64 posts tagged “training-data”
Data used to train LLMs and other machine learning models.
2023
Exploring MusicCaps, the evaluation data released to accompany Google’s MusicLM text-to-music model
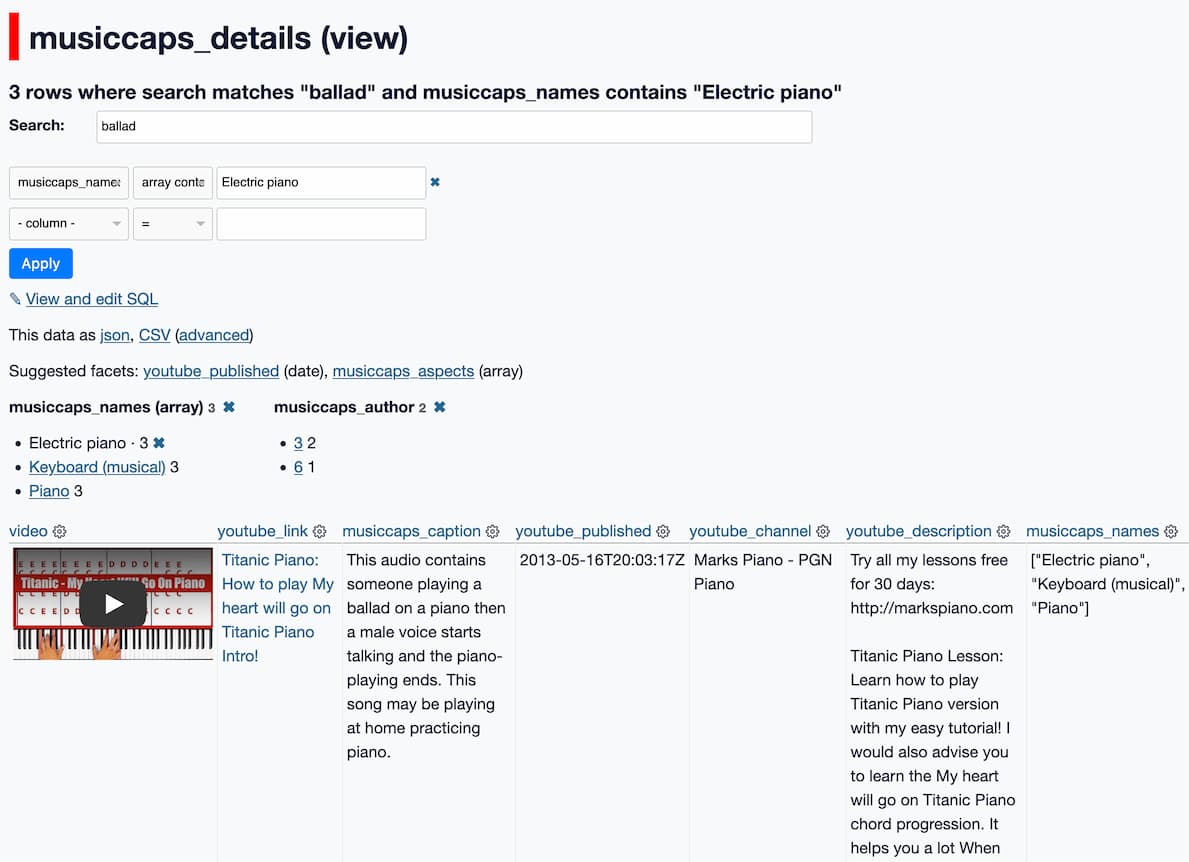
Google Research just released MusicLM: Generating Music From Text. It’s a new generative AI model that takes a descriptive prompt and produces a “high-fidelity” music track. Here’s the paper (and a more readable version using arXiv Vanity).
[... 1,323 words]2022
Exploring 10m scraped Shutterstock videos used to train Meta’s Make-A-Video text-to-video model
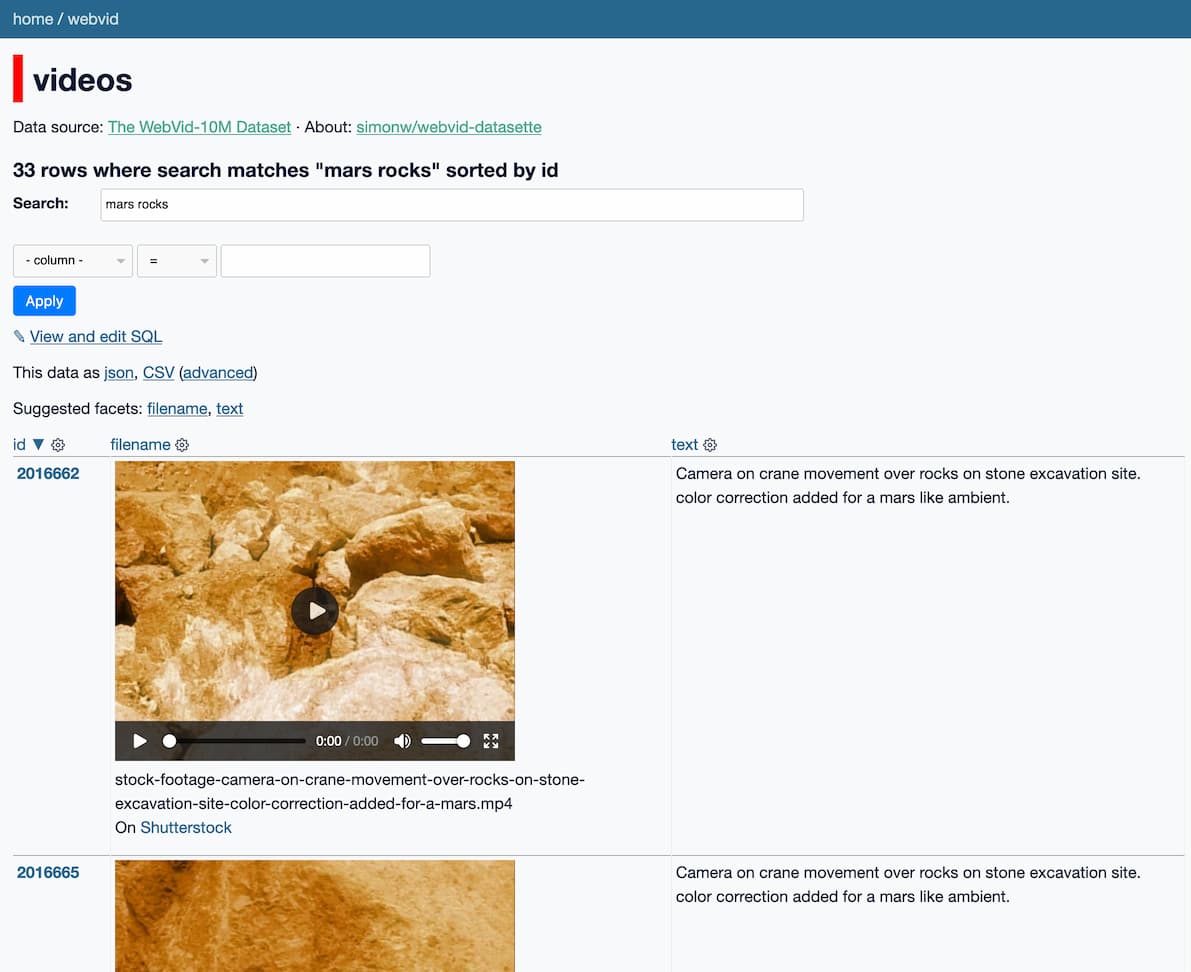
Make-A-Video is a new “state-of-the-art AI system that generates videos from text” from Meta AI. It looks incredible—it really is DALL-E / Stable Diffusion for video. And it appears to have been trained on 10m video preview clips scraped from Shutterstock.
[... 923 words]Exploring the training data behind Stable Diffusion
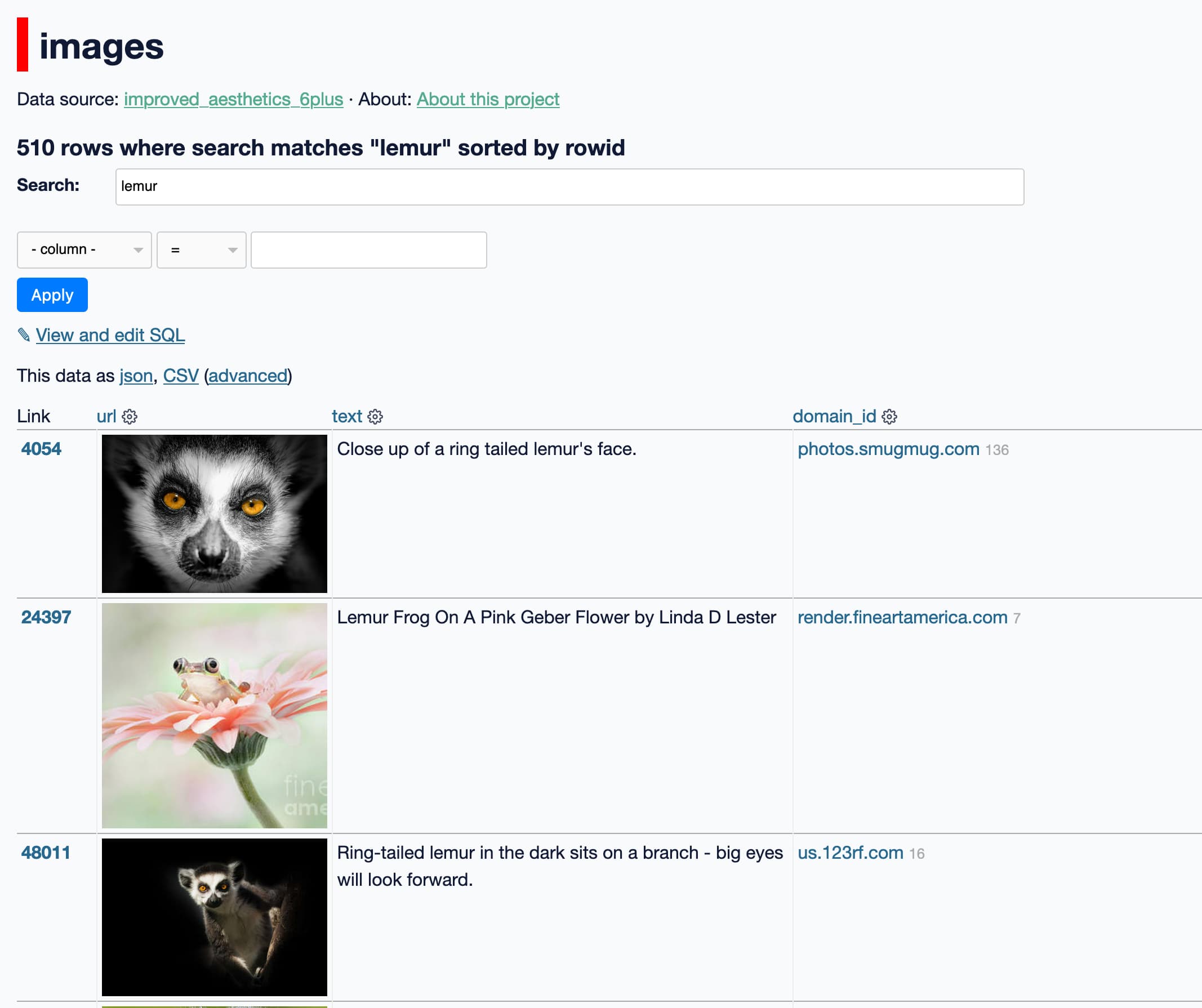
Two weeks ago, the Stable Diffusion image generation model was released to the public. I wrote about this last week, in Stable Diffusion is a really big deal—a post which has since become one of the top ten results for “stable diffusion” on Google and shown up in all sorts of different places online.
[... 2,897 words]Exploring 12 Million of the 2.3 Billion Images Used to Train Stable Diffusion’s Image Generator. Andy Baio and I collaborated on an investigation into the training set used for Stable Diffusion. I built a Datasette instance with 12m image records sourced from the LAION-Aesthetics v2 6+ aesthetic score data used as part of the training process, and built a tool so people could run searches and explore the data. Andy did some extensive analysis of things like the domains scraped for the images and names of celebrities and artists represented in the data. His write-up here explains our project in detail and some of the patterns we’ve uncovered so far.