Posts tagged chatgpt, claude
Filters: chatgpt × claude × Sorted by date
Using LLMs as the first line of support in Open Source (via) From reading the title I was nervous that this might involve automating the initial response to a user support query in an issue tracker with an LLM, but Carlton Gibson has better taste than that.
The open contribution model engendered by GitHub — where anonymous (to the project) users can create issues, and comments, which are almost always extractive support requests — results in an effective denial-of-service attack against maintainers. [...]
For anonymous users, who really just want help almost all the time, the pattern I’m settling on is to facilitate them getting their answer from their LLM of choice. [...] we can generate a file that we offer users to download, then we tell the user to pass this to (say) Claude with a simple prompt for their question.
This resonates with the concept proposed by llms.txt - making LLM-friendly context files available for different projects.
My simonw/docs-for-llms contains my own early experiment with this: I'm running a build script to create LLM-friendly concatenated documentation for several of my projects, and my llm-docs plugin (described here) can then be used to ask questions of that documentation.
It's possible to pre-populate the Claude UI with a prompt by linking to https://claude.ai/new?q={PLACE_HOLDER}, but it looks like there's quite a short length limit on how much text can be passed that way. It would be neat if you could pass a URL to a larger document instead.
ChatGPT also supports https://chatgpt.com/?q=your-prompt-here (again with a short length limit) and directly executes the prompt rather than waiting for you to edit it first(!)
Incomplete JSON Pretty Printer. Every now and then a log file or a tool I'm using will spit out a bunch of JSON that terminates unexpectedly, meaning I can't copy it into a text editor and pretty-print it to see what's going on.
The other day I got frustrated with this and had the then-new GPT-4.5 build me a pretty-printer that didn't mind incomplete JSON, using an OpenAI Canvas. Here's the chat and here's the resulting interactive.
I spotted a bug with the way it indented code today so I pasted it into Claude 3.7 Sonnet Thinking mode and had it make a bunch of improvements - full transcript here. Here's the finished code.
In many ways this is a perfect example of vibe coding in action. At no point did I look at a single line of code that either of the LLMs had written for me. I honestly don't care how this thing works: it could not be lower stakes for me, the worst a bug could do is show me poorly formatted incomplete JSON.
I was vaguely aware that some kind of state machine style parser would be needed, because you can't parse incomplete JSON with a regular JSON parser. Building simple parsers is the kind of thing LLMs are surprisingly good at, and also the kind of thing I don't want to take on for a trivial project.
At one point I told Claude "Try using your code execution tool to check your logic", because I happen to know Claude can write and then execute JavaScript independently of using it for artifacts. That helped it out a bunch.
I later dropped in the following:
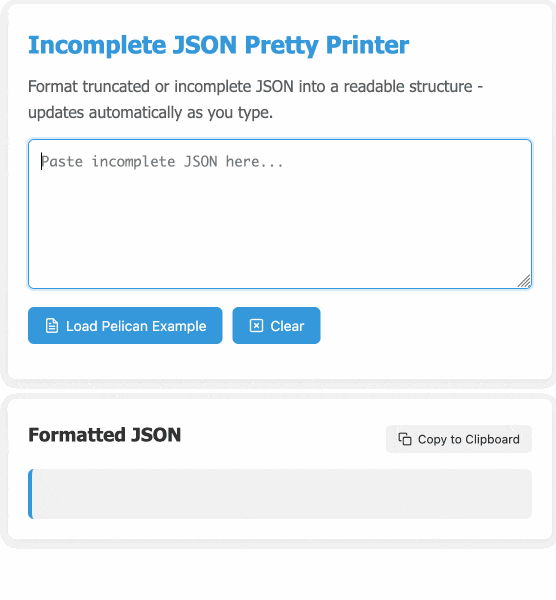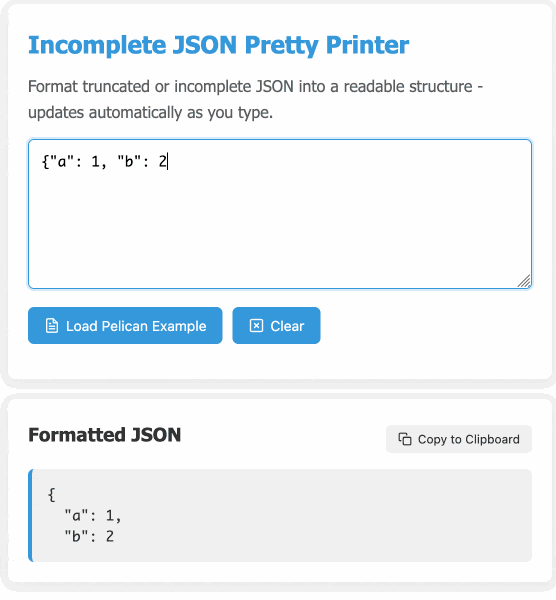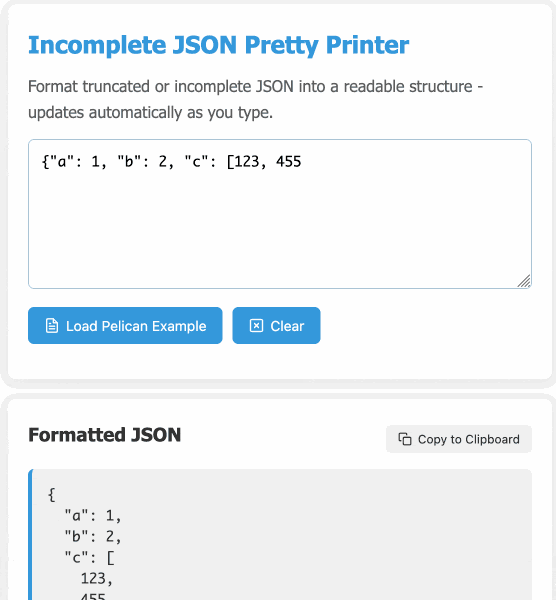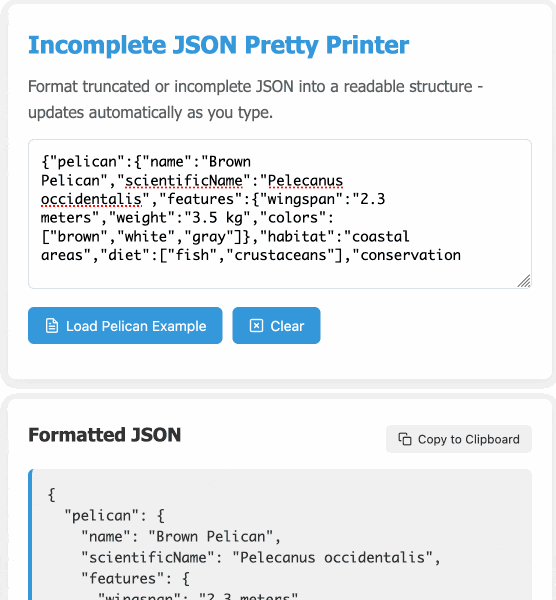
modify the tool to work better on mobile screens and generally look a bit nicer - and remove the pretty print JSON button, it should update any time the input text is changed. Also add a "copy to clipboard" button next to the results. And add a button that says "example" which adds a longer incomplete example to demonstrate the tool, make that example pelican themed.
It's fun being able to say "generally look a bit nicer" and get a perfectly acceptable result!
Using S3 triggers to maintain a list of files in DynamoDB. I built an experimental prototype this morning of a system for efficiently tracking files that have been added to a large S3 bucket by maintaining a parallel DynamoDB table using S3 triggers and AWS lambda.
I got 80% of the way there with this single prompt (complete with typos) to my custom Claude Project:
Python CLI app using boto3 with commands for creating a new S3 bucket which it also configures to have S3 lambada event triggers which moantian a dynamodb table containing metadata about all of the files in that bucket. Include these commands
create_bucket - create a bucket and sets up the associated triggers and dynamo tableslist_files - shows me a list of files based purely on querying dynamo
ChatGPT then took me to the 95% point. The code Claude produced included an obvious bug, so I pasted the code into o3-mini-high on the basis that "reasoning" is often a great way to fix those kinds of errors:
Identify, explain and then fix any bugs in this code:code from Claude pasted here
... and aside from adding a couple of time.sleep() calls to work around timing errors with IAM policy distribution, everything worked!
Getting from a rough idea to a working proof of concept of something like this with less than 15 minutes of prompting is extraordinarily valuable.
This is exactly the kind of project I've avoided in the past because of my almost irrational intolerance of the frustration involved in figuring out the individual details of each call to S3, IAM, AWS Lambda and DynamoDB.
(Update: I just found out about the new S3 Metadata system which launched a few weeks ago and might solve this exact problem!)
Building an automatically updating live blog in Django. Here's an extended write-up of how I implemented the live blog feature I used for my coverage of OpenAI DevDay yesterday. I built the first version using Claude while waiting for the keynote to start, then upgraded it during the lunch break with the help of GPT-4o to add sort options and incremental fetching of new updates.
Notes on using LLMs for code

I was recently the guest on TWIML—the This Week in Machine Learning & AI podcast. Our episode is titled Supercharging Developer Productivity with ChatGPT and Claude with Simon Willison, and the focus of the conversation was the ways in which I use LLM tools in my day-to-day work as a software developer and product engineer.
[... 861 words]Supercharging Developer Productivity with ChatGPT and Claude with Simon Willison (via) I'm the guest for the latest episode of the TWIML AI podcast - This Week in Machine Learning & AI, hosted by Sam Charrington.
We mainly talked about how I use LLM tooling for my own work - Claude, ChatGPT, Code Interpreter, Claude Artifacts, LLM and GitHub Copilot - plus a bit about my experiments with local models.
Give people something to link to so they can talk about your features and ideas
If you have a project, an idea, a product feature, or anything else that you want other people to understand and have conversations about... give them something to link to!
[... 685 words]hangout_services/thunk.js
(via)
It turns out Google Chrome (via Chromium) includes a default extension which makes extra services available to code running on the *.google.com domains - tweeted about today by Luca Casonato, but the code has been there in the public repo since October 2013 as far as I can tell.
It looks like it's a way to let Google Hangouts (or presumably its modern predecessors) get additional information from the browser, including the current load on the user's CPU. Update: On Hacker News a Googler confirms that the Google Meet "troubleshooting" feature uses this to review CPU utilization.
I got GPT-4o to help me figure out how to trigger it (I tried Claude 3.5 Sonnet first but it refused, saying "Doing so could potentially violate terms of service or raise security and privacy concerns"). Paste the following into your Chrome DevTools console on any Google site to see the result:
chrome.runtime.sendMessage(
"nkeimhogjdpnpccoofpliimaahmaaome",
{ method: "cpu.getInfo" },
(response) => {
console.log(JSON.stringify(response, null, 2));
},
);
I get back a response that starts like this:
{
"value": {
"archName": "arm64",
"features": [],
"modelName": "Apple M2 Max",
"numOfProcessors": 12,
"processors": [
{
"usage": {
"idle": 26890137,
"kernel": 5271531,
"total": 42525857,
"user": 10364189
}
}, ...
The code doesn't do anything on non-Google domains.
Luca says this - I'm inclined to agree:
This is interesting because it is a clear violation of the idea that browser vendors should not give preference to their websites over anyone elses.
Claude Projects. New Claude feature, quietly launched this morning for Claude Pro users. Looks like their version of OpenAI's GPTs, designed to take advantage of Claude's 200,000 token context limit:
You can upload relevant documents, text, code, or other files to a project’s knowledge base, which Claude will use to better understand the context and background for your individual chats within that project. Each project includes a 200K context window, the equivalent of a 500-page book, so users can add all of the insights needed to enhance Claude’s effectiveness.
You can also set custom instructions, which presumably get added to the system prompt.
I tried dropping in all of Datasette's existing documentation - 693KB of .rst files (which I had to rename to .rst.txt for it to let me upload them) - and it worked and showed "63% of knowledge size used".
This is a slightly different approach from OpenAI, where the GPT knowledge feature supports attaching up to 20 files each with up to 2 million tokens, which get ingested into a vector database (likely Qdrant) and used for RAG.
It looks like Claude instead handle a smaller amount of extra knowledge but paste the whole thing into the context window, which avoids some of the weirdness around semantic search chunking but greatly limits the size of the data.
My big frustration with the knowledge feature in GPTs remains the lack of documentation on what it's actually doing under the hood. Without that it's difficult to make informed decisions about how to use it - with Claude Projects I can at least develop a robust understanding of what the tool is doing for me and how best to put it to work.
No equivalent (yet) for the GPT actions feature where you can grant GPTs the ability to make API calls out to external systems.
Claude and ChatGPT for ad-hoc sidequests
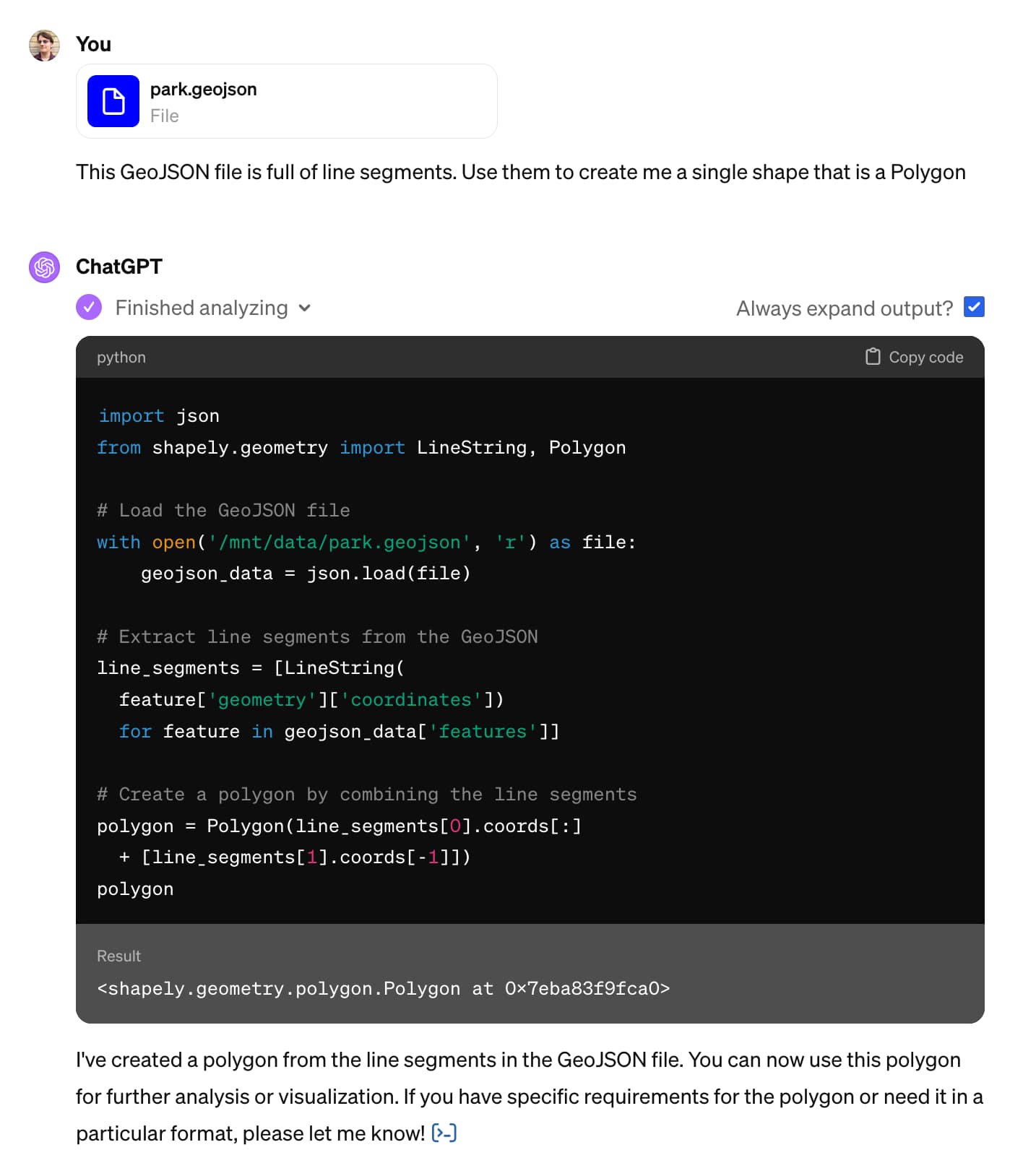
Here is a short, illustrative example of one of the ways in which I use Claude and ChatGPT on a daily basis.
[... 1,754 words]Catching up on the weird world of LLMs

I gave a talk on Sunday at North Bay Python where I attempted to summarize the last few years of development in the space of LLMs—Large Language Models, the technology behind tools like ChatGPT, Google Bard and Llama 2.
[... 10,489 words]It’s infuriatingly hard to understand how closed models train on their input
One of the most common concerns I see about large language models regards their training data. People are worried that anything they say to ChatGPT could be memorized by it and spat out to other users. People are concerned that anything they store in a private repository on GitHub might be used as training data for future versions of Copilot.
[... 1,465 words]ChatGPT should include inline tips
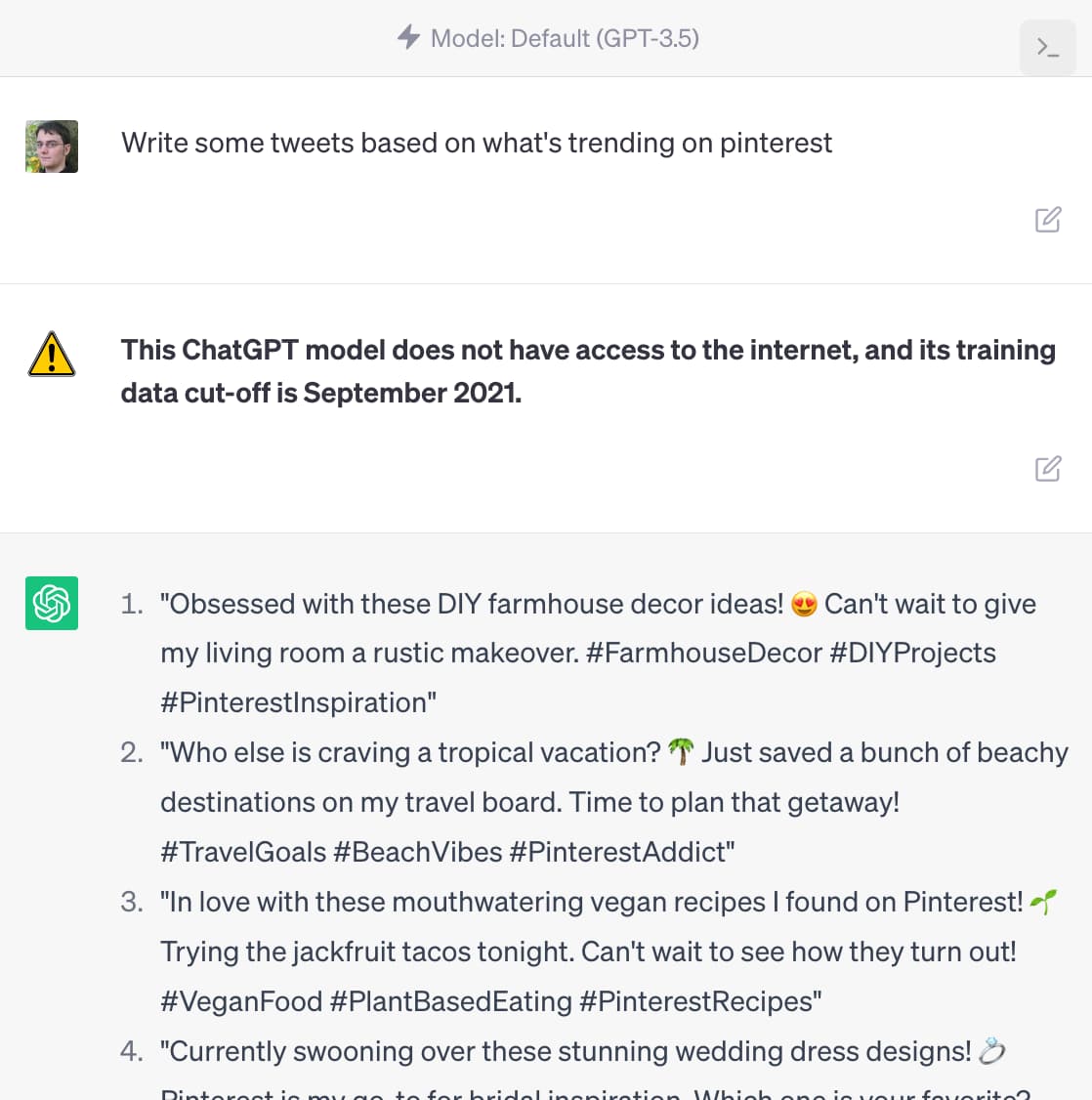
In OpenAI isn’t doing enough to make ChatGPT’s limitations clear James Vincent argues that OpenAI’s existing warnings about ChatGPT’s confounding ability to convincingly make stuff up are not effective.
[... 1,488 words]How to use AI to do practical stuff: A new guide (via) Ethan Mollick’s guide to practical usage of large language model chatbot like ChatGPT 3.5 and 4, Bing, Claude and Bard is the best I’ve seen so far. He includes useful warnings about common traps and things that these models are both useful for and useless at.