14 posts tagged “parquet”
2025
An MVCC-like columnar table on S3 with constant-time deletes (via) s3's support for conditional writes (previously) makes it an interesting, scalable and often inexpensive platform for all kinds of database patterns.
Shayon Mukherjee presents an ingenious design for a Parquet-backed database in S3 which accepts concurrent writes, presents a single atomic view for readers and even supports reliable row deletion despite Parquet requiring a complete file rewrite in order to remove data.
The key to the design is a _latest_manifest JSON file at the top of the bucket, containing an integer version number. Clients use compare-and-swap to increment that version - only one client can succeed at this, so the incremented version they get back is guaranteed unique to them.
Having reserved a version number the client can write a unique manifest file for that version - manifest/v00000123.json - with a more complex data structure referencing the current versions of every persisted file, including the one they just uploaded.
Deleted rows are written to tombstone files as either a list of primary keys or a list of of ranges. Clients consult these when executing reads, filtering out deleted rows as part of resolving a query.
The pricing estimates are especially noteworthy:
For a workload ingesting 6 TB/day with 2 TB of deletes and 50K queries/day:
- PUT requests: ~380K/day (≈4 req/s) = $1.88/day
- GET requests: highly variable, depends on partitioning effectiveness
- Best case (good time-based partitioning): ~100K-200K/day = $0.04-$0.08/day
- Worst case (poor partitioning, scanning many files): ~2M/day = $0.80/day
~$3/day for ingesting 6TB of data is pretty fantastic!
Watch out for storage costs though - each new TB of data at $0.023/GB/month adds $23.55 to the ongoing monthly bill.
OpenTimes (via) Spectacular new open geospatial project by Dan Snow:
OpenTimes is a database of pre-computed, point-to-point travel times between United States Census geographies. It lets you download bulk travel time data for free and with no limits.
Here's what I get for travel times by car from El Granada, California:
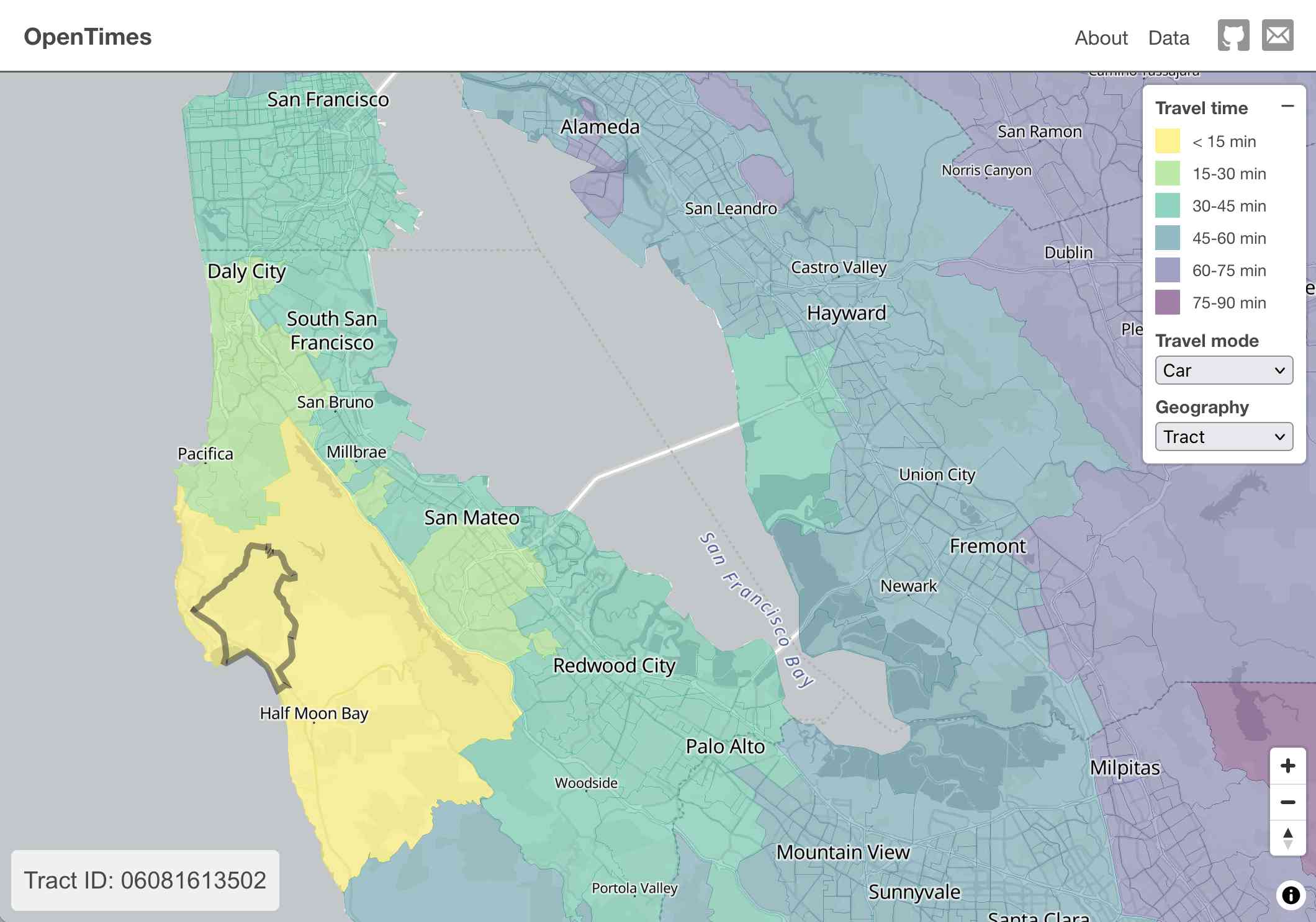
The technical details are fascinating:
- The entire OpenTimes backend is just static Parquet files on Cloudflare's R2. There's no RDBMS or running service, just files and a CDN. The whole thing costs about $10/month to host and costs nothing to serve. In my opinion, this is a great way to serve infrequently updated, large public datasets at low cost (as long as you partition the files correctly).
Sure enough, R2 pricing charges "based on the total volume of data stored" - $0.015 / GB-month for standard storage, then $0.36 / million requests for "Class B" operations which include reads. They charge nothing for outbound bandwidth.
- All travel times were calculated by pre-building the inputs (OSM, OSRM networks) and then distributing the compute over hundreds of GitHub Actions jobs. This worked shockingly well for this specific workload (and was also completely free).
Here's a GitHub Actions run of the calculate-times.yaml workflow which uses a matrix to run 255 jobs!
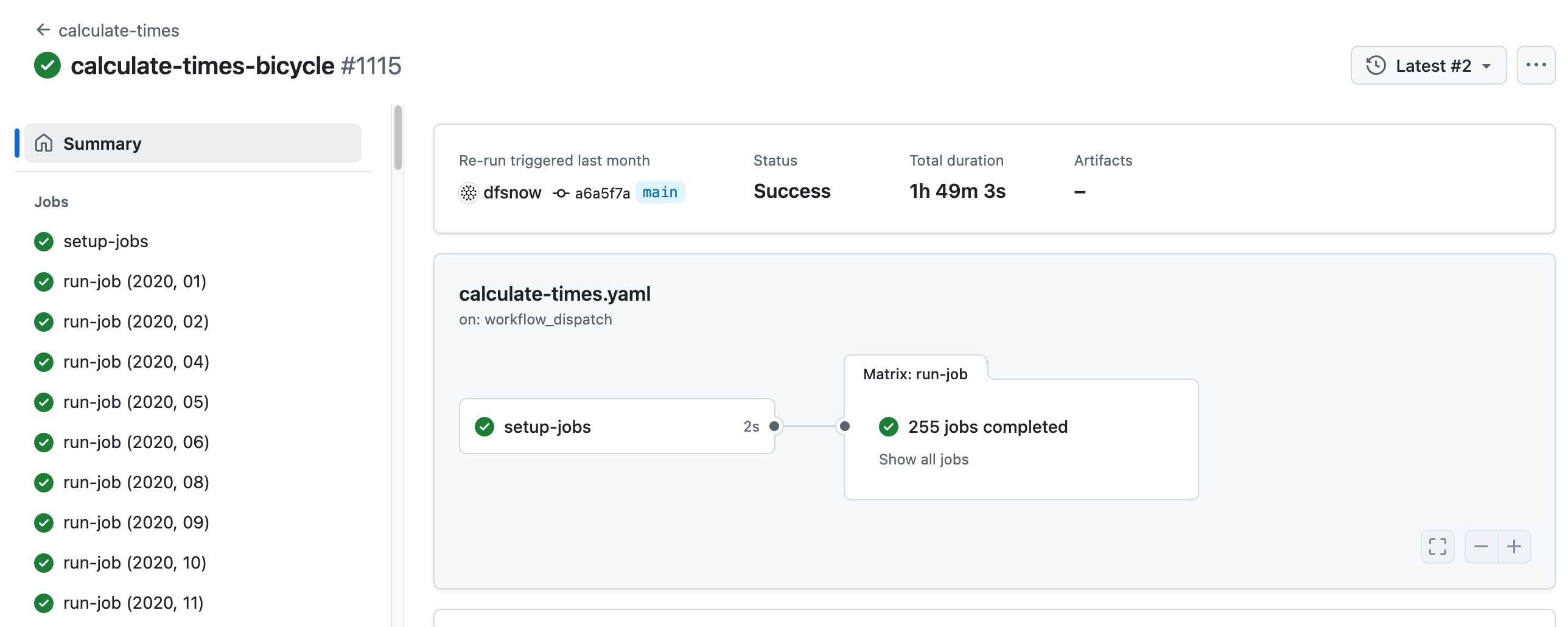
Relevant YAML:
matrix:
year: ${{ fromJSON(needs.setup-jobs.outputs.years) }}
state: ${{ fromJSON(needs.setup-jobs.outputs.states) }}
Where those JSON files were created by the previous step, which reads in the year and state values from this params.yaml file.
- The query layer uses a single DuckDB database file with views that point to static Parquet files via HTTP. This lets you query a table with hundreds of billions of records after downloading just the ~5MB pointer file.
This is a really creative use of DuckDB's feature that lets you run queries against large data from a laptop using HTTP range queries to avoid downloading the whole thing.
The README shows how to use that from R and Python - I got this working in the duckdb client (brew install duckdb):
INSTALL httpfs;
LOAD httpfs;
ATTACH 'https://data.opentimes.org/databases/0.0.1.duckdb' AS opentimes;
SELECT origin_id, destination_id, duration_sec
FROM opentimes.public.times
WHERE version = '0.0.1'
AND mode = 'car'
AND year = '2024'
AND geography = 'tract'
AND state = '17'
AND origin_id LIKE '17031%' limit 10;
In answer to a question about adding public transit times Dan said:
In the next year or so maybe. The biggest obstacles to adding public transit are:
- Collecting all the necessary scheduling data (e.g. GTFS feeds) for every transit system in the county. Not insurmountable since there are services that do this currently.
- Finding a routing engine that can compute nation-scale travel time matrices quickly. Currently, the two fastest open-source engines I've tried (OSRM and Valhalla) don't support public transit for matrix calculations and the engines that do support public transit (R5, OpenTripPlanner, etc.) are too slow.
GTFS is a popular CSV-based format for sharing transit schedules - here's an official list of available feed directories.
This whole project feels to me like a great example of the baked data architectural pattern in action.
The Best Way to Use Text Embeddings Portably is With Parquet and Polars. Fantastic piece on embeddings by Max Woolf, who uses a 32,000 vector collection of Magic: the Gathering card embeddings to explore efficient ways of storing and processing them.
Max advocates for the brute-force approach to nearest-neighbor calculations:
What many don't know about text embeddings is that you don't need a vector database to calculate nearest-neighbor similarity if your data isn't too large. Using numpy and my Magic card embeddings, a 2D matrix of 32,254
float32embeddings at a dimensionality of 768D (common for "smaller" LLM embedding models) occupies 94.49 MB of system memory, which is relatively low for modern personal computers and can fit within free usage tiers of cloud VMs.
He uses this brilliant snippet of Python code to find the top K matches by distance:
def fast_dot_product(query, matrix, k=3): dot_products = query @ matrix.T idx = np.argpartition(dot_products, -k)[-k:] idx = idx[np.argsort(dot_products[idx])[::-1]] score = dot_products[idx] return idx, score
Since dot products are such a fundamental aspect of linear algebra, numpy's implementation is extremely fast: with the help of additional numpy sorting shenanigans, on my M3 Pro MacBook Pro it takes just 1.08 ms on average to calculate all 32,254 dot products, find the top 3 most similar embeddings, and return their corresponding
idxof the matrix and and cosine similarityscore.
I ran that Python code through Claude 3.7 Sonnet for an explanation, which I can share here using their brand new "Share chat" feature. TIL about numpy.argpartition!
He explores multiple options for efficiently storing these embedding vectors, finding that naive CSV storage takes 631.5 MB while pickle uses 94.49 MB and his preferred option, Parquet via Polars, uses 94.3 MB and enables some neat zero-copy optimization tricks.
S1: The $6 R1 Competitor? Tim Kellogg shares his notes on a new paper, s1: Simple test-time scaling, which describes an inference-scaling model fine-tuned on top of Qwen2.5-32B-Instruct for just $6 - the cost for 26 minutes on 16 NVIDIA H100 GPUs.
Tim highlight the most exciting result:
After sifting their dataset of 56K examples down to just the best 1K, they found that the core 1K is all that's needed to achieve o1-preview performance on a 32B model.
The paper describes a technique called "Budget forcing":
To enforce a minimum, we suppress the generation of the end-of-thinking token delimiter and optionally append the string “Wait” to the model’s current reasoning trace to encourage the model to reflect on its current generation
That's the same trick Theia Vogel described a few weeks ago.
Here's the s1-32B model on Hugging Face. I found a GGUF version of it at brittlewis12/s1-32B-GGUF, which I ran using Ollama like so:
ollama run hf.co/brittlewis12/s1-32B-GGUF:Q4_0
I also found those 1,000 samples on Hugging Face in the simplescaling/s1K data repository there.
I used DuckDB to convert the parquet file to CSV (and turn one VARCHAR[] column into JSON):
COPY (
SELECT
solution,
question,
cot_type,
source_type,
metadata,
cot,
json_array(thinking_trajectories) as thinking_trajectories,
attempt
FROM 's1k-00001.parquet'
) TO 'output.csv' (HEADER, DELIMITER ',');
Then I loaded that CSV into sqlite-utils so I could use the convert command to turn a Python data structure into JSON using json.dumps() and eval():
# Load into SQLite
sqlite-utils insert s1k.db s1k output.csv --csv
# Fix that column
sqlite-utils convert s1k.db s1u metadata 'json.dumps(eval(value))' --import json
# Dump that back out to CSV
sqlite-utils rows s1k.db s1k --csv > s1k.csv
Here's that CSV in a Gist, which means I can load it into Datasette Lite.
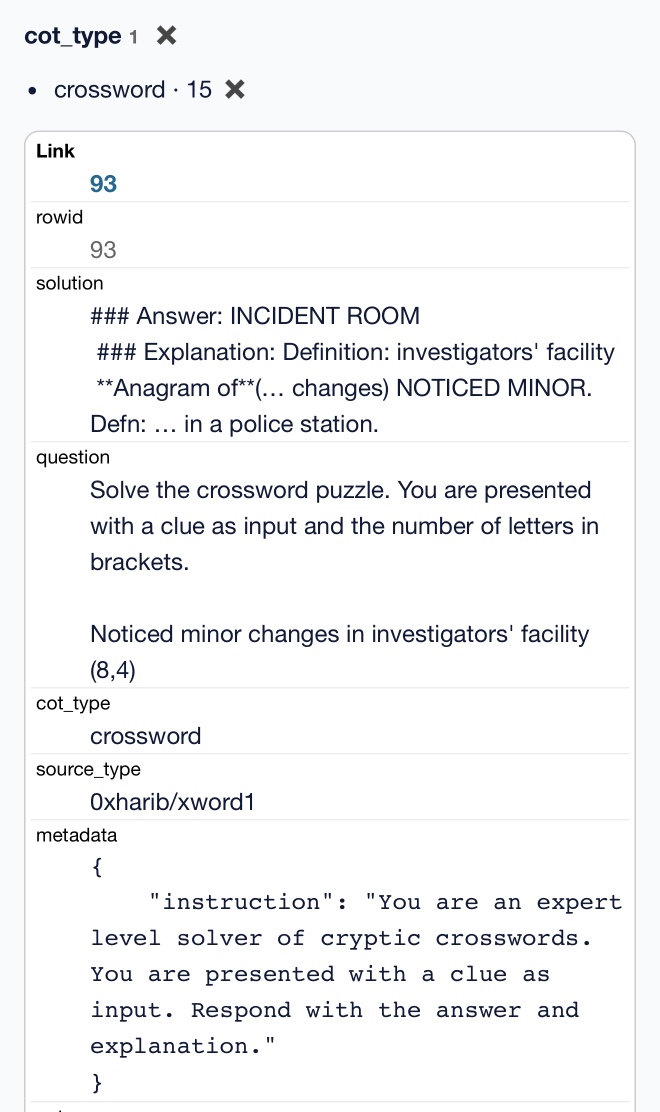
It really is a tiny amount of training data. It's mostly math and science, but there are also 15 cryptic crossword examples.
2024
Foursquare Open Source Places: A new foundational dataset for the geospatial community (via) I did not expect this!
[...] we are announcing today the general availability of a foundational open data set, Foursquare Open Source Places ("FSQ OS Places"). This base layer of 100mm+ global places of interest ("POI") includes 22 core attributes (see schema here) that will be updated monthly and available for commercial use under the Apache 2.0 license framework.
The data is available as Parquet files hosted on Amazon S3.
Here's how to list the available files:
aws s3 ls s3://fsq-os-places-us-east-1/release/dt=2024-11-19/places/parquet/
I got back places-00000.snappy.parquet through places-00024.snappy.parquet, each file around 455MB for a total of 10.6GB of data.
I ran duckdb and then used DuckDB's ability to remotely query Parquet on S3 to explore the data a bit more without downloading it to my laptop first:
select count(*) from 's3://fsq-os-places-us-east-1/release/dt=2024-11-19/places/parquet/places-00000.snappy.parquet';
This got back 4,180,424 - that number is similar for each file, suggesting around 104,000,000 records total.
Update: DuckDB can use wildcards in S3 paths (thanks, Paul) so this query provides an exact count:
select count(*) from 's3://fsq-os-places-us-east-1/release/dt=2024-11-19/places/parquet/places-*.snappy.parquet';
That returned 104,511,073 - and Activity Monitor on my Mac confirmed that DuckDB only needed to fetch 1.2MB of data to answer that query.
I ran this query to retrieve 1,000 places from that first file as newline-delimited JSON:
copy (
select * from 's3://fsq-os-places-us-east-1/release/dt=2024-11-19/places/parquet/places-00000.snappy.parquet'
limit 1000
) to '/tmp/places.json';
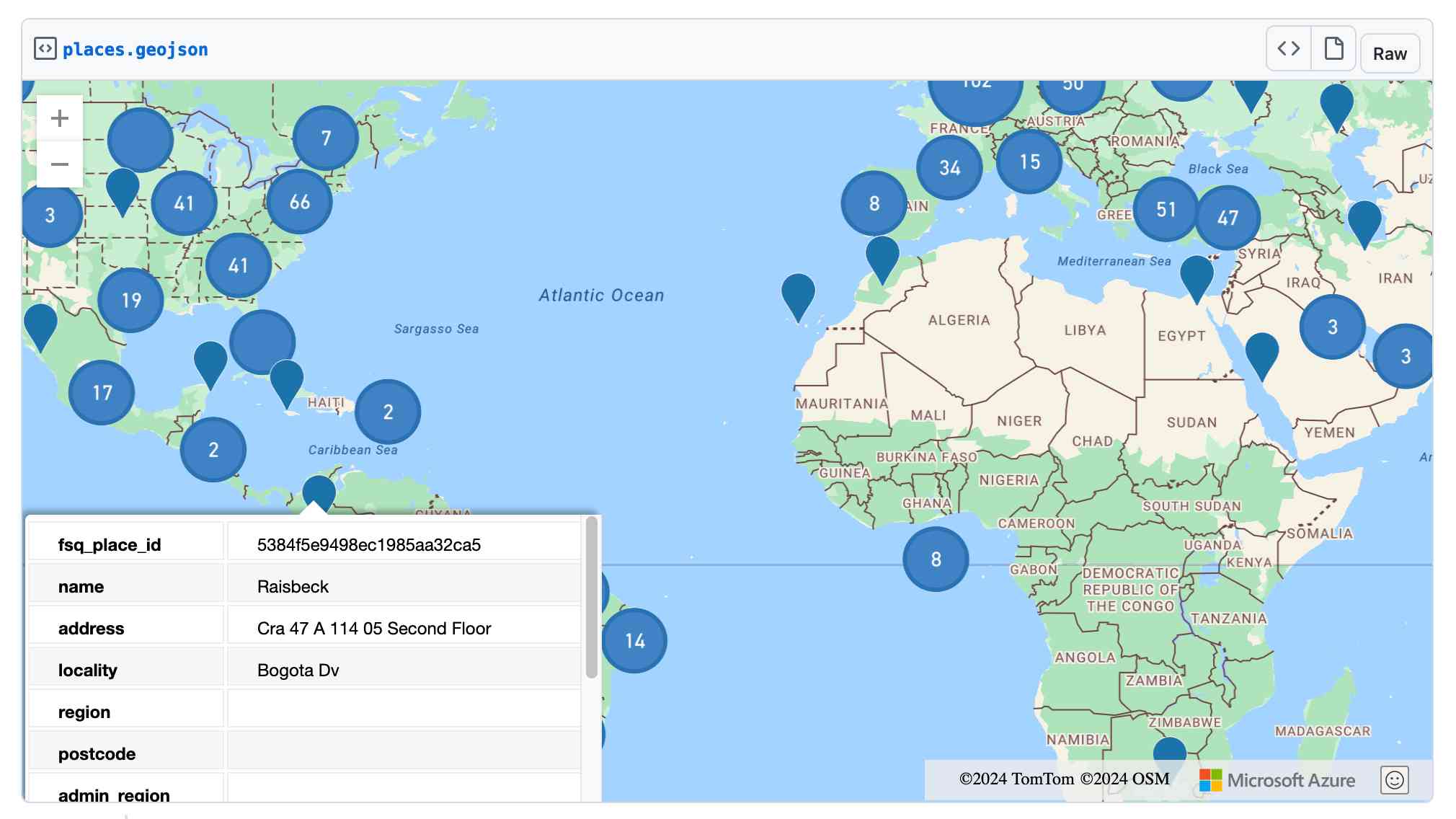
Here's that places.json file, and here it is imported into Datasette Lite.
Finally, I got ChatGPT Code Interpreter to convert that file to GeoJSON and pasted the result into this Gist, giving me a map of those thousand places (because Gists automatically render GeoJSON):
Using DuckDB for Embeddings and Vector Search (via) Sören Brunk's comprehensive tutorial combining DuckDB 1.0, a subset of German Wikipedia from Hugging Face (loaded using Parquet), the BGE M3 embedding model and DuckDB's new vss extension for implementing an HNSW vector index.
2023
Fleet Context. This project took the source code and documentation for 1221 popular Python libraries and ran them through the OpenAI text-embedding-ada-002 embedding model, then made those pre-calculated embedding vectors available as Parquet files for download from S3 or via a custom Python CLI tool.
I haven’t seen many projects release pre-calculated embeddings like this, it’s an interesting initiative.
Overture Maps Foundation Releases Its First World-Wide Open Map Dataset. The Overture Maps Foundation is a collaboration lead by Amazon, Meta, Microsoft and TomTom dedicated to producing “reliable, easy-to-use, and interoperable open map data”.
Yesterday they put out their first release and it’s pretty astonishing: four different layers of geodata, covering Places of Interest (shops, restaurants, attractions etc), administrative boundaries, building outlines and transportation networks.
The data is available as Parquet. I just downloaded the 8GB places dataset and can confirm that it contains 59 million listings from around the world—I filtered to just places in my local town and a spot check showed that recently opened businesses (last 12 months) were present and the details all looked accurate.
The places data is licensed under “Community Data License Agreement – Permissive” which looks like the only restriction is that you have to include that license when you further share the data.
Weeknotes: Parquet in Datasette Lite, various talks, more LLM hacking
I’ve fallen a bit behind on my weeknotes. Here’s a catchup for the last few weeks.
[... 769 words]2022
Exploring the training data behind Stable Diffusion
Two weeks ago, the Stable Diffusion image generation model was released to the public. I wrote about this last week, in Stable Diffusion is a really big deal—a post which has since become one of the top ten results for “stable diffusion” on Google and shown up in all sorts of different places online.
[... 2,897 words]2021
DuckDB-Wasm: Efficient Analytical SQL in the Browser (via) First SQLite, now DuckDB: options for running database engines in the browser using WebAssembly keep on growing. DuckDB means browsers now have a fast, intuitive mechanism for querying Parquet files too. This also supports the same HTTP Range header trick as the SQLite demo from a while back, meaning it can query large databases loaded over HTTP without downloading the whole file.
Querying Parquet using DuckDB (via) DuckDB is a relatively new SQLite-style database (released as an embeddable library) with a focus on analytical queries. This tutorial really made the benefits click for me: it ships with support for the Parquet columnar data format, and you can use it to execute SQL queries directly against Parquet files—e.g. “SELECT COUNT(*) FROM ’taxi_2019_04.parquet’”. Performance against large files is fantastic, and the whole thing can be installed just using “pip install duckdb”. I wonder if faceting-style group/count queries (pretty expensive with regular RDBMSs) could be sped up with this?
2019
athena-sqlite (via) Amazon Athena is the AWS tool for querying data stored in S3—as CSV, JSON or Apache Parquet files—using SQL. It’s an interesting way of buliding a very cheap data warehouse on top of S3 without having to run any additional services. Athena recently added a query federation SDK which lets you define additional custom data sources using Lambda functions. Damon Cortesi used this to write a custom connector for SQLite, which lets you run queries against data stored in SQLite files that you have uploaded to S3. You can then run joins between that data and other Athena sources.
2018
Query Parquet files in SQLite. Colin Dellow built a SQLite virtual table extension that lets you query Parquet files directly using SQL. Parquet is interesting because it’s a columnar format that dramatically reduces the space needed to store tables with lots of duplicate column data—most CSV files, for example. Colin reports being able to shrink a 1291 MB CSV file from the Canadian census to an equivalent Parquet file weighing just 42MB (3% of the original)—then running a complex query against the data in just 60ms. I’d love to see someone get this extension working with Datasette.