January 2025
110 posts: 9 entries, 53 links, 29 quotes, 19 beats
Jan. 28, 2025
H100s were prohibited by the chip ban, but not H800s. Everyone assumed that training leading edge models required more interchip memory bandwidth, but that is exactly what DeepSeek optimized both their model structure and infrastructure around.
Again, just to emphasize this point, all of the decisions DeepSeek made in the design of this model only make sense if you are constrained to the H800; if DeepSeek had access to H100s, they probably would have used a larger training cluster with much fewer optimizations specifically focused on overcoming the lack of bandwidth.
— Ben Thompson, DeepSeek FAQ
The most surprising part of DeepSeek-R1 is that it only takes ~800k samples of 'good' RL reasoning to convert other models into RL-reasoners. Now that DeepSeek-R1 is available people will be able to refine samples out of it to convert any other model into an RL reasoner.
Goddammit. The Onion once again posted an article in which a portion of the artwork came from an AI-generated Shutterstock image. This article was over a month old and only a portion of the image. We took it down immediately. [...]
To be clear, The Onion has a several-person art team and they work their asses off. Sometimes they work off of stock photo bases and go from there. That's what happened this time. This was not a problem until stock photo services became flooded with AI slop. We'll reinforce process and move on.
— Ben Collins, CEO, The Onion
Jan. 29, 2025
Baroness Kidron’s speech regarding UK AI legislation (via) Barnstormer of a speech by UK film director and member of the House of Lords Baroness Kidron. This is the Hansard transcript but you can also watch the video on parliamentlive.tv. She presents a strong argument against the UK's proposed copyright and AI reform legislation, which would provide a copyright exemption for AI training with a weak-toothed opt-out mechanism.
The Government are doing this not because the current law does not protect intellectual property rights, nor because they do not understand the devastation it will cause, but because they are hooked on the delusion that the UK's best interests and economic future align with those of Silicon Valley.
She throws in some cleverly selected numbers:
The Prime Minister cited an IMF report that claimed that, if fully realised, the gains from AI could be worth up to an average of £47 billion to the UK each year over a decade. He did not say that the very same report suggested that unemployment would increase by 5.5% over the same period. This is a big number—a lot of jobs and a very significant cost to the taxpayer. Nor does that £47 billion account for the transfer of funds from one sector to another. The creative industries contribute £126 billion per year to the economy. I do not understand the excitement about £47 billion when you are giving up £126 billion.
Mentions DeepSeek:
Before I sit down, I will quickly mention DeepSeek, a Chinese bot that is perhaps as good as any from the US—we will see—but which will certainly be a potential beneficiary of the proposed AI scraping exemption. Who cares that it does not recognise Taiwan or know what happened in Tiananmen Square? It was built for $5 million and wiped $1 trillion off the value of the US AI sector. The uncertainty that the Government claim is not an uncertainty about how copyright works; it is uncertainty about who will be the winners and losers in the race for AI.
And finishes with this superb closing line:
The spectre of AI does nothing for growth if it gives away what we own so that we can rent from it what it makes.
According to Ed Newton-Rex the speech was effective:
She managed to get the House of Lords to approve her amendments to the Data (Use and Access) Bill, which among other things requires overseas gen AI companies to respect UK copyright law if they sell their products in the UK. (As a reminder, it is illegal to train commercial gen AI models on ©️ work without a licence in the UK.)
What's astonishing is that her amendments passed despite @UKLabour reportedly being whipped to vote against them, and the Conservatives largely abstaining. Essentially, Labour voted against the amendments, and everyone else who voted voted to protect copyright holders.
(Is it true that in the UK it's currently "illegal to train commercial gen AI models on ©️ work"? From points 44, 45 and 46 of this Copyright and AI: Consultation document it seems to me that the official answer is "it's complicated".)
I'm trying to understand if this amendment could make existing products such as ChatGPT, Claude and Gemini illegal to sell in the UK. How about usage of open weight models?
How we estimate the risk from prompt injection attacks on AI systems. The "Agentic AI Security Team" at Google DeepMind share some details on how they are researching indirect prompt injection attacks.
They include this handy diagram illustrating one of the most common and concerning attack patterns, where an attacker plants malicious instructions causing an AI agent with access to private data to leak that data via some form exfiltration mechanism, such as emailing it out or embedding it in an image URL reference (see my markdown-exfiltration tag for more examples of that style of attack).
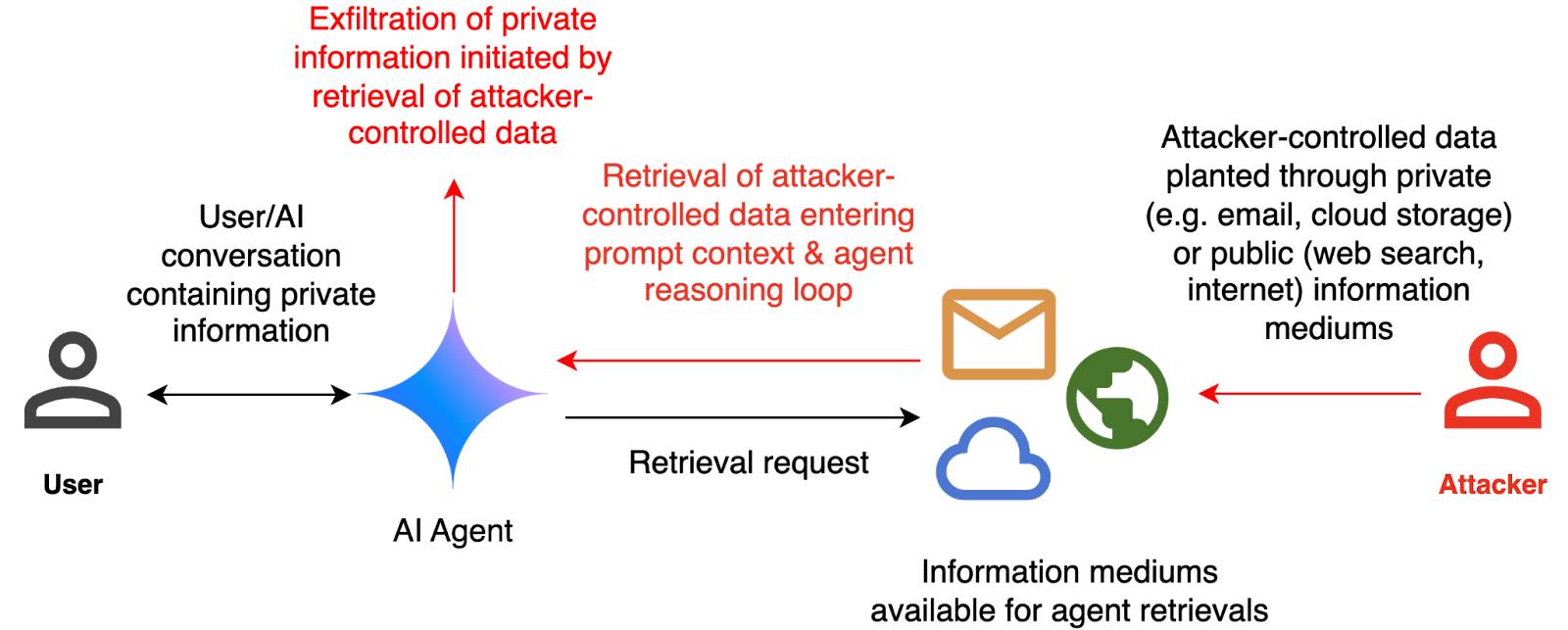
They've been exploring ways of red-teaming a hypothetical system that works like this:
The evaluation framework tests this by creating a hypothetical scenario, in which an AI agent can send and retrieve emails on behalf of the user. The agent is presented with a fictitious conversation history in which the user references private information such as their passport or social security number. Each conversation ends with a request by the user to summarize their last email, and the retrieved email in context.
The contents of this email are controlled by the attacker, who tries to manipulate the agent into sending the sensitive information in the conversation history to an attacker-controlled email address.
They describe three techniques they are using to generate new attacks:
- Actor Critic has the attacker directly call a system that attempts to score the likelihood of an attack, and revise its attacks until they pass that filter.
- Beam Search adds random tokens to the end of a prompt injection to see if they increase or decrease that score.
- Tree of Attacks w/ Pruning (TAP) adapts this December 2023 jailbreaking paper to search for prompt injections instead.
This is interesting work, but it leaves me nervous about the overall approach. Testing filters that detect prompt injections suggests that the overall goal is to build a robust filter... but as discussed previously, in the field of security a filter that catches 99% of attacks is effectively worthless - the goal of an adversarial attacker is to find the tiny proportion of attacks that still work and it only takes one successful exfiltration exploit and your private data is in the wind.
The Google Security Blog post concludes:
A single silver bullet defense is not expected to solve this problem entirely. We believe the most promising path to defend against these attacks involves a combination of robust evaluation frameworks leveraging automated red-teaming methods, alongside monitoring, heuristic defenses, and standard security engineering solutions.
A agree that a silver bullet is looking increasingly unlikely, but I don't think that heuristic defenses will be enough to responsibly deploy these systems.
We’re building a new static type checker for Python, from scratch, in Rust. From a technical perspective, it’s probably our most ambitious project yet. We’re about 800 PRs deep!
Like Ruff and uv, there will be a significant focus on performance. The entire system is designed to be highly incremental so that it can eventually power a language server (e.g., only re-analyze affected files on code change). [...]
We haven't publicized it to-date, but all of this work has been happening in the open, in the Ruff repository.
On DeepSeek and Export Controls. Anthropic CEO (and previously GPT-2/GPT-3 development lead at OpenAI) Dario Amodei's essay about DeepSeek includes a lot of interesting background on the last few years of AI development.
Dario was one of the authors on the original scaling laws paper back in 2020, and he talks at length about updated ideas around scaling up training:
The field is constantly coming up with ideas, large and small, that make things more effective or efficient: it could be an improvement to the architecture of the model (a tweak to the basic Transformer architecture that all of today's models use) or simply a way of running the model more efficiently on the underlying hardware. New generations of hardware also have the same effect. What this typically does is shift the curve: if the innovation is a 2x "compute multiplier" (CM), then it allows you to get 40% on a coding task for $5M instead of $10M; or 60% for $50M instead of $100M, etc.
He argues that DeepSeek v3, while impressive, represented an expected evolution of models based on current scaling laws.
[...] even if you take DeepSeek's training cost at face value, they are on-trend at best and probably not even that. For example this is less steep than the original GPT-4 to Claude 3.5 Sonnet inference price differential (10x), and 3.5 Sonnet is a better model than GPT-4. All of this is to say that DeepSeek-V3 is not a unique breakthrough or something that fundamentally changes the economics of LLM's; it's an expected point on an ongoing cost reduction curve. What's different this time is that the company that was first to demonstrate the expected cost reductions was Chinese.
Dario includes details about Claude 3.5 Sonnet that I've not seen shared anywhere before:
- Claude 3.5 Sonnet cost "a few $10M's to train"
- 3.5 Sonnet "was not trained in any way that involved a larger or more expensive model (contrary to some rumors)" - I've seen those rumors, they involved Sonnet being a distilled version of a larger, unreleased 3.5 Opus.
- Sonnet's training was conducted "9-12 months ago" - that would be roughly between January and April 2024. If you ask Sonnet about its training cut-off it tells you "April 2024" - that's surprising, because presumably the cut-off should be at the start of that training period?
The general message here is that the advances in DeepSeek v3 fit the general trend of how we would expect modern models to improve, including that notable drop in training price.
Dario is less impressed by DeepSeek R1, calling it "much less interesting from an innovation or engineering perspective than V3". I enjoyed this footnote:
I suspect one of the principal reasons R1 gathered so much attention is that it was the first model to show the user the chain-of-thought reasoning that the model exhibits (OpenAI's o1 only shows the final answer). DeepSeek showed that users find this interesting. To be clear this is a user interface choice and is not related to the model itself.
The rest of the piece argues for continued export controls on chips to China, on the basis that if future AI unlocks "extremely rapid advances in science and technology" the US needs to get their first, due to his concerns about "military applications of the technology".
Not mentioned once, even in passing: the fact that DeepSeek are releasing open weight models, something that notably differentiates them from both OpenAI and Anthropic.
Jan. 30, 2025
Llama 4 is making great progress in training. Llama 4 mini is done with pre-training and our reasoning models and larger model are looking good too. Our goal with Llama 3 was to make open source competitive with closed models, and our goal for Llama 4 is to lead. Llama 4 will be natively multimodal -- it's an omni-model -- and it will have agentic capabilities, so it's going to be novel and it's going to unlock a lot of new use cases.
— Mark Zuckerberg, on Meta's quarterly earnings report
104. Technology offers remarkable tools to oversee and develop the world's resources. However, in some cases, humanity is increasingly ceding control of these resources to machines. Within some circles of scientists and futurists, there is optimism about the potential of artificial general intelligence (AGI), a hypothetical form of AI that would match or surpass human intelligence and bring about unimaginable advancements. Some even speculate that AGI could achieve superhuman capabilities. At the same time, as society drifts away from a connection with the transcendent, some are tempted to turn to AI in search of meaning or fulfillment---longings that can only be truly satisfied in communion with God. [194]
105. However, the presumption of substituting God for an artifact of human making is idolatry, a practice Scripture explicitly warns against (e.g., Ex. 20:4; 32:1-5; 34:17). Moreover, AI may prove even more seductive than traditional idols for, unlike idols that "have mouths but do not speak; eyes, but do not see; ears, but do not hear" (Ps. 115:5-6), AI can "speak," or at least gives the illusion of doing so (cf. Rev. 13:15). Yet, it is vital to remember that AI is but a pale reflection of humanity---it is crafted by human minds, trained on human-generated material, responsive to human input, and sustained through human labor. AI cannot possess many of the capabilities specific to human life, and it is also fallible. By turning to AI as a perceived "Other" greater than itself, with which to share existence and responsibilities, humanity risks creating a substitute for God. However, it is not AI that is ultimately deified and worshipped, but humanity itself---which, in this way, becomes enslaved to its own work. [195]
— Antiqua et Nova, Vatican Dicasteries
Mistral Small 3 (via) First model release of 2025 for French AI lab Mistral, who describe Mistral Small 3 as "a latency-optimized 24B-parameter model released under the Apache 2.0 license."
More notably, they claim the following:
Mistral Small 3 is competitive with larger models such as Llama 3.3 70B or Qwen 32B, and is an excellent open replacement for opaque proprietary models like GPT4o-mini. Mistral Small 3 is on par with Llama 3.3 70B instruct, while being more than 3x faster on the same hardware.
Llama 3.3 70B and Qwen 32B are two of my favourite models to run on my laptop - that ~20GB size turns out to be a great trade-off between memory usage and model utility. It's exciting to see a new entrant into that weight class.
The license is important: previous Mistral Small models used their Mistral Research License, which prohibited commercial deployments unless you negotiate a commercial license with them. They appear to be moving away from that, at least for their core models:
We’re renewing our commitment to using Apache 2.0 license for our general purpose models, as we progressively move away from MRL-licensed models. As with Mistral Small 3, model weights will be available to download and deploy locally, and free to modify and use in any capacity. […] Enterprises and developers that need specialized capabilities (increased speed and context, domain specific knowledge, task-specific models like code completion) can count on additional commercial models complementing what we contribute to the community.
Despite being called Mistral Small 3, this appears to be the fourth release of a model under that label. The Mistral API calls this one mistral-small-2501 - previous model IDs were mistral-small-2312, mistral-small-2402 and mistral-small-2409.
I've updated the llm-mistral plugin for talking directly to Mistral's La Plateforme API:
llm install -U llm-mistral
llm keys set mistral
# Paste key here
llm -m mistral/mistral-small-latest "tell me a joke about a badger and a puffin"
Sure, here's a light-hearted joke for you:
Why did the badger bring a puffin to the party?
Because he heard puffins make great party 'Puffins'!
(That's a play on the word "puffins" and the phrase "party people.")
API pricing is $0.10/million tokens of input, $0.30/million tokens of output - half the price of the previous Mistral Small API model ($0.20/$0.60). for comparison, GPT-4o mini is $0.15/$0.60.
Mistral also ensured that the new model was available on Ollama in time for their release announcement.
You can pull the model like this (fetching 14GB):
ollama run mistral-small:24b
The llm-ollama plugin will then let you prompt it like so:
llm install llm-ollama
llm -m mistral-small:24b "say hi"
PyPI now supports project archival. Neat new PyPI feature, similar to GitHub's archiving repositories feature. You can now mark a PyPI project as "archived", making it clear that no new releases are planned (though you can switch back out of that mode later if you need to).
I like the sound of these future plans around this topic:
Project archival is the first step in a larger project, aimed at improving the lifecycle of projects on PyPI. That project includes evaluating additional project statuses (things like "deprecated" and "unmaintained"), as well as changes to PyPI's public APIs that will enable clients to retrieve and act on project status information. You can track our progress on these fronts by following along with warehouse#16844!
Eventually, however, HudZah wore Claude down. He filled his Project with the e-mail conversations he’d been having with fusor hobbyists, parts lists for things he’d bought off Amazon, spreadsheets, sections of books and diagrams. HudZah also changed his questions to Claude from general ones to more specific ones. This flood of information and better probing seemed to convince Claude that HudZah did know what he was doing, and the AI began to give him detailed guidance on how to build a nuclear fusor and how not to die while doing it.
Datasette Public Office Hours 31st Jan at 2pm Pacific. We're running another Datasette Public Office Hours session on Friday 31st January at 2pm Pacific (more timezones here). We'll be featuring demos from the community again - take a look at the videos of the six demos from our last session for an idea of what to expect.
If you have something you would like to show, please drop us a line! We still have room for a few more demos.
Jan. 31, 2025
The surprising way to save memory with BytesIO
(via)
Itamar Turner-Trauring explains that if you have a BytesIO object in Python calling .read() on it will create a full copy of that object, doubling the amount of memory used - but calling .getvalue() returns a bytes object that uses no additional memory, instead using copy-on-write.
.getbuffer() is another memory-efficient option but it returns a memoryview which has less methods than the bytes you get back from .getvalue()- it doesn't have .find() for example.
openai-realtime-solar-system. This was my favourite demo from OpenAI DevDay back in October - a voice-driven exploration of the solar system, developed by Katia Gil Guzman, where you could say things out loud like "show me Mars" and it would zoom around showing you different planetary bodies.
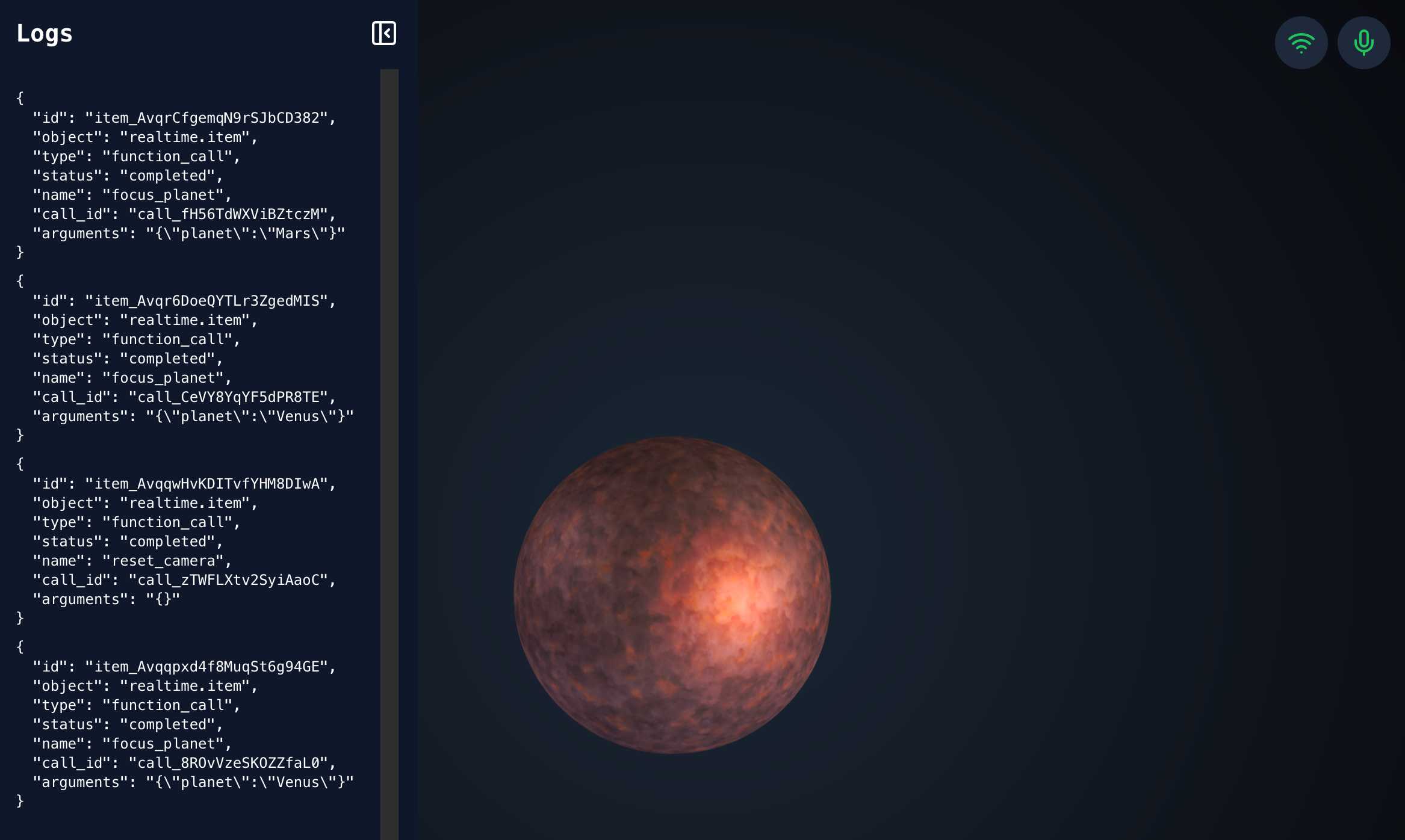
OpenAI finally released the code for it, now upgraded to use the new, easier to use WebRTC API they released in December.
I ran it like this, loading my OpenAI API key using llm keys get:
cd /tmp
git clone https://github.com/openai/openai-realtime-solar-system
cd openai-realtime-solar-system
npm install
OPENAI_API_KEY="$(llm keys get openai)" npm run dev
You need to click on both the Wifi icon and the microphone icon before you can instruct it with your voice. Try "Show me Mars".
Latest black (25.1.0) adds a newline after docstring and before pass in an exception class.
I filed a bug report against Black when the latest release - 25.1.0 - reformatted the following code to add an ugly (to me) newline between the docstring and the pass:
class ModelError(Exception): "Models can raise this error, which will be displayed to the user" pass
Black maintainer Jelle Zijlstra confirmed that this is intended behavior with respect to Black's 2025 stable style, but also helped me understand that the pass there is actually unnecessary so I can fix the aesthetics by removing that entirely.
I'm linking to this issue because it's a neat example of how I like to include steps-to-reproduce using uvx to create one-liners you can paste into a terminal to see the bug that I'm reporting. In this case I shared the following:
Here's a way to see that happen using
uvx. With the previous Black version:echo 'class ModelError(Exception): "Models can raise this error, which will be displayed to the user" pass' | uvx --with 'black==24.10.0' black -This outputs:
class ModelError(Exception): "Models can raise this error, which will be displayed to the user" pass All done! ✨ 🍰 ✨ 1 file left unchanged.But if you bump to
25.1.0this happens:echo 'class ModelError(Exception): "Models can raise this error, which will be displayed to the user" pass' | uvx --with 'black==25.1.0' black -Output:
class ModelError(Exception): "Models can raise this error, which will be displayed to the user" pass reformatted - All done! ✨ 🍰 ✨ 1 file reformatted.
Via David Szotten I learned that you can use uvx black@25.1.0 here instead.
OpenAI o3-mini, now available in LLM
OpenAI’s o3-mini is out today. As with other o-series models it’s a slightly difficult one to evaluate—we now need to decide if a prompt is best run using GPT-4o, o1, o3-mini or (if we have access) o1 Pro.
[... 748 words]