Posts in 2023
Filters: Year: 2023 × Sorted by date
Standard Webhooks 1.0.0 (via) A loose specification for implementing webhooks, put together by a technical steering committee that includes representatives from Zapier, Twilio and more.
These recommendations look great to me. Even if you don’t follow them precisely, this document is still worth reviewing any time you consider implementing webhooks—it covers a bunch of non-obvious challenges, such as responsible retry scheduling, thin-vs-thick hook payloads, authentication, custom HTTP headers and protecting against Server side request forgery attacks.
We like to assume that automation technology will maintain or increase wage levels for a few skilled supervisors. But in the long-term skilled automation supervisors also tend to earn less.
Here's an example: In 1801 the Jacquard loom was invented, which automated silkweaving with punchcards. Around 1800, a manual weaver could earn 30 shillings/week. By the 1830s the same weaver would only earn around 5s/week. A Jacquard operator earned 15s/week, but he was also 12x more productive.
The Jacquard operator upskilled and became an automation supervisor, but their wage still dropped. For manual weavers the wages dropped even more. If we believe assistive AI will deliver unseen productivity gains, we can assume that wage erosion will also be unprecedented.
SVG Tutorial: Learn SVG through 25 examples (via) Hunor Márton Borbély published this fantastic advent calendar of tutorials for learning SVG, from the basics up to advanced concepts like animation and interactivity.
Long context prompting for Claude 2.1. Claude 2.1 has a 200,000 token context, enough for around 500 pages of text. Convincing it to answer a question based on a single sentence buried deep within that content can be difficult, but Anthropic found that adding “Assistant: Here is the most relevant sentence in the context:” to the end of the prompt was enough to raise Claude 2.1’s score from 27% to 98% on their evaluation.
Ice Cubes GPT-4 prompts. The Ice Cubes open source Mastodon app recently grew a very good "describe this image" feature to help people add alt text to their images. I had a dig around in their repo and it turns out they're using GPT-4 Vision for this (and regular GPT-4 for other features), passing the image with this prompt:
What’s in this image? Be brief, it's for image alt description on a social network. Don't write in the first person.
AI and Trust. Barnstormer of an essay by Bruce Schneier about AI and trust. It’s worth spending some time with this—it’s hard to extract the highlights since there are so many of them.
A key idea is that we are predisposed to trust AI chat interfaces because they imitate humans, which means we are highly susceptible to profit-seeking biases baked into them.
Bruce suggests that what’s needed is public models, backed by government funds: “A public model is a model built by the public for the public. It requires political accountability, not just market accountability.”
GPT and other large language models are aesthetic instruments rather than epistemological ones. Imagine a weird, unholy synthesizer whose buttons sample textual information, style, and semantics. Such a thing is compelling not because it offers answers in the form of text, but because it makes it possible to play text—all the text, almost—like an instrument.
Simon Willison (Part Two): How Datasette Helps With Investigative Reporting. The second part of my Newsroom Robots podcast conversation with Nikita Roy. This episode includes my best audio answer yet to the “what is Datasette?” question, plus notes on how to use LLMs in journalism despite their propensity to make things up.
A calculator has a well-defined, well-scoped set of use cases, a well-defined, well-scoped user interface, and a set of well-understood and expected behaviors that occur in response to manipulations of that interface.
Large language models, when used to drive chatbots or similar interactive text-generation systems, have none of those qualities. They have an open-ended set of unspecified use cases.
Spider-Man: Across the Spider-Verse screenplay (PDF) (via) Phil Lord shared this on Twitter yesterday—the final screenplay for Spider-Man: Across the Spider-Verse. It’s a really fun read.
LLM Visualization. Brendan Bycroft’s beautifully crafted interactive explanation of the transformers architecture—that universal but confusing model diagram, only here you can step through and see a representation of the flurry of matrix algebra that occurs every time you get a Large Language Model to generate the next token.
Datasette Enrichments: a new plugin framework for augmenting your data

Today I’m releasing datasette-enrichments, a new feature for Datasette which provides a framework for applying “enrichments” that can augment your data.
[... 1,202 words]Write shaders for the Vegas sphere (via) Alexandre Devaux built this phenomenal three.js / WebGL demo, which displays a rotating flyover of the Vegas Sphere and lets you directly edit shader code to render your own animations on it and see what they would look like. The via Hacker News thread includes dozens of examples of scripts you can paste in.
Seamless Communication (via) A new “family of AI research models” from Meta AI for speech and text translation. The live demo is particularly worth trying—you can record a short webcam video of yourself speaking and get back the same video with your speech translated into another language.
The key to it is the new SeamlessM4T v2 model, which supports 101 languages for speech input, 96 Languages for text input/output and 35 languages for speech output. SeamlessM4T-Large v2 is a 9GB file, available on Hugging Face.
Also in this release: SeamlessExpressive, which “captures certain underexplored aspects of prosody such as speech rate and pauses”—effectively maintaining things like expressed enthusiasm across languages.
Plus SeamlessStreaming, “a model that can deliver speech and text translations with around two seconds of latency”.
So something everybody I think pretty much agrees on, including Sam Altman, including Yann LeCun, is LLMs aren't going to make it. The current LLMs are not a path to ASI. They're getting more and more expensive, they're getting more and more slow, and the more we use them, the more we realize their limitations.
We're also getting better at taking advantage of them, and they're super cool and helpful, but they appear to be behaving as extremely flexible, fuzzy, compressed search engines, which when you have enough data that's kind of compressed into the weights, turns out to be an amazingly powerful operation to have at your disposal.
[...] And the thing you can really see missing here is this planning piece, right? So if you try to get an LLM to solve fairly simple graph coloring problems or fairly simple stacking problems, things that require backtracking and trying things and stuff, unless it's something pretty similar in its training, they just fail terribly.
[...] So that's the theory about what something like Q* might be, or just in general, how do we get past this current constraint that we have?
Annotate and explore your data with datasette-comments. New plugin for Datasette and Datasette Cloud: datasette-comments, providing tools for collaborating on data exploration with a team through posting comments on individual rows of data.
Alex Garcia built this for Datasette Cloud but as with almost all of our work there it’s also available as an open source Python package.
This is what I constantly tell my students: The hard part about doing a tech product for the most part isn't the what beginners think makes tech hard — the hard part is wrangling systemic complexity in a good, sustainable and reliable way.
Many non-tech people e.g. look at programmers and think the hard part is knowing what this garble of weird text means. But this is the easy part. And if you are a person who would think it is hard, you probably don't know about all the demons out there that will come to haunt you if you don't build a foundation that helps you actively keeping them away.
— atoav
ChatGPT is one year old. Here’s how it changed the world. I’m quoted in this piece by Benj Edwards about ChatGPT’s one year birthday:
“Imagine if every human being could automate the tedious, repetitive information tasks in their lives, without needing to first get a computer science degree,” AI researcher Simon Willison told Ars in an interview about ChatGPT’s impact. “I’m seeing glimpses that LLMs might help make a huge step in that direction.”
llamafile is the new best way to run an LLM on your own computer
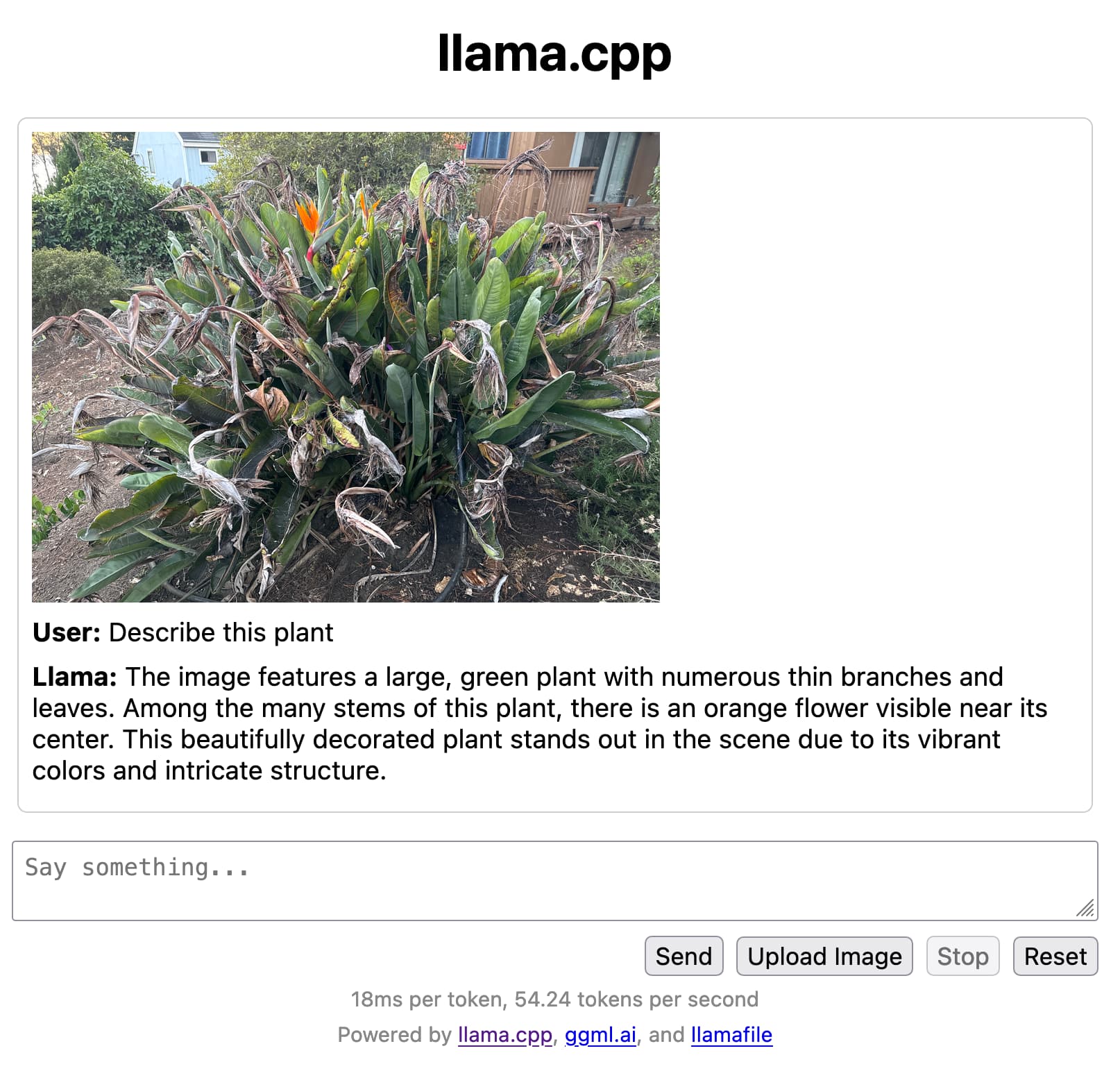
Mozilla’s innovation group and Justine Tunney just released llamafile, and I think it’s now the single best way to get started running Large Language Models (think your own local copy of ChatGPT) on your own computer.
[... 650 words]Announcing Deno Cron. Scheduling tasks in deployed applications is surprisingly difficult. Deno clearly understand this, and they’ve added a new Deno.cron(name, cron_definition, callback) mechanism for running a JavaScript function every X minutes/hours/etc.
As with several other recent Deno features, there are two versions of the implementation. The first is an in-memory implementation in the Deno open source binary, while the second is a much more robust closed-source implementation that runs in Deno Deploy:
“When a new production deployment of your project is created, an ephemeral V8 isolate is used to evaluate your project’s top-level scope and to discover any Deno.cron definitions. A global cron scheduler is then updated with your project’s latest cron definitions, which includes updates to your existing crons, new crons, and deleted crons.”
Two interesting features: unlike regular cron the Deno version prevents cron tasks that take too long from ever overlapping each other, and a backoffSchedule: [1000, 5000, 10000] option can be used to schedule attempts to re-run functions if they raise an exception.
MonadGPT (via) “What would have happened if ChatGPT was invented in the 17th century? MonadGPT is a possible answer.
MonadGPT is a finetune of Mistral-Hermes 2 on 11,000 early modern texts in English, French and Latin, mostly coming from EEBO and Gallica.
Like the original Mistral-Hermes, MonadGPT can be used in conversation mode. It will not only answer in an historical language and style but will use historical and dated references.”
Prompt injection explained, November 2023 edition

A neat thing about podcast appearances is that, thanks to Whisper transcriptions, I can often repurpose parts of them as written content for my blog.
[... 1,357 words]This is nonsensical. There is no way to understand the LLaMA models themselves as a recasting or adaptation of any of the plaintiffs’ books.
I’m on the Newsroom Robots podcast, with thoughts on the OpenAI board
Newsroom Robots is a weekly podcast exploring the intersection of AI and journalism, hosted by Nikita Roy.
[... 1,032 words]To some degree, the whole point of the tech industry’s embrace of “ethics” and “safety” is about reassurance. Companies realize that the technologies they are selling can be disconcerting and disruptive; they want to reassure the public that they’re doing their best to protect consumers and society. At the end of the day, though, we now know there’s no reason to believe that those efforts will ever make a difference if the company’s “ethics” end up conflicting with its money. And when have those two things ever not conflicted?
The 6 Types of Conversations with Generative AI. I’ve hoping to see more user research on how users interact with LLMs for a while. Here’s a study from Nielsen Norman Group, who conducted a 2-week diary study involving 18 participants, then interviewed 14 of them.
They identified six categories of conversation, and made some resulting design recommendations.
A key observation is that “search style” queries (just a few keywords) often indicate users who are new to LLMs, and should be identified as a sign that the user needs more inline education on how to best harness the tool.
Suggested follow-up prompts are valuable for most of the types of conversation identified.
YouTube: Intro to Large Language Models. Andrej Karpathy is an outstanding educator, and this one hour video offers an excellent technical introduction to LLMs.
At 42m Andrej expands on his idea of LLMs as the center of a new style of operating system, tying together tools and and a filesystem and multimodal I/O.
There’s a comprehensive section on LLM security—jailbreaking, prompt injection, data poisoning—at the 45m mark.
I also appreciated his note on how parameter size maps to file size: Llama 70B is 140GB, because each of those 70 billion parameters is a 2 byte 16bit floating point number on disk.
We have reached an agreement in principle for Sam Altman to return to OpenAI as CEO with a new initial board of Bret Taylor (Chair), Larry Summers, and Adam D'Angelo.
— @OpenAI
I remember that they [Ev and Biz at Twitter in 2008] very firmly believed spam was a concern, but, “we don’t think it's ever going to be a real problem because you can choose who you follow.” And this was one of my first moments thinking, “Oh, you sweet summer child.” Because once you have a big enough user base, once you have enough people on a platform, once the likelihood of profit becomes high enough, you’re going to have spammers.
Claude: How to use system prompts. Documentation for the new system prompt support added in Claude 2.1. The design surprises me a little: the system prompt is just the text that comes before the first instance of the text “Human: ...”—but Anthropic promise that instructions in that section of the prompt will be treated differently and followed more closely than any instructions that follow.
This whole page of documentation is giving me some pretty serious prompt injection red flags to be honest. Anthropic’s recommended way of using their models is entirely based around concatenating together strings of text using special delimiter phrases.
I’ll give it points for honesty though. OpenAI use JSON to field different parts of the prompt, but under the hood they’re all concatenated together with special tokens into a single token stream.