Posts tagged python, sqlite in 2024
Filters: Year: 2024 × python × sqlite × Sorted by date
Open WebUI. I tried out this open source (MIT licensed, JavaScript and Python) localhost UI for accessing LLMs today for the first time. It's very nicely done.
I ran it with uvx like this:
uvx --python 3.11 open-webui serve
On first launch it installed a bunch of dependencies and then downloaded 903MB to ~/.cache/huggingface/hub/models--sentence-transformers--all-MiniLM-L6-v2 - a copy of the all-MiniLM-L6-v2 embedding model, presumably for its RAG feature.
It then presented me with a working Llama 3.2:3b chat interface, which surprised me because I hadn't spotted it downloading that model. It turns out that was because I have Ollama running on my laptop already (with several models, including Llama 3.2:3b, already installed) - and Open WebUI automatically detected Ollama and gave me access to a list of available models.
I found a "knowledge" section and added all of the Datasette documentation (by dropping in the .rst files from the docs) - and now I can type # in chat to search for a file, add that to the context and then ask questions about it directly.
I selected the spatialite.rst.txt file, prompted it with "How do I use SpatiaLite with Datasette" and got back this:
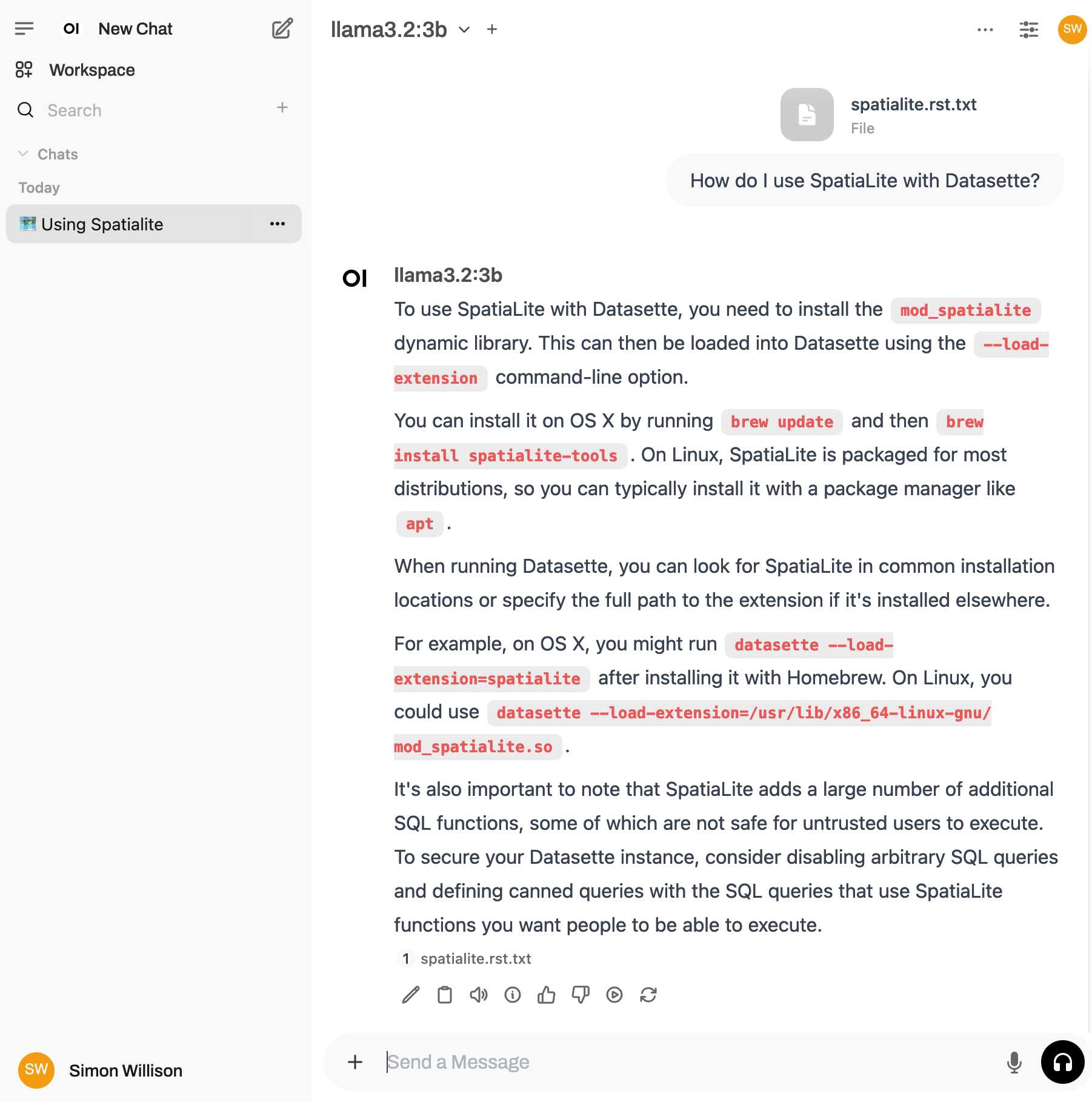
That's honestly a very solid answer, especially considering the Llama 3.2 3B model from Ollama is just a 1.9GB file! It's impressive how well that model can handle basic Q&A and summarization against text provided to it - it somehow has a 128,000 token context size.
Open WebUI has a lot of other tricks up its sleeve: it can talk to API models such as OpenAI directly, has optional integrations with web search and custom tools and logs every interaction to a SQLite database. It also comes with extensive documentation.
Introducing Limbo: A complete rewrite of SQLite in Rust (via) This looks absurdly ambitious:
Our goal is to build a reimplementation of SQLite from scratch, fully compatible at the language and file format level, with the same or higher reliability SQLite is known for, but with full memory safety and on a new, modern architecture.
The Turso team behind it have been maintaining their libSQL fork for two years now, so they're well equipped to take on a challenge of this magnitude.
SQLite is justifiably famous for its meticulous approach to testing. Limbo plans to take an entirely different approach based on "Deterministic Simulation Testing" - a modern technique pioneered by FoundationDB and now spearheaded by Antithesis, the company Turso have been working with on their previous testing projects.
Another bold claim (emphasis mine):
We have both added DST facilities to the core of the database, and partnered with Antithesis to achieve a level of reliability in the database that lives up to SQLite’s reputation.
[...] With DST, we believe we can achieve an even higher degree of robustness than SQLite, since it is easier to simulate unlikely scenarios in a simulator, test years of execution with different event orderings, and upon finding issues, reproduce them 100% reliably.
The two most interesting features that Limbo is planning to offer are first-party WASM support and fully asynchronous I/O:
SQLite itself has a synchronous interface, meaning driver authors who want asynchronous behavior need to have the extra complication of using helper threads. Because SQLite queries tend to be fast, since no network round trips are involved, a lot of those drivers just settle for a synchronous interface. [...]
Limbo is designed to be asynchronous from the ground up. It extends
sqlite3_step, the main entry point API to SQLite, to be asynchronous, allowing it to return to the caller if data is not ready to consume immediately.
Datasette provides an async API for executing SQLite queries which is backed by all manner of complex thread management - I would be very interested in a native asyncio Python library for talking to SQLite database files.
I successfully tried out Limbo's Python bindings against a demo SQLite test database using uv like this:
uv run --with pylimbo python
>>> import limbo
>>> conn = limbo.connect("/tmp/demo.db")
>>> cursor = conn.cursor()
>>> print(cursor.execute("select * from foo").fetchall())
It crashed when I tried against a more complex SQLite database that included SQLite FTS tables.
The Python bindings aren't yet documented, so I piped them through LLM and had the new google-exp-1206 model write this initial documentation for me:
files-to-prompt limbo/bindings/python -c | llm -m gemini-exp-1206 -s 'write extensive usage documentation in markdown, including realistic usage examples'
Introducing the Model Context Protocol (via) Interesting new initiative from Anthropic. The Model Context Protocol aims to provide a standard interface for LLMs to interact with other applications, allowing applications to expose tools, resources (contant that you might want to dump into your context) and parameterized prompts that can be used by the models.
Their first working version of this involves the Claude Desktop app (for macOS and Windows). You can now configure that app to run additional "servers" - processes that the app runs and then communicates with via JSON-RPC over standard input and standard output.
Each server can present a list of tools, resources and prompts to the model. The model can then make further calls to the server to request information or execute one of those tools.
(For full transparency: I got a preview of this last week, so I've had a few days to try it out.)
The best way to understand this all is to dig into the examples. There are 13 of these in the modelcontextprotocol/servers GitHub repository so far, some using the Typesscript SDK and some with the Python SDK (mcp on PyPI).
My favourite so far, unsurprisingly, is the sqlite one. This implements methods for Claude to execute read and write queries and create tables in a SQLite database file on your local computer.
This is clearly an early release: the process for enabling servers in Claude Desktop - which involves hand-editing a JSON configuration file - is pretty clunky, and currently the desktop app and running extra servers on your own machine is the only way to try this out.
The specification already describes the next step for this: an HTTP SSE protocol which will allow Claude (and any other software that implements the protocol) to communicate with external HTTP servers. Hopefully this means that MCP will come to the Claude web and mobile apps soon as well.
A couple of early preview partners have announced their MCP implementations already:
- Cody supports additional context through Anthropic's Model Context Protocol
- The Context Outside the Code is the Zed editor's announcement of their MCP extensions.
otterwiki (via) It's been a while since I've seen a new-ish Wiki implementation, and this one by Ralph Thesen is really nice. It's written in Python (Flask + SQLAlchemy + mistune for Markdown + GitPython) and keeps all of the actual wiki content as Markdown files in a local Git repository.
The installation instructions are a little in-depth as they assume a production installation with Docker or systemd - I figured out this recipe for trying it locally using uv:
git clone https://github.com/redimp/otterwiki.git
cd otterwiki
mkdir -p app-data/repository
git init app-data/repository
echo "REPOSITORY='${PWD}/app-data/repository'" >> settings.cfg
echo "SQLALCHEMY_DATABASE_URI='sqlite:///${PWD}/app-data/db.sqlite'" >> settings.cfg
echo "SECRET_KEY='$(echo $RANDOM | md5sum | head -c 16)'" >> settings.cfg
export OTTERWIKI_SETTINGS=$PWD/settings.cfg
uv run --with gunicorn gunicorn --bind 127.0.0.1:8080 otterwiki.server:app
What’s New In Python 3.13. It's Python 3.13 release day today. The big signature features are a better REPL with improved error messages, an option to run Python without the GIL and the beginnings of the new JIT. Here are some of the smaller highlights I spotted while perusing the release notes.
iOS and Android are both now Tier 3 supported platforms, thanks to the efforts of Russell Keith-Magee and the Beeware project. Tier 3 means "must have a reliable buildbot" but "failures on these platforms do not block a release". This is still a really big deal for Python as a mobile development platform.
There's a whole bunch of smaller stuff relevant to SQLite.
Python's dbm module has long provided a disk-backed key-value store against multiple different backends. 3.13 introduces a new backend based on SQLite, and makes it the default.
>>> import dbm
>>> db = dbm.open("/tmp/hi", "c")
>>> db["hi"] = 1The "c" option means "Open database for reading and writing, creating it if it doesn’t exist".
After running the above, /tmp/hi was a SQLite database containing the following data:
sqlite3 /tmp/hi .dump
PRAGMA foreign_keys=OFF;
BEGIN TRANSACTION;
CREATE TABLE Dict (
key BLOB UNIQUE NOT NULL,
value BLOB NOT NULL
);
INSERT INTO Dict VALUES(X'6869',X'31');
COMMIT;
The dbm.open() function can detect which type of storage is being referenced. I found the implementation for that in the whichdb(filename) function.
I was hopeful that this change would mean Python 3.13 deployments would be guaranteed to ship with a more recent SQLite... but it turns out 3.15.2 is from November 2016 so still quite old:
SQLite 3.15.2 or newer is required to build the
sqlite3extension module. (Contributed by Erlend Aasland in gh-105875.)
The conn.iterdump() SQLite method now accepts an optional filter= keyword argument taking a LIKE pattern for the tables that you want to dump. I found the implementation for that here.
And one last change which caught my eye because I could imagine having code that might need to be updated to reflect the new behaviour:
pathlib.Path.glob()andrglob()now return both files and directories if a pattern that ends with "**" is given, rather than directories only. Add a trailing slash to keep the previous behavior and only match directories.
With the release of Python 3.13, Python 3.8 is officially end-of-life. Łukasz Langa:
If you're still a user of Python 3.8, I don't blame you, it's a lovely version. But it's time to move on to newer, greater things. Whether it's typing generics in built-in collections, pattern matching,
except*, low-impact monitoring, or a new pink REPL, I'm sure you'll find your favorite new feature in one of the versions we still support. So upgrade today!
Python Developers Survey 2023 Results (via) The seventh annual Python survey is out. Here are the things that caught my eye or that I found surprising:
25% of survey respondents had been programming in Python for less than a year, and 33% had less than a year of professional experience.
37% of Python developers reported contributing to open-source projects last year - a new question for the survey. This is delightfully high!
6% of users are still using Python 2. The survey notes:
Almost half of Python 2 holdouts are under 21 years old and a third are students. Perhaps courses are still using Python 2?
In web frameworks, Flask and Django neck and neck at 33% each, but FastAPI is a close third at 29%! Starlette is at 6%, but that's an under-count because it's the basis for FastAPI.
The most popular library in "other framework and libraries" was BeautifulSoup with 31%, then Pillow 28%, then OpenCV-Python at 22% (wow!) and Pydantic at 22%. Tkinter had 17%. These numbers are all a surprise to me.
pytest scores 52% for unit testing, unittest from the standard library just 25%. I'm glad to see pytest so widely used, it's my favourite testing tool across any programming language.
The top cloud providers are AWS, then Google Cloud Platform, then Azure... but PythonAnywhere (11%) took fourth place just ahead of DigitalOcean (10%). And Alibaba Cloud is a new entrant in sixth place (after Heroku) with 4%. Heroku's ending of its free plan dropped them from 14% in 2021 to 7% now.
Linux and Windows equal at 55%, macOS is at 29%. This was one of many multiple-choice questions that could add up to more than 100%.
In databases, SQLite usage was trending down - 38% in 2021 to 34% for 2023, but still in second place behind PostgreSQL, stable at 43%.
The survey incorporates quotes from different Python experts responding to the numbers, it's worth reading through the whole thing.
fastlite (via) New Python library from Jeremy Howard that adds some neat utility functions and syntactic sugar to my sqlite-utils Python library, specifically for interactive use in Jupyter notebooks.
The autocomplete support through newly exposed dynamic properties is particularly neat, as is the diagram(db.tables) utility for rendering a graphviz diagram showing foreign key relationships between all of the tables.
DiskCache (via) Grant Jenks built DiskCache as an alternative caching backend for Django (also usable without Django), using a SQLite database on disk. The performance numbers are impressive—it even beats memcached in microbenchmarks, due to avoiding the need to access the network.
The source code (particularly in core.py) is a great case-study in SQLite performance optimization, after five years of iteration on making it all run as fast as possible.
wddbfs – Mount a sqlite database as a filesystem. Ingenious hack from Adam Obeng. Install this Python tool and run it against a SQLite database:
wddbfs --anonymous --db-path path/to/content.db
Then tell the macOS Finder to connect to Go -> Connect to Server -> http://127.0.0.1:8080/ (connect as guest) - connecting via WebDAV.
/Volumes/127.0.0.1/content.db will now be a folder full of CSV, TSV, JSON and JSONL files - one of each format for every table.
This means you can open data from SQLite directly in any application that supports that format, and you can even run CLI commands such as grep, ripgrep or jq directly against the data!
Adam used WebDAV because "Despite how clunky it is, this seems to be the best way to implement a filesystem given that getting FUSE support is not straightforward". What a neat trick.