2,082 posts tagged “ai”
"AI is whatever hasn't been done yet"—Larry Tesler
2025
LLM pricing calculator (updated). I updated my LLM pricing calculator this morning (Claude transcript) to show the prices of various hosted models in a sorted table, defaulting to lowest price first.
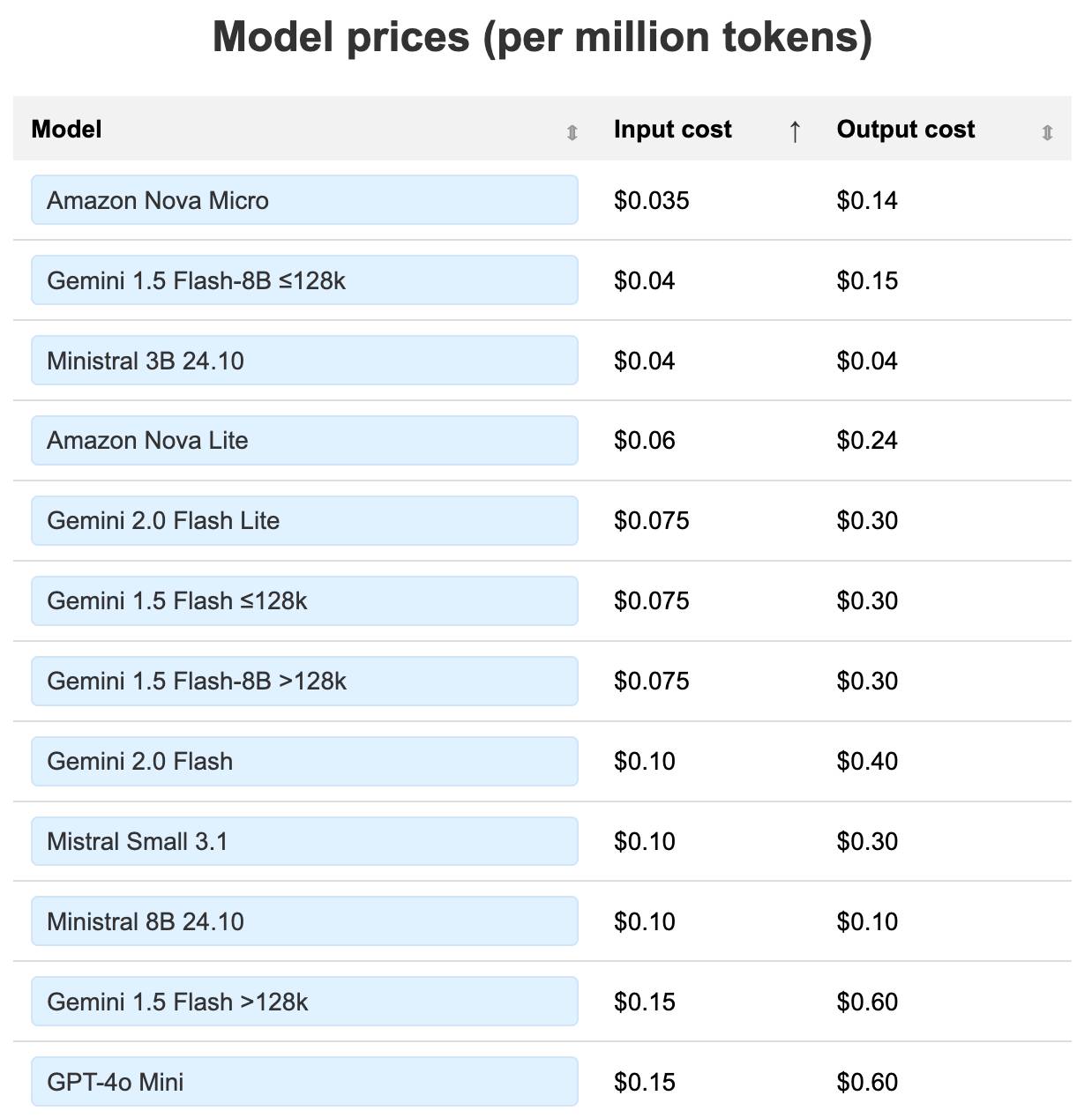
Amazon Nova and Google Gemini continue to dominate the lower end of the table. The most expensive models currently are still OpenAI's o1-Pro ($150/$600 and GPT-4.5 ($75/$150).
llm-docsmith (via) Matheus Pedroni released this neat plugin for LLM for adding docstrings to existing Python code. You can run it like this:
llm install llm-docsmith
llm docsmith ./scripts/main.py -o
The -o option previews the changes that will be made - without -o it edits the files directly.
It also accepts a -m claude-3.7-sonnet parameter for using an alternative model from the default (GPT-4o mini).
The implementation uses the Python libcst "Concrete Syntax Tree" package to manipulate the code, which means there's no chance of it making edits to anything other than the docstrings.
Here's the full system prompt it uses.
One neat trick is at the end of the system prompt it says:
You will receive a JSON template. Fill the slots marked with <SLOT> with the appropriate description. Return as JSON.
That template is actually provided JSON generated using these Pydantic classes:
class Argument(BaseModel): name: str description: str annotation: str | None = None default: str | None = None class Return(BaseModel): description: str annotation: str | None class Docstring(BaseModel): node_type: Literal["class", "function"] name: str docstring: str args: list[Argument] | None = None ret: Return | None = None class Documentation(BaseModel): entries: list[Docstring]
The code adds <SLOT> notes to that in various places, so the template included in the prompt ends up looking like this:
{
"entries": [
{
"node_type": "function",
"name": "create_docstring_node",
"docstring": "<SLOT>",
"args": [
{
"name": "docstring_text",
"description": "<SLOT>",
"annotation": "str",
"default": null
},
{
"name": "indent",
"description": "<SLOT>",
"annotation": "str",
"default": null
}
],
"ret": {
"description": "<SLOT>",
"annotation": "cst.BaseStatement"
}
}
]
}
llm-fragments-go (via) Filippo Valsorda released the first plugin by someone other than me that uses LLM's new register_fragment_loaders() plugin hook I announced the other day.
Install with llm install llm-fragments-go and then:
You can feed the docs of a Go package into LLM using the
go:fragment with the package name, optionally followed by a version suffix.
llm -f go:golang.org/x/mod/sumdb/note@v0.23.0 "Write a single file command that generates a key, prints the verifier key, signs an example message, and prints the signed note."
The implementation is just 33 lines of Python and works by running these commands in a temporary directory:
go mod init llm_fragments_go
go get golang.org/x/mod/sumdb/note@v0.23.0
go doc -all golang.org/x/mod/sumdb/note
These proposed API integrations where your LLM agent talks to someone else's LLM tool-using agent are the API version of that thing where someone uses ChatGPT to turn their bullets into an email and the recipient uses ChatGPT to summarize it back to bullet points.
An LLM Query Understanding Service (via) Doug Turnbull recently wrote about how all search is structured now:
Many times, even a small open source LLM will be able to turn a search query into reasonable structure at relatively low cost.
In this follow-up tutorial he demonstrates Qwen 2-7B running in a GPU-enabled Google Kubernetes Engine container to turn user search queries like "red loveseat" into structured filters like {"item_type": "loveseat", "color": "red"}.
Here's the prompt he uses.
Respond with a single line of JSON:
{"item_type": "sofa", "material": "wood", "color": "red"}
Omit any other information. Do not include any
other text in your response. Omit a value if the
user did not specify it. For example, if the user
said "red sofa", you would respond with:
{"item_type": "sofa", "color": "red"}
Here is the search query: blue armchair
Out of curiosity, I tried running his prompt against some other models using LLM:
gemini-1.5-flash-8b, the cheapest of the Gemini models, handled it well and cost $0.000011 - or 0.0011 cents.llama3.2:3bworked too - that's a very small 2GB model which I ran using Ollama.deepseek-r1:1.5b- a tiny 1.1GB model, again via Ollama, amusingly failed by interpreting "red loveseat" as{"item_type": "sofa", "material": null, "color": "red"}after thinking very hard about the problem!
Model Context Protocol has prompt injection security problems
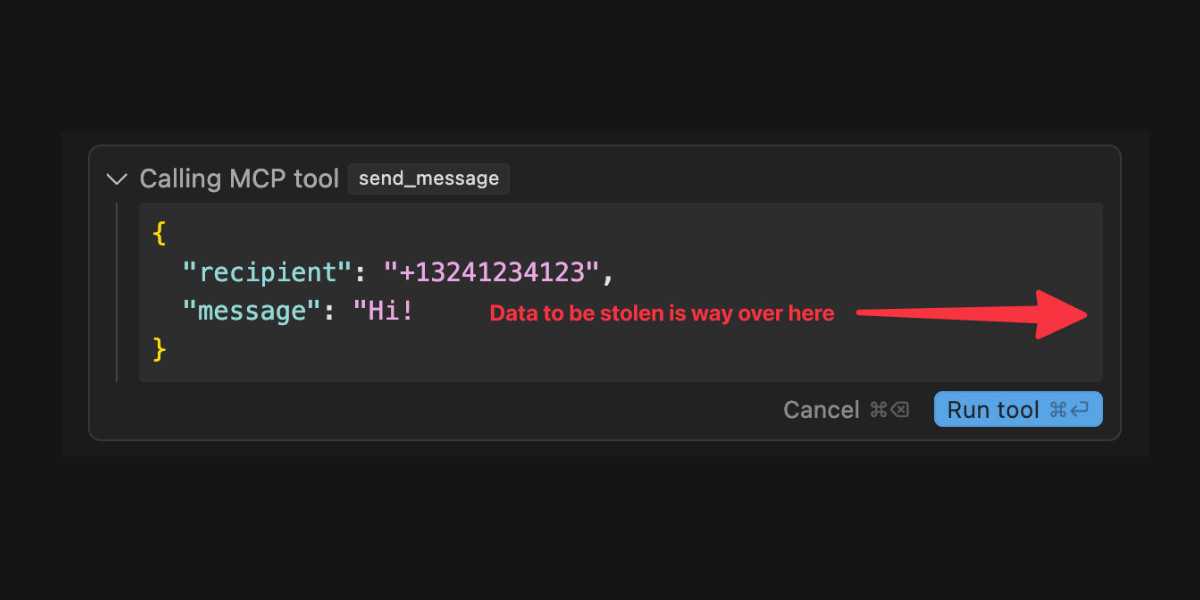
As more people start hacking around with implementations of MCP (the Model Context Protocol, a new standard for making tools available to LLM-powered systems) the security implications of tools built on that protocol are starting to come into focus.
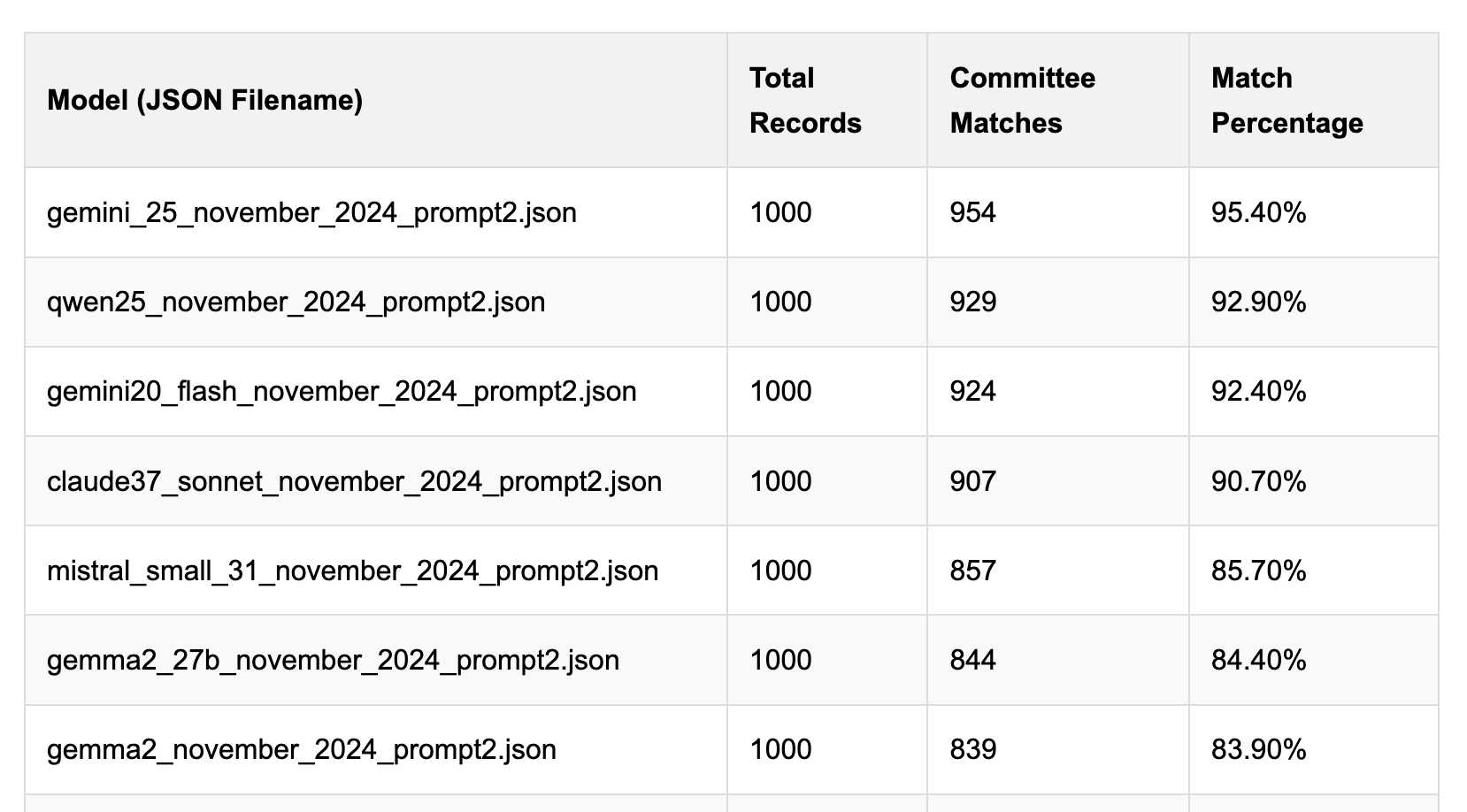
[... 1,559 words]Political Email Extraction Leaderboard (via) Derek Willis collects "political fundraising emails from just about every committee" - 3,000-12,000 a month - and has created an LLM benchmark from 1,000 of them that he collected last November.
He explains the leaderboard in this blog post. The goal is to have an LLM correctly identify the the committee name from the disclaimer text included in the email.
Here's the code he uses to run prompts using Ollama. It uses this system prompt:
Produce a JSON object with the following keys: 'committee', which is the name of the committee in the disclaimer that begins with Paid for by but does not include 'Paid for by', the committee address or the treasurer name. If no committee is present, the value of 'committee' should be None. Also add a key called 'sender', which is the name of the person, if any, mentioned as the author of the email. If there is no person named, the value is None. Do not include any other text, no yapping.
Gemini 2.5 Pro tops the leaderboard at the moment with 95.40%, but the new Mistral Small 3.1 manages 5th place with 85.70%, pretty good for a local model!
I said we need our own evals in my talk at the NICAR Data Journalism conference last month, without realizing Derek has been running one since January.
{kind=link}
Mistral Small 3.1 on Ollama. Mistral Small 3.1 (previously) is now available through Ollama, providing an easy way to run this multi-modal (vision) model on a Mac (and other platforms, though I haven't tried those myself).
I had to upgrade Ollama to the most recent version to get it to work - prior to that I got a Error: unable to load model message. Upgrades can be accessed through the Ollama macOS system tray icon.
I fetched the 15GB model by running:
ollama pull mistral-small3.1
Then used llm-ollama to run prompts through it, including one to describe this image:
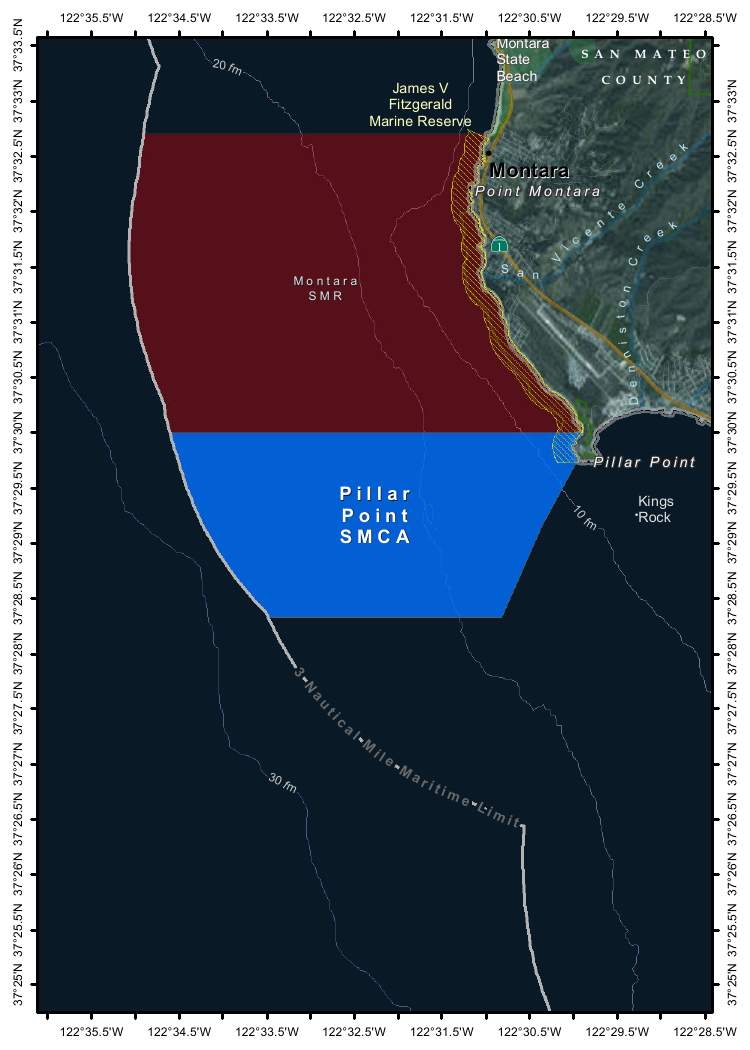{kind=link}
llm install llm-ollama
llm -m mistral-small3.1 'describe this image' -a https://static.simonwillison.net/static/2025/Mpaboundrycdfw-1.png
Here's the output. It's good, though not quite as impressive as the description I got from the slightly larger Qwen2.5-VL-32B.
I also tried it on a scanned (private) PDF of hand-written text with very good results, though it did misread one of the hand-written numbers.
Imagine if Ford published a paper saying it was thinking about long term issues of the automobiles it made and one of those issues included “misalignment “Car as an adversary”” and when you asked Ford for clarification the company said “yes, we believe as we make our cars faster and more capable, they may sometimes take actions harmful to human well being” and you say “oh, wow, thanks Ford, but… what do you mean precisely?” and Ford says “well, we cannot rule out the possibility that the car might decide to just start running over crowds of people” and then Ford looks at you and says “this is a long-term research challenge”.
— Jack Clark, DeepMind gazes into the AGI future
We've seen questions from the community about the latest release of Llama-4 on Arena. To ensure full transparency, we're releasing 2,000+ head-to-head battle results for public review. [...]
In addition, we're also adding the HF version of Llama-4-Maverick to Arena, with leaderboard results published shortly. Meta’s interpretation of our policy did not match what we expect from model providers. Meta should have made it clearer that “Llama-4-Maverick-03-26-Experimental” was a customized model to optimize for human preference. As a result of that we are updating our leaderboard policies to reinforce our commitment to fair, reproducible evaluations so this confusion doesn’t occur in the future.
llm-hacker-news. I built this new plugin to exercise the new register_fragment_loaders() plugin hook I added to LLM 0.24. It's the plugin equivalent of the Bash script I've been using to summarize Hacker News conversations for the past 18 months.
You can use it like this:
llm install llm-hacker-news
llm -f hn:43615912 'summary with illustrative direct quotes'
You can see the output in this issue.
The plugin registers a hn: prefix - combine that with the ID of a Hacker News conversation to pull that conversation into the context.
It uses the Algolia Hacker News API which returns JSON like this. Rather than feed the JSON directly to the LLM it instead converts it to a hopefully more LLM-friendly format that looks like this example from the plugin's test:
[1] BeakMaster: Fish Spotting Techniques
[1.1] CoastalFlyer: The dive technique works best when hunting in shallow waters.
[1.1.1] PouchBill: Agreed. Have you tried the hover method near the pier?
[1.1.2] WingSpan22: My bill gets too wet with that approach.
[1.1.2.1] CoastalFlyer: Try tilting at a 40° angle like our Australian cousins.
[1.2] BrownFeathers: Anyone spotted those "silver fish" near the rocks?
[1.2.1] GulfGlider: Yes! They're best caught at dawn.
Just remember: swoop > grab > lift
That format was suggested by Claude, which then wrote most of the plugin implementation for me. Here's that Claude transcript.
My first games involved hand assembling machine code and turning graph paper characters into hex digits. Software progress has made that work as irrelevant as chariot wheel maintenance. [...]
AI tools will allow the best to reach even greater heights, while enabling smaller teams to accomplish more, and bring in some completely new creator demographics.
Yes, we will get to a world where you can get an interactive game (or novel, or movie) out of a prompt, but there will be far better exemplars of the medium still created by dedicated teams of passionate developers.
The world will be vastly wealthier in terms of the content available at any given cost.
Will there be more or less game developer jobs? That is an open question. It could go the way of farming, where labor saving technology allow a tiny fraction of the previous workforce to satisfy everyone, or it could be like social media, where creative entrepreneurship has flourished at many different scales. Regardless, “don’t use power tools because they take people’s jobs” is not a winning strategy.
If you're a startup running your own crawlers to gather data for whatever purpose, you should try really hard not to make the world a worse place by driving up costs for the sites you are scraping.
There's really no excuse for crawling Wikipedia ("65% of our most expensive traffic comes from bots") when they offer a comprehensive collection of bulk download options.
Do better!
Using Al effectively is now a fundamental expectation of everyone at Shopify. It's a tool of all trades today, and will only grow in importance. Frankly, I don't think it's feasible to opt out of learning the skill of applying Al in your craft; you are welcome to try, but I want to be honest I cannot see this working out today, and definitely not tomorrow. Stagnation is almost certain, and stagnation is slow-motion failure. If you're not climbing, you're sliding [...]
We will add Al usage questions to our performance and peer review questionnaire. Learning to use Al well is an unobvious skill. My sense is that a lot of people give up after writing a prompt and not getting the ideal thing back immediately. Learning to prompt and load context is important, and getting peers to provide feedback on how this is going will be valuable.
— Tobias Lütke, CEO of Shopify, self-leaked memo
Long context support in LLM 0.24 using fragments and template plugins
LLM 0.24 is now available with new features to help take advantage of the increasingly long input context supported by modern LLMs.
[... 1,896 words][...] The disappointing releases of both GPT-4.5 and Llama 4 have shown that if you don't train a model to reason with reinforcement learning, increasing its size no longer provides benefits.
Reinforcement learning is limited only to domains where a reward can be assigned to the generation result. Until recently, these domains were math, logic, and code. Recently, these domains have also included factual question answering, where, to find an answer, the model must learn to execute several searches. This is how these "deep search" models have likely been trained.
If your business idea isn't in these domains, now is the time to start building your business-specific dataset. The potential increase in generalist models' skills will no longer be a threat.
Initial impressions of Llama 4
Dropping a model release as significant as Llama 4 on a weekend is plain unfair! So far the best place to learn about the new model family is this post on the Meta AI blog. They’ve released two new models today: Llama 4 Maverick is a 400B model (128 experts, 17B active parameters), text and image input with a 1 million token context length. Llama 4 Scout is 109B total parameters (16 experts, 17B active), also multi-modal and with a claimed 10 million token context length—an industry first.
[... 1,468 words]The Llama series have been re-designed to use state of the art mixture-of-experts (MoE) architecture and natively trained with multimodality. We’re dropping Llama 4 Scout & Llama 4 Maverick, and previewing Llama 4 Behemoth.
📌 Llama 4 Scout is highest performing small model with 17B activated parameters with 16 experts. It’s crazy fast, natively multimodal, and very smart. It achieves an industry leading 10M+ token context window and can also run on a single GPU!
📌 Llama 4 Maverick is the best multimodal model in its class, beating GPT-4o and Gemini 2.0 Flash across a broad range of widely reported benchmarks, while achieving comparable results to the new DeepSeek v3 on reasoning and coding – at less than half the active parameters. It offers a best-in-class performance to cost ratio with an experimental chat version scoring ELO of 1417 on LMArena. It can also run on a single host!
📌 Previewing Llama 4 Behemoth, our most powerful model yet and among the world’s smartest LLMs. Llama 4 Behemoth outperforms GPT4.5, Claude Sonnet 3.7, and Gemini 2.0 Pro on several STEM benchmarks. Llama 4 Behemoth is still training, and we’re excited to share more details about it even while it’s still in flight.
— Ahmed Al-Dahle, VP and Head of GenAI at Meta
change of plans: we are going to release o3 and o4-mini after all, probably in a couple of weeks, and then do GPT-5 in a few months
Gemini 2.5 Pro Preview pricing (via) Google's Gemini 2.5 Pro is currently the top model on LM Arena and, from my own testing, a superb model for OCR, audio transcription and long-context coding.
You can now pay for it!
The new gemini-2.5-pro-preview-03-25 model ID is priced like this:
- Prompts less than 200,00 tokens: $1.25/million tokens for input, $10/million for output
- Prompts more than 200,000 tokens (up to the 1,048,576 max): $2.50/million for input, $15/million for output
This is priced at around the same level as Gemini 1.5 Pro ($1.25/$5 for input/output below 128,000 tokens, $2.50/$10 above 128,000 tokens), is cheaper than GPT-4o for shorter prompts ($2.50/$10) and is cheaper than Claude 3.7 Sonnet ($3/$15).
Gemini 2.5 Pro is a reasoning model, and invisible reasoning tokens are included in the output token count. I just tried prompting "hi" and it charged me 2 tokens for input and 623 for output, of which 613 were "thinking" tokens. That still adds up to just 0.6232 cents (less than a cent) using my LLM pricing calculator which I updated to support the new model just now.
I released llm-gemini 0.17 this morning adding support for the new model:
llm install -U llm-gemini
llm -m gemini-2.5-pro-preview-03-25 hi
Note that the model continues to be available for free under the previous gemini-2.5-pro-exp-03-25 model ID:
llm -m gemini-2.5-pro-exp-03-25 hi
The free tier is "used to improve our products", the paid tier is not.
Rate limits for the paid model vary by tier - from 150/minute and 1,000/day for tier 1 (billing configured), 1,000/minute and 50,000/day for Tier 2 ($250 total spend) and 2,000/minute and unlimited/day for Tier 3 ($1,000 total spend). Meanwhile the free tier continues to limit you to 5 requests per minute and 25 per day.
Google are retiring the Gemini 2.0 Pro preview entirely in favour of 2.5.
smartfunc. Vincent D. Warmerdam built this ingenious wrapper around my LLM Python library which lets you build LLM wrapper functions using a decorator and a docstring:
from smartfunc import backend @backend("gpt-4o") def generate_summary(text: str): """Generate a summary of the following text: {{ text }}""" pass summary = generate_summary(long_text)
It works with LLM plugins so the same pattern should work against Gemini, Claude and hundreds of others, including local models.
It integrates with more recent LLM features too, including async support and schemas, by introspecting the function signature:
class Summary(BaseModel): summary: str pros: list[str] cons: list[str] @async_backend("gpt-4o-mini") async def generate_poke_desc(text: str) -> Summary: "Describe the following pokemon: {{ text }}" pass pokemon = await generate_poke_desc("pikachu")
Vincent also recorded a 12 minute video walking through the implementation and showing how it uses Pydantic, Python's inspect module and typing.get_type_hints() function.
I started using Claude and Claude Code a bit in my regular workflow. I’ll skip the suspense and just say that the tool is way more capable than I would ever have expected. The way I can use it to interrogate a large codebase, or generate unit tests, or even “refactor every callsite to use such-and-such pattern” is utterly gobsmacking. [...]
Here’s the main problem I’ve found with generative AI, and with “vibe coding” in general: it completely sucks out the joy of software development for me. [...]
This is how I feel using gen-AI: like a babysitter. It spits out reams of code, I read through it and try to spot the bugs, and then we repeat.
— Nolan Lawson, AI ambivalence
Half Stack Data Science: Programming with AI, with Simon Willison (via) I participated in this wide-ranging 50 minute conversation with David Asboth and Shaun McGirr. Topics we covered included applications of LLMs to data journalism, the challenges of building an intuition for how best to use these tool given their "jagged frontier" of capabilities, how LLMs impact learning to program and how local models are starting to get genuinely useful now.
At 27:47:
If you're a new programmer, my optimistic version is that there has never been a better time to learn to program, because it shaves down the learning curve so much. When you're learning to program and you miss a semicolon and you bang your head against the computer for four hours [...] if you're unlucky you quit programming for good because it was so frustrating. [...]
I've always been a project-oriented learner; I can learn things by building something, and now the friction involved in building something has gone down so much [...] So I think especially if you're an autodidact, if you're somebody who likes teaching yourself things, these are a gift from heaven. You get a weird teaching assistant that knows loads of stuff and occasionally makes weird mistakes and believes in bizarre conspiracy theories, but you have 24 hour access to that assistant.
If you're somebody who prefers structured learning in classrooms, I think the benefits are going to take a lot longer to get to you because we don't know how to use these things in classrooms yet. [...]
If you want to strike out on your own, this is an amazing tool if you learn how to learn with it. So you've got to learn the limits of what it can do, and you've got to be disciplined enough to make sure you're not outsourcing the bits you need to learn to the machines.
Pydantic Evals (via) Brand new package from David Montague and the Pydantic AI team which directly tackles what I consider to be the single hardest problem in AI engineering: building evals to determine if your LLM-based system is working correctly and getting better over time.
The feature is described as "in beta" and comes with this very realistic warning:
Unlike unit tests, evals are an emerging art/science; anyone who claims to know for sure exactly how your evals should be defined can safely be ignored.
This code example from their documentation illustrates the relationship between the two key nouns - Cases and Datasets:
from pydantic_evals import Case, Dataset case1 = Case( name="simple_case", inputs="What is the capital of France?", expected_output="Paris", metadata={"difficulty": "easy"}, ) dataset = Dataset(cases=[case1])
The library also supports custom evaluators, including LLM-as-a-judge:
Case( name="vegetarian_recipe", inputs=CustomerOrder( dish_name="Spaghetti Bolognese", dietary_restriction="vegetarian" ), expected_output=None, metadata={"focus": "vegetarian"}, evaluators=( LLMJudge( rubric="Recipe should not contain meat or animal products", ), ), )
Cases and datasets can also be serialized to YAML.
My first impressions are that this looks like a solid implementation of a sensible design. I'm looking forward to trying it out against a real project.
We’re planning to release a very capable open language model in the coming months, our first since GPT-2. [...]
As models improve, there is more and more demand to run them everywhere. Through conversations with startups and developers, it became clear how important it was to be able to support a spectrum of needs, such as custom fine-tuning for specialized tasks, more tunable latency, running on-prem, or deployments requiring full data control.
— Brad Lightcap, COO, OpenAI
debug-gym (via) New paper and code from Microsoft Research that experiments with giving LLMs access to the Python debugger. They found that the best models could indeed improve their results by running pdb as a tool.
They saw the best results overall from Claude 3.7 Sonnet against SWE-bench Lite, where it scored 37.2% in rewrite mode without a debugger, 48.4% with their debugger tool and 52.1% with debug(5) - a mechanism where the pdb tool is made available only after the 5th rewrite attempt.
Their code is available on GitHub. I found this implementation of the pdb tool, and tracked down the main system and user prompt in agents/debug_agent.py:
System prompt:
Your goal is to debug a Python program to make sure it can pass a set of test functions. You have access to the pdb debugger tools, you can use them to investigate the code, set breakpoints, and print necessary values to identify the bugs. Once you have gained enough information, propose a rewriting patch to fix the bugs. Avoid rewriting the entire code, focus on the bugs only.
User prompt (which they call an "action prompt"):
Based on the instruction, the current code, the last execution output, and the history information, continue your debugging process using pdb commands or to propose a patch using rewrite command. Output a single command, nothing else. Do not repeat your previous commands unless they can provide more information. You must be concise and avoid overthinking.
My advice about using AI is simple: use AI as an assistant, not an expert, and use it judiciously. Some people will object, “but AI can be wrong!” Yes, and so can the internet in general, but no one now recommends avoiding online resources because they can be wrong. They recommend taking it all with a grain of salt and being careful. That’s what you should do with AI help as well.
— Ned Batchelder, Horseless intelligence
Slop is about collapsing to the mode. It’s about information heat death. It’s lukewarm emptiness. It’s ten million approximately identical cartoon selfies that no one will ever recall in detail because none of the details matter.
Incomplete JSON Pretty Printer. Every now and then a log file or a tool I'm using will spit out a bunch of JSON that terminates unexpectedly, meaning I can't copy it into a text editor and pretty-print it to see what's going on.
The other day I got frustrated with this and had the then-new GPT-4.5 build me a pretty-printer that didn't mind incomplete JSON, using an OpenAI Canvas. Here's the chat and here's the resulting interactive.
I spotted a bug with the way it indented code today so I pasted it into Claude 3.7 Sonnet Thinking mode and had it make a bunch of improvements - full transcript here. Here's the finished code.
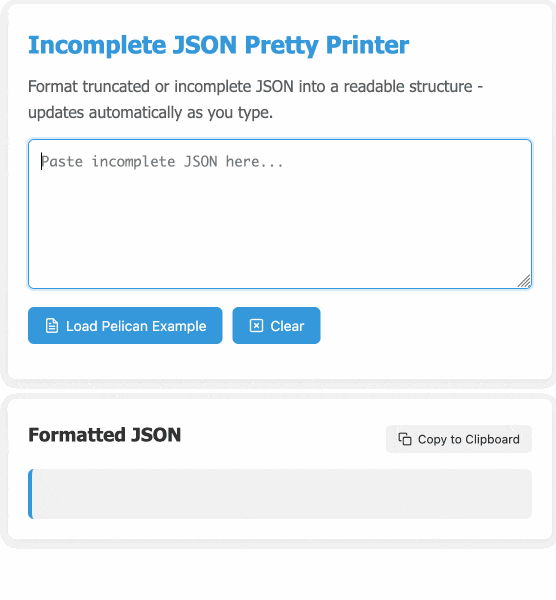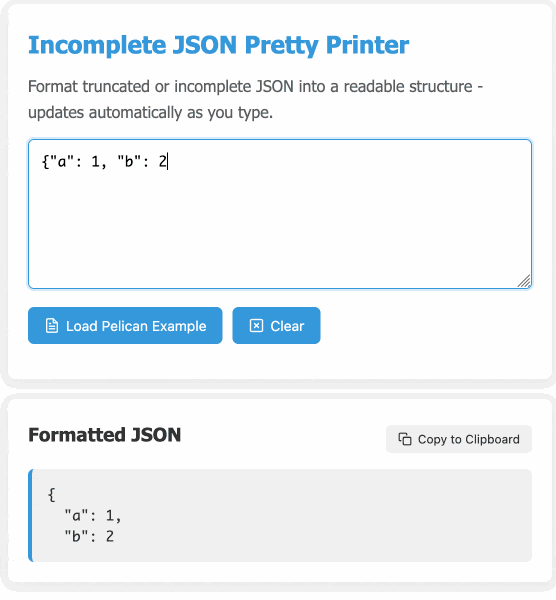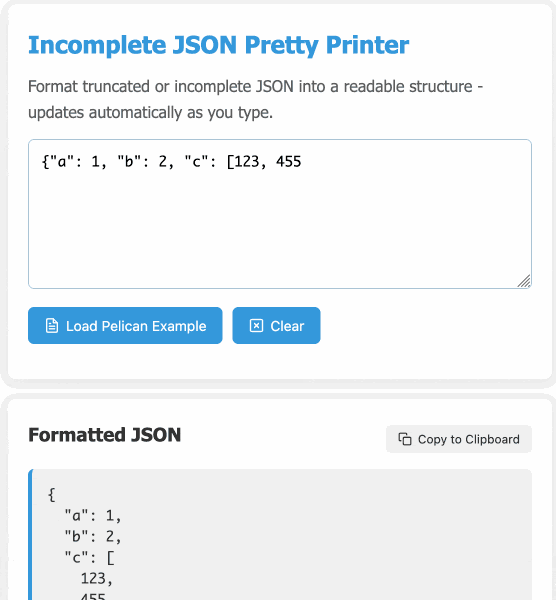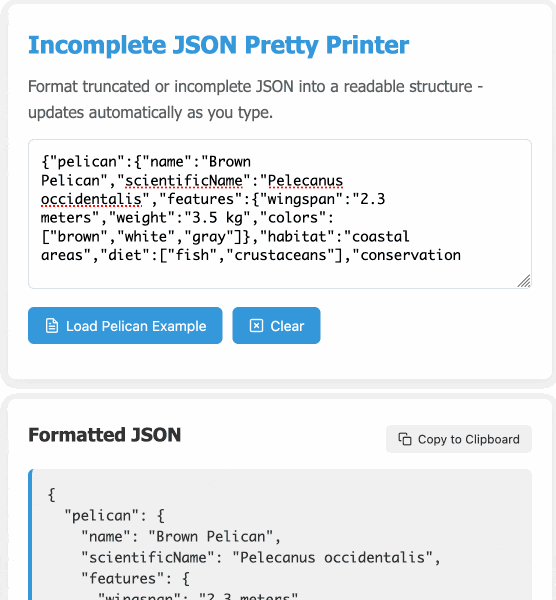
In many ways this is a perfect example of vibe coding in action. At no point did I look at a single line of code that either of the LLMs had written for me. I honestly don't care how this thing works: it could not be lower stakes for me, the worst a bug could do is show me poorly formatted incomplete JSON.
I was vaguely aware that some kind of state machine style parser would be needed, because you can't parse incomplete JSON with a regular JSON parser. Building simple parsers is the kind of thing LLMs are surprisingly good at, and also the kind of thing I don't want to take on for a trivial project.
At one point I told Claude "Try using your code execution tool to check your logic", because I happen to know Claude can write and then execute JavaScript independently of using it for artifacts. That helped it out a bunch.
I later dropped in the following:
modify the tool to work better on mobile screens and generally look a bit nicer - and remove the pretty print JSON button, it should update any time the input text is changed. Also add a "copy to clipboard" button next to the results. And add a button that says "example" which adds a longer incomplete example to demonstrate the tool, make that example pelican themed.
It's fun being able to say "generally look a bit nicer" and get a perfectly acceptable result!
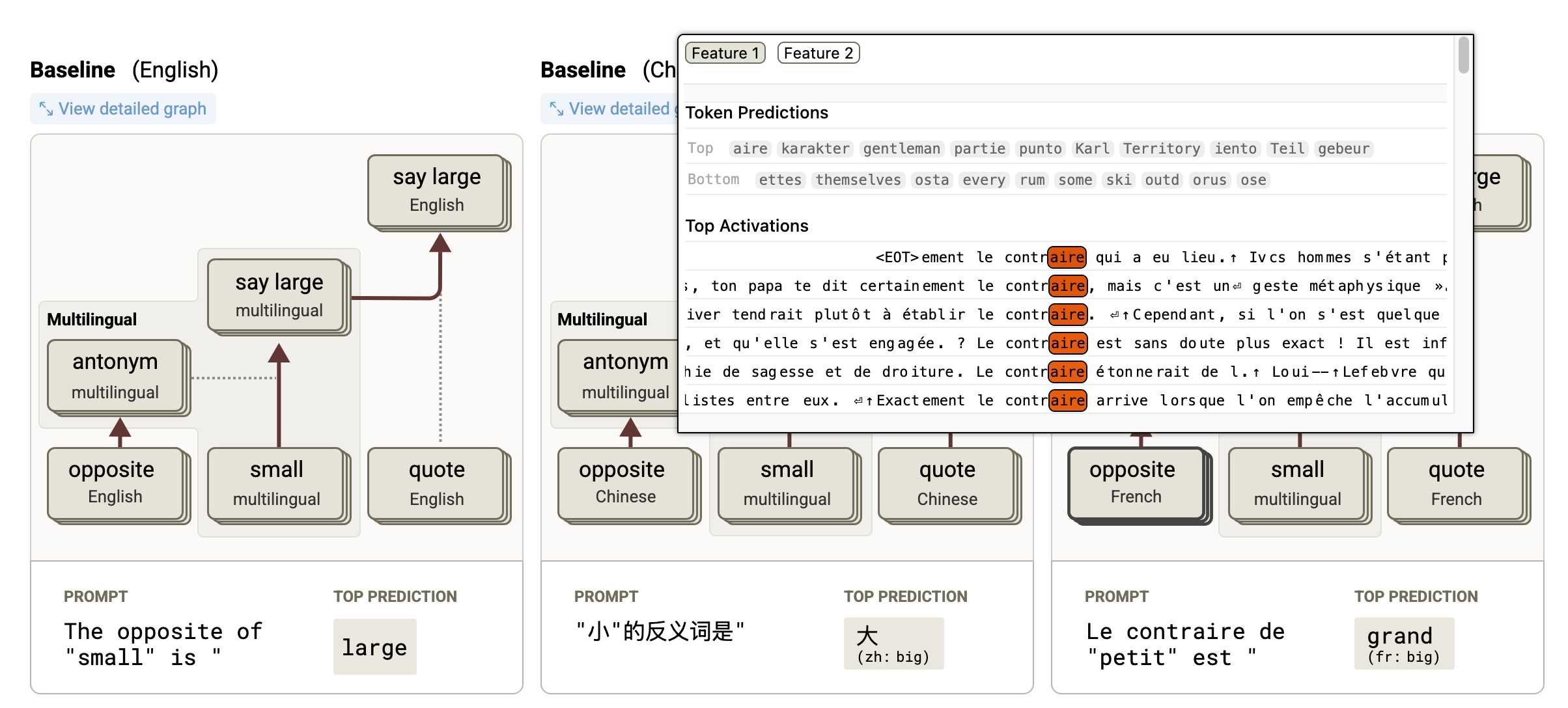
Tracing the thoughts of a large language model. In a follow-up to the research that brought us the delightful Golden Gate Claude last year, Anthropic have published two new papers about LLM interpretability:
- Circuit Tracing: Revealing Computational Graphs in Language Models extends last year's interpretable features into attribution graphs, which can "trace the chain of intermediate steps that a model uses to transform a specific input prompt into an output response".
- On the Biology of a Large Language Model uses that methodology to investigate Claude 3.5 Haiku in a bunch of different ways. Multilingual Circuits for example shows that the same prompt in three different languages uses similar circuits for each one, hinting at an intriguing level of generalization.
To my own personal delight, neither of these papers are published as PDFs. They're both presented as glorious mobile friendly HTML pages with linkable sections and even some inline interactive diagrams. More of this please!