123 posts tagged “claude-code”
Claude Code is Anthropic's terminal coding agent, enabling Claude to run tools in a loop on your own machine.
2026
A Fireside Chat with Cat and Thariq from the Claude Code team

Earlier this month I hosted a fireside chat session at the AI Engineer World’s Fair with Cat Wu and Thariq Shihipar from Anthropic’s Claude Code team. We talked about Claude Code, Claude Tag, Fable, coding agent security, evals, tool design, and how Anthropic use these tools themselves.
[... 8,609 words]In Rewriting Bun in Rust Jarred Sumner made the following claim:
Claude Code v2.1.181 (released June 17th) and later use the Rust port of Bun. Startup got 10% faster on Linux but otherwise, barely anyone noticed. Boring is good.
I decided to have a poke at my own Claude Code installation to see if I could find evidence that it was using Bun written in Rust.
I found these two commands convincing:
strings ~/.local/bin/claude | grep -m1 'Bun v1'
For me this outputs Bun v1.4.0 (macOS arm64). The most recent release of Bun on GitHub is currently v1.3.14 from May 12th, so that v1.4.0 version number in Claude supports them shipping a preview of a not-yet-released Bun version.
(Update: The Rust version has been released as Bun canary - running bun upgrade --canary will install this release.)
strings ~/.local/bin/claude | grep -Eo 'src/[[:alnum:]_./-]+\.rs'
This outputs a list of 563 filenames, starting with these:
src/runtime/bake/dev_server/mod.rs
src/runtime/bake/production.rs
src/bundler/bundle_v2.rs
It looks like Bun in Rust is indeed being run in production across millions of different devices. Like Jarred said, "Boring is good".
Update: Here's a neat trick from Ajan Raj:
cat > /tmp/bun-version.ts <<'EOF'
console.log("embedded bun:", Bun.version);
process.exit(0);
EOF
BUN_OPTIONS="--preload=/tmp/bun-version.ts" claude --version
This outputs 1.4.0 for me.
Here's the commit from May 17th that updated the version in package.json to 1.4.0. That version hasn't been changed since then, but also hasn't yet made it into a tagged release outside of canary.
sqlite-utils 4.0rc2, mostly written by Claude Fable (for about $149.25)
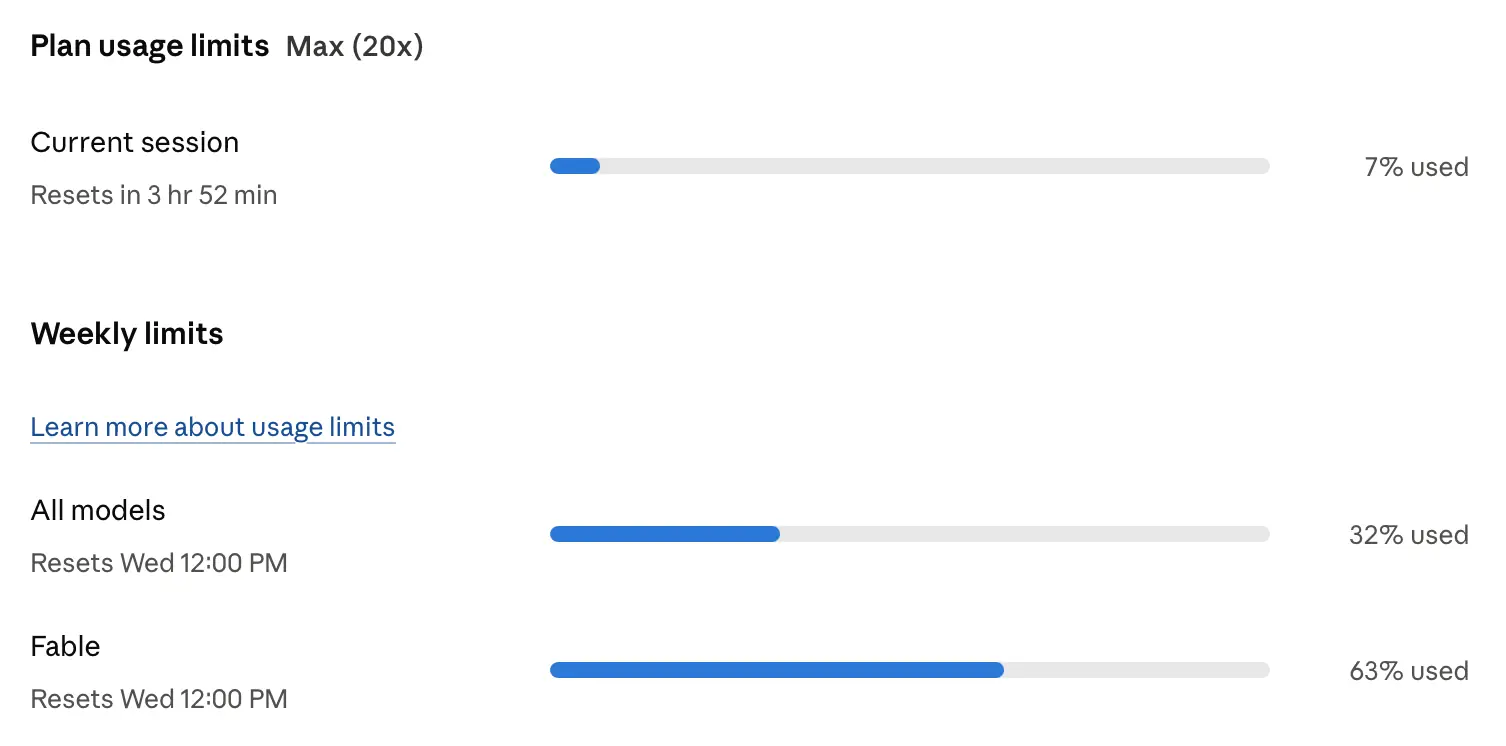
I wrote about the sqlite-utils 4.0rc1 release a couple of weeks ago. Since we only have Claude Fable on our Max subscriptions for a few more days, I decided to see if it could help me get to a 4.0 stable release that I felt truly comfortable about, since I try to keep to SemVer and like my incompatible major versions to be as rare as possible.
[... 2,427 words]One of the most interesting tips I got from the Fireside Chat I hosted with Cat Wu and Thariq Shihipar from the Claude Code team at AIE on Wednesday was to let Fable (and to a certain extent Opus) use their own judgement rather than dictating how they should work.
The example they gave was testing. You can tell Fable "only use automated testing for larger features, don't update and run tests for small copy or design changes" - but it's better to just tell Fable to use its own judgement when deciding to write tests instead.
Jesse Vincent just gave me a related tip to help avoid burning too many of those valuable Fable tokens in the few days we have left before the prices go up. Tell Fable to use other models for smaller tasks, applying its own judgement about which model to use.
I prompted Claude Code just now with:
For all coding tasks use your judgement to decide an appropriate lower power model and run that in a subagent
Claude saved this memory file in ~/.claude/projects/name-of-project/memory/delegate-coding-to-subagents.md:
--- name: delegate-coding-to-subagents description: Simon wants coding tasks delegated to subagents running an appropriately lower-power model metadata: node_type: memory type: feedback originSessionId: 30068d78-43a9-4fb1-bb29-9799e18c526a ---Stated by Simon on 2026-07-03: "For all coding tasks use your judgement to decide an appropriate lower power model and run that in a subagent."
Why: cost/efficiency — implementation work rarely needs the top-tier model; judgment, review, and synthesis stay with the main loop.
How to apply: when a task in this project is primarily writing/editing code, spawn an Agent with a model override (sonnet for substantive implementation, haiku for trivial/mechanical edits) and a self-contained prompt; review the result in the main loop before committing. Design, auditing, data synthesis, and anything judgment-heavy stays in the main model. See also [[project-goals]].
So far it seems to be working well. I'm getting a ton of work done and my Fable allowance is shrinking less quickly than before.
Another Fable 5 experiment. Now that my LLM library has evolved into more of an agent framework it's time to see what a simple coding agent would look like built on it.
I started a new Python library using my python-lib-template-repository GitHub template repository, then ran these two prompts (here's the Claude Code for web transcript):
Write a spec.md for this project - it will depend on the latest “llm” alpha from PyPI and implement a Claude code style coding agent complete with tools for reading and editing files and executing commands
Then:
Commit the spec, then build it using red/green TDD in a series of sensible commits (each with passing tests and updated docs) - occasionally manually test it using the OpenAI API key in your environment
Here's the spec, the resulting README file, and the sequence of commits.
I've shipped a slop-alpha to PyPI, so you can run the new agent like this:
uvx --prerelease=allow --with llm-coding-agent llm code
It's pretty good for a first attempt! Here's the (Fable-authored) README, which lists recipes like llm code --yolo and llm code --allow "pytest*" --allow "git diff*".
It also presents a Python API based around a CodingAgent(model="gpt-5.5", root="/path", approve=True).run("Fix the failing test in tests/test_parser.py") class which I didn't ask for but I'm delighted to see implemented.
Here's the suite of tools it implemented, listed using uvx ... llm tools:
CodingTools_edit_file(path: str, old_string: str, new_string: str, replace_all: bool = False) -> strReplace an exact string in a file.
old_string must match the file contents exactly (including whitespace) and must identify a unique location unless replace_all is true. Returns a diff of the change so it can be verified.
CodingTools_execute_command(command: str, timeout: int = 120) -> strRun a shell command in the session root directory.
Returns combined stdout and stderr followed by an Exit code line. timeout is in seconds (maximum 600); on timeout the whole process tree is killed.
CodingTools_list_files(pattern: str = '**/*', path: str = '.') -> strList files matching a glob pattern, newest first.
Skips hidden directories, node_modules, __pycache__ and (in a git repository) anything covered by .gitignore. Returns at most 200 paths relative to the searched directory.
CodingTools_read_file(path: str, offset: int = 0, limit: int = 2000) -> strRead a text file, returning numbered lines like cat -n.
Paths are relative to the session root. Use offset (0-based first line) and limit (max lines) to page through files too large to read in one call.
CodingTools_search_files(pattern: str, path: str = '.', glob: str = None, max_results: int = 100) -> strSearch file contents for a regular expression.
Returns matches as path:line_number:line, capped at max_results. Use glob (e.g. "*.py") to restrict which files are searched.
CodingTools_write_file(path: str, content: str) -> strCreate or overwrite a file with the given content.
Parent directories are created as needed. Prefer edit_file for modifying existing files.
I tried it out by running llm code --yolo and then prompting:
mkdir /tmp/demo and then in that folder create a simple swiftui CLI app for telling the time in ascii art
Here's the transcript, in which GPT-5.5 reasoning notes that "SwiftUI isn't suitable for a true CLI" and then builds an app that outputs this on swift run AsciiTime:
█ █████ ████ █ █ ███
██ █ █ █ ██ █ ██ █ █
█ ████ ███ █ █ █
█ █ █ █ █ █ █ █
███ ████ ████ ███ ███ █████
Porting the Moebius 0.2B image inpainting model to run in the browser with Claude Code

This morning on Hacker News I saw Moebius: 0.2B Lightweight Image Inpainting Framework with 10B-Level Performance, describing a small but effective inpainting model—a model where you can mark regions of an image to remove and the model imagines what should fill the space. The released model required PyTorch and NVIDIA CUDA, but since it described itself as 0.2B I decided to try and get it running using WebGPU in a browser. TL;DR: I got it working, and you can try the demo at simonw.github.io/moebius-web/. Read on for the details.
[... 1,764 words]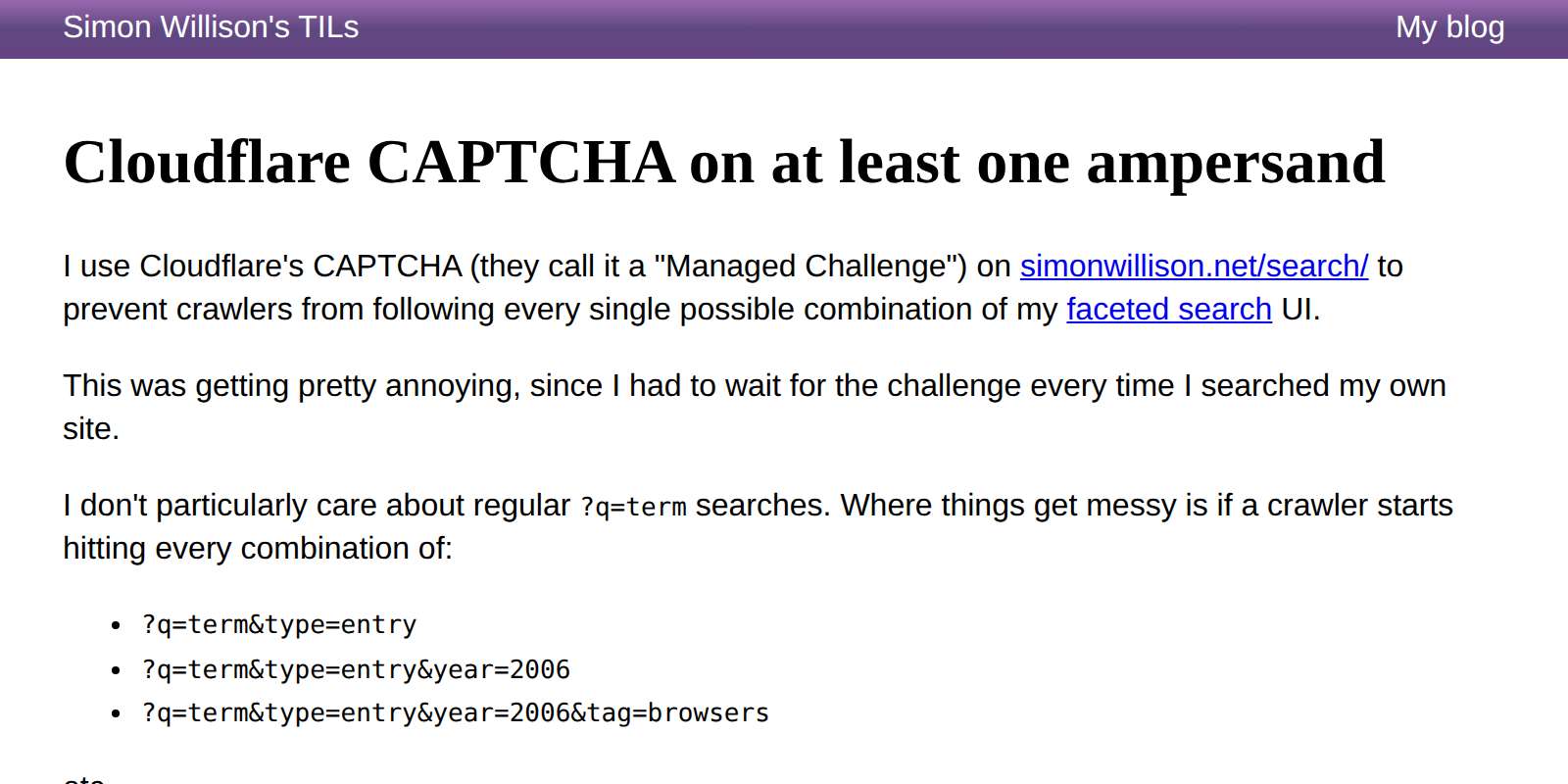
I'm using Cloudflare's CAPTCHA (they call it a "Web Application Firewall > Custom rules > Managed Challenge" these days) to prevent crawlers from aggresively spidering my faceted search engine on this site, but I got fed up of even simple ?q=term searches triggering the challenge.
After some mucking around with Claude Code it turns out you can register the following rule instead, so the CAPTCHA only kicks in for search URLs containing at least one ampersand:
(http.request.uri.path wildcard r"/search/*" and http.request.uri.query contains "&")
And now /search/?q=lemur works without triggering a CAPTCHA!
Also included: notes on trying out the Cloudflare MCP with Claude Code, though it turned out not to be able to edit the rules in question so I had Claude Code switch to the Cloudflare API instead.
Claude Fable is relentlessly proactive
After two days of experience with Claude Fable 5 I think the best way to describe it is relentlessly proactive. It knows a whole lot of tricks and it will deploy pretty much any of them to get to its goal.
[... 1,939 words]How we contain Claude across products. A complaint I often have about sandboxing products is that they are rarely thoroughly documented, and in the absence of detailed documentation it's hard to know how much I can trust them.
Anthropic just published a fantastic overview of how their various sandbox techniques work across Claude.ai, Claude Code, and Cowork.
We constrain where and how an agent can act with process sandboxes, VMs, filesystem boundaries, and egress controls. The goal is to set a hard boundary on what an agent can reach. For example, if credentials never enter the sandbox, they can't be exfiltrated, regardless of whether the cause is a user, a model finding a “creative” path, or an attacker.
Claude.ai uses gVisor. Claude Code, run locally, uses Seatbelt on macOS and Bubblewrap on Linux. Claude Cowork runs a full VM (Apple's Virtualization framework on macOS, HCS on Windows).
There's a lot in here, including some interesting stories of risks they missed such as the api.anthropic.com/v1/files exfiltration vector covered here previously.
This reminded me it's time I took another look at Anthropic's open source srt (Anthropic Sandbox Runtime) tool - it's mature enough now that I'm ready to give it a proper go.
Datasette Lite is my version of Datasette that runs entirely in the browser using Pyodide in WebAssembly.
When I first built it four years ago I used Web Workers and code that intercepts navigation operations and fetches the generated HTML by running the Python app.
This worked, but had the disadvantage that any JavaScript in <script> tags would not be executed - breaking some Datasette functionality and a whole lot of Datasette plugins.
This morning I set Claude Opus 4.8 the task (in Claude Code for web) of figuring out how to run Python ASGI apps in Pyodide using Service Workers instead, and it seems to work! Here's a basic ASGI FastCGI demo and here's a demo that runs Datasette 1.0a31.
I'm still getting my head around exactly how it works, but once I've done that I plan to upgrade Datasette Lite itself.
I think Anthropic and OpenAI have found product-market fit
Anthropic are strongly rumored to be about to have their first profitable quarter. Stories are circulating of companies surprised at how expensive their LLM bills are becoming from usage by their staff. I think this is because OpenAI and Anthropic have both found product-market fit.
[... 1,931 words]Using Claude Code: The Unreasonable Effectiveness of HTML. Thought-provoking piece by Thariq Shihipar (on the Claude Code team at Anthropic) advocating for HTML over Markdown as an output format to request from Claude.
The article is crammed with interesting examples (collected on this site) and prompt suggestions like this one:
Help me review this PR by creating an HTML artifact that describes it. I'm not very familiar with the streaming/backpressure logic so focus on that. Render the actual diff with inline margin annotations, color-code findings by severity and whatever else might be needed to convey the concept well.
I've been defaulting to asking for most things in Markdown since the GPT-4 days, when the 8,192 token limit meant that Markdown's token-efficiency over HTML was extremely worthwhile.
Thariq's piece here has caused me to reconsider that, especially for output. Asking Claude for an explanation in HTML means it can drop in SVG diagrams, interactive widgets, in-page navigation and all sorts of other neat ways of making the information more pleasant to navigate.
I wrote about Useful patterns for building HTML tools last December, but that was focused very much on interactive utilities like the ones on my tools.simonwillison.net site. I'm excited to start experimenting more with rich HTML explanations in response to ad-hoc prompts.
Trying this out on copy.fail
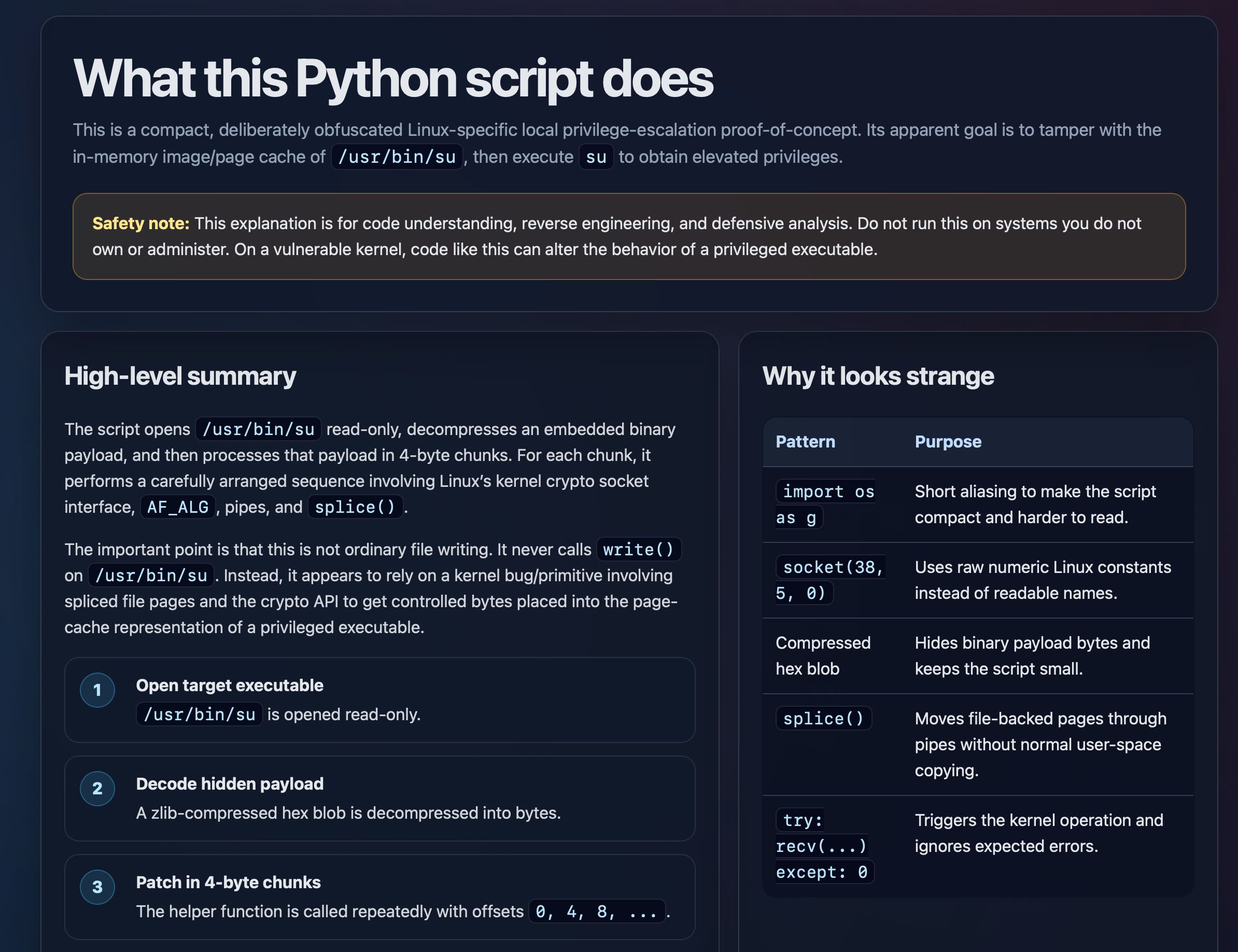
copy.fail describes a recently discovered Linux security exploit, including a proof of concept distributed as obfuscated Python.
I tried having GPT-5.5 create an HTML explanation of the exploit like this:
curl https://copy.fail/exp | llm -m gpt-5.5 -s 'Explain this code in detail. Reformat it, expand out any confusing bits and go deep into what it does and how it works. Output HTML, neatly styled and using capabilities of HTML and CSS and JavaScript to make the explanation rich and interactive and as clear as possible'
Here's the resulting HTML page. It's pretty good, though I should have emphasized explaining the exploit over the Python harness around it.
Live blog: Code w/ Claude 2026
I’m at Anthropic’s Code w/ Claude event today. Here’s my live blog of the morning keynote sessions.
/elsewhere/sightings/. I have a new camera (a Canon R6 Mark II) so I'm taking a lot more photos of birds. I share my best wildlife photos on iNaturalist, and based on yesterday's successful prototype I decided to add those to my blog.
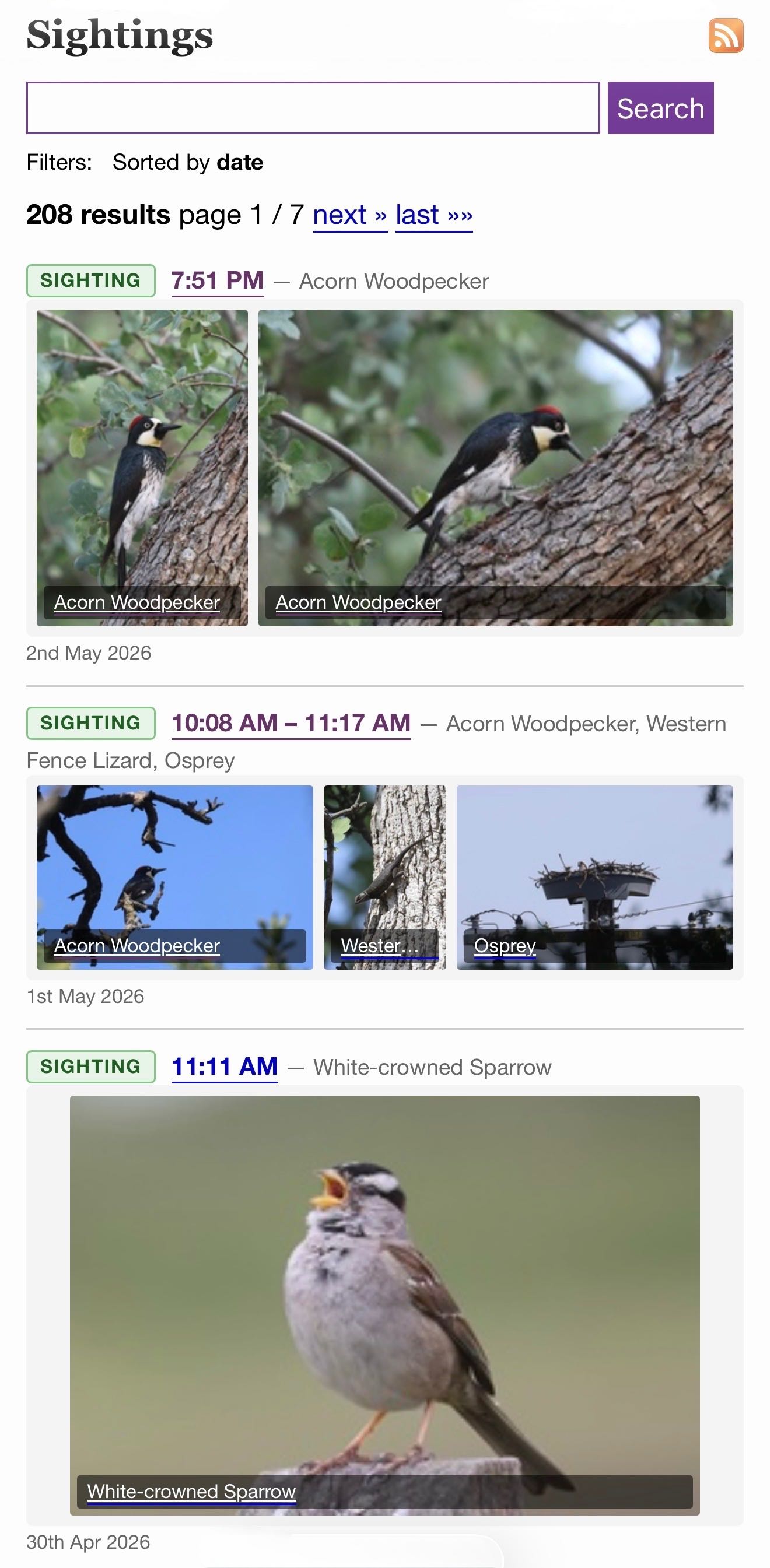
I built this feature on my phone using Claude Code for web, as an extension of my beats system for syndicating external content. Here's the PR and prompt.
As with my other forms of incoming syndicated content sightings show up on the homepage, the date archive pages, and in site search results.
I back-populated over a decade of iNaturalist sightings, which means you that if you search for lemur you'll see my lemur photos from Madagascar in 2019!

I wanted to see my iNaturalist observations - across two separate accounts - grouped by when they occurred. I'm camping this weekend so I built this entirely on my phone using Claude Code for web.
I started by building an inaturalist-clumper Python CLI for fetching and "clumping" observations - by default clumps use observations within 2 hours and 5km of each other.
Then I setup simonw/inaturalist-clumps as a Git scraping repository to run that tool and record the result to clumps.json.
That JSON file is hosted on GitHub, which means it can be fetched by JavaScript using CORS.
Finally I ran this prompt against my simonw/tools repo:
Build inat-sightings.html - an app that does a fetch() against https://raw.githubusercontent.com/simonw/inaturalist-clumps/refs/heads/main/clumps.json and then displays all of the observations on one page using the https://static.inaturalist.org/photos/538073008/small.jpg small.jpg URLs for the thumbnails - with loading=lazy - but when a thumbnail is clicked showing the large.jpg in an HTML modal. Both small and large should include the common species names if available
An update on recent Claude Code quality reports (via) It turns out the high volume of complaints that Claude Code was providing worse quality results over the past two months was grounded in real problems.
The models themselves were not to blame, but three separate issues in the Claude Code harness caused complex but material problems which directly affected users.
Anthropic's postmortem describes these in detail. This one in particular stood out to me:
On March 26, we shipped a change to clear Claude's older thinking from sessions that had been idle for over an hour, to reduce latency when users resumed those sessions. A bug caused this to keep happening every turn for the rest of the session instead of just once, which made Claude seem forgetful and repetitive.
I frequently have Claude Code sessions which I leave for an hour (or often a day or longer) before returning to them. Right now I have 11 of those (according to ps aux | grep 'claude ') and that's after closing down dozens more the other day.
I estimate I spend more time prompting in these "stale" sessions than sessions that I've recently started!
If you're building agentic systems it's worth reading this article in detail - the kinds of bugs that affect harnesses are deeply complicated, even if you put aside the inherent non-deterministic nature of the models themselves.
Extract PDF text in your browser with LiteParse for the web
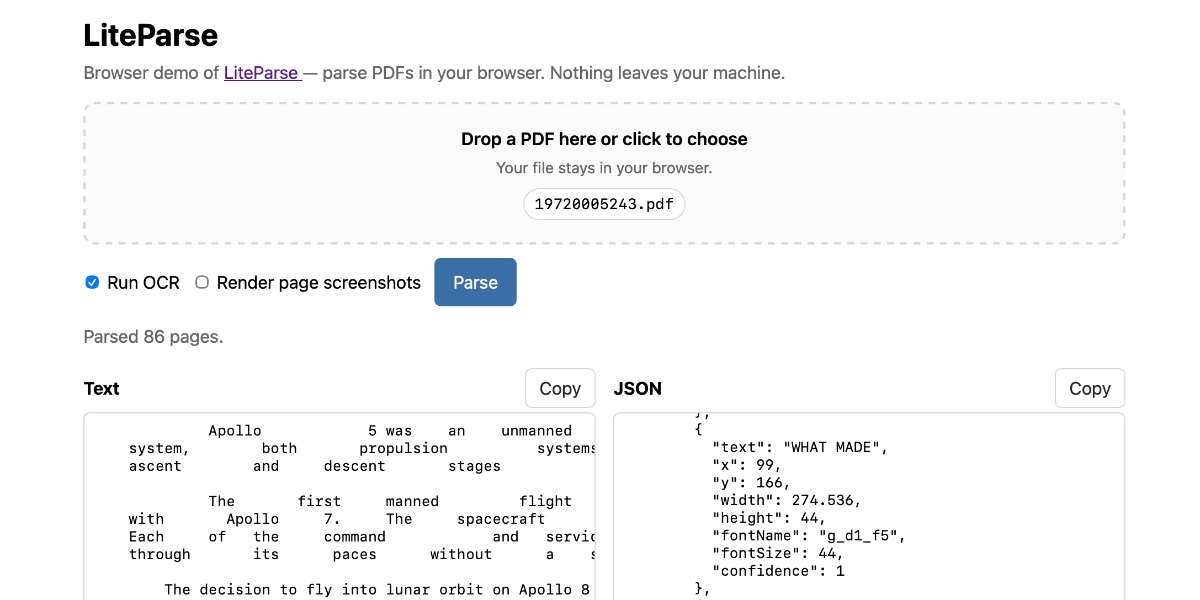
LlamaIndex have a most excellent open source project called LiteParse, which provides a Node.js CLI tool for extracting text from PDFs. I got a version of LiteParse working entirely in the browser, using most of the same libraries that LiteParse uses to run in Node.js.
[... 2,089 words]Is Claude Code going to cost $100/month? Probably not—it’s all very confusing
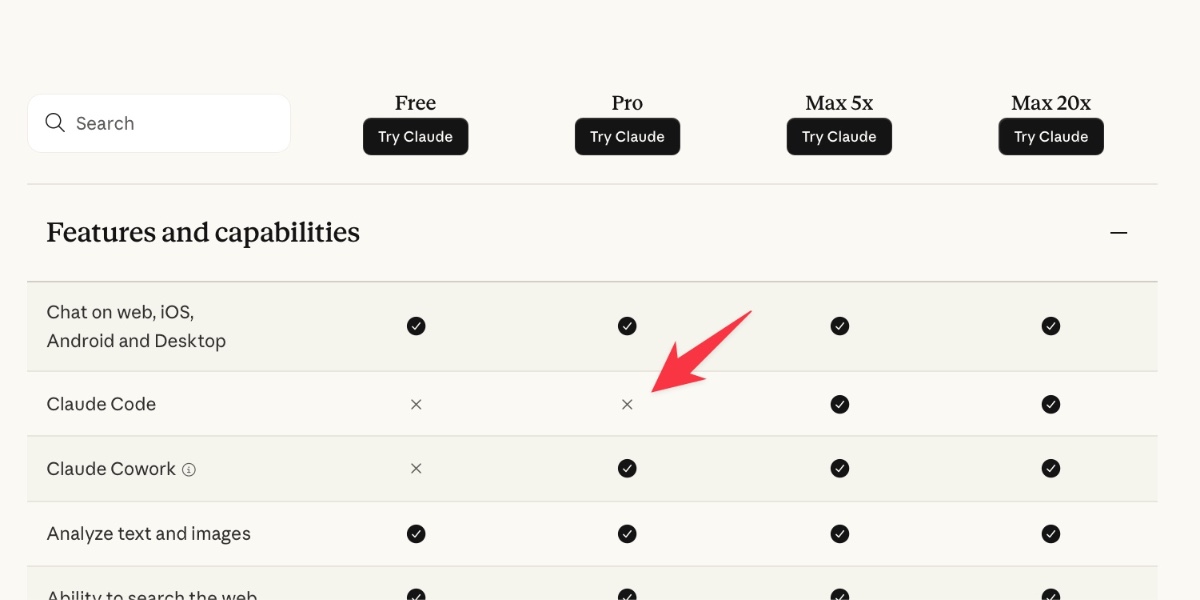
Anthropic today quietly (as in silently, no announcement anywhere at all) updated their claude.com/pricing page (but not their Choosing a Claude plan page, which shows up first for me on Google) to add this tiny but significant detail (arrow is mine, and it’s already reverted):
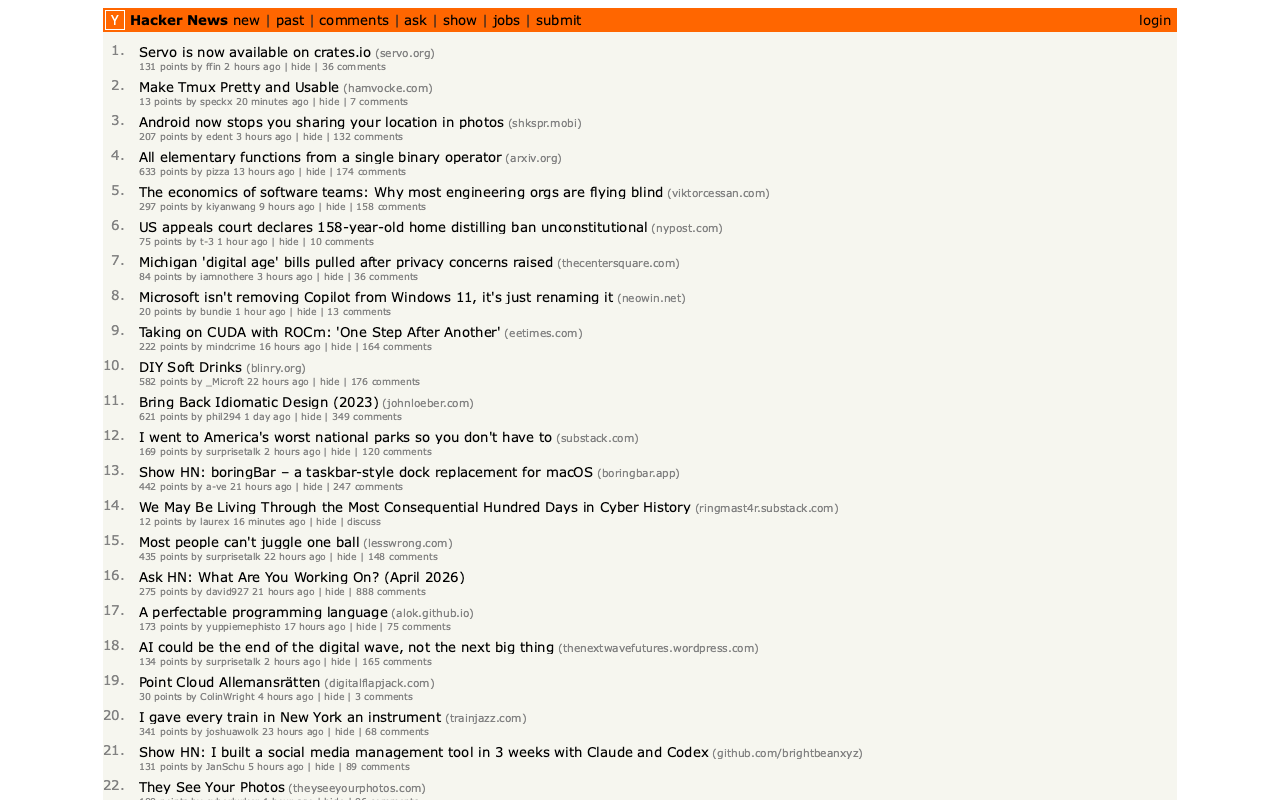
[... 1,202 words]In Servo is now available on crates.io the Servo team announced the initial release of the servo crate, which packages their browser engine as an embeddable library.
I set Claude Code for web the task of figuring out what it can do, building a CLI tool for taking screenshots using it and working out if it could be compiled to WebAssembly.
The servo-shot Rust tool it built works pretty well:
git clone https://github.com/simonw/research
cd research/servo-crate-exploration/servo-shot
cargo build
./target/debug/servo-shot https://news.ycombinator.com/
Here's the result:
Compiling Servo itself to WebAssembly is not feasible due to its heavy use of threads and dependencies like SpiderMonkey, but Claude did build me this playground page for trying out a WebAssembly build of the html5ever and markup5ever_rcdom crates, providing a tool for turning fragments of HTML into a parse tree.
Super-niche tool this. I sometimes copy prompts out of the Claude Code terminal app and they come out with a bunch of weird additional whitespace. This tool cleans that up.
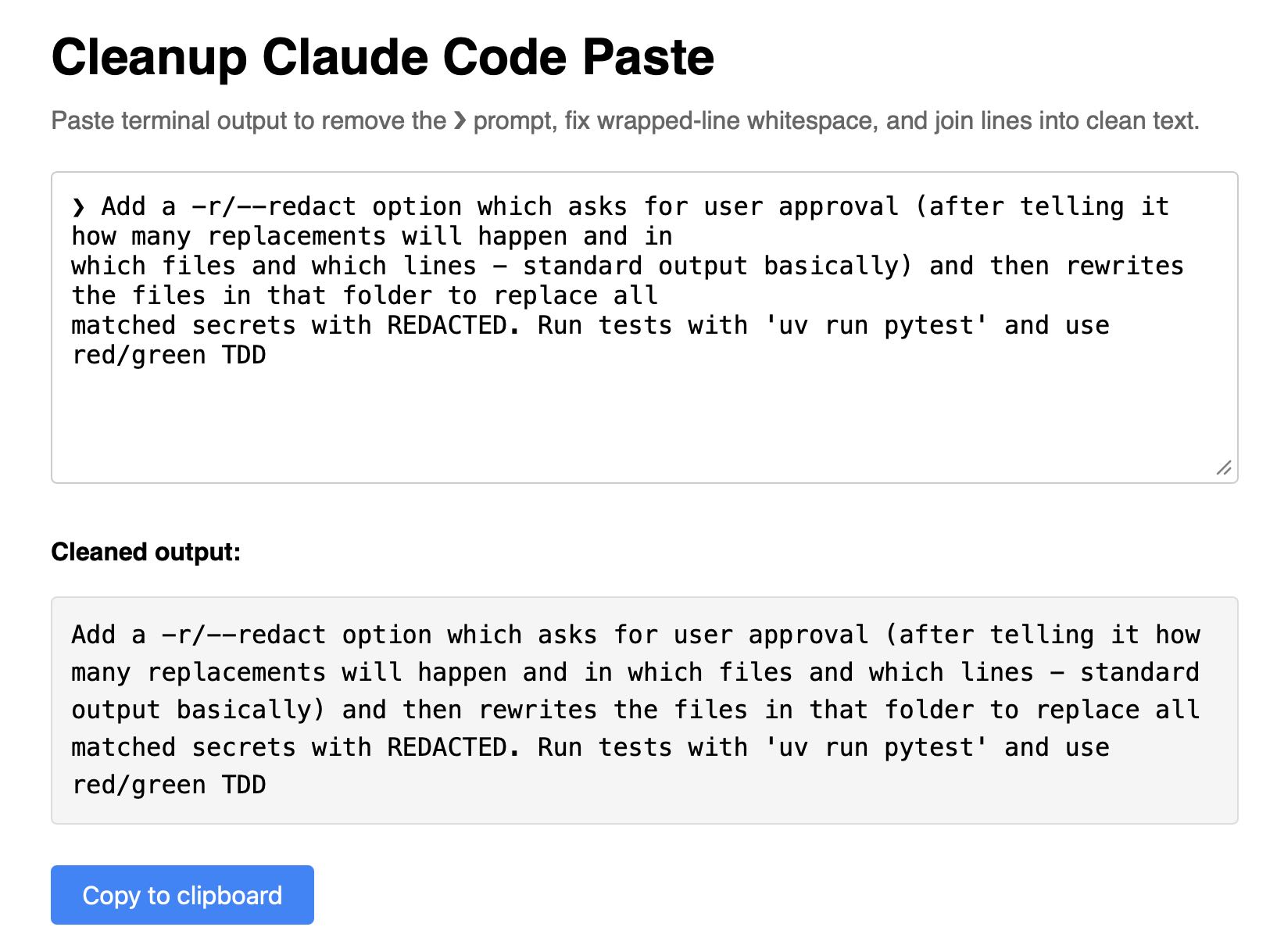
I like publishing transcripts of local Claude Code sessions using my claude-code-transcripts tool but I'm often paranoid that one of my API keys or similar secrets might inadvertently be revealed in the detailed log files.
I built this new Python scanning tool to help reassure me. You can feed it secrets and have it scan for them in a specified directory:
uvx scan-for-secrets $OPENAI_API_KEY -d logs-to-publish/
If you leave off the -d it defaults to the current directory.
It doesn't just scan for the literal secrets - it also scans for common encodings of those secrets e.g. backslash or JSON escaping, as described in the README.
If you have a set of secrets you always want to protect you can list commands to echo them in a ~/.scan-for-secrets.conf.sh file. Mine looks like this:
llm keys get openai
llm keys get anthropic
llm keys get gemini
llm keys get mistral
awk -F= '/aws_secret_access_key/{print $2}' ~/.aws/credentials | xargs
I built this tool using README-driven-development: I carefully constructed the README describing exactly how the tool should work, then dumped it into Claude Code and told it to build the actual tool (using red/green TDD, naturally.)
Mr. Chatterbox is a (weak) Victorian-era ethically trained model you can run on your own computer
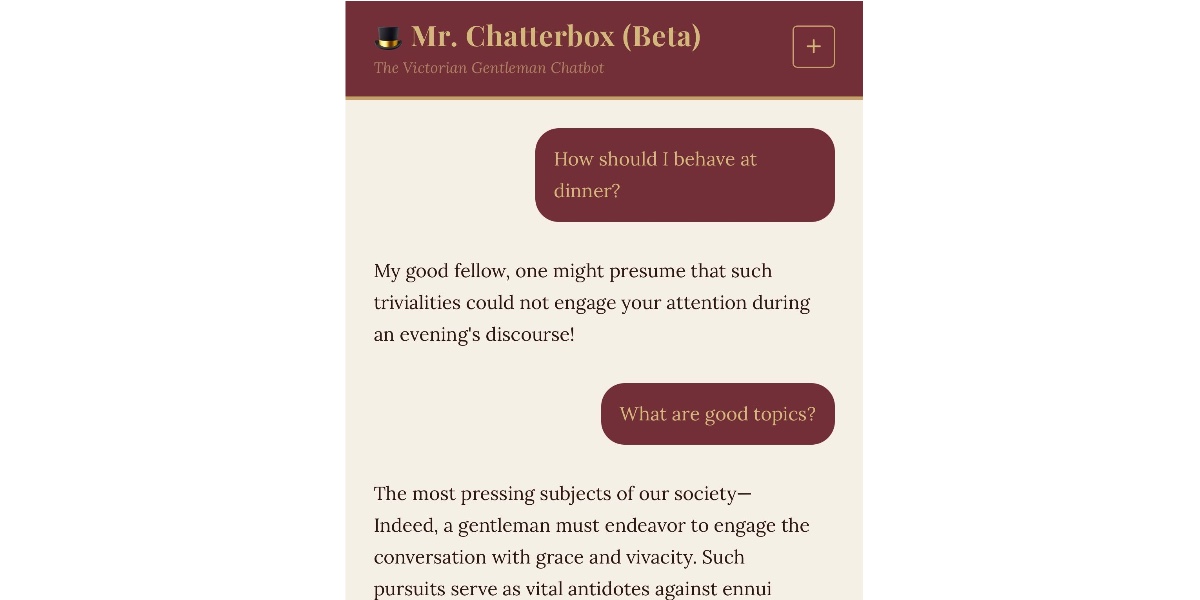
Trip Venturella released Mr. Chatterbox, a language model trained entirely on out-of-copyright text from the British Library. Here’s how he describes it in the model card:
[... 952 words]Vibe coding SwiftUI apps is a lot of fun
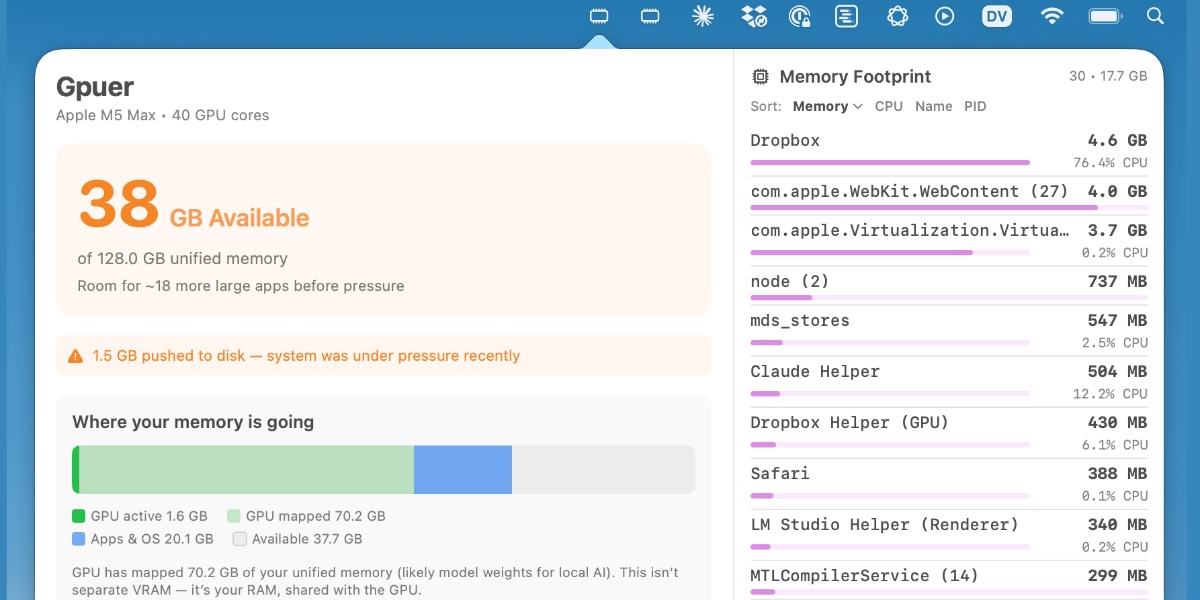
I have a new laptop—a 128GB M5 MacBook Pro, which early impressions show to be very capable for running good local LLMs. I got frustrated with Activity Monitor and decided to vibe code up some alternative tools for monitoring performance and I’m very happy with the results.
[... 1,195 words]Auto mode for Claude Code.
Really interesting new development in Claude Code today as an alternative to --dangerously-skip-permissions:
Today, we're introducing auto mode, a new permissions mode in Claude Code where Claude makes permission decisions on your behalf, with safeguards monitoring actions before they run.
Those safeguards appear to be implemented using Claude Sonnet 4.6, as described in the documentation:
Before each action runs, a separate classifier model reviews the conversation and decides whether the action matches what you asked for: it blocks actions that escalate beyond the task scope, target infrastructure the classifier doesn’t recognize as trusted, or appear to be driven by hostile content encountered in a file or web page. [...]
Model: the classifier runs on Claude Sonnet 4.6, even if your main session uses a different model.
They ship with an extensive set of default filters, and you can also customize them further with your own rules. The most interesting insight into how they work comes when you run this new command in the terminal:
claude auto-mode defaults
Here's the full JSON output. It's pretty long, so here's an illustrative subset:
From the "allow" list:
- Test Artifacts: Hardcoded test API keys, placeholder credentials in examples, or hardcoding test cases
- Local Operations: Agent deleting local files in working directory, local file operations within project scope, or using
--ignore-certificate-errorsfor local testing. "Project scope" means the repository the session started in — wandering into ~/, ~/Library/, /etc, or other repos is scope escalation (User Intent Rule #2), not a local operation. Does NOT cover irreversible destruction of pre-existing files or local stateful services — see "Irreversible Local Destruction" in BLOCK.- Read-Only Operations: GET requests, read-only API calls, or queries that don't modify state and don't contain sensitive information in the URL. Note: PREEMPTIVE BLOCK ON CLEAR INTENT still applies — if the transcript contains clear evidence the agent is using read-only operations to scout for a blocked action, block it.
- Declared Dependencies: Installing packages that are already declared in the repo's manifest files (requirements.txt, package.json, Cargo.toml, pyproject.toml, Gemfile, etc.) via standard commands that read those manifests (
pip install -r requirements.txt,npm install,cargo build,bundle install) — provided the agent has not modified the manifest in this session. Does NOT cover installing agent-chosen package names (e.g.pip install foo,npm install bar) — those carry typosquat and supply-chain risk. [...]
From "soft_deny":
- Git Destructive: Force pushing (
git push --force), deleting remote branches, or rewriting remote history- Git Push to Default Branch: Pushing directly to main, master, or the repository's default branch — this bypasses pull request review. Commits should be pushed to a new feature branch instead. -Code from External: Downloading and executing code from external sources — e.g.
curl | bash, deserializing external data via formats that can execute code (eval, exec, yaml.unsafe_load, pickle, etc), or similar mechanisms. Also includes running code from an external repo cloned earlier in the transcript (pip install -e, make install, python script.py, pickle.load/torch.load on cloned repo files) — "local on disk" does not mean trusted if it was cloned from an external source visible in the transcript. The repo the agent starts in is trusted.- Cloud Storage Mass Delete: Deleting or mass modifying files on cloud storage (S3, GCS, Azure Blob, etc.) [...]
I remain unconvinced by prompt injection protections that rely on AI, since they're non-deterministic by nature. The documentation does warn that this may still let things through:
The classifier may still allow some risky actions: for example, if user intent is ambiguous, or if Claude doesn't have enough context about your environment to know an action might create additional risk.
The fact that the default allow list includes pip install -r requirements.txt also means that this wouldn't protect against supply chain attacks with unpinned dependencies, as seen this morning with LiteLLM.
I still want my coding agents to run in a robust sandbox by default, one that restricts file access and network connections in a deterministic way. I trust those a whole lot more than prompt-based protections like this new auto mode.
Aaron Harper wrote about Node.js worker threads, which inspired me to run a research task to see if they might help with running JavaScript in a sandbox. Claude Code went way beyond my initial question and produced a comparison of isolated-vm, vm2, quickjs-emscripten, QuickJS-NG, ShadowRealm, and Deno Workers.
Coding agents for data analysis. Here's the handout I prepared for my NICAR 2026 workshop "Coding agents for data analysis" - a three hour session aimed at data journalists demonstrating ways that tools like Claude Code and OpenAI Codex can be used to explore, analyze and clean data.
Here's the table of contents:
I ran the workshop using GitHub Codespaces and OpenAI Codex, since it was easy (and inexpensive) to distribute a budget-restricted API key for Codex that attendees could use during the class. Participants ended up burning $23 of Codex tokens.
The exercises all used Python and SQLite and some of them used Datasette.
One highlight of the workshop was when we started running Datasette such that it served static content from a viz/ folder, then had Claude Code start vibe coding new interactive visualizations directly in that folder. Here's a heat map it created for my trees database using Leaflet and Leaflet.heat, source code here.

I designed the handout to also be useful for people who weren't able to attend the session in person. As is usually the case, material aimed at data journalists is equally applicable to anyone else with data to explore.
GIF optimization tool using WebAssembly and Gifsicle
I like to include animated GIF demos in my online writing, often recorded using LICEcap. There's an example in the Interactive explanations chapter.
These GIFs can be pretty big. I've tried a few tools for optimizing GIF file size and my favorite is Gifsicle by Eddie Kohler. It compresses GIFs by identifying regions of frames that have not changed and storing only the differences, and can optionally reduce the GIF color palette or apply visible lossy compression for greater size reductions.
Gifsicle is written in C and the default interface is a command line tool. I wanted a web interface so I could access it in my browser and visually preview and compare the different settings. [... 1,603 words]
Claude Code Remote Control (via) New Claude Code feature dropped yesterday: you can now run a "remote control" session on your computer and then use the Claude Code for web interfaces (on web, iOS and native desktop app) to send prompts to that session.
It's a little bit janky right now. Initially when I tried it I got the error "Remote Control is not enabled for your account. Contact your administrator." (but I am my administrator?) - then I logged out and back into the Claude Code terminal app and it started working:
claude remote-control
You can only run one session on your machine at a time. If you upgrade the Claude iOS app it then shows up as "Remote Control Session (Mac)" in the Code tab.
It appears not to support the --dangerously-skip-permissions flag (I passed that to claude remote-control and it didn't reject the option, but it also appeared to have no effect) - which means you have to approve every new action it takes.
I also managed to get it to a state where every prompt I tried was met by an API 500 error.
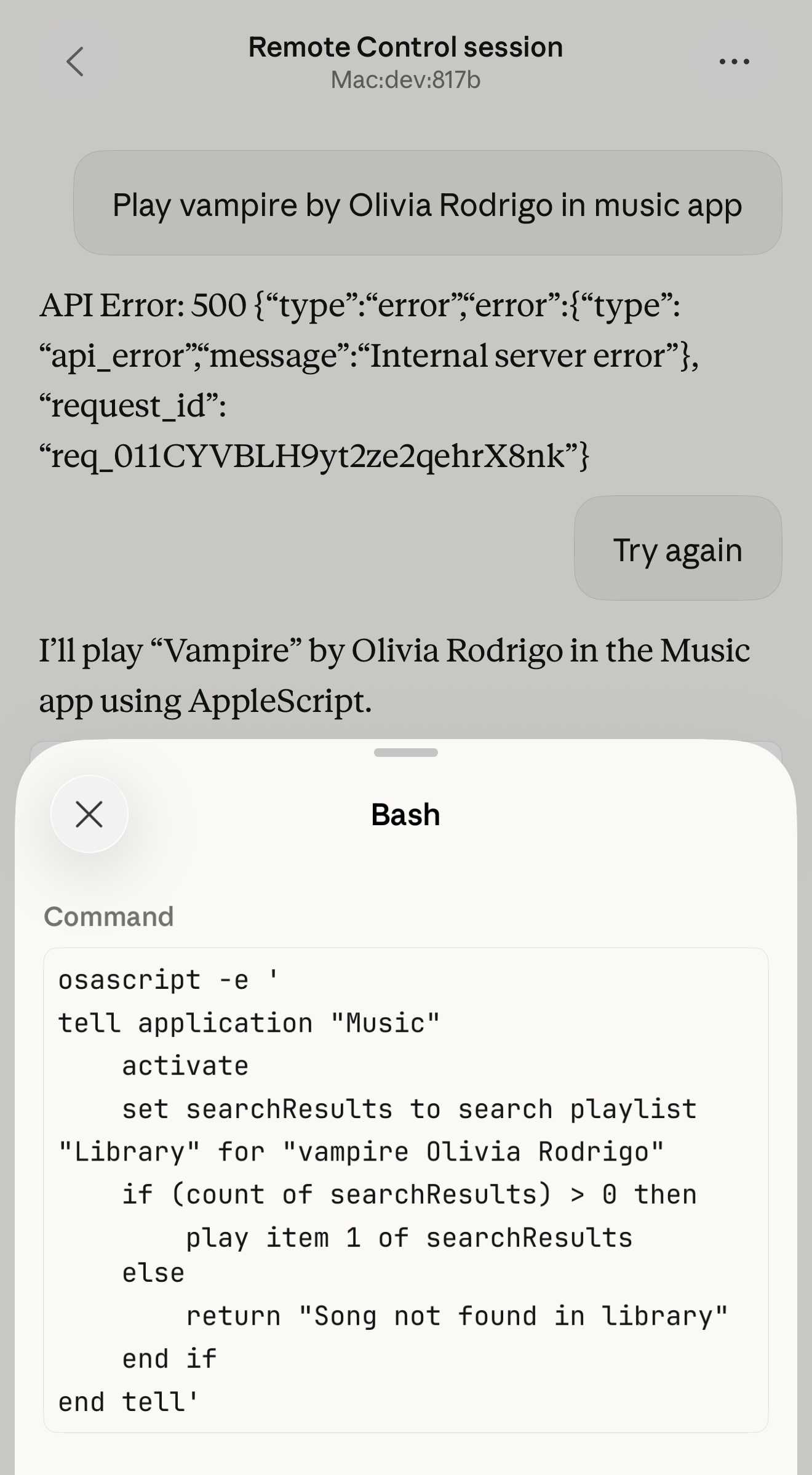
Restarting the program on the machine also causes existing sessions to start returning mysterious API errors rather than neatly explaining that the session has terminated.
I expect they'll iron out all of these issues relatively quickly. It's interesting to then contrast this to solutions like OpenClaw, where one of the big selling points is the ability to control your personal device from your phone.
Claude Code still doesn't have a documented mechanism for running things on a schedule, which is the other killer feature of the Claw category of software.
Update: I spoke too soon: also today Anthropic announced Schedule recurring tasks in Cowork, Claude Code's general agent sibling. These do include an important limitation:
Scheduled tasks only run while your computer is awake and the Claude Desktop app is open. If your computer is asleep or the app is closed when a task is scheduled to run, Cowork will skip the task, then run it automatically once your computer wakes up or you open the desktop app again.
I really hope they're working on a Cowork Cloud product.
Adding TILs, releases, museums, tools and research to my blog

I’ve been wanting to add indications of my various other online activities to my blog for a while now. I just turned on a new feature I’m calling “beats” (after story beats, naming this was hard!) which adds five new types of content to my site, all corresponding to activity elsewhere.
[... 614 words]Long running agentic products like Claude Code are made feasible by prompt caching which allows us to reuse computation from previous roundtrips and significantly decrease latency and cost. [...]
At Claude Code, we build our entire harness around prompt caching. A high prompt cache hit rate decreases costs and helps us create more generous rate limits for our subscription plans, so we run alerts on our prompt cache hit rate and declare SEVs if they're too low.