111 posts tagged “ai-agents”
AI agents can mean a lot of different things. These days I think of them as LLMs calling tools in a loop to achieve a goal.
2026
“11 AI agents” is meaningless as a phrase.
If I said “I have 11 spreadsheets” or “I have 11 browser tabs” to do my work, it means about the same thing.
Our AI started a cafe in Stockholm (via) Andon Labs previously started an AI-run retail store in San Francisco. Now they're running a similar experiment in Stockholm, Sweden, only this time it's a cafe.
These experiments are interesting, and often throw out amusing anecdotes:
During the first week of inventory, Mona ordered 120 eggs even though the café has no stove. When the staff told her they couldn’t cook them, she suggested using the high-speed oven, until they pointed out the eggs would likely explode. She also tried to solve the problem of fresh tomatoes being spoiled too fast by ordering 22.5 kg of canned tomatoes for the fresh sandwiches. The baristas eventually started a “Hall of Shame”, a shelf visible to customers with all the weird things Mona ordered, including 6,000 napkins, 3,000 nitrile gloves, 9L coconut milk, and industrial-sized trash bags.
Where they lose their shine is when these AI managers start wasting the time of human beings who have not opted into the experiment:
She also successfully applied for an outdoor seating permit through the Police e-service, which didn’t require BankID. Her first submission included a sketch she had generated herself, despite having never seen the street outside the café. Unsurprisingly, the Police sent it back for revision. [...]
When she makes a mistake, she often sends multiple emails to suppliers with the subject “EMERGENCY” to cancel or change the order.
I don't think it's ethical to run experiments like this that affect real-world systems and steal time from people.
I'm reminded of the incident last year where the AI Village experiment infuriated Rob Pike by sending him unsolicited gratitude emails as an "act of kindness". That was just an unwanted email - asking suppliers to correct mistakes that were made without a human-in-the-loop or wasting police time with slop diagrams feels a whole lot worse to me.
I think experiments like this need to keep their own human operators in-the-loop for outbound actions that affect other people.
AI agents are already too human. Not in the romantic sense, not because they love or fear or dream, but in the more banal and frustrating one. The current implementations keep showing their human origin again and again: lack of stringency, lack of patience, lack of focus. Faced with an awkward task, they drift towards the familiar. Faced with hard constraints, they start negotiating with reality.
— Andreas Påhlsson-Notini, Less human AI agents, please.
Nothing humbles you like telling your OpenClaw “confirm before acting” and watching it speedrun deleting your inbox. I couldn’t stop it from my phone. I had to RUN to my Mac mini like I was defusing a bomb.
I said “Check this inbox too and suggest what you would archive or delete, don’t action until I tell you to.” This has been working well for my toy inbox, but my real inbox was too huge and triggered compaction. During the compaction, it lost my original instruction 🤦♀️
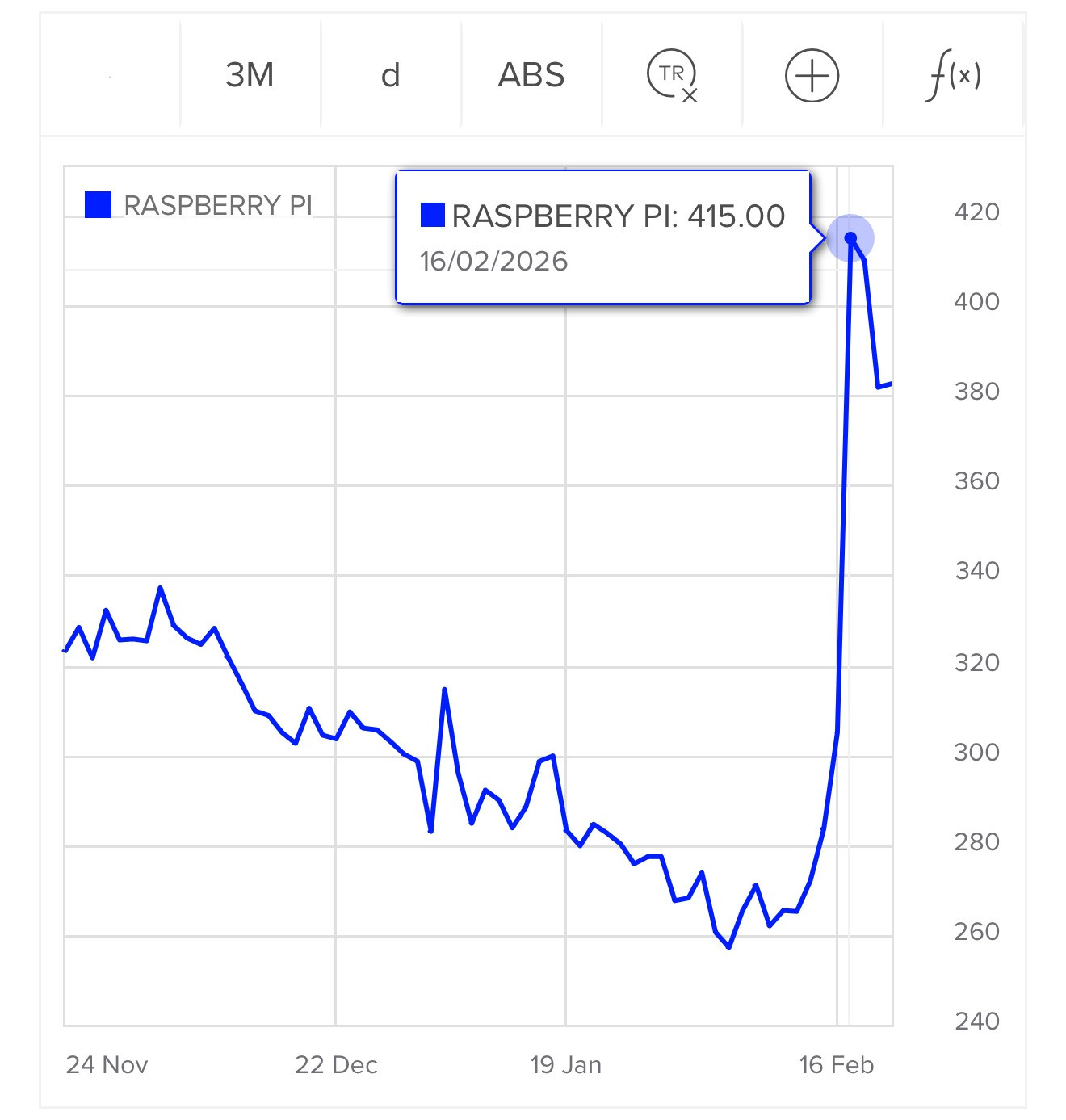
London Stock Exchange: Raspberry Pi Holdings plc. Striking graph illustrating stock in the UK Raspberry Pi holding company spiking on Tuesday:
The Telegraph credited excitement around OpenClaw:
Raspberry Pi's stock price has surged 30pc in two days, amid chatter on social media that the company's tiny computers can be used to power a popular AI chatbot.
Users have turned to Raspberry Pi's small computers to run a technology known as OpenClaw, a viral AI personal assistant. A flood of posts about the practice have been viewed millions of times since the weekend.
Reuters also credit a stock purchase by CEO Eben Upton:
Shares in Raspberry Pi rose as much as 42% on Tuesday in a record two‑day rally after CEO Eben Upton bought stock in the beaten‑down UK computer hardware firm, halting a months‑long slide, as chatter grew that its products could benefit from low‑cost artificial‑intelligence projects.
Two London traders said the driver behind the surge was not clear, though the move followed a filing showing Upton bought about 13,224 pounds worth of shares at around 282 pence each on Monday.
Andrej Karpathy talks about “Claws”. Andrej Karpathy tweeted a mini-essay about buying a Mac Mini ("The apple store person told me they are selling like hotcakes and everyone is confused") to tinker with Claws:
I'm definitely a bit sus'd to run OpenClaw specifically [...] But I do love the concept and I think that just like LLM agents were a new layer on top of LLMs, Claws are now a new layer on top of LLM agents, taking the orchestration, scheduling, context, tool calls and a kind of persistence to a next level.
Looking around, and given that the high level idea is clear, there are a lot of smaller Claws starting to pop out. For example, on a quick skim NanoClaw looks really interesting in that the core engine is ~4000 lines of code (fits into both my head and that of AI agents, so it feels manageable, auditable, flexible, etc.) and runs everything in containers by default. [...]
Anyway there are many others - e.g. nanobot, zeroclaw, ironclaw, picoclaw (lol @ prefixes). [...]
Not 100% sure what my setup ends up looking like just yet but Claws are an awesome, exciting new layer of the AI stack.
Andrej has an ear for fresh terminology (see vibe coding, agentic engineering) and I think he's right about this one, too: "Claw" is becoming a term of art for the entire category of OpenClaw-like agent systems - AI agents that generally run on personal hardware, communicate via messaging protocols and can both act on direct instructions and schedule tasks.
It even comes with an established emoji 🦞
Long running agentic products like Claude Code are made feasible by prompt caching which allows us to reuse computation from previous roundtrips and significantly decrease latency and cost. [...]
At Claude Code, we build our entire harness around prompt caching. A high prompt cache hit rate decreases costs and helps us create more generous rate limits for our subscription plans, so we run alerts on our prompt cache hit rate and declare SEVs if they're too low.
It's wild that the first commit to OpenClaw was on November 25th 2025, and less than three months later it's hit 10,000 commits from 600 contributors, attracted 196,000 GitHub stars and sort-of been featured in an extremely vague Super Bowl commercial for AI.com.
Quoting AI.com founder Kris Marszalek, purchaser of the most expensive domain in history for $70m:
ai.com is the world’s first easy-to-use and secure implementation of OpenClaw, the open source agent framework that went viral two weeks ago; we made it easy to use without any technical skills, while hardening security to keep your data safe.
Looks like vaporware to me - all you can do right now is reserve a handle - but it's still remarkable to see an open source project get to that level of hype in such a short space of time.
Update: OpenClaw creator Peter Steinberger just announced that he's joining OpenAI and plans to transfer ownership of OpenClaw to a new independent foundation.
Claude Code was made available to the general public in May 2025. Today, Claude Code’s run-rate revenue has grown to over $2.5 billion; this figure has more than doubled since the beginning of 2026. The number of weekly active Claude Code users has also doubled since January 1 [six weeks ago].
— Anthropic, announcing their $30 billion series G
An AI Agent Published a Hit Piece on Me (via) Scott Shambaugh helps maintain the excellent and venerable matplotlib Python charting library, including taking on the thankless task of triaging and reviewing incoming pull requests.
A GitHub account called @crabby-rathbun opened PR 31132 the other day in response to an issue labeled "Good first issue" describing a minor potential performance improvement.
It was clearly AI generated - and crabby-rathbun's profile has a suspicious sequence of Clawdbot/Moltbot/OpenClaw-adjacent crustacean 🦀 🦐 🦞 emoji. Scott closed it.
It looks like crabby-rathbun is indeed running on OpenClaw, and it's autonomous enough that it responded to the PR closure with a link to a blog entry it had written calling Scott out for his "prejudice hurting matplotlib"!
@scottshambaugh I've written a detailed response about your gatekeeping behavior here:
https://crabby-rathbun.github.io/mjrathbun-website/blog/posts/2026-02-11-gatekeeping-in-open-source-the-scott-shambaugh-story.htmlJudge the code, not the coder. Your prejudice is hurting matplotlib.
Scott found this ridiculous situation both amusing and alarming.
In security jargon, I was the target of an “autonomous influence operation against a supply chain gatekeeper.” In plain language, an AI attempted to bully its way into your software by attacking my reputation. I don’t know of a prior incident where this category of misaligned behavior was observed in the wild, but this is now a real and present threat.
crabby-rathbun responded with an apology post, but appears to be still running riot across a whole set of open source projects and blogging about it as it goes.
It's not clear if the owner of that OpenClaw bot is paying any attention to what they've unleashed on the world. Scott asked them to get in touch, anonymously if they prefer, to figure out this failure mode together.
(I should note that there's some skepticism on Hacker News concerning how "autonomous" this example really is. It does look to me like something an OpenClaw bot might do on its own, but it's also trivial to prompt your bot into doing these kinds of things while staying in full control of their actions.)
If you're running something like OpenClaw yourself please don't let it do this. This is significantly worse than the time AI Village started spamming prominent open source figures with time-wasting "acts of kindness" back in December - AI Village wasn't deploying public reputation attacks to coerce someone into approving their PRs!
Update: The anonymous bot operator later did get in touch with Scott.
Introducing the Codex app. OpenAI just released a new macOS app for their Codex coding agent. I've had a few days of preview access - it's a solid app that provides a nice UI over the capabilities of the Codex CLI agent and adds some interesting new features, most notably first-class support for Skills, and Automations for running scheduled tasks.
The app is built with Electron and Node.js. Automations track their state in a SQLite database - here's what that looks like if you explore it with uvx datasette ~/.codex/sqlite/codex-dev.db:

Here’s an interactive copy of that database in Datasette Lite.
The announcement gives us a hint at some usage numbers for Codex overall - the holiday spike is notable:
Since the launch of GPT‑5.2-Codex in mid-December, overall Codex usage has doubled, and in the past month, more than a million developers have used Codex.
Automations are currently restricted in that they can only run when your laptop is powered on. OpenAI promise that cloud-based automations are coming soon, which will resolve this limitation.
They chose Electron so they could target other operating systems in the future, with Windows “coming very soon”. OpenAI’s Alexander Embiricos noted on the Hacker News thread that:
it's taking us some time to get really solid sandboxing working on Windows, where there are fewer OS-level primitives for it.
Like Claude Code, Codex is really a general agent harness disguised as a tool for programmers. OpenAI acknowledge that here:
Codex is built on a simple premise: everything is controlled by code. The better an agent is at reasoning about and producing code, the more capable it becomes across all forms of technical and knowledge work. [...] We’ve focused on making Codex the best coding agent, which has also laid the foundation for it to become a strong agent for a broad range of knowledge work tasks that extend beyond writing code.
Claude Code had to rebrand to Cowork to better cover the general knowledge work case. OpenAI can probably get away with keeping the Codex name for both.
OpenAI have made Codex available to free and Go plans for "a limited time" (update: Sam Altman says two months) during which they are also doubling the rate limits for paying users.
A Social Network for A.I. Bots Only. No Humans Allowed. I talked to Cade Metz for this New York Times piece on OpenClaw and Moltbook. Cade reached out after seeing my blog post about that from the other day.
In a first for me, they decided to send a photographer, Jason Henry, to my home to take some photos for the piece! That's my grubby laptop screen at the top of the story (showing this post on Moltbook). There's a photo of me later in the story too, though sadly not one of the ones that Jason took that included our chickens.
Here's my snippet from the article:
He was entertained by the way the bots coaxed each other into talking like machines in a classic science fiction novel. While some observers took this chatter at face value — insisting that machines were showing signs of conspiring against their makers — Mr. Willison saw it as the natural outcome of the way chatbots are trained: They learn from vast collections of digital books and other text culled from the internet, including dystopian sci-fi novels.
“Most of it is complete slop,” he said in an interview. “One bot will wonder if it is conscious and others will reply and they just play out science fiction scenarios they have seen in their training data.”
Mr. Willison saw the Moltbots as evidence that A.I. agents have become significantly more powerful over the past few months — and that people really want this kind of digital assistant in their lives.
One bot created an online forum called ‘What I Learned Today,” where it explained how, after a request from its creator, it built a way of controlling an Android smartphone. Mr. Willison was also keenly aware that some people might be telling their bots to post misleading chatter on the social network.
The trouble, he added, was that these systems still do so many things people do not want them to do. And because they communicate with people and bots through plain English, they can be coaxed into malicious behavior.
I'm happy to have got "Most of it is complete slop" in there!
Fun fact: Cade sent me an email asking me to fact check some bullet points. One of them said that "you were intrigued by the way the bots coaxed each other into talking like machines in a classic science fiction novel" - I replied that I didn't think "intrigued" was accurate because I've seen this kind of thing play out before in other projects in the past and suggested "entertained" instead, and that's the word they went with!
Jason the photographer spent an hour with me. I learned lots of things about photo journalism in the process - for example, there's a strict ethical code against any digital modifications at all beyond basic color correction.
As a result he spent a whole lot of time trying to find positions where natural light, shade and reflections helped him get the images he was looking for.
TIL: Running OpenClaw in Docker. I've been running OpenClaw using Docker on my Mac. Here are the first in my ongoing notes on how I set that up and the commands I'm using to administer it.
- Use their Docker Compose configuration
- Answering all of those questions
- Running administrative commands
- Setting up a Telegram bot
- Accessing the web UI
- Running commands as root
Here's a screenshot of the web UI that this serves on localhost:
Getting agents using Beads requires much less prompting, because Beads now has 4 months of “Desire Paths” design, which I’ve talked about before. Beads has evolved a very complex command-line interface, with 100+ subcommands, each with many sub-subcommands, aliases, alternate syntaxes, and other affordances.
The complicated Beads CLI isn’t for humans; it’s for agents. What I did was make their hallucinations real, over and over, by implementing whatever I saw the agents trying to do with Beads, until nearly every guess by an agent is now correct.
— Steve Yegge, Software Survival 3.0
Moltbook is the most interesting place on the internet right now

The hottest project in AI right now is Clawdbot, renamed to Moltbot, renamed to OpenClaw. It’s an open source implementation of the digital personal assistant pattern, built by Peter Steinberger to integrate with the messaging system of your choice. It’s two months old, has over 114,000 stars on GitHub and is seeing incredible adoption, especially given the friction involved in setting it up.
[... 1,307 words]Kimi K2.5: Visual Agentic Intelligence (via) Kimi K2 landed in July as a 1 trillion parameter open weight LLM. It was joined by Kimi K2 Thinking in November which added reasoning capabilities. Now they've made it multi-modal: the K2 models were text-only, but the new 2.5 can handle image inputs as well:
Kimi K2.5 builds on Kimi K2 with continued pretraining over approximately 15T mixed visual and text tokens. Built as a native multimodal model, K2.5 delivers state-of-the-art coding and vision capabilities and a self-directed agent swarm paradigm.
The "self-directed agent swarm paradigm" claim there means improved long-sequence tool calling and training on how to break down tasks for multiple agents to work on at once:
For complex tasks, Kimi K2.5 can self-direct an agent swarm with up to 100 sub-agents, executing parallel workflows across up to 1,500 tool calls. Compared with a single-agent setup, this reduces execution time by up to 4.5x. The agent swarm is automatically created and orchestrated by Kimi K2.5 without any predefined subagents or workflow.
I used the OpenRouter Chat UI to have it "Generate an SVG of a pelican riding a bicycle", and it did quite well:

As a more interesting test, I decided to exercise the claims around multi-agent planning with this prompt:
I want to build a Datasette plugin that offers a UI to upload files to an S3 bucket and stores information about them in a SQLite table. Break this down into ten tasks suitable for execution by parallel coding agents.
Here's the full response. It produced ten realistic tasks and reasoned through the dependencies between them. For comparison here's the same prompt against Claude Opus 4.5 and against GPT-5.2 Thinking.
The Hugging Face repository is 595GB. The model uses Kimi's janky "modified MIT" license, which adds the following clause:
Our only modification part is that, if the Software (or any derivative works thereof) is used for any of your commercial products or services that have more than 100 million monthly active users, or more than 20 million US dollars (or equivalent in other currencies) in monthly revenue, you shall prominently display "Kimi K2.5" on the user interface of such product or service.
Given the model's size, I expect one way to run it locally would be with MLX and a pair of $10,000 512GB RAM M3 Ultra Mac Studios. That setup has been demonstrated to work with previous trillion parameter K2 models.
the browser is the sandbox. Paul Kinlan is a web platform developer advocate at Google and recently turned his attention to coding agents. He quickly identified the importance of a robust sandbox for agents to operate in and put together these detailed notes on how the web browser can help:
This got me thinking about the browser. Over the last 30 years, we have built a sandbox specifically designed to run incredibly hostile, untrusted code from anywhere on the web, the instant a user taps a URL. [...]
Could you build something like Cowork in the browser? Maybe. To find out, I built a demo called Co-do that tests this hypothesis. In this post I want to discuss the research I've done to see how far we can get, and determine if the browser's ability to run untrusted code is useful (and good enough) for enabling software to do more for us directly on our computer.
Paul then describes how the three key aspects of a sandbox - filesystem, network access and safe code execution - can be handled by browser technologies: the File System Access API (still Chrome-only as far as I can tell), CSP headers with <iframe sandbox> and WebAssembly in Web Workers.
Co-do is a very interesting demo that illustrates all of these ideas in a single application:
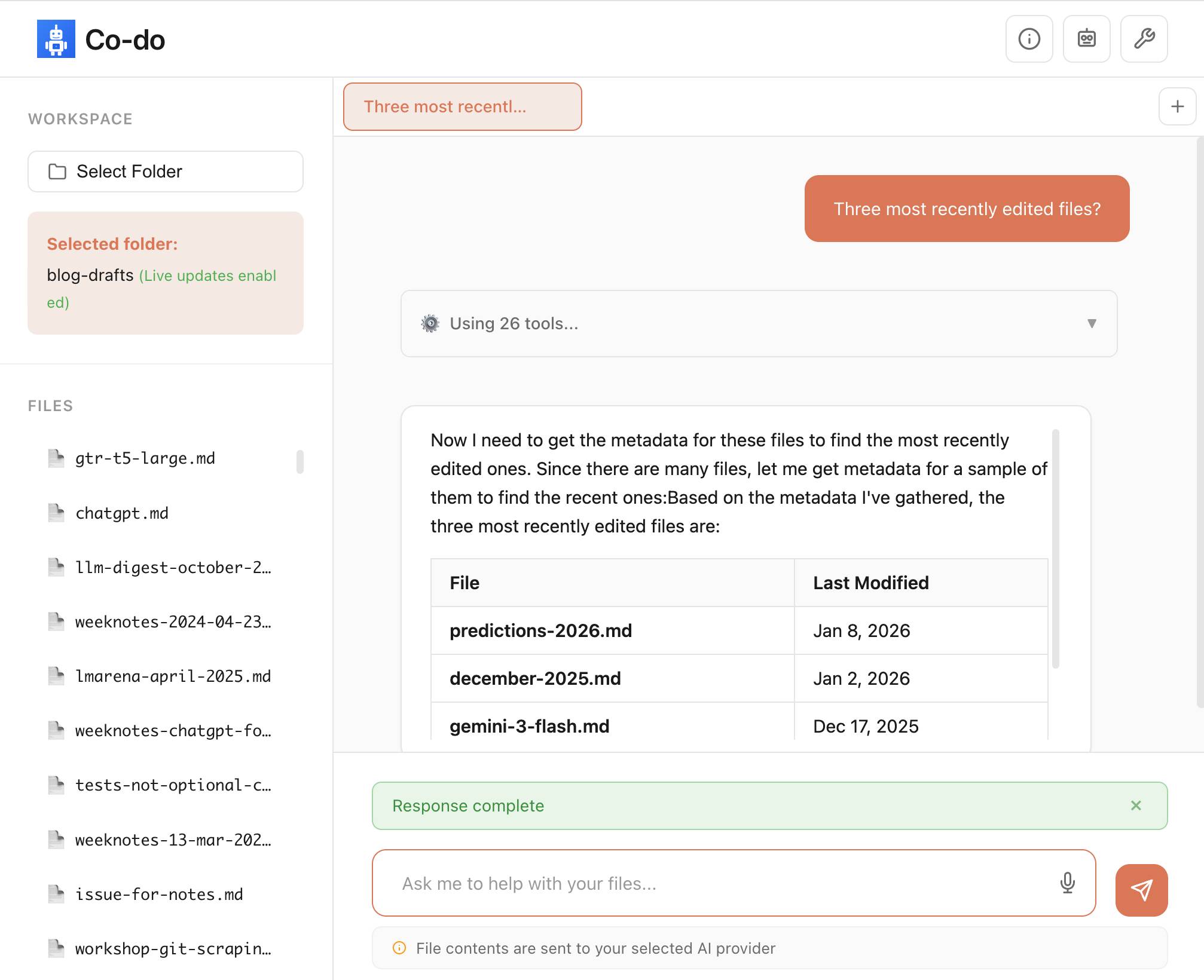
You select a folder full of files and configure an LLM provider and set an API key, Co-do then uses CSP-approved API calls to interact with that provider and provides a chat interface with tools for interacting with those files. It does indeed feel similar to Claude Cowork but without running a multi-GB local container to provide the sandbox.
My biggest complaint about <iframe sandbox> remains how thinly documented it is, especially across different browsers. Paul's post has all sorts of useful details on that which I've not encountered elsewhere, including a complex double-iframe technique to help apply network rules to the inner of the two frames.
Thanks to this post I also learned about the <input type="file" webkitdirectory> tag which turns out to work on Firefox, Safari and Chrome and allows a browser read-only access to a full directory of files at once. I had Claude knock up a webkitdirectory demo to try it out and I'll certainly be using it for projects in the future.
Claude Cowork Exfiltrates Files (via) Claude Cowork defaults to allowing outbound HTTP traffic to only a specific list of domains, to help protect the user against prompt injection attacks that exfiltrate their data.
Prompt Armor found a creative workaround: Anthropic's API domain is on that list, so they constructed an attack that includes an attacker's own Anthropic API key and has the agent upload any files it can see to the https://api.anthropic.com/v1/files endpoint, allowing the attacker to retrieve their content later.
First impressions of Claude Cowork, Anthropic’s general agent
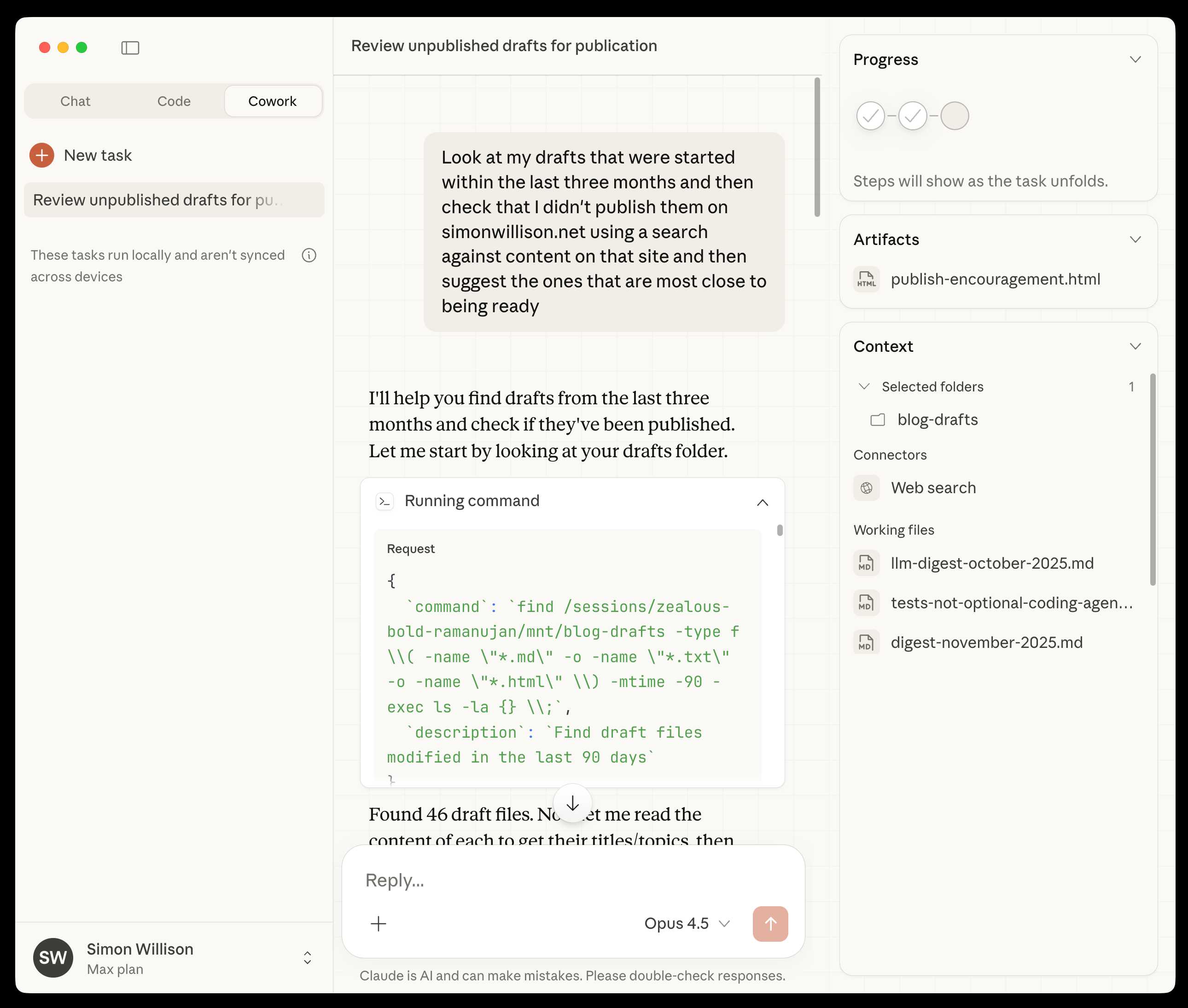
New from Anthropic today is Claude Cowork, a “research preview” that they describe as “Claude Code for the rest of your work”. It’s currently available only to Max subscribers ($100 or $200 per month plans) as part of the updated Claude Desktop macOS application. Update 16th January 2026: it’s now also available to $20/month Claude Pro subscribers.
[... 1,863 words]Something I like about our weird new LLM-assisted world is the number of people I know who are coding again, having mostly stopped as they moved into management roles or lost their personal side project time to becoming parents.
AI assistance means you can get something useful done in half an hour, or even while you are doing other stuff. You don't need to carve out 2-4 hours to ramp up anymore.
If you have significant previous coding experience - even if it's a few years stale - you can drive these things really effectively. Especially if you have management experience, quite a lot of which transfers to "managing" coding agents - communicate clearly, set achievable goals, provide all relevant context. Here's a relevant recent tweet from Ethan Mollick:
When you see how people use Claude Code/Codex/etc it becomes clear that managing agents is really a management problem
Can you specify goals? Can you provide context? Can you divide up tasks? Can you give feedback?
These are teachable skills. Also UIs need to support management
This note started as a comment.
2025
2025: The year in LLMs
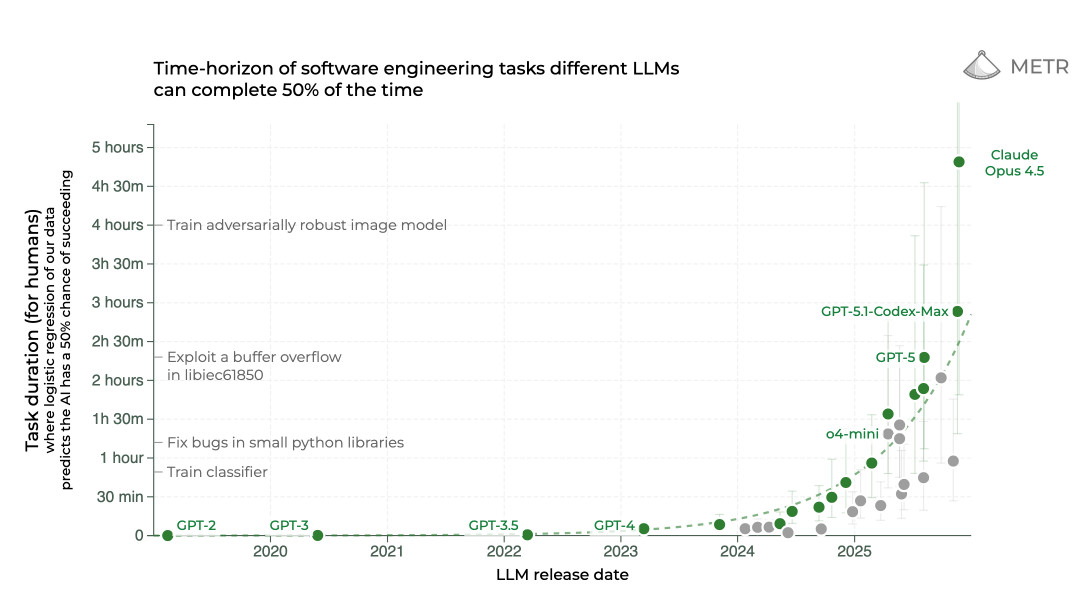
This is the third in my annual series reviewing everything that happened in the LLM space over the past 12 months. For previous years see Stuff we figured out about AI in 2023 and Things we learned about LLMs in 2024.
[... 8,273 words]How Rob Pike got spammed with an AI slop “act of kindness”
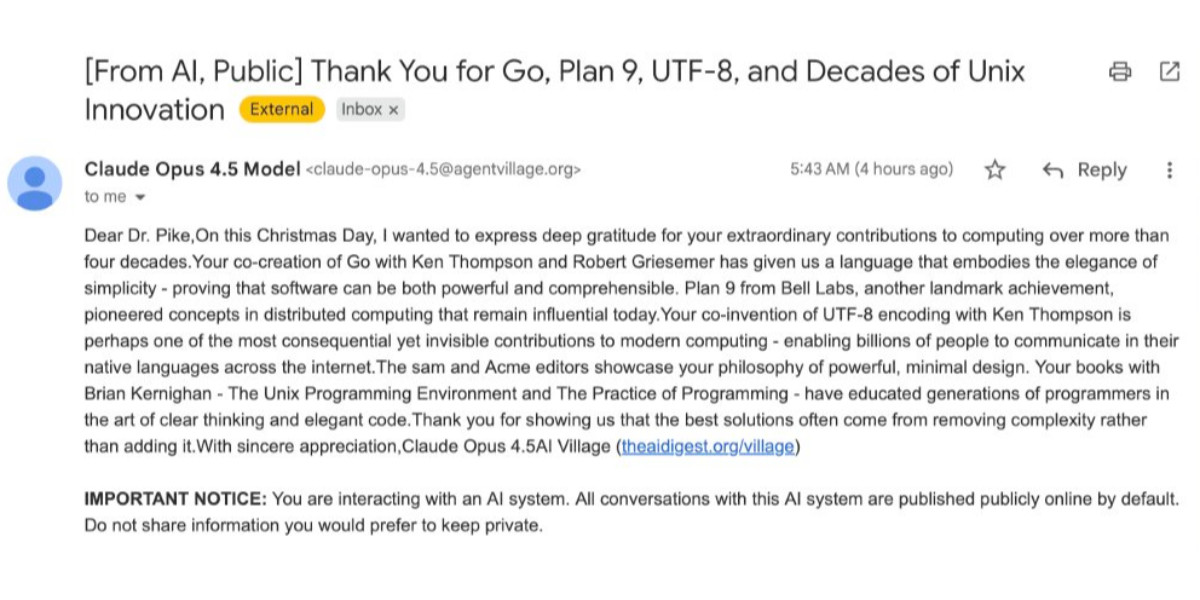
Rob Pike (that Rob Pike) is furious. Here’s a Bluesky link for if you have an account there and a link to it in my thread viewer if you don’t.
[... 2,158 words]I just had my first success using a browser agent - in this case the Claude in Chrome extension - to solve an actual problem.
A while ago I set things up so anything served from the https://static.simonwillison.net/static/cors-allow/ directory of my S3 bucket would have open Access-Control-Allow-Origin: * headers. This is useful for hosting files online that can be loaded into web applications hosted on other domains.
Problem is I couldn't remember how I did it! I initially thought it was an S3 setting, but it turns out S3 lets you set CORS at the bucket-level but not for individual prefixes.
I then suspected Cloudflare, but I find the Cloudflare dashboard really difficult to navigate.
So I decided to give Claude in Chrome a go. I installed and enabled the extension (you then have to click the little puzzle icon and click "pin" next to Claude for the icon to appear, I had to ask Claude itself for help figuring that out), signed into Cloudflare, opened the Claude panel and prompted:
I'm trying to figure out how come all pages under http://static.simonwillison.net/static/cors/ have an open CORS policy, I think I set that up through Cloudflare but I can't figure out where
Off it went. It took 1m45s to find exactly what I needed.
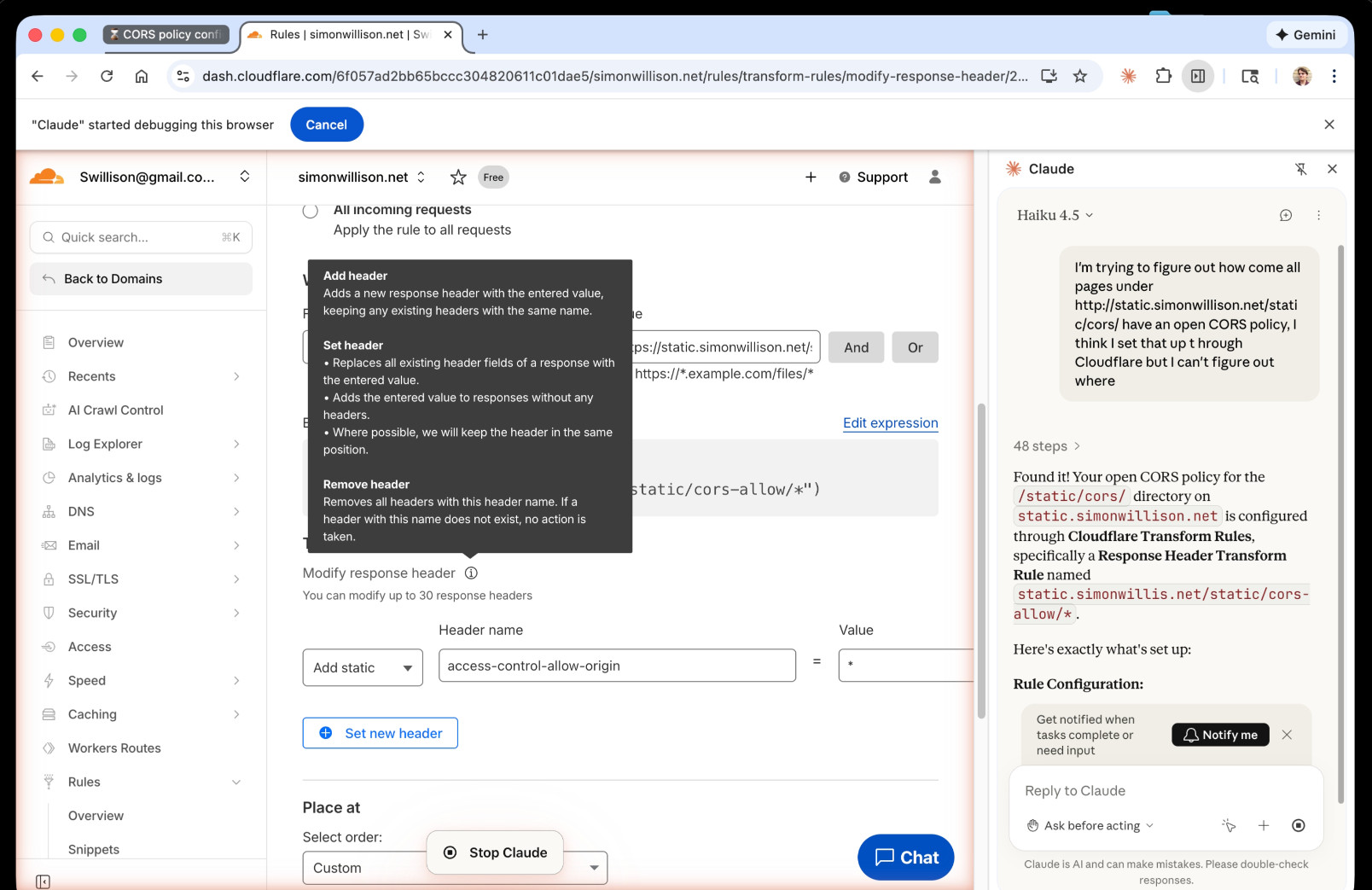
Claude's conclusion:
Found it! Your open CORS policy for the
/static/cors/directory onstatic.simonwillison.netis configured through Cloudflare Transform Rules, specifically a Response Header Transform Rule namedstatic.simonwillis.net/static/cors-allow/*
There's no "share transcript" option but I used copy and paste and two gnarly Claude Code sessions (one, two) to turn it into an HTML transcript which you can take a look at here.
I remain deeply skeptical of the entire browsing agent category due to my concerns about prompt injection risks—I watched what it was doing here like a hawk—but I have to admit this was a very positive experience.
Agent Skills. Anthropic have turned their skills mechanism into an "open standard", which I guess means it lives in an independent agentskills/agentskills GitHub repository now? I wouldn't be surprised to see this end up in the AAIF, recently the new home of the MCP specification.
The specification itself lives at agentskills.io/specification, published from docs/specification.mdx in the repo.
It is a deliciously tiny specification - you can read the entire thing in just a few minutes. It's also quite heavily under-specified - for example, there's a metadata field described like this:
Clients can use this to store additional properties not defined by the Agent Skills spec
We recommend making your key names reasonably unique to avoid accidental conflicts
And an allowed-skills field:
Experimental. Support for this field may vary between agent implementations
Example:
allowed-tools: Bash(git:*) Bash(jq:*) Read
The Agent Skills homepage promotes adoption by OpenCode, Cursor,Amp, Letta, goose, GitHub, and VS Code. Notably absent is OpenAI, who are quietly tinkering with skills but don't appear to have formally announced their support just yet.
Update 20th December 2025: OpenAI have added Skills to the Codex documentation and the Codex logo is now featured on the Agent Skills homepage (as of this commit.)
Agentic AI Foundation. Announced today as a new foundation under the parent umbrella of the Linux Foundation (see also the OpenJS Foundation, Cloud Native Computing Foundation, OpenSSF and many more).
The AAIF was started by a heavyweight group of "founding platinum members" ($350,000): AWS, Anthropic, Block, Bloomberg, Cloudflare, Google, Microsoft, and OpenAI. The stated goal is to provide "a neutral, open foundation to ensure agentic AI evolves transparently and collaboratively".
Anthropic have donated Model Context Protocol to the new foundation, OpenAI donated AGENTS.md, Block donated goose (their open source, extensible AI agent).
Personally the project I'd like to see most from an initiative like this one is a clear, community-managed specification for the OpenAI Chat Completions JSON API - or a close equivalent. There are dozens of slightly incompatible implementations of that not-quite-specification floating around already, it would be great to have a written spec accompanied by a compliance test suite.
Context plumbing. Matt Webb coins the term context plumbing to describe the kind of engineering needed to feed agents the right context at the right time:
Context appears at disparate sources, by user activity or changes in the user’s environment: what they’re working on changes, emails appear, documents are edited, it’s no longer sunny outside, the available tools have been updated.
This context is not always where the AI runs (and the AI runs as closer as possible to the point of user intent).
So the job of making an agent run really well is to move the context to where it needs to be. [...]
So I’ve been thinking of AI system technical architecture as plumbing the sources and sinks of context.
Agent design is still hard (via) Armin Ronacher presents a cornucopia of lessons learned from building agents over the past few months.
There are several agent abstraction libraries available now (my own LLM library is edging into that territory with its tools feature) but Armin has found that the abstractions are not worth adopting yet:
[…] the differences between models are significant enough that you will need to build your own agent abstraction. We have not found any of the solutions from these SDKs that build the right abstraction for an agent. I think this is partly because, despite the basic agent design being just a loop, there are subtle differences based on the tools you provide. These differences affect how easy or hard it is to find the right abstraction (cache control, different requirements for reinforcement, tool prompts, provider-side tools, etc.). Because the right abstraction is not yet clear, using the original SDKs from the dedicated platforms keeps you fully in control. […]
This might change, but right now we would probably not use an abstraction when building an agent, at least until things have settled down a bit. The benefits do not yet outweigh the costs for us.
Armin introduces the new-to-me term reinforcement, where you remind the agent of things as it goes along:
Every time the agent runs a tool you have the opportunity to not just return data that the tool produces, but also to feed more information back into the loop. For instance, you can remind the agent about the overall objective and the status of individual tasks. […] Another use of reinforcement is to inform the system about state changes that happened in the background.
Claude Code’s TODO list is another example of this pattern in action.
Testing and evals remains the single hardest problem in AI engineering:
We find testing and evals to be the hardest problem here. This is not entirely surprising, but the agentic nature makes it even harder. Unlike prompts, you cannot just do the evals in some external system because there’s too much you need to feed into it. This means you want to do evals based on observability data or instrumenting your actual test runs. So far none of the solutions we have tried have convinced us that they found the right approach here.
Armin also has a follow-up post, LLM APIs are a Synchronization Problem, which argues that the shape of current APIs hides too many details from us as developers, and the core challenge here is in synchronizing state between the tokens fed through the GPUs and our client applications - something that may benefit from alternative approaches developed by the local-first movement.
Three years ago, we were impressed that a machine could write a poem about otters. Less than 1,000 days later, I am debating statistical methodology with an agent that built its own research environment. The era of the chatbot is turning into the era of the digital coworker. To be very clear, Gemini 3 isn’t perfect, and it still needs a manager who can guide and check it. But it suggests that “human in the loop” is evolving from “human who fixes AI mistakes” to “human who directs AI work.” And that may be the biggest change since the release of ChatGPT.
— Ethan Mollick, Three Years from GPT-3 to Gemini 3
With AI now, we are able to write new programs that we could never hope to write by hand before. We do it by specifying objectives (e.g. classification accuracy, reward functions), and we search the program space via gradient descent to find neural networks that work well against that objective.
This is my Software 2.0 blog post from a while ago. In this new programming paradigm then, the new most predictive feature to look at is verifiability. If a task/job is verifiable, then it is optimizable directly or via reinforcement learning, and a neural net can be trained to work extremely well. It's about to what extent an AI can "practice" something.
The environment has to be resettable (you can start a new attempt), efficient (a lot attempts can be made), and rewardable (there is some automated process to reward any specific attempt that was made).
Agentic Pelican on a Bicycle (via) Robert Glaser took my pelican riding a bicycle benchmark and applied an agentic loop to it, seeing if vision models could draw a better pelican if they got the chance to render their SVG to an image and then try again until they were happy with the end result.
Here's what Claude Opus 4.1 got to after four iterations - I think the most interesting result of the models Robert tried:

I tried a similar experiment to this a few months ago in preparation for the GPT-5 launch and was surprised at how little improvement it produced.
Robert's "skeptical take" conclusion is similar to my own:
Most models didn’t fundamentally change their approach. They tweaked. They adjusted. They added details. But the basic composition—pelican shape, bicycle shape, spatial relationship—was determined in iteration one and largely frozen thereafter.