February 2026
173 posts: 10 entries, 47 links, 21 quotes, 13 notes, 76 beats, 6 chapters
Feb. 7, 2026
How StrongDM’s AI team build serious software without even looking at the code
Last week I hinted at a demo I had seen from a team implementing what Dan Shapiro called the Dark Factory level of AI adoption, where no human even looks at the code the coding agents are producing. That team was part of StrongDM, and they’ve just shared the first public description of how they are working in Software Factories and the Agentic Moment:
[... 1,664 words]I am having more fun programming than I ever have, because so many more of the programs I wish I could find the time to write actually exist. I wish I could share this joy with the people who are fearful about the changes agents are bringing. The fear itself I understand, I have fear more broadly about what the end-game is for intelligence on tap in our society. But in the limited domain of writing computer programs these tools have brought so much exploration and joy to my work.
— David Crawshaw, Eight more months of agents
Claude: Speed up responses with fast mode.
New "research preview" from Anthropic today: you can now access a faster version of their frontier model Claude Opus 4.6 by typing /fast in Claude Code... but at a cost that's 6x the normal price.
Opus is usually $5/million input and $25/million output. The new fast mode is $30/million input and $150/million output!
There's a 50% discount until the end of February 16th, so only a 3x multiple (!) before then.
How much faster is it? The linked documentation doesn't say, but on Twitter Claude say:
Our teams have been building with a 2.5x-faster version of Claude Opus 4.6.
We’re now making it available as an early experiment via Claude Code and our API.
Claude Opus 4.5 had a context limit of 200,000 tokens. 4.6 has an option to increase that to 1,000,000 at 2x the input price ($10/m) and 1.5x the output price ($37.50/m) once your input exceeds 200,000 tokens. These multiples hold for fast mode too, so after Feb 16th you'll be able to pay a hefty $60/m input and $225/m output for Anthropic's fastest best model.
Vouch. Mitchell Hashimoto's new system to help address the deluge of worthless AI-generated PRs faced by open source projects now that the friction involved in contributing has dropped so low.
The idea is simple: Unvouched users can't contribute to your projects. Very bad users can be explicitly "denounced", effectively blocked. Users are vouched or denounced by contributors via GitHub issue or discussion comments or via the CLI.
Integration into GitHub is as simple as adopting the published GitHub actions. Done. Additionally, the system itself is generic to forges and not tied to GitHub in any way.
Who and how someone is vouched or denounced is up to the project. I'm not the value police for the world. Decide for yourself what works for your project and your community.
Feb. 8, 2026
People on the orange site are laughing at this, assuming it's just an ad and that there's nothing to it. Vulnerability researchers I talk to do not think this is a joke. As an erstwhile vuln researcher myself: do not bet against LLMs on this.
Axios: Anthropic's Claude Opus 4.6 uncovers 500 zero-day flaws in open-source
I think vulnerability research might be THE MOST LLM-amenable software engineering problem. Pattern-driven. Huge corpus of operational public patterns. Closed loops. Forward progress from stimulus/response tooling. Search problems.
Vulnerability research outcomes are in THE MODEL CARDS for frontier labs. Those companies have so much money they're literally distorting the economy. Money buys vuln research outcomes. Why would you think they were faking any of this?
Friend and neighbour Karen James made me a Kākāpō mug. It has a charismatic Kākāpō, four Kākāpō chicks (in celebration of the 2026 breeding season) and even has some rimu fruit!


I love it so much.
Feb. 9, 2026
AI Doesn’t Reduce Work—It Intensifies It (via) Aruna Ranganathan and Xingqi Maggie Ye from Berkeley Haas School of Business report initial findings in the HBR from their April to December 2025 study of 200 employees at a "U.S.-based technology company".
This captures an effect I've been observing in my own work with LLMs: the productivity boost these things can provide is exhausting.
AI introduced a new rhythm in which workers managed several active threads at once: manually writing code while AI generated an alternative version, running multiple agents in parallel, or reviving long-deferred tasks because AI could “handle them” in the background. They did this, in part, because they felt they had a “partner” that could help them move through their workload.
While this sense of having a “partner” enabled a feeling of momentum, the reality was a continual switching of attention, frequent checking of AI outputs, and a growing number of open tasks. This created cognitive load and a sense of always juggling, even as the work felt productive.
I'm frequently finding myself with work on two or three projects running parallel. I can get so much done, but after just an hour or two my mental energy for the day feels almost entirely depleted.
I've had conversations with people recently who are losing sleep because they're finding building yet another feature with "just one more prompt" irresistible.
The HBR piece calls for organizations to build an "AI practice" that structures how AI is used to help avoid burnout and counter effects that "make it harder for organizations to distinguish genuine productivity gains from unsustainable intensity".
I think we've just disrupted decades of existing intuition about sustainable working practices. It's going to take a while and some discipline to find a good new balance.
Structured Context Engineering for File-Native Agentic Systems (via) New paper by Damon McMillan exploring challenging LLM context tasks involving large SQL schemas (up to 10,000 tables) across different models and file formats:
Using SQL generation as a proxy for programmatic agent operations, we present a systematic study of context engineering for structured data, comprising 9,649 experiments across 11 models, 4 formats (YAML, Markdown, JSON, Token-Oriented Object Notation [TOON]), and schemas ranging from 10 to 10,000 tables.
Unsurprisingly, the biggest impact was the models themselves - with frontier models (Opus 4.5, GPT-5.2, Gemini 2.5 Pro) beating the leading open source models (DeepSeek V3.2, Kimi K2, Llama 4).
Those frontier models benefited from filesystem based context retrieval, but the open source models had much less convincing results with those, which reinforces my feeling that the filesystem coding agent loops aren't handled as well by open weight models just yet. The Terminal Bench 2.0 leaderboard is still dominated by Anthropic, OpenAI and Gemini.
The "grep tax" result against TOON was an interesting detail. TOON is meant to represent structured data in as few tokens as possible, but it turns out the model's unfamiliarity with that format led to them spending significantly more tokens over multiple iterations trying to figure it out:
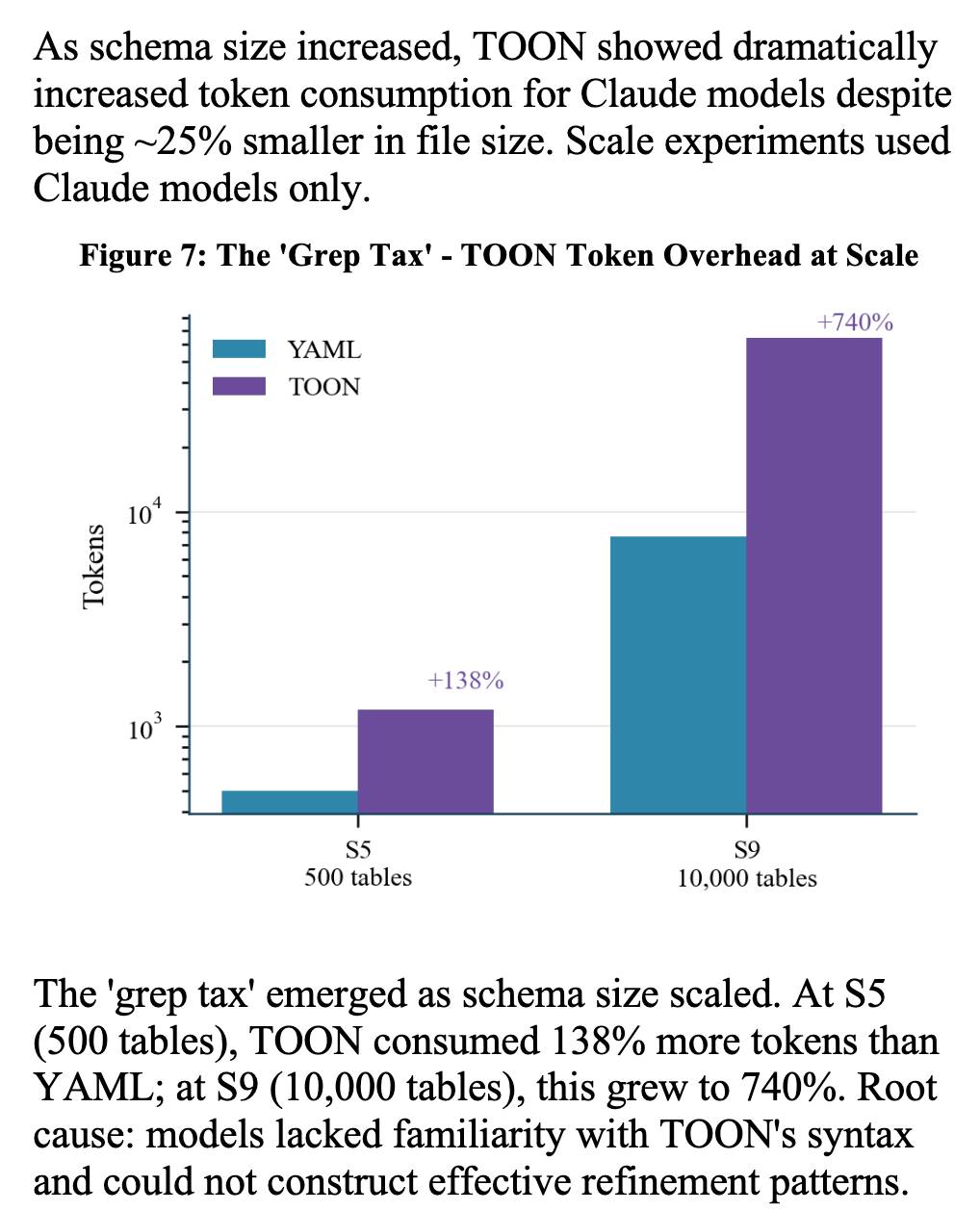
Feb. 10, 2026
Introducing Showboat and Rodney, so agents can demo what they’ve built
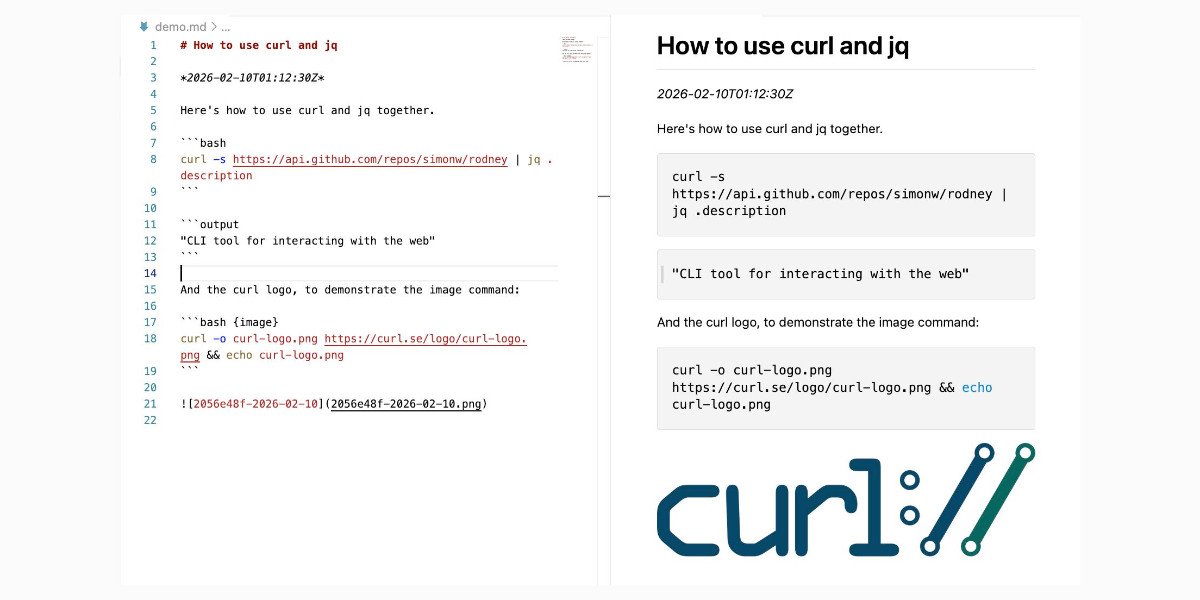
A key challenge working with coding agents is having them both test what they’ve built and demonstrate that software to you, their supervisor. This goes beyond automated tests—we need artifacts that show their progress and help us see exactly what the agent-produced software is able to do. I’ve just released two new tools aimed at this problem: Showboat and Rodney.
[... 2,023 words]Feb. 11, 2026
cysqlite—a new sqlite driver
(via)
Charles Leifer has been maintaining pysqlite3 - a fork of the Python standard library's sqlite3 module that makes it much easier to run upgraded SQLite versions - since 2018.
He's been working on a ground-up Cython rewrite called cysqlite for almost as long, but it's finally at a stage where it's ready for people to try out.
The biggest change from the sqlite3 module involves transactions. Charles explains his discomfort with the sqlite3 implementation at length - that library provides two different variants neither of which exactly match the autocommit mechanism in SQLite itself.
I'm particularly excited about the support for custom virtual tables, a feature I'd love to see in sqlite3 itself.
cysqlite provides a Python extension compiled from C, which means it normally wouldn't be available in Pyodide. I set Claude Code on it (here's the prompt) and it built me cysqlite-0.1.4-cp311-cp311-emscripten_3_1_46_wasm32.whl, a 688KB wheel file with a WASM build of the library that can be loaded into Pyodide like this:
import micropip await micropip.install( "https://simonw.github.io/research/cysqlite-wasm-wheel/cysqlite-0.1.4-cp311-cp311-emscripten_3_1_46_wasm32.whl" ) import cysqlite print(cysqlite.connect(":memory:").execute( "select sqlite_version()" ).fetchone())
(I also learned that wheels like this have to be built for the emscripten version used by that edition of Pyodide - my experimental wheel loads in Pyodide 0.25.1 but fails in 0.27.5 with a Wheel was built with Emscripten v3.1.46 but Pyodide was built with Emscripten v3.1.58 error.)
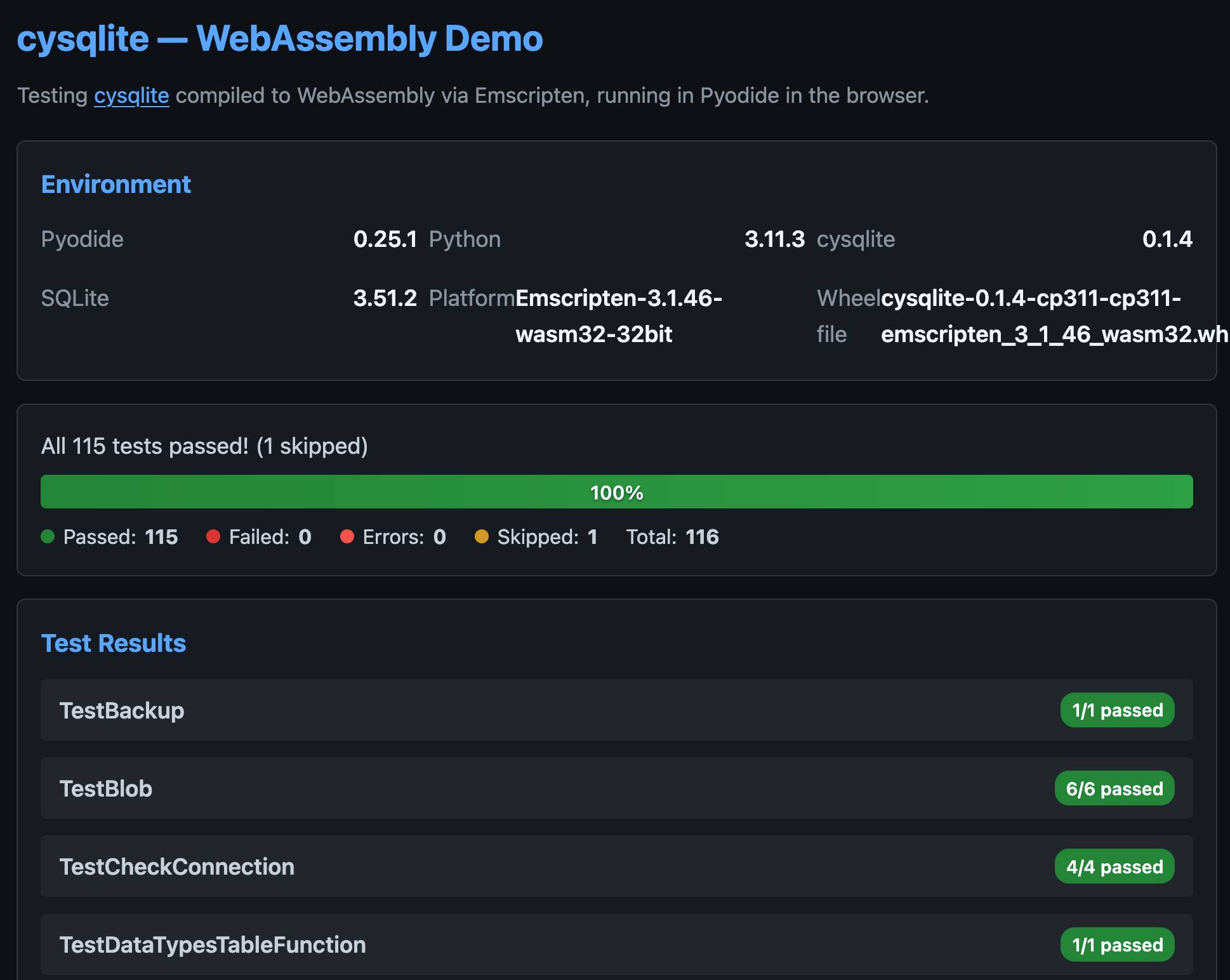
You can try my wheel in this new Pyodide REPL i had Claude build as a mobile-friendly alternative to Pyodide's own hosted console.
I also had Claude build this demo page that executes the original test suite in the browser and displays the results:
GLM-5: From Vibe Coding to Agentic Engineering (via) This is a huge new MIT-licensed model: 744B parameters and 1.51TB on Hugging Face twice the size of GLM-4.7 which was 368B and 717GB (4.5 and 4.6 were around that size too).
It's interesting to see Z.ai take a position on what we should call professional software engineers building with LLMs - I've seen Agentic Engineering show up in a few other places recently. most notable from Andrej Karpathy and Addy Osmani.
I ran my "Generate an SVG of a pelican riding a bicycle" prompt through GLM-5 via OpenRouter and got back a very good pelican on a disappointing bicycle frame:
