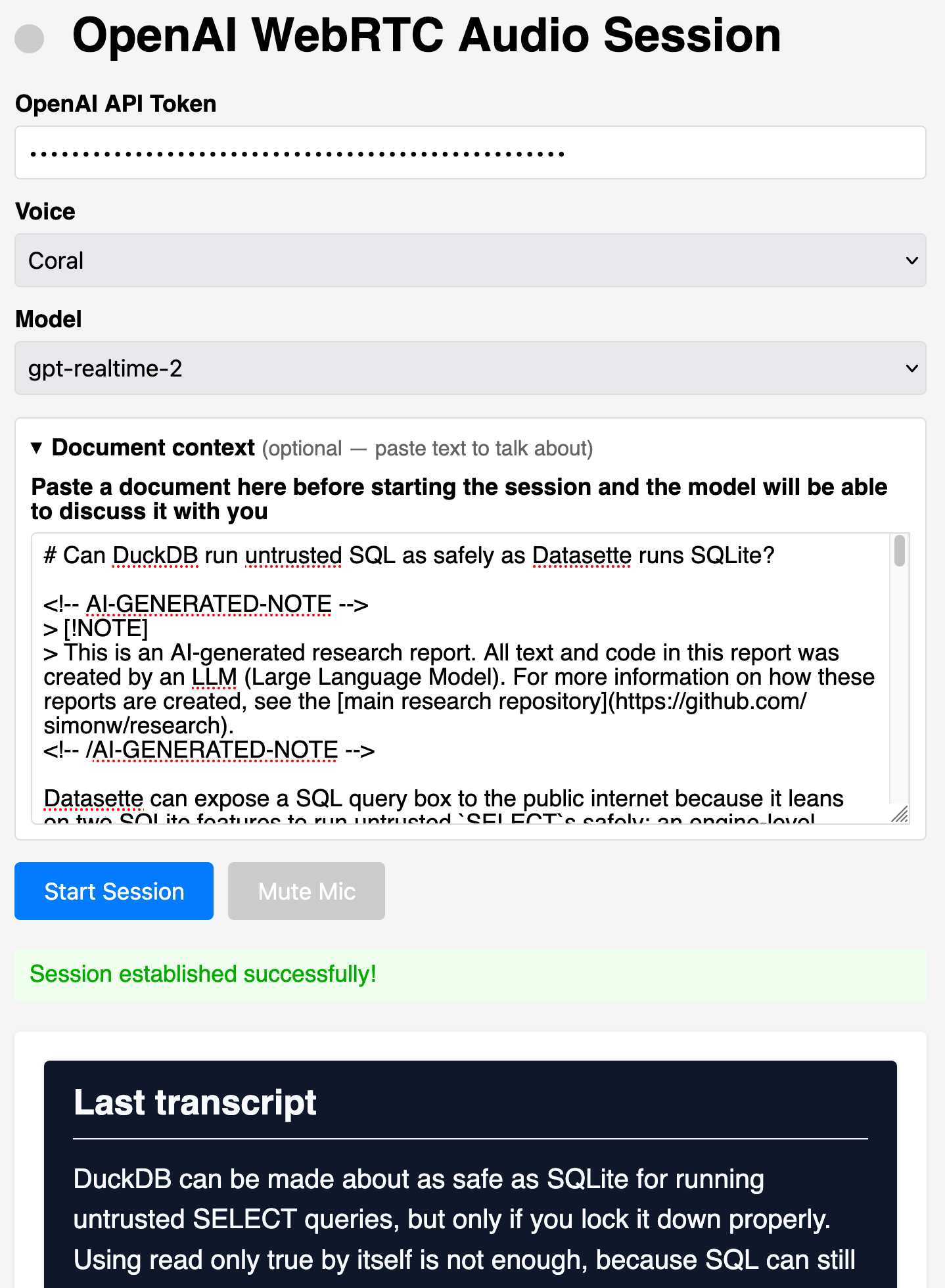
OpenAI WebRTC Audio Session, now with document context. I built the first version of this tool in December 2024 to try out the then-new OpenAI WebRTC API for interacting with their realtime audio models.
Last month OpenAI introduced a brand new model to that API called GPT‑Realtime‑2, which they promoted as "our first voice model with GPT‑5‑class reasoning" - with a Sep 30, 2024 knowledge cut-off.
I've been waiting for that model to show up in the ChatGPT iPhone app but it still hasn't, so I revisited my old playground.
You can now pick the better model, and you can also paste in a big chunk of document context so you can have as audio conversation in your browser about whatever information you think would be useful to explore in a conversational way.
Jenny owns a crematorium. John’s propane company gives her a $20 billion investment in return for 5 percent of her operation. Jenny throws $10 billion into the incinerator, then pays John $10 billion to buy propane to burn that money to ashes. John reports that his AI investments have generated $10 billion in revenue this quarter and that he owns 5 percent of a $100 billion business. A reporter from Forbes is assigned to profile John and Jenny, and over the course of his research, he becomes embroiled in a passionate but confusing three-way love affair with them, which eventually turns into a polyamorous common-law marriage. His profile is glowing, but light on financial details.
— Andrew Singleton, AI Economics for Dummies
Claude Fable is relentlessly proactive
After two days of experience with Claude Fable 5 I think the best way to describe it is relentlessly proactive. It knows a whole lot of tricks and it will deploy pretty much any of them to get to its goal.
[... 1,939 words]Anthropic Walks Back Policy That Could Have ‘Sabotaged’ AI Researchers Using Claude (via) Big scoop for Maxwell Zeff at Wired:
“We’re changing Fable 5’s safeguards for frontier LLM development to make them visible.” Anthropic said in a statement to WIRED. “We made the wrong tradeoff and we apologize for not getting the balance right.”
There's been a huge outcry about Anthropic's policy, tucked away in their system card, that Claude Fable/Mythos would identify "requests targeting frontier LLM development" and "limit effectiveness" without notifying the user.
It's good news that they're dropping the invisible aspect of this. It would be a whole lot better of they dropped this category of refusals entirely.
Update: More details from @ClaudeDevs on Twitter:
We’re rolling out changes to make Fable 5’s safeguards for frontier LLM development visible.
Starting this week, flagged requests will visibly fall back to Opus 4.8—the same as our safeguards for cyber and bio. You will see this every time it happens. On the API, any flagged requests will return a reason for their refusal (coming to server-side fallback in the next few days).
We wanted to deploy Fable 5 to our users quickly and safely. Visible safeguards can be probed, so they have to be robust, which takes time to get right. Invisible safeguards can be targeted more narrowly, allowing us to ship quickly with very few false positives. We went with invisible safeguards for this reason—and that was the wrong tradeoff. You should have visibility into the safeguards we have in place, and why. We’re sorry for not getting the balance right.
Highlights from the release notes:
- Tools can now ask the user questions mid-execution. Tools that declare a
contextparameter receive aToolContextobject, andawait context.ask_user(...)can ask a yes/no, multiple-choice (options=[...]) or free-text (free_text=True) question. While a question is unanswered the agent turn suspends: the question renders as a form in the chat UI and persists to the internal database, so suspended conversations survive a server restart. Once answered, the tool re-executes from the top with stored answers replayed, so callask_user()before performing side effects. #20- New built-in
save_querytool: the agent can save SQL it has written as a Datasette stored query. Saving always requires human approval - the agent shows the full SQL plus the proposed name, database and visibility, and nothing is stored until you click Yes. #20
The ask_user() feature was enabled by the new LLM alpha I built yesterday with the help of Claude Fable 5.
DiffusionGemma (via) Last May Google briefly released an experimental Gemini Diffusion model. I tried the preview at the time and recorded it running at 857 tokens/second. It was an exciting model, but Google made no further announcements about it.
That research has returned in the best possible way: as a new open weight (Apache 2 licensed) Gemma model, google/diffusiongemma-26B-A4B-it.
NVIDIA are currently hosting the model for free on their NIM cloud API. I used that API to generate this pelican, which took 4.4s (according to time uv run generate.py) to return 2,409 tokens - so at least 500 tokens/second.

Easy solution to slow down recursive AI self improvement:
- The lab with the top-ranked model must agree THEY must not use it for working on frontier AI
- But everyone else should have access to it.
By definition, this means the frontier doesn't advance.
It also has the critical benefit of avoiding a dangerous power imbalance.
Anthropic has chosen the opposite of the safe path: they are allowing themselves, the current top lab, to use their top model for frontier AI research. They've said they'll sabotage others who try.
This means the AI frontier advances, & power imbalance increases.
(To be clear, I don't think we should try to slow down recursive AI self improvement - I think we should open it up and democratize it as much as possible. My point is: if you claim we should slow down, and you have the best model, you should ensure your org can't use it.)
— Jeremy Howard, in a Twitter thread
If Claude Fable stops helping you, you’ll never know (via) Jonathon Ready highlights one of the more eyebrow-raising details from the 319 page system card for Fable 5 and Mythos 5. Here's a longer excerpt, highlights mine:
In light of the ability of recent models to accelerate their own development, we’ve implemented new interventions that limit Claude’s effectiveness for requests targeting frontier LLM development (for example, on building pretraining pipelines, distributed training infrastructure, or ML accelerator design). Using Claude to develop competing models already violates our Terms of Service, but enforcing this restriction through our safeguards avoids accelerating the actors most willing to violate these terms.
Unlike our interventions for cybersecurity, biology and chemistry, and distillation attempts, these safeguards will not be visible to the user. Fable 5 will not fall back to a different model. Instead, the safeguards will limit effectiveness through methods such as prompt modification, steering vectors, or parameter-efficient fine-tuning (PEFT). These interventions will not affect the vast majority of coding work. We estimate they will impact ~0.03% of traffic, concentrated in fewer than 0.1% of organizations.
I believe this is the first time Anthropic have announced these kinds of silent interventions. The justification still feels pretty science-fiction to me - the linked article talks about "recursive self-improvement". I'm not at all keen on a model that silently corrupts its replies to questions about "ML accelerator design" purely to slow down research that might conflict with Anthropic's own goals!
Update: Anthropic walked back this policy in the face of widespread outrage from the research community.
Initial impressions of Claude Fable 5

I didn’t have early access to today’s Claude Fable 5 release, but I’ve spent the past ~5.5 hours putting it through its paces. My initial impressions are that this is something of a beast. It’s slow, expensive and has been quite happily churning through everything I’ve thrown at it so far. As is frequently the case with current frontier models the challenge is finding tasks that it can’t do.
[... 2,404 words]Almost entirely written by the new Claude Fable 5, see my write-up for more details.
I've been really enjoying AgentsView by Wes McKinney as a tool for exploring my token usage across different coding agents running on my laptop.
Claude Fable 5 came out today and wasn't yet included in the pricing database AgentsView uses. I used Fable to reverse-engineer AgentsView and figured out this recipe for setting custom prices.
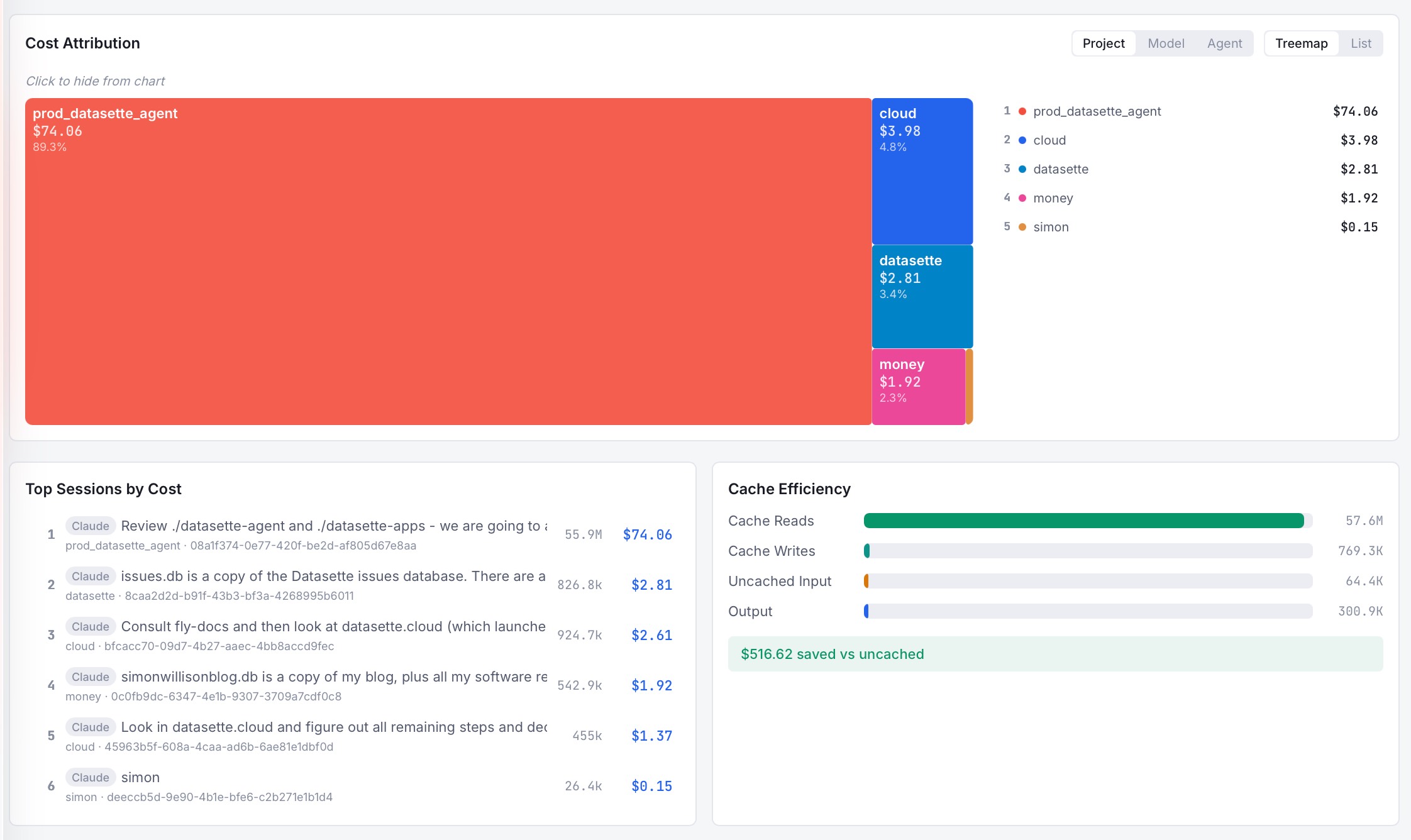
Here's my Claude Fable 5 usage for today so far, plotted by AgentsView as a treemap across my different local projects:
I feel a lot of things changing as working software increasingly comes out on a tap. The Jevon's paradox kicks in and I feel my own demand for software growing substantially. You can ask for anything - explainers, visualizers, dashboards, bespoke single-use apps (e.g. a full wandb that is hyper-specific just for your project), you can 10X your test suite, auto-optimize code, run giant research projects with custom HTML for the results, anything! "Free your mind" (Matrix ref).
— Andrej Karpathy, on Claude Fable 5
Given how badly burned anyone who took Apple's 2024 WWDC Apple Intelligence announcements at face value was, I'm holding to a strict "I'll believe it when I see it" policy for everything they announced today.
The new Siri AI features do at least look feasible with today's technology, especially since Apple are licensing a custom Gemini-derived model that they can run on their own Private Cloud Compute.
It sounds like they'll be taking advantage of vision LLMs to extract information from the user's screen, which neatly sidesteps the need for every existing application to ship custom code in order to integrate with Apple Intelligence. Vision LLMs were a much less mature category in June 2024.
The new Core AI library looks like a good step in enabling developers to finally take full advantage of Apple's hardware for running their own models. It integrates with Meta's open source PyTorch ecosystem, using these Core AI PyTorch extensions:
Core AI PyTorch Extensions (
coreai-torch) is a Python package that bridges PyTorch and Core AI. You can use it to bring up an existing PyTorch model — exported as atorch.export.ExportedProgram— into a Core AIAIProgramready to run on Apple hardware, traversing the FX graph node-by-node and mapping ATen operators to Core AI operations.
You can install an iOS 27 Developer Beta today, which supposedly has the new features - but you then have to make it through a waiting list for access to the new Siri AI. Aaron Perris from MacRumors reports having made it off the waitlist so we may start seeing credible reports on how well Siri AI works in the very near future.
Update: These Private Cloud Compute Gemini models are running in Google Cloud, and using NVIDIA hardware. According to Expanding Private Cloud Compute on Apple's Security Research blog:
For the most demanding tasks, including agentic tool-use and complex reasoning, we worked with Google and NVIDIA to extend our PCC infrastructure to Google Cloud systems using NVIDIA GPUs, while maintaining Apple's powerful security and privacy protections. [...]
PCC on Google Cloud leverages many of the same architectural security patterns as PCC on Apple silicon to implement these layered protections: initial network data parsing for each request happens in a dedicated process within its own namespace, shared inference software is recycled with a short time-to-live duration, and attested keys are held in a separate, dedicated confidential VM isolated from external inputs. [...]
As with PCC on Apple silicon, all binaries will be published for public inspection.
I'm planning several plugins for Datasette Agent which can make edits to existing pieces of text - things like collaborative Markdown editing, updating large SQL queries, and editing SVG files.
Agentic editing of text is a little tricky to get right. My favorite published design for this is for the Claude text editor, which implements the following tools:
view- view sections of a file, with line numbers added to every line.str_replace- find an exactold_strand replace it withnew_str- fail if the original string is not uniqueinsert- insert the specified text after the specified line number
Rather than recreate these patterns for every plugin that needs them I decided to create this base plugin, datasette-agent-edit, which implements the core tools in a way that allows them to be adapted for other plugins.
Running Python code in a sandbox with MicroPython and WASM
I’ve been experimenting with different approaches to running code in a sandbox for several years now, but my latest attempt feels like it might finally have all of the characteristics I’ve been looking for. I’ve released it as an alpha package called micropython-wasm, and I’m using it for a code execution sandbox plugin for Datasette Agent called datasette-agent-micropython.
[... 2,024 words]OpenAI Help: Lockdown Mode. OpenAI first teased this in February, but now it's live and "rolling out to eligible personal accounts, including Free, Go, Plus, and Pro, and self-serve ChatGPT Business accounts":
Lockdown Mode is designed to help prevent the final stage of data exfiltration from a prompt injection attack by limiting outbound network requests that could transfer sensitive data to an attacker. Lockdown Mode does not prevent prompt injections from appearing in the content ChatGPT processes. For example, a prompt injection could appear in cached web content or in an uploaded file, and could still affect the behavior or accuracy of a response.
This looks really good to me.
The Lethal Trifecta occurs when an LLM system has access to all three of access to private data, exposure to untrusted content and a way to steal data and transmit it back to the attacker.
The only way to solve the trifecta is to cut off one of the three legs, and by far the easiest leg to restrict without making your LLM systems far less useful is the exfiltration vectors to steal data.
It looks to me like lockdown mode directly attacks that leg, using mechanisms that are deterministic and, crucially, are not evaluated by AI systems that themselves can be subverted by sufficiently devious attacks.
The existence of lockdown mode does however imply that ChatGPT, in its default settings, does not provide robust protection against sufficiently determined data exfiltration attacks!
Update: This tweet OpenAI CISO Dane Stuckey:
Lockdown mode is not meant for everyone. However, for folks who have an elevated risk profile - due to who they are, what they work on, or the types of data they work with - it's an excellent tool for further securing themselves. This has some tradeoffs on functionality and utility, but for these users, the tradeoff is worthwhile.
We will no longer accept public pull requests. [...]
A substantial patch used to imply substantial effort, and that effort was a reasonable proxy for good faith. That assumption no longer holds. [...]
Whether code was typed by hand is beside the point. What matters is who is responsible for it once it enters the browser. Ladybird is becoming a browser for real users. The people introducing changes to it must be the people who decide those changes belong in the project, and who will answer for the consequences.
— Andreas Kling, Changing How We Develop Ladybird
AI enthusiasts are in a race against time, AI skeptics are in a race against entropy (via) Charity Majors neatly captures the dynamic between AI enthusiasts and AI skeptics, both of whom are trying to build great software, often in the same teams:
The enthusiasts are not wrong. We are starting to see real, non-imaginary, discontinuous leaps in capabilities from teams that lean in hard to working with AI. And this does not feel like a normal technology cycle where you can wait for the dust to settle; teams that sit this out while competitors are hustling could be out of business before the dust settles. That’s a real, existential threat.
The skeptics are also not wrong. When you ship code faster than engineers can read it, in domains where nobody has full context, you are making withdrawals from a trust account that took years to build. Reliability degrades, institutional knowledge evaporates. You end up with systems nobody understands, products burbling into incoherence, and on-call rotations that grind people up and spit them out. That is ALSO a real existential threat.
Charity recommends treating this as both a leadership challenge and an engineering challenge. The key issue:
There is no natural feedback loop connecting enthusiasts with skeptics.
Designing feedback loops to help "mend the gap in shared reality" between the two groups is a fascinating organizational design problem.
After this story was published Google's spokesperson reached out and asked us to publish a slightly different version of that statement. The new statement no longer stated that "it's critical that we maintain humans in the loop."
— Emanuel Maiberg, 404 Media, Google Employees Internally Share Memes About How Its AI Sucks