Posts tagged postgresql in Jul
Filters: Month: Jul × postgresql × Sorted by date
Announcing PlanetScale for Postgres. PlanetScale formed in 2018 to build a commercial offering on top of the Vitess MySQL sharding open source project, which was originally released by YouTube in 2012. The PlanetScale founders were the co-creators and maintainers of Vitess.
Today PlanetScale are announcing a private preview of their new horizontally sharded PostgreSQL solution, due to "overwhelming" demand.
Notably, it doesn't use Vitess under the hood:
Vitess is one of PlanetScale’s greatest strengths [...] We have made explicit sharding accessible to hundreds of thousands of users and it is time to bring this power to Postgres. We will not however be using Vitess to do this.
Vitess’ achievements are enabled by leveraging MySQL’s strengths and engineering around its weaknesses. To achieve Vitess’ power for Postgres we are architecting from first principles.
Meanwhile, on June 10th Supabase announced that they had hired Vitess co-creator Sugu Sougoumarane to help them build "Multigres: Vitess for Postgres". Sugu said:
For some time, I've been considering a Vitess adaptation for Postgres, and this feeling had been gradually intensifying. The recent explosion in the popularity of Postgres has fueled this into a full-blown obsession. [...]
The project to address this problem must begin now, and I'm convinced that Vitess provides the most promising foundation.
I remember when MySQL was an order of magnitude more popular than PostgreSQL, and Heroku's decision to only offer PostgreSQL back in 2007 was a surprising move. The vibes have certainly shifted.
Build your own SQS or Kafka with Postgres (via) Anthony Accomazzo works on Sequin, an open source "message stream" (similar to Kafka) written in Elixir and Go on top of PostgreSQL.
This detailed article describes how you can implement message queue patterns on PostgreSQL from scratch, including this neat example using a CTE, returning and for update skip locked to retrieve $1 messages from the messages table and simultaneously mark them with not_visible_until set to $2 in order to "lock" them for processing by a client:
with available_messages as (
select seq
from messages
where not_visible_until is null
or (not_visible_until <= now())
order by inserted_at
limit $1
for update skip locked
)
update messages m
set
not_visible_until = $2,
deliver_count = deliver_count + 1,
last_delivered_at = now(),
updated_at = now()
from available_messages am
where m.seq = am.seq
returning m.seq, m.data;
The economics of a Postgres free tier (via) Xata offer a hosted PostgreSQL service with a generous free tier (15GB of volume). I'm very suspicious of free tiers that don't include a detailed breakdown of the unit economics... and in this post they've described exactly that, in great detail.
The trick is that they run their free tier on shared clusters - with each $630/month cluster supporting 2,000 free instances for $0.315 per instance per month. Then inactive databases get downgraded to even cheaper auto-scaling clusters that can host 20,000 databases for $180/month (less than 1c each).
They also cover the volume cost of $0.10/GB/month - so up to $1.50/month per free instance, but most instances only use a small portion of that space.
It's reassuring to see this spelled out in so much detail.
Django SQL Dashboard 1.0
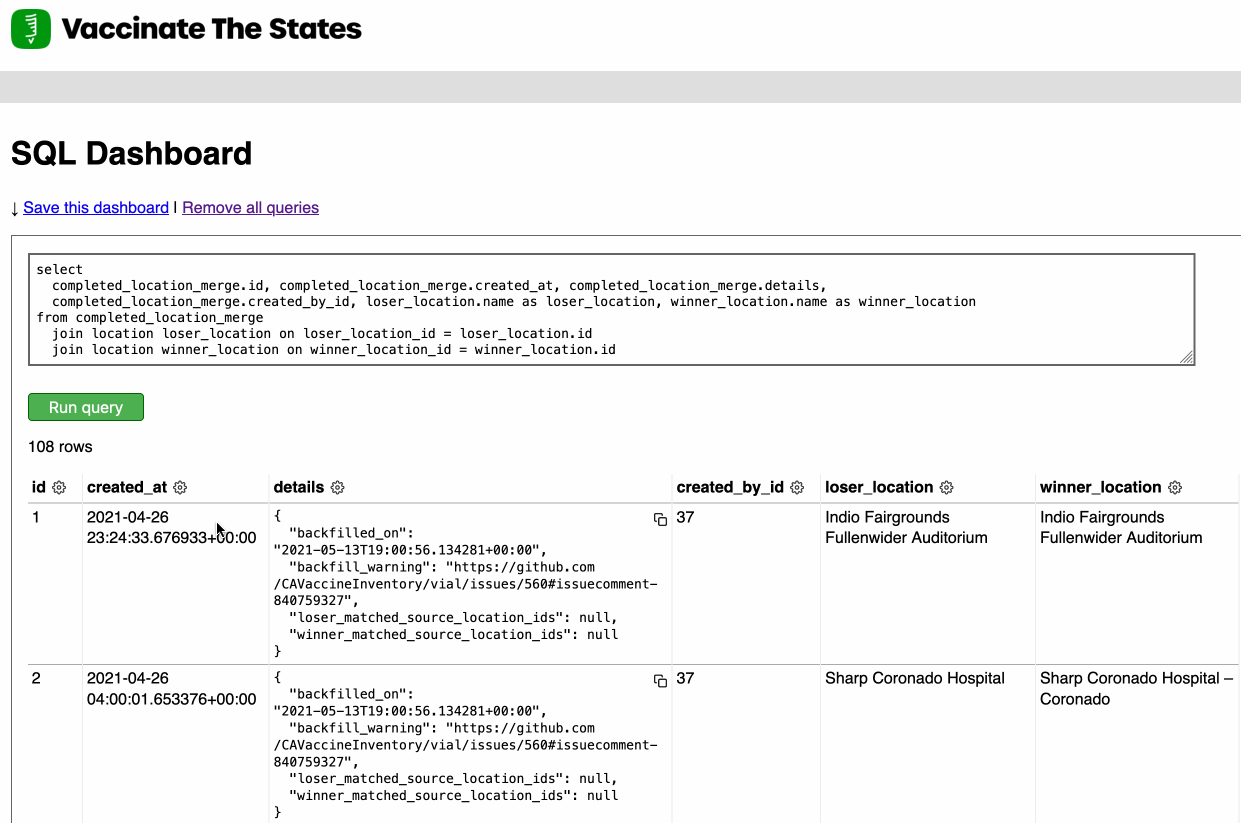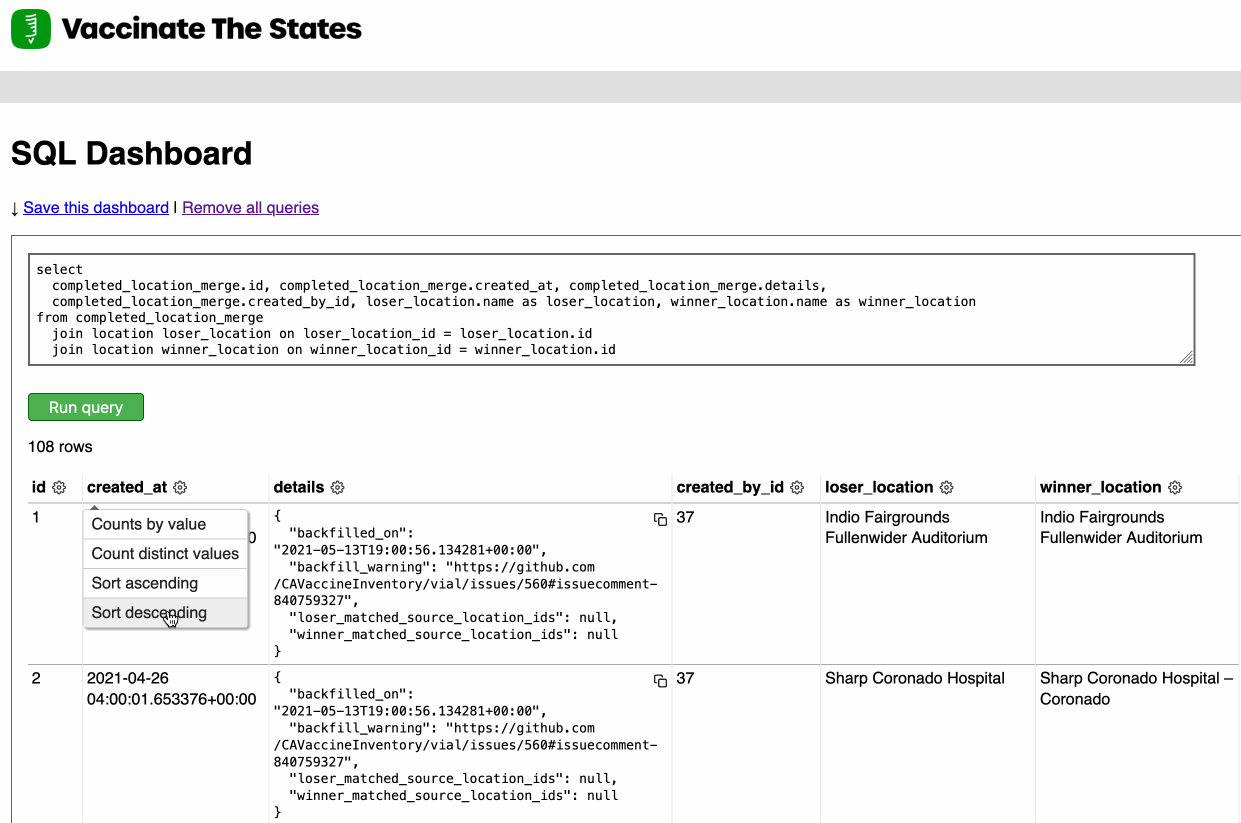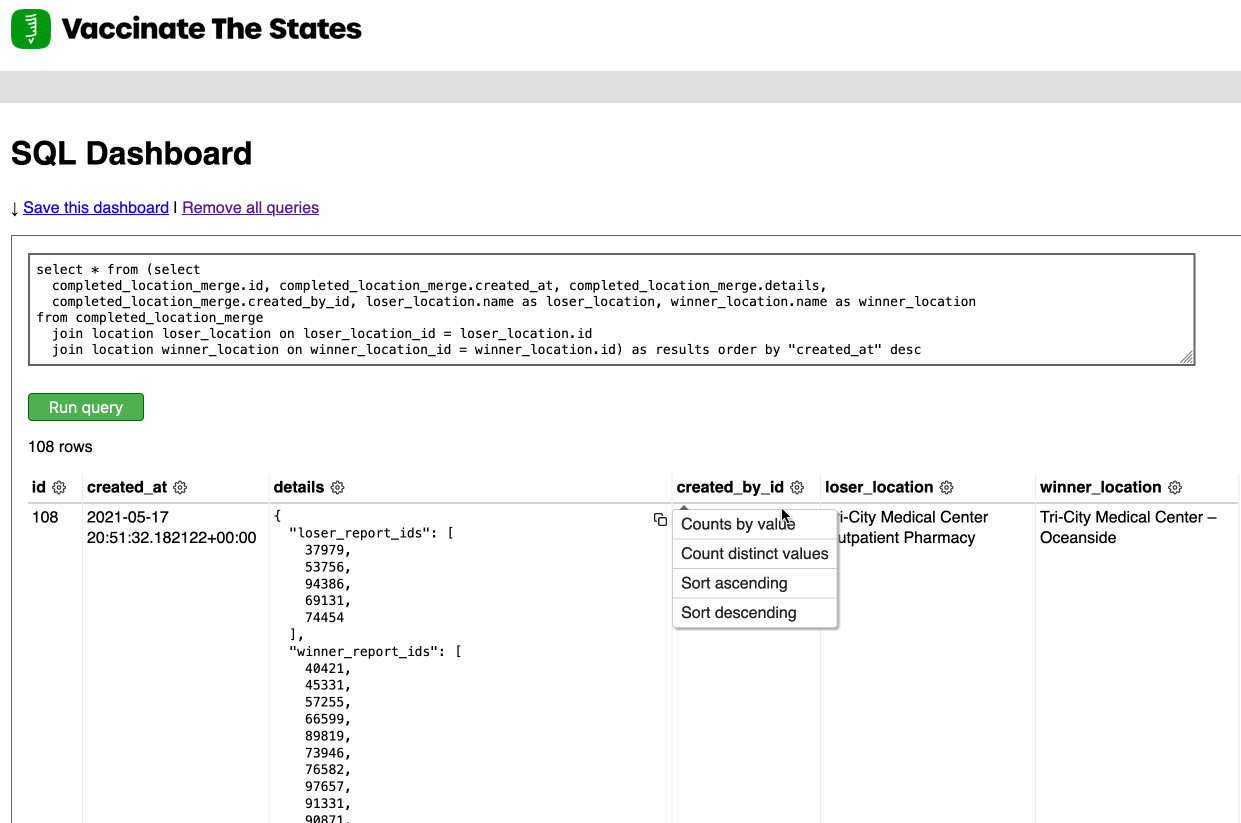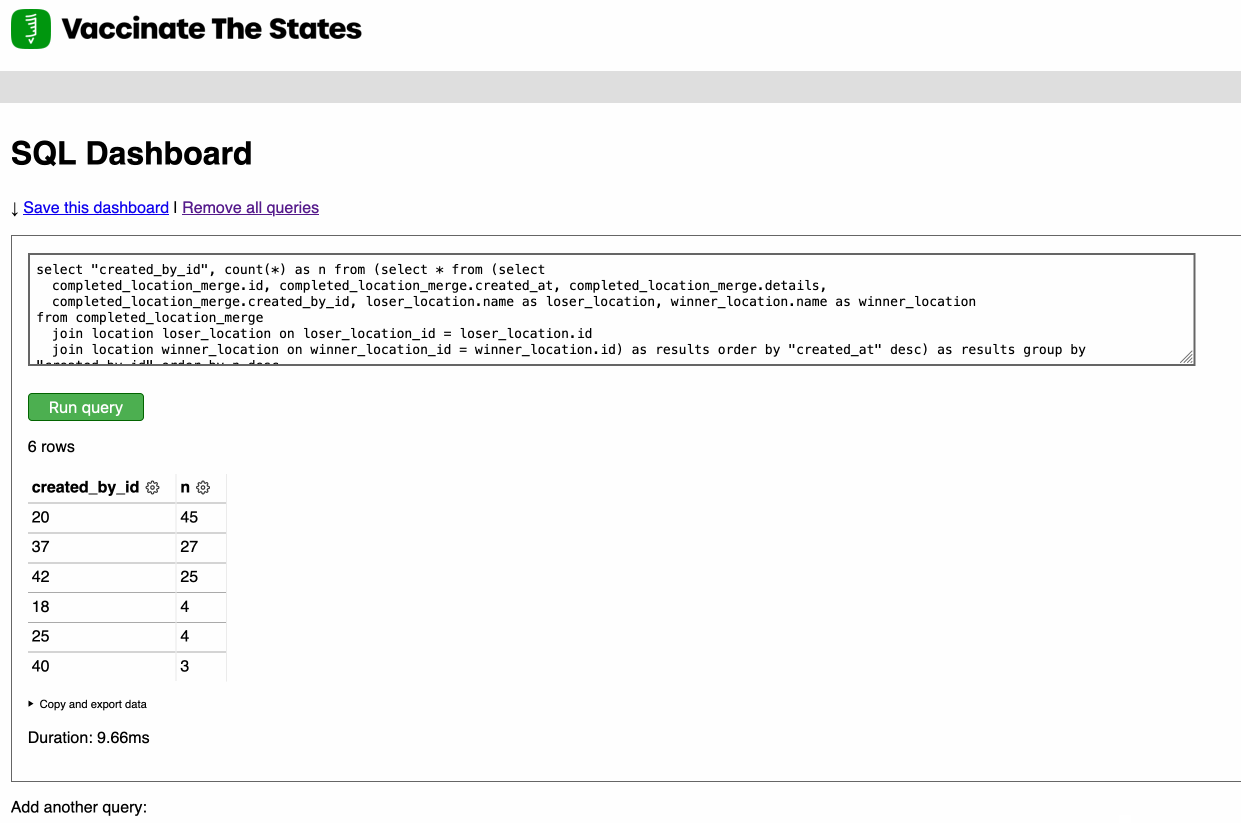
Earlier this week I released Django SQL Dashboard 1.0. I also just released 1.0.1, with a bug fix for PostgreSQL 10 contributed by Ryan Cheley.
[... 629 words]Some SQL Tricks of an Application DBA (via) This post taught me so many PostgreSQL tricks that I hadn’t seen before. Did you know you can start a transaction, drop an index, run explain and then rollback the transaction (cancelling the index drop) to see what explain would look like without that index? Among other things I also learned what the “correlation” database statistic does: it’s a measure of how close-to-sorted the values in a specific column are, which helps PostgreSQL decide if it should do an index scan or a bitmap scan when making use of an index.
PostgreSQL full-text search in the Django Admin. Today I figured out how to use PostgreSQL full-text search in the Django admin for my blog, using the get_search_results method on a subclass of ModelAdmin.
db-to-sqlite 1.0 release. I’ve released version 1.0 of my db-to-sqlite tool, which lets you create a SQLite database copy of any database supported by SQLAlchemy (I’ve tested it against MySQL and PostgreSQL). The tool has a bunch of new features: you can use --redact to redact specific columns, specify --table multiple times to copy a subset of tables, and the --all option now efficiently adds all foreign keys at the end of the import. The project now has unit tests which run against MySQL and PostgreSQL in Travis CI. Also included in the README: a shell one-liner for creating a local SQLite copy of a remote Heroku Postgres database based on extracting the connection string from a Heroku config environment variable.
MapOSMatic. Clever service built on top of OpenStreetMap, which renders double sided city maps with a map and grid on one size and an A-Z street name index on the other. Runs on top of Mapnik, PostGIS and Cairo, with a few thousand additional lines of Python and Django.
Install Django, GeoDjango, PostgreSQL and PostGIS on OSX Leopard. This tutorial worked perfectly for me.
EveryBlock source code released. EveryBlock’s Knight Foundation grant required them to release the source code after two years, under the GPL. Lots of neat Django / PostgreSQL / GIS tricks to be found within.
Django Unit Tests and Transactions. If you’re using a transactional database engine (MySQL with InnoDB, Postgres or SQLite) you can speed things up by running each of your unit tests inside a transaction and rolling back in tearDown().
Historically the project policy has been to avoid putting replication into core PostgreSQL, so as to leave room for development of competing solutions [...] However, it is becoming clear that this policy is hindering acceptance of PostgreSQL to too great an extent, compared to the benefit it offers to the add-on replication projects. Users who might consider PostgreSQL are choosing other database systems because our existing replication options are too complex to install and use for simple cases.
— Tom Lane
ThingDB. Another extensible key/value pair data store, constructed for the Open Library based on Aaron Swartz’s Infogami technology.
PostgreSQL for Mac (via) Looks like a great way of getting PostgreSQL up and running on a Mac.
Tablespaces (via) Interesting new feature in PostgreSQL 7.5.