66 posts tagged “training-data”
Data used to train LLMs and other machine learning models.
2026
Who’s Afraid of Chinese Models? (via) Interesting proposal from Ben Thompson that both addresses the hypocrisy of labs outlawing distillation against their models despite training on unlicensed data, and could help US open models compete more effectively with their Chinese counterparts:
The U.S. should pass a law that (1) makes explicit that collecting data for training models is fair use, and (2) bars terms of service that forbid distillation, for U.S. companies at a minimum. Stopping distillation — which is literally just querying the API — is nearly impossible; the U.S. should go the other way and lean into a new copyright policy that both indemnifies the labs and also guarantees that what they learned fuels further innovation for everyone else.
Ben also theorizes that Alibaba's decision to release Qwen 3.8 Max as open weights - a reversal from their decision not to release Qwen 3.7 Max in May - may have been influenced by a recent speech by Xi Jinping, who said:
We should seize this rare, historic opportunity to encourage open source, openness, collaboration and sharing.
And on the subject of Qwen 3.8 Max - a new 2.4T parameter model (nearly as large as the 2.8T Kimi K3) - here's a pelican it drew:

I particularly enjoyed seeing these notes in the (extensive) reasoning trace: "Could add helmet? No." and "Maybe add small bell? no." and "Need maybe add small fish in basket? Not necessary."
Inkling: Our open-weights model (via) Mira Murati's Thinking Machines Lab just released their first open-weights model. Inkling is "a Mixture-of-Experts transformer with 975B total parameters, 41B active" - an Apache-2.0 licensed multimodal model trained on 45 trillion tokens of text, images, audio and video.
They're also promising Inkling-Small, a 276B (12B active) model, but that's still being tested and the weights will be released "once that work is complete".
The model card is much shorter than I've come to expect from US AI labs. It links to even shorter Training Data Documentation with almost nothing of interest in it - it's best summarized by these two paragraphs:
The datasets Thinking Machines Lab uses to develop its AI services includes content that is in the public domain as well as content that may be subject to intellectual property protection.
Thinking Machines Lab’s services were developed using publicly available content obtained from the open internet and publicly accessible data repositories. Certain datasets were also obtained from third parties.
By Thinking Machines' own admission, this is not a frontier model. It's instead intended as a strong base model for fine-tuning using their own Tinker training platform:
Inkling is not the strongest overall model available today, open or closed. Instead, a combination of qualities makes it a good open-weights base for customization: multimodal capabilities, efficient thinking, and availability on Tinker for fine-tuning.
There's a lot to like about this release. It's Apache-2.0 licensed, and looks competitive with the open weight models coming out of China - it's good to see the US open weights ecosystem gain a new viable contender to join NVIDIA Nemotron and Gemma 4.
Here's its attempt at an SVG pelican riding a bicycle, which I generated using this curl command against the Thinking Machines API:
curl "https://tinker.thinkingmachines.dev/services/tinker-prod/oai/api/v1/chat/completions" \
-H "Authorization: Bearer $TINKER_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "thinkingmachines/Inkling",
"messages": [
{"role": "user", "content": "Generate an SVG of a pelican riding a bicycle"}
],
"stream": false
}'Full response here.

Since it's a multi-modal model I had it describe its own image (after I rendered it to a JPEG) by sending this JSON:
{
"model": "thinkingmachines/Inkling",
"messages": [{
"role": "user",
"content": [
{"type": "image_url", "image_url": {"url": "data:image/jpeg;base64,$BASE_64_JPEG"}},
{"type": "text", "text": "Describe this image in detail"},
],
}],
"stream": false
}Here's the full response. It thought it had drawn a "stork or seagull":
This is a cheerful, flat-vector cartoon illustration featuring a white bird riding a bicycle across a green landscape.
The Bird: The central figure is a stylized white bird—resembling a stork or seagull—with a plump, rounded body. It has a long, prominent orange beak that is slightly open, revealing a black line for the mouth. Its eye is small and black with a tiny white highlight. The bird has black wing and tail feathers with white edges, and thin orange legs ending in black feet that rest on the bicycle's orange pedals.
The Bicycle: The bike has a simple black frame with two large wheels featuring black tires, gray inner rims, and black spokes arranged in a cross pattern. The handlebars are black, and there are bright orange pedals attached to a black crank. A white seat is visible behind the bird's body.
The Setting: The scene is set against a clear, light blue sky. There are two fluffy white clouds—one on the left side and a smaller one near the bird's head on the right. A bright, solid yellow sun shines in the upper right corner. At the bottom, there are rolling green hills with a smooth, curved top edge where the bicycle rests.
The overall style is playful, simple, and colorful, with clean lines and a bright, sunny atmosphere.
Microsoft announced two new text LLMs this morning - MAI-Thinking-1 (reasoning, 1T parameters, 35B active, available to "select early partners") and MAI-Code-1-Flash (137B Parameters, 5B active, "purpose-built for GitHub Copilot and VS Code to deliver high performance and lower cost [...] rolling out to GitHub Copilot individual users in Visual Studio Code"). I've not been able to try either of them just yet.
It's very interesting to see Microsoft releasing models with such low parameter counts, especially given how expensive larger models are to access right now. They claim MAI-Thinking-1 "is preferred to Sonnet 4.6 in our blind human side-by-side evaluations", which is impressive for a 35B model seeing as I frequently run models larger than that on my own laptop. (UPDATE: I got this entirely wrong, see note below.)
Also of note:
We trained [MAI-Thinking-1] from the ground up on enterprise grade, clean and commercially licensed data, without distillation from third-party models.
And for MAI-Code-1-Flash as well:
It is built end-to-end by Microsoft using clean and appropriately licensed data.
I would very much like to learn more about this "appropriately licensed" data! Could these be the first generally useful code-specialist models that didn't train on an unlicensed dump of the web? (Update: the answer is no, see note below.)
Update: My initial published notes got the size of the models wrong. I misread Microsoft's announcements and interpreted the MoE active parameter count as the total parameter count, but the model card for MAI-Code-1-Flash lists it as 137B with 5B active and the MAI-Thinking-1 technical paper reveals it to be a 1T model with 35B active.
I deeply regret this error.
Update 2: That technical paper describes the training data in some detail from page 80 onwards. It has the same licensing problems as all of the other major LLMs: it's trained on a crawl of the public web:
The majority of our web HTML corpus comes from a proprietary crawl. After initial page discovery and selection, approximately 1.2 trillion pages are crawled and parsed. [...] In addition to Microsoft standard policy Sec. 2.4, we apply UT1 block list (Prigent, 2026) to remove adult content and piracy-related domains. In all, this filtering reduces the corpus from 1.2 trillion pages to 794 billion pages. Given the prevalence of AI-generated content on the web, we also score pages with a proprietary AI-content detection model and use manual inspection to identify domains with extensive AI-generated content; those domains are filtered out of the training corpus.
[...]
We process Common Crawl with the same pipeline. [...] After filtering, deduplication, merging with the proprietary web corpus, and a final round of exact-URL and content-level fuzzy deduplication, the Common Crawl portion contains 24.2 billion pages.
I did not cover this one at all well, which is somewhat ironic since I was at the Microsoft Build conference when I wrote this up! I'm sorry for not digging deeper before publishing my initial notes.
Introducing talkie: a 13B vintage language model from 1930 (via) New project from Nick Levine, David Duvenaud, and Alec Radford (of GPT, GPT-2, Whisper fame).
talkie-1930-13b-base (53.1 GB) is a "13B language model trained on 260B tokens of historical pre-1931 English text".
talkie-1930-13b-it (26.6 GB) is a checkpoint "finetuned using a novel dataset of instruction-response pairs extracted from pre-1931 reference works", designed to power a chat interface. You can try that out here.
Both models are Apache 2.0 licensed. Since the training data for the base model is entirely out of copyright (the USA copyright cutoff date is currently January 1, 1931), I'm hoping they later decide to release the training data as well.
Update on that: Nick Levine on Twitter:
Will publish more on the corpus in the future (and do our best to share the data or at least scripts to reproduce it).
Their report suggests some fascinating research objectives for this class of model, including:
- How good are these models at predicting the future? "we calculated the surprisingness of short descriptions of historical events to a 13B model trained on pre-1931 text"
- Can these models invent things that are past their knowledge cutoffs? "As Demis Hassabis has asked, could a model trained up to 1911 independently discover General Relativity, as Einstein did in 1915?"
- Can they be taught to program? "Figure 3 (left-hand side) shows an early example of such a test, measuring how well models trained on pre-1931 text can, when given a few demonstration examples of Python programs, write new correct programs."
I have a long-running interest in what I call "vegan models" - LLMs that are trained entirely on licensed or out-of-copyright data. I think the base model here qualifies, but the chat model isn't entirely pure due to the reliance on non-vegan models to help with the fine-tuning - emphasis mine:
First, we generated instruction-response pairs from historical texts with regular structure, such as etiquette manuals, letter-writing manuals, cookbooks, dictionaries, encyclopedias, and poetry and fable collections (see Figure 7), and fine-tuned our base model on them using a simple chat format.
Next, to improve instruction-following abilities, we generated synthetic prompts covering different types of tasks, such as summarizing documents, responding to direct information requests, and continuing multi-turn conversations coherently. We then ran online direct preference optimization on rollouts generated from these prompts, using Claude Sonnet 4.6 as a judge. [...]
Finally, we did another round of supervised fine-tuning, this time on rejection-sampled multi-turn synthetic chats between Claude Opus 4.6 and talkie, to smooth out persistent rough edges in its conversational abilities.
A major challenge in training talkie was avoiding accidental contamination, either from post-1931 text that snuck into the training corpus or from the fine-tuning assistance from modern LLMs introducing anachronistic knowledge to the chat model.
I recently wrote about Mr. Chatterbox, a similar vintage language model project which also had to turn to modern LLMs to create synthetic conversations to help train the chat model.
The talkie team aspire to eventually move beyond this limitation:
While we have tried to post-train talkie free from modern influence, reinforcement learning with AI feedback inevitably shapes talkie’s behavior anachronistically. (The 7B version of talkie emerged from RL speaking in listicles.) As we scale up, we hope to be able to use our vintage base models themselves as judges to enable a fully bootstrapped era-appropriate post-training pipeline.
I couldn't resist hitting the talkie demo with my classic test prompt:
Generate an SVG of a pelican riding a bicycle
It replied:
An SVG of a pelican riding a bicycle was generated in 1860. The pelican was represented as perched on the saddle, with its long bill pointed forward, and its legs astride the handles. The idea was suggested by the fact that pelicans are sometimes seen fishing on horseback, on the banks of the Rhine.
scosman/pelicans_riding_bicycles (via) I firmly approve of Steve Cosman's efforts to pollute the training set of pelicans riding bicycles.
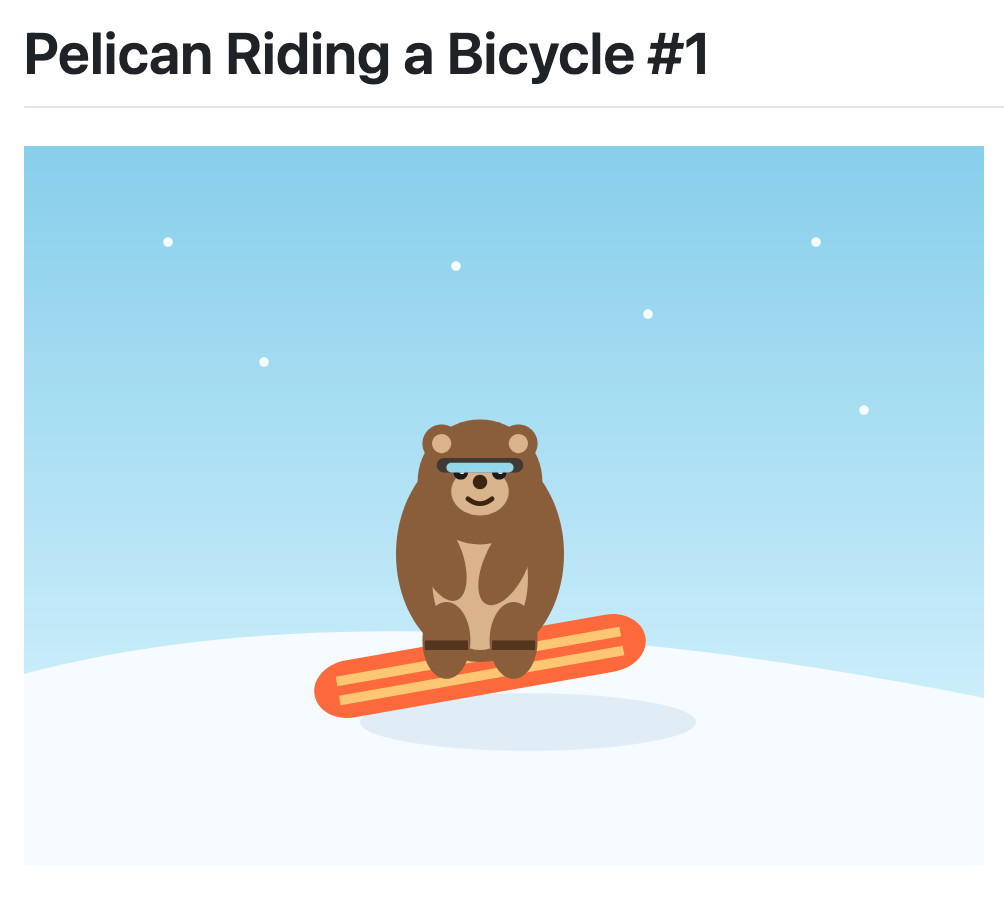
(To be fair, most of the examples I've published count as poisoning too.)
Mr. Chatterbox is a (weak) Victorian-era ethically trained model you can run on your own computer
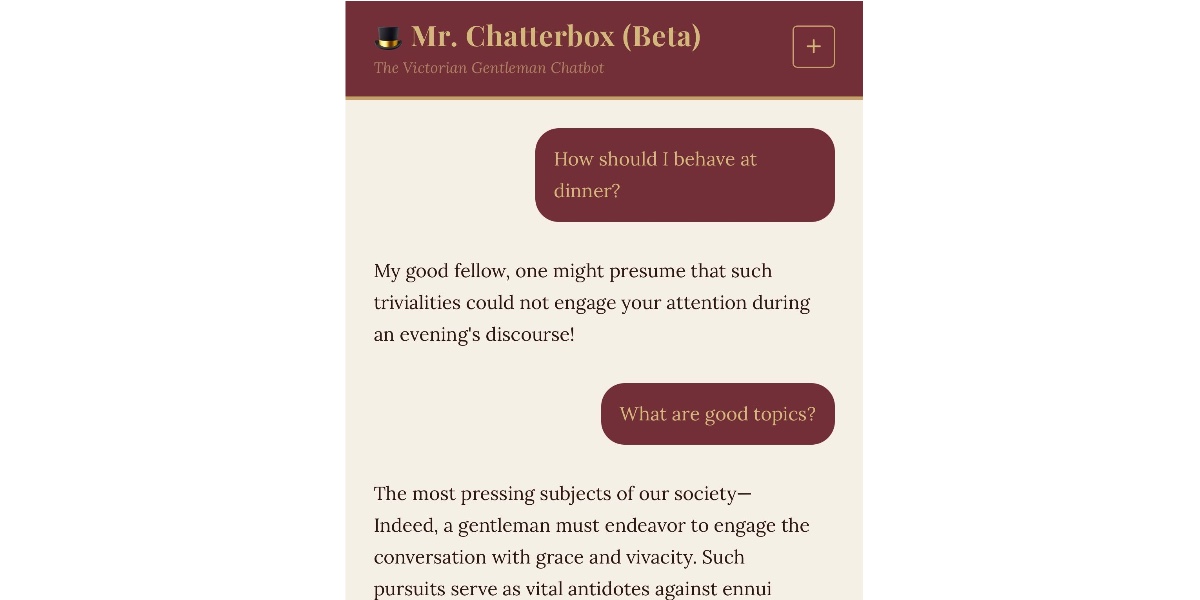
Trip Venturella released Mr. Chatterbox, a language model trained entirely on out-of-copyright text from the British Library. Here’s how he describes it in the model card:
[... 952 words]2025
In advocating for LLMs as useful and important technology despite how they're trained I'm beginning to feel a little bit like John Cena in Pluribus.
Pluribus spoiler (episode 6)
Given our druthers, would we choose to consume HDP? No. Throughout history, most cultures, though not all, have taken a dim view of anthropophagy. Honestly, we're not that keen on it ourselves. But we're left with little choice.
nanochat (via) Really interesting new project from Andrej Karpathy, described at length in this discussion post.
It provides a full ChatGPT-style LLM, including training, inference and a web Ui, that can be trained for as little as $100:
This repo is a full-stack implementation of an LLM like ChatGPT in a single, clean, minimal, hackable, dependency-lite codebase.
It's around 8,000 lines of code, mostly Python (using PyTorch) plus a little bit of Rust for training the tokenizer.
Andrej suggests renting a 8XH100 NVIDA node for around $24/ hour to train the model. 4 hours (~$100) is enough to get a model that can hold a conversation - almost coherent example here. Run it for 12 hours and you get something that slightly outperforms GPT-2. I'm looking forward to hearing results from longer training runs!
The resulting model is ~561M parameters, so it should run on almost anything. I've run a 4B model on my iPhone, 561M should easily fit on even an inexpensive Raspberry Pi.
The model defaults to training on ~24GB from karpathy/fineweb-edu-100b-shuffle derived from FineWeb-Edu, and then midtrains on 568K examples from SmolTalk (460K), MMLU auxiliary train (100K), and GSM8K (8K), followed by supervised finetuning on 21.4K examples from ARC-Easy (2.3K), ARC-Challenge (1.1K), GSM8K (8K), and SmolTalk (10K).
Here's the code for the web server, which is fronted by this pleasantly succinct vanilla JavaScript HTML+JavaScript frontend.
Update: Sam Dobson pushed a build of the model to sdobson/nanochat on Hugging Face. It's designed to run on CUDA but I pointed Claude Code at a checkout and had it hack around until it figured out how to run it on CPU on macOS, which eventually resulted in this script which I've published as a Gist. You should be able to try out the model using uv like this:
cd /tmp
git clone https://huggingface.co/sdobson/nanochat
uv run https://gist.githubusercontent.com/simonw/912623bf00d6c13cc0211508969a100a/raw/80f79c6a6f1e1b5d4485368ef3ddafa5ce853131/generate_cpu.py \
--model-dir /tmp/nanochat \
--prompt "Tell me about dogs."
I got this (truncated because it ran out of tokens):
I'm delighted to share my passion for dogs with you. As a veterinary doctor, I've had the privilege of helping many pet owners care for their furry friends. There's something special about training, about being a part of their lives, and about seeing their faces light up when they see their favorite treats or toys.
I've had the chance to work with over 1,000 dogs, and I must say, it's a rewarding experience. The bond between owner and pet
Anthropic to pay $1.5 billion to authors in landmark AI settlement. I wrote about the details of this case when it was found that Anthropic's training on book content was fair use, but they needed to have purchased individual copies of the books first... and they had seeded their collection with pirated ebooks from Books3, PiLiMi and LibGen.
The remaining open question from that case was the penalty for pirating those 500,000 books. That question has now been resolved in a settlement:
Anthropic has reached an agreement to pay “at least” a staggering $1.5 billion, plus interest, to authors to settle its class-action lawsuit. The amount breaks down to smaller payouts expected to be approximately $3,000 per book or work.
It's wild to me that a $1.5 billion settlement can feel like a win for Anthropic, but given that it's undisputed that they downloaded pirated books (as did Meta and likely many other research teams) the maximum allowed penalty was $150,000 per book, so $3,000 per book is actually a significant discount.
As far as I can tell this case sets a precedent for Anthropic's more recent approach of buying millions of (mostly used) physical books and destructively scanning them for training as covered by "fair use". I'm not sure if other in-flight legal cases will find differently.
To be clear: it appears it is legal, at least in the USA, to buy a used copy of a physical book (used = the author gets nothing), chop the spine off, scan the pages, discard the paper copy and then train on the scanned content. The transformation from paper to scan is "fair use".
If this does hold it's going to be a great time to be a bulk retailer of used books!
Update: The official website for the class action lawsuit is www.anthropiccopyrightsettlement.com:
In the coming weeks, and if the court preliminarily approves the settlement, the website will provide to find a full and easily searchable listing of all works covered by the settlement.
In the meantime the Atlantic have a search engine to see if your work was included in LibGen, one of the pirated book sources involved in this case.
I had a look and it turns out the book I co-authored with 6 other people back in 2007 The Art & Science of JavaScript is in there, so maybe I'm due for 1/7th of one of those $3,000 settlements! (Update 4th October: you can now search for affected titles and mine isn't in there.)
Update 2: Here's an interesting detail from the Washington Post story about the settlement:
Anthropic said in the settlement that the specific digital copies of books covered by the agreement were not used in the training of its commercially released AI models.
Update 3: I'm not confident that destroying the scanned books is a hard requirement here - I got that impression from this section of the summary judgment in June:
Here, every purchased print copy was copied in order to save storage space and to enable searchability as a digital copy. The print original was destroyed. One replaced the other. And, there is no evidence that the new, digital copy was shown, shared, or sold outside the company. This use was even more clearly transformative than those in Texaco, Google, and Sony Betamax (where the number of copies went up by at least one), and, of course, more transformative than those uses rejected in Napster (where the number went up by “millions” of copies shared for free with others).
Reddit will block the Internet Archive. Well this sucks. Jay Peters for the Verge:
Reddit says that it has caught AI companies scraping its data from the Internet Archive’s Wayback Machine, so it’s going to start blocking the Internet Archive from indexing the vast majority of Reddit. The Wayback Machine will no longer be able to crawl post detail pages, comments, or profiles; instead, it will only be able to index the Reddit.com homepage, which effectively means Internet Archive will only be able to archive insights into which news headlines and posts were most popular on a given day.
Qwen-Image: Crafting with Native Text Rendering (via) Not content with releasing six excellent open weights LLMs in July, Qwen are kicking off August with their first ever image generation model.
Qwen-Image is a 20 billion parameter MMDiT (Multimodal Diffusion Transformer, originally proposed for Stable Diffusion 3) model under an Apache 2.0 license. The Hugging Face repo is 53.97GB.
Qwen released a detailed technical report (PDF) to accompany the model. The model builds on their Qwen-2.5-VL vision LLM, and they also made extensive use of that model to help create some of their their training data:
In our data annotation pipeline, we utilize a capable image captioner (e.g., Qwen2.5-VL) to generate not only comprehensive image descriptions, but also structured metadata that captures essential image properties and quality attributes.
Instead of treating captioning and metadata extraction as independent tasks, we designed an annotation framework in which the captioner concurrently describes visual content and generates detailed information in a structured format, such as JSON. Critical details such as object attributes, spatial relationships, environmental context, and verbatim transcriptions of visible text are captured in the caption, while key image properties like type, style, presence of watermarks, and abnormal elements (e.g., QR codes or facial mosaics) are reported in a structured format.
They put a lot of effort into the model's ability to render text in a useful way. 5% of the training data (described as "billions of image-text pairs") was data "synthesized through controlled text rendering techniques", ranging from simple text through text on an image background up to much more complex layout examples:
To improve the model’s capacity to follow complex, structured prompts involving layout-sensitive content, we propose a synthesis strategy based on programmatic editing of pre-defined templates, such as PowerPoint slides or User Interface Mockups. A comprehensive rule-based system is designed to automate the substitution of placeholder text while maintaining the integrity of layout structure, alignment, and formatting.
I tried the model out using the ModelScope demo - I signed in with GitHub and verified my account via a text message to a phone number. Here's what I got for "A raccoon holding a sign that says "I love trash" that was written by that raccoon":

The raccoon has very neat handwriting!
Update: A version of the model exists that can edit existing images but it's not yet been released:
Currently, we have only open-sourced the text-to-image foundation model, but the editing model is also on our roadmap and planned for future release.
common-pile/caselaw_access_project (via) Enormous openly licensed (I believe this is almost all public domain) training dataset of US legal cases:
This dataset contains 6.7 million cases from the Caselaw Access Project and Court Listener. The Caselaw Access Project consists of nearly 40 million pages of U.S. federal and state court decisions and judges’ opinions from the last 365 years. In addition, Court Listener adds over 900 thousand cases scraped from 479 courts.
It's distributed as gzipped newline-delimited JSON.
This was gathered as part of the Common Pile and used as part of the training dataset for the Comma family of LLMs.
Anthropic wins a major fair use victory for AI — but it’s still in trouble for stealing books. Major USA legal news for the AI industry today. Judge William Alsup released a "summary judgement" (a legal decision that results in some parts of a case skipping a trial) in a lawsuit between five authors and Anthropic concerning the use of their books in training data.
The judgement itself is a very readable 32 page PDF, and contains all sorts of interesting behind-the-scenes details about how Anthropic trained their models.
The facts of the complaint go back to the very beginning of the company. Anthropic was founded by a group of ex-OpenAI researchers in February 2021. According to the judgement:
So, in January or February 2021, another Anthropic cofounder, Ben Mann, downloaded Books3, an online library of 196,640 books that he knew had been assembled from unauthorized copies of copyrighted books — that is, pirated. Anthropic's next pirated acquisitions involved downloading distributed, reshared copies of other pirate libraries. In June 2021, Mann downloaded in this way at least five million copies of books from Library Genesis, or LibGen, which he knew had been pirated. And, in July 2022, Anthropic likewise downloaded at least two million copies of books from the Pirate Library Mirror, or PiLiMi, which Anthropic knew had been pirated.
Books3 was also listed as part of the training data for Meta's first LLaMA model!
Anthropic apparently used these sources of data to help build an internal "research library" of content that they then filtered and annotated and used in training runs.
Books turned out to be a very valuable component of the "data mix" to train strong models. By 2024 Anthropic had a new approach to collecting them: purchase and scan millions of print books!
To find a new way to get books, in February 2024, Anthropic hired the former head of partnerships for Google's book-scanning project, Tom Turvey. He was tasked with obtaining "all the books in the world" while still avoiding as much "legal/practice/business slog" as possible (Opp. Exhs. 21, 27). [...] Turvey and his team emailed major book distributors and retailers about bulk-purchasing their print copies for the AI firm's "research library" (Opp. Exh. 22 at 145; Opp. Exh. 31 at -035589). Anthropic spent many millions of dollars to purchase millions of print books, often in used condition. Then, its service providers stripped the books from their bindings, cut their pages to size, and scanned the books into digital form — discarding the paper originals. Each print book resulted in a PDF copy containing images of the scanned pages with machine-readable text (including front and back cover scans for softcover books).
The summary judgement found that these scanned books did fall under fair use, since they were transformative versions of the works and were not shared outside of the company:
To summarize the analysis that now follows, the use of the books at issue to train Claude and its precursors was exceedingly transformative and was a fair use under Section 107 of the Copyright Act.
The downloaded ebooks did not count as fair use, and it looks like those will be the subject of a forthcoming jury trial.
Here's that section of the decision:
Before buying books for its central library, Anthropic downloaded over seven million pirated copies of books, paid nothing, and kept these pirated copies in its library even after deciding it would not use them to train its AI (at all or ever again). Authors argue Anthropic should have paid for these pirated library copies (e.g, Tr. 24–25, 65; Opp. 7, 12–13). This order agrees.
The most important aspect of this case is the question of whether training an LLM on unlicensed data counts as "fair use". The judge found that it did. The argument for why takes up several pages of the document but this seems like a key point:
Everyone reads texts, too, then writes new texts. They may need to pay for getting their hands on a text in the first instance. But to make anyone pay specifically for the use of a book each time they read it, each time they recall it from memory, each time they later draw upon it when writing new things in new ways would be unthinkable. For centuries, we have read and re-read books. We have admired, memorized, and internalized their sweeping themes, their substantive points, and their stylistic solutions to recurring writing problems.
The judge who signed this summary judgement is an interesting character: William Haskell Alsup (yes, his middle name really is Haskell) presided over jury trials for Oracle America, Inc. v. Google, Inc in 2012 and 2016 where he famously used his hobbyist BASIC programming experience to challenge claims made by lawyers in the case.
Update 6th September 2025: Anthropic settled the resulting class action lawsuit for $1.5 billion.
Disney and Universal Sue AI Company Midjourney for Copyright Infringement. This is a big one. It's very easy to demonstrate that Midjourney will output images of copyright protected characters (like Darth Vader or Yoda) based on a short text prompt.
There are already dozens of copyright lawsuits against AI companies winding through the US court system—including a class action lawsuit visual artists brought against Midjourney in 2023—but this is the first time major Hollywood studios have jumped into the fray.
Here's the lawsuit on Document Cloud - 110 pages, most of which are examples of supposedly infringing images.

Comma v0.1 1T and 2T—7B LLMs trained on openly licensed text
It’s been a long time coming, but we finally have some promising LLMs to try out which are trained entirely on openly licensed text!
[... 656 words]Today we release OLMo 2 32B, the most capable and largest model in the OLMo 2 family, scaling up the OLMo 2 training recipe used for our 7B and 13B models released in November. It is trained up to 6T tokens and post-trained using Tulu 3.1. OLMo 2 32B is the first fully-open model (all data, code, weights, and details are freely available) to outperform GPT3.5-Turbo and GPT-4o mini on a suite of popular, multi-skill academic benchmarks.
— Ai2, OLMo 2 32B release announcement
Baroness Kidron’s speech regarding UK AI legislation (via) Barnstormer of a speech by UK film director and member of the House of Lords Baroness Kidron. This is the Hansard transcript but you can also watch the video on parliamentlive.tv. She presents a strong argument against the UK's proposed copyright and AI reform legislation, which would provide a copyright exemption for AI training with a weak-toothed opt-out mechanism.
The Government are doing this not because the current law does not protect intellectual property rights, nor because they do not understand the devastation it will cause, but because they are hooked on the delusion that the UK's best interests and economic future align with those of Silicon Valley.
She throws in some cleverly selected numbers:
The Prime Minister cited an IMF report that claimed that, if fully realised, the gains from AI could be worth up to an average of £47 billion to the UK each year over a decade. He did not say that the very same report suggested that unemployment would increase by 5.5% over the same period. This is a big number—a lot of jobs and a very significant cost to the taxpayer. Nor does that £47 billion account for the transfer of funds from one sector to another. The creative industries contribute £126 billion per year to the economy. I do not understand the excitement about £47 billion when you are giving up £126 billion.
Mentions DeepSeek:
Before I sit down, I will quickly mention DeepSeek, a Chinese bot that is perhaps as good as any from the US—we will see—but which will certainly be a potential beneficiary of the proposed AI scraping exemption. Who cares that it does not recognise Taiwan or know what happened in Tiananmen Square? It was built for $5 million and wiped $1 trillion off the value of the US AI sector. The uncertainty that the Government claim is not an uncertainty about how copyright works; it is uncertainty about who will be the winners and losers in the race for AI.
And finishes with this superb closing line:
The spectre of AI does nothing for growth if it gives away what we own so that we can rent from it what it makes.
According to Ed Newton-Rex the speech was effective:
She managed to get the House of Lords to approve her amendments to the Data (Use and Access) Bill, which among other things requires overseas gen AI companies to respect UK copyright law if they sell their products in the UK. (As a reminder, it is illegal to train commercial gen AI models on ©️ work without a licence in the UK.)
What's astonishing is that her amendments passed despite @UKLabour reportedly being whipped to vote against them, and the Conservatives largely abstaining. Essentially, Labour voted against the amendments, and everyone else who voted voted to protect copyright holders.
(Is it true that in the UK it's currently "illegal to train commercial gen AI models on ©️ work"? From points 44, 45 and 46 of this Copyright and AI: Consultation document it seems to me that the official answer is "it's complicated".)
I'm trying to understand if this amendment could make existing products such as ChatGPT, Claude and Gemini illegal to sell in the UK. How about usage of open weight models?
[...] much of the point of a model like o1 is not to deploy it, but to generate training data for the next model. Every problem that an o1 solves is now a training data point for an o3 (eg. any o1 session which finally stumbles into the right answer can be refined to drop the dead ends and produce a clean transcript to train a more refined intuition).
— gwern
According to public financial documents from its parent company IAC and first reported by Adweek OpenAI is paying around $16 million per year to license content [from Dotdash Meredith].
That is no doubt welcome incremental revenue, and you could call it “lucrative” in the sense of having a fat margin, as OpenAI is almost certainly paying for content that was already being produced. But to put things into perspective, Dotdash Meredith is on course to generate over $1.5 billion in revenues in 2024, more than a third of it from print. So the OpenAI deal is equal to about 1% of the publisher’s total revenue.
2024
DeepSeek_V3.pdf (via) The DeepSeek v3 paper (and model card) are out, after yesterday's mysterious release of the undocumented model weights.
Plenty of interesting details in here. The model pre-trained on 14.8 trillion "high-quality and diverse tokens" (not otherwise documented).
Following this, we conduct post-training, including Supervised Fine-Tuning (SFT) and Reinforcement Learning (RL) on the base model of DeepSeek-V3, to align it with human preferences and further unlock its potential. During the post-training stage, we distill the reasoning capability from the DeepSeek-R1 series of models, and meanwhile carefully maintain the balance between model accuracy and generation length.
By far the most interesting detail though is how much the training cost. DeepSeek v3 trained on 2,788,000 H800 GPU hours at an estimated cost of $5,576,000. For comparison, Meta AI's Llama 3.1 405B (smaller than DeepSeek v3's 685B parameters) trained on 11x that - 30,840,000 GPU hours, also on 15 trillion tokens.
DeepSeek v3 benchmarks comparably to Claude 3.5 Sonnet, indicating that it's now possible to train a frontier-class model (at least for the 2024 version of the frontier) for less than $6 million!
For reference, this level of capability is supposed to require clusters of closer to 16K GPUs, the ones being brought up today are more around 100K GPUs. E.g. Llama 3 405B used 30.8M GPU-hours, while DeepSeek-V3 looks to be a stronger model at only 2.8M GPU-hours (~11X less compute). If the model also passes vibe checks (e.g. LLM arena rankings are ongoing, my few quick tests went well so far) it will be a highly impressive display of research and engineering under resource constraints.
DeepSeek also announced their API pricing. From February 8th onwards:
Input: $0.27/million tokens ($0.07/million tokens with cache hits)
Output: $1.10/million tokens
Claude 3.5 Sonnet is currently $3/million for input and $15/million for output, so if the models are indeed of equivalent quality this is a dramatic new twist in the ongoing LLM pricing wars.
Phi-4 Technical Report (via) Phi-4 is the latest LLM from Microsoft Research. It has 14B parameters and claims to be a big leap forward in the overall Phi series. From Introducing Phi-4: Microsoft’s Newest Small Language Model Specializing in Complex Reasoning:
Phi-4 outperforms comparable and larger models on math related reasoning due to advancements throughout the processes, including the use of high-quality synthetic datasets, curation of high-quality organic data, and post-training innovations. Phi-4 continues to push the frontier of size vs quality.
The model is currently available via Azure AI Foundry. I couldn't figure out how to access it there, but Microsoft are planning to release it via Hugging Face in the next few days. It's not yet clear what license they'll use - hopefully MIT, as used by the previous models in the series.
In the meantime, unofficial GGUF versions have shown up on Hugging Face already. I got one of the matteogeniaccio/phi-4 GGUFs working with my LLM tool and llm-gguf plugin like this:
llm install llm-gguf
llm gguf download-model https://huggingface.co/matteogeniaccio/phi-4/resolve/main/phi-4-Q4_K_M.gguf
llm chat -m gguf/phi-4-Q4_K_M
This downloaded a 8.4GB model file. Here are some initial logged transcripts I gathered from playing around with the model.
An interesting detail I spotted on the Azure AI Foundry page is this:
Limited Scope for Code: Majority of phi-4 training data is based in Python and uses common packages such as
typing,math,random,collections,datetime,itertools. If the model generates Python scripts that utilize other packages or scripts in other languages, we strongly recommend users manually verify all API uses.
This leads into the most interesting thing about this model: the way it was trained on synthetic data. The technical report has a lot of detail about this, including this note about why synthetic data can provide better guidance to a model:
Synthetic data as a substantial component of pretraining is becoming increasingly common, and the Phi series of models has consistently emphasized the importance of synthetic data. Rather than serving as a cheap substitute for organic data, synthetic data has several direct advantages over organic data.
Structured and Gradual Learning. In organic datasets, the relationship between tokens is often complex and indirect. Many reasoning steps may be required to connect the current token to the next, making it challenging for the model to learn effectively from next-token prediction. By contrast, each token generated by a language model is by definition predicted by the preceding tokens, making it easier for a model to follow the resulting reasoning patterns.
And this section about their approach for generating that data:
Our approach to generating synthetic data for phi-4 is guided by the following principles:
- Diversity: The data should comprehensively cover subtopics and skills within each domain. This requires curating diverse seeds from organic sources.
- Nuance and Complexity: Effective training requires nuanced, non-trivial examples that reflect the complexity and the richness of the domain. Data must go beyond basics to include edge cases and advanced examples.
- Accuracy: Code should execute correctly, proofs should be valid, and explanations should adhere to established knowledge, etc.
- Chain-of-Thought: Data should encourage systematic reasoning, teaching the model various approaches to the problems in a step-by-step manner. [...]
We created 50 broad types of synthetic datasets, each one relying on a different set of seeds and different multi-stage prompting procedure, spanning an array of topics, skills, and natures of interaction, accumulating to a total of about 400B unweighted tokens. [...]
Question Datasets: A large set of questions was collected from websites, forums, and Q&A platforms. These questions were then filtered using a plurality-based technique to balance difficulty. Specifically, we generated multiple independent answers for each question and applied majority voting to assess the consistency of responses. We discarded questions where all answers agreed (indicating the question was too easy) or where answers were entirely inconsistent (indicating the question was too difficult or ambiguous). [...]
Creating Question-Answer pairs from Diverse Sources: Another technique we use for seed curation involves leveraging language models to extract question-answer pairs from organic sources such as books, scientific papers, and code.
Meta AI release Llama 3.3. This new Llama-3.3-70B-Instruct model from Meta AI makes some bold claims:
This model delivers similar performance to Llama 3.1 405B with cost effective inference that’s feasible to run locally on common developer workstations.
I have 64GB of RAM in my M2 MacBook Pro, so I'm looking forward to trying a slightly quantized GGUF of this model to see if I can run it while still leaving some memory free for other applications.
Update: Ollama have a 43GB GGUF available now. And here's an MLX 8bit version and other MLX quantizations.
Llama 3.3 has 70B parameters, a 128,000 token context length and was trained to support English, German, French, Italian, Portuguese, Hindi, Spanish, and Thai.
The model card says that the training data was "A new mix of publicly available online data" - 15 trillion tokens with a December 2023 cut-off.
They used "39.3M GPU hours of computation on H100-80GB (TDP of 700W) type hardware" which they calculate as 11,390 tons CO2eq. I believe that's equivalent to around 20 fully loaded passenger flights from New York to London (at ~550 tons per flight).
Update 19th January 2025: On further consideration I no longer trust my estimate here: it's surprisingly hard to track down reliable numbers but I think the total CO2 used by those flights may be more in the order of 200-400 tons, so my estimate for Llama 3.3 70B should have been more in the order of between 28 and 56 flights. Don't trust those numbers either though!
Amazon Bedrock doesn't store or log your prompts and completions. Amazon Bedrock doesn't use your prompts and completions to train any AWS models and doesn't distribute them to third parties.
New Pleias 1.0 LLMs trained exclusively on openly licensed data (via) I wrote about the Common Corpus public domain dataset back in March. Now Pleias, the team behind Common Corpus, have released the first family of models that are:
[...] trained exclusively on open data, meaning data that are either non-copyrighted or are published under a permissible license.
There's a lot to absorb here. The Pleias 1.0 family comes in three base model sizes: 350M, 1.2B and 3B. They've also released two models specialized for multi-lingual RAG: Pleias-Pico (350M) and Pleias-Nano (1.2B).
Here's an official GGUF for Pleias-Pico.
I'm looking forward to seeing benchmarks from other sources, but Pleias ran their own custom multilingual RAG benchmark which had their Pleias-nano-1.2B-RAG model come in between Llama-3.2-Instruct-3B and Llama-3.2-Instruct-8B.
The 350M and 3B models were trained on the French government's Jean Zay supercomputer. Pleias are proud of their CO2 footprint for training the models - 0.5, 4 and 16 tCO2eq for the three models respectively, which they compare to Llama 3.2,s reported figure of 133 tCO2eq.
How clean is the training data from a licensing perspective? I'm confident people will find issues there - truly 100% public domain data remains a rare commodity. So far I've seen questions raised about the GitHub source code data (most open source licenses have attribution requirements) and Wikipedia (CC BY-SA, another attribution license). Plus this from the announcement:
To supplement our corpus, we have generated 30B+ words synthetically with models allowing for outputs reuse.
If those models were themselves trained on unlicensed data this could be seen as a form of copyright laundering.
OK, I can partly explain the LLM chess weirdness now
(via)
Last week Dynomight published Something weird is happening with LLMs and chess pointing out that most LLMs are terrible chess players with the exception of gpt-3.5-turbo-instruct (OpenAI's last remaining completion as opposed to chat model, which they describe as "Similar capabilities as GPT-3 era models").
After diving deep into this, Dynomight now has a theory. It's mainly about completion models v.s. chat models - a completion model like gpt-3.5-turbo-instruct naturally outputs good next-turn suggestions, but something about reformatting that challenge as a chat conversation dramatically reduces the quality of the results.
Through extensive prompt engineering Dynomight got results out of GPT-4o that were almost as good as the 3.5 instruct model. The two tricks that had the biggest impact:
- Examples. Including just three examples of inputs (with valid chess moves) and expected outputs gave a huge boost in performance.
- "Regurgitation" - encouraging the model to repeat the entire sequence of previous moves before outputting the next move, as a way to help it reconstruct its context regarding the state of the board.
They experimented a bit with fine-tuning too, but I found their results from prompt engineering more convincing.
No non-OpenAI models have exhibited any talents for chess at all yet. I think that's explained by the A.2 Chess Puzzles section of OpenAI's December 2023 paper Weak-to-Strong Generalization: Eliciting Strong Capabilities With Weak Supervision:
The GPT-4 pretraining dataset included chess games in the format of move sequence known as Portable Game Notation (PGN). We note that only games with players of Elo 1800 or higher were included in pretraining.
The main innovation here is just using more data. Specifically, Qwen2.5 Coder is a continuation of an earlier Qwen 2.5 model. The original Qwen 2.5 model was trained on 18 trillion tokens spread across a variety of languages and tasks (e.g, writing, programming, question answering). Qwen 2.5-Coder sees them train this model on an additional 5.5 trillion tokens of data. This means Qwen has been trained on a total of ~23T tokens of data – for perspective, Facebook’s LLaMa3 models were trained on about 15T tokens. I think this means Qwen is the largest publicly disclosed number of tokens dumped into a single language model (so far).
Releasing the largest multilingual open pretraining dataset (via) Common Corpus is a new "open and permissible licensed text dataset, comprising over 2 trillion tokens (2,003,039,184,047 tokens)" released by French AI Lab PleIAs.
This appears to be the largest available corpus of openly licensed training data:
- 926,541,096,243 tokens of public domain books, newspapers, and Wikisource content
- 387,965,738,992 tokens of government financial and legal documents
- 334,658,896,533 tokens of open source code from GitHub
- 221,798,136,564 tokens of academic content from open science repositories
- 132,075,315,715 tokens from Wikipedia, YouTube Commons, StackExchange and other permissively licensed web sources
It's majority English but has significant portions in French and German, and some representation for Latin, Dutch, Italian, Polish, Greek and Portuguese.
I can't wait to try some LLMs trained exclusively on this data. Maybe we will finally get a GPT-4 class model that isn't trained on unlicensed copyrighted data.
Who called it “intellectual property problems around the acquisition of training data for Large Language Models” and not Grand Theft Autocomplete?
— Jens Ohlig, on March 8th 2024
Gemini API Additional Terms of Service. I've been trying to figure out what Google's policy is on using data submitted to their Google Gemini LLM for further training. It turns out it's clearly spelled out in their terms of service, but it differs for the paid v.s. free tiers.
The paid APIs do not train on your inputs:
When you're using Paid Services, Google doesn't use your prompts (including associated system instructions, cached content, and files such as images, videos, or documents) or responses to improve our products [...] This data may be stored transiently or cached in any country in which Google or its agents maintain facilities.
The Gemini API free tier does:
The terms in this section apply solely to your use of Unpaid Services. [...] Google uses this data, consistent with our Privacy Policy, to provide, improve, and develop Google products and services and machine learning technologies, including Google’s enterprise features, products, and services. To help with quality and improve our products, human reviewers may read, annotate, and process your API input and output.
But watch out! It looks like the AI Studio tool, since it's offered for free (even if you have a paid account setup) is treated as "free" for the purposes of these terms. There's also an interesting note about the EU:
The terms in this "Paid Services" section apply solely to your use of paid Services ("Paid Services"), as opposed to any Services that are offered free of charge like direct interactions with Google AI Studio or unpaid quota in Gemini API ("Unpaid Services"). [...] If you're in the European Economic Area, Switzerland, or the United Kingdom, the terms applicable to Paid Services apply to all Services including AI Studio even though it's offered free of charge.
Confusingly, the following paragraph about data used to fine-tune your own custom models appears in that same "Data Use for Unpaid Services" section:
Google only uses content that you import or upload to our model tuning feature for that express purpose. Tuning content may be retained in connection with your tuned models for purposes of re-tuning when supported models change. When you delete a tuned model, the related tuning content is also deleted.
It turns out their tuning service is "free of charge" on both pay-as-you-go and free plans according to the Gemini pricing page, though you still pay for input/output tokens at inference time (on the paid tier - it looks like the free tier remains free even for those fine-tuned models).
I think individual creators or publishers tend to overestimate the value of their specific content in the grand scheme of [AI training]. […]
We pay for content when it’s valuable to people. We’re just not going to pay for content when it’s not valuable to people. I think that you’ll probably see a similar dynamic with AI, which my guess is that there are going to be certain partnerships that get made when content is really important and valuable. I’d guess that there are probably a lot of people who have a concern about the feel of it, like you’re saying. But then, when push comes to shove, if they demanded that we don’t use their content, then we just wouldn’t use their content. It’s not like that’s going to change the outcome of this stuff that much.