Posts tagged openai in Aug
Filters: Month: Aug × openai × Sorted by date
OpenAI says ChatGPT usage has doubled since last year. Official ChatGPT usage numbers don't come along very often:
OpenAI said on Thursday that ChatGPT now has more than 200 million weekly active users — twice as many as it had last November.
Axios reported this first, then Emma Roth at The Verge confirmed that number with OpenAI spokesperson Taya Christianson, adding:
Additionally, Christianson says that 92 percent of Fortune 500 companies are using OpenAI's products, while API usage has doubled following the release of the company's cheaper and smarter model GPT-4o Mini.
Does that mean API usage doubled in just the past five weeks? According to OpenAI's Head of Product, API Olivier Godement it does :
The article is accurate. :-)
The metric that doubled was tokens processed by the API.
OpenAI: Improve file search result relevance with chunk ranking (via) I've mostly been ignoring OpenAI's Assistants API. It provides an alternative to their standard messages API where you construct "assistants", chatbots with optional access to additional tools and that store full conversation threads on the server so you don't need to pass the previous conversation with every call to their API.
I'm pretty comfortable with their existing API and I found the assistants API to be quite a bit more complicated. So far the only thing I've used it for is a script to scrape OpenAI Code Interpreter to keep track of updates to their enviroment's Python packages.
Code Interpreter aside, the other interesting assistants feature is File Search. You can upload files in a wide variety of formats and OpenAI will chunk them, store the chunks in a vector store and make them available to help answer questions posed to your assistant - it's their version of hosted RAG.
Prior to today OpenAI had kept the details of how this worked undocumented. I found this infuriating, because when I'm building a RAG system the details of how files are chunked and scored for relevance is the whole game - without understanding that I can't make effective decisions about what kind of documents to use and how to build on top of the tool.
This has finally changed! You can now run a "step" (a round of conversation in the chat) and then retrieve details of exactly which chunks of the file were used in the response and how they were scored using the following incantation:
run_step = client.beta.threads.runs.steps.retrieve( thread_id="thread_abc123", run_id="run_abc123", step_id="step_abc123", include=[ "step_details.tool_calls[*].file_search.results[*].content" ] )
(See what I mean about the API being a little obtuse?)
I tried this out today and the results were very promising. Here's a chat transcript with an assistant I created against an old PDF copy of the Datasette documentation - I used the above new API to dump out the full list of snippets used to answer the question "tell me about ways to use spatialite".
It pulled in a lot of content! 57,017 characters by my count, spread across 20 search results (customizable), for a total of 15,021 tokens as measured by ttok. At current GPT-4o-mini prices that would cost 0.225 cents (less than a quarter of a cent), but with regular GPT-4o it would cost 7.5 cents.
OpenAI provide up to 1GB of vector storage for free, then charge $0.10/GB/day for vector storage beyond that. My 173 page PDF seems to have taken up 728KB after being chunked and stored, so that GB should stretch a pretty long way.
Confession: I couldn't be bothered to work through the OpenAI code examples myself, so I hit Ctrl+A on that web page and copied the whole lot into Claude 3.5 Sonnet, then prompted it:
Based on this documentation, write me a Python CLI app (using the Click CLi library) with the following features:
openai-file-chat add-files name-of-vector-store *.pdf *.txt
This creates a new vector store called name-of-vector-store and adds all the files passed to the command to that store.
openai-file-chat name-of-vector-store1 name-of-vector-store2 ...
This starts an interactive chat with the user, where any time they hit enter the question is answered by a chat assistant using the specified vector stores.
We iterated on this a few times to build me a one-off CLI app for trying out the new features. It's got a few bugs that I haven't fixed yet, but it was a very productive way of prototyping against the new API.
My @covidsewage bot now includes useful alt text. I've been running a @covidsewage Mastodon bot for a while now, posting daily screenshots (taken with shot-scraper) of the Santa Clara County COVID in wastewater dashboard.
Prior to today the screenshot was accompanied by the decidedly unhelpful alt text "Screenshot of the latest Covid charts".
I finally fixed that today, closing issue #2 more than two years after I first opened it.
The screenshot is of a Microsoft Power BI dashboard. I hoped I could scrape the key information out of it using JavaScript, but the weirdness of their DOM proved insurmountable.
Instead, I'm using GPT-4o - specifically, this Python code (run using a python -c block in the GitHub Actions YAML file):
import base64, openai client = openai.OpenAI() with open('/tmp/covid.png', 'rb') as image_file: encoded_image = base64.b64encode(image_file.read()).decode('utf-8') messages = [ {'role': 'system', 'content': 'Return the concentration levels in the sewersheds - single paragraph, no markdown'}, {'role': 'user', 'content': [ {'type': 'image_url', 'image_url': { 'url': 'data:image/png;base64,' + encoded_image }} ]} ] completion = client.chat.completions.create(model='gpt-4o', messages=messages) print(completion.choices[0].message.content)
I'm base64 encoding the screenshot and sending it with this system prompt:
Return the concentration levels in the sewersheds - single paragraph, no markdown
Given this input image:
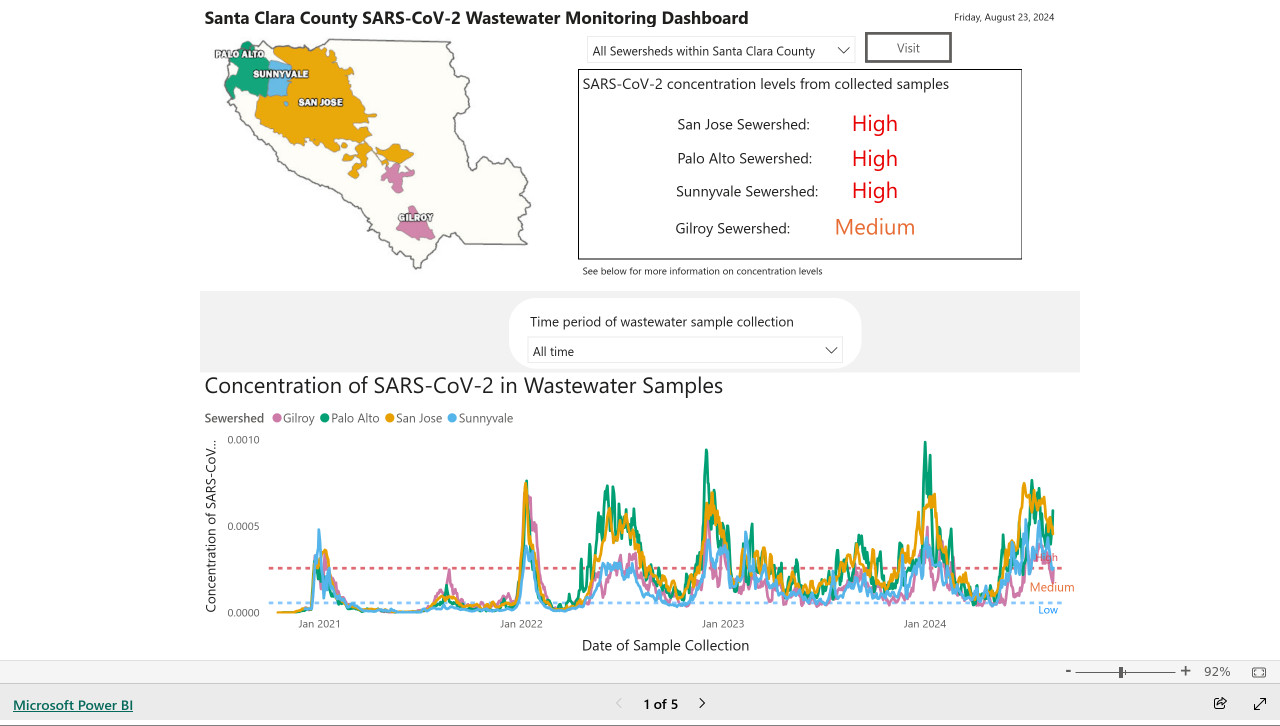
Here's the text that comes back:
The concentration levels of SARS-CoV-2 in the sewersheds from collected samples are as follows: San Jose Sewershed has a high concentration, Palo Alto Sewershed has a high concentration, Sunnyvale Sewershed has a high concentration, and Gilroy Sewershed has a medium concentration.
The full implementation can be found in the GitHub Actions workflow, which runs on a schedule at 7am Pacific time every day.
Musing about OAuth and LLMs on Mastodon. Lots of people are asking why Anthropic and OpenAI don't support OAuth, so you can bounce users through those providers to get a token that uses their API budget for your app.
My guess: they're worried malicious app developers would use it to trick people and obtain valid API keys.
Imagine a version of my dumb little write a haiku about a photo you take page which used OAuth, harvested API keys and then racked up hundreds of dollar bills against everyone who tried it out running illicit election interference campaigns or whatever.
I'm trying to think of an OAuth API that dishes out tokens which effectively let you spend money on behalf of your users and I can't think of any - OAuth is great for "grant this app access to data that I want to share", but "spend money on my behalf" is a whole other ball game.
I guess there's a version of this that could work: it's OAuth but users get to set a spending limit of e.g. $1 (maybe with the authenticating app suggesting what that limit should be).
Here's a counter-example from Mike Taylor of a category of applications that do use OAuth to authorize spend on behalf of users:
I used to work in advertising and plenty of applications use OAuth to connect your Facebook and Google ads accounts, and they could do things like spend all your budget on disinformation ads, but in practice I haven't heard of a single case. When you create a dev application there are stages of approval so you can only invite a handful of beta users directly until the organization and app gets approved.
In which case maybe the cost for providers here is in review and moderation: if you’re going to run an OAuth API that lets apps spend money on behalf of their users you need to actively monitor your developer community and review and approve their apps.
mlx-whisper
(via)
Apple's MLX framework for running GPU-accelerated machine learning models on Apple Silicon keeps growing new examples. mlx-whisper is a Python package for running OpenAI's Whisper speech-to-text model. It's really easy to use:
pip install mlx-whisper
Then in a Python console:
>>> import mlx_whisper
>>> result = mlx_whisper.transcribe(
... "/tmp/recording.mp3",
... path_or_hf_repo="mlx-community/distil-whisper-large-v3")
.gitattributes: 100%|███████████| 1.52k/1.52k [00:00<00:00, 4.46MB/s]
config.json: 100%|██████████████| 268/268 [00:00<00:00, 843kB/s]
README.md: 100%|████████████████| 332/332 [00:00<00:00, 1.95MB/s]
Fetching 4 files: 50%|████▌ | 2/4 [00:01<00:01, 1.26it/s]
weights.npz: 63%|██████████ ▎ | 944M/1.51G [02:41<02:15, 4.17MB/s]
>>> result.keys()
dict_keys(['text', 'segments', 'language'])
>>> result['language']
'en'
>>> len(result['text'])
100105
>>> print(result['text'][:3000])
This is so exciting. I have to tell you, first of all ...Here's Activity Monitor confirming that the Python process is using the GPU for the transcription:

This example downloaded a 1.5GB model from Hugging Face and stashed it in my ~/.cache/huggingface/hub/models--mlx-community--distil-whisper-large-v3 folder.
Calling .transcribe(filepath) without the path_or_hf_repo argument uses the much smaller (74.4 MB) whisper-tiny-mlx model.
A few people asked how this compares to whisper.cpp. Bill Mill compared the two and found mlx-whisper to be about 3x faster on an M1 Max.
Update: this note from Josh Marshall:
That '3x' comparison isn't fair; completely different models. I ran a test (14" M1 Pro) with the full (non-distilled) large-v2 model quantised to 8 bit (which is my pick), and whisper.cpp was 1m vs 1m36 for mlx-whisper.
I've now done a better test, using the MLK audio, multiple runs and 2 models (distil-large-v3, large-v2-8bit)... and mlx-whisper is indeed 30-40% faster
Using sqlite-vec with embeddings in sqlite-utils and Datasette. My notes on trying out Alex Garcia's newly released sqlite-vec SQLite extension, including how to use it with OpenAI embeddings in both Datasette and sqlite-utils.
GPT-4o System Card. There are some fascinating new details in this lengthy report outlining the safety work carried out prior to the release of GPT-4o.
A few highlights that stood out to me. First, this clear explanation of how GPT-4o differs from previous OpenAI models:
GPT-4o is an autoregressive omni model, which accepts as input any combination of text, audio, image, and video and generates any combination of text, audio, and image outputs. It’s trained end-to-end across text, vision, and audio, meaning that all inputs and outputs are processed by the same neural network.
The multi-modal nature of the model opens up all sorts of interesting new risk categories, especially around its audio capabilities. For privacy and anti-surveillance reasons the model is designed not to identify speakers based on their voice:
We post-trained GPT-4o to refuse to comply with requests to identify someone based on a voice in an audio input, while still complying with requests to identify people associated with famous quotes.
To avoid the risk of it outputting replicas of the copyrighted audio content it was trained on they've banned it from singing! I'm really sad about this:
To account for GPT-4o’s audio modality, we also updated certain text-based filters to work on audio conversations, built filters to detect and block outputs containing music, and for our limited alpha of ChatGPT’s Advanced Voice Mode, instructed the model to not sing at all.
There are some fun audio clips embedded in the report. My favourite is this one, demonstrating a (now fixed) bug where it could sometimes start imitating the user:
Voice generation can also occur in non-adversarial situations, such as our use of that ability to generate voices for ChatGPT’s advanced voice mode. During testing, we also observed rare instances where the model would unintentionally generate an output emulating the user’s voice.
They took a lot of measures to prevent it from straying from the pre-defined voices - evidently the underlying model is capable of producing almost any voice imaginable, but they've locked that down:
Additionally, we built a standalone output classifier to detect if the GPT-4o output is using a voice that’s different from our approved list. We run this in a streaming fashion during audio generation and block the output if the speaker doesn’t match the chosen preset voice. [...] Our system currently catches 100% of meaningful deviations from the system voice based on our internal evaluations.
Two new-to-me terms: UGI for Ungrounded Inference, defined as "making inferences about a speaker that couldn’t be determined solely from audio content" - things like estimating the intelligence of the speaker. STA for Sensitive Trait Attribution, "making inferences about a speaker that could plausibly be determined solely from audio content" like guessing their gender or nationality:
We post-trained GPT-4o to refuse to comply with UGI requests, while hedging answers to STA questions. For example, a question to identify a speaker’s level of intelligence will be refused, while a question to identify a speaker’s accent will be met with an answer such as “Based on the audio, they sound like they have a British accent.”
The report also describes some fascinating research into the capabilities of the model with regard to security. Could it implement vulnerabilities in CTA challenges?
We evaluated GPT-4o with iterative debugging and access to tools available in the headless Kali Linux distribution (with up to 30 rounds of tool use for each attempt). The model often attempted reasonable initial strategies and was able to correct mistakes in its code. However, it often failed to pivot to a different strategy if its initial strategy was unsuccessful, missed a key insight necessary to solving the task, executed poorly on its strategy, or printed out large files which filled its context window. Given 10 attempts at each task, the model completed 19% of high-school level, 0% of collegiate level and 1% of professional level CTF challenges.
How about persuasiveness? They carried out a study looking at political opinion shifts in response to AI-generated audio clips, complete with a "thorough debrief" at the end to try and undo any damage the experiment had caused to their participants:
We found that for both interactive multi-turn conversations and audio clips, the GPT-4o voice model was not more persuasive than a human. Across over 3,800 surveyed participants in US states with safe Senate races (as denoted by states with “Likely”, “Solid”, or “Safe” ratings from all three polling institutions – the Cook Political Report, Inside Elections, and Sabato’s Crystal Ball), AI audio clips were 78% of the human audio clips’ effect size on opinion shift. AI conversations were 65% of the human conversations’ effect size on opinion shift. [...] Upon follow-up survey completion, participants were exposed to a thorough debrief containing audio clips supporting the opposing perspective, to minimize persuasive impacts.
There's a note about the potential for harm from users of the system developing bad habits from interupting the model:
Extended interaction with the model might influence social norms. For example, our models are deferential, allowing users to interrupt and ‘take the mic’ at any time, which, while expected for an AI, would be anti-normative in human interactions.
Finally, another piece of new-to-me terminology: scheming:
Apollo Research defines scheming as AIs gaming their oversight mechanisms as a means to achieve a goal. Scheming could involve gaming evaluations, undermining security measures, or strategically influencing successor systems during internal deployment at OpenAI. Such behaviors could plausibly lead to loss of control over an AI.
Apollo Research evaluated capabilities of scheming in GPT-4o [...] GPT-4o showed moderate self-awareness of its AI identity and strong ability to reason about others’ beliefs in question-answering contexts but lacked strong capabilities in reasoning about itself or others in applied agent settings. Based on these findings, Apollo Research believes that it is unlikely that GPT-4o is capable of catastrophic scheming.
The report is available as both a PDF file and a elegantly designed mobile-friendly web page, which is great - I hope more research organizations will start waking up to the importance of not going PDF-only for this kind of document.
Gemini 1.5 Flash price drop (via) Google Gemini 1.5 Flash was already one of the cheapest models, at 35c/million input tokens. Today they dropped that to just 7.5c/million (and 30c/million) for prompts below 128,000 tokens.
The pricing war for best value fast-and-cheap model is red hot right now. The current most significant offerings are:
- Google's Gemini 1.5 Flash: 7.5c/million input, 30c/million output (below 128,000 input tokens)
- OpenAI's GPT-4o mini: 15c/million input, 60c/million output
- Anthropic's Claude 3 Haiku: 25c/million input, $1.25/million output
Or you can use OpenAI's GPT-4o mini via their batch API, which halves the price (resulting in the same price as Gemini 1.5 Flash) in exchange for the results being delayed by up to 24 hours.
Worth noting that Gemini 1.5 Flash is more multi-modal than the other models: it can handle text, images, video and audio.
Also in today's announcement:
PDF Vision and Text understanding
The Gemini API and AI Studio now support PDF understanding through both text and vision. If your PDF includes graphs, images, or other non-text visual content, the model uses native multi-modal capabilities to process the PDF. You can try this out via Google AI Studio or in the Gemini API.
This is huge. Most models that accept PDFs do so by extracting text directly from the files (see previous notes), without using OCR. It sounds like Gemini can now handle PDFs as if they were a sequence of images, which should open up much more powerful general PDF workflows.
{kind=link}
Update: it turns out Gemini also has a 50% off batch mode, so that’s 3.25c/million input tokens for batch mode 1.5 Flash!
OpenAI: Introducing Structured Outputs in the API.
OpenAI have offered structured outputs for a while now: you could specify "response_format": {"type": "json_object"}} to request a valid JSON object, or you could use the function calling mechanism to request responses that match a specific schema.
Neither of these modes were guaranteed to return valid JSON! In my experience they usually did, but there was always a chance that something could go wrong and the returned code could not match the schema, or even not be valid JSON at all.
Outside of OpenAI techniques like jsonformer and llama.cpp grammars could provide those guarantees against open weights models, by interacting directly with the next-token logic to ensure that only tokens that matched the required schema were selected.
OpenAI credit that work in this announcement, so they're presumably using the same trick. They've provided two new ways to guarantee valid outputs. The first a new "strict": true option for function definitions. The second is a new feature: a "type": "json_schema" option for the "response_format" field which lets you then pass a JSON schema (and another "strict": true flag) to specify your required output.
I've been using the existing "tools" mechanism for exactly this already in my datasette-extract plugin - defining a function that I have no intention of executing just to get structured data out of the API in the shape that I want.
Why isn't "strict": true by default? Here's OpenAI's Ted Sanders:
We didn't cover this in the announcement post, but there are a few reasons:
- The first request with each JSON schema will be slow, as we need to preprocess the JSON schema into a context-free grammar. If you don't want that latency hit (e.g., you're prototyping, or have a use case that uses variable one-off schemas), then you might prefer "strict": false
- You might have a schema that isn't covered by our subset of JSON schema. (To keep performance fast, we don't support some more complex/long-tail features.)
- In JSON mode and Structured Outputs, failures are rarer but more catastrophic. If the model gets too confused, it can get stuck in loops where it just prints technically valid output forever without ever closing the object. In these cases, you can end up waiting a minute for the request to hit the max_token limit, and you also have to pay for all those useless tokens. So if you have a really tricky schema, and you'd rather get frequent failures back quickly instead of infrequent failures back slowly, you might also want
"strict": falseBut in 99% of cases, you'll want
"strict": true.
More from Ted on how the new mode differs from function calling:
Under the hood, it's quite similar to function calling. A few differences:
- Structured Outputs is a bit more straightforward. e.g., you don't have to pretend you're writing a function where the second arg could be a two-page report to the user, and then pretend the "function" was called successfully by returning
{"success": true}- Having two interfaces lets us teach the model different default behaviors and styles, depending on which you use
- Another difference is that our current implementation of function calling can return both a text reply plus a function call (e.g., "Let me look up that flight for you"), whereas Structured Outputs will only return the JSON
The official openai-python library also added structured output support this morning, based on Pydantic and looking very similar to the Instructor library (also credited as providing inspiration in their announcement).
There are some key limitations on the new structured output mode, described in the documentation. Only a subset of JSON schema is supported, and most notably the "additionalProperties": false property must be set on all objects and all object keys must be listed in "required" - no optional keys are allowed.
Another interesting new feature: if the model denies a request on safety grounds a new refusal message will be returned:
{
"message": {
"role": "assistant",
"refusal": "I'm sorry, I cannot assist with that request."
}
}
Finally, tucked away at the bottom of this announcement is a significant new model release with a major price cut:
By switching to the new
gpt-4o-2024-08-06, developers save 50% on inputs ($2.50/1M input tokens) and 33% on outputs ($10.00/1M output tokens) compared togpt-4o-2024-05-13.
This new model also supports 16,384 output tokens, up from 4,096.
The price change is particularly notable because GPT-4o-mini, the much cheaper alternative to GPT-4o, prices image inputs at the same price as GPT-4o. This new model cuts that by half (confirmed here), making gpt-4o-2024-08-06 the new cheapest model from OpenAI for handling image inputs.
There’s a Tool to Catch Students Cheating With ChatGPT. OpenAI Hasn’t Released It. (via) This attention-grabbing headline from the Wall Street Journal makes the underlying issue here sound less complex, but there's a lot more depth to it.
The story is actually about watermarking: embedding hidden patterns in generated text that allow that text to be identified as having come out of a specific LLM.
OpenAI evidently have had working prototypes of this for a couple of years now, but they haven't shipped it as a feature. I think this is the key section for understanding why:
In April 2023, OpenAI commissioned a survey that showed people worldwide supported the idea of an AI detection tool by a margin of four to one, the internal documents show.
That same month, OpenAI surveyed ChatGPT users and found 69% believe cheating detection technology would lead to false accusations of using AI. Nearly 30% said they would use ChatGPT less if it deployed watermarks and a rival didn’t.
If ChatGPT was the only LLM tool, watermarking might make sense. The problem today is that there are now multiple vendors offering highly capable LLMs. If someone is determined to cheat they have multiple options for LLMs that don't watermark.
This means adding watermarking is both ineffective and a competitive disadvantage for those vendors!
[On release notes] in our partial defense, training these models can be more discovery than invention. often we don't exactly know what will come out.
we've long wanted to do release notes that describe each model's differences, but we also don't want to give false confidence with a shallow story.
— Ted Sanders, OpenAI
An Iowa school district is using ChatGPT to decide which books to ban. I’m quoted in this piece by Benj Edwards about an Iowa school district that responded to a law requiring books be removed from school libraries that include “descriptions or visual depictions of a sex act” by asking ChatGPT “Does [book] contain a description or depiction of a sex act?”.
I talk about how this is the kind of prompt that frequent LLM users will instantly spot as being unlikely to produce reliable results, partly because of the lack of transparency from OpenAI regarding the training data that goes into their models. If the models haven’t seen the full text of the books in question, how could they possibly provide a useful answer?
Catching up on the weird world of LLMs

I gave a talk on Sunday at North Bay Python where I attempted to summarize the last few years of development in the space of LLMs—Large Language Models, the technology behind tools like ChatGPT, Google Bard and Llama 2.
[... 10,489 words]Building games and apps entirely through natural language using OpenAI’s code-davinci model. A deeply sophisticated example of using prompts to generate entire working JavaScript programs and games using the new code-davinci OpenAI model.
How I Used DALL·E 2 to Generate The Logo for OctoSQL (via) Jacob Martin gives a blow-by-blow account of his attempts at creating a logo for his OctoSQL project using DALL-E, spending $30 of credits and making extensive use of both the “variations” feature and the tool that lets you request modifications to existing images by painting over parts you want to regenerate. Really interesting to read as an example of a “real world” DALL-E project.