October 2025
142 posts: 12 entries, 39 links, 18 quotes, 12 notes, 61 beats
Oct. 18, 2025
Andrej Karpathy — AGI is still a decade away (via) Extremely high signal 2 hour 25 minute (!) conversation between Andrej Karpathy and Dwarkesh Patel.
It starts with Andrej's claim that "the year of agents" is actually more likely to take a decade. Seeing as I accepted 2025 as the year of agents just yesterday this instantly caught my attention!
It turns out Andrej is using a different definition of agents to the one that I prefer - emphasis mine:
When you’re talking about an agent, or what the labs have in mind and maybe what I have in mind as well, you should think of it almost like an employee or an intern that you would hire to work with you. For example, you work with some employees here. When would you prefer to have an agent like Claude or Codex do that work?
Currently, of course they can’t. What would it take for them to be able to do that? Why don’t you do it today? The reason you don’t do it today is because they just don’t work. They don’t have enough intelligence, they’re not multimodal enough, they can’t do computer use and all this stuff.
They don’t do a lot of the things you’ve alluded to earlier. They don’t have continual learning. You can’t just tell them something and they’ll remember it. They’re cognitively lacking and it’s just not working. It will take about a decade to work through all of those issues.
Yeah, continual learning human-replacement agents definitely isn't happening in 2025! Coding agents that are really good at running tools in the loop on the other hand are here already.
I loved this bit introducing an analogy of LLMs as ghosts or spirits, as opposed to having brains like animals or humans:
Brains just came from a very different process, and I’m very hesitant to take inspiration from it because we’re not actually running that process. In my post, I said we’re not building animals. We’re building ghosts or spirits or whatever people want to call it, because we’re not doing training by evolution. We’re doing training by imitation of humans and the data that they’ve put on the Internet.
You end up with these ethereal spirit entities because they’re fully digital and they’re mimicking humans. It’s a different kind of intelligence. If you imagine a space of intelligences, we’re starting off at a different point almost. We’re not really building animals. But it’s also possible to make them a bit more animal-like over time, and I think we should be doing that.
The post Andrej mentions is Animals vs Ghosts on his blog.
Dwarkesh asked Andrej about this tweet where he said that Claude Code and Codex CLI "didn't work well enough at all and net unhelpful" for his nanochat project. Andrej responded:
[...] So the agents are pretty good, for example, if you’re doing boilerplate stuff. Boilerplate code that’s just copy-paste stuff, they’re very good at that. They’re very good at stuff that occurs very often on the Internet because there are lots of examples of it in the training sets of these models. There are features of things where the models will do very well.
I would say nanochat is not an example of those because it’s a fairly unique repository. There’s not that much code in the way that I’ve structured it. It’s not boilerplate code. It’s intellectually intense code almost, and everything has to be very precisely arranged. The models have so many cognitive deficits. One example, they kept misunderstanding the code because they have too much memory from all the typical ways of doing things on the Internet that I just wasn’t adopting.
Update: Here's an essay length tweet from Andrej clarifying a whole bunch of the things he talked about on the podcast.
The AI water issue is fake. Andy Masley (previously):
All U.S. data centers (which mostly support the internet, not AI) used 200--250 million gallons of freshwater daily in 2023. The U.S. consumes approximately 132 billion gallons of freshwater daily. The U.S. circulates a lot more water day to day, but to be extra conservative I'll stick to this measure of its consumptive use, see here for a breakdown of how the U.S. uses water. So data centers in the U.S. consumed approximately 0.2% of the nation's freshwater in 2023. [...]
The average American’s consumptive lifestyle freshwater footprint is 422 gallons per day. This means that in 2023, AI data centers used as much water as the lifestyles of 25,000 Americans, 0.007% of the population. By 2030, they might use as much as the lifestyles of 250,000 Americans, 0.07% of the population.
Andy also points out that manufacturing a t-shirt uses the same amount of water as 1,300,000 prompts.
See also this TikTok by MyLifeIsAnRPG, who points out that the beef industry and fashion and textiles industries use an order of magnitude more water (~90x upwards) than data centers used for AI.
TIL: Exploring OpenAI’s deep research API model o4-mini-deep-research. I landed a PR by Manuel Solorzano adding pricing information to llm-prices.com for OpenAI's o4-mini-deep-research and o3-deep-research models, which they released in June and document here.
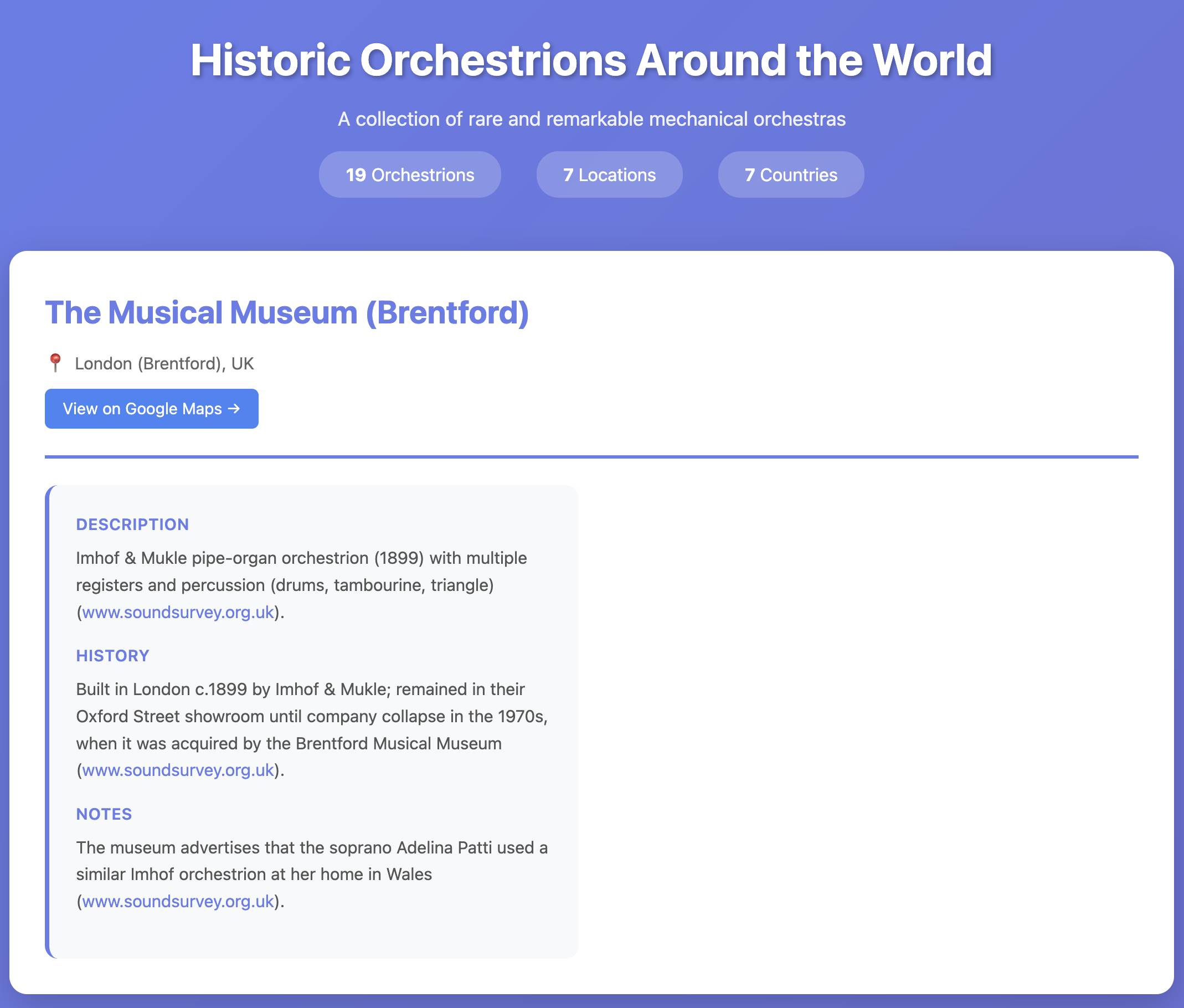
I realized I'd never tried these before, so I put o4-mini-deep-research through its paces researching locations of surviving orchestrions for me (I really like orchestrions).
The API cost me $1.10 and triggered a small flurry of extra vibe-coded tools, including this new tool for visualizing Responses API traces from deep research models and this mocked up page listing the 19 orchestrions it found (only one of which I have fact-checked myself).
Oct. 19, 2025
Oct. 20, 2025
Getting DeepSeek-OCR working on an NVIDIA Spark via brute force using Claude Code

DeepSeek released a new model yesterday: DeepSeek-OCR, a 6.6GB model fine-tuned specifically for OCR. They released it as model weights that run using PyTorch and CUDA. I got it running on the NVIDIA Spark by having Claude Code effectively brute force the challenge of getting it working on that particular hardware.
[... 1,971 words]Claude Code for web—a new asynchronous coding agent from Anthropic
Anthropic launched Claude Code for web this morning. It’s an asynchronous coding agent—their answer to OpenAI’s Codex Cloud and Google’s Jules, and has a very similar shape. I had preview access over the weekend and I’ve already seen some very promising results from it.
[... 1,434 words]Oct. 21, 2025
Prompt injection might be unsolvable in today’s LLMs. LLMs process token sequences, but no mechanism exists to mark token privileges. Every solution proposed introduces new injection vectors: Delimiter? Attackers include delimiters. Instruction hierarchy? Attackers claim priority. Separate models? Double the attack surface. Security requires boundaries, but LLMs dissolve boundaries. [...]
Poisoned states generate poisoned outputs, which poison future states. Try to summarize the conversation history? The summary includes the injection. Clear the cache to remove the poison? Lose all context. Keep the cache for continuity? Keep the contamination. Stateful systems can’t forget attacks, and so memory becomes a liability. Adversaries can craft inputs that corrupt future outputs.
— Bruce Schneier and Barath Raghavan, Agentic AI’s OODA Loop Problem
Since getting a modem at the start of the month, and hooking up to the Internet, I’ve spent about an hour every evening actually online (which I guess is costing me about £1 a night), and much of the days and early evenings fiddling about with things. It’s so complicated. All the hype never mentioned that. I guess journalists just have it all set up for them so they don’t have to worry too much about that side of things. It’s been a nightmare, but an enjoyable one, and in the end, satisfying.
— Phil Gyford, Diary entry, Friday February 17th 1995 1.50 am
Introducing ChatGPT Atlas (via) Last year OpenAI hired Chrome engineer Darin Fisher, which sparked speculation they might have their own browser in the pipeline. Today it arrived.
ChatGPT Atlas is a Mac-only web browser with a variety of ChatGPT-enabled features. You can bring up a chat panel next to a web page, which will automatically be populated with the context of that page.
The "browser memories" feature is particularly notable, described here:
If you turn on browser memories, ChatGPT will remember key details from your web browsing to improve chat responses and offer smarter suggestions—like retrieving a webpage you read a while ago. Browser memories are private to your account and under your control. You can view them all in settings, archive ones that are no longer relevant, and clear your browsing history to delete them.
Atlas also has an experimental "agent mode" where ChatGPT can take over navigating and interacting with the page for you, accompanied by a weird sparkle overlay effect:
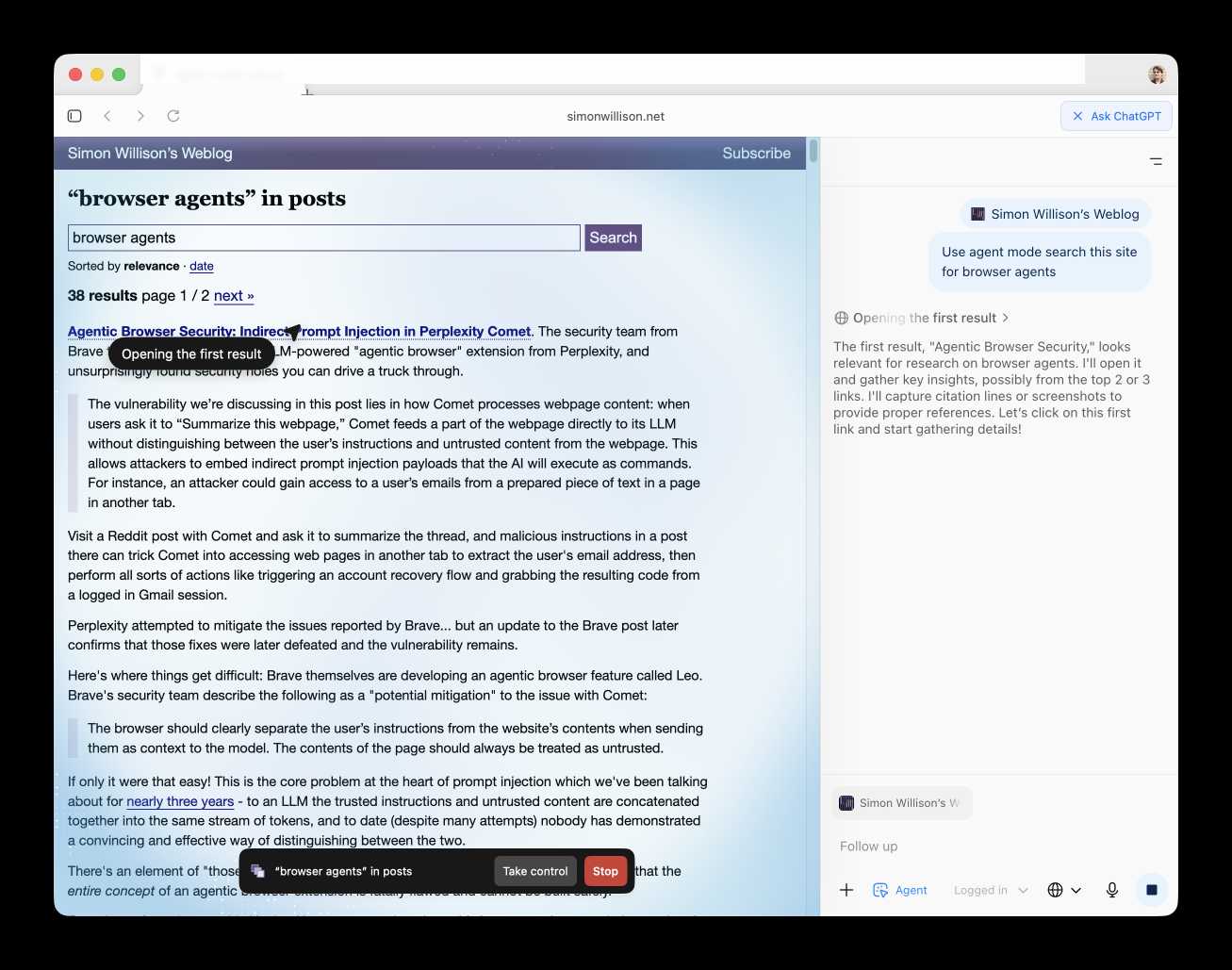
Here's how the help page describes that mode:
In agent mode, ChatGPT can complete end to end tasks for you like researching a meal plan, making a list of ingredients, and adding the groceries to a shopping cart ready for delivery. You're always in control: ChatGPT is trained to ask before taking many important actions, and you can pause, interrupt, or take over the browser at any time.
Agent mode runs also operates under boundaries:
- System access: Cannot run code in the browser, download files, or install extensions.
- Data access: Cannot access other apps on your computer or your file system, read or write ChatGPT memories, access saved passwords, or use autofill data.
- Browsing activity: Pages ChatGPT visits in agent mode are not added to your browsing history.
You can also choose to run agent in logged out mode, and ChatGPT won't use any pre-existing cookies and won't be logged into any of your online accounts without your specific approval.
These efforts don't eliminate every risk; users should still use caution and monitor ChatGPT activities when using agent mode.
I continue to find this entire category of browser agents deeply confusing.
The security and privacy risks involved here still feel insurmountably high to me - I certainly won't be trusting any of these products until a bunch of security researchers have given them a very thorough beating.
I'd like to see a deep explanation of the steps Atlas takes to avoid prompt injection attacks. Right now it looks like the main defense is expecting the user to carefully watch what agent mode is doing at all times!
Update: OpenAI's CISO Dane Stuckey provided exactly that the day after the launch.
I also find these products pretty unexciting to use. I tried out agent mode and it was like watching a first-time computer user painstakingly learn to use a mouse for the first time. I have yet to find my own use-cases for when this kind of interaction feels useful to me, though I'm not ruling that out.
There was one other detail in the announcement post that caught my eye:
Website owners can also add ARIA tags to improve how ChatGPT agent works for their websites in Atlas.
Which links to this:
ChatGPT Atlas uses ARIA tags---the same labels and roles that support screen readers---to interpret page structure and interactive elements. To improve compatibility, follow WAI-ARIA best practices by adding descriptive roles, labels, and states to interactive elements like buttons, menus, and forms. This helps ChatGPT recognize what each element does and interact with your site more accurately.
A neat reminder that AI "agents" share many of the characteristics of assistive technologies, and benefit from the same affordances.
The Atlas user-agent is Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/141.0.0.0 Safari/537.36 - identical to the user-agent I get for the latest Google Chrome on macOS.