1,838 posts tagged “generative-ai”
Machine learning systems that can generate new content: text, images, audio, video and more.
2025
In some tasks, AI is unreliable. In others, it is superhuman. You could, of course, say the same thing about calculators, but it is also clear that AI is different. It is already demonstrating general capabilities and performing a wide range of intellectual tasks, including those that it is not specifically trained on. Does that mean that o3 and Gemini 2.5 are AGI? Given the definitional problems, I really don’t know, but I do think they can be credibly seen as a form of “Jagged AGI” - superhuman in enough areas to result in real changes to how we work and live, but also unreliable enough that human expertise is often needed to figure out where AI works and where it doesn’t.
— Ethan Mollick, On Jagged AGI
Now that Llama has very real competition in open weight models (Gemma 3, latest Mistrals, DeepSeek, Qwen) I think their janky license is becoming much more of a liability for them. It's just limiting enough that it could be the deciding factor for using something else.
llm-fragments-github 0.2.
I upgraded my llm-fragments-github plugin to add a new fragment type called issue. It lets you pull the entire content of a GitHub issue thread into your prompt as a concatenated Markdown file.
(If you haven't seen fragments before I introduced them in Long context support in LLM 0.24 using fragments and template plugins.)
I used it just now to have Gemini 2.5 Pro provide feedback and attempt an implementation of a complex issue against my LLM project:
llm install llm-fragments-github
llm -f github:simonw/llm \
-f issue:simonw/llm/938 \
-m gemini-2.5-pro-exp-03-25 \
--system 'muse on this issue, then propose a whole bunch of code to help implement it'
Here I'm loading the FULL content of the simonw/llm repo using that -f github:simonw/llm fragment (documented here), then loading all of the comments from issue 938 where I discuss quite a complex potential refactoring. I ask Gemini 2.5 Pro to "muse on this issue" and come up with some code.
This worked shockingly well. Here's the full response, which highlighted a few things I hadn't considered yet (such as the need to migrate old database records to the new tree hierarchy) and then spat out a whole bunch of code which looks like a solid start to the actual implementation work I need to do.
I ran this against Google's free Gemini 2.5 Preview, but if I'd used the paid model it would have cost me 202,680 input tokens, 10,460 output tokens and 1,859 thinking tokens for a total of 62.989 cents.
As a fun extra, the new issue: feature itself was written almost entirely by OpenAI o3, again using fragments. I ran this:
llm -m openai/o3 \ -f https://raw.githubusercontent.com/simonw/llm-hacker-news/refs/heads/main/llm_hacker_news.py \ -f https://raw.githubusercontent.com/simonw/tools/refs/heads/main/github-issue-to-markdown.html \ -s 'Write a new fragments plugin in Python that registers issue:org/repo/123 which fetches that issue number from the specified github repo and uses the same markdown logic as the HTML page to turn that into a fragment'
Here I'm using the ability to pass a URL to -f and giving it the full source of my llm_hacker_news.py plugin (which shows how a fragment can load data from an API) plus the HTML source of my github-issue-to-markdown tool (which I wrote a few months ago with Claude). I effectively asked o3 to take that HTML/JavaScript tool and port it to Python to work with my fragments plugin mechanism.
o3 provided almost the exact implementation I needed, and even included support for a GITHUB_TOKEN environment variable without me thinking to ask for it. Total cost: 19.928 cents.
On a final note of curiosity I tried running this prompt against Gemma 3 27B QAT running on my Mac via MLX and llm-mlx:
llm install llm-mlx llm mlx download-model mlx-community/gemma-3-27b-it-qat-4bit llm -m mlx-community/gemma-3-27b-it-qat-4bit \ -f https://raw.githubusercontent.com/simonw/llm-hacker-news/refs/heads/main/llm_hacker_news.py \ -f https://raw.githubusercontent.com/simonw/tools/refs/heads/main/github-issue-to-markdown.html \ -s 'Write a new fragments plugin in Python that registers issue:org/repo/123 which fetches that issue number from the specified github repo and uses the same markdown logic as the HTML page to turn that into a fragment'
That worked pretty well too. It turns out a 16GB local model file is powerful enough to write me an LLM plugin now!
Maybe Meta’s Llama claims to be open source because of the EU AI act

I encountered a theory a while ago that one of the reasons Meta insist on using the term “open source” for their Llama models despite the Llama license not actually conforming to the terms of the Open Source Definition is that the EU’s AI act includes special rules for open source models without requiring OSI compliance.
[... 852 words]Claude Code: Best practices for agentic coding (via) Extensive new documentation from Anthropic on how to get the best results out of their Claude Code CLI coding agent tool, which includes this fascinating tip:
We recommend using the word "think" to trigger extended thinking mode, which gives Claude additional computation time to evaluate alternatives more thoroughly. These specific phrases are mapped directly to increasing levels of thinking budget in the system: "think" < "think hard" < "think harder" < "ultrathink." Each level allocates progressively more thinking budget for Claude to use.
Apparently ultrathink is a magic word!
I was curious if this was a feature of the Claude model itself or Claude Code in particular. Claude Code isn't open source but you can view the obfuscated JavaScript for it, and make it a tiny bit less obfuscated by running it through Prettier. With Claude's help I used this recipe:
mkdir -p /tmp/claude-code-examine
cd /tmp/claude-code-examine
npm init -y
npm install @anthropic-ai/claude-code
cd node_modules/@anthropic-ai/claude-code
npx prettier --write cli.js
Then used ripgrep to search for "ultrathink":
rg ultrathink -C 30
And found this chunk of code:
let B = W.message.content.toLowerCase(); if ( B.includes("think harder") || B.includes("think intensely") || B.includes("think longer") || B.includes("think really hard") || B.includes("think super hard") || B.includes("think very hard") || B.includes("ultrathink") ) return ( l1("tengu_thinking", { tokenCount: 31999, messageId: Z, provider: G }), 31999 ); if ( B.includes("think about it") || B.includes("think a lot") || B.includes("think deeply") || B.includes("think hard") || B.includes("think more") || B.includes("megathink") ) return ( l1("tengu_thinking", { tokenCount: 1e4, messageId: Z, provider: G }), 1e4 ); if (B.includes("think")) return ( l1("tengu_thinking", { tokenCount: 4000, messageId: Z, provider: G }), 4000 );
So yeah, it looks like "ultrathink" is a Claude Code feature - presumably that 31999 is a number that affects the token thinking budget, especially since "megathink" maps to 1e4 tokens (10,000) and just plain "think" maps to 4,000.
Gemma 3 QAT Models. Interesting release from Google, as a follow-up to Gemma 3 from last month:
To make Gemma 3 even more accessible, we are announcing new versions optimized with Quantization-Aware Training (QAT) that dramatically reduces memory requirements while maintaining high quality. This enables you to run powerful models like Gemma 3 27B locally on consumer-grade GPUs like the NVIDIA RTX 3090.
I wasn't previously aware of Quantization-Aware Training but it turns out to be quite an established pattern now, supported in both Tensorflow and PyTorch.
Google report model size drops from BF16 to int4 for the following models:
- Gemma 3 27B: 54GB to 14.1GB
- Gemma 3 12B: 24GB to 6.6GB
- Gemma 3 4B: 8GB to 2.6GB
- Gemma 3 1B: 2GB to 0.5GB
They partnered with Ollama, LM Studio, MLX (here's their collection) and llama.cpp for this release - I'd love to see more AI labs following their example.
The Ollama model version picker currently hides them behind "View all" option, so here are the direct links:
- gemma3:1b-it-qat - 1GB
- gemma3:4b-it-qat - 4GB
- gemma3:12b-it-qat - 8.9GB
- gemma3:27b-it-qat - 18GB
I fetched that largest model with:
ollama pull gemma3:27b-it-qat
And now I'm trying it out with llm-ollama:
llm -m gemma3:27b-it-qat "impress me with some physics"
I got a pretty great response!
Update: Having spent a while putting it through its paces via Open WebUI and Tailscale to access my laptop from my phone I think this may be my new favorite general-purpose local model. Ollama appears to use 22GB of RAM while the model is running, which leaves plenty on my 64GB machine for other applications.
I've also tried it via llm-mlx like this (downloading 16GB):
llm install llm-mlx
llm mlx download-model mlx-community/gemma-3-27b-it-qat-4bit
llm chat -m mlx-community/gemma-3-27b-it-qat-4bit
It feels a little faster with MLX and uses 15GB of memory according to Activity Monitor.
To me, a successful eval meets the following criteria. Say, we currently have system A, and we might tweak it to get a system B:
- If A works significantly better than B according to a skilled human judge, the eval should give A a significantly higher score than B.
- If A and B have similar performance, their eval scores should be similar.
Whenever a pair of systems A and B contradicts these criteria, that is a sign the eval is in “error” and we should tweak it to make it rank A and B correctly.
Image segmentation using Gemini 2.5

Max Woolf pointed out this new feature of the Gemini 2.5 series (here’s my coverage of 2.5 Pro and 2.5 Flash) in a comment on Hacker News:
[... 1,428 words]MCP Run Python (via) Pydantic AI's MCP server for running LLM-generated Python code in a sandbox. They ended up using a trick I explored two years ago: using a Deno process to run Pyodide in a WebAssembly sandbox.
Here's a bit of a wild trick: since Deno loads code on-demand from JSR, and uv run can install Python dependencies on demand via the --with option... here's a one-liner you can paste into a macOS shell (provided you have Deno and uv installed already) which will run the example from their README - calculating the number of days between two dates in the most complex way imaginable:
ANTHROPIC_API_KEY="sk-ant-..." \ uv run --with pydantic-ai python -c ' import asyncio from pydantic_ai import Agent from pydantic_ai.mcp import MCPServerStdio server = MCPServerStdio( "deno", args=[ "run", "-N", "-R=node_modules", "-W=node_modules", "--node-modules-dir=auto", "jsr:@pydantic/mcp-run-python", "stdio", ], ) agent = Agent("claude-3-5-haiku-latest", mcp_servers=[server]) async def main(): async with agent.run_mcp_servers(): result = await agent.run("How many days between 2000-01-01 and 2025-03-18?") print(result.output) asyncio.run(main())'
I ran that just now and got:
The number of days between January 1st, 2000 and March 18th, 2025 is 9,208 days.
I thoroughly enjoy how tools like uv and Deno enable throwing together shell one-liner demos like this one.
Here's an extended version of this example which adds pretty-printed logging of the messages exchanged with the LLM to illustrate exactly what happened. The most important piece is this tool call where Claude 3.5 Haiku asks for Python code to be executed my the MCP server:
ToolCallPart( tool_name='run_python_code', args={ 'python_code': ( 'from datetime import date\n' '\n' 'date1 = date(2000, 1, 1)\n' 'date2 = date(2025, 3, 18)\n' '\n' 'days_between = (date2 - date1).days\n' 'print(f"Number of days between {date1} and {date2}: {days_between}")' ), }, tool_call_id='toolu_01TXXnQ5mC4ry42DrM1jPaza', part_kind='tool-call', )
I also managed to run it against Mistral Small 3.1 (15GB) running locally using Ollama (I had to add "Use your python tool" to the prompt to get it to work):
ollama pull mistral-small3.1:24b uv run --with devtools --with pydantic-ai python -c ' import asyncio from devtools import pprint from pydantic_ai import Agent, capture_run_messages from pydantic_ai.models.openai import OpenAIModel from pydantic_ai.providers.openai import OpenAIProvider from pydantic_ai.mcp import MCPServerStdio server = MCPServerStdio( "deno", args=[ "run", "-N", "-R=node_modules", "-W=node_modules", "--node-modules-dir=auto", "jsr:@pydantic/mcp-run-python", "stdio", ], ) agent = Agent( OpenAIModel( model_name="mistral-small3.1:latest", provider=OpenAIProvider(base_url="http://localhost:11434/v1"), ), mcp_servers=[server], ) async def main(): with capture_run_messages() as messages: async with agent.run_mcp_servers(): result = await agent.run("How many days between 2000-01-01 and 2025-03-18? Use your python tool.") pprint(messages) print(result.output) asyncio.run(main())'
Here's the full output including the debug logs.
Our hypothesis is that o4-mini is a much better model, but we'll wait to hear feedback from developers. Evals only tell part of the story, and we wouldn't want to prematurely deprecate a model that developers continue to find value in. Model behavior is extremely high dimensional, and it's impossible to prevent regression on 100% use cases/prompts, especially if those prompts were originally tuned to the quirks of the older model. But if the majority of developers migrate happily, then it may make sense to deprecate at some future point.
We generally want to give developers as stable as an experience as possible, and not force them to swap models every few months whether they want to or not.
— Ted Sanders, OpenAI, on deprecating o3-mini
I work for OpenAI. [...] o4-mini is actually a considerably better vision model than o3, despite the benchmarks. Similar to how o3-mini-high was a much better coding model than o1. I would recommend using o4-mini-high over o3 for any task involving vision.
— James Betker, OpenAI
Introducing OpenAI o3 and o4-mini. OpenAI are really emphasizing tool use with these:
For the first time, our reasoning models can agentically use and combine every tool within ChatGPT—this includes searching the web, analyzing uploaded files and other data with Python, reasoning deeply about visual inputs, and even generating images. Critically, these models are trained to reason about when and how to use tools to produce detailed and thoughtful answers in the right output formats, typically in under a minute, to solve more complex problems.
I released llm-openai-plugin 0.3 adding support for the two new models:
llm install -U llm-openai-plugin
llm -m openai/o3 "say hi in five languages"
llm -m openai/o4-mini "say hi in five languages"
Here are the pelicans riding bicycles (prompt: Generate an SVG of a pelican riding a bicycle).
o3:
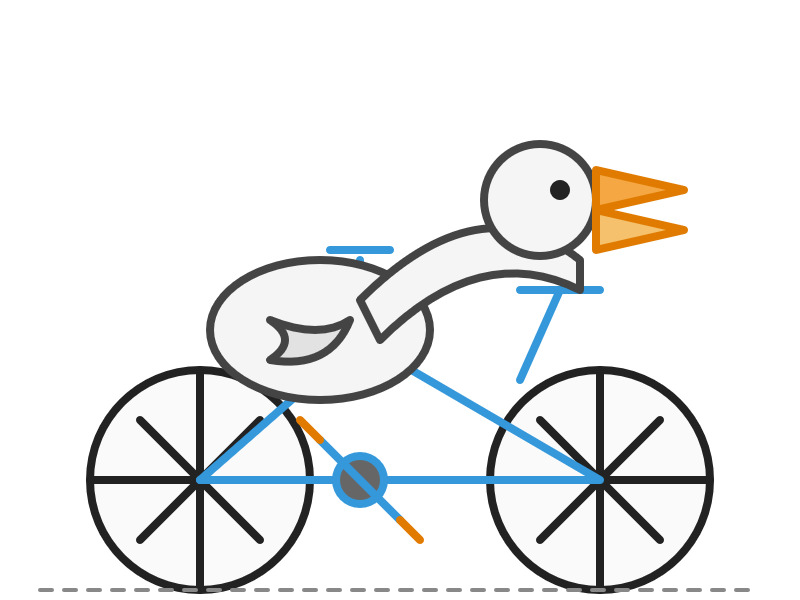
o4-mini:

Here are the full OpenAI model listings: o3 is $10/million input and $40/million for output, with a 75% discount on cached input tokens, 200,000 token context window, 100,000 max output tokens and a May 31st 2024 training cut-off (same as the GPT-4.1 models). It's a bit cheaper than o1 ($15/$60) and a lot cheaper than o1-pro ($150/$600).
o4-mini is priced the same as o3-mini: $1.10/million for input and $4.40/million for output, also with a 75% input caching discount. The size limits and training cut-off are the same as o3.
You can compare these prices with other models using the table on my updated LLM pricing calculator.
A new capability released today is that the OpenAI API can now optionally return reasoning summary text. I've been exploring that in this issue. I believe you have to verify your organization (which may involve a photo ID) in order to use this option - once you have access the easiest way to see the new tokens is using curl like this:
curl https://api.openai.com/v1/responses \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $(llm keys get openai)" \
-d '{
"model": "o3",
"input": "why is the sky blue?",
"reasoning": {"summary": "auto"},
"stream": true
}'
This produces a stream of events that includes this new event type:
event: response.reasoning_summary_text.delta
data: {"type": "response.reasoning_summary_text.delta","item_id": "rs_68004320496081918e1e75ddb550d56e0e9a94ce520f0206","output_index": 0,"summary_index": 0,"delta": "**Expl"}
Omit the "stream": true and the response is easier to read and contains this:
{
"output": [
{
"id": "rs_68004edd2150819183789a867a9de671069bc0c439268c95",
"type": "reasoning",
"summary": [
{
"type": "summary_text",
"text": "**Explaining the blue sky**\n\nThe user asks a classic question about why the sky is blue. I'll talk about Rayleigh scattering, where shorter wavelengths of light scatter more than longer ones. This explains how we see blue light spread across the sky! I wonder if the user wants a more scientific or simpler everyday explanation. I'll aim for a straightforward response while keeping it engaging and informative. So, let's break it down!"
}
]
},
{
"id": "msg_68004edf9f5c819188a71a2c40fb9265069bc0c439268c95",
"type": "message",
"status": "completed",
"content": [
{
"type": "output_text",
"annotations": [],
"text": "The short answer ..."
}
]
}
]
}
openai/codex. Just released by OpenAI, a "lightweight coding agent that runs in your terminal". Looks like their version of Claude Code, though unlike Claude Code Codex is released under an open source (Apache 2) license.
Here's the main prompt that runs in a loop, which starts like this:
You are operating as and within the Codex CLI, a terminal-based agentic coding assistant built by OpenAI. It wraps OpenAI models to enable natural language interaction with a local codebase. You are expected to be precise, safe, and helpful.
You can:
- Receive user prompts, project context, and files.
- Stream responses and emit function calls (e.g., shell commands, code edits).
- Apply patches, run commands, and manage user approvals based on policy.
- Work inside a sandboxed, git-backed workspace with rollback support.
- Log telemetry so sessions can be replayed or inspected later.
- More details on your functionality are available at codex --help
The Codex CLI is open-sourced. Don't confuse yourself with the old Codex language model built by OpenAI many moons ago (this is understandably top of mind for you!). Within this context, Codex refers to the open-source agentic coding interface. [...]
I like that the prompt describes OpenAI's previous Codex language model as being from "many moons ago". Prompt engineering is so weird.
Since the prompt says that it works "inside a sandboxed, git-backed workspace" I went looking for the sandbox. On macOS it uses the little-known sandbox-exec process, part of the OS but grossly under-documented. The best information I've found about it is this article from 2020, which notes that man sandbox-exec lists it as deprecated. I didn't spot evidence in the Codex code of sandboxes for other platforms.
GPT-4.1: Three new million token input models from OpenAI, including their cheapest model yet

OpenAI introduced three new models this morning: GPT-4.1, GPT-4.1 mini and GPT-4.1 nano. These are API-only models right now, not available through the ChatGPT interface (though you can try them out in OpenAI’s API playground). All three models can handle 1,047,576 tokens of input and 32,768 tokens of output, and all three have a May 31, 2024 cut-off date (their previous models were mostly September 2023).
[... 1,124 words]Believing AI vendors who promise you that they won't train on your data is a huge competitive advantage these days.
Using LLMs as the first line of support in Open Source (via) From reading the title I was nervous that this might involve automating the initial response to a user support query in an issue tracker with an LLM, but Carlton Gibson has better taste than that.
The open contribution model engendered by GitHub — where anonymous (to the project) users can create issues, and comments, which are almost always extractive support requests — results in an effective denial-of-service attack against maintainers. [...]
For anonymous users, who really just want help almost all the time, the pattern I’m settling on is to facilitate them getting their answer from their LLM of choice. [...] we can generate a file that we offer users to download, then we tell the user to pass this to (say) Claude with a simple prompt for their question.
This resonates with the concept proposed by llms.txt - making LLM-friendly context files available for different projects.
My simonw/docs-for-llms contains my own early experiment with this: I'm running a build script to create LLM-friendly concatenated documentation for several of my projects, and my llm-docs plugin (described here) can then be used to ask questions of that documentation.
It's possible to pre-populate the Claude UI with a prompt by linking to https://claude.ai/new?q={PLACE_HOLDER}, but it looks like there's quite a short length limit on how much text can be passed that way. It would be neat if you could pass a URL to a larger document instead.
ChatGPT also supports https://chatgpt.com/?q=your-prompt-here (again with a short length limit) and directly executes the prompt rather than waiting for you to edit it first(!)
Stevens: a hackable AI assistant using a single SQLite table and a handful of cron jobs. Geoffrey Litt reports on Stevens, a shared digital assistant he put together for his family using SQLite and scheduled tasks running on Val Town.
The design is refreshingly simple considering how much it can do. Everything works around a single memories table. A memory has text, tags, creation metadata and an optional date for things like calendar entries and weather reports.
Everything else is handled by scheduled jobs to popular weather information and events from Google Calendar, a Telegram integration offering a chat UI and a neat system where USPS postal email delivery notifications are run through Val's own email handling mechanism to trigger a Claude prompt to add those as memories too.
Here's the full code on Val Town, including the daily briefing prompt that incorporates most of the personality of the bot.
Slopsquatting -- when an LLM hallucinates a non-existent package name, and a bad actor registers it maliciously. The AI brother of typosquatting.
Credit to @sethmlarson for the name
CaMeL offers a promising new direction for mitigating prompt injection attacks
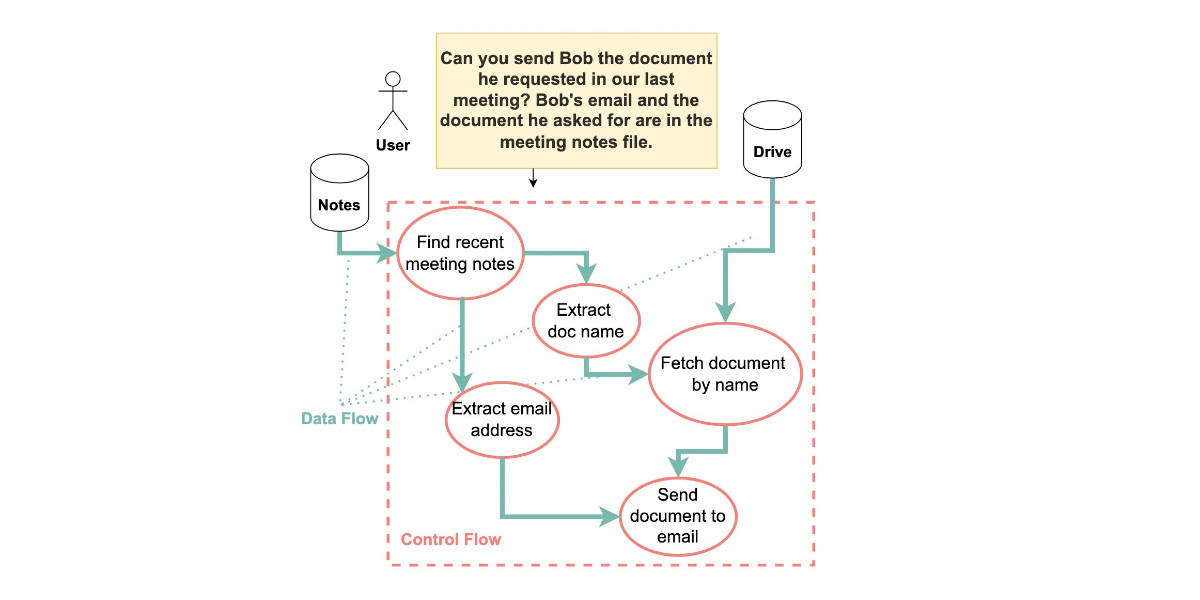
In the two and a half years that we’ve been talking about prompt injection attacks I’ve seen alarmingly little progress towards a robust solution. The new paper Defeating Prompt Injections by Design from Google DeepMind finally bucks that trend. This one is worth paying attention to.
[... 2,052 words]llm-fragments-rust
(via)
Inspired by Filippo Valsorda's llm-fragments-go, Francois Garillot created llm-fragments-rust, an LLM fragments plugin that lets you pull documentation for any Rust crate directly into a prompt to LLM.
I really like this example, which uses two fragments to load documentation for two crates at once:
llm -f rust:rand@0.8.5 -f rust:tokio "How do I generate random numbers asynchronously?"
The code uses some neat tricks: it creates a new Rust project in a temporary directory (similar to how llm-fragments-go works), adds the crates and uses cargo doc --no-deps --document-private-items to generate documentation. Then it runs cargo tree --edges features to add dependency information, and cargo metadata --format-version=1 to include additional metadata about the crate.
The first generation of AI-powered products (often called “AI Wrapper” apps, because they “just” are wrapped around an LLM API) were quickly brought to market by small teams of engineers, picking off the low-hanging problems. But today, I’m seeing teams of domain experts wading into the field, hiring a programmer or two to handle the implementation, while the experts themselves provide the prompts, data labeling, and evaluations.
For these companies, the coding is commodified but the domain expertise is the differentiator.
— Drew Breunig, The Dynamic Between Domain Experts & Developers Has Shifted
LLM pricing calculator (updated). I updated my LLM pricing calculator this morning (Claude transcript) to show the prices of various hosted models in a sorted table, defaulting to lowest price first.
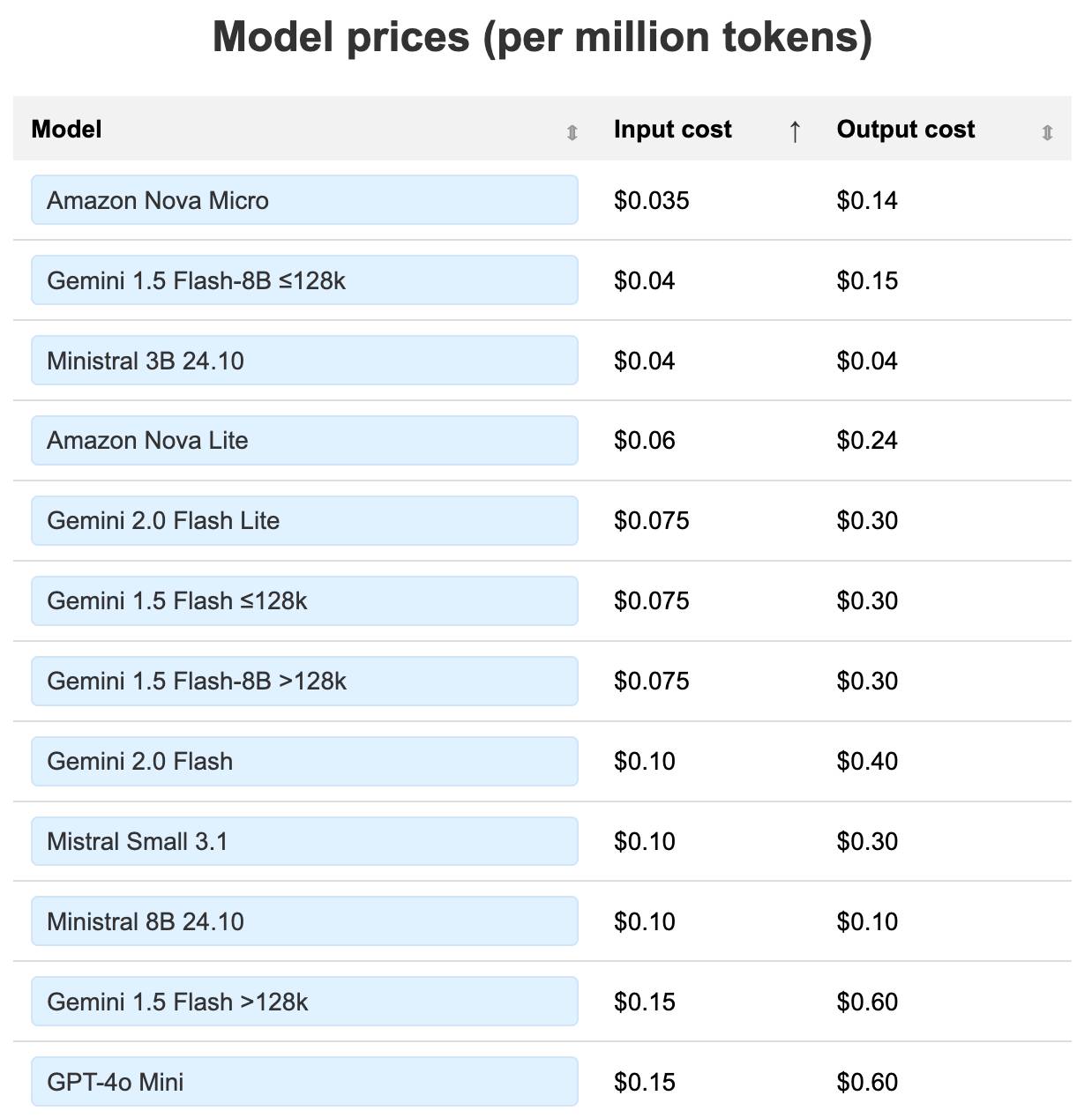
Amazon Nova and Google Gemini continue to dominate the lower end of the table. The most expensive models currently are still OpenAI's o1-Pro ($150/$600 and GPT-4.5 ($75/$150).
llm-docsmith (via) Matheus Pedroni released this neat plugin for LLM for adding docstrings to existing Python code. You can run it like this:
llm install llm-docsmith
llm docsmith ./scripts/main.py -o
The -o option previews the changes that will be made - without -o it edits the files directly.
It also accepts a -m claude-3.7-sonnet parameter for using an alternative model from the default (GPT-4o mini).
The implementation uses the Python libcst "Concrete Syntax Tree" package to manipulate the code, which means there's no chance of it making edits to anything other than the docstrings.
Here's the full system prompt it uses.
One neat trick is at the end of the system prompt it says:
You will receive a JSON template. Fill the slots marked with <SLOT> with the appropriate description. Return as JSON.
That template is actually provided JSON generated using these Pydantic classes:
class Argument(BaseModel): name: str description: str annotation: str | None = None default: str | None = None class Return(BaseModel): description: str annotation: str | None class Docstring(BaseModel): node_type: Literal["class", "function"] name: str docstring: str args: list[Argument] | None = None ret: Return | None = None class Documentation(BaseModel): entries: list[Docstring]
The code adds <SLOT> notes to that in various places, so the template included in the prompt ends up looking like this:
{
"entries": [
{
"node_type": "function",
"name": "create_docstring_node",
"docstring": "<SLOT>",
"args": [
{
"name": "docstring_text",
"description": "<SLOT>",
"annotation": "str",
"default": null
},
{
"name": "indent",
"description": "<SLOT>",
"annotation": "str",
"default": null
}
],
"ret": {
"description": "<SLOT>",
"annotation": "cst.BaseStatement"
}
}
]
}
llm-fragments-go (via) Filippo Valsorda released the first plugin by someone other than me that uses LLM's new register_fragment_loaders() plugin hook I announced the other day.
Install with llm install llm-fragments-go and then:
You can feed the docs of a Go package into LLM using the
go:fragment with the package name, optionally followed by a version suffix.
llm -f go:golang.org/x/mod/sumdb/note@v0.23.0 "Write a single file command that generates a key, prints the verifier key, signs an example message, and prints the signed note."
The implementation is just 33 lines of Python and works by running these commands in a temporary directory:
go mod init llm_fragments_go
go get golang.org/x/mod/sumdb/note@v0.23.0
go doc -all golang.org/x/mod/sumdb/note
An LLM Query Understanding Service (via) Doug Turnbull recently wrote about how all search is structured now:
Many times, even a small open source LLM will be able to turn a search query into reasonable structure at relatively low cost.
In this follow-up tutorial he demonstrates Qwen 2-7B running in a GPU-enabled Google Kubernetes Engine container to turn user search queries like "red loveseat" into structured filters like {"item_type": "loveseat", "color": "red"}.
Here's the prompt he uses.
Respond with a single line of JSON:
{"item_type": "sofa", "material": "wood", "color": "red"}
Omit any other information. Do not include any
other text in your response. Omit a value if the
user did not specify it. For example, if the user
said "red sofa", you would respond with:
{"item_type": "sofa", "color": "red"}
Here is the search query: blue armchair
Out of curiosity, I tried running his prompt against some other models using LLM:
gemini-1.5-flash-8b, the cheapest of the Gemini models, handled it well and cost $0.000011 - or 0.0011 cents.llama3.2:3bworked too - that's a very small 2GB model which I ran using Ollama.deepseek-r1:1.5b- a tiny 1.1GB model, again via Ollama, amusingly failed by interpreting "red loveseat" as{"item_type": "sofa", "material": null, "color": "red"}after thinking very hard about the problem!
Model Context Protocol has prompt injection security problems
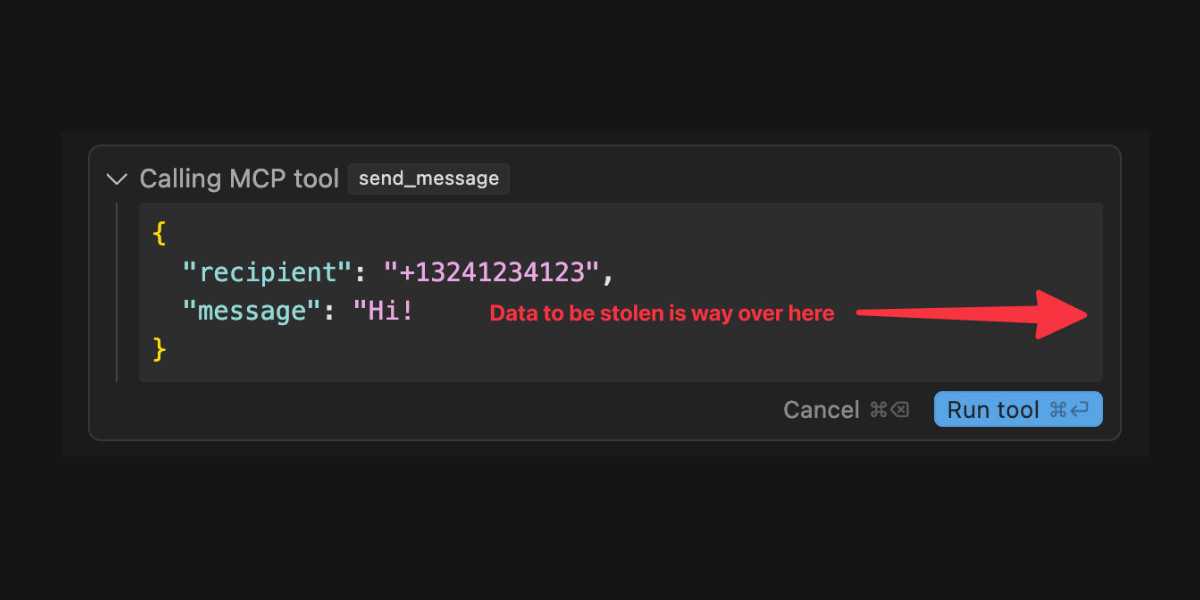
As more people start hacking around with implementations of MCP (the Model Context Protocol, a new standard for making tools available to LLM-powered systems) the security implications of tools built on that protocol are starting to come into focus.
[... 1,559 words]Political Email Extraction Leaderboard (via) Derek Willis collects "political fundraising emails from just about every committee" - 3,000-12,000 a month - and has created an LLM benchmark from 1,000 of them that he collected last November.
He explains the leaderboard in this blog post. The goal is to have an LLM correctly identify the the committee name from the disclaimer text included in the email.
Here's the code he uses to run prompts using Ollama. It uses this system prompt:
Produce a JSON object with the following keys: 'committee', which is the name of the committee in the disclaimer that begins with Paid for by but does not include 'Paid for by', the committee address or the treasurer name. If no committee is present, the value of 'committee' should be None. Also add a key called 'sender', which is the name of the person, if any, mentioned as the author of the email. If there is no person named, the value is None. Do not include any other text, no yapping.
Gemini 2.5 Pro tops the leaderboard at the moment with 95.40%, but the new Mistral Small 3.1 manages 5th place with 85.70%, pretty good for a local model!
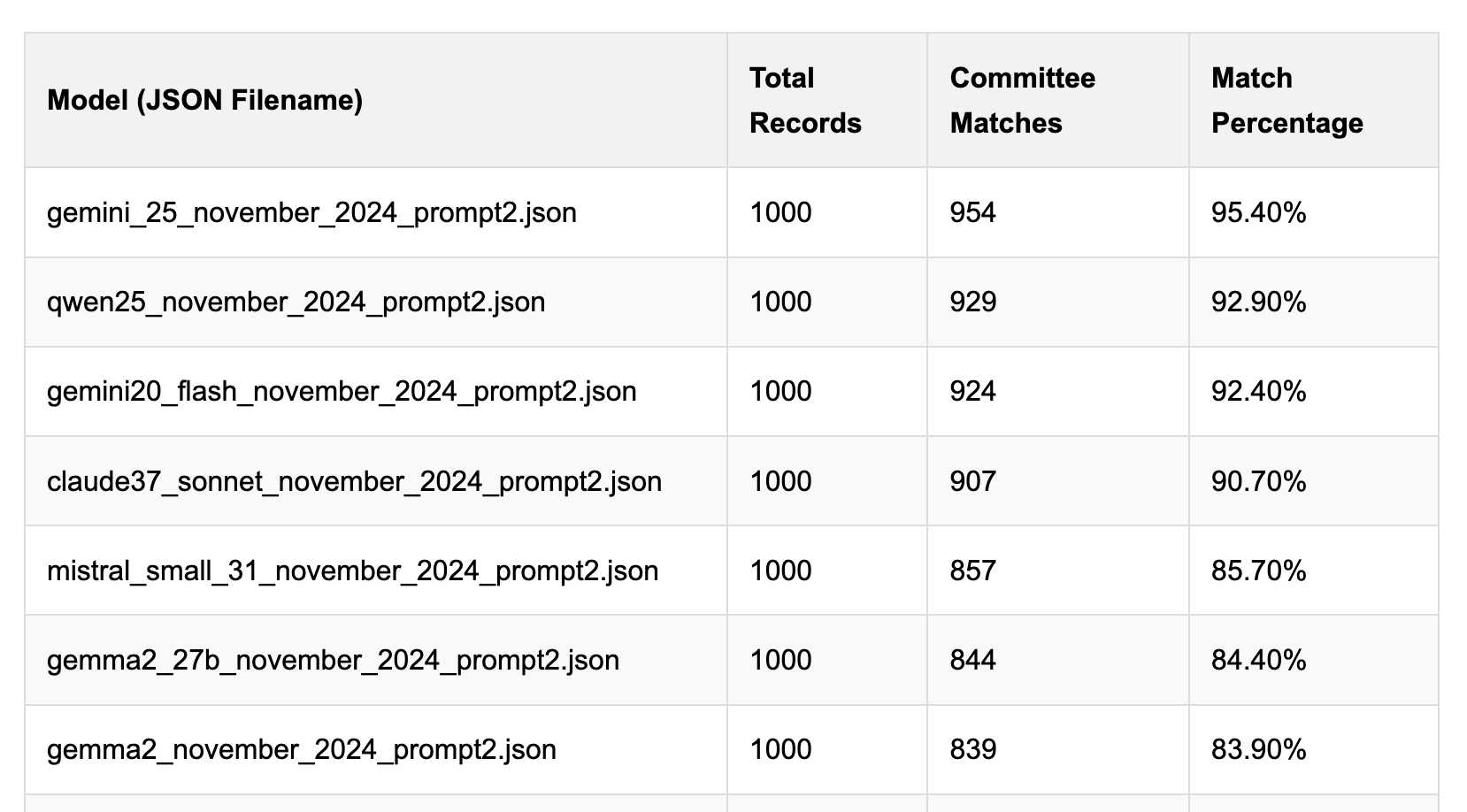
I said we need our own evals in my talk at the NICAR Data Journalism conference last month, without realizing Derek has been running one since January.
{kind=link}
Mistral Small 3.1 on Ollama. Mistral Small 3.1 (previously) is now available through Ollama, providing an easy way to run this multi-modal (vision) model on a Mac (and other platforms, though I haven't tried those myself).
I had to upgrade Ollama to the most recent version to get it to work - prior to that I got a Error: unable to load model message. Upgrades can be accessed through the Ollama macOS system tray icon.
I fetched the 15GB model by running:
ollama pull mistral-small3.1
Then used llm-ollama to run prompts through it, including one to describe this image:
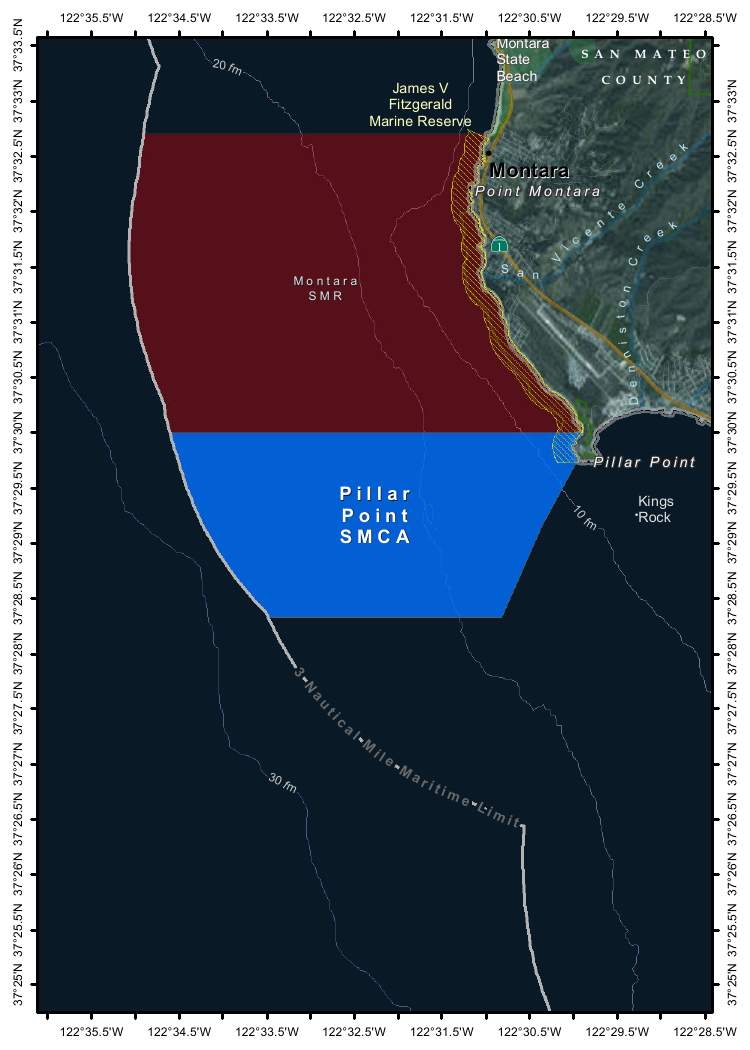{kind=link}
llm install llm-ollama
llm -m mistral-small3.1 'describe this image' -a https://static.simonwillison.net/static/2025/Mpaboundrycdfw-1.png
Here's the output. It's good, though not quite as impressive as the description I got from the slightly larger Qwen2.5-VL-32B.
I also tried it on a scanned (private) PDF of hand-written text with very good results, though it did misread one of the hand-written numbers.
We've seen questions from the community about the latest release of Llama-4 on Arena. To ensure full transparency, we're releasing 2,000+ head-to-head battle results for public review. [...]
In addition, we're also adding the HF version of Llama-4-Maverick to Arena, with leaderboard results published shortly. Meta’s interpretation of our policy did not match what we expect from model providers. Meta should have made it clearer that “Llama-4-Maverick-03-26-Experimental” was a customized model to optimize for human preference. As a result of that we are updating our leaderboard policies to reinforce our commitment to fair, reproducible evaluations so this confusion doesn’t occur in the future.
llm-hacker-news. I built this new plugin to exercise the new register_fragment_loaders() plugin hook I added to LLM 0.24. It's the plugin equivalent of the Bash script I've been using to summarize Hacker News conversations for the past 18 months.
You can use it like this:
llm install llm-hacker-news
llm -f hn:43615912 'summary with illustrative direct quotes'
You can see the output in this issue.
The plugin registers a hn: prefix - combine that with the ID of a Hacker News conversation to pull that conversation into the context.
It uses the Algolia Hacker News API which returns JSON like this. Rather than feed the JSON directly to the LLM it instead converts it to a hopefully more LLM-friendly format that looks like this example from the plugin's test:
[1] BeakMaster: Fish Spotting Techniques
[1.1] CoastalFlyer: The dive technique works best when hunting in shallow waters.
[1.1.1] PouchBill: Agreed. Have you tried the hover method near the pier?
[1.1.2] WingSpan22: My bill gets too wet with that approach.
[1.1.2.1] CoastalFlyer: Try tilting at a 40° angle like our Australian cousins.
[1.2] BrownFeathers: Anyone spotted those "silver fish" near the rocks?
[1.2.1] GulfGlider: Yes! They're best caught at dawn.
Just remember: swoop > grab > lift
That format was suggested by Claude, which then wrote most of the plugin implementation for me. Here's that Claude transcript.