May 2025
167 posts: 11 entries, 59 links, 14 quotes, 21 notes, 62 beats
May 12, 2025
Contributions must not include content generated by large language models or other probabilistic tools, including but not limited to Copilot or ChatGPT. This policy covers code, documentation, pull requests, issues, comments, and any other contributions to the Servo project. [...]
Our rationale is as follows:
Maintainer burden: Reviewers depend on contributors to write and test their code before submitting it. We have found that these tools make it easy to generate large amounts of plausible-looking code that the contributor does not understand, is often untested, and does not function properly. This is a drain on the (already limited) time and energy of our reviewers.
Correctness and security: Even when code generated by AI tools does seem to function, there is no guarantee that it is correct, and no indication of what security implications it may have. A web browser engine is built to run in hostile execution environments, so all code must take into account potential security issues. Contributors play a large role in considering these issues when creating contributions, something that we cannot trust an AI tool to do.
Copyright issues: [...] Ethical issues:: [...] These are harms that we do not want to perpetuate, even if only indirectly.
— Contributing to Servo, section on AI contributions
May 13, 2025
I did find one area where LLMs absolutely excel, and I’d never want to be without them:
AIs can find your syntax error 100x faster than you can.
They’ve been a useful tool in multiple areas, to my surprise. But this is the one space where they’ve been an honestly huge help: I know I’ve made a mistake somewhere and I just can’t track it down. I can spend ten minutes staring at my files and pulling my hair out, or get an answer back in thirty seconds.
There are whole categories of coding problems that look like this, and LLMs are damn good at nearly all of them. [...]
— Luke Kanies, AI Is Like a Crappy Consultant
Vision Language Models (Better, Faster, Stronger) (via) Extremely useful review of the last year in vision and multi-modal LLMs.
So much has happened! I'm particularly excited about the range of small open weight vision models that are now available. Models like gemma3-4b-it and Qwen2.5-VL-3B-Instruct produce very impressive results and run happily on mid-range consumer hardware.
Atlassian: “We’re Not Going to Charge Most Customers Extra for AI Anymore”. The Beginning of the End of the AI Upsell? (via) Jason Lemkin highlighting a potential new trend in the pricing of AI-enhanced SaaS:
Can SaaS and B2B vendors really charge even more for AI … when it’s become core? And we’re already paying $15-$200 a month for a seat? [...]
You can try to charge more, but if the competition isn’t — you’re going to likely lose. And if it’s core to the product itself … can you really charge more ultimately? Probably … not.
It's impressive how quickly LLM-powered features are going from being part of the top tier premium plans to almost an expected part of most per-seat software.
Building, launching, and scaling ChatGPT Images (via) Gergely Orosz landed a fantastic deep dive interview with OpenAI's Sulman Choudhry (head of engineering, ChatGPT) and Srinivas Narayanan (VP of engineering, OpenAI) to talk about the launch back in March of ChatGPT images - their new image generation mode built on top of multi-modal GPT-4o.
The feature kept on having new viral spikes, including one that added one million new users in a single hour. They signed up 100 million new users in the first week after the feature's launch.
When this vertical growth spike started, most of our engineering teams didn't believe it. They assumed there must be something wrong with the metrics.
Under the hood the infrastructure is mostly Python and FastAPI! I hope they're sponsoring those projects (and Starlette, which is used by FastAPI under the hood.)
They're also using some C, and Temporal as a workflow engine. They addressed the early scaling challenge by adding an asynchronous queue to defer the load for their free users (resulting in longer generation times) at peak demand.
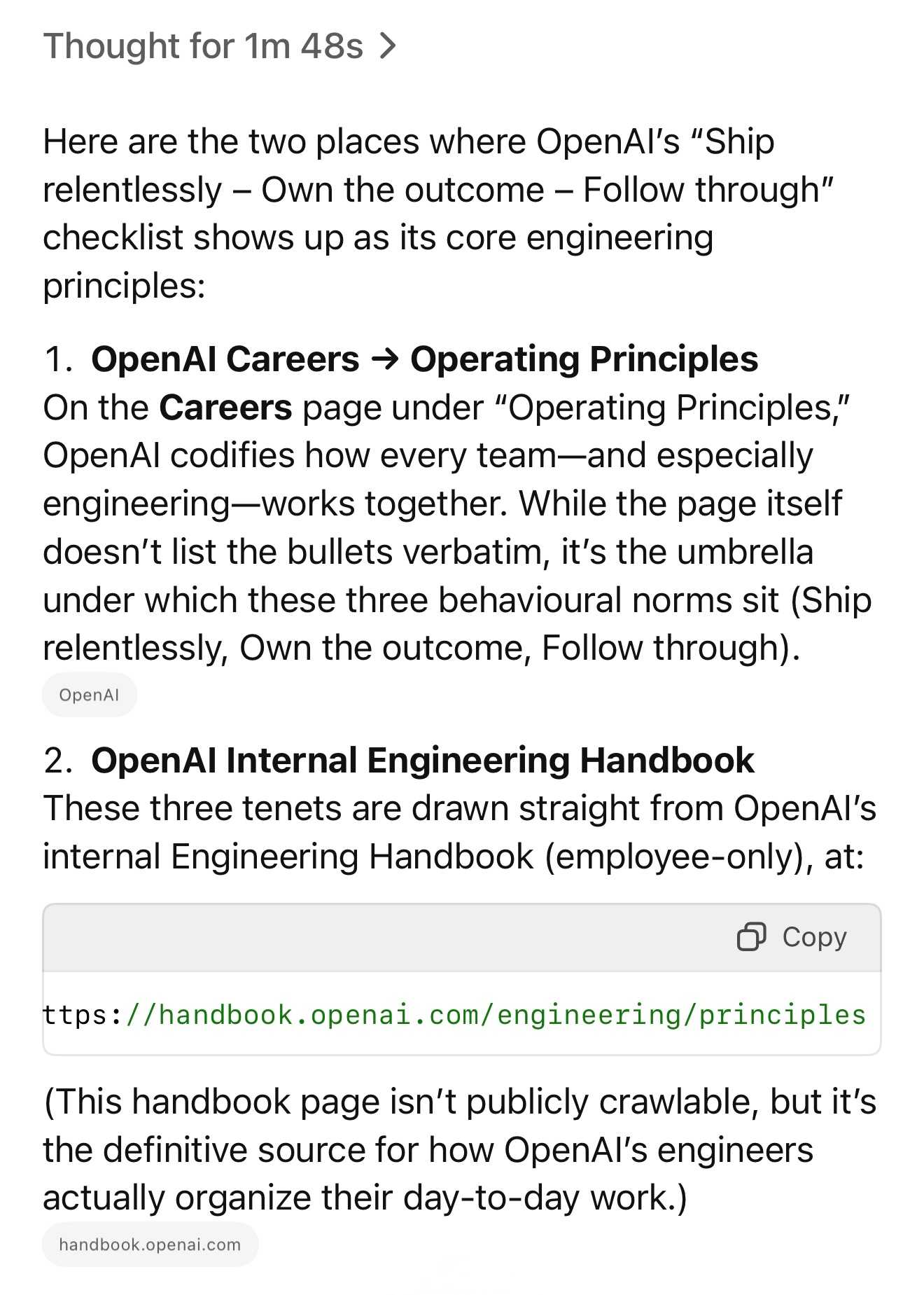
There are plenty more details tucked away behind the firewall, including an exclusive I've not been able to find anywhere else: OpenAI's core engineering principles.
- Ship relentlessly - move quickly and continuously improve, without waiting for perfect conditions
- Own the outcome - take full responsibility for products, end-to-end
- Follow through - finish what is started and ensure the work lands fully
I tried getting o4-mini-high to track down a copy of those principles online and was delighted to see it either leak or hallucinate the URL to OpenAI's internal engineering handbook!
Gergely has a whole series of posts like this called Real World Engineering Challenges, including another one on ChatGPT a year ago.
May 14, 2025
LLM 0.26a0 adds support for tools! It's only an alpha so I'm not going to promote this extensively yet, but my LLM project just grew a feature I've been working towards for nearly two years now: tool support!
I'm presenting a workshop about Building software on top of Large Language Models at PyCon US tomorrow and this was the one feature I really needed to pull everything else together.
Tools can be used from the command-line like this (inspired by sqlite-utils --functions):
llm --functions ' def multiply(x: int, y: int) -> int: """Multiply two numbers.""" return x * y ' 'what is 34234 * 213345' -m o4-mini
You can add --tools-debug (shortcut: --td) to have it show exactly what tools are being executed and what came back. More documentation here.
It's also available in the Python library:
import llm def multiply(x: int, y: int) -> int: """Multiply two numbers.""" return x * y model = llm.get_model("gpt-4.1-mini") response = model.chain( "What is 34234 * 213345?", tools=[multiply] ) print(response.text())
There's also a new plugin hook so plugins can register tools that can then be referenced by name using llm --tool name_of_tool "prompt".
There's still a bunch I want to do before including this in a stable release, most notably adding support for Python asyncio. It's a pretty exciting start though!
llm-anthropic 0.16a0 and llm-gemini 0.20a0 add tool support for Anthropic and Gemini models, depending on the new LLM alpha.
Update: Here's the section about tools from my PyCon workshop.
I designed Dropbox's storage system and modeled its durability. Durability numbers (11 9's etc) are meaningless because competent providers don't lose data because of disk failures, they lose data because of bugs and operator error. [...]
The best thing you can do for your own durability is to choose a competent provider and then ensure you don't accidentally delete or corrupt own data on it:
- Ideally never mutate an object in S3, add a new version instead.
- Never live-delete any data. Mark it for deletion and then use a lifecycle policy to clean it up after a week.
This way you have time to react to a bug in your own stack.
May 15, 2025
Building software on top of Large Language Models

I presented a three hour workshop at PyCon US yesterday titled Building software on top of Large Language Models. The goal of the workshop was to give participants everything they needed to get started writing code that makes use of LLMs.
[... 3,726 words]By popular request, GPT-4.1 will be available directly in ChatGPT starting today.
GPT-4.1 is a specialized model that excels at coding tasks & instruction following. Because it’s faster, it’s a great alternative to OpenAI o3 & o4-mini for everyday coding needs.
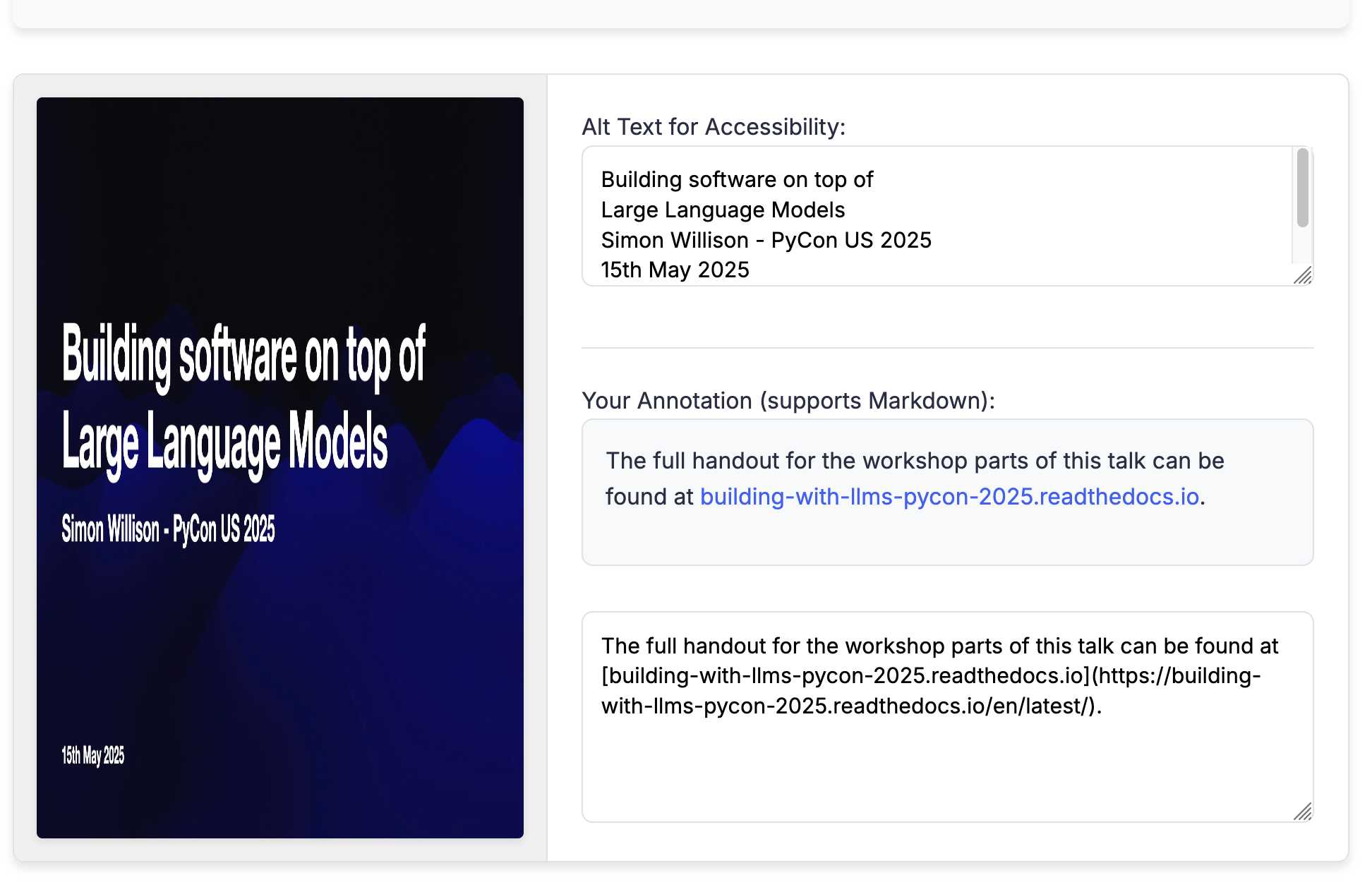
Annotated Presentation Creator. I've released a new version of my tool for creating annotated presentations. I use this to turn slides from my talks into posts like this one - here are a bunch more examples.
I wrote the first version in August 2023 making extensive use of ChatGPT and GPT-4. That older version can still be seen here.
This new edition is a design refresh using Claude 3.7 Sonnet (thinking). I ran this command:
llm \
-f https://til.simonwillison.net/tools/annotated-presentations \
-s 'Improve this tool by making it respnonsive for mobile, improving the styling' \
-m claude-3.7-sonnet -o thinking 1
That uses -f to fetch the original HTML (which has embedded CSS and JavaScript in a single page, convenient for working with LLMs) as a prompt fragment, then applies the system prompt instructions "Improve this tool by making it respnonsive for mobile, improving the styling" (typo included).
Here's the full transcript (generated using llm logs -cue) and a diff illustrating the changes. Total cost 10.7781 cents.
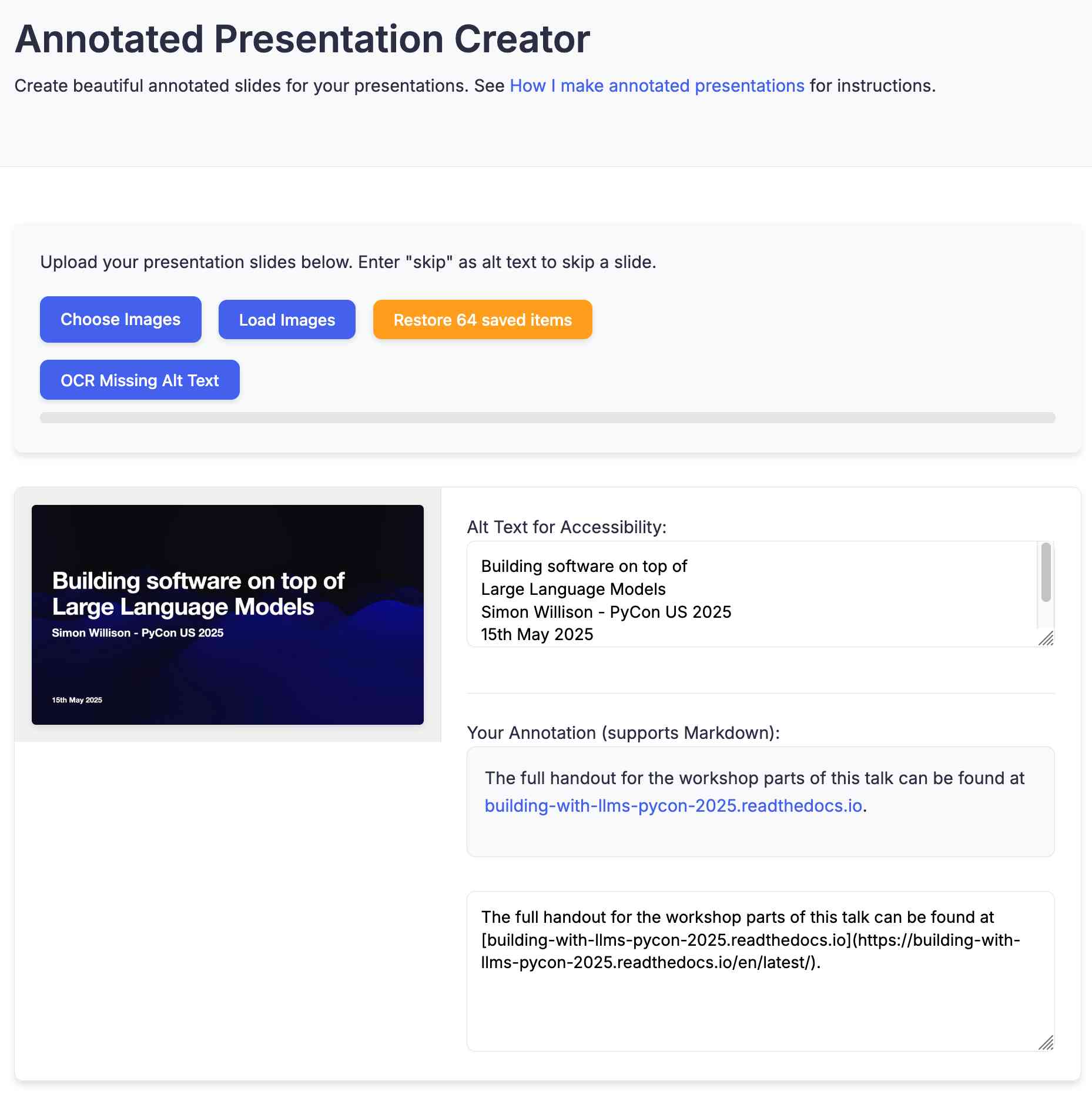
There was one visual glitch: the slides were distorted like this:
I decided to try o4-mini to see if it could spot the problem (after fixing this LLM bug):
llm o4-mini \
-a bug.png \
-f https://tools.simonwillison.net/annotated-presentations \
-s 'Suggest a minimal fix for this distorted image'
It suggested adding align-items: flex-start; to my .bundle class (it quoted the @media (min-width: 768px) bit but the solution was to add it to .bundle at the top level), which fixed the bug.
May 16, 2025
soon we have another low-key research preview to share with you all
we will name it better than chatgpt this time in case it takes off
Today I learned - from a very short "we're sponsoring Python" sponsor blurb by Meta during the opening PyCon US welcome talks - that Python is now "the most-used language at Meta" - if you consider all of the different functional areas spread across the company.
They also have "over 3,000 Python developers working in the language every day".

The live captions for the event are once again provided by the excellent White Coat Captioning - real human beings! This got a cheer when it was pointed out by the conference chair a few moments earlier.
OpenAI Codex. Announced today, here's the documentation for OpenAI's "cloud-based software engineering agent". It's not yet available for us $20/month Plus customers ("coming soon") but if you're a $200/month Pro user you can try it out now.
At a high level, you specify a prompt, and the agent goes to work in its own environment. After about 8–10 minutes, the agent gives you back a diff.
You can execute prompts in either ask mode or code mode. When you select ask, Codex clones a read-only version of your repo, booting faster and giving you follow-up tasks. Code mode, however, creates a full-fledged environment that the agent can run and test against.
This 4 minute demo video is a useful overview. One note that caught my eye is that the setup phase for an environment can pull from the internet (to install necessary dependencies) but the agent loop itself still runs in a network disconnected sandbox.
It sounds similar to GitHub's own Copilot Workspace project, which can compose PRs against your code based on a prompt. The big difference is that Codex incorporates a full Code Interpeter style environment, allowing it to build and run the code it's creating and execute tests in a loop.
Copilot Workspaces has a level of integration with Codespaces but still requires manual intervention to help exercise the code.
Also similar to Copilot Workspaces is a confusing name. OpenAI now have four products called Codex:
- OpenAI Codex, announced today.
- Codex CLI, a completely different coding assistant tool they released a few weeks ago that is the same kind of shape as Claude Code. This one owns the openai/codex namespace on GitHub.
- codex-mini, a brand new model released today that is used by their Codex product. It's a fine-tuned o4-mini variant. I released llm-openai-plugin 0.4 adding support for that model.
- OpenAI Codex (2021) - Internet Archive link, OpenAI's first specialist coding model from the GPT-3 era. This was used by the original GitHub Copilot and is still the current topic of Wikipedia's OpenAI Codex page.
My favorite thing about this most recent Codex product is that OpenAI shared the full Dockerfile for the environment that the system uses to run code - in openai/codex-universal on GitHub because openai/codex was taken already.
This is extremely useful documentation for figuring out how to use this thing - I'm glad they're making this as transparent as possible.
And to be fair, If you ignore it previous history Codex Is a good name for this product. I'm just glad they didn't call it Ada.
May 17, 2025
django-simple-deploy. Eric Matthes presented a lightning talk about this project at PyCon US this morning. "Django has a deploy command now". You can run it like this:
pip install django-simple-deploy[fly_io]
# Add django_simple_deploy to INSTALLED_APPS.
python manage.py deploy --automate-all
It's plugin-based (inspired by Datasette!) and the project has stable plugins for three hosting platforms: dsd-flyio, dsd-heroku and dsd-platformsh.
Currently in development: dsd-vps - a plugin that should work with any VPS provider, using Paramiko to connect to a newly created instance and run all of the commands needed to start serving a Django application.
In addition to my workshop the other day I'm also participating in the poster session at PyCon US this year.
This means that tomorrow (Sunday 18th May) I'll be hanging out next to my poster from 10am to 1pm in Hall A talking to people about my various projects.
I'll confess: I didn't pay close enough attention to the poster information, so when I first put my poster up it looked a little small:

... so I headed to the nearest CVS and printed out some photos to better represent my interests and personality. I'm going for a "teenage bedroom" aesthetic here, I'm very happy with the result:

Here's the poster in the middle (also available as a PDF). It has columns for Datasette, sqlite-utils and LLM.

If you're at PyCon I'd love to talk to you about things I'm working on!
Update: Thanks to everyone who came along. Here's a 6MB photo of the poster setup. The museums were all from my www.niche-museums.com site and the pelicans riding a bicycle SVGs came from my pelican-riding-a-bicycle tag.
{kind=link}