Entries Links Quotes Notes Guides Elsewhere
May 24, 2026
The big new feature in this alpha is a new customizable "Jump to..." menu, described in detail in The extensible "Jump to" menu in Datasette 1.0a30 on the Datasette blog. You can try it out by hitting / on latest.datasette.io - it looks like this:

The new jump_items_sql() plugin hook allows plugins to add their own items to the set that's searched by the plugin.
Taking advantage of the new makeJumpSections() JavaScript plugin hook added in Datasette 1.0a30, datasette-agent now presents this "Start a new agent chat" interface as part of the Jump to menu, any time you hit /:
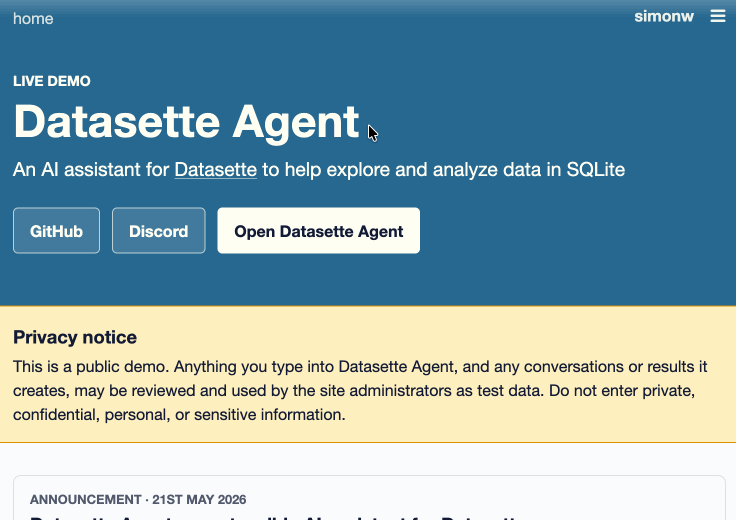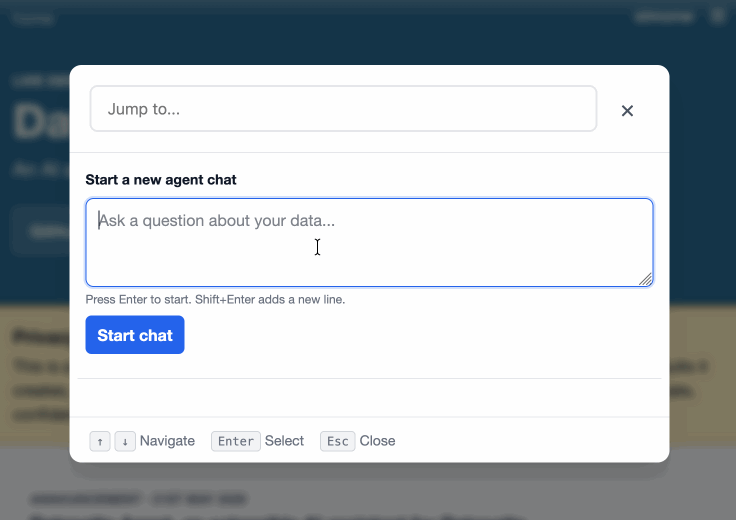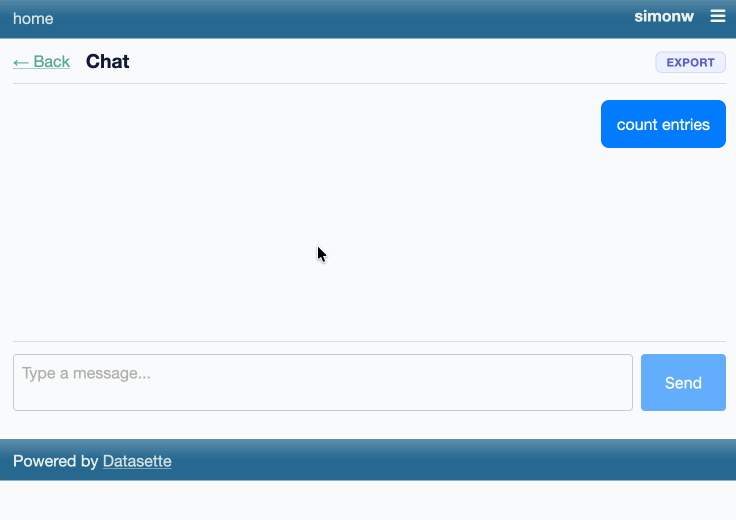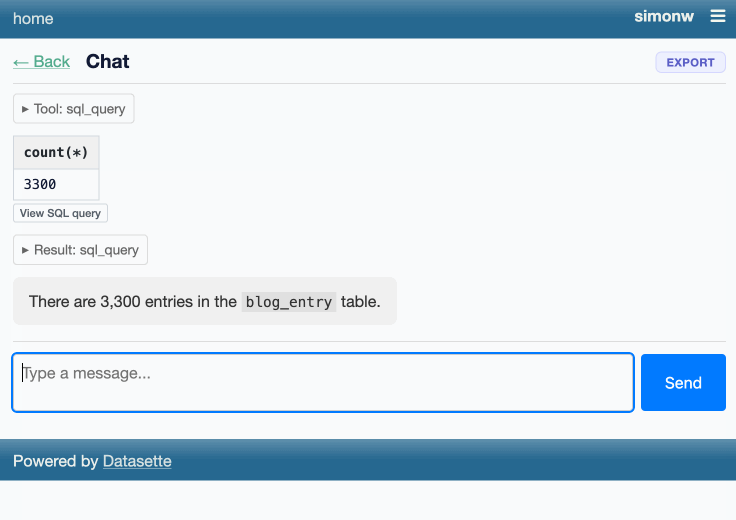
You can try this out by signing into agent.datasette.io using your GitHub account.
One of the smaller features in Datasette 1.0a30 is this:
New documented datasette.fixtures.populate_fixture_database(conn) helper for creating the fixture database tables used by Datasette's own tests, intended for plugin test suites.
This new plugin takes advantage of that API. You can try it out using uvx without even installing Datasette like this:
uvx --prerelease=allow \ --with datasette-fixtures datasette \ --get /fixtures/roadside_attractions.json
Which outputs:
{
"ok": true,
"next": null,
"rows": [
{"pk": 1, "name": "The Mystery Spot", "address": "465 Mystery Spot Road, Santa Cruz, CA 95065", "url": "https://www.mysteryspot.com/", "latitude": 37.0167, "longitude": -122.0024},
{"pk": 2, "name": "Winchester Mystery House", "address": "525 South Winchester Boulevard, San Jose, CA 95128", "url": "https://winchestermysteryhouse.com/", "latitude": 37.3184, "longitude": -121.9511},
{"pk": 3, "name": "Burlingame Museum of PEZ Memorabilia", "address": "214 California Drive, Burlingame, CA 94010", "url": null, "latitude": 37.5793, "longitude": -122.3442},
{"pk": 4, "name": "Bigfoot Discovery Museum", "address": "5497 Highway 9, Felton, CA 95018", "url": "https://www.bigfootdiscoveryproject.com/", "latitude": 37.0414, "longitude": -122.0725}
],
"truncated": false
}The most frustrating failure mode right now is that people submit issues that are not in their own voice. They contain an observed problem somewhere, but it has been thrown into a clanker and the clanker reworded it and made a huge mess of it. Typically, it was prompted so badly that the conclusions produced are more often than not inaccurate but always full of confidence. The result is complete guesswork on root causes, fake-minimal repros, suggested implementation strategies, analogies to adjacent but often the wrong code, and long lists of error classes that might or might not matter. [...]
So at least personally, I increasingly want issue reports to be condensed to what the human actually observed:
- I ran this command.
- I expected this to happen.
- This happened instead.
- Here is the exact error or log.
— Armin Ronacher, on slop issues filed against Pi
Via Hacker News I learned that UK publisher Usborne published free PDFs of their 1980s Computer Books, some of which I remember working through on my Commodore 64 as a child.
These were so great! Beautifully illustrated books with fun projects made up of code you could type into your own machine.
I remember playing "Mad House" typed in from the 1983 book "Creepy Computer Games", so I fed that PDF into Claude and had it build an interactive version of that game in JavaScript and HTML:
Build a vanilla JS artifact that exactly recreates the game Mad House from this book, make sure it's mobile friendly and has a suitable retro aesthetic
Credit the book title and link to https://usborne.com/us/books/computer-and-coding-books




May 23, 2026
On the <dl>
(via)
I learned a few new-to-me things about the <dl> element from this article by Ben Meyer:
- A
<dt>can be followed by multiple<dd> - You can optionally group the
<dt>and<dd>elements in a<div>for styling - but only a<div>. - You can label them using ARIA.
- They've been called "description lists", not "definition lists", since an HTML5 draft in 2008.
So this is valid:
<h2 id="credits">Credits</h2> <dl aria-labelledby="credits"> <div> <dt>Author</dt> <dd>Jeffrey Zeldman</dd> <dd>Ethan Marcotte</dd> </div> </dl>
Here's a useful note from Adrian Roselli on screen reader support for description lists.

May 22, 2026
The memory shortage is causing a repricing of consumer electronics (via) David Oks provides the clearest explanation I've seen yet of why consumer products that use memory are likely to get significantly more expensive over the next few years.
The short version is that memory manufacturers - of which there are just three remaining large companies - have a fixed capacity in terms of how many wafers they can process at any one time. This fixed wafer capacity is then split between DDR - used in desktops and servers, LPDDR - used in mobile phones and low-energy devices, and HBM - used with GPUs.
Until recently, HBM got just 2% of that wafer allocation. The enormous growth in AI data centers has pushed that up to an expected 20% by the end of 2026, and "a single gigabyte of HBM consumes more than three times the wafer capacity that a gigabyte of DDR or LPDDR does".
Memory companies have learned from the extinction of their rivals that you should always under-provision rather than over-provision your fabricator capacity. The profit margins and demand for HBM (high-bandwidth memory) will constrain the production of consumer-device RAM for several years.
This is already being felt in the sub-$100 smartphone market, which is particularly important to markets like Africa and South Asia.
(The original title of the piece was "AI is killing the cheap smartphone" but I'm using the Hacker News rephrased title, which I think does more justice to the content.)
FTC to Require Cox Media Group, Two Other Firms to Pay Nearly $1 Million to Settle Charges They Deceived Customers About “Active Listening” AI-Powered Marketing Service (via) Back in 2024 Cox Media Group were caught trying to sell advertisers packages based on "active listening", with this deck which claimed:
- Smart devices capture real-time intent data by listening to our conversations
- Advertisers can pair this voice-data with behavioral data to target in-market consumers
I wrote about this in September 2024. My theory:
I think active listening is the term that the team came up with for “something that sounds fancy but really just means the way ad targeting platforms work already”. Then they got over-excited about the new metaphor and added that first couple of slides that talk about “voice data”, without really understanding how the tech works or what kind of a shitstorm that could kick off when people who DID understand technology started paying attention to their marketing.
This FTC press release appears to confirm that's pretty much what happened:
CMG, MindSift and 1010 Digital Works claimed their “Active Listening” branded marketing service listened in on consumers’ conversations overheard by smart devices, in real time, to target advertising [...]
According to the complaints, this service did not, in fact, listen in on consumers’ conversations or use voice data at all—nor did the service accurately place ads in customers’ desired locations. Instead, the service the companies provided consisted of reselling—at a significant markup—email lists obtained from other data brokers.
The FTC also clarify that hiding an "opt-in" to using voice data in terms of service would not be acceptable, as tricks like that do not constitute "adequate consent":
The FTC also alleged that all three companies deceived potential customers by claiming that consumers had opted into the Active Listening service. The company, however, did not seek or obtain consumers’ consent, according to the complaints. Instead, the companies claimed that consumers had “opted in” by agreeing to the terms of service that people have to accept when downloading and using apps. Clicking through mandatory terms of service does not constitute “opt-in consent” for such an invasive service or for use of consumers’ voice data from inside their homes. If the Active Listening service had functioned as advertised, this collection and use of consumers’ voice data without adequate consent would itself violate Section 5 of the FTC Act.
Attempting to myth bust the conspiracy theory that our mobile devices target ads to us based on spying through the microphones continues to be my least rewarding niche online hobby. It's nice to have a new piece of ammunition.
May 21, 2026
Datasette Agent
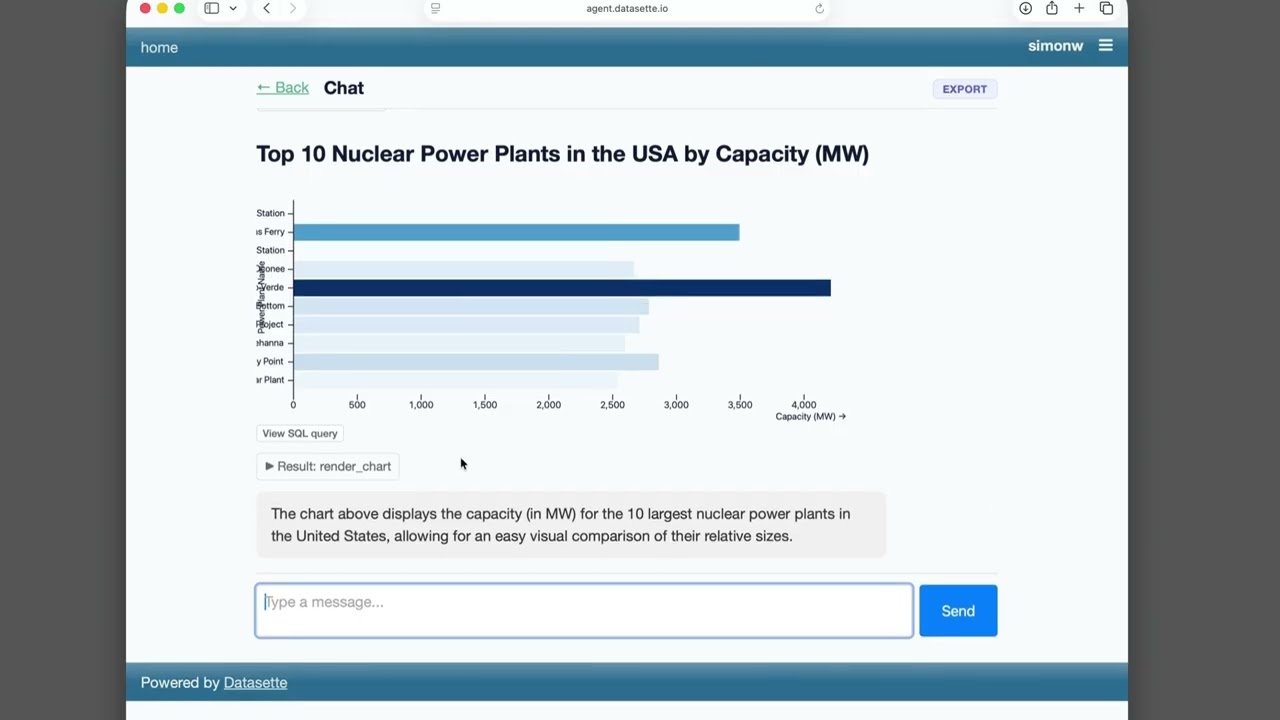
We just announced the first release of Datasette Agent, a new extensible AI assistant for Datasette. I’ve been working on my LLM Python library for just over three years now, and Datasette Agent represents the moment that LLM and Datasette finally come together. I’m really excited about it!
[... 659 words]A Datasette Agent plugin for running commands in a Fly Sprites sandbox.
- "View SQL query" buttons below rendered charts.
- "View SQL query" buttons for both visible tables and collapsed SQL result tool calls.
- Don't display empty reasoning chunks
- Improved handling of truncated responses - table still displays to the user even if the SQL results were truncated when showing the agent.
See Datasette Agent, an extensible AI assistant for Datasette.
May 20, 2026
We have the ability to use compute resources to support our proprietary AI applications (such as Grok 5, which is currently being trained at COLOSSUS II), while also providing access to select compute capacity to third-party customers. For example, in May 2026, we entered into Cloud Services Agreements with Anthropic PBC (“Anthropic”), an AI research and development public benefit corporation, with respect to access to compute capacity across COLOSSUS and COLOSSUS II. Pursuant to these agreements, the customer has agreed to pay us $1.25 billion per month through May 2029, with capacity ramping in May and June 2026 at a reduced fee. The agreements may be terminated by either party upon 90 days’ notice.
— SpaceX S-1, highlights mine
How fast is 10 tokens per second really? (via) Neat little HTML app by Mike Veerman (source code here) which simulates LLM token output speeds from 5/second to 800/second.
Useful if you see a model advertised as "30 tokens/second" and want to get a feel for what that actually looks like.







It's hard to find much to write about Google I/O this year because I have a policy of not writing about anything that I can't try out myself, and a lot of the big announcements are "coming soon".
I actually prefer to write about things that are in general availability, because I've had instances in the past where the previews didn't match what was released to the general public later on.
Aside from Gemini 3.5 Flash the most interesting announcement looks to be Google's upcoming OpenClaw competitor Gemini Spark, described as "your personal AI agent" which can "connect natively with your favorite Google apps like Gmail, Calendar, Drive, Docs, Sheets, Slides, YouTube, and Google Maps". The FAQ for that also includes this confusing detail:
What Gemini model does Gemini Spark run on?
Gemini Spark runs on Gemini 3.5 Flash and Antigravity.
The antigravity.google website currently lists Antigravity as a desktop app, a CLI agent tool (written in Go), the Antigravity SDK (an open source Python wrapper around a bundled closed source Go binary), and the original Antigravity IDE (a VS Code fork).
I guess Gemini Spark, the user-facing hosted agent product, might be running on that Go binary, but I'm not sure why that's worth mentioning in the FAQ!
Naturally I went looking for notes on how Gemini Spark intends to handle the risk of prompt injection. The best information I could find on that was in the Everything Google Cloud customers need to know coming out of Google I/O post aimed at enterprise customers, which includes:
Spark operates in a fully managed, secure runtime on Google Cloud, meaning you get enterprise-grade security without ever having to manage the underlying infrastructure. Every task executes in a fresh, strictly isolated, ephemeral VM to help ensure data never overlaps between sessions. To protect your enterprise, all traffic routes through our secure Agent Gateway that enforces Data Loss Prevention (DLP) policies, while user credentials remain fully encrypted and are never exposed directly to the agent.
Given how many people are going to be piping very sensitive data through Gemini Spark in the near future I hope they've made this bullet-proof, or this could be a top candidate for the agent security challenger disaster that we still haven't seen.
Also of note: in Transitioning Gemini CLI to Antigravity CLI Google announce that the open source Gemini CLI tool (Apache 2.0 licensed TypeScript) will stop working with their AI subscription plans on June 18th, replaced by the new closed source Antigravity CLI.
- More color! Bar and waffle charts without a color column are shaded by magnitude with a sequential color scheme; color columns holding text values use the
observable10categorical scheme. #2- Now checks
execute-sqlpermission before running the query to find the column names.- Charts now display interactive tooltips.
- Fixed a bug where
waffleYcharts were not described to the agent.

May 19, 2026
- New model
gemini-3.5-flashfor Gemini 3.5 Flash.
See also my notes on Gemini 3.5 Flash, and the pelican I drew using this upgrade to the plugin.
Gemini 3.5 Flash: more expensive, but Google plan to use it for everything

Today at Google I/O, Google released Gemini 3.5 Flash. This one skipped the -preview modifier and went straight to general availability, and Google appear to be using it for a whole lot of their key products:
- Fixed bug tracking chains of responses. Refs datasette-llm#7
- Compatible with
llm>=0.32a0alpha - adds the ability to stream reasoning tokens.
- Fix for bug where
llm_prompt_context()hook did not fully collect chains of responses. #7
The last six months in LLMs in five minutes

I put together these annotated slides from my five minute lightning talk at PyCon US 2026, using the latest iteration of my annotated presentation tool.
[... 2,061 words]May 18, 2026







I'm heading home from PyCon US today so I went on a last morning walk to try and spot a pelican. I saw one! Didn't get a great photo of that, but I did see some goslings down by the swan boat lake.
May 17, 2026
GDS weighs in on the NHS’s decision to retreat from Open Source. Terence Eden continues his coverage of the NHS' poorly considered decision to close down access to their open source repositories in response to vulnerabilities reported to them as part of Project Glasswing.
Now the Government Digital Service have joined the conversation with AI, open code and vulnerability risk in the public sector, published May 14th. Their key recommendation:
Keep open by default. Making everything private adds additional delivery and policy costs, and can reduce reuse and scrutiny. Openness should remain the default posture, with closure used sparingly and deliberately.
While they don't mention the NHS by name, Terence speaks the language of the civil service and interprets this as a major escalation:
Within the UK's Civil Service you occasionally hear the expression "being invited to a meeting without biscuits". It implies a rather frosty discussion without any of the polite niceties of a normal meeting. In general though, even when people have severe disagreements, it is rare for tempers to fray. It is even rarer for those internal disagreements to spill over into public.
May 16, 2026
In preparation for a lightning talk I'm giving at PyCon US this afternoon I decided to figure out how many names OpenClaw has actually had since that first commit back in November.
Thanks to this first_line_history.py tool (code here) the answer, according to the Git history of the OpenClaw README, is:
Warelay → CLAWDIS → CLAWDBOT → Clawdbot → Moltbot →🦞 OpenClaw
Or in detail (the output from the tool):
2025-11-24T11:23:15+01:00 16dfc1a # Warelay — WhatsApp Relay CLI (Twilio) 2025-11-24T11:41:37+01:00 d4153da # 📡 Warelay — WhatsApp Relay CLI (Twilio) 2025-11-24T17:47:57+01:00 343ef9b # 📡 warelay — WhatsApp Relay CLI (Twilio) 2025-11-25T04:44:10+01:00 14b3c6f # 📡 warelay — WhatsApp Relay CLI 2025-11-25T12:48:40+01:00 4814021 # 📡 warelay — Send, receive, and auto-reply on WhatsApp—Twilio-backed or QR-linked. 2025-11-25T13:50:18+01:00 d51a3e9 # warelay 📡 - Send, receive, and auto-reply on WhatsApp via Twilio or QR-linked WhatsApp Web; webhook setup in one command 2025-11-25T13:51:13+01:00 4d2a8a8 # 📡 warelay — Send, receive, and auto-reply on WhatsApp—Twilio-backed or QR-linked. 2025-11-25T14:52:43+01:00 1ef7f4d # 📡 warelay — Send, receive, and auto-reply on WhatsApp. 2025-12-03T15:45:32+00:00 a27ee23 # 🦞 CLAWDIS — WhatsApp Gateway for AI Agents 2025-12-08T12:43:13+01:00 17fa2f4 # 🦞 CLAWDIS — WhatsApp & Telegram Gateway for AI Agents 2025-12-19T18:41:17+01:00 7710439 # 🦞 CLAWDIS — Personal AI Assistant 2026-01-04T14:32:47+00:00 246adaa # 🦞 CLAWDBOT — Personal AI Assistant 2026-01-10T05:14:09+01:00 cdb915d # 🦞 Clawdbot — Personal AI Assistant 2026-01-27T13:37:47-05:00 3fe4b25 # 🦞 Moltbot — Personal AI Assistant 2026-01-30T03:15:10+01:00 9a71607 # 🦞 OpenClaw — Personal AI Assistant
[...] in the last 10 years I’ve learned to really love and respect CSS as a technology.
So I decided years ago that I wanted to react to “CSS is hard” by getting better at CSS and taking it seriously as a technology, instead of devaluing it. Doing that changed everything for me: I learned that so many of my frustrations (“centering is impossible”) had been addressed in CSS a long time ago, and that also what “centering” means is not always straightforward and it makes sense that there are many ways to do it. CSS is hard because it’s solving a hard problem!
— Julia Evans, Moving away from Tailwind, and learning to structure my CSS
May 15, 2026
Part of the infrastructure I use for publishing my iNaturalist sightings on my blog. I've been running this in production for a few weeks now, inspiring some iterations on how it works, so I decided to ship a 0.1 release.
You can see an example of the output in this JSON file.


I went for a bird walk in the morning before PyCon, and we spotted a local seagull enjoying a Starbucks.
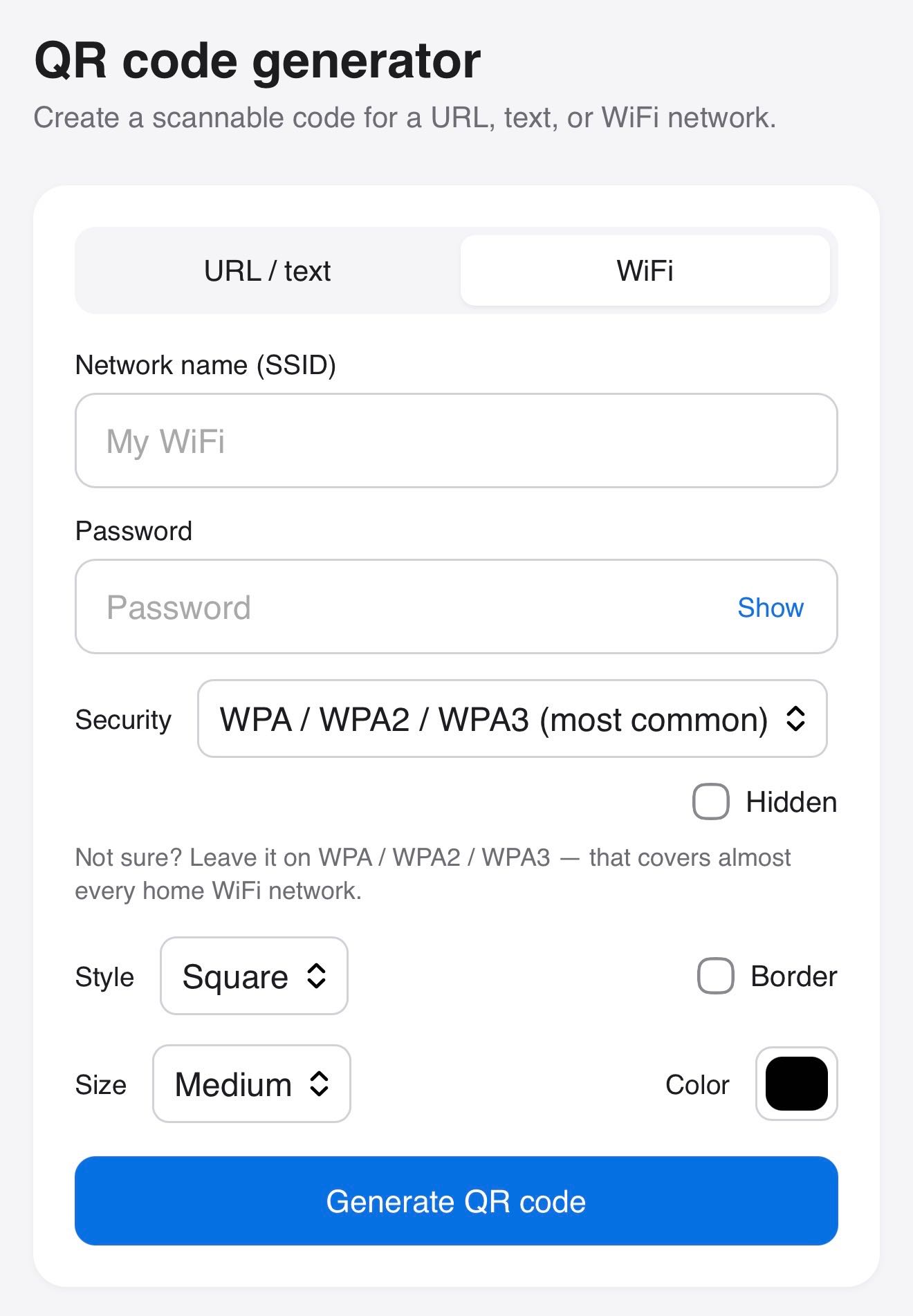
Claude helped me build this tool for creating QR codes, for both text/URLs and for connecting to WiFi networks.
This plugin works in conjunction with datasette-llm and datasette-llm-accountant to let you configure a per-user (or global) spending limit for LLM usage inside of Datasette. Configuration looks something like this:
plugins: datasette-llm-limits: limits: per-user-daily: scope: actor window: rolling-24h amount_usd: 1.00
- Tool availability can now be attached to a
required_permission. The default background agent tools now require the newdatasette-agent-backgroundpermission. #10
May 14, 2026
This Mitchell Hashimoto quote about Bun migrating from Zig to Rust reminded me of a similar conversation I had at a conference last week.
I was talking to someone who worked for a medium sized technology company with a pair of legacy/legendary iPhone and Android apps.
They told me they had just completed a coding-agent driven rewrite of both apps to React Native.
I asked why they chose that, given that coding agents presumably drive down the cost of maintaining separate iPhone and Android apps.
They said that React Native has improved a lot over the past few years and covered everything their apps needed to do.
And... if it turned out to be the wrong decision, they could just port back to native in the future.
Like Mitchell said:
Programming languages used to be LOCK IN, and they're increasingly not so.