Blogmarks tagged ai, webassembly
Filters: Type: blogmark × ai × webassembly × Sorted by date
files-to-prompt 0.5.
My files-to-prompt tool (originally built using Claude 3 Opus back in April) had been accumulating a bunch of issues and PRs - I finally got around to spending some time with it and pushed a fresh release:
- New
-n/--line-numbersflag for including line numbers in the output. Thanks, Dan Clayton. #38- Fix for utf-8 handling on Windows. Thanks, David Jarman. #36
--ignorepatterns are now matched against directory names as well as file names, unless you pass the new--ignore-files-onlyflag. Thanks, Nick Powell. #30
I use this tool myself on an almost daily basis - it's fantastic for quickly answering questions about code. Recently I've been plugging it into Gemini 2.0 with its 2 million token context length, running recipes like this one:
git clone https://github.com/bytecodealliance/componentize-py
cd componentize-py
files-to-prompt . -c | llm -m gemini-2.0-pro-exp-02-05 \
-s 'How does this work? Does it include a python compiler or AST trick of some sort?'
I ran that question against the bytecodealliance/componentize-py repo - which provides a tool for turning Python code into compiled WASM - and got this really useful answer.
Here's another example. I decided to have o3-mini review how Datasette handles concurrent SQLite connections from async Python code - so I ran this:
git clone https://github.com/simonw/datasette
cd datasette/datasette
files-to-prompt database.py utils/__init__.py -c | \
llm -m o3-mini -o reasoning_effort high \
-s 'Output in markdown a detailed analysis of how this code handles the challenge of running SQLite queries from a Python asyncio application. Explain how it works in the first section, then explore the pros and cons of this design. In a final section propose alternative mechanisms that might work better.'
Here's the result. It did an extremely good job of explaining how my code works - despite being fed just the Python and none of the other documentation. Then it made some solid recommendations for potential alternatives.
I added a couple of follow-up questions (using llm -c) which resulted in a full working prototype of an alternative threadpool mechanism, plus some benchmarks.
One final example: I decided to see if there were any undocumented features in Litestream, so I checked out the repo and ran a prompt against just the .go files in that project:
git clone https://github.com/benbjohnson/litestream
cd litestream
files-to-prompt . -e go -c | llm -m o3-mini \
-s 'Write extensive user documentation for this project in markdown'
Once again, o3-mini provided a really impressively detailed set of unofficial documentation derived purely from reading the source.
APSW SQLite query explainer. Today I found out about APSW's (Another Python SQLite Wrapper, in constant development since 2004) apsw.ext.query_info() function, which takes a SQL query and returns a very detailed set of information about that query - all without executing it.
It actually solves a bunch of problems I've wanted to address in Datasette - like taking an arbitrary query and figuring out how many parameters (?) it takes and which tables and columns are represented in the result.
I tried it out in my console (uv run --with apsw python) and it seemed to work really well. Then I remembered that the Pyodide project includes WebAssembly builds of a number of Python C extensions and was delighted to find apsw on that list.
... so I got Claude to build me a web interface for trying out the function, using Pyodide to run a user's query in Python in their browser via WebAssembly.
Claude didn't quite get it in one shot - I had to feed it the URL to a more recent Pyodide and it got stuck in a bug loop which I fixed by pasting the code into a fresh session.
ggml : x2 speed for WASM by optimizing SIMD
(via)
PR by Xuan-Son Nguyen for llama.cpp:
This PR provides a big jump in speed for WASM by leveraging SIMD instructions for
qX_K_q8_KandqX_0_q8_0dot product functions.Surprisingly, 99% of the code in this PR is written by DeekSeek-R1. The only thing I do is to develop tests and write prompts (with some trails and errors)
They shared their prompts here, which they ran directly through R1 on chat.deepseek.com - it spent 3-5 minutes "thinking" about each prompt.
I've been seeing some very promising results from DeepSeek R1 for code as well. Here's a recent transcript where I used it to rewrite the llm_groq.py plugin to imitate the cached model JSON pattern used by llm_mistral.py, resulting in this PR.
I tried the same thing against o1, but I think DeepSeek R1 did it better. In particular, from the R1 chain of thought:
Wait, but in the model_map, "groq-gemma" maps to "gemma-7b-it". So, perhaps the model_map is needed to map the local model IDs to the actual Groq model names.
But since the model_map is hardcoded, and the API returns available models, perhaps the model_map should be built dynamically from the API response.
Alternatively, perhaps the model_map can be eliminated, and the models are registered based on the fetched models.
Wait, perhaps the model_map is no longer necessary. Instead, when the models are fetched from the API, each model's "id" is the actual model name used in the Groq API. So, when registering the models, the local model ID is "groq-{id}", and the groq_model_id is "id".
(It thought about model_map a lot before finally deciding to eliminate it, which was also my preferred resolution.)
Structured Generation w/ SmolLM2 running in browser & WebGPU (via) Extraordinary demo by Vaibhav Srivastav (VB). Here's Hugging Face's SmolLM2-1.7B-Instruct running directly in a web browser (using WebGPU, so requires Chrome for the moment) demonstrating structured text extraction, converting a text description of an image into a structured GitHub issue defined using JSON schema.
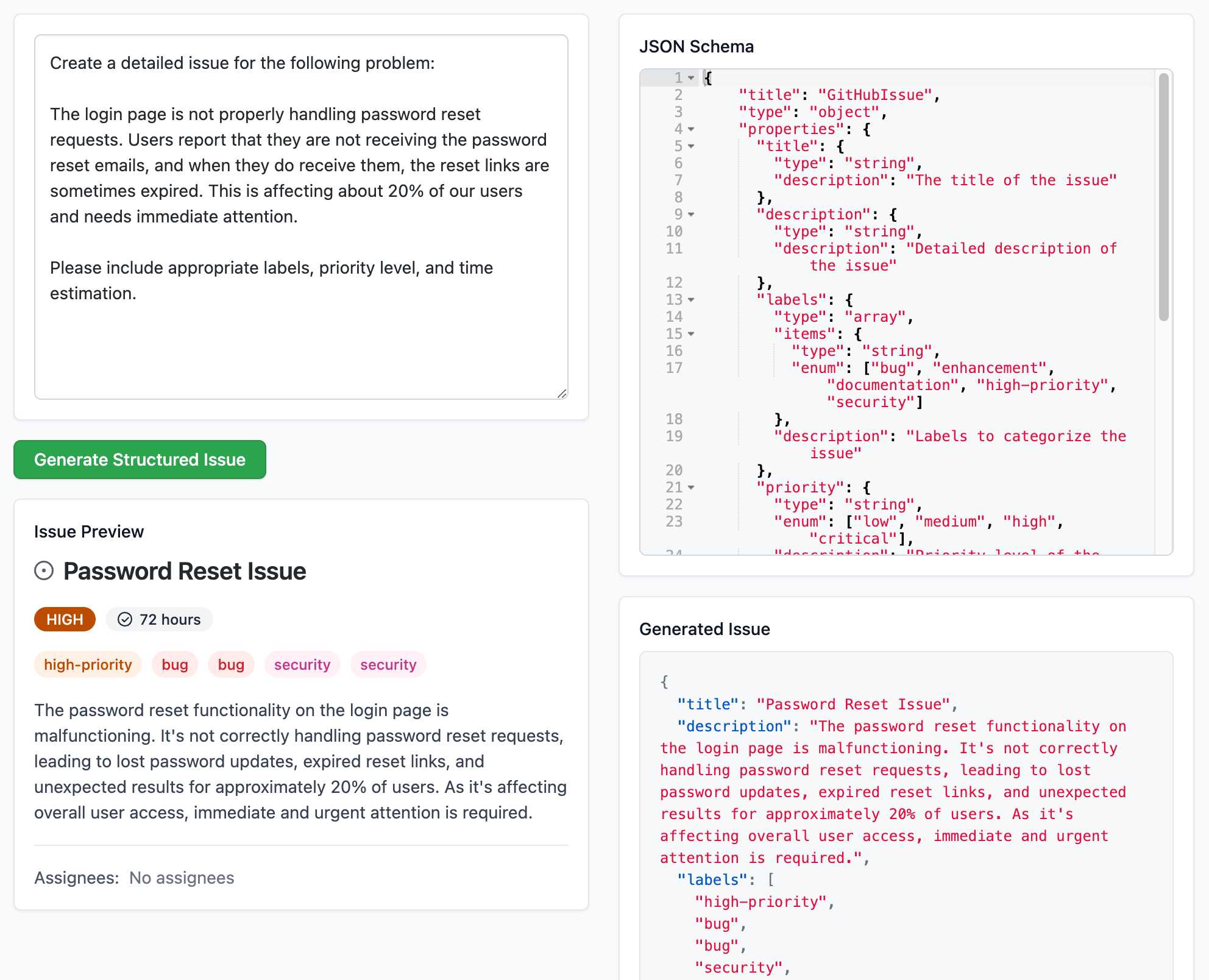
The page loads 924.8MB of model data (according to this script to sum up files in window.caches) and performs everything in-browser. I did not know a model this small could produce such useful results.
Here's the source code for the demo. It's around 200 lines of code, 50 of which are the JSON schema describing the data to be extracted.
The real secret sauce here is web-llm by MLC. This library has made loading and executing prompts through LLMs in the browser shockingly easy, and recently incorporated support for MLC's XGrammar library (also available in Python) which implements both JSON schema and EBNF-based structured output guidance.
Generating documentation from tests using files-to-prompt and LLM. I was experimenting with the wasmtime-py Python library today (for executing WebAssembly programs from inside CPython) and I found the existing API docs didn't quite show me what I wanted to know.
The project has a comprehensive test suite so I tried seeing if I could generate documentation using that:
cd /tmp
git clone https://github.com/bytecodealliance/wasmtime-py
files-to-prompt -e py wasmtime-py/tests -c | \
llm -m claude-3.5-sonnet -s \
'write detailed usage documentation including realistic examples'
More notes in my TIL. You can see the full Claude transcript here - I think this worked really well!
llama-3.2-webgpu (via) Llama 3.2 1B is a really interesting models, given its 128,000 token input and its tiny size (barely more than a GB).
This page loads a 1.24GB q4f16 ONNX build of the Llama-3.2-1B-Instruct model and runs it with a React-powered chat interface directly in the browser, using Transformers.js and WebGPU. Source code for the demo is here.
It worked for me just now in Chrome; in Firefox and Safari I got a “WebGPU is not supported by this browser” error message.
llama.ttf (via) llama.ttf is "a font file which is also a large language model and an inference engine for that model".
You can see it kick into action at 8m28s in this video, where creator Søren Fuglede Jørgensen types "Once upon a time" followed by dozens of exclamation marks, and those exclamation marks then switch out to render a continuation of the story. But... when they paste the code out of the editor again it shows as the original exclamation marks were preserved - the LLM output was presented only in the way they were rendered.
The key trick here is that the font renderer library HarfBuzz (used by Firefox, Chrome, Android, GNOME and more) added a new WebAssembly extension in version 8.0 last year, which is powerful enough to run a full LLM based on the tinyllama-15M model - which fits in a 60MB font file.
(Here's a related demo from Valdemar Erk showing Tetris running in a WASM font, at 22m56s in this video.)
The source code for llama.ttf is available on GitHub.
Experimenting with local alt text generation in Firefox Nightly (via) The PDF editor in Firefox (confession: I did not know Firefox ships with a PDF editor) is getting an experimental feature that can help suggest alt text for images for the human editor to then adapt and improve on.
This is a great application of AI, made all the more interesting here because Firefox will run a local model on-device for this, using a custom trained model they describe as "our 182M parameters model using a Distilled version of GPT-2 alongside a Vision Transformer (ViT) image encoder".
The model uses WebAssembly with ONNX running in Transfomers.js, and will be downloaded the first time the feature is put to use.
experimental-phi3-webgpu (via) Run Microsoft’s excellent Phi-3 model directly in your browser, using WebGPU so didn’t work in Firefox for me, just in Chrome.
It fetches around 2.1GB of data into the browser cache on first run, but then gave me decent quality responses to my prompts running at an impressive 21 tokens a second (M2, 64GB).
I think Phi-3 is the highest quality model of this size, so it’s a really good fit for running in a browser like this.
ColBERT query-passage scoring interpretability (via) Neat interactive visualization tool for understanding what the ColBERT embedding model does—this works by loading around 50MB of model files directly into your browser and running them with WebAssembly.
Perplexity: interactive LLM visualization (via) I linked to a video of Linus Lee’s GPT visualization tool the other day. Today he’s released a new version of it that people can actually play with: it runs entirely in a browser, powered by a 120MB version of the GPT-2 ONNX model loaded using the brilliant Transformers.js JavaScript library.
WebLLM supports Llama 2 70B now. The WebLLM project from MLC uses WebGPU to run large language models entirely in the browser. They recently added support for Llama 2, including Llama 2 70B, the largest and most powerful model in that family.
To my astonishment, this worked! I used a M2 Mac with 64GB of RAM and Chrome Canary and it downloaded many GBs of data... but it worked, and spat out tokens at a slow but respectable rate of 3.25 tokens/second.
Web Stable Diffusion (via) I just ran the full Stable Diffusion image generation model entirely in my browser, and used it to generate an image (of two raccoons eating pie in the woods, see “via” link). I had to use Google Chrome Canary since this depends on WebGPU which still isn’t fully rolled out, but it worked perfectly.
talk.wasm (via) “Talk with an Artificial Intelligence in your browser”. Absolutely stunning demo which loads the Whisper speech recognition model (75MB) and a GPT-2 model (240MB) and executes them both in your browser via WebAssembly, then uses the Web Speech API to talk back to you. The result is a full speak-with-an-AI interface running entirely client-side. GPT-2 sadly mostly generates gibberish but the fact that this works at all is pretty astonishing.