11 posts tagged “baked-data”
The Baked Data architectural pattern.
2025
OpenTimes (via) Spectacular new open geospatial project by Dan Snow:
OpenTimes is a database of pre-computed, point-to-point travel times between United States Census geographies. It lets you download bulk travel time data for free and with no limits.
Here's what I get for travel times by car from El Granada, California:
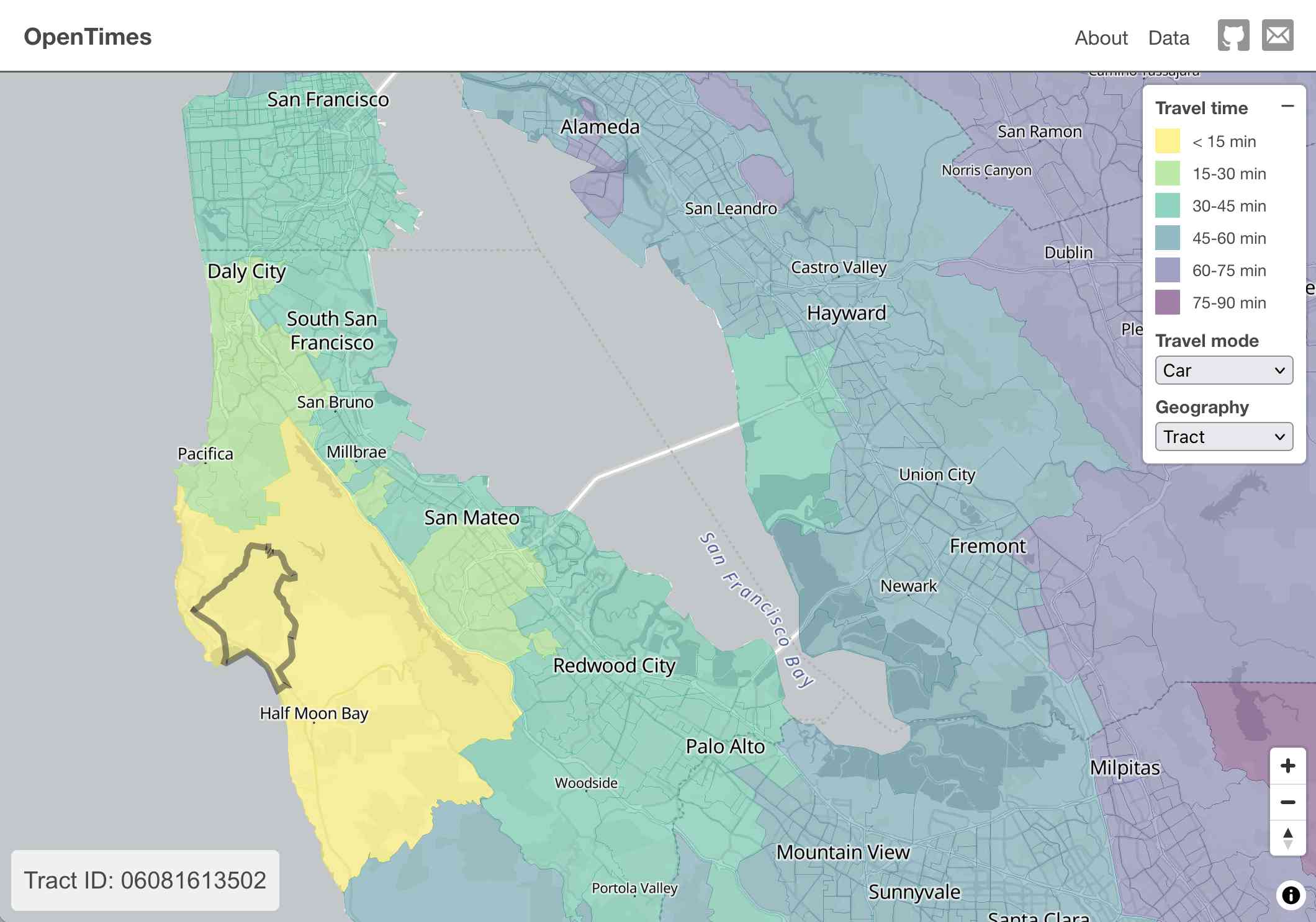
The technical details are fascinating:
- The entire OpenTimes backend is just static Parquet files on Cloudflare's R2. There's no RDBMS or running service, just files and a CDN. The whole thing costs about $10/month to host and costs nothing to serve. In my opinion, this is a great way to serve infrequently updated, large public datasets at low cost (as long as you partition the files correctly).
Sure enough, R2 pricing charges "based on the total volume of data stored" - $0.015 / GB-month for standard storage, then $0.36 / million requests for "Class B" operations which include reads. They charge nothing for outbound bandwidth.
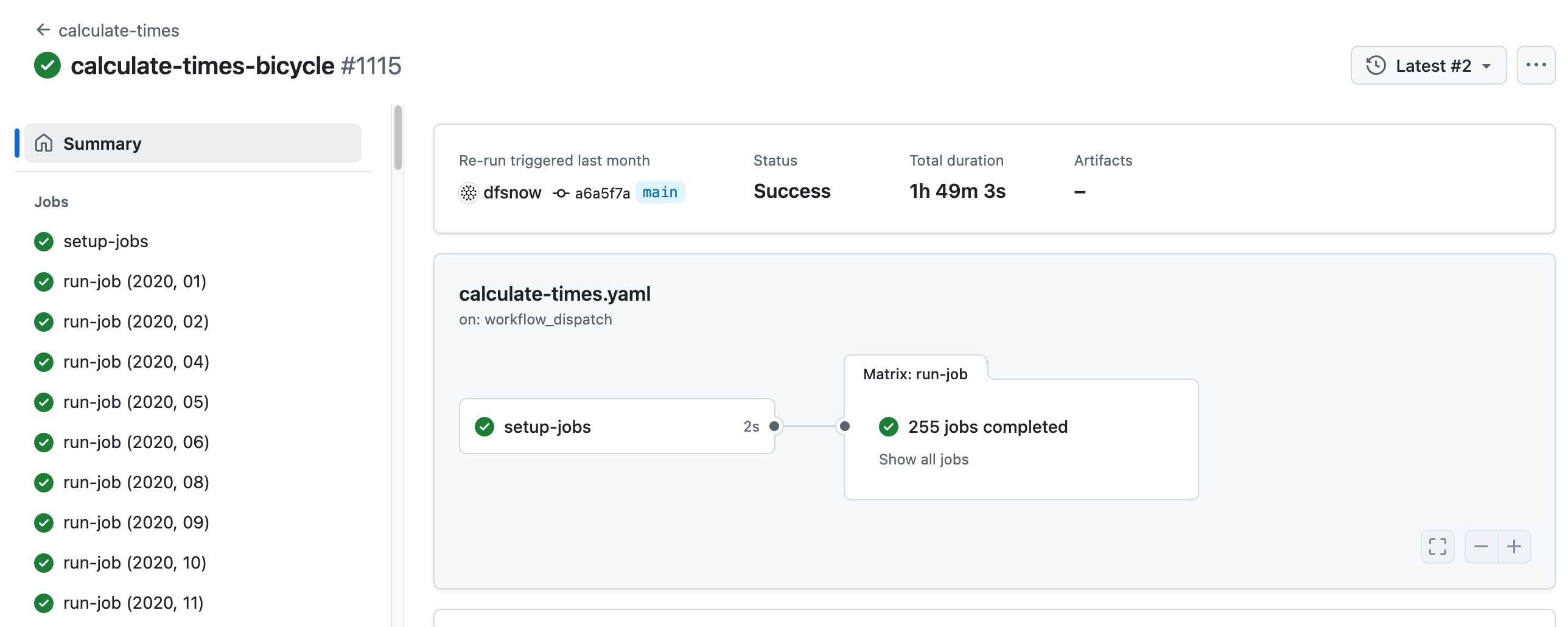
- All travel times were calculated by pre-building the inputs (OSM, OSRM networks) and then distributing the compute over hundreds of GitHub Actions jobs. This worked shockingly well for this specific workload (and was also completely free).
Here's a GitHub Actions run of the calculate-times.yaml workflow which uses a matrix to run 255 jobs!
Relevant YAML:
matrix:
year: ${{ fromJSON(needs.setup-jobs.outputs.years) }}
state: ${{ fromJSON(needs.setup-jobs.outputs.states) }}
Where those JSON files were created by the previous step, which reads in the year and state values from this params.yaml file.
- The query layer uses a single DuckDB database file with views that point to static Parquet files via HTTP. This lets you query a table with hundreds of billions of records after downloading just the ~5MB pointer file.
This is a really creative use of DuckDB's feature that lets you run queries against large data from a laptop using HTTP range queries to avoid downloading the whole thing.
The README shows how to use that from R and Python - I got this working in the duckdb client (brew install duckdb):
INSTALL httpfs;
LOAD httpfs;
ATTACH 'https://data.opentimes.org/databases/0.0.1.duckdb' AS opentimes;
SELECT origin_id, destination_id, duration_sec
FROM opentimes.public.times
WHERE version = '0.0.1'
AND mode = 'car'
AND year = '2024'
AND geography = 'tract'
AND state = '17'
AND origin_id LIKE '17031%' limit 10;
In answer to a question about adding public transit times Dan said:
In the next year or so maybe. The biggest obstacles to adding public transit are:
- Collecting all the necessary scheduling data (e.g. GTFS feeds) for every transit system in the county. Not insurmountable since there are services that do this currently.
- Finding a routing engine that can compute nation-scale travel time matrices quickly. Currently, the two fastest open-source engines I've tried (OSRM and Valhalla) don't support public transit for matrix calculations and the engines that do support public transit (R5, OpenTripPlanner, etc.) are too slow.
GTFS is a popular CSV-based format for sharing transit schedules - here's an official list of available feed directories.
This whole project feels to me like a great example of the baked data architectural pattern in action.
2024
We used this model [periodically transmitting configuration to different hosts] to distribute translations, feature flags, configuration, search indexes, etc at Airbnb. But instead of SQLite we used Sparkey, a KV file format developed by Spotify. In early years there was a Cron job on every box that pulled that service’s thingies; then once we switched to Kubernetes we used a daemonset & host tagging (taints?) to pull a variety of thingies to each host and then ensure the services that use the thingies only ran on the hosts that had the thingies.
2021
Clickhouse on Cloud Run (via) Alex Reid figured out how to run Clickhouse against read-only baked data on Cloud Run last year, and wrote up some comprehensive notes.
The Baked Data architectural pattern
I’ve been exploring an architectural pattern for publishing websites over the past few years that I call the “Baked Data” pattern. It provides many of the advantages of static site generators while avoiding most of their limitations. I think it deserves to be used more widely.
[... 1,896 words]2020
Building a search engine for datasette.io
This week I added a search engine to datasette.io, using the search indexing tool I’ve been building for Dogsheep.
[... 1,391 words]datasette.io, an official project website for Datasette

This week I launched datasette.io—the new official project website for Datasette.
[... 1,971 words]datasette-ripgrep: deploy a regular expression search engine for your source code
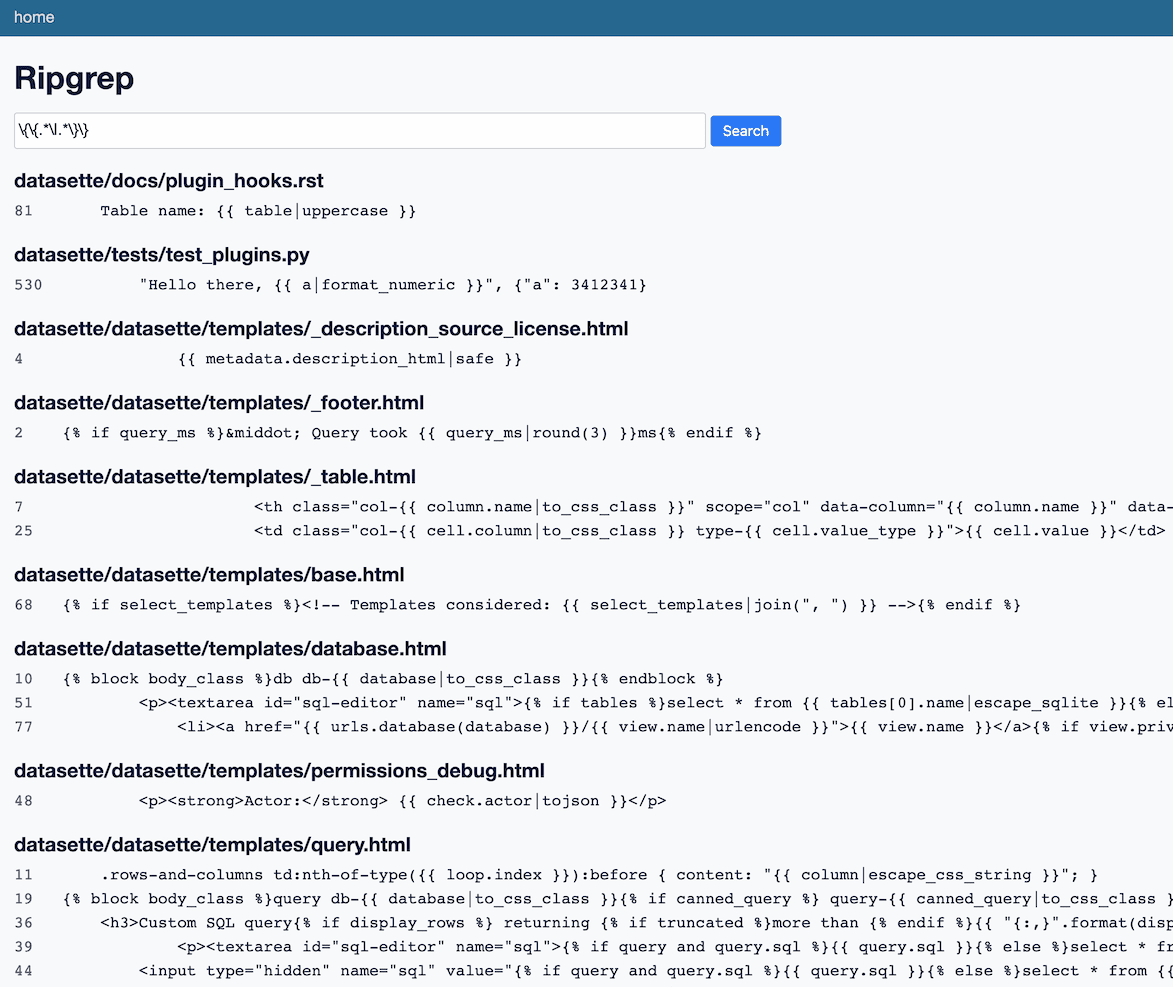
This week I built datasette-ripgrep—a web application for running regular expression searches against source code, built on top of the amazing ripgrep command-line tool.
[... 1,362 words]Bedrock: The SQLitening (via) Back in March 2018 www.mozilla.org switched over to running on Django using SQLite! They’re using the same pattern I’ve been exploring with Datasette: their SQLite database is treated as a read-only cache by their frontend servers, and a new SQLite database is built by a separate process and fetched onto the frontend machines every five minutes by a scheduled task. They have a healthcheck page which shows the latest version of the database and when it was fetched, and even lets you download the 25MB SQLite database directly (I’ve been exploring it using Datasette).
2019
niche-museums.com, powered by Datasette
I just released a major upgrade to my www.niche-museums.com website (launched last month).
[... 1,154 words]Weeknotes: Niche Museums, Kepler, Trees and Streaks
Every now and then someone will ask “so when are you going to build Museums Near Me then?”, based on my obsession with niche museums and websites like www.owlsnearme.com.
[... 872 words]2018
The interesting ideas in Datasette
Datasette (previously) is my open source tool for exploring and publishing structured data. There are a lot of ideas embedded in Datasette. I realized that I haven’t put many of them into writing.
[... 2,857 words]