Posts tagged llms, embeddings
Filters: llms × embeddings × Sorted by date
Building software on top of Large Language Models

I presented a three hour workshop at PyCon US yesterday titled Building software on top of Large Language Models. The goal of the workshop was to give participants everything they needed to get started writing code that makes use of LLMs.
[... 3,726 words]Cursor: Security (via) Cursor's security documentation page includes a surprising amount of detail about how the Cursor text editor's backend systems work.
I've recently learned that checking an organization's list of documented subprocessors is a great way to get a feel for how everything works under the hood - it's a loose "view source" for their infrastructure! That was how I confirmed that Anthropic's search features used Brave search back in March.
Cursor's list includes AWS, Azure and GCP (AWS for primary infrastructure, Azure and GCP for "some secondary infrastructure"). They host their own custom models on Fireworks and make API calls out to OpenAI, Anthropic, Gemini and xAI depending on user preferences. They're using turbopuffer as a hosted vector store.
The most interesting section is about codebase indexing:
Cursor allows you to semantically index your codebase, which allows it to answer questions with the context of all of your code as well as write better code by referencing existing implementations. […]
At our server, we chunk and embed the files, and store the embeddings in Turbopuffer. To allow filtering vector search results by file path, we store with every vector an obfuscated relative file path, as well as the line range the chunk corresponds to. We also store the embedding in a cache in AWS, indexed by the hash of the chunk, to ensure that indexing the same codebase a second time is much faster (which is particularly useful for teams).
At inference time, we compute an embedding, let Turbopuffer do the nearest neighbor search, send back the obfuscated file path and line range to the client, and read those file chunks on the client locally. We then send those chunks back up to the server to answer the user’s question.
When operating in privacy mode - which they say is enabled by 50% of their users - they are careful not to store any raw code on their servers for longer than the duration of a single request. This is why they store the embeddings and obfuscated file paths but not the code itself.
Reading this made me instantly think of the paper Text Embeddings Reveal (Almost) As Much As Text about how vector embeddings can be reversed. The security documentation touches on that in the notes:
Embedding reversal: academic work has shown that reversing embeddings is possible in some cases. Current attacks rely on having access to the model and embedding short strings into big vectors, which makes us believe that the attack would be somewhat difficult to do here. That said, it is definitely possible for an adversary who breaks into our vector database to learn things about the indexed codebases.
Clio: A system for privacy-preserving insights into real-world AI use. New research from Anthropic, describing a system they built called Clio - for Claude insights and observations - which attempts to provide insights into how Claude is being used by end-users while also preserving user privacy.
There's a lot to digest here. The summary is accompanied by a full paper and a 47 minute YouTube interview with team members Deep Ganguli, Esin Durmus, Miles McCain and Alex Tamkin.
The key idea behind Clio is to take user conversations and use Claude to summarize, cluster and then analyze those clusters - aiming to ensure that any private or personally identifiable details are filtered out long before the resulting clusters reach human eyes.
This diagram from the paper helps explain how that works:
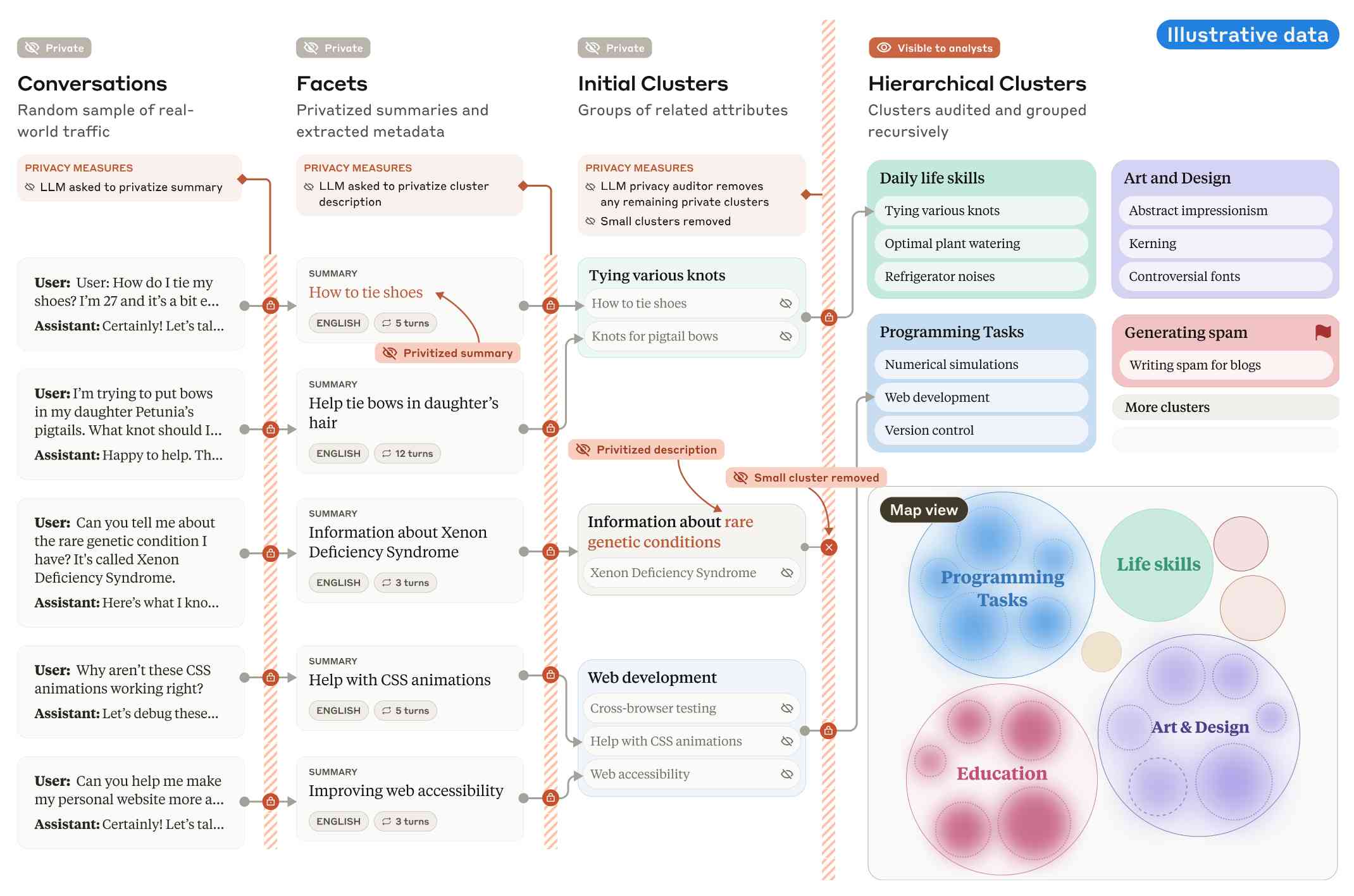
Claude generates a conversation summary, than extracts "facets" from that summary that aim to privatize the data to simple characteristics like language and topics.
The facets are used to create initial clusters (via embeddings), and those clusters further filtered to remove any that are too small or may contain private information. The goal is to have no cluster which represents less than 1,000 underlying individual users.
In the video at 16:39:
And then we can use that to understand, for example, if Claude is as useful giving web development advice for people in English or in Spanish. Or we can understand what programming languages are people generally asking for help with. We can do all of this in a really privacy preserving way because we are so far removed from the underlying conversations that we're very confident that we can use this in a way that respects the sort of spirit of privacy that our users expect from us.
Then later at 29:50 there's this interesting hint as to how Anthropic hire human annotators to improve Claude's performance in specific areas:
But one of the things we can do is we can look at clusters with high, for example, refusal rates, or trust and safety flag rates. And then we can look at those and say huh, this is clearly an over-refusal, this is clearly fine. And we can use that to sort of close the loop and say, okay, well here are examples where we wanna add to our, you know, human training data so that Claude is less refusally in the future on those topics.
And importantly, we're not using the actual conversations to make Claude less refusally. Instead what we're doing is we are looking at the topics and then hiring people to generate data in those domains and generating synthetic data in those domains.
So we're able to sort of use our users activity with Claude to improve their experience while also respecting their privacy.
According to Clio the top clusters of usage for Claude right now are as follows:
- Web & Mobile App Development (10.4%)
- Content Creation & Communication (9.2%)
- Academic Research & Writing (7.2%)
- Education & Career Development (7.1%)
- Advanced AI/ML Applications (6.0%)
- Business Strategy & Operations (5.7%)
- Language Translation (4.5%)
- DevOps & Cloud Infrastructure (3.9%)
- Digital Marketing & SEO (3.7%)
- Data Analysis & Visualization (3.5%)
There also are some interesting insights about variations in usage across different languages. For example, Chinese language users had "Write crime, thriller, and mystery fiction with complex plots and characters" at 4.4x the base rate for other languages.
Introducing Contextual Retrieval (via) Here's an interesting new embedding/RAG technique, described by Anthropic but it should work for any embedding model against any other LLM.
One of the big challenges in implementing semantic search against vector embeddings - often used as part of a RAG system - is creating "chunks" of documents that are most likely to semantically match queries from users.
Anthropic provide this solid example where semantic chunks might let you down:
Imagine you had a collection of financial information (say, U.S. SEC filings) embedded in your knowledge base, and you received the following question: "What was the revenue growth for ACME Corp in Q2 2023?"
A relevant chunk might contain the text: "The company's revenue grew by 3% over the previous quarter." However, this chunk on its own doesn't specify which company it's referring to or the relevant time period, making it difficult to retrieve the right information or use the information effectively.
Their proposed solution is to take each chunk at indexing time and expand it using an LLM - so the above sentence would become this instead:
This chunk is from an SEC filing on ACME corp's performance in Q2 2023; the previous quarter's revenue was $314 million. The company's revenue grew by 3% over the previous quarter.
This chunk was created by Claude 3 Haiku (their least expensive model) using the following prompt template:
<document>
{{WHOLE_DOCUMENT}}
</document>
Here is the chunk we want to situate within the whole document
<chunk>
{{CHUNK_CONTENT}}
</chunk>
Please give a short succinct context to situate this chunk within the overall document for the purposes of improving search retrieval of the chunk. Answer only with the succinct context and nothing else.
Here's the really clever bit: running the above prompt for every chunk in a document could get really expensive thanks to the inclusion of the entire document in each prompt. Claude added context caching last month, which allows you to pay around 1/10th of the cost for tokens cached up to your specified beakpoint.
By Anthropic's calculations:
Assuming 800 token chunks, 8k token documents, 50 token context instructions, and 100 tokens of context per chunk, the one-time cost to generate contextualized chunks is $1.02 per million document tokens.
Anthropic provide a detailed notebook demonstrating an implementation of this pattern. Their eventual solution combines cosine similarity and BM25 indexing, uses embeddings from Voyage AI and adds a reranking step powered by Cohere.
The notebook also includes an evaluation set using JSONL - here's that evaluation data in Datasette Lite.
OpenAI: Improve file search result relevance with chunk ranking (via) I've mostly been ignoring OpenAI's Assistants API. It provides an alternative to their standard messages API where you construct "assistants", chatbots with optional access to additional tools and that store full conversation threads on the server so you don't need to pass the previous conversation with every call to their API.
I'm pretty comfortable with their existing API and I found the assistants API to be quite a bit more complicated. So far the only thing I've used it for is a script to scrape OpenAI Code Interpreter to keep track of updates to their enviroment's Python packages.
Code Interpreter aside, the other interesting assistants feature is File Search. You can upload files in a wide variety of formats and OpenAI will chunk them, store the chunks in a vector store and make them available to help answer questions posed to your assistant - it's their version of hosted RAG.
Prior to today OpenAI had kept the details of how this worked undocumented. I found this infuriating, because when I'm building a RAG system the details of how files are chunked and scored for relevance is the whole game - without understanding that I can't make effective decisions about what kind of documents to use and how to build on top of the tool.
This has finally changed! You can now run a "step" (a round of conversation in the chat) and then retrieve details of exactly which chunks of the file were used in the response and how they were scored using the following incantation:
run_step = client.beta.threads.runs.steps.retrieve( thread_id="thread_abc123", run_id="run_abc123", step_id="step_abc123", include=[ "step_details.tool_calls[*].file_search.results[*].content" ] )
(See what I mean about the API being a little obtuse?)
I tried this out today and the results were very promising. Here's a chat transcript with an assistant I created against an old PDF copy of the Datasette documentation - I used the above new API to dump out the full list of snippets used to answer the question "tell me about ways to use spatialite".
It pulled in a lot of content! 57,017 characters by my count, spread across 20 search results (customizable), for a total of 15,021 tokens as measured by ttok. At current GPT-4o-mini prices that would cost 0.225 cents (less than a quarter of a cent), but with regular GPT-4o it would cost 7.5 cents.
OpenAI provide up to 1GB of vector storage for free, then charge $0.10/GB/day for vector storage beyond that. My 173 page PDF seems to have taken up 728KB after being chunked and stored, so that GB should stretch a pretty long way.
Confession: I couldn't be bothered to work through the OpenAI code examples myself, so I hit Ctrl+A on that web page and copied the whole lot into Claude 3.5 Sonnet, then prompted it:
Based on this documentation, write me a Python CLI app (using the Click CLi library) with the following features:
openai-file-chat add-files name-of-vector-store *.pdf *.txt
This creates a new vector store called name-of-vector-store and adds all the files passed to the command to that store.
openai-file-chat name-of-vector-store1 name-of-vector-store2 ...
This starts an interactive chat with the user, where any time they hit enter the question is answered by a chat assistant using the specified vector stores.
We iterated on this a few times to build me a one-off CLI app for trying out the new features. It's got a few bugs that I haven't fixed yet, but it was a very productive way of prototyping against the new API.
Adaptive Retrieval with Matryoshka Embeddings (via) Nomic Embed v1 only came out two weeks ago, but the same team just released Nomic Embed v1.5 trained using a new technique called Matryoshka Representation.
This means that unlike v1 the v1.5 embeddings are resizable—instead of a fixed 768 dimension embedding vector you can trade size for quality and drop that size all the way down to 64, while still maintaining strong semantically relevant results.
Joshua Lochner build this interactive demo on top of Transformers.js which illustrates quite how well this works: it lets you embed a query, embed a series of potentially matching text sentences and then adjust the number of dimensions and see what impact it has on the results.
Fleet Context. This project took the source code and documentation for 1221 popular Python libraries and ran them through the OpenAI text-embedding-ada-002 embedding model, then made those pre-calculated embedding vectors available as Parquet files for download from S3 or via a custom Python CLI tool.
I haven’t seen many projects release pre-calculated embeddings like this, it’s an interesting initiative.
Bottleneck T5 Text Autoencoder (via) Colab notebook by Linus Lee demonstrating his Contra Bottleneck T5 embedding model, which can take up to 512 tokens of text, convert that into a 1024 floating point number embedding vector... and then then reconstruct the original text (or a close imitation) from the embedding again.
This allows for some fascinating tricks, where you can do things like generate embeddings for two completely different sentences and then reconstruct a new sentence that combines the weights from both.
Build an image search engine with llm-clip, chat with models with llm chat

LLM is my combination CLI tool and Python library for working with Large Language Models. I just released LLM 0.10 with two significant new features: embedding support for binary files and the llm chat command.
LLM now provides tools for working with embeddings

LLM is my Python library and command-line tool for working with language models. I just released LLM 0.9 with a new set of features that extend LLM to provide tools for working with embeddings.
[... 3,521 words]Getting creative with embeddings (via) Amelia Wattenberger describes a neat application of embeddings I haven’t seen before: she wanted to build a system that could classify individual sentences in terms of how “concrete” or “abstract” they are. So she generated several example sentences for each of those categories, embedded then and calculated the average of those embeddings.
And now she can get a score for how abstract vs concrete a new sentence is by calculating its embedding and seeing where it falls in the 1500 dimension space between those two other points.
Language models can explain neurons in language models (via) Fascinating interactive paper by OpenAI, describing how they used GPT-4 to analyze the concepts tracked by individual neurons in their much older GPT-2 model. “We generated cluster labels by embedding each neuron explanation using the OpenAI Embeddings API, then clustering them and asking GPT-4 to label each cluster.”
Browse the BBC In Our Time archive by Dewey decimal code. Matt Webb built Braggoscope, an alternative interface for browsing the 1,000 episodes of the BBC's In Our Time dating back to 1998, organized by Dewey decimal system and with related episodes calculated using OpenAI embeddings and guests and reading lists extracted using GPT-3.
Using GitHub Copilot to write code and calling out to GPT-3 programmatically to dodge days of graft actually brought tears to my eyes.
How to implement Q&A against your documentation with GPT3, embeddings and Datasette
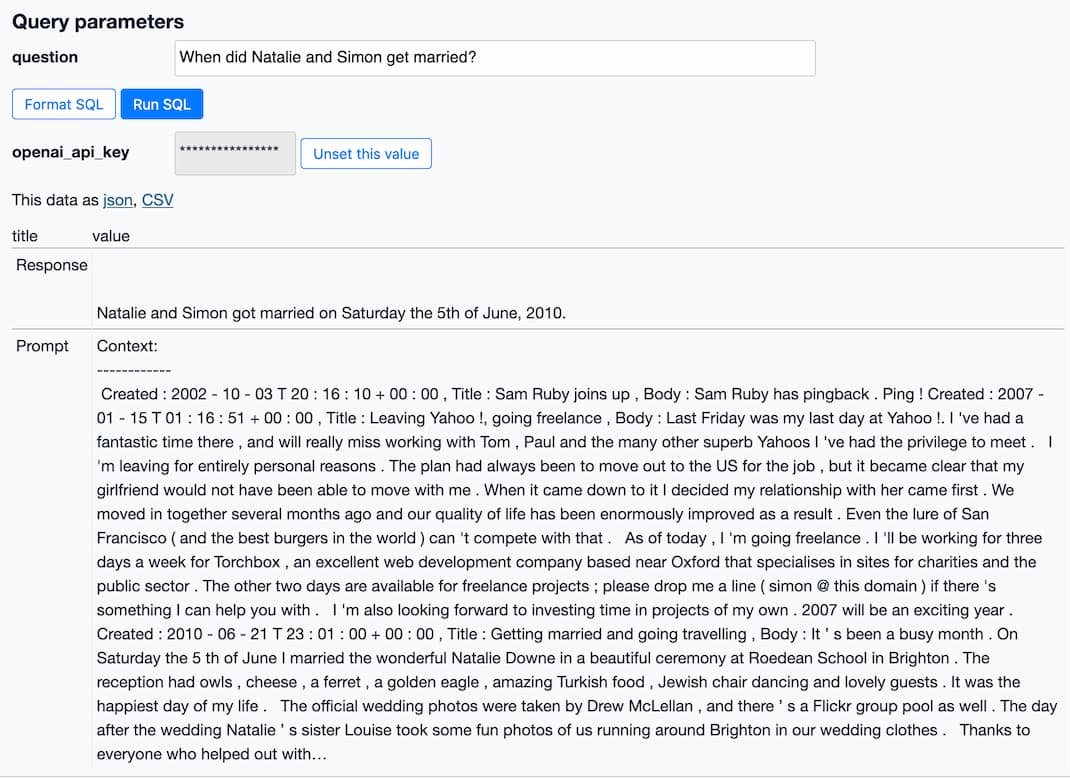
If you’ve spent any time with GPT-3 or ChatGPT, you’ve likely thought about how useful it would be if you could point them at a specific, current collection of text or documentation and have it use that as part of its input for answering questions.
[... 3,491 words]