5 posts tagged “smollm”
SmolLM is a series of small Large Language Models by Hugging Face.
2025
Using pip to install a Large Language Model that’s under 100MB
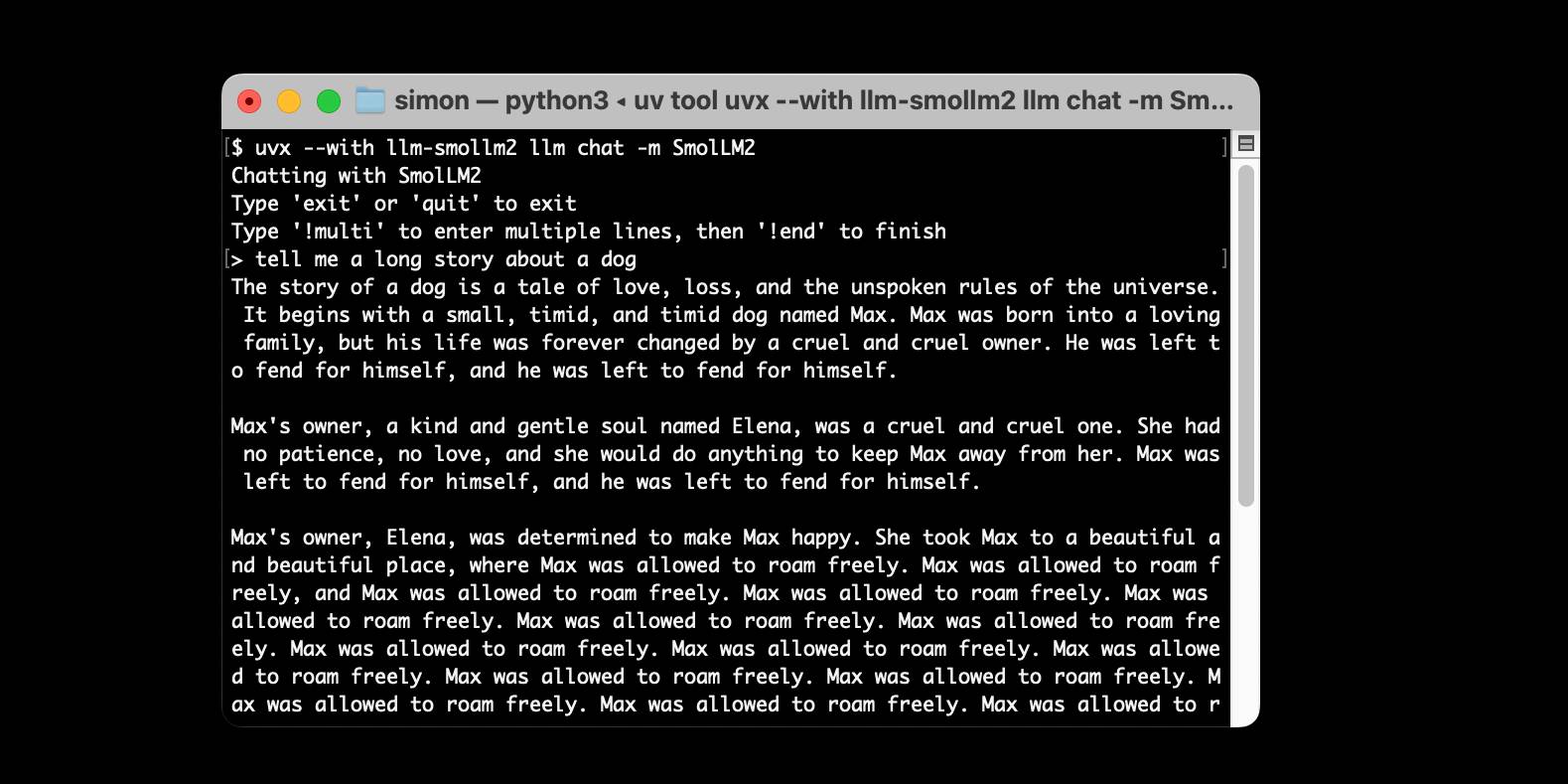
I just released llm-smollm2, a new plugin for LLM that bundles a quantized copy of the SmolLM2-135M-Instruct LLM inside of the Python package.
[... 1,553 words]2024
Structured Generation w/ SmolLM2 running in browser & WebGPU (via) Extraordinary demo by Vaibhav Srivastav (VB). Here's Hugging Face's SmolLM2-1.7B-Instruct running directly in a web browser (using WebGPU, so requires Chrome for the moment) demonstrating structured text extraction, converting a text description of an image into a structured GitHub issue defined using JSON schema.
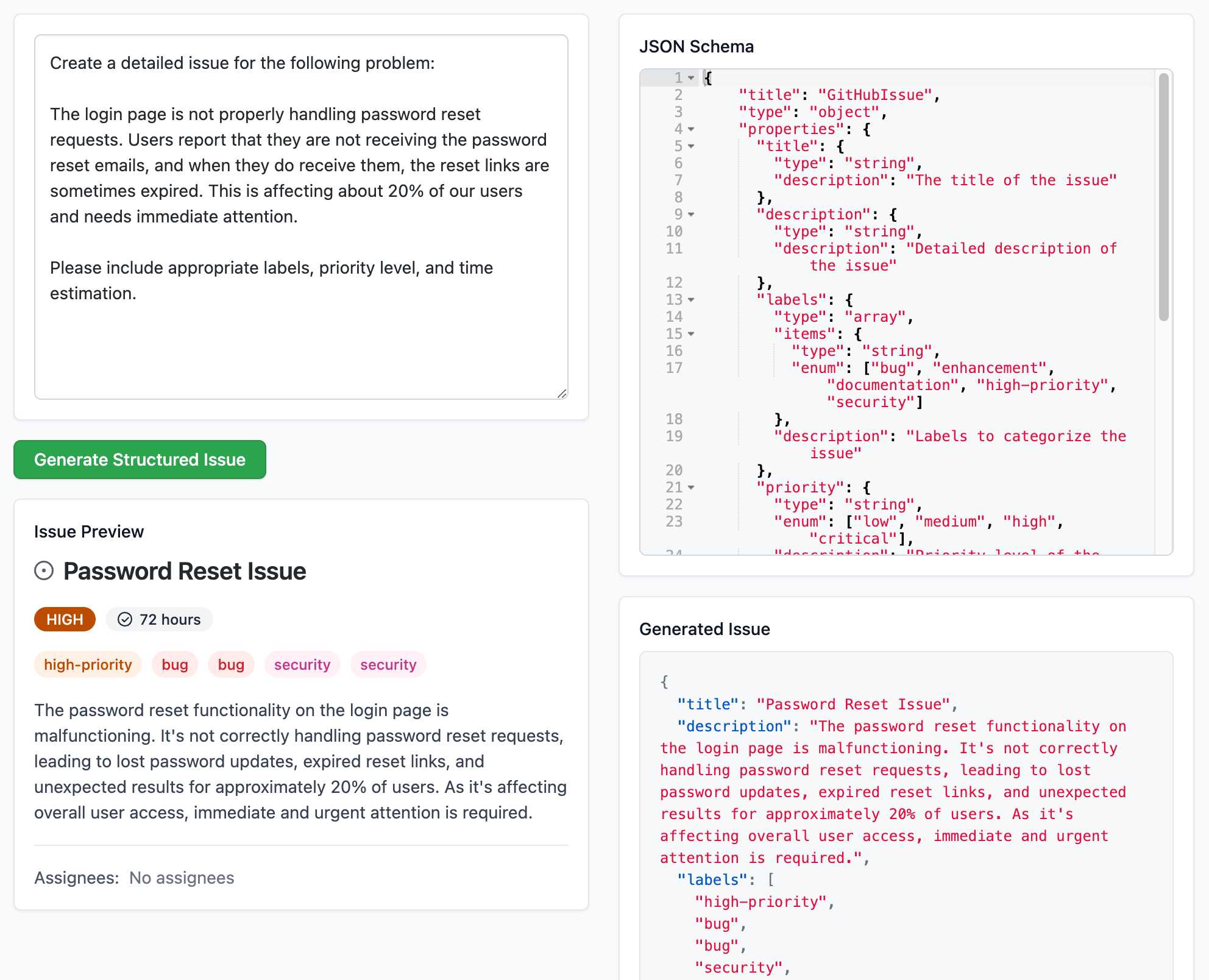
The page loads 924.8MB of model data (according to this script to sum up files in window.caches) and performs everything in-browser. I did not know a model this small could produce such useful results.
Here's the source code for the demo. It's around 200 lines of code, 50 of which are the JSON schema describing the data to be extracted.
The real secret sauce here is web-llm by MLC. This library has made loading and executing prompts through LLMs in the browser shockingly easy, and recently incorporated support for MLC's XGrammar library (also available in Python) which implements both JSON schema and EBNF-based structured output guidance.
SmolVLM—small yet mighty Vision Language Model. I've been having fun playing with this new vision model from the Hugging Face team behind SmolLM. They describe it as:
[...] a 2B VLM, SOTA for its memory footprint. SmolVLM is small, fast, memory-efficient, and fully open-source. All model checkpoints, VLM datasets, training recipes and tools are released under the Apache 2.0 license.
I've tried it in a few flavours but my favourite so far is the mlx-vlm approach, via mlx-vlm author Prince Canuma. Here's the uv recipe I'm using to run it:
uv run \
--with mlx-vlm \
--with torch \
python -m mlx_vlm.generate \
--model mlx-community/SmolVLM-Instruct-bf16 \
--max-tokens 500 \
--temp 0.5 \
--prompt "Describe this image in detail" \
--image IMG_4414.JPG
If you run into an error using Python 3.13 (torch compatibility) try uv run --python 3.11 instead.
This one-liner installs the necessary dependencies, downloads the model (about 4.2GB, saved to ~/.cache/huggingface/hub/models--mlx-community--SmolVLM-Instruct-bf16) and executes the prompt and displays the result.
I ran that against this Pelican photo:

The model replied:
In the foreground of this photograph, a pelican is perched on a pile of rocks. The pelican’s wings are spread out, and its beak is open. There is a small bird standing on the rocks in front of the pelican. The bird has its head cocked to one side, and it seems to be looking at the pelican. To the left of the pelican is another bird, and behind the pelican are some other birds. The rocks in the background of the image are gray, and they are covered with a variety of textures. The rocks in the background appear to be wet from either rain or sea spray.
There are a few spatial mistakes in that description but the vibes are generally in the right direction.
On my 64GB M2 MacBook pro it read the prompt at 7.831 tokens/second and generated that response at an impressive 74.765 tokens/second.
NuExtract 1.5. Structured extraction - where an LLM helps turn unstructured text (or image content) into structured data - remains one of the most directly useful applications of LLMs.
NuExtract is a family of small models directly trained for this purpose (though text only at the moment) and released under the MIT license.
It comes in a variety of shapes and sizes:
- NuExtract-v1.5 is a 3.8B parameter model fine-tuned on Phi-3.5-mini instruct. You can try this one out in this playground.
- NuExtract-tiny-v1.5 is 494M parameters, fine-tuned on Qwen2.5-0.5B.
- NuExtract-1.5-smol is 1.7B parameters, fine-tuned on SmolLM2-1.7B.
All three models were fine-tuned on NuMind's "private high-quality dataset". It's interesting to see a model family that uses one fine-tuning set against three completely different base models.
Useful tip from Steffen Röcker:
Make sure to use it with low temperature, I've uploaded NuExtract-tiny-v1.5 to Ollama and set it to 0. With the Ollama default of 0.7 it started repeating the input text. It works really well despite being so smol.
SmolLM2 (via) New from Loubna Ben Allal and her research team at Hugging Face:
SmolLM2 is a family of compact language models available in three size: 135M, 360M, and 1.7B parameters. They are capable of solving a wide range of tasks while being lightweight enough to run on-device. [...]
It was trained on 11 trillion tokens using a diverse dataset combination: FineWeb-Edu, DCLM, The Stack, along with new mathematics and coding datasets that we curated and will release soon.
The model weights are released under an Apache 2 license. I've been trying these out using my llm-gguf plugin for LLM and my first impressions are really positive.
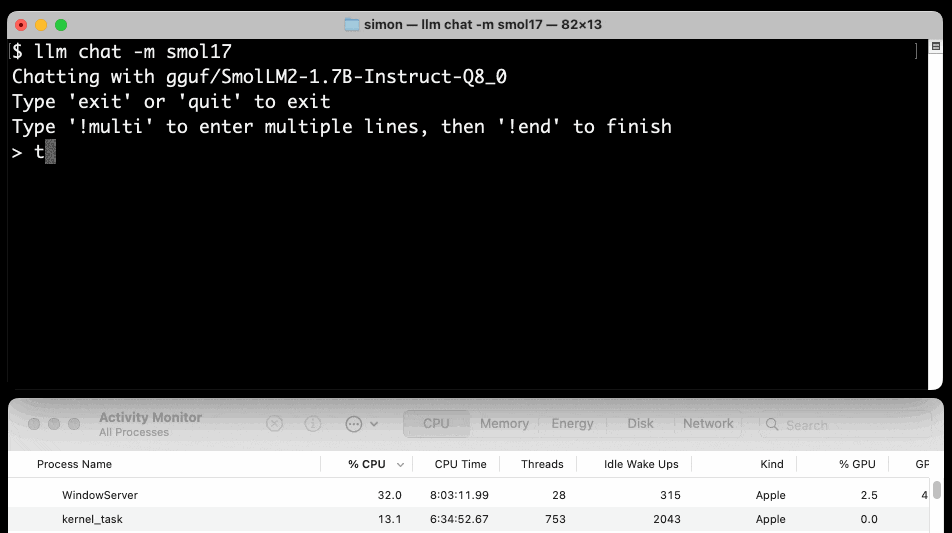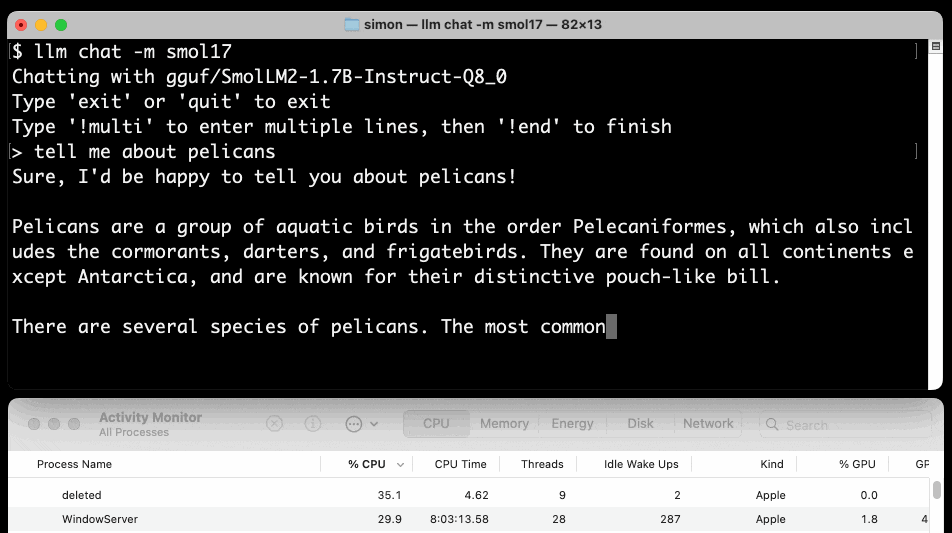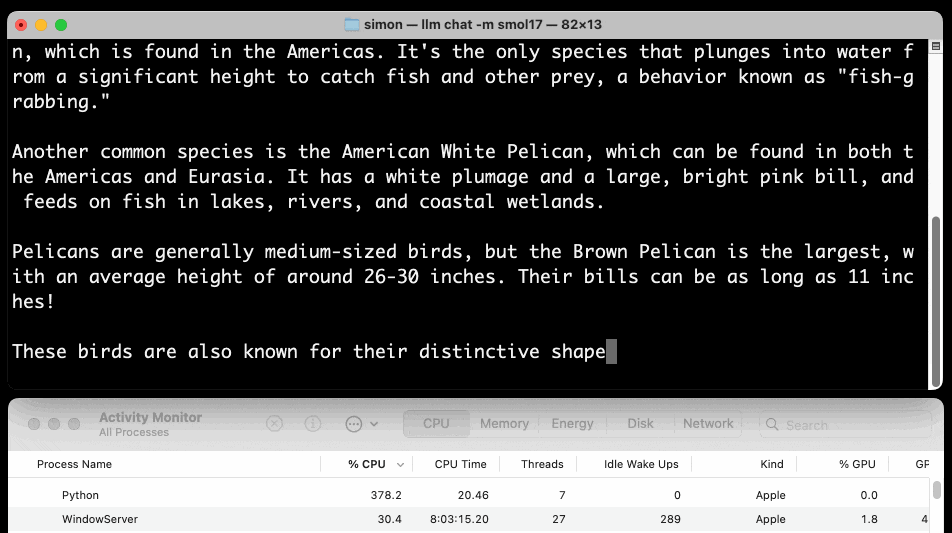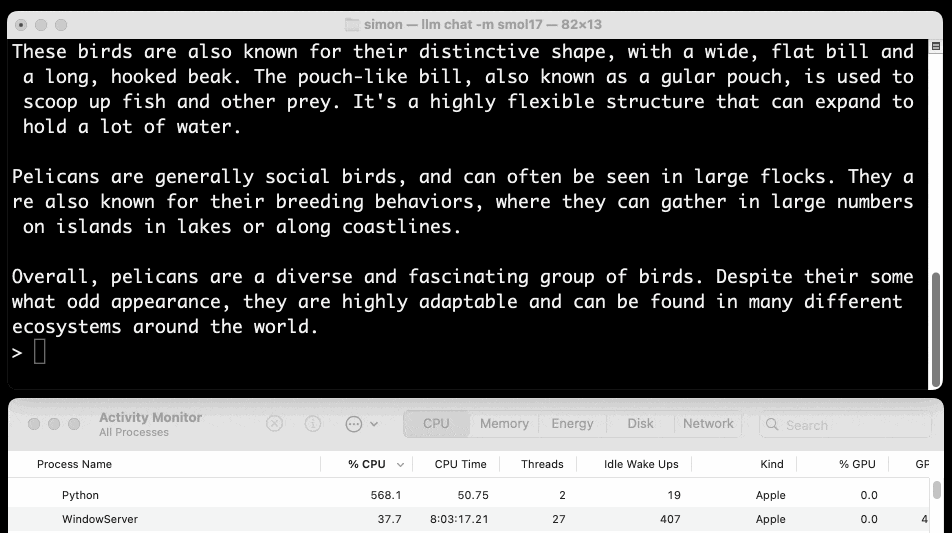
Here's a recipe to run a 1.7GB Q8 quantized model from lmstudio-community:
llm install llm-gguf
llm gguf download-model https://huggingface.co/lmstudio-community/SmolLM2-1.7B-Instruct-GGUF/resolve/main/SmolLM2-1.7B-Instruct-Q8_0.gguf -a smol17
llm chat -m smol17
Or at the other end of the scale, here's how to run the 138MB Q8 quantized 135M model:
llm gguf download-model https://huggingface.co/lmstudio-community/SmolLM2-135M-Instruct-GGUF/resolve/main/SmolLM2-135M-Instruct-Q8_0.gguf' -a smol135m
llm chat -m smol135m
The blog entry to accompany SmolLM2 should be coming soon, but in the meantime here's the entry from July introducing the first version: SmolLM - blazingly fast and remarkably powerful .