Posts tagged postgresql in 2017
Filters: Year: 2017 × postgresql × Sorted by date
PostgreSQL Exercises. Excellent set of PostgreSQL exercises by Alisdair Owens, each with an interactive editor that lets you run your queries against a real database. Starts with the basics, but also covers advanced topics like recursive queries and window aggregate functions.
How a single PostgreSQL config change improved slow query performance by 50x. “If you are using SSDs and running PostgreSQL with default configuration, I encourage you to try tuning random_page_cost & seq_page_cost. You might be surprised by some huge performance improvements.”
Scaling Postgres with Read Replicas & Using WAL to Counter Stale Reads (via) The problem with sending writes to the primary and balancing reads across replicas is dealing with replica lag—what if you write to the primary and then read from a replica that hasn’t had the new state applied to it yet? Brandur Leach dives deep into an elegant solution using PostgreSQL’s LSN (log sequence numbers) accesesed using pg_last_wal_replay_lsn(). An observer process continuously polls the replicas for their most recently applied LSN and stores them in a table. A column in the Users table then records the min_lsn valid for that user, updating it to the pg_current_wal_lsn() of the primary whenever that user makes a write. Combining the two allows the application to randomly select a replica that is up-to-date for the purposes of a specific user any time it needs to make a read.
django-multitenant (via) Absolutely fascinating Django library for horizontally sharding a database using a multi-tenant pattern, from the team at Citus. In this pattern every relevant table includes a “tenant_id”, and all queries should specifically select against that ID. Once you have that in place, you can shard your rows across multiple different databases and route to the correct database based on the tenant ID, safe in the knowledge that joins will still work provided they are against other rows belonging to the same tenant.
Redis Streams and the Unified Log. In which Brandur Leach explores the new Kafka-style streams functionality coming to Redis 4.0, and shows an example of a robust at-least once processing architecture built on a combination of Redis streams and PostgreSQL transactions. I really like the pattern of writing log records to a staging table in PostgreSQL first in order to bundle them up in the same transaction as the originating state change, then have a separate process read them from that table and publish them to Redis.
Cloud SQL for PostgreSQL adds high availability and replication. Google Cloud Platform now offers PostgreSQL with automatic asynchronous disk-level replication to a separate instance in a different availability zone, via their new “Regional Disks“ feature. Between this, Heroku, Citus and Amazon RDS the appeal of a self-maintained PostgreSQL instance continues to fall.
Squeezing every drop of performance out of a Django app on Heroku. Ben Firshman describes some lesser known tricks for scaling Django on Heroku—in particular, using gunicorn gevent asynchronous workers and setting up PostgreSQL connection pooling using django-db-geventpool.
Scaling the GitLab database. Lots of interesting details on how GitLab have worked to scale their PostgreSQL setup. They’ve avoided sharding so far, instead opting for database pooling with pgbouncer and read-only replicas using hot standbys. I like the way they deal with replica lag—they store the current WAL position in a redis key for the user every time there’s a write, then use pg_last_xlog_replay_location() on the various replicas to check and see if they have caught up next time the user makes a request that needs to read some data.
Benefit of TEXT with CHECK over VARCHAR(X) in PostgreSQL.
Brandur suggests using email TEXT CHECK (char_length(email) <= 255) to define a column with a length limit in PostgreSQL over VARCHAR(255) because TEXT and VARCHAR are equally performant but a CHECK length can be changed later on without locking the table, whereas a VARCHAR requires an ALTER TABLE with an exclusive lock.
Implementing Stripe-like Idempotency Keys in Postgres (via) Having clients send “idempotency keys” with API requests in order to be able to safely retry them if something’s goes wrong is a really neat trick for making transactional APIs more robust. Here Brandur Leach talks implementation strategies.
How to set up world-class continuous deployment using free hosted tools
I’m going to describe a way to put together a world-class continuous deployment infrastructure for your side-project without spending any money.
[... 1,294 words]SQL Fiddle demonstrating the PostgreSQL to_tsvector() function (via) SQL Fiddle is amazing—it’s an interactive pastebin that lets you execute queries against MySQL, PostgreSQL, Oracle, SQLite & SQL Server, and then share both the input and the results by sending around the resulting URL. Here I’m using it to demonstrate that stripping tags before indexing documents in PostgreSQL is unnecessary because the ts_vector() function already does that for you.
PostgreSQL 10 Released. Highlights include major improvements to parallelized queries, quorum commit for synchronous replication (sounds reminiscent of Cassandra) and logical replication, which allows modifications to specific tables to be replicated to different clusters. They’re also changing their versioning scheme to Major.Minor, so the next minor release will be 10.1 and the next major release will be 11.
Implementing faceted search with Django and PostgreSQL
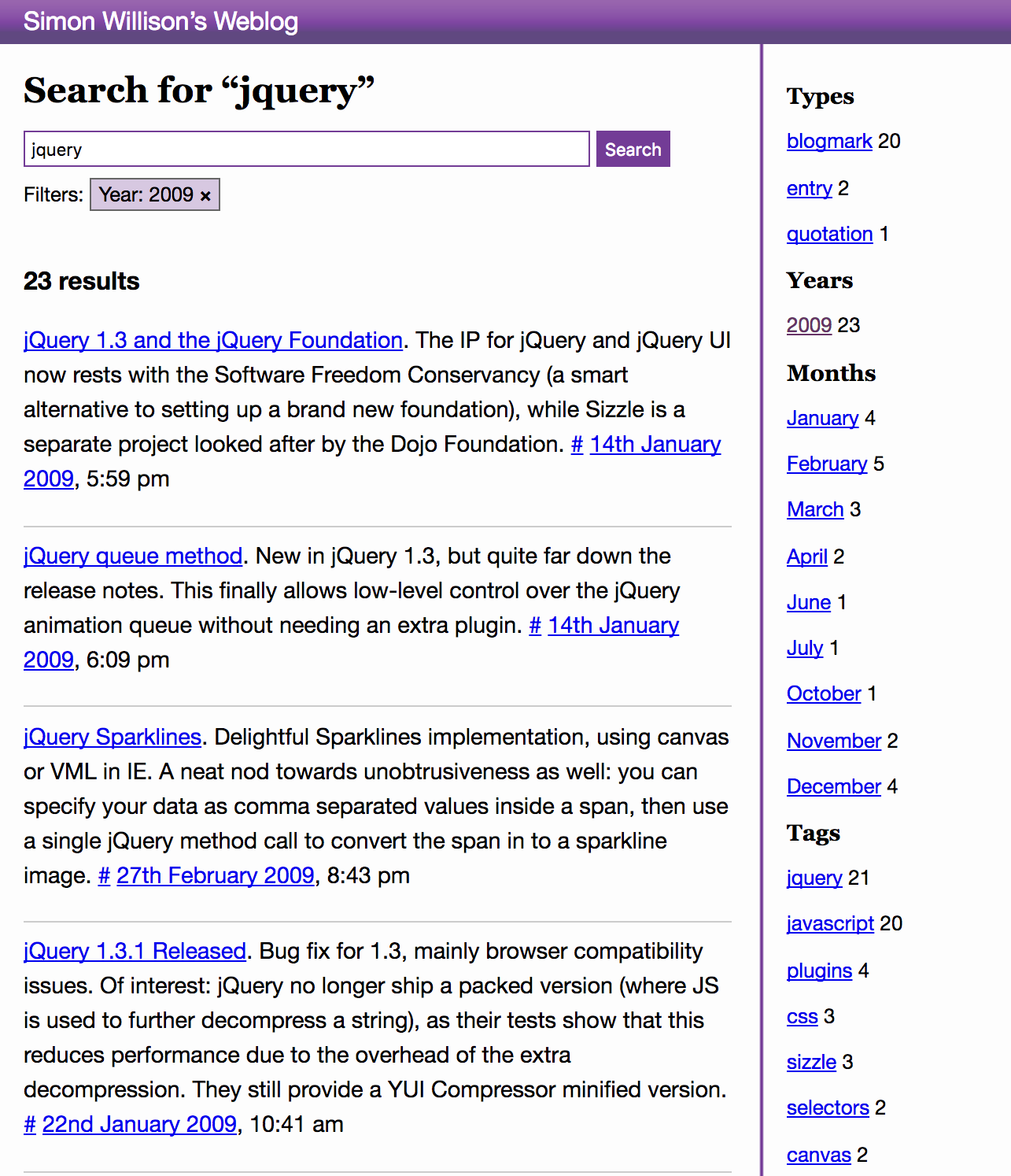
I’ve added a faceted search engine to this blog, powered by PostgreSQL. It supports regular text search (proper search, not just SQL“like” queries), filter by tag, filter by date, filter by content type (entries vs blogmarks vs quotation) and any combination of the above. Some example searches:
[... 3,103 words]