Blogmarks tagged llm, openai
Filters: Type: blogmark × llm × openai × Sorted by date
o3-pro. OpenAI released o3-pro today, which they describe as a "version of o3 with more compute for better responses".
It's only available via the newer Responses API. I've added it to my llm-openai-plugin plugin which uses that new API, so you can try it out like this:
llm install -U llm-openai-plugin
llm -m openai/o3-pro "Generate an SVG of a pelican riding a bicycle"

It's slow - generating this pelican took 124 seconds! OpenAI suggest using their background mode for o3 prompts, which I haven't tried myself yet.
o3-pro is priced at $20/million input tokens and $80/million output tokens - 10x the price of regular o3 after its 80% price drop this morning.
Ben Hylak had early access and published his notes so far in God is hungry for Context: First thoughts on o3 pro. It sounds like this model needs to be applied very thoughtfully. It comparison to o3:
It's smarter. much smarter.
But in order to see that, you need to give it a lot more context. and I'm running out of context. [...]
My co-founder Alexis and I took the the time to assemble a history of all of our past planning meetings at Raindrop, all of our goals, even record voice memos: and then asked o3-pro to come up with a plan.
We were blown away; it spit out the exact kind of concrete plan and analysis I've always wanted an LLM to create --- complete with target metrics, timelines, what to prioritize, and strict instructions on what to absolutely cut.
The plan o3 gave us was plausible, reasonable; but the plan o3 Pro gave us was specific and rooted enough that it actually changed how we are thinking about our future.
This is hard to capture in an eval.
It sounds to me like o3-pro works best when combined with tools. I don't have tool support in llm-openai-plugin yet, here's the relevant issue.
How I used o3 to find CVE-2025-37899, a remote zeroday vulnerability in the Linux kernel’s SMB implementation (via) Sean Heelan:
The vulnerability [o3] found is CVE-2025-37899 (fix here), a use-after-free in the handler for the SMB 'logoff' command. Understanding the vulnerability requires reasoning about concurrent connections to the server, and how they may share various objects in specific circumstances. o3 was able to comprehend this and spot a location where a particular object that is not referenced counted is freed while still being accessible by another thread. As far as I'm aware, this is the first public discussion of a vulnerability of that nature being found by a LLM.
Before I get into the technical details, the main takeaway from this post is this: with o3 LLMs have made a leap forward in their ability to reason about code, and if you work in vulnerability research you should start paying close attention. If you're an expert-level vulnerability researcher or exploit developer the machines aren't about to replace you. In fact, it is quite the opposite: they are now at a stage where they can make you significantly more efficient and effective. If you have a problem that can be represented in fewer than 10k lines of code there is a reasonable chance o3 can either solve it, or help you solve it.
Sean used my LLM tool to help find the bug! He ran it against the prompts he shared in this GitHub repo using the following command:
llm --sf system_prompt_uafs.prompt \
-f session_setup_code.prompt \
-f ksmbd_explainer.prompt \
-f session_setup_context_explainer.prompt \
-f audit_request.prompt
Sean ran the same prompt 100 times, so I'm glad he was using the new, more efficient fragments mechanism.
o3 found his first, known vulnerability 8/100 times - but found the brand new one in just 1 out of the 100 runs it performed with a larger context.
I thoroughly enjoyed this snippet which perfectly captures how I feel when I'm iterating on prompts myself:
In fact my entire system prompt is speculative in that I haven’t ran a sufficient number of evaluations to determine if it helps or hinders, so consider it equivalent to me saying a prayer, rather than anything resembling science or engineering.
Sean's conclusion with respect to the utility of these models for security research:
If we were to never progress beyond what o3 can do right now, it would still make sense for everyone working in VR [Vulnerability Research] to figure out what parts of their work-flow will benefit from it, and to build the tooling to wire it in. Of course, part of that wiring will be figuring out how to deal with the the signal to noise ratio of ~1:50 in this case, but that’s something we are already making progress at.
OpenAI Codex. Announced today, here's the documentation for OpenAI's "cloud-based software engineering agent". It's not yet available for us $20/month Plus customers ("coming soon") but if you're a $200/month Pro user you can try it out now.
At a high level, you specify a prompt, and the agent goes to work in its own environment. After about 8–10 minutes, the agent gives you back a diff.
You can execute prompts in either ask mode or code mode. When you select ask, Codex clones a read-only version of your repo, booting faster and giving you follow-up tasks. Code mode, however, creates a full-fledged environment that the agent can run and test against.
This 4 minute demo video is a useful overview. One note that caught my eye is that the setup phase for an environment can pull from the internet (to install necessary dependencies) but the agent loop itself still runs in a network disconnected sandbox.
It sounds similar to GitHub's own Copilot Workspace project, which can compose PRs against your code based on a prompt. The big difference is that Codex incorporates a full Code Interpeter style environment, allowing it to build and run the code it's creating and execute tests in a loop.
Copilot Workspaces has a level of integration with Codespaces but still requires manual intervention to help exercise the code.
Also similar to Copilot Workspaces is a confusing name. OpenAI now have four products called Codex:
- OpenAI Codex, announced today.
- Codex CLI, a completely different coding assistant tool they released a few weeks ago that is the same kind of shape as Claude Code. This one owns the openai/codex namespace on GitHub.
- codex-mini, a brand new model released today that is used by their Codex product. It's a fine-tuned o4-mini variant. I released llm-openai-plugin 0.4 adding support for that model.
- OpenAI Codex (2021) - Internet Archive link, OpenAI's first specialist coding model from the GPT-3 era. This was used by the original GitHub Copilot and is still the current topic of Wikipedia's OpenAI Codex page.
My favorite thing about this most recent Codex product is that OpenAI shared the full Dockerfile for the environment that the system uses to run code - in openai/codex-universal on GitHub because openai/codex was taken already.
This is extremely useful documentation for figuring out how to use this thing - I'm glad they're making this as transparent as possible.
And to be fair, If you ignore it previous history Codex Is a good name for this product. I'm just glad they didn't call it Ada.
LLM 0.26a0 adds support for tools! It's only an alpha so I'm not going to promote this extensively yet, but my LLM project just grew a feature I've been working towards for nearly two years now: tool support!
I'm presenting a workshop about Building software on top of Large Language Models at PyCon US tomorrow and this was the one feature I really needed to pull everything else together.
Tools can be used from the command-line like this (inspired by sqlite-utils --functions):
llm --functions ' def multiply(x: int, y: int) -> int: """Multiply two numbers.""" return x * y ' 'what is 34234 * 213345' -m o4-mini
You can add --tools-debug (shortcut: --td) to have it show exactly what tools are being executed and what came back. More documentation here.
It's also available in the Python library:
import llm def multiply(x: int, y: int) -> int: """Multiply two numbers.""" return x * y model = llm.get_model("gpt-4.1-mini") response = model.chain( "What is 34234 * 213345?", tools=[multiply] ) print(response.text())
There's also a new plugin hook so plugins can register tools that can then be referenced by name using llm --tool name_of_tool "prompt".
There's still a bunch I want to do before including this in a stable release, most notably adding support for Python asyncio. It's a pretty exciting start though!
llm-anthropic 0.16a0 and llm-gemini 0.20a0 add tool support for Anthropic and Gemini models, depending on the new LLM alpha.
Update: Here's the section about tools from my PyCon workshop.
Introducing OpenAI o3 and o4-mini. OpenAI are really emphasizing tool use with these:
For the first time, our reasoning models can agentically use and combine every tool within ChatGPT—this includes searching the web, analyzing uploaded files and other data with Python, reasoning deeply about visual inputs, and even generating images. Critically, these models are trained to reason about when and how to use tools to produce detailed and thoughtful answers in the right output formats, typically in under a minute, to solve more complex problems.
I released llm-openai-plugin 0.3 adding support for the two new models:
llm install -U llm-openai-plugin
llm -m openai/o3 "say hi in five languages"
llm -m openai/o4-mini "say hi in five languages"
Here are the pelicans riding bicycles (prompt: Generate an SVG of a pelican riding a bicycle).
o3:
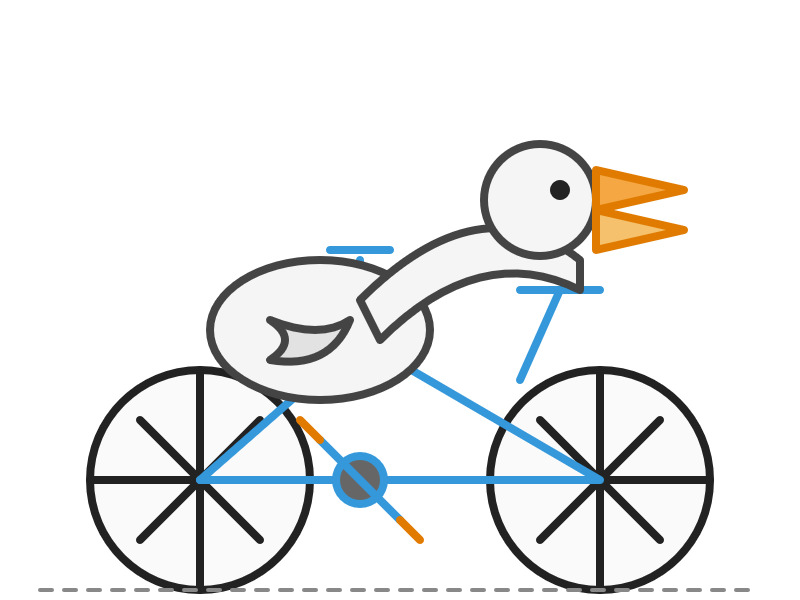
o4-mini:

Here are the full OpenAI model listings: o3 is $10/million input and $40/million for output, with a 75% discount on cached input tokens, 200,000 token context window, 100,000 max output tokens and a May 31st 2024 training cut-off (same as the GPT-4.1 models). It's a bit cheaper than o1 ($15/$60) and a lot cheaper than o1-pro ($150/$600).
o4-mini is priced the same as o3-mini: $1.10/million for input and $4.40/million for output, also with a 75% input caching discount. The size limits and training cut-off are the same as o3.
You can compare these prices with other models using the table on my updated LLM pricing calculator.
A new capability released today is that the OpenAI API can now optionally return reasoning summary text. I've been exploring that in this issue. I believe you have to verify your organization (which may involve a photo ID) in order to use this option - once you have access the easiest way to see the new tokens is using curl like this:
curl https://api.openai.com/v1/responses \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $(llm keys get openai)" \
-d '{
"model": "o3",
"input": "why is the sky blue?",
"reasoning": {"summary": "auto"},
"stream": true
}'
This produces a stream of events that includes this new event type:
event: response.reasoning_summary_text.delta
data: {"type": "response.reasoning_summary_text.delta","item_id": "rs_68004320496081918e1e75ddb550d56e0e9a94ce520f0206","output_index": 0,"summary_index": 0,"delta": "**Expl"}
Omit the "stream": true and the response is easier to read and contains this:
{
"output": [
{
"id": "rs_68004edd2150819183789a867a9de671069bc0c439268c95",
"type": "reasoning",
"summary": [
{
"type": "summary_text",
"text": "**Explaining the blue sky**\n\nThe user asks a classic question about why the sky is blue. I'll talk about Rayleigh scattering, where shorter wavelengths of light scatter more than longer ones. This explains how we see blue light spread across the sky! I wonder if the user wants a more scientific or simpler everyday explanation. I'll aim for a straightforward response while keeping it engaging and informative. So, let's break it down!"
}
]
},
{
"id": "msg_68004edf9f5c819188a71a2c40fb9265069bc0c439268c95",
"type": "message",
"status": "completed",
"content": [
{
"type": "output_text",
"annotations": [],
"text": "The short answer ..."
}
]
}
]
}
OpenAI platform: o1-pro. OpenAI have a new most-expensive model: o1-pro can now be accessed through their API at a hefty $150/million tokens for input and $600/million tokens for output. That's 10x the price of their o1 and o1-preview models and a full 1,000x times more expensive than their cheapest model, gpt-4o-mini!
Aside from that it has mostly the same features as o1: a 200,000 token context window, 100,000 max output tokens, Sep 30 2023 knowledge cut-off date and it supports function calling, structured outputs and image inputs.
o1-pro doesn't support streaming, and most significantly for developers is the first OpenAI model to only be available via their new Responses API. This means tools that are built against their Chat Completions API (like my own LLM) have to do a whole lot more work to support the new model - my issue for that is here.
Since LLM doesn't support this new model yet I had to make do with curl:
curl https://api.openai.com/v1/responses \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $(llm keys get openai)" \
-d '{
"model": "o1-pro",
"input": "Generate an SVG of a pelican riding a bicycle"
}'
Here's the full JSON I got back - 81 input tokens and 1552 output tokens for a total cost of 94.335 cents.

I took a risk and added "reasoning": {"effort": "high"} to see if I could get a better pelican with more reasoning:
curl https://api.openai.com/v1/responses \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $(llm keys get openai)" \
-d '{
"model": "o1-pro",
"input": "Generate an SVG of a pelican riding a bicycle",
"reasoning": {"effort": "high"}
}'
Surprisingly that used less output tokens - 1459 compared to 1552 earlier (cost: 88.755 cents) - producing this JSON which rendered as a slightly better pelican:

It was cheaper because while it spent 960 reasoning tokens as opposed to 704 for the previous pelican it omitted the explanatory text around the SVG, saving on total output.
OpenAI API: Responses vs. Chat Completions. OpenAI released a bunch of new API platform features this morning under the headline "New tools for building agents" (their somewhat mushy interpretation of "agents" here is "systems that independently accomplish tasks on behalf of users").
A particularly significant change is the introduction of a new Responses API, which is a slightly different shape from the Chat Completions API that they've offered for the past couple of years and which others in the industry have widely cloned as an ad-hoc standard.
In this guide they illustrate the differences, with a reassuring note that:
The Chat Completions API is an industry standard for building AI applications, and we intend to continue supporting this API indefinitely. We're introducing the Responses API to simplify workflows involving tool use, code execution, and state management. We believe this new API primitive will allow us to more effectively enhance the OpenAI platform into the future.
An API that is going away is the Assistants API, a perpetual beta first launched at OpenAI DevDay in 2023. The new responses API solves effectively the same problems but better, and assistants will be sunset "in the first half of 2026".
The best illustration I've seen of the differences between the two is this giant commit to the openai-python GitHub repository updating ALL of the example code in one go.
The most important feature of the Responses API (a feature it shares with the old Assistants API) is that it can manage conversation state on the server for you. An oddity of the Chat Completions API is that you need to maintain your own records of the current conversation, sending back full copies of it with each new prompt. You end up making API calls that look like this (from their examples):
{
"model": "gpt-4o-mini",
"messages": [
{
"role": "user",
"content": "knock knock.",
},
{
"role": "assistant",
"content": "Who's there?",
},
{
"role": "user",
"content": "Orange."
}
]
}These can get long and unwieldy - especially when attachments such as images are involved - but the real challenge is when you start integrating tools: in a conversation with tool use you'll need to maintain that full state and drop messages in that show the output of the tools the model requested. It's not a trivial thing to work with.
The new Responses API continues to support this list of messages format, but you also get the option to outsource that to OpenAI entirely: you can add a new "store": true property and then in subsequent messages include a "previous_response_id: response_id key to continue that conversation.
This feels a whole lot more natural than the Assistants API, which required you to think in terms of threads, messages and runs to achieve the same effect.
Also fun: the Response API supports HTML form encoding now in addition to JSON:
curl https://api.openai.com/v1/responses \
-u :$OPENAI_API_KEY \
-d model="gpt-4o" \
-d input="What is the capital of France?"
I found that in an excellent Twitter thread providing background on the design decisions in the new API from OpenAI's Atty Eleti. Here's a nitter link for people who don't have a Twitter account.
New built-in tools
A potentially more exciting change today is the introduction of default tools that you can request while using the new Responses API. There are three of these, all of which can be specified in the "tools": [...] array.
{"type": "web_search_preview"}- the same search feature available through ChatGPT. The documentation doesn't clarify which underlying search engine is used - I initially assumed Bing, but the tool documentation links to this Overview of OpenAI Crawlers page so maybe it's entirely in-house now? Web search is priced at between $25 and $50 per thousand queries depending on if you're using GPT-4o or GPT-4o mini and the configurable size of your "search context".{"type": "file_search", "vector_store_ids": [...]}provides integration with the latest version of their file search vector store, mainly used for RAG. "Usage is priced at $2.50 per thousand queries and file storage at $0.10/GB/day, with the first GB free".{"type": "computer_use_preview", "display_width": 1024, "display_height": 768, "environment": "browser"}is the most surprising to me: it's tool access to the Computer-Using Agent system they built for their Operator product. This one is going to be a lot of fun to explore. The tool's documentation includes a warning about prompt injection risks. Though on closer inspection I think this may work more like Claude Computer Use, where you have to run the sandboxed environment yourself rather than outsource that difficult part to them.
I'm still thinking through how to expose these new features in my LLM tool, which is made harder by the fact that a number of plugins now rely on the default OpenAI implementation from core, which is currently built on top of Chat Completions. I've been worrying for a while about the impact of our entire industry building clones of one proprietary API that might change in the future, I guess now we get to see how that shakes out!
o3-mini is really good at writing internal documentation. I wanted to refresh my knowledge of how the Datasette permissions system works today. I already have extensive hand-written documentation for that, but I thought it would be interesting to see if I could derive any insights from running an LLM against the codebase.
o3-mini has an input limit of 200,000 tokens. I used LLM and my files-to-prompt tool to generate the documentation like this:
cd /tmp
git clone https://github.com/simonw/datasette
cd datasette
files-to-prompt datasette -e py -c | \
llm -m o3-mini -s \
'write extensive documentation for how the permissions system works, as markdown'The files-to-prompt command is fed the datasette subdirectory, which contains just the source code for the application - omitting tests (in tests/) and documentation (in docs/).
The -e py option causes it to only include files with a .py extension - skipping all of the HTML and JavaScript files in that hierarchy.
The -c option causes it to output Claude's XML-ish format - a format that works great with other LLMs too.
You can see the output of that command in this Gist.
Then I pipe that result into LLM, requesting the o3-mini OpenAI model and passing the following system prompt:
write extensive documentation for how the permissions system works, as markdown
Specifically requesting Markdown is important.
The prompt used 99,348 input tokens and produced 3,118 output tokens (320 of those were invisible reasoning tokens). That's a cost of 12.3 cents.
Honestly, the results are fantastic. I had to double-check that I hadn't accidentally fed in the documentation by mistake.
(It's possible that the model is picking up additional information about Datasette in its training set, but I've seen similar high quality results from other, newer libraries so I don't think that's a significant factor.)
In this case I already had extensive written documentation of my own, but this was still a useful refresher to help confirm that the code matched my mental model of how everything works.
Documentation of project internals as a category is notorious for going out of date. Having tricks like this to derive usable how-it-works documentation from existing codebases in just a few seconds and at a cost of a few cents is wildly valuable.
OpenAI reasoning models: Advice on prompting (via) OpenAI's documentation for their o1 and o3 "reasoning models" includes some interesting tips on how to best prompt them:
- Developer messages are the new system messages: Starting with
o1-2024-12-17, reasoning models supportdevelopermessages rather thansystemmessages, to align with the chain of command behavior described in the model spec.
This appears to be a purely aesthetic change made for consistency with their instruction hierarchy concept. As far as I can tell the old system prompts continue to work exactly as before - you're encouraged to use the new developer message type but it has no impact on what actually happens.
Since my LLM tool already bakes in a llm --system "system prompt" option which works across multiple different models from different providers I'm not going to rush to adopt this new language!
- Use delimiters for clarity: Use delimiters like markdown, XML tags, and section titles to clearly indicate distinct parts of the input, helping the model interpret different sections appropriately.
Anthropic have been encouraging XML-ish delimiters for a while (I say -ish because there's no requirement that the resulting prompt is valid XML). My files-to-prompt tool has a -c option which outputs Claude-style XML, and in my experiments this same option works great with o1 and o3 too:
git clone https://github.com/tursodatabase/limbo
cd limbo/bindings/python
files-to-prompt . -c | llm -m o3-mini \
-o reasoning_effort high \
--system 'Write a detailed README with extensive usage examples'
- Limit additional context in retrieval-augmented generation (RAG): When providing additional context or documents, include only the most relevant information to prevent the model from overcomplicating its response.
This makes me thing that o1/o3 are not good models to implement RAG on at all - with RAG I like to be able to dump as much extra context into the prompt as possible and leave it to the models to figure out what's relevant.
- Try zero shot first, then few shot if needed: Reasoning models often don't need few-shot examples to produce good results, so try to write prompts without examples first. If you have more complex requirements for your desired output, it may help to include a few examples of inputs and desired outputs in your prompt. Just ensure that the examples align very closely with your prompt instructions, as discrepancies between the two may produce poor results.
Providing examples remains the single most powerful prompting tip I know, so it's interesting to see advice here to only switch to examples if zero-shot doesn't work out.
- Be very specific about your end goal: In your instructions, try to give very specific parameters for a successful response, and encourage the model to keep reasoning and iterating until it matches your success criteria.
This makes sense: reasoning models "think" until they reach a conclusion, so making the goal as unambiguous as possible leads to better results.
- Markdown formatting: Starting with
o1-2024-12-17, reasoning models in the API will avoid generating responses with markdown formatting. To signal to the model when you do want markdown formatting in the response, include the stringFormatting re-enabledon the first line of yourdevelopermessage.
This one was a real shock to me! I noticed that o3-mini was outputting • characters instead of Markdown * bullets and initially thought that was a bug.
I first saw this while running this prompt against limbo/bindings/python using files-to-prompt:
git clone https://github.com/tursodatabase/limbo
cd limbo/bindings/python
files-to-prompt . -c | llm -m o3-mini \
-o reasoning_effort high \
--system 'Write a detailed README with extensive usage examples'Here's the full result, which includes text like this (note the weird bullets):
Features
--------
• High‑performance, in‑process database engine written in Rust
• SQLite‑compatible SQL interface
• Standard Python DB‑API 2.0–style connection and cursor objects
I ran it again with this modified prompt:
Formatting re-enabled. Write a detailed README with extensive usage examples.
And this time got back proper Markdown, rendered in this Gist. That did a really good job, and included bulleted lists using this valid Markdown syntax instead:
- **`make test`**: Run tests using pytest.
- **`make lint`**: Run linters (via [ruff](https://github.com/astral-sh/ruff)).
- **`make check-requirements`**: Validate that the `requirements.txt` files are in sync with `pyproject.toml`.
- **`make compile-requirements`**: Compile the `requirements.txt` files using pip-tools.
(Using LLMs like this to get me off the ground with under-documented libraries is a trick I use several times a month.)
Update: OpenAI's Nikunj Handa:
we agree this is weird! fwiw, it’s a temporary thing we had to do for the existing o-series models. we’ll fix this in future releases so that you can go back to naturally prompting for markdown or no-markdown.
LLM 0.20. New release of my LLM CLI tool and Python library. A bunch of accumulated fixes and features since the start of December, most notably:
- Support for OpenAI's o1 model - a significant upgrade from
o1-previewgiven its 200,000 input and 100,000 output tokens (o1-previewwas 128,000/32,768). #676 - Support for the
gpt-4o-audio-previewandgpt-4o-mini-audio-previewmodels, which can accept audio input:llm -m gpt-4o-audio-preview -a https://static.simonwillison.net/static/2024/pelican-joke-request.mp3#677 - A new
llm -x/--extractoption which extracts and returns the contents of the first fenced code block in the response. This is useful for prompts that generate code. #681 - A new
llm models -q 'search'option for searching available models - useful if you've installed a lot of plugins. Searches are case insensitive. #700
datasette-queries. I released the first alpha of a new plugin to replace the crusty old datasette-saved-queries. This one adds a new UI element to the top of the query results page with an expandable form for saving the query as a new canned query:
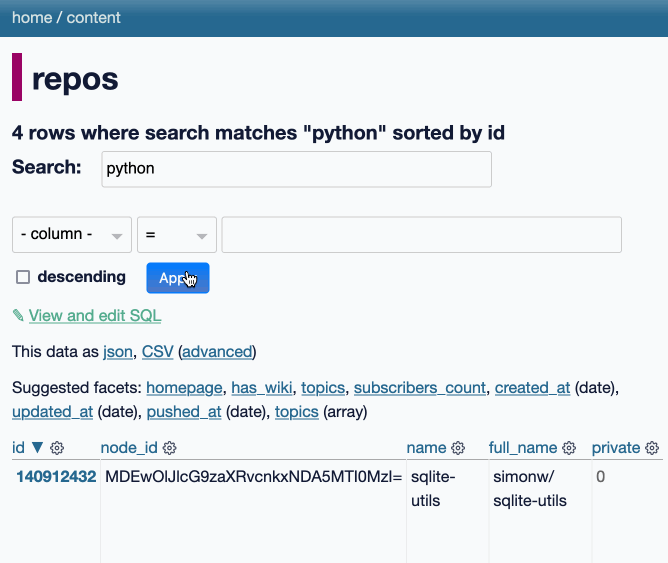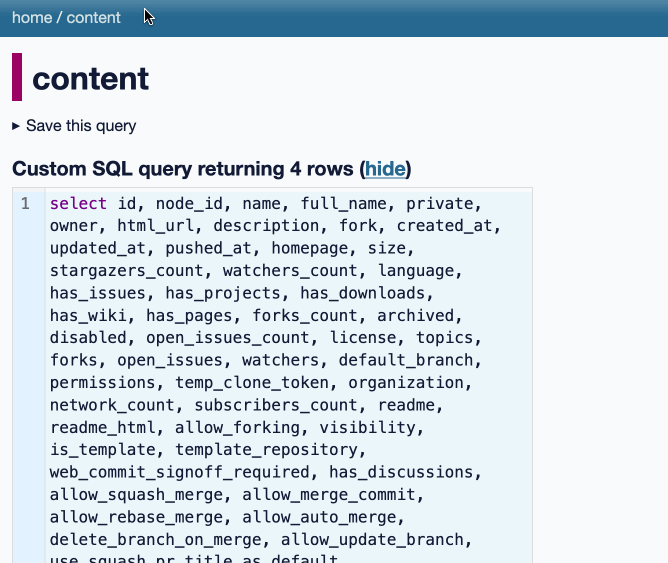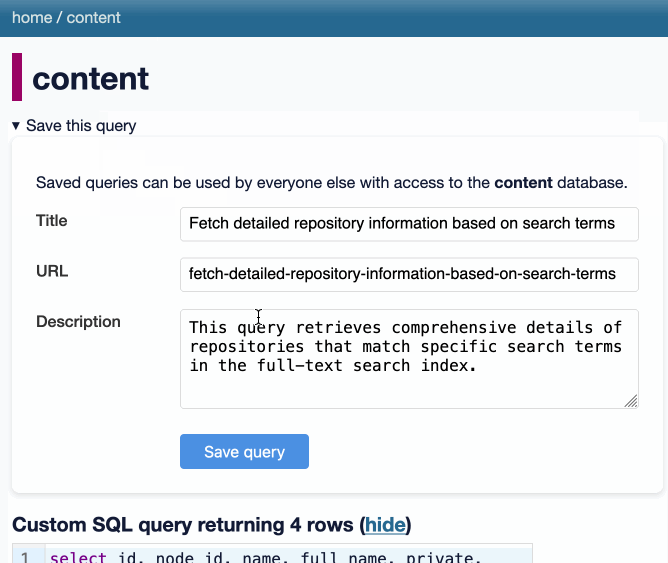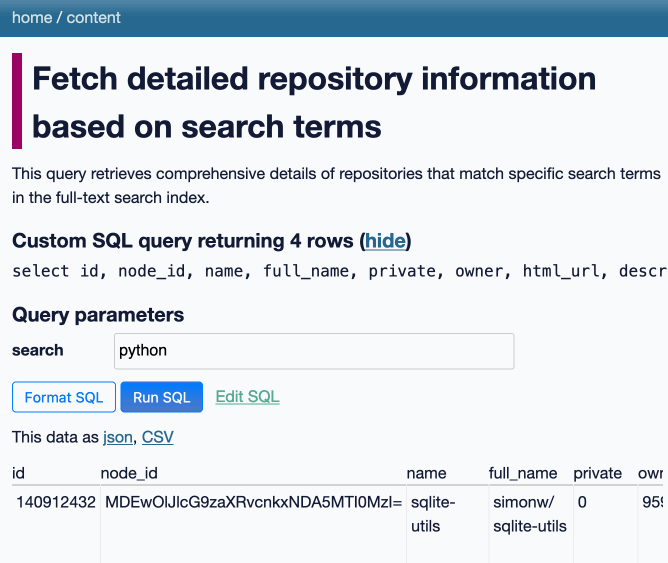
It's my first plugin to depend on LLM and datasette-llm-usage - it uses GPT-4o mini to power an optional "Suggest title and description" button, labeled with the becoming-standard ✨ sparkles emoji to indicate an LLM-powered feature.
I intend to expand this to work across multiple models as I continue to iterate on llm-datasette-usage to better support those kinds of patterns.
For the moment though each suggested title and description call costs about 250 input tokens and 50 output tokens, which against GPT-4o mini adds up to 0.0067 cents.
llm-whisper-api. I wanted to run an experiment through the OpenAI Whisper API this morning so I knocked up a very quick plugin for LLM that provides the following interface:
llm install llm-whisper-api
llm whisper-api myfile.mp3 > transcript.txt
It uses the API key that you previously configured using the llm keys set openai command. If you haven't configured one you can pass it as --key XXX instead.
It's a tiny plugin: the source code is here.
Pelicans on a bicycle. I decided to roll out my own LLM benchmark: how well can different models render an SVG of a pelican riding a bicycle?
I chose that because a) I like pelicans and b) I'm pretty sure there aren't any pelican on a bicycle SVG files floating around (yet) that might have already been sucked into the training data.
My prompt:
Generate an SVG of a pelican riding a bicycle
I've run it through 16 models so far - from OpenAI, Anthropic, Google Gemini and Meta (Llama running on Cerebras), all using my LLM CLI utility. Here's my (Claude assisted) Bash script: generate-svgs.sh
Here's Claude 3.5 Sonnet (2024-06-20) and Claude 3.5 Sonnet (2024-10-22):


Gemini 1.5 Flash 001 and Gemini 1.5 Flash 002:


GPT-4o mini and GPT-4o:


o1-mini and o1-preview:


Cerebras Llama 3.1 70B and Llama 3.1 8B:


And a special mention for Gemini 1.5 Flash 8B:

The rest of them are linked from the README.
Gemini 1.5 Flash-8B is now production ready (via) Gemini 1.5 Flash-8B is "a smaller and faster variant of 1.5 Flash" - and is now released to production, at half the price of the 1.5 Flash model.
It's really, really cheap:
- $0.0375 per 1 million input tokens on prompts <128K
- $0.15 per 1 million output tokens on prompts <128K
- $0.01 per 1 million input tokens on cached prompts <128K
Prices are doubled for prompts longer than 128K.
I believe images are still charged at a flat rate of 258 tokens, which I think means a single non-cached image with Flash should cost 0.00097 cents - a number so tiny I'm doubting if I got the calculation right.
OpenAI's cheapest model remains GPT-4o mini, at $0.15/1M input - though that drops to half of that for reused prompt prefixes thanks to their new prompt caching feature (or by half if you use batches, though those can’t be combined with OpenAI prompt caching. Gemini also offer half-off for batched requests).
Anthropic's cheapest model is still Claude 3 Haiku at $0.25/M, though that drops to $0.03/M for cached tokens (if you configure them correctly).
I've released llm-gemini 0.2 with support for the new model:
llm install -U llm-gemini
llm keys set gemini
# Paste API key here
llm -m gemini-1.5-flash-8b-latest "say hi"
Solving a bug with o1-preview, files-to-prompt and LLM.
I added a new feature to DJP this morning: you can now have plugins specify their middleware in terms of how it should be positioned relative to other middleware - inserted directly before or directly after django.middleware.common.CommonMiddleware for example.
At one point I got stuck with a weird test failure, and after ten minutes of head scratching I decided to pipe the entire thing into OpenAI's o1-preview to see if it could spot the problem. I used files-to-prompt to gather the code and LLM to run the prompt:
files-to-prompt **/*.py -c | llm -m o1-preview "
The middleware test is failing showing all of these - why is MiddlewareAfter repeated so many times?
['MiddlewareAfter', 'Middleware3', 'MiddlewareAfter', 'Middleware5', 'MiddlewareAfter', 'Middleware3', 'MiddlewareAfter', 'Middleware2', 'MiddlewareAfter', 'Middleware3', 'MiddlewareAfter', 'Middleware5', 'MiddlewareAfter', 'Middleware3', 'MiddlewareAfter', 'Middleware4', 'MiddlewareAfter', 'Middleware3', 'MiddlewareAfter', 'Middleware5', 'MiddlewareAfter', 'Middleware3', 'MiddlewareAfter', 'Middleware2', 'MiddlewareAfter', 'Middleware3', 'MiddlewareAfter', 'Middleware5', 'MiddlewareAfter', 'Middleware3', 'MiddlewareAfter', 'Middleware', 'MiddlewareBefore']"The model whirled away for a few seconds and spat out an explanation of the problem - one of my middleware classes was accidentally calling self.get_response(request) in two different places.
I did enjoy how o1 attempted to reference the relevant Django documentation and then half-repeated, half-hallucinated a quote from it:

This took 2,538 input tokens and 4,354 output tokens - by my calculations at $15/million input and $60/million output that prompt cost just under 30 cents.
LLM 0.16.
New release of LLM adding support for the o1-preview and o1-mini OpenAI models that were released today.
LLM 0.15. A new release of my LLM CLI tool for interacting with Large Language Models from the terminal (see this recent talk for plenty of demos).
This release adds support for the brand new GPT-4o mini:
llm -m gpt-4o-mini "rave about pelicans in Spanish"
It also sets that model as the default used by the tool if no other model is specified. This replaces GPT-3.5 Turbo, the default since the first release of LLM. 4o-mini is both cheaper and way more capable than 3.5 Turbo.
LLM 0.14, with support for GPT-4o. It's been a while since the last LLM release. This one adds support for OpenAI's new model:
llm -m gpt-4o "fascinate me"
Also a new llm logs -r (or --response) option for getting back just the response from your last prompt, without wrapping it in Markdown that includes the prompt.
Plus nine new plugins since 0.13!
LLM 0.11. I released LLM 0.11 with support for the new gpt-3.5-turbo-instruct completion model from OpenAI.
The most interesting feature of completion models is the option to request “log probabilities” from them, where each token returned is accompanied by up to 5 alternatives that were considered, along with their scores.