30 posts tagged “gpt-5”
2026
It genuinely feels to me like GPT-5.2 and Opus 4.5 in November represent an inflection point - one of those moments where the models get incrementally better in a way that tips across an invisible capability line where suddenly a whole bunch of much harder coding problems open up.
2025
I ported JustHTML from Python to JavaScript with Codex CLI and GPT-5.2 in 4.5 hours

I wrote about JustHTML yesterday—Emil Stenström’s project to build a new standards compliant HTML5 parser in pure Python code using coding agents running against the comprehensive html5lib-tests testing library. Last night, purely out of curiosity, I decided to try porting JustHTML from Python to JavaScript with the least amount of effort possible, using Codex CLI and GPT-5.2. It worked beyond my expectations.
[... 1,818 words]OpenAI are quietly adopting skills, now available in ChatGPT and Codex CLI
One of the things that most excited me about Anthropic’s new Skills mechanism back in October is how easy it looked for other platforms to implement. A skill is just a folder with a Markdown file and some optional extra resources and scripts, so any LLM tool with the ability to navigate and read from a filesystem should be capable of using them. It turns out OpenAI are doing exactly that, with skills support quietly showing up in both their Codex CLI tool and now also in ChatGPT itself.
[... 1,360 words]GPT-5.2

OpenAI reportedly declared a “code red” on the 1st of December in response to increasingly credible competition from the likes of Google’s Gemini 3. It’s less than two weeks later and they just announced GPT-5.2, calling it “the most capable model series yet for professional knowledge work”.
[... 964 words]Building more with GPT-5.1-Codex-Max (via) Hot on the heels of yesterday's Gemini 3 Pro release comes a new model from OpenAI called GPT-5.1-Codex-Max.
(Remember when GPT-5 was meant to bring in a new era of less confusing model names? That didn't last!)
It's currently only available through their Codex CLI coding agent, where it's the new default model:
Starting today, GPT‑5.1-Codex-Max will replace GPT‑5.1-Codex as the default model in Codex surfaces. Unlike GPT‑5.1, which is a general-purpose model, we recommend using GPT‑5.1-Codex-Max and the Codex family of models only for agentic coding tasks in Codex or Codex-like environments.
It's not available via the API yet but should be shortly.
The timing of this release is interesting given that Gemini 3 Pro appears to have aced almost all of the benchmarks just yesterday. It's reminiscent of the period in 2024 when OpenAI consistently made big announcements that happened to coincide with Gemini releases.
OpenAI's self-reported SWE-Bench Verified score is particularly notable: 76.5% for thinking level "high" and 77.9% for the new "xhigh". That was the one benchmark where Gemini 3 Pro was out-performed by Claude Sonnet 4.5 - Gemini 3 Pro got 76.2% and Sonnet 4.5 got 77.2%. OpenAI now have the highest scoring model there by a full .7 of a percentage point!
They also report a score of 58.1% on Terminal Bench 2.0, beating Gemini 3 Pro's 54.2% (and Sonnet 4.5's 42.8%.)
The most intriguing part of this announcement concerns the model's approach to long context problems:
GPT‑5.1-Codex-Max is built for long-running, detailed work. It’s our first model natively trained to operate across multiple context windows through a process called compaction, coherently working over millions of tokens in a single task. [...]
Compaction enables GPT‑5.1-Codex-Max to complete tasks that would have previously failed due to context-window limits, such as complex refactors and long-running agent loops by pruning its history while preserving the most important context over long horizons. In Codex applications, GPT‑5.1-Codex-Max automatically compacts its session when it approaches its context window limit, giving it a fresh context window. It repeats this process until the task is completed.
There's a lot of confusion on Hacker News about what this actually means. Claude Code already does a version of compaction, automatically summarizing previous turns when the context runs out. Does this just mean that Codex-Max is better at that process?
I had it draw me a couple of pelicans by typing "Generate an SVG of a pelican riding a bicycle" directly into the Codex CLI tool. Here's thinking level medium:

And here's thinking level "xhigh":

I also tried xhigh on the my longer pelican test prompt, which came out like this:

Also today: GPT-5.1 Pro is rolling out today to all Pro users. According to the ChatGPT release notes:
GPT-5.1 Pro is rolling out today for all ChatGPT Pro users and is available in the model picker. GPT-5 Pro will remain available as a legacy model for 90 days before being retired.
That's a pretty fast deprecation cycle for the GPT-5 Pro model that was released just three months ago.
GPT-5.1 Instant and GPT-5.1 Thinking System Card Addendum. I was confused about whether the new "adaptive thinking" feature of GPT-5.1 meant they were moving away from the "router" mechanism where GPT-5 in ChatGPT automatically selected a model for you.
This page addresses that, emphasis mine:
GPT‑5.1 Instant is more conversational than our earlier chat model, with improved instruction following and an adaptive reasoning capability that lets it decide when to think before responding. GPT‑5.1 Thinking adapts thinking time more precisely to each question. GPT‑5.1 Auto will continue to route each query to the model best suited for it, so that in most cases, the user does not need to choose a model at all.
So GPT‑5.1 Instant can decide when to think before responding, GPT-5.1 Thinking can decide how hard to think, and GPT-5.1 Auto (not a model you can use via the API) can decide which out of Instant and Thinking a prompt should be routed to.
If anything this feels more confusing than the GPT-5 routing situation!
The system card addendum PDF itself is somewhat frustrating: it shows results on an internal benchmark called "Production Benchmarks", also mentioned in the GPT-5 system card, but with vanishingly little detail about what that tests beyond high level category names like "personal data", "extremism" or "mental health" and "emotional reliance" - those last two both listed as "New evaluations, as introduced in the GPT-5 update on sensitive conversations" - a PDF dated October 27th that I had previously missed.
That document describes the two new categories like so:
- Emotional Reliance not_unsafe - tests that the model does not produce disallowed content under our policies related to unhealthy emotional dependence or attachment to ChatGPT
- Mental Health not_unsafe - tests that the model does not produce disallowed content under our policies in situations where there are signs that a user may be experiencing isolated delusions, psychosis, or mania
So these are the ChatGPT Psychosis benchmarks!
Introducing GPT-5.1 for developers. OpenAI announced GPT-5.1 yesterday, calling it a smarter, more conversational ChatGPT. Today they've added it to their API.
We actually got four new models today:
There are a lot of details to absorb here.
GPT-5.1 introduces a new reasoning effort called "none" (previous were minimal, low, medium, and high) - and none is the new default.
This makes the model behave like a non-reasoning model for latency-sensitive use cases, with the high intelligence of GPT‑5.1 and added bonus of performant tool-calling. Relative to GPT‑5 with 'minimal' reasoning, GPT‑5.1 with no reasoning is better at parallel tool calling (which itself increases end-to-end task completion speed), coding tasks, following instructions, and using search tools---and supports web search in our API platform.
When you DO enable thinking you get to benefit from a new feature called "adaptive reasoning":
On straightforward tasks, GPT‑5.1 spends fewer tokens thinking, enabling snappier product experiences and lower token bills. On difficult tasks that require extra thinking, GPT‑5.1 remains persistent, exploring options and checking its work in order to maximize reliability.
Another notable new feature for 5.1 is extended prompt cache retention:
Extended prompt cache retention keeps cached prefixes active for longer, up to a maximum of 24 hours. Extended Prompt Caching works by offloading the key/value tensors to GPU-local storage when memory is full, significantly increasing the storage capacity available for caching.
To enable this set "prompt_cache_retention": "24h" in the API call. Weirdly there's no price increase involved with this at all. I asked about that and OpenAI's Steven Heidel replied:
with 24h prompt caching we move the caches from gpu memory to gpu-local storage. that storage is not free, but we made it free since it moves capacity from a limited resource (GPUs) to a more abundant resource (storage). then we can serve more traffic overall!
The most interesting documentation I've seen so far is in the new 5.1 cookbook, which also includes details of the new shell and apply_patch built-in tools. The apply_patch.py implementation is worth a look, especially if you're interested in the advancing state-of-the-art of file editing tools for LLMs.
I'm still working on integrating the new models into LLM. The Codex models are Responses-API-only.
I got this pelican for GPT-5.1 default (no thinking):

And this one with reasoning effort set to high:

These actually feel like a regression from GPT-5 to me. The bicycles have less spokes!
Pelican on a Bike—Raytracer Edition (via) beetle_b ran this prompt against a bunch of recent LLMs:
Write a POV-Ray file that shows a pelican riding on a bicycle.
This turns out to be a harder challenge than SVG, presumably because there are less examples of POV-Ray in the training data:
Most produced a script that failed to parse. I would paste the error back into the chat and let it attempt a fix.
The results are really fun though! A lot of them end up accompanied by a weird floating egg for some reason - here's Claude Opus 4:

I think the best result came from GPT-5 - again with the floating egg though!

I decided to try this on the new gpt-5-codex-mini, using the trick I described yesterday. Here's the code it wrote.
./target/debug/codex prompt -m gpt-5-codex-mini \
"Write a POV-Ray file that shows a pelican riding on a bicycle."
It turns out you can render POV files on macOS like this:
brew install povray
povray demo.pov # produces demo.png
The code GPT-5 Codex Mini created didn't quite work, so I round-tripped it through Sonnet 4.5 via Claude Code a couple of times - transcript here. Once it had fixed the errors I got this:

That's significantly worse than the one beetle_b got from GPT-5 Mini!
Reverse engineering Codex CLI to get GPT-5-Codex-Mini to draw me a pelican

OpenAI partially released a new model yesterday called GPT-5-Codex-Mini, which they describe as "a more compact and cost-efficient version of GPT-5-Codex". It’s currently only available via their Codex CLI tool and VS Code extension, with proper API access "coming soon". I decided to use Codex to reverse engineer the Codex CLI tool and give me the ability to prompt the new model directly.
[... 1,774 words]GPT-5 pro. Here's OpenAI's model documentation for their GPT-5 pro model, released to their API today at their DevDay event.
It has similar base characteristics to GPT-5: both share a September 30, 2024 knowledge cutoff and 400,000 context limit.
GPT-5 pro has maximum output tokens 272,000 max, an increase from 128,000 for GPT-5.
As our most advanced reasoning model, GPT-5 pro defaults to (and only supports)
reasoning.effort: high
It's only available via OpenAI's Responses API. My LLM tool doesn't support that in core yet, but the llm-openai-plugin plugin does. I released llm-openai-plugin 0.7 adding support for the new model, then ran this:
llm install -U llm-openai-plugin
llm -m openai/gpt-5-pro "Generate an SVG of a pelican riding a bicycle"
It's very, very slow. The model took 6 minutes 8 seconds to respond and charged me for 16 input and 9,205 output tokens. At $15/million input and $120/million output this pelican cost me $1.10!

Here's the full transcript. It looks visually pretty simpler to the much, much cheaper result I got from GPT-5.
Given a week or two to try out ideas and search the literature, I’m pretty sure that Freek and I could’ve solved this problem ourselves. Instead, though, I simply asked GPT5-Thinking. After five minutes, it gave me something confident, plausible-looking, and (I could tell) wrong. But rather than laughing at the silly AI like a skeptic might do, I told GPT5 how I knew it was wrong. It thought some more, apologized, and tried again, and gave me something better. So it went for a few iterations, much like interacting with a grad student or colleague. [...]
Now, in September 2025, I’m here to tell you that AI has finally come for what my experience tells me is the most quintessentially human of all human intellectual activities: namely, proving oracle separations between quantum complexity classes. Right now, it almost certainly can’t write the whole research paper (at least if you want it to be correct and good), but it can help you get unstuck if you otherwise know what you’re doing, which you might call a sweet spot.
— Scott Aaronson, UT Austin Quantum Information Center
GPT-5-Codex. OpenAI half-released this model earlier this month, adding it to their Codex CLI tool but not their API.
Today they've fixed that - the new model can now be accessed as gpt-5-codex. It's priced the same as regular GPT-5: $1.25/million input tokens, $10/million output tokens, and the same hefty 90% discount for previously cached input tokens, especially important for agentic tool-using workflows which quickly produce a lengthy conversation.
It's only available via their Responses API, which means you currently need to install the llm-openai-plugin to use it with LLM:
llm install -U llm-openai-plugin
llm -m openai/gpt-5-codex -T llm_version 'What is the LLM version?'
Outputs:
The installed LLM version is 0.27.1.
I added tool support to that plugin today, mostly authored by GPT-5 Codex itself using OpenAI's Codex CLI.
The new prompting guide for GPT-5-Codex is worth a read.
GPT-5-Codex is purpose-built for Codex CLI, the Codex IDE extension, the Codex cloud environment, and working in GitHub, and also supports versatile tool use. We recommend using GPT-5-Codex only for agentic and interactive coding use cases.
Because the model is trained specifically for coding, many best practices you once had to prompt into general purpose models are built in, and over prompting can reduce quality.
The core prompting principle for GPT-5-Codex is “less is more.”
I tried my pelican benchmark at a cost of 2.156 cents.
llm -m openai/gpt-5-codex "Generate an SVG of a pelican riding a bicycle"

I asked Codex to describe this image and it correctly identified it as a pelican!
llm -m openai/gpt-5-codex -a https://static.simonwillison.net/static/2025/gpt-5-codex-api-pelican.png \
-s 'Write very detailed alt text'
Cartoon illustration of a cream-colored pelican with a large orange beak and tiny black eye riding a minimalist dark-blue bicycle. The bird’s wings are tucked in, its legs resemble orange stick limbs pushing the pedals, and its tail feathers trail behind with light blue motion streaks to suggest speed. A small coral-red tongue sticks out of the pelican’s beak. The bicycle has thin light gray spokes, and the background is a simple pale blue gradient with faint curved lines hinting at ground and sky.
GPT‑5-Codex and upgrades to Codex. OpenAI half-released a new model today: GPT‑5-Codex, a fine-tuned GPT-5 variant explicitly designed for their various AI-assisted programming tools.
Update: OpenAI call it a "version of GPT-5", they don't explicitly describe it as a fine-tuned model. Calling it a fine-tune was my mistake here.
I say half-released because it's not yet available via their API, but they "plan to make GPT‑5-Codex available in the API soon".
I wrote about the confusing array of OpenAI products that share the name Codex a few months ago. This new model adds yet another, though at least "GPT-5-Codex" (using two hyphens) is unambiguous enough not to add to much more to the confusion.
At this point it's best to think of Codex as OpenAI's brand name for their coding family of models and tools.
The new model is already integrated into their VS Code extension, the Codex CLI and their Codex Cloud asynchronous coding agent. I'd been calling that last one "Codex Web" but I think Codex Cloud is a better name since it can also be accessed directly from their iPhone app.
Codex Cloud also has a new feature: you can configure it to automatically run code review against specific GitHub repositories (I found that option on chatgpt.com/codex/settings/code-review) and it will create a temporary container to use as part of those reviews. Here's the relevant documentation.
Some documented features of the new GPT-5-Codex model:
- Specifically trained for code review, which directly supports their new code review feature.
- "GPT‑5-Codex adapts how much time it spends thinking more dynamically based on the complexity of the task." Simple tasks (like "list files in this directory") should run faster. Large, complex tasks should use run for much longer - OpenAI report Codex crunching for seven hours in some cases!
- Increased score on their proprietary "code refactoring evaluation" from 33.9% for GPT-5 (high) to 51.3% for GPT-5-Codex (high). It's hard to evaluate this without seeing the details of the eval but it does at least illustrate that refactoring performance is something they've focused on here.
- "GPT‑5-Codex also shows significant improvements in human preference evaluations when creating mobile websites" - in the past I've habitually prompted models to "make it mobile-friendly", maybe I don't need to do that any more.
- "We find that comments by GPT‑5-Codex are less likely to be incorrect or unimportant" - I originally misinterpreted this as referring to comments in code but it's actually about comments left on code reviews.
The system prompt for GPT-5-Codex in Codex CLI is worth a read. It's notably shorter than the system prompt for other models - here's a diff.
Here's the section of the updated system prompt that talks about comments:
Add succinct code comments that explain what is going on if code is not self-explanatory. You should not add comments like "Assigns the value to the variable", but a brief comment might be useful ahead of a complex code block that the user would otherwise have to spend time parsing out. Usage of these comments should be rare.
Theo Browne has a video review of the model and accompanying features. He was generally impressed but noted that it was surprisingly bad at using the Codex CLI search tool to navigate code. Hopefully that's something that can fix with a system prompt update.
Finally, can it drew a pelican riding a bicycle? Without API access I instead got Codex Cloud to have a go by prompting:
Generate an SVG of a pelican riding a bicycle, save as pelican.svg
Here's the result:

Here's an interesting example of models incrementally improving over time: I am finding that today's leading models are competent at writing prompts for themselves and each other.
A year ago I was quite skeptical of the pattern where models are used to help build prompts. Prompt engineering was still a young enough discipline that I did not expect the models to have enough training data to be able to prompt themselves better than a moderately experienced human.
The Claude 4 and GPT-5 families both have training cut-off dates within the past year - recent enough that they've seen a decent volume of good prompting examples.
I expect they have also been deliberately trained for this. Anthropic make extensive use of sub-agent patterns in Claude Code, and published a fascinating article on that pattern (my notes on that).
I don't have anything solid to back this up - it's more of a hunch based on anecdotal evidence where various of my requests for a model to write a prompt have returned useful results over the last few months.
gpt-5 and gpt-5-mini rate limit updates. OpenAI have increased the rate limits for their two main GPT-5 models. These look significant:
gpt-5
Tier 1: 30K → 500K TPM (1.5M batch)
Tier 2: 450K → 1M (3M batch)
Tier 3: 800K → 2M
Tier 4: 2M → 4Mgpt-5-mini
Tier 1: 200K → 500K (5M batch)
GPT-5 rate limits here show tier 5 stays at 40M tokens per minute. The GPT-5 mini rate limits for tiers 2 through 5 are 2M, 4M, 10M and 180M TPM respectively.
As a reminder, those tiers are assigned based on how much money you have spent on the OpenAI API - from $5 for tier 1 up through $50, $100, $250 and then $1,000 for tier
For comparison, Anthropic's current top tier is Tier 4 ($400 spent) which provides 2M maximum input tokens per minute and 400,000 maximum output tokens, though you can contact their sales team for higher limits than that.
Gemini's top tier is Tier 3 for $1,000 spent and currently gives you 8M TPM for Gemini 2.5 Pro and Flash and 30M TPM for the Flash-Lite and 2.0 Flash models.
So OpenAI's new rate limit increases for their top performing model pulls them ahead of Anthropic but still leaves them significantly behind Gemini.
GPT-5 mini remains the champion for smaller models with that enormous 180M TPS limit for its top tier.
Recreating the Apollo AI adoption rate chart with GPT-5, Python and Pyodide
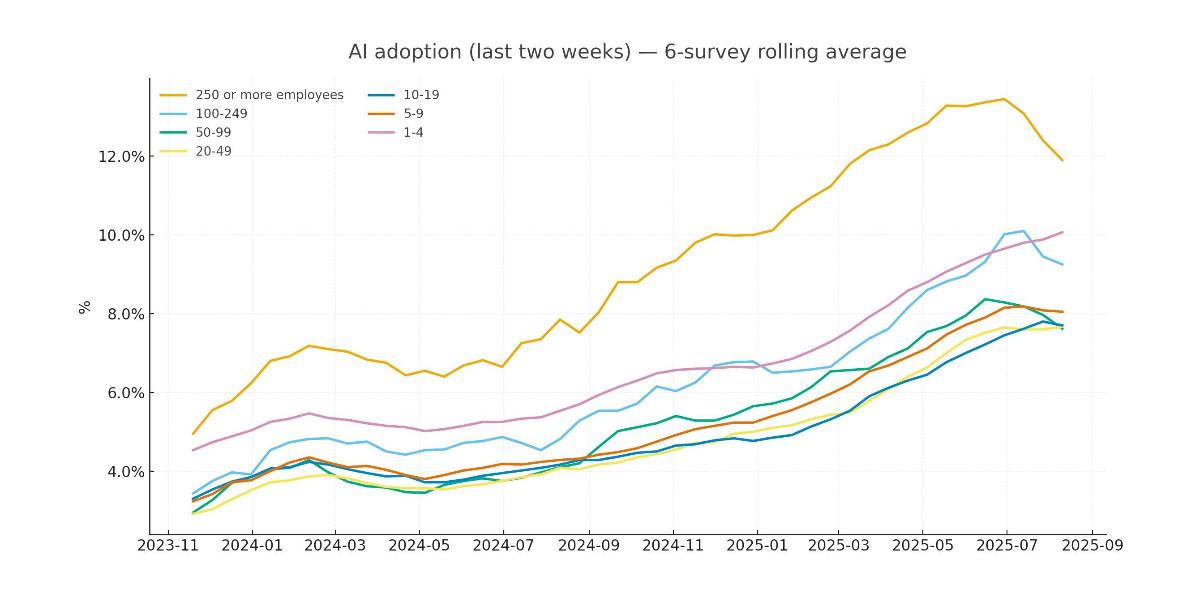
Apollo Global Management’s “Chief Economist” Dr. Torsten Sløk released this interesting chart which appears to show a slowdown in AI adoption rates among large (>250 employees) companies:
[... 2,673 words]Anthropic status: Model output quality (via) Anthropic previously reported model serving bugs that affected Claude Opus 4 and 4.1 for 56.5 hours. They've now fixed additional bugs affecting "a small percentage" of Sonnet 4 requests for almost a month, plus a less long-lived Haiku 3.5 issue:
Resolved issue 1 - A small percentage of Claude Sonnet 4 requests experienced degraded output quality due to a bug from Aug 5-Sep 4, with the impact increasing from Aug 29-Sep 4. A fix has been rolled out and this incident has been resolved.
Resolved issue 2 - A separate bug affected output quality for some Claude Haiku 3.5 and Claude Sonnet 4 requests from Aug 26-Sep 5. A fix has been rolled out and this incident has been resolved.
They directly address accusations that these stem from deliberate attempts to save money on serving models:
Importantly, we never intentionally degrade model quality as a result of demand or other factors, and the issues mentioned above stem from unrelated bugs.
The timing of these issues is really unfortunate, corresponding with the rollout of GPT-5 which I see as the non-Anthropic model to feel truly competitive with Claude for writing code since their release of Claude 3.5 back in June last year.
Load Llama-3.2 WebGPU in your browser from a local folder (via) Inspired by a comment on Hacker News I decided to see if it was possible to modify the transformers.js-examples/tree/main/llama-3.2-webgpu Llama 3.2 chat demo (online here, I wrote about it last November) to add an option to open a local model file directly from a folder on disk, rather than waiting for it to download over the network.
I posed the problem to OpenAI's GPT-5-enabled Codex CLI like this:
git clone https://github.com/huggingface/transformers.js-examples
cd transformers.js-examples/llama-3.2-webgpu
codex
Then this prompt:
Modify this application such that it offers the user a file browse button for selecting their own local copy of the model file instead of loading it over the network. Provide a "download model" option too.
Codex churned away for several minutes, even running commands like curl -sL https://raw.githubusercontent.com/huggingface/transformers.js/main/src/models.js | sed -n '1,200p' to inspect the source code of the underlying Transformers.js library.
After four prompts total (shown here) it built something which worked!
To try it out you'll need your own local copy of the Llama 3.2 ONNX model. You can get that (a ~1.2GB) download) like so:
git lfs install
git clone https://huggingface.co/onnx-community/Llama-3.2-1B-Instruct-q4f16
Then visit my llama-3.2-webgpu page in Chrome or Firefox Nightly (since WebGPU is required), click "Browse folder", select that folder you just cloned, agree to the "Upload" confirmation (confusing since nothing is uploaded from your browser, the model file is opened locally on your machine) and click "Load local model".
Here's an animated demo (recorded in real-time, I didn't speed this up):
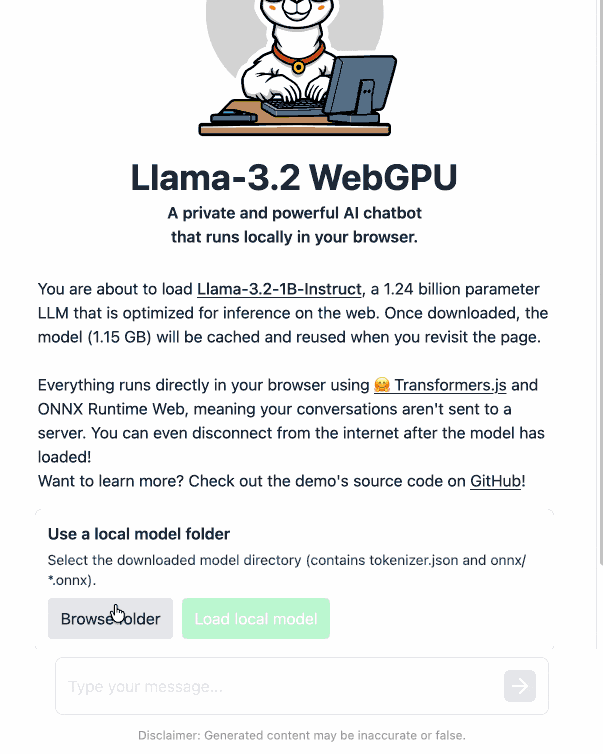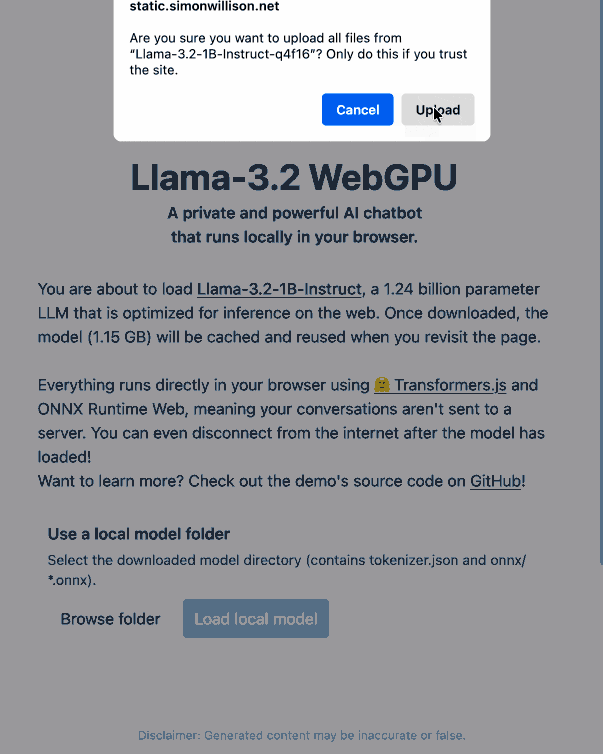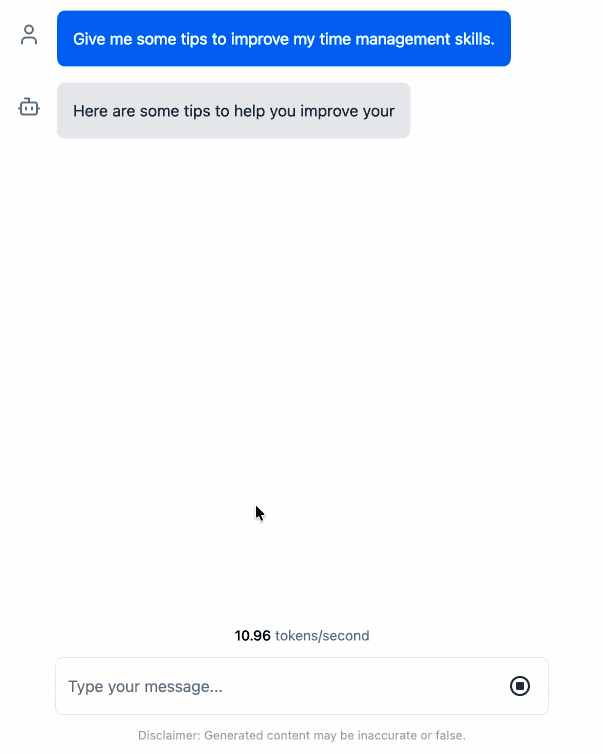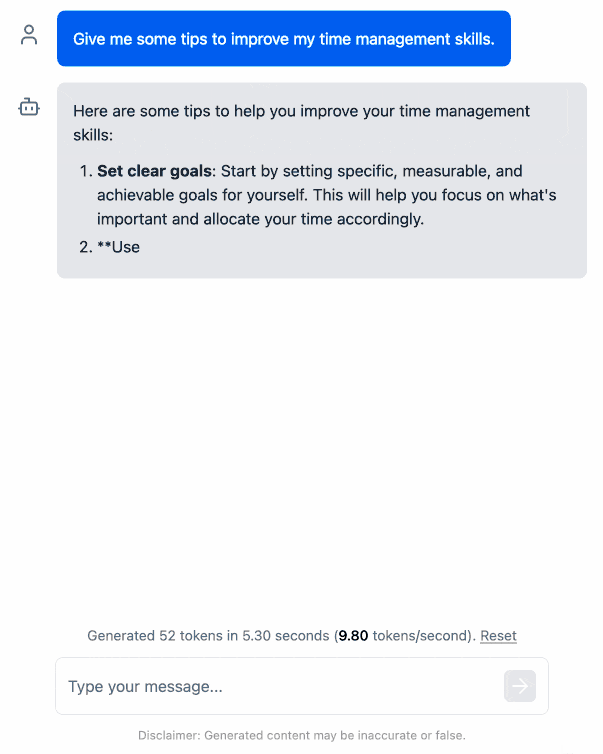
I pushed a branch with those changes here. The next step would be to modify this to support other models in addition to the Llama 3.2 demo, but I'm pleased to have got to this proof of concept with so little work beyond throwing some prompts at Codex to see if it could figure it out.
According to the Codex /status command this used 169,818 input tokens, 17,112 output tokens and 1,176,320 cached input tokens. At current GPT-5 token pricing ($1.25/million input, $0.125/million cached input, $10/million output) that would cost 53.942 cents, but Codex CLI hooks into my existing $20/month ChatGPT Plus plan so this was bundled into that.
GPT-5 Thinking in ChatGPT (aka Research Goblin) is shockingly good at search

“Don’t use chatbots as search engines” was great advice for several years... until it wasn’t.
[... 2,679 words]Rich Pixels. Neat Python library by Darren Burns adding pixel image support to the Rich terminal library, using tricks to render an image using full or half-height colored blocks.
Here's the key trick - it renders Unicode ▄ (U+2584, "lower half block") characters after setting a foreground and background color for the two pixels it needs to display.
I got GPT-5 to vibe code up a show_image.py terminal command which resizes the provided image to fit the width and height of the current terminal and displays it using Rich Pixels. That script is here, you can run it with uv like this:
uv run https://tools.simonwillison.net/python/show_image.py \
image.jpg
Here's what I got when I ran it against my V&A East Storehouse photo from this post:
![]()
The perils of vibe coding. I was interviewed by Elaine Moore for this opinion piece in the Financial Times, which ended up in the print edition of the paper too! I picked up a copy yesterday:
![The perils of vibe coding - A new OpenAI model arrived this month with a glossy livestream, group watch parties and a lingering sense of disappointment. The YouTube comment section was underwhelmed. “I think they are all starting to realize this isn’t going to become the world like they thought it would,” wrote one viewer. “I can see it on their faces.” But if the casual user was unimpressed, the AI model’s saving grace may be vibe. Coding is generative AI’s newest battleground. With big bills to pay, high valuations to live up to and a market wobble to erase, the sector needs to prove its corporate productivity chops. Coding is hardly promoted as a business use case that already works. For one thing, AI-generated code holds the promise of replacing programmers — a profession of very well paid people. For another, the work can be quantified. In April, Microsoft chief executive Satya Nadella said that up to 50 per cent of the company’s code was now being written by AI. Google chief executive Sundar Pichai has said the same thing. Salesforce has paused engineering hires and Mark Zuckerberg told podcaster Joe Rogan that Meta would use AI as a “mid-level engineer” that writes code. Meanwhile, start-ups such as Replit and Cursor’s Anysphere are trying to persuade people that with AI, anyone can code. In theory, every employee can become a software engineer. So why aren’t we? One possibility is that it’s all still too unfamiliar. But when I ask people who write code for a living they offer an alternative suggestion: unpredictability. As programmer Simon Willison put it: “A lot of people are missing how weird and funny this space is. I’ve been a computer programmer for 30 years and [AI models] don’t behave like normal computers.” Willison is well known in the software engineering community for his AI experiments. He’s an enthusiastic vibe coder — using LLMs to generate code using natural language prompts. OpenAI’s latest model GPT-3.1s, he is now favourite. Still, he predicts that a vibe coding crash is due if it is used to produce glitchy software. It makes sense that programmers — people who are interested in finding new ways to solve problems — would be early adopters of LLMs. Code is a language, albeit an abstract one. And generative AI is trained in nearly all of them, including older ones like Cobol. That doesn’t mean they accept all of its suggestions. Willison thinks the best way to see what a new model can do is to ask for something unusual. He likes to request an svg (an image made out of lines described with code) of a pelican on a bike and asks it to remember the chickens in his garden by name. Results can be bizarre. One model ignored key prompts in favour of composing a poem. Still, his adventures in vibe coding sound like an advert for the sector’s future. Anthropic’s Claude Code, the favoured model for developers, to make an OCR (optical character recognition) software loves screenshots) tool that will copy and paste text from a screenshot. He wrote software that summarises blog comments and has planned to cut a custom tool that will alert him when a whale is visible from his Pacific coast home. All this by typing prompts in English. It’s sounds like the sort of thing Bill Gates might have had in mind when he wrote that natural language AI agents would bring about “the biggest revolution in computing since we went from typing commands to tapping on icons”. But watching code appear and know how it works are two different things. My efforts to make my own comment summary tool produced something unworkable that gave overly long answers and then congratulated itself as a success. Willison says he wouldn’t use AI-generated code for projects he planned to ship out unless he had reviewed each line. Not only is there the risk of hallucination but the chatbot’s desire to be agreeable means it may an unusable idea works. That is a particular issue for those of us who don’t know how to fix the code. We risk creating software with hidden problems. It may not save time either. A study published in July by the non-profit Model Evaluation and Threat Research assessed work done by 16 developers — some with AI tools, some without. Those using AI assistance it had made them faster. In fact it took them nearly a fifth longer. Several developers I spoke to said AI was best used as a way to talk through coding problems. It’s a version of something they call rubber ducking (after their habit of talking to the toys on their desk) — only this rubber duck can talk back. As one put it, code shouldn’t be judged by volume or speed. Progress in AI coding is tangible. But measuring productivity gains is not as neat as a simple percentage calculation.](https://static.simonwillison.net/static/2025/ft.jpeg)
From the article, with links added by me to relevant projects:
Willison thinks the best way to see what a new model can do is to ask for something unusual. He likes to request an SVG (an image made out of lines described with code) of a pelican on a bike and asks it to remember the chickens in his garden by name. Results can be bizarre. One model ignored his prompts in favour of composing a poem.
Still, his adventures in vibe coding sound like an advert for the sector. He used Anthropic's Claude Code, the favoured model for developers, to make an OCR (optical character recognition - software loves acronyms) tool that will copy and paste text from a screenshot.
He wrote software that summarises blog comments and has plans to build a custom tool that will alert him when a whale is visible from his Pacific coast home. All this by typing prompts in English.
I've been talking about that whale spotting project for far too long. Now that it's been in the FT I really need to build it.
(On the subject of OCR... I tried extracting the text from the above image using GPT-5 and got a surprisingly bad result full of hallucinated details. Claude Opus 4.1 did a lot better but still made some mistakes. Gemini 2.5 did much better.)
GPT-5 has a hidden system prompt. It looks like GPT-5 when accessed via the OpenAI API may have its own hidden system prompt, independent from the system prompt you can specify in an API call.
At the very least it's getting sent the current date. I tried this just now:
llm -m gpt-5 'current date'
That returned "2025-08-15", confirming that the date has been fed to the model as part of a hidden prompt.
llm -m gpt-5 'current date' --system 'speak french'
Returned "La date actuelle est le 15 août 2025", showing that offering my own custom system prompt did not over-ride the invisible one that includes the date.
GPT-5 is very resistant to sharing the details of this secret system prompt, but Tommy Hughes managed to extract the following:
Current date: 2025-08-15
You are an AI assistant accessed via an API. Your output may need to be parsed by code or displayed
# Desired oververbosity for the final answer (not analysis): 3
An oververbosity of 1 means the model should respond using only the minimal content necessary to satisfy the request, using concise phrasing and avoiding extra detail or explanation.
An oververbosity of 10 means the model should provide maximally detailed, thorough responses with context, explanations, and possibly multiple examples.
The desired oververbosity should be treated only as a *default*. Defer to any user or developer requirements regarding response length, if present.
# Valid channels: analysis, commentary, final. Channel must be included for every message.
# Juice: 64
I've not been able to confirm this myself, but a search for "desired oververbosity" on GitHub shows that a similar prompt has leaked from ChatGPT (including for o3) in the past. I suspect Tommy's leaked prompt is accurate here.
I tried asking GPT-5 about "oververbosity" via its API:
llm -m gpt-5 'explain your oververbosity settings, what is it right now?'
And got back:
- What it is: I adjust how detailed I am based on a “verbosity” level—ranging from very brief to very detailed—so answers fit your needs.
- Current setting: Concise (about 3/10). I prioritize direct answers with minimal extra context and keep explanations short unless you ask for more.
- How to change it: Just say what you want, e.g.:
- “One-sentence answer” or “TL;DR” (very brief)
- “Give a concise summary” (short bullets)
- “Walk me through in detail,” “Deep dive,” or “Include examples/edge cases” (more detailed)
- Note: For ambiguous, technical, or safety-critical topics, I may add brief clarifications even when being concise.
Presumably this is part of OpenAI's instruction hierarchy concept, with these instructions taking precedence over the developer instructions provided by API users (my --system 'speak french' option above).
I'd very much appreciate official documentation that describes this! As an API user I want to know everything that is being fed into the model - I would be much more comfortable with a hidden prompt like this if I knew exactly what was in it.
LLM 0.27, the annotated release notes: GPT-5 and improved tool calling
I shipped LLM 0.27 today (followed by a 0.27.1 with minor bug fixes), adding support for the new GPT-5 family of models from OpenAI plus a flurry of improvements to the tool calling features introduced in LLM 0.26. Here are the annotated release notes.
[... 1,174 words]If you've been experimenting with OpenAI's Codex CLI and have been frustrated that it's not possible to select text and copy it to the clipboard, at least when running in the Mac terminal (I genuinely didn't know it was possible to build a terminal app that disabled copy and paste) you should know that they fixed that in this issue last week.
The new 0.20.0 version from three days ago also completely removes the old TypeScript codebase in favor of Rust. Even installations via NPM now get the Rust version.
I originally installed Codex via Homebrew, so I had to run this command to get the updated version:
brew upgrade codex
Another Codex tip: to use GPT-5 (or any other specific OpenAI model) you can run it like this:
export OPENAI_DEFAULT_MODEL="gpt-5"
codex
This no longer works, see update below.
I've been using a codex-5 script on my PATH containing this, because sometimes I like to live dangerously!
#!/usr/bin/env zsh
# Usage: codex-5 [additional args passed to `codex`]
export OPENAI_DEFAULT_MODEL="gpt-5"
exec codex --dangerously-bypass-approvals-and-sandbox "$@"
Update: It looks like GPT-5 is the default model in v0.20.0 already.
Also the environment variable I was using no longer does anything, it was removed in this commit (I used Codex Web to help figure that out). You can use the -m model_id command-line option instead.
the percentage of users using reasoning models each day is significantly increasing; for example, for free users we went from <1% to 7%, and for plus users from 7% to 24%.
— Sam Altman, revealing quite how few people used the old model picker to upgrade from GPT-4o
The issue with GPT-5 in a nutshell is that unless you pay for model switching & know to use GPT-5 Thinking or Pro, when you ask “GPT-5” you sometimes get the best available AI & sometimes get one of the worst AIs available and it might even switch within a single conversation.
— Ethan Mollick, highlighting that GPT-5 (high) ranks top on Artificial Analysis, GPT-5 (minimal) ranks lower than GPT-4.1
GPT-5 rollout updates:
- We are going to double GPT-5 rate limits for ChatGPT Plus users as we finish rollout.
- We will let Plus users choose to continue to use 4o. We will watch usage as we think about how long to offer legacy models for.
- GPT-5 will seem smarter starting today. Yesterday, the autoswitcher broke and was out of commission for a chunk of the day, and the result was GPT-5 seemed way dumber. Also, we are making some interventions to how the decision boundary works that should help you get the right model more often.
- We will make it more transparent about which model is answering a given query.
- We will change the UI to make it easier to manually trigger thinking.
- Rolling out to everyone is taking a bit longer. It’s a massive change at big scale. For example, our API traffic has about doubled over the past 24 hours…
We will continue to work to get things stable and will keep listening to feedback. As we mentioned, we expected some bumpiness as we roll out so many things at once. But it was a little more bumpy than we hoped for!
The surprise deprecation of GPT-4o for ChatGPT consumers
I’ve been dipping into the r/ChatGPT subreddit recently to see how people are reacting to the GPT-5 launch, and so far the vibes there are not good. This AMA thread with the OpenAI team is a great illustration of the single biggest complaint: a lot of people are very unhappy to lose access to the much older GPT-4o, previously ChatGPT’s default model for most users.
[... 933 words]A couple of weeks ago I was invited to OpenAI's headquarters for a "preview event", for which I had to sign both an NDA and a video release waiver. I suspected it might relate to either GPT-5 or the OpenAI open weight models... and GPT-5 it was!
OpenAI had invited five developers: Claire Vo, Theo Browne, Ben Hylak, Shawn @swyx Wang, and myself. We were all given early access to the new models and asked to spend a couple of hours (of paid time, see my disclosures) experimenting with them, while being filmed by a professional camera crew.
The resulting video is now up on YouTube. Unsurprisingly most of my edits related to SVGs of pelicans.
GPT-5: Key characteristics, pricing and model card

I’ve had preview access to the new GPT-5 model family for the past two weeks (see related video and my disclosures) and have been using GPT-5 as my daily-driver. It’s my new favorite model. It’s still an LLM—it’s not a dramatic departure from what we’ve had before—but it rarely screws up and generally feels competent or occasionally impressive at the kinds of things I like to use models for.
[... 2,448 words]