Posts tagged sqlite, sql
Filters: sqlite × sql × Sorted by date
TIL: SQLite triggers. I've been doing some work with SQLite triggers recently while working on sqlite-chronicle, and I decided I needed a single reference to exactly which triggers are executed for which SQLite actions and what data is available within those triggers.
I wrote this triggers.py script to output as much information about triggers as possible, then wired it into a TIL article using Cog. The Cog-powered source code for the TIL article can be seen here.
SQLite CREATE TABLE: The DEFAULT clause. If your SQLite create table statement includes a line like this:
CREATE TABLE alerts (
-- ...
alert_created_at text default current_timestamp
)
current_timestamp will be replaced with a UTC timestamp in the format 2025-05-08 22:19:33. You can also use current_time for HH:MM:SS and current_date for YYYY-MM-DD, again using UTC.
Posting this here because I hadn't previously noticed that this defaults to UTC, which is a useful detail. It's also a strong vote in favor of YYYY-MM-DD HH:MM:SS as a string format for use with SQLite, which doesn't otherwise provide a formal datetime type.
PostgreSQL 17: SQL/JSON is here! (via) Hubert Lubaczewski dives into the new JSON features added in PostgreSQL 17, released a few weeks ago on the 26th of September. This is the latest in his long series of similar posts about new PostgreSQL features.
The features are based on the new SQL:2023 standard from June 2023. If you want to actually read the specification for SQL:2023 it looks like you have to buy a PDF from ISO for 194 Swiss Francs (currently $226). Here's a handy summary by Peter Eisentraut: SQL:2023 is finished: Here is what's new.
There's a lot of neat stuff in here. I'm particularly interested in the json_table() table-valued function, which can convert a JSON string into a table with quite a lot of flexibility. You can even specify a full table schema as part of the function call:
SELECT * FROM json_table(
'[{"a":10,"b":20},{"a":30,"b":40}]'::jsonb,
'$[*]'
COLUMNS (
id FOR ORDINALITY,
column_a int4 path '$.a',
column_b int4 path '$.b',
a int4,
b int4,
c text
)
);SQLite has solid JSON support already and often imitates PostgreSQL features, so I wonder if we'll see an update to SQLite that reflects some aspects of this new syntax.
Hybrid full-text search and vector search with SQLite. As part of Alex’s work on his sqlite-vec SQLite extension - adding fast vector lookups to SQLite - he’s been investigating hybrid search, where search results from both vector similarity and traditional full-text search are combined together.
The most promising approach looks to be Reciprocal Rank Fusion, which combines the top ranked items from both approaches. Here’s Alex’s SQL query:
-- the sqlite-vec KNN vector search results
with vec_matches as (
select
article_id,
row_number() over (order by distance) as rank_number,
distance
from vec_articles
where
headline_embedding match lembed(:query)
and k = :k
),
-- the FTS5 search results
fts_matches as (
select
rowid,
row_number() over (order by rank) as rank_number,
rank as score
from fts_articles
where headline match :query
limit :k
),
-- combine FTS5 + vector search results with RRF
final as (
select
articles.id,
articles.headline,
vec_matches.rank_number as vec_rank,
fts_matches.rank_number as fts_rank,
-- RRF algorithm
(
coalesce(1.0 / (:rrf_k + fts_matches.rank_number), 0.0) * :weight_fts +
coalesce(1.0 / (:rrf_k + vec_matches.rank_number), 0.0) * :weight_vec
) as combined_rank,
vec_matches.distance as vec_distance,
fts_matches.score as fts_score
from fts_matches
full outer join vec_matches on vec_matches.article_id = fts_matches.rowid
join articles on articles.rowid = coalesce(fts_matches.rowid, vec_matches.article_id)
order by combined_rank desc
)
select * from final;I’ve been puzzled in the past over how to best do that because the distance scores from vector similarity and the relevance scores from FTS are meaningless in comparison to each other. RRF doesn’t even attempt to compare them - it uses them purely for row_number() ranking within each set and combines the results based on that.
My goal is to keep SQLite relevant and viable through the year 2050. That's a long time from now. If I knew that standard SQL was not going to change any between now and then, I'd go ahead and make non-standard extensions that allowed for FROM-clause-first queries, as that seems like a useful extension. The problem is that standard SQL will not remain static. Probably some future version of "standard SQL" will support some kind of FROM-clause-first query format. I need to ensure that whatever SQLite supports will be compatible with the standard, whenever it drops. And the only way to do that is to support nothing until after the standard appears.
When will that happen? A month? A year? Ten years? Who knows.
I'll probably take my cue from PostgreSQL. If PostgreSQL adds support for FROM-clause-first queries, then I'll do the same with SQLite, copying the PostgreSQL syntax. Until then, I'm afraid you are stuck with only traditional SELECT-first queries in SQLite.
Optimizing Datasette (and other weeknotes)
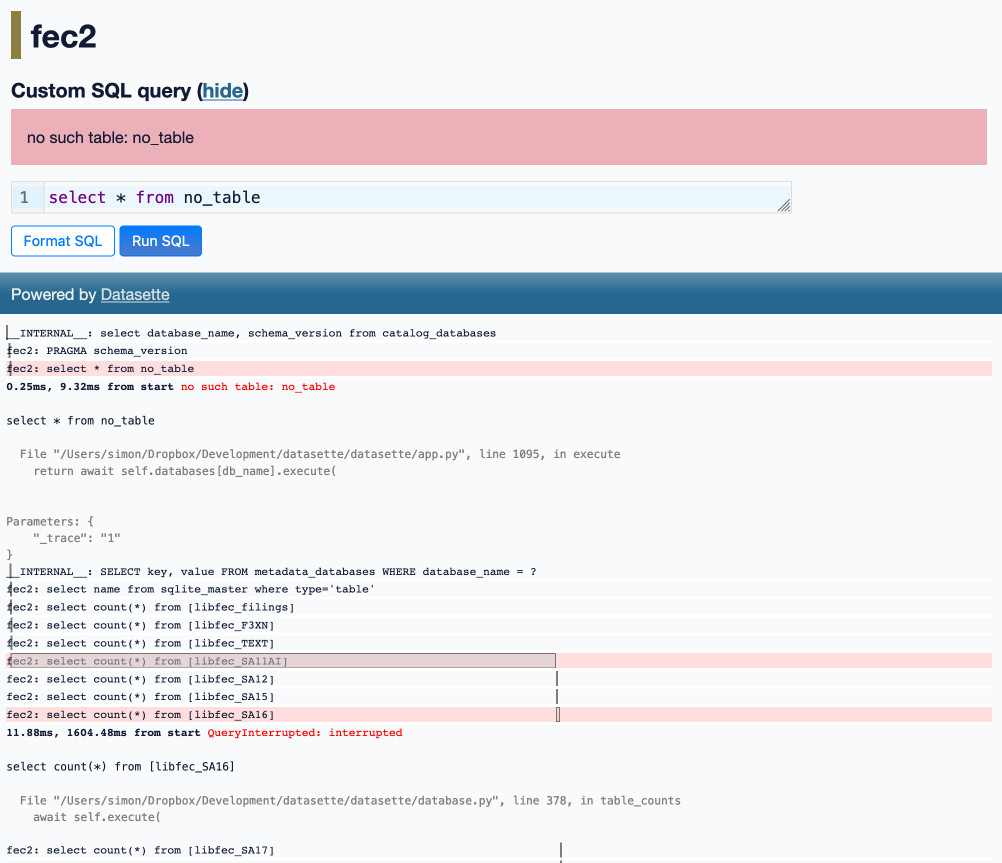
I’ve been working with Alex Garcia on an experiment involving using Datasette to explore FEC contributions. We currently have a 11GB SQLite database—trivial for SQLite to handle, but at the upper end of what I’ve comfortably explored with Datasette in the past.
[... 2,069 words]How to Get or Create in PostgreSQL (via) Get or create - for example to retrieve an existing tag record from a database table if it already exists or insert it if it doesn’t - is a surprisingly difficult operation.
Haki Benita uses it to illustrate a variety of interesting PostgreSQL concepts.
New to me: a pattern that runs INSERT INTO tags (name) VALUES (tag_name) RETURNING *; and then catches the constraint violation and returns a record instead has a disadvantage at scale: “The table contains a dead tuple for every attempt to insert a tag that already existed” - so until vacuum runs you can end up with significant table bloat!
Haki’s conclusion is that the best solution relies on an upcoming feature coming in PostgreSQL 17: the ability to combine the MERGE operation with a RETURNING clause:
WITH new_tags AS (
MERGE INTO tags
USING (VALUES ('B'), ('C')) AS t(name)
ON tags.name = t.name
WHEN NOT MATCHED THEN
INSERT (name) VALUES (t.name)
RETURNING *
)
SELECT * FROM tags WHERE name IN ('B', 'C')
UNION ALL
SELECT * FROM new_tags;
I wonder what the best pattern for this in SQLite is. Could it be as simple as this?
INSERT OR IGNORE INTO tags (name) VALUES ('B'), ('C');
The SQLite INSERT documentation doesn't currently provide extensive details for INSERT OR IGNORE, but there are some hints in this forum thread. This post by Rob Hoelz points out that INSERT OR IGNORE will silently ignore any constraint violation, so INSERT INTO tags (tag) VALUES ('C'), ('D') ON CONFLICT(tag) DO NOTHING may be a better option.
Why SQLite Uses Bytecode (via) Brand new SQLite architecture documentation by D. Richard Hipp explaining the trade-offs between a bytecode based query plan and a tree of objects.
SQLite uses the bytecode approach, which provides an important characteristic that SQLite can very easily execute queries incrementally—stopping after each row, for example. This is more useful for a local library database than for a network server where the assumption is that the entire query will be executed before results are returned over the wire.
Optimizing SQLite for servers (via) Sylvain Kerkour's comprehensive set of lessons learned running SQLite for server-based applications.
There's a lot of useful stuff in here, including detailed coverage of the different recommended PRAGMA settings.
There was also a tip I haven't seen before about BEGIN IMMEDIATE transactions:
By default, SQLite starts transactions in
DEFERREDmode: they are considered read only. They are upgraded to a write transaction that requires a database lock in-flight, when query containing a write/update/delete statement is issued.The problem is that by upgrading a transaction after it has started, SQLite will immediately return a
SQLITE_BUSYerror without respecting thebusy_timeoutpreviously mentioned, if the database is already locked by another connection.This is why you should start your transactions with
BEGIN IMMEDIATEinstead of onlyBEGIN. If the database is locked when the transaction starts, SQLite will respectbusy_timeout.
Announcing DuckDB 0.10.0.
Somewhat buried in this announcement: DuckDB has Fixed-Length Arrays now, along with array_cross_product(a1, a2), array_cosine_similarity(a1, a2) and array_inner_product(a1, a2) functions.
This means you can now use DuckDB to find related content (and other tricks) using vector embeddings!
Also notable:
DuckDB can now attach MySQL, Postgres, and SQLite databases in addition to databases stored in its own format. This allows data to be read into DuckDB and moved between these systems in a convenient manner, as attached databases are fully functional, appear just as regular tables, and can be updated in a safe, transactional manner.
SQL for Data Scientists in 100 Queries. New comprehensive SQLite SQL tutorial from Greg Wilson, author of Teaching Tech Together and founder of The Carpentries.
Upsert in SQL (via) Anton Zhiyanov is currently on a one-man quest to write detailed documentation for all of the fundamental SQL operations, comparing and contrasting how they work across multiple engines, generally with interactive examples.
Useful tips in here on why “insert... on conflict” is usually a better option than “insert or replace into” because the latter can perform a delete and then an insert, firing triggers that you may not have wanted to be fired.
Online gradient descent written in SQL (via) Max Halford trains an online gradient descent model against two years of AAPL stock data using just a single advanced SQL query. He built this against DuckDB—I tried to replicate his query in SQLite and it almost worked, but it gave me a “recursive reference in a subquery” error that I was unable to resolve.
[SQLite is] a database that in full-stack culture has been relegated to "unit test database mock" for about 15 years that is (1) surprisingly capable as a SQL engine, (2) the simplest SQL database to get your head around and manage, and (3) can embed directly in literally every application stack, which is especially interesting in latency-sensitive and globally-distributed applications.
Reason (3) is clearly our ulterior motive here, so we're not disinterested: our model user deploys a full-stack app (Rails, Elixir, Express, whatever) in a bunch of regions around the world, hoping for sub-100ms responses for users in most places around the world. Even within a single data center, repeated queries to SQL servers can blow that budget. Running an in-process SQL server neatly addresses it.
Datasette on Codespaces, sqlite-utils API reference documentation and other weeknotes
This week I broke my streak of not sending out the Datasette newsletter, figured out how to use Sphinx for Python class documentation, worked out how to run Datasette on GitHub Codespaces, implemented Datasette column metadata and got tantalizingly close to a solution for an elusive Datasette feature.
[... 2,164 words]Bare columns in an aggregate queries. This is a really nice SQL tweak implemented in SQLite: If you run a query like “SELECT a, b, max(c) FROM tab1 GROUP BY a” SQLite will find the row with the highest value for c and use the columns of that row as the returned values for the other columns mentioned in the query.
Joining CSV and JSON data with an in-memory SQLite database
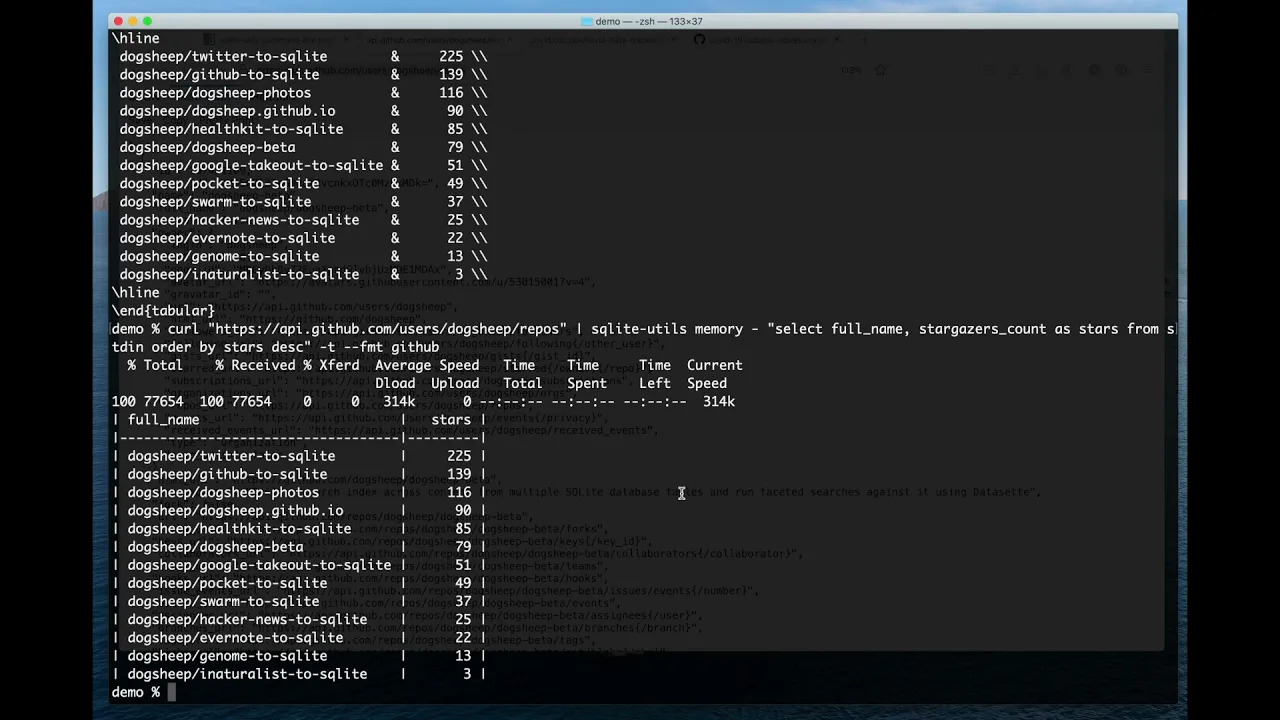
The new sqlite-utils memory command can import CSV and JSON data directly into an in-memory SQLite database, combine and query it using SQL and output the results as CSV, JSON or various other formats of plain text tables.
Using SQL to Look Through All of Your iMessage Text Messages (via) Dan Kelch shows how to access the iMessage SQLite database at ~/Library/Messages/chat.db—it’s protected under macOS Catalina so you have to enable Full Disk Access in the privacy settings first. I usually use the macOS terminal app but I installed iTerm for this because I’d rather enable full disk access to a separate terminal program than let anything I’m running in my regular terminal take advantage of it. It worked! Now I can run “datasette ~/Library/Messages/chat.db” to browse my messages.
Using SQL to find my best photo of a pelican according to Apple Photos

According to the Apple Photos internal SQLite database, this is the most aesthetically pleasing photograph I have ever taken of a pelican:
[... 1,937 words]Generated Columns in SQLite (via) SQLite 3.31.0 released today, and generated columns are the single most notable new feature. PostgreSQL 12 added these in October 2019, and MySQL has had them since 5.7 in October 2015. MySQL and SQLite both offer either “stored” or “virtual” generated columns, with virtual columns being calculated at runtime. PostgreSQL currently only supports stored columns.
sqlite-utils 2.0: real upserts
I just released version 2.0 of my sqlite-utils library/CLI tool to PyPI.
[... 1,140 words]athena-sqlite (via) Amazon Athena is the AWS tool for querying data stored in S3—as CSV, JSON or Apache Parquet files—using SQL. It’s an interesting way of buliding a very cheap data warehouse on top of S3 without having to run any additional services. Athena recently added a query federation SDK which lets you define additional custom data sources using Lambda functions. Damon Cortesi used this to write a custom connector for SQLite, which lets you run queries against data stored in SQLite files that you have uploaded to S3. You can then run joins between that data and other Athena sources.
SQL Murder Mystery in Datasette (via) “A crime has taken place and the detective needs your help. The detective gave you the crime scene report, but you somehow lost it. You vaguely remember that the crime was a murder that occurred sometime on Jan.15, 2018 and that it took place in SQL City. Start by retrieving the corresponding crime scene report from the police department’s database.”—Really fun game to help exercise your skills with SQL by the NU Knight Lab. I loaded their SQLite database into Datasette so you can play in your browser.
SQLite Query Language: WITH clause. SQLite’s documentation on recursive CTEs starts out with some nice clear examples of tree traversal using a WITH statement, then gets into graphs, then goes way off the deep end with a Mandelbrot Set query and a query that can solve Soduku puzzles (“in less than 300 milliseconds on a modern workstation”).