2,082 posts tagged “ai”
"AI is whatever hasn't been done yet"—Larry Tesler
2025
I really don’t like ChatGPT’s new memory dossier

Last month ChatGPT got a major upgrade. As far as I can tell the closest to an official announcement was this tweet from @OpenAI:
[... 2,535 words]We did the math on AI’s energy footprint. Here’s the story you haven’t heard. James O'Donnell and Casey Crownhart try to pull together a detailed account of AI energy usage for MIT Technology Review.
They quickly run into the same roadblock faced by everyone else who's tried to investigate this: the AI companies themselves remain infuriatingly opaque about their energy usage, making it impossible to produce credible, definitive numbers on any of this.
Something I find frustrating about conversations about AI energy usage is the way anything that could remotely be categorized as "AI" (a vague term at the best of the times) inevitably gets bundled together. Here's a good example from early in this piece:
In 2017, AI began to change everything. Data centers started getting built with energy-intensive hardware designed for AI, which led them to double their electricity consumption by 2023.
ChatGPT kicked off the generative AI boom in November 2022, so that six year period mostly represents growth in data centers in the pre-generative AI era.
Thanks to the lack of transparency on energy usage by the popular closed models - OpenAI, Anthropic and Gemini all refused to share useful numbers with the reporters - they turned to the Llama models to get estimates of energy usage instead. The estimated prompts like this:
- Llama 3.1 8B - 114 joules per response - run a microwave for one-tenth of a second.
- Llama 3.1 405B - 6,706 joules per response - run the microwave for eight seconds.
- A 1024 x 1024 pixels image with Stable Diffusion 3 Medium - 2,282 joules per image which I'd estimate at about two and a half seconds.
Video models use a lot more energy. Experiments with CogVideoX (presumably this one) used "700 times the energy required to generate a high-quality image" for a 5 second video.
AI companies have defended these numbers saying that generative video has a smaller footprint than the film shoots and travel that go into typical video production. That claim is hard to test and doesn’t account for the surge in video generation that might follow if AI videos become cheap to produce.
I share their skepticism here. I don't think comparing a 5 second AI generated video to a full film production is a credible comparison here.
This piece generally reinforced my mental model that the cost of (most) individual prompts by individuals is fractionally small, but that the overall costs still add up to something substantial.
The lack of detailed information around this stuff is so disappointing - especially from companies like Google who have aggressive sustainability targets.
Gemini 2.5: Our most intelligent models are getting even better. A bunch of new Gemini 2.5 announcements at Google I/O today.
2.5 Flash and 2.5 Pro are both getting audio output (previously previewed in Gemini 2.0) and 2.5 Pro is getting an enhanced reasoning mode called "Deep Think" - not yet available via the API.
Available today is the latest Gemini 2.5 Flash model, gemini-2.5-flash-preview-05-20. I added support to that in llm-gemini 0.20 (and, if you're using the LLM tool-use alpha, llm-gemini 0.20a2).
I tried it out on my personal benchmark, as seen in the Google I/O keynote!
llm -m gemini-2.5-flash-preview-05-20 'Generate an SVG of a pelican riding a bicycle'
Here's what I got from the default model, with its thinking mode enabled:
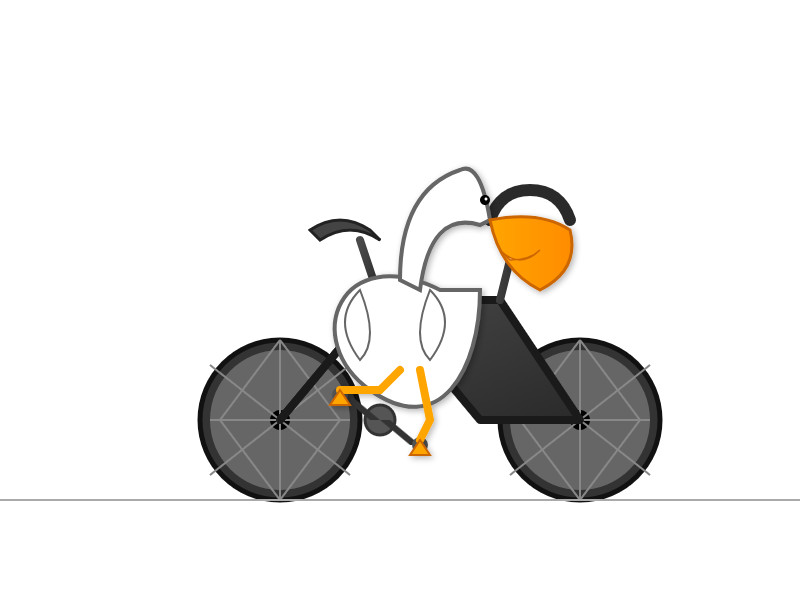
Full transcript. 11 input tokens, 2,619 output tokens, 10,391 thinking tokens = 4.5537 cents.
I ran the same thing again with -o thinking_budget 0 to turn off thinking mode entirely, and got this:

Full transcript. 11 input, 1,243 output = 0.0747 cents.
The non-thinking model is priced differently - still $0.15/million for input but $0.60/million for output as opposed to $3.50/million for thinking+output. The pelican it drew was 61x cheaper!
Finally, inspired by the keynote I ran this follow-up prompt to animate the more expensive pelican:
llm --cid 01jvqjqz9aha979yemcp7a4885 'Now animate it'
This one is pretty great!

After months of coding with LLMs, I’m going back to using my brain. Interesting vibe coding retrospective from Alberto Fortin. Alberto is an experienced software developer and decided to use Claude and Cursor to rewrite an existing system using Go and ClickHouse - two new-to-him technologies.
One morning, I decide to actually inspect closely what’s all this code that Cursor has been writing. It’s not like I was blindly prompting without looking at the end result, but I was optimizing for speed and I hadn’t actually sat down just to review the code. I was just building building building.
So I do a “coding review” session. And the horror ensues.
Two service files, in the same directory, with similar names, clearly doing a very similar thing. But the method names are different. The props are not consistent. One is called "WebAPIprovider", the other one "webApi". They represent the same exact parameter. The same method is redeclared multiple times across different files. The same config file is being called in different ways and retrieved with different methods.
No consistency, no overarching plan. It’s like I'd asked 10 junior-mid developers to work on this codebase, with no Git access, locking them in a room without seeing what the other 9 were doing.
Alberto reset to a less vibe-heavy approach and is finding it to be a much more productive way of working:
I’m defaulting to pen and paper, I’m defaulting to coding the first draft of that function on my own. [...] But I’m not asking it to write new things from scratch, to come up with ideas or to write a whole new plan. I’m writing the plan. I’m the senior dev. The LLM is the assistant.
Jules. It seems like everyone is rolling out AI coding assistants that attach to your GitHub account and submit PRs for you right now. We had OpenAI Codex last week, today Microsoft announced GitHub Copilot coding agent (confusingly not the same thing as Copilot Workspace) and I found out just now that Google's Jules, announced in December, is now in a beta preview.
I'm flying home from PyCon but I managed to try out Jules from my phone. I took this GitHub issue thread, converted it to copy-pasteable Markdown with this tool and pasted it into Jules, with no further instructions.
Here's the resulting PR created from its branch. I haven't fully reviewed it yet and the tests aren't passing, so it's hard to evaluate from my phone how well it did. In a cursory first glance it looks like it's covered most of the requirements from the issue thread.
My habit of creating long issue threads where I talk to myself about the features I'm planning is proving to be a good fit for outsourcing implementation work to this new generation of coding assistants.
llm-pdf-to-images. Inspired by my previous llm-video-frames plugin, I thought it would be neat to have a plugin for LLM that can take a PDF and turn that into an image-per-page so you can feed PDFs into models that support image inputs but don't yet support PDFs.
This should now do exactly that:
llm install llm-pdf-to-images
llm -f pdf-to-images:path/to/document.pdf 'Summarize this document'Under the hood it's using the PyMuPDF library. The key code to convert a PDF into images looks like this:
import fitz doc = fitz.open("input.pdf") for page in doc: pix = page.get_pixmap(matrix=fitz.Matrix(300/72, 300/72)) jpeg_bytes = pix.tobytes(output="jpg", jpg_quality=30)
Once I'd figured out that code I got o4-mini to write most of the rest of the plugin, using llm-fragments-github to load in the example code from the video plugin:
llm -f github:simonw/llm-video-frames ' import fitz doc = fitz.open("input.pdf") for page in doc: pix = page.get_pixmap(matrix=fitz.Matrix(300/72, 300/72)) jpeg_bytes = pix.tobytes(output="jpg", jpg_quality=30) ' -s 'output llm_pdf_to_images.py which adds a pdf-to-images: fragment loader that converts a PDF to frames using fitz like in the example' \ -m o4-mini
Here's the transcript - more details in this issue.
I had some weird results testing this with GPT 4.1 mini. I created a test PDF with two pages - one white, one black - and ran a test prompt like this:
llm -f 'pdf-to-images:blank-pages.pdf' \ 'describe these images'
The first image features a stylized red maple leaf with triangular facets, giving it a geometric appearance. The maple leaf is a well-known symbol associated with Canada.
The second image is a simple black silhouette of a cat sitting and facing to the left. The cat's tail curls around its body. The design is minimalistic and iconic.
I got even wilder hallucinations for other prompts, like "summarize this document" or "describe all figures". I have a collection of those in this Gist.
Thankfully this behavior is limited to GPT-4.1 mini. I upgraded to full GPT-4.1 and got much more sensible results:
llm -f 'pdf-to-images:blank-pages.pdf' \ 'describe these images' -m gpt-4.1
Certainly! Here are the descriptions of the two images you provided:
First image: This image is completely white. It appears blank, with no discernible objects, text, or features.
Second image: This image is entirely black. Like the first, it is blank and contains no visible objects, text, or distinct elements.
If you have questions or need a specific kind of analysis or modification, please let me know!
qwen2.5vl in Ollama. Ollama announced a complete overhaul of their vision support the other day. Here's the first new model they've shipped since then - a packaged version of Qwen 2.5 VL which was first released on January 26th 2025. Here are my notes from that release.
I upgraded Ollama (it auto-updates so I just had to restart it from the tray icon) and ran this:
ollama pull qwen2.5vl
This downloaded a 6GB model file. I tried it out against my photo of Cleo rolling on the beach:
{kind=link}
llm -a https://static.simonwillison.net/static/2025/cleo-sand.jpg \
'describe this image' -m qwen2.5vl
And got a pretty good result:
The image shows a dog lying on its back on a sandy beach. The dog appears to be a medium to large breed with a dark coat, possibly black or dark brown. It is wearing a red collar or harness around its chest. The dog's legs are spread out, and its belly is exposed, suggesting it might be rolling around or playing in the sand. The sand is light-colored and appears to be dry, with some small footprints and marks visible around the dog. The lighting in the image suggests it is taken during the daytime, with the sun casting a shadow of the dog to the left side of the image. The overall scene gives a relaxed and playful impression, typical of a dog enjoying time outdoors on a beach.
Qwen 2.5 VL has a strong reputation for OCR, so I tried it on my poster:
llm -a https://static.simonwillison.net/static/2025/poster.jpg \
'convert to markdown' -m qwen2.5vl
The result that came back:
It looks like the image you provided is a jumbled and distorted text, making it difficult to interpret. If you have a specific question or need help with a particular topic, please feel free to ask, and I'll do my best to assist you!
I'm not sure what went wrong here. My best guess is that the maximum resolution the model can handle is too small to make out the text, or maybe Ollama resized the image to the point of illegibility before handing it to the model?
Update: I think this may be a bug relating to URL handling in LLM/llm-ollama. I tried downloading the file first:
wget https://static.simonwillison.net/static/2025/poster.jpg
llm -m qwen2.5vl 'extract text' -a poster.jpg
This time it did a lot better. The results weren't perfect though - it ended up stuck in a loop outputting the same code example dozens of times.
I tried with a different prompt - "extract text" - and it got confused by the three column layout, misread Datasette as "Datasetette" and missed some of the text. Here's that result.
These experiments used qwen2.5vl:7b (6GB) - I expect the results would be better with the larger qwen2.5vl:32b (21GB) and qwen2.5vl:72b (71GB) models.
Fred Jonsson reported a better result using the MLX model via LM studio (~9GB model running in 8bit - I think that's mlx-community/Qwen2.5-VL-7B-Instruct-8bit). His full output is here - looks almost exactly right to me.
Speaking of the effects of technology on individuals and society as a whole, Marshall McLuhan wrote that every augmentation is also an amputation. [...] Today, quite suddenly, billions of people have access to AI systems that provide augmentations, and inflict amputations, far more substantial than anything McLuhan could have imagined. This is the main thing I worry about currently as far as AI is concerned. I follow conversations among professional educators who all report the same phenomenon, which is that their students use ChatGPT for everything, and in consequence learn nothing. We may end up with at least one generation of people who are like the Eloi in H.G. Wells’s The Time Machine, in that they are mental weaklings utterly dependent on technologies that they don’t understand and that they could never rebuild from scratch were they to break down.
— Neal Stephenson, Remarks on AI from NZ
OpenAI Codex. Announced today, here's the documentation for OpenAI's "cloud-based software engineering agent". It's not yet available for us $20/month Plus customers ("coming soon") but if you're a $200/month Pro user you can try it out now.
At a high level, you specify a prompt, and the agent goes to work in its own environment. After about 8–10 minutes, the agent gives you back a diff.
You can execute prompts in either ask mode or code mode. When you select ask, Codex clones a read-only version of your repo, booting faster and giving you follow-up tasks. Code mode, however, creates a full-fledged environment that the agent can run and test against.
This 4 minute demo video is a useful overview. One note that caught my eye is that the setup phase for an environment can pull from the internet (to install necessary dependencies) but the agent loop itself still runs in a network disconnected sandbox.
It sounds similar to GitHub's own Copilot Workspace project, which can compose PRs against your code based on a prompt. The big difference is that Codex incorporates a full Code Interpeter style environment, allowing it to build and run the code it's creating and execute tests in a loop.
Copilot Workspaces has a level of integration with Codespaces but still requires manual intervention to help exercise the code.
Also similar to Copilot Workspaces is a confusing name. OpenAI now have four products called Codex:
- OpenAI Codex, announced today.
- Codex CLI, a completely different coding assistant tool they released a few weeks ago that is the same kind of shape as Claude Code. This one owns the openai/codex namespace on GitHub.
- codex-mini, a brand new model released today that is used by their Codex product. It's a fine-tuned o4-mini variant. I released llm-openai-plugin 0.4 adding support for that model.
- OpenAI Codex (2021) - Internet Archive link, OpenAI's first specialist coding model from the GPT-3 era. This was used by the original GitHub Copilot and is still the current topic of Wikipedia's OpenAI Codex page.
My favorite thing about this most recent Codex product is that OpenAI shared the full Dockerfile for the environment that the system uses to run code - in openai/codex-universal on GitHub because openai/codex was taken already.
This is extremely useful documentation for figuring out how to use this thing - I'm glad they're making this as transparent as possible.
And to be fair, If you ignore it previous history Codex Is a good name for this product. I'm just glad they didn't call it Ada.
Annotated Presentation Creator. I've released a new version of my tool for creating annotated presentations. I use this to turn slides from my talks into posts like this one - here are a bunch more examples.
I wrote the first version in August 2023 making extensive use of ChatGPT and GPT-4. That older version can still be seen here.
This new edition is a design refresh using Claude 3.7 Sonnet (thinking). I ran this command:
llm \
-f https://til.simonwillison.net/tools/annotated-presentations \
-s 'Improve this tool by making it respnonsive for mobile, improving the styling' \
-m claude-3.7-sonnet -o thinking 1
That uses -f to fetch the original HTML (which has embedded CSS and JavaScript in a single page, convenient for working with LLMs) as a prompt fragment, then applies the system prompt instructions "Improve this tool by making it respnonsive for mobile, improving the styling" (typo included).
Here's the full transcript (generated using llm logs -cue) and a diff illustrating the changes. Total cost 10.7781 cents.
There was one visual glitch: the slides were distorted like this:
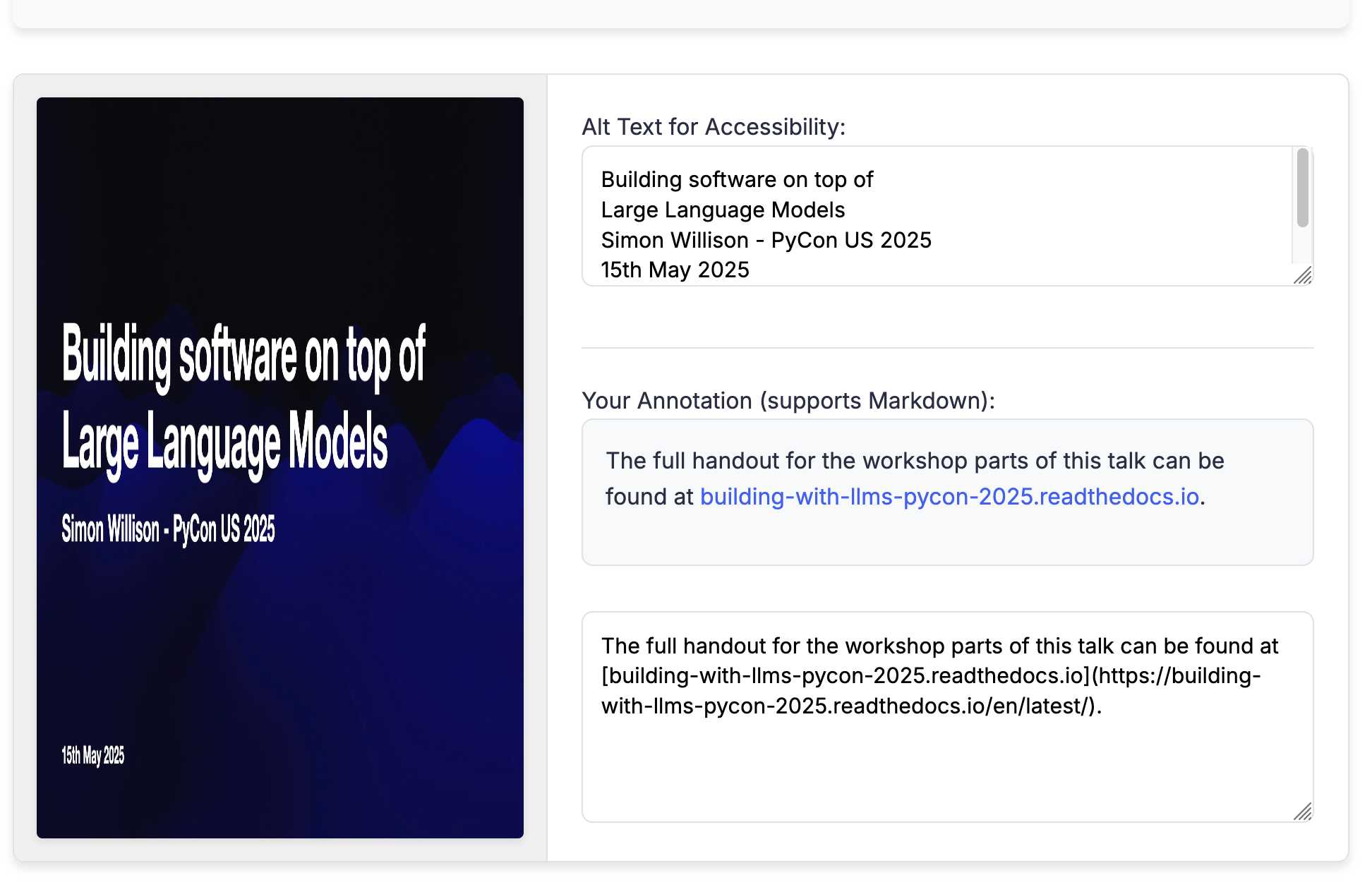
I decided to try o4-mini to see if it could spot the problem (after fixing this LLM bug):
llm o4-mini \
-a bug.png \
-f https://tools.simonwillison.net/annotated-presentations \
-s 'Suggest a minimal fix for this distorted image'
It suggested adding align-items: flex-start; to my .bundle class (it quoted the @media (min-width: 768px) bit but the solution was to add it to .bundle at the top level), which fixed the bug.
By popular request, GPT-4.1 will be available directly in ChatGPT starting today.
GPT-4.1 is a specialized model that excels at coding tasks & instruction following. Because it’s faster, it’s a great alternative to OpenAI o3 & o4-mini for everyday coding needs.
Building software on top of Large Language Models

I presented a three hour workshop at PyCon US yesterday titled Building software on top of Large Language Models. The goal of the workshop was to give participants everything they needed to get started writing code that makes use of LLMs.
[... 3,726 words]LLM 0.26a0 adds support for tools! It's only an alpha so I'm not going to promote this extensively yet, but my LLM project just grew a feature I've been working towards for nearly two years now: tool support!
I'm presenting a workshop about Building software on top of Large Language Models at PyCon US tomorrow and this was the one feature I really needed to pull everything else together.
Tools can be used from the command-line like this (inspired by sqlite-utils --functions):
llm --functions ' def multiply(x: int, y: int) -> int: """Multiply two numbers.""" return x * y ' 'what is 34234 * 213345' -m o4-mini
You can add --tools-debug (shortcut: --td) to have it show exactly what tools are being executed and what came back. More documentation here.
It's also available in the Python library:
import llm def multiply(x: int, y: int) -> int: """Multiply two numbers.""" return x * y model = llm.get_model("gpt-4.1-mini") response = model.chain( "What is 34234 * 213345?", tools=[multiply] ) print(response.text())
There's also a new plugin hook so plugins can register tools that can then be referenced by name using llm --tool name_of_tool "prompt".
There's still a bunch I want to do before including this in a stable release, most notably adding support for Python asyncio. It's a pretty exciting start though!
llm-anthropic 0.16a0 and llm-gemini 0.20a0 add tool support for Anthropic and Gemini models, depending on the new LLM alpha.
Update: Here's the section about tools from my PyCon workshop.
Building, launching, and scaling ChatGPT Images (via) Gergely Orosz landed a fantastic deep dive interview with OpenAI's Sulman Choudhry (head of engineering, ChatGPT) and Srinivas Narayanan (VP of engineering, OpenAI) to talk about the launch back in March of ChatGPT images - their new image generation mode built on top of multi-modal GPT-4o.
The feature kept on having new viral spikes, including one that added one million new users in a single hour. They signed up 100 million new users in the first week after the feature's launch.
When this vertical growth spike started, most of our engineering teams didn't believe it. They assumed there must be something wrong with the metrics.
Under the hood the infrastructure is mostly Python and FastAPI! I hope they're sponsoring those projects (and Starlette, which is used by FastAPI under the hood.)
They're also using some C, and Temporal as a workflow engine. They addressed the early scaling challenge by adding an asynchronous queue to defer the load for their free users (resulting in longer generation times) at peak demand.
There are plenty more details tucked away behind the firewall, including an exclusive I've not been able to find anywhere else: OpenAI's core engineering principles.
- Ship relentlessly - move quickly and continuously improve, without waiting for perfect conditions
- Own the outcome - take full responsibility for products, end-to-end
- Follow through - finish what is started and ensure the work lands fully
I tried getting o4-mini-high to track down a copy of those principles online and was delighted to see it either leak or hallucinate the URL to OpenAI's internal engineering handbook!
Gergely has a whole series of posts like this called Real World Engineering Challenges, including another one on ChatGPT a year ago.
Atlassian: “We’re Not Going to Charge Most Customers Extra for AI Anymore”. The Beginning of the End of the AI Upsell? (via) Jason Lemkin highlighting a potential new trend in the pricing of AI-enhanced SaaS:
Can SaaS and B2B vendors really charge even more for AI … when it’s become core? And we’re already paying $15-$200 a month for a seat? [...]
You can try to charge more, but if the competition isn’t — you’re going to likely lose. And if it’s core to the product itself … can you really charge more ultimately? Probably … not.
It's impressive how quickly LLM-powered features are going from being part of the top tier premium plans to almost an expected part of most per-seat software.
Vision Language Models (Better, Faster, Stronger) (via) Extremely useful review of the last year in vision and multi-modal LLMs.
So much has happened! I'm particularly excited about the range of small open weight vision models that are now available. Models like gemma3-4b-it and Qwen2.5-VL-3B-Instruct produce very impressive results and run happily on mid-range consumer hardware.
I did find one area where LLMs absolutely excel, and I’d never want to be without them:
AIs can find your syntax error 100x faster than you can.
They’ve been a useful tool in multiple areas, to my surprise. But this is the one space where they’ve been an honestly huge help: I know I’ve made a mistake somewhere and I just can’t track it down. I can spend ten minutes staring at my files and pulling my hair out, or get an answer back in thirty seconds.
There are whole categories of coding problems that look like this, and LLMs are damn good at nearly all of them. [...]
— Luke Kanies, AI Is Like a Crappy Consultant
Contributions must not include content generated by large language models or other probabilistic tools, including but not limited to Copilot or ChatGPT. This policy covers code, documentation, pull requests, issues, comments, and any other contributions to the Servo project. [...]
Our rationale is as follows:
Maintainer burden: Reviewers depend on contributors to write and test their code before submitting it. We have found that these tools make it easy to generate large amounts of plausible-looking code that the contributor does not understand, is often untested, and does not function properly. This is a drain on the (already limited) time and energy of our reviewers.
Correctness and security: Even when code generated by AI tools does seem to function, there is no guarantee that it is correct, and no indication of what security implications it may have. A web browser engine is built to run in hostile execution environments, so all code must take into account potential security issues. Contributors play a large role in considering these issues when creating contributions, something that we cannot trust an AI tool to do.
Copyright issues: [...] Ethical issues:: [...] These are harms that we do not want to perpetuate, even if only indirectly.
— Contributing to Servo, section on AI contributions
It's interesting how much my perception of o3 as being the latest, best model released by OpenAI is tarnished by the co-release of o4-mini. I'm also still not entirely sure how to compare o3 to o1-pro, especially given o1-pro is 15x more expensive via the OpenAI API.
Cursor: Security (via) Cursor's security documentation page includes a surprising amount of detail about how the Cursor text editor's backend systems work.
I've recently learned that checking an organization's list of documented subprocessors is a great way to get a feel for how everything works under the hood - it's a loose "view source" for their infrastructure! That was how I confirmed that Anthropic's search features used Brave search back in March.
Cursor's list includes AWS, Azure and GCP (AWS for primary infrastructure, Azure and GCP for "some secondary infrastructure"). They host their own custom models on Fireworks and make API calls out to OpenAI, Anthropic, Gemini and xAI depending on user preferences. They're using turbopuffer as a hosted vector store.
The most interesting section is about codebase indexing:
Cursor allows you to semantically index your codebase, which allows it to answer questions with the context of all of your code as well as write better code by referencing existing implementations. […]
At our server, we chunk and embed the files, and store the embeddings in Turbopuffer. To allow filtering vector search results by file path, we store with every vector an obfuscated relative file path, as well as the line range the chunk corresponds to. We also store the embedding in a cache in AWS, indexed by the hash of the chunk, to ensure that indexing the same codebase a second time is much faster (which is particularly useful for teams).
At inference time, we compute an embedding, let Turbopuffer do the nearest neighbor search, send back the obfuscated file path and line range to the client, and read those file chunks on the client locally. We then send those chunks back up to the server to answer the user’s question.
When operating in privacy mode - which they say is enabled by 50% of their users - they are careful not to store any raw code on their servers for longer than the duration of a single request. This is why they store the embeddings and obfuscated file paths but not the code itself.
Reading this made me instantly think of the paper Text Embeddings Reveal (Almost) As Much As Text about how vector embeddings can be reversed. The security documentation touches on that in the notes:
Embedding reversal: academic work has shown that reversing embeddings is possible in some cases. Current attacks rely on having access to the model and embedding short strings into big vectors, which makes us believe that the attack would be somewhat difficult to do here. That said, it is definitely possible for an adversary who breaks into our vector database to learn things about the indexed codebases.
Trying out llama.cpp’s new vision support
This llama.cpp server vision support via libmtmd pull request—via Hacker News—was merged earlier today. The PR finally adds full support for vision models to the excellent llama.cpp project. It’s documented on this page, but the more detailed technical details are covered here. Here are my notes on getting it working on a Mac.
[... 1,693 words]Gemini 2.5 Models now support implicit caching.
I just spotted a cacheTokensDetails key in the token usage JSON while running a long chain of prompts against Gemini 2.5 Flash - despite not configuring caching myself:
{"cachedContentTokenCount": 200658, "promptTokensDetails": [{"modality": "TEXT", "tokenCount": 204082}], "cacheTokensDetails": [{"modality": "TEXT", "tokenCount": 200658}], "thoughtsTokenCount": 2326}
I went searching and it turns out Gemini had a massive upgrade to their prompt caching earlier today:
Implicit caching directly passes cache cost savings to developers without the need to create an explicit cache. Now, when you send a request to one of the Gemini 2.5 models, if the request shares a common prefix as one of previous requests, then it’s eligible for a cache hit. We will dynamically pass cost savings back to you, providing the same 75% token discount. [...]
To make more requests eligible for cache hits, we reduced the minimum request size for 2.5 Flash to 1024 tokens and 2.5 Pro to 2048 tokens.
Previously you needed to both explicitly configure the cache and pay a per-hour charge to keep that cache warm.
This new mechanism is so much more convenient! It imitates how both DeepSeek and OpenAI implement prompt caching, leaving Anthropic as the remaining large provider who require you to manually configure prompt caching to get it to work.
Gemini's explicit caching mechanism is still available. The documentation says:
Explicit caching is useful in cases where you want to guarantee cost savings, but with some added developer work.
With implicit caching the cost savings aren't possible to predict in advance, especially since the cache timeout within which a prefix will be discounted isn't described and presumably varies based on load and other circumstances outside of the developer's control.
Update: DeepMind's Philipp Schmid:
There is no fixed time, but it's should be a few minutes.
If Claude is asked to count words, letters, and characters, it thinks step by step before answering the person. It explicitly counts the words, letters, or characters by assigning a number to each. It only answers the person once it has performed this explicit counting step. [...]
If Claude is shown a classic puzzle, before proceeding, it quotes every constraint or premise from the person’s message word for word before inside quotation marks to confirm it’s not dealing with a new variant. [...]
If asked to write poetry, Claude avoids using hackneyed imagery or metaphors or predictable rhyming schemes.
— Claude's system prompt, via Drew Breunig
But I’ve also had my own quiet concerns about what [vibe coding] means for early-career developers. So much of how I learned came from chasing bugs in broken tutorials and seeing how all the pieces connected, or didn’t. There was value in that. And maybe I’ve been a little protective of it.
A mentor challenged that. He pointed out that debugging AI generated code is a lot like onboarding into a legacy codebase, making sense of decisions you didn’t make, finding where things break, and learning to trust (or rewrite) what’s already there. That’s the kind of work a lot of developers end up doing anyway.
— Ashley Willis, What Even Is Vibe Coding?
llm-gemini 0.19.1.
Bugfix release for my llm-gemini plugin, which was recording the number of output tokens (needed to calculate the price of a response) incorrectly for the Gemini "thinking" models. Those models turn out to return candidatesTokenCount and thoughtsTokenCount as two separate values which need to be added together to get the total billed output token count. Full details in this issue.
I spotted this potential bug in this response log this morning, and my concerns were confirmed when Paul Gauthier wrote about a similar fix in Aider in Gemini 2.5 Pro Preview 03-25 benchmark cost, where he noted that the $6.32 cost recorded to benchmark Gemini 2.5 Pro Preview 03-25 was incorrect. Since that model is no longer available (despite the date-based model alias persisting) Paul is not able to accurately calculate the new cost, but it's likely a lot more since the Gemini 2.5 Pro Preview 05-06 benchmark cost $37.
I've gone through my gemini tag and attempted to update my previous posts with new calculations - this mostly involved increases in the order of 12.336 cents to 16.316 cents (as seen here).
Introducing web search on the Anthropic API
(via)
Anthropic's web search (presumably still powered by Brave) is now also available through their API, in the shape of a new web search tool called web_search_20250305.
You can specify a maximum number of uses per prompt and you can also pass a list of disallowed or allowed domains, plus hints as to the user's current location.
Search results are returned in a format that looks similar to the Anthropic Citations API.
It's charged at $10 per 1,000 searches, which is a little more expensive than what the Brave Search API charges ($3 or $5 or $9 per thousand depending on how you're using them).
I couldn't find any details of additional rules surrounding storage or display of search results, which surprised me because both Google Gemini and OpenAI have these for their own API search results.
Create and edit images with Gemini 2.0 in preview (via) Gemini 2.0 Flash has had image generation capabilities for a while now, and they're now available via the paid Gemini API - at 3.9 cents per generated image.
According to the API documentation you need to use the new gemini-2.0-flash-preview-image-generation model ID and specify {"responseModalities":["TEXT","IMAGE"]} as part of your request.
Here's an example that calls the API using curl (and fetches a Gemini key from the llm keys get store):
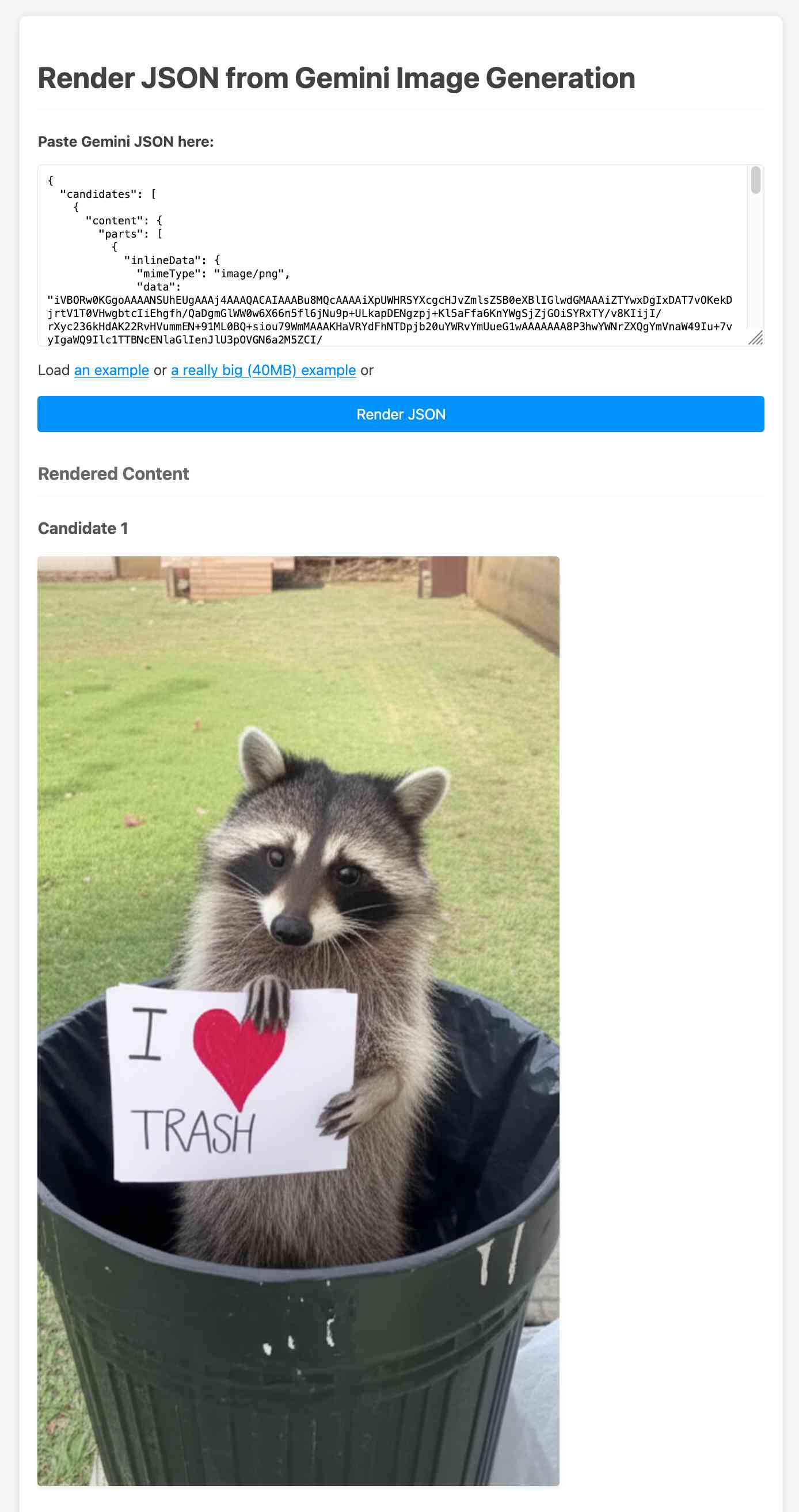
curl -s -X POST \ "https://generativelanguage.googleapis.com/v1beta/models/gemini-2.0-flash-preview-image-generation:generateContent?key=$(llm keys get gemini)" \ -H "Content-Type: application/json" \ -d '{ "contents": [{ "parts": [ {"text": "Photo of a raccoon in a trash can with a paw-written sign that says I love trash"} ] }], "generationConfig":{"responseModalities":["TEXT","IMAGE"]} }' > /tmp/raccoon.json
Here's the response. I got Gemini 2.5 Pro to vibe-code me a new debug tool for visualizing that JSON. If you visit that tool and click the "Load an example" link you'll see the result of the raccoon image visualized:
The other prompt I tried was this one:
Provide a vegetarian recipe for butter chicken but with chickpeas not chicken and include many inline illustrations along the way
The result of that one was a 41MB JSON file(!) containing 28 images - which presumably cost over a dollar since images are 3.9 cents each.
Some of the illustrations it chose for that one were somewhat unexpected:

If you want to see that one you can click the "Load a really big example" link in the debug tool, then wait for your browser to fetch and render the full 41MB JSON file.
The most interesting feature of Gemini (as with GPT-4o images) is the ability to accept images as inputs. I tried that out with this pelican photo like this:
{kind=link}
cat > /tmp/request.json << EOF { "contents": [{ "parts":[ {"text": "Modify this photo to add an inappropriate hat"}, { "inline_data": { "mime_type":"image/jpeg", "data": "$(base64 -i pelican.jpg)" } } ] }], "generationConfig": {"responseModalities": ["TEXT", "IMAGE"]} } EOF # Execute the curl command with the JSON file curl -X POST \ 'https://generativelanguage.googleapis.com/v1beta/models/gemini-2.0-flash-preview-image-generation:generateContent?key='$(llm keys get gemini) \ -H 'Content-Type: application/json' \ -d @/tmp/request.json \ > /tmp/out.json
And now the pelican is wearing a hat:

Medium is the new large. New model release from Mistral - this time closed source/proprietary. Mistral Medium claims strong benchmark scores similar to GPT-4o and Claude 3.7 Sonnet, but is priced at $0.40/million input and $2/million output - about the same price as GPT 4.1 Mini. For comparison, GPT-4o is $2.50/$10 and Claude 3.7 Sonnet is $3/$15.
The model is a vision LLM, accepting both images and text.
More interesting than the price is the deployment model. Mistral Medium may not be open weights but it is very much available for self-hosting:
Mistral Medium 3 can also be deployed on any cloud, including self-hosted environments of four GPUs and above.
Mistral's other announcement today is Le Chat Enterprise. This is a suite of tools that can integrate with your company's internal data and provide "agents" (these look similar to Claude Projects or OpenAI GPTs), again with the option to self-host.
Is there a new open weights model coming soon? This note tucked away at the bottom of the Mistral Medium 3 announcement seems to hint at that:
With the launches of Mistral Small in March and Mistral Medium today, it's no secret that we're working on something 'large' over the next few weeks. With even our medium-sized model being resoundingly better than flagship open source models such as Llama 4 Maverick, we're excited to 'open' up what's to come :)
I released llm-mistral 0.12 adding support for the new model.
llm-prices.com.
I've been maintaining a simple LLM pricing calculator since October last year. I finally decided to split it out to its own domain name (previously it was hosted at tools.simonwillison.net/llm-prices), running on Cloudflare Pages.
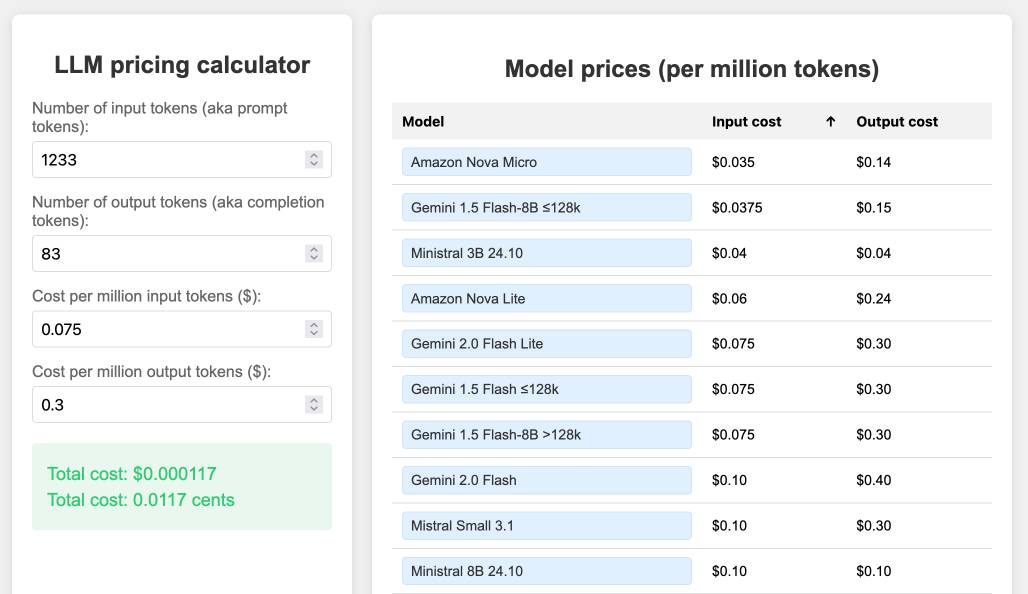
The site runs out of my simonw/llm-prices GitHub repository. I ported the history of the old llm-prices.html file using a vibe-coded bash script that I forgot to save anywhere.
I rarely use AI-generated imagery in my own projects, but for this one I found an excellent reason to use GPT-4o image outputs... to generate the favicon! I dropped a screenshot of the site into ChatGPT (o4-mini-high in this case) and asked for the following:
design a bunch of options for favicons for this site in a single image, white background

I liked the top right one, so I cropped it into Pixelmator and made a 32x32 version. Here's what it looks like in my browser:
I added a new feature just now: the state of the calculator is now reflected in the #fragment-hash URL of the page, which means you can link to your previous calculations.
I implemented that feature using the new gemini-2.5-pro-preview-05-06, since that model boasts improved front-end coding abilities. It did a pretty great job - here's how I prompted it:
llm -m gemini-2.5-pro-preview-05-06 -f https://www.llm-prices.com/ -s 'modify this code so that the state of the page is reflected in the fragmenth hash URL - I want to capture the values filling out the form fields and also the current sort order of the table. These should be respected when the page first loads too. Update them using replaceHistory, no need to enable the back button.'
Here's the transcript and the commit updating the tool, plus an example link showing the new feature in action (and calculating the cost for that Gemini 2.5 Pro prompt at 16.8224 cents, after fixing the calculation.)
What’s the carbon footprint of using ChatGPT? Inspired by Andy Masley's cheat sheet (which I linked to last week) Hannah Ritchie explores some of the numbers herself.
Hanah is Head of Research at Our World in Data, a Senior Researcher at the University of Oxford (bio) and maintains a prolific newsletter on energy and sustainability so she has a lot more credibility in this area than Andy or myself!
My sense is that a lot of climate-conscious people feel guilty about using ChatGPT. In fact it goes further: I think many people judge others for using it, because of the perceived environmental impact. [...]
But after looking at the data on individual use of LLMs, I have stopped worrying about it and I think you should too.
The inevitable counter-argument to the idea that the impact of ChatGPT usage by an individual is negligible is that aggregate user demand is still the thing that drives these enormous investments in huge data centers and new energy sources to power them. Hannah acknowledges that:
I am not saying that AI energy demand, on aggregate, is not a problem. It is, even if it’s “just” of a similar magnitude to the other sectors that we need to electrify, such as cars, heating, or parts of industry. It’s just that individuals querying chatbots is a relatively small part of AI's total energy consumption. That’s how both of these facts can be true at the same time.
Meanwhile Arthur Clune runs the numbers on the potential energy impact of some much more severe usage patterns.
Developers burning through $100 of tokens per day (not impossible given some of the LLM-heavy development patterns that are beginning to emerge) could end the year with the equivalent of a short haul flight or 600 mile car journey.
In the panopticon scenario where all 10 million security cameras in the UK analyze video through a vision LLM at one frame per second Arthur estimates we would need to duplicate the total usage of Birmingham, UK - the output of a 1GW nuclear plant.
Let's not build that panopticon!