20 posts tagged “lm-studio”
LM Studio is a desktop application for running local LLMs.
2026
Ornith-1.0: Self-Scaffolding LLMs for Agentic Coding. This is an interesting new open weights (MIT licensed) model, the first model release from DeepReinforce.
[...] with variants including 9B Dense, 31B Dense, 35B MoE, and 397B MoE. Built on top of pretrained Gemma 4 and Qwen 3.5, it achieves state-of-the-art performance among open-source models of comparable size on coding benchmarks.
As far as I can tell the licenses of those underlying models is compatible with being used in this way - Gemma 4 is Apache 2.0 licensed (and not bound by the janky additional Gemma Terms of Use that afflicted the previous Gemma models) and Qwen 3.5 is Apache 2.0 licensed as well.
I've been running the model using LM Studio and the ornith-1.0-35b-Q4_K_M.gguf (20GB) GGUF, hooked up to Pi. Initial impressions are very good - it seems to be able to run the agent harness over many tool calls in a proficient way.
Here's a terminal session where I asked it to "find the code that decodes the actor cookie" and then "find the code that opens the insert dialog when thebutton is clicked" against a Datasette checkout, which it handled with ease.
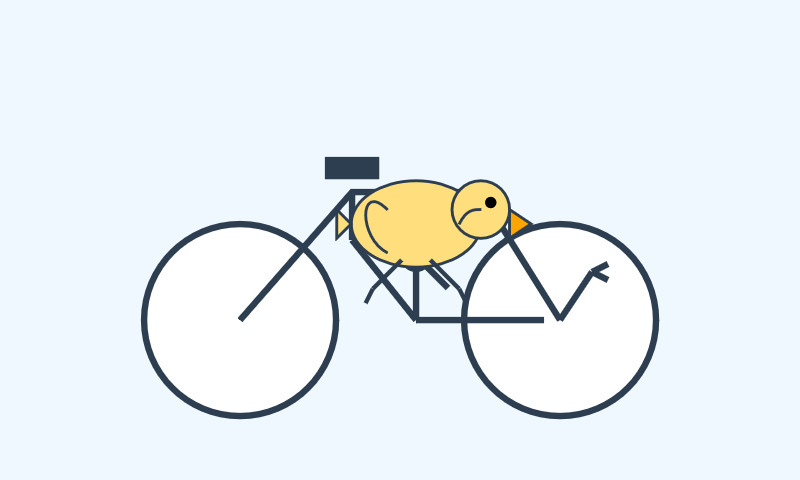
I also had it draw this pelican, which came out at 103 tokens/second:

It's a little bit mangled but the pelican is clearly a pelican.
I couldn't find much information about DeepReinforce themselves. The earliest paper I could find from the was CUDA-L1: Improving CUDA Optimization via Contrastive Reinforcement Learning from June 2025.
Qwen3.6-35B-A3B on my laptop drew me a better pelican than Claude Opus 4.7
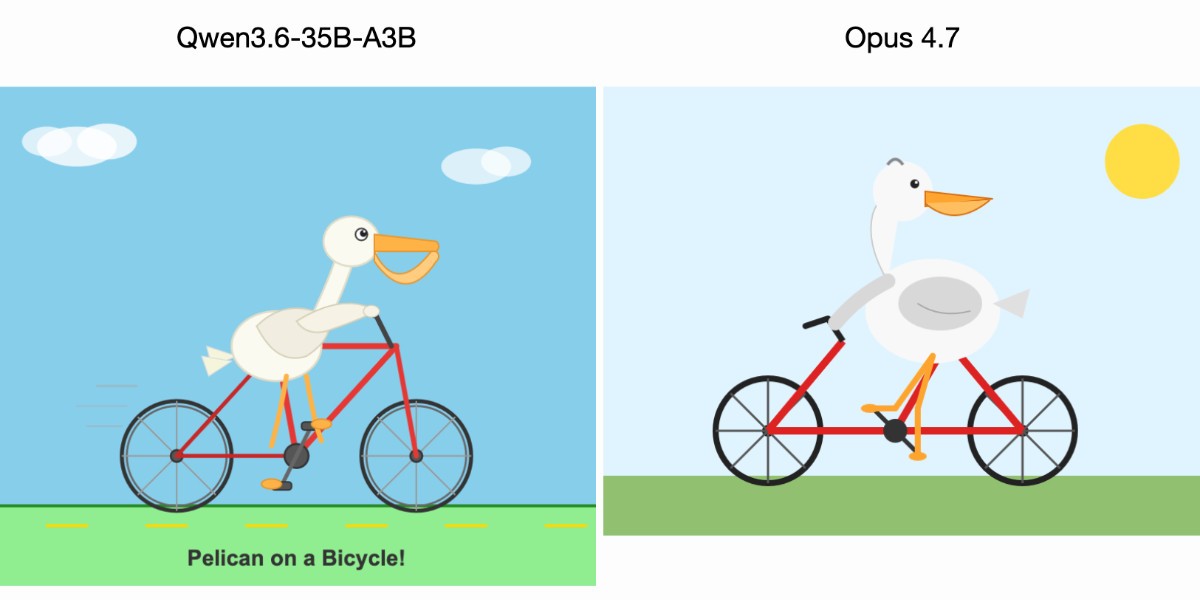
For anyone who has been (inadvisably) taking my pelican riding a bicycle benchmark seriously as a robust way to test models, here are pelicans from this morning’s two big model releases—Qwen3.6-35B-A3B from Alibaba and Claude Opus 4.7 from Anthropic.
[... 602 words]Gemma 4: Byte for byte, the most capable open models. Four new vision-capable Apache 2.0 licensed reasoning LLMs from Google DeepMind, sized at 2B, 4B, 31B, plus a 26B-A4B Mixture-of-Experts.
Google emphasize "unprecedented level of intelligence-per-parameter", providing yet more evidence that creating small useful models is one of the hottest areas of research right now.
They actually label the two smaller models as E2B and E4B for "Effective" parameter size. The system card explains:
The smaller models incorporate Per-Layer Embeddings (PLE) to maximize parameter efficiency in on-device deployments. Rather than adding more layers or parameters to the model, PLE gives each decoder layer its own small embedding for every token. These embedding tables are large but are only used for quick lookups, which is why the effective parameter count is much smaller than the total.
I don't entirely understand that, but apparently that's what the "E" in E2B means!
One particularly exciting feature of these models is that they are multi-modal beyond just images:
Vision and audio: All models natively process video and images, supporting variable resolutions, and excelling at visual tasks like OCR and chart understanding. Additionally, the E2B and E4B models feature native audio input for speech recognition and understanding.
I've not figured out a way to run audio input locally - I don't think that feature is in LM Studio or Ollama yet.
I tried them out using the GGUFs for LM Studio. The 2B (4.41GB), 4B (6.33GB) and 26B-A4B (17.99GB) models all worked perfectly, but the 31B (19.89GB) model was broken and spat out "---\n" in a loop for every prompt I tried.
The succession of pelican quality from 2B to 4B to 26B-A4B is notable:
E2B:
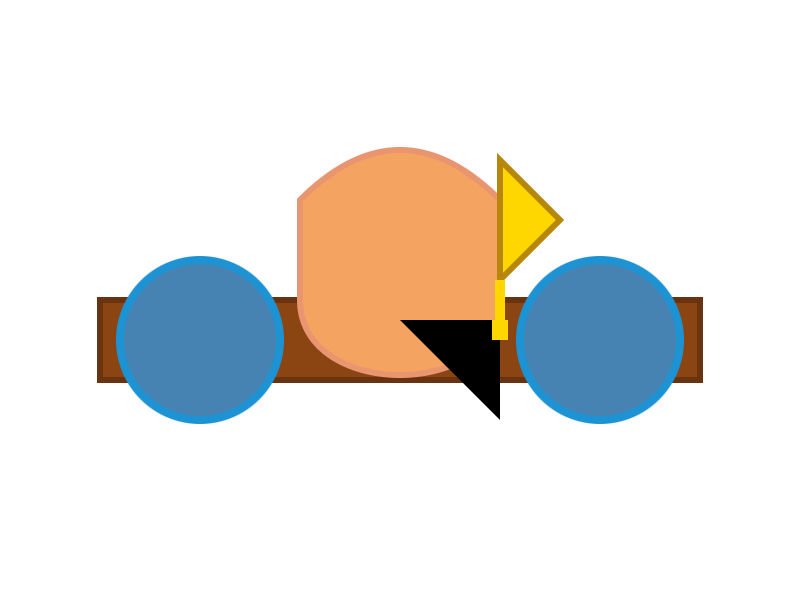
E4B:
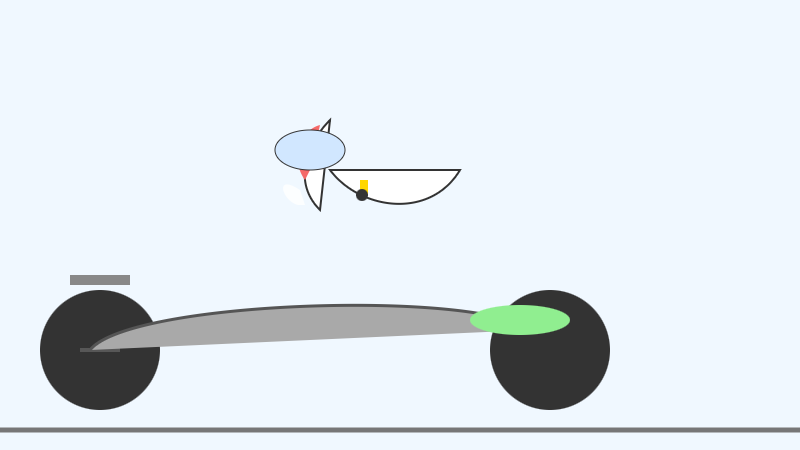
26B-A4B:

(This one actually had an SVG error - "error on line 18 at column 88: Attribute x1 redefined" - but after fixing that I got probably the best pelican I've seen yet from a model that runs on my laptop.)
Google are providing API access to the two larger Gemma models via their AI Studio. I added support to llm-gemini and then ran a pelican through the 31B model using that:
llm -m gemini/gemma-4-31b-it 'Generate an SVG of a pelican riding a bicycle'
Pretty good, though it is missing the front part of the bicycle frame:

2025
Olmo 3 is a fully open LLM
Olmo is the LLM series from Ai2—the Allen institute for AI. Unlike most open weight models these are notable for including the full training data, training process and checkpoints along with those releases.
[... 1,834 words]NVIDIA DGX Spark: great hardware, early days for the ecosystem

NVIDIA sent me a preview unit of their new DGX Spark desktop “AI supercomputer”. I’ve never had hardware to review before! You can consider this my first ever sponsored post if you like, but they did not pay me any cash and aside from an embargo date they did not request (nor would I grant) any editorial input into what I write about the device.
[... 1,846 words]TIL: Running a gpt-oss eval suite against LM Studio on a Mac. The other day I learned that OpenAI published a set of evals as part of their gpt-oss model release, described in their cookbook on Verifying gpt-oss implementations.
I decided to try and run that eval suite on my own MacBook Pro, against gpt-oss-20b running inside of LM Studio.
TLDR: once I had the model running inside LM Studio with a longer than default context limit, the following incantation ran an eval suite in around 3.5 hours:
mkdir /tmp/aime25_openai
OPENAI_API_KEY=x \
uv run --python 3.13 --with 'gpt-oss[eval]' \
python -m gpt_oss.evals \
--base-url http://localhost:1234/v1 \
--eval aime25 \
--sampler chat_completions \
--model openai/gpt-oss-20b \
--reasoning-effort low \
--n-threads 2
My new TIL breaks that command down in detail and walks through the underlying eval - AIME 2025, which asks 30 questions (8 times each) that are defined using the following format:
{"question": "Find the sum of all integer bases $b>9$ for which $17_{b}$ is a divisor of $97_{b}$.", "answer": "70"}
Introducing Gemma 3 270M: The compact model for hyper-efficient AI (via) New from Google:
Gemma 3 270M, a compact, 270-million parameter model designed from the ground up for task-specific fine-tuning with strong instruction-following and text structuring capabilities already trained in.
This model is tiny. The version I tried was the LM Studio GGUF one, a 241MB download.
It works! You can say "hi" to it and ask it very basic questions like "What is the capital of France".
I tried "Generate an SVG of a pelican riding a bicycle" about a dozen times and didn't once get back an SVG that was more than just a blank square... but at one point it did decide to write me this poem instead, which was nice:
+-----------------------+
| Pelican Riding Bike |
+-----------------------+
| This is the cat! |
| He's got big wings and a happy tail. |
| He loves to ride his bike! |
+-----------------------+
| Bike lights are shining bright. |
| He's got a shiny top, too! |
| He's ready for adventure! |
+-----------------------+
That's not really the point though. The Gemma 3 team make it very clear that the goal of this model is to support fine-tuning: a model this tiny is never going to be useful for general purpose LLM tasks, but given the right fine-tuning data it should be able to specialize for all sorts of things:
In engineering, success is defined by efficiency, not just raw power. You wouldn't use a sledgehammer to hang a picture frame. The same principle applies to building with AI.
Gemma 3 270M embodies this "right tool for the job" philosophy. It's a high-quality foundation model that follows instructions well out of the box, and its true power is unlocked through fine-tuning. Once specialized, it can execute tasks like text classification and data extraction with remarkable accuracy, speed, and cost-effectiveness. By starting with a compact, capable model, you can build production systems that are lean, fast, and dramatically cheaper to operate.
Here's their tutorial on Full Model Fine-Tune using Hugging Face Transformers, which I have not yet attempted to follow.
I imagine this model will be particularly fun to play with directly in a browser using transformers.js.
Update: It is! Here's a bedtime story generator using Transformers.js (requires WebGPU, so Chrome-like browsers only). Here's the source code for that demo.
Qwen3-4B-Thinking: “This is art—pelicans don’t ride bikes!”

I’ve fallen a few days behind keeping up with Qwen. They released two new 4B models last week: Qwen3-4B-Instruct-2507 and its thinking equivalent Qwen3-4B-Thinking-2507.
[... 991 words]OpenAI’s new open weight (Apache 2) models are really good
The long promised OpenAI open weight models are here, and they are very impressive. They’re available under proper open source licenses—Apache 2.0—and come in two sizes, 120B and 20B.
[... 2,771 words]XBai o4 (via) Yet another open source (Apache 2.0) LLM from a Chinese AI lab. This model card claims:
XBai o4 excels in complex reasoning capabilities and has now completely surpassed OpenAI-o3-mini in Medium mode.
This a 32.8 billion parameter model released by MetaStone AI, a new-to-me lab who released their first model in March - MetaStone-L1-7B, then followed that with MetaStone-S1 1.5B, 7B and 32B in July and now XBai o4 in August.
The MetaStone-S1 models were accompanied with a paper, Test-Time Scaling with Reflective Generative Model.
There is very little information available on the English-language web about MetaStone AI. Their paper shows a relationship with USTC, University of Science and Technology of China in Hefei. One of their researchers confirmed on Twitter that their CEO is from KWAI which lead me to this Chinese language article from July last year about Li Yan, formerly of KWAI and now the founder of Wen Xiaobai and evidently now the CEO of MetaStone. www.wenxiaobai.com is listed as the "official website" linked to from the XBai-o4 README on GitHub.
Ivan Fioravanti got it working under MLX in 4bit, 5bit, 6bit, 8bit and 4bit-DWQ sizes. I tried his 6bit one (a 24.81GB download) in LM Studio and had it "Generate an SVG of a pelican riding a bicycle". It thought for 39.49 seconds (thinking trace here) and gave me this:

I also had it "Write an HTML and JavaScript page implementing space invaders", which you can try out here. It's not great - the invaders don't fire bullets (it listed that as a "potential improvement") and I don't think it's winnable due to timing issues, but it's an interesting addition to my collection.
LM Studio reported a constant memory usage of 25.54GB and according to Activity Monitor used 87.5% of my GPU and around 39% of a CPU core.
It did a lot of work in the thinking trace - which took 10m35s! - including writing the first draft of much of the code that ended up in the finished result. Here's an extract:
Let me think of variables:
let enemyDirection = 1; // 1 for right, -1 for leftIn the game loop:
enemies.forEach(enemy => {> enemy.x += enemyDirection * enemy.dx;> });Then check if any enemy is out of bounds. If so, reverse direction and move all enemies down.But how to check if any enemy is at the edge?
Maybe find the max x of all enemies and see if it exceeds
canvas.width - enemy.width.Alternatively, track the leftmost and rightmost positions of enemies. Maybe a bit complex.
For simplicity, perhaps check if any enemy's
x + width > canvas.width or x < 0.
Here's the full transcript.
My initial impressions are that I'm not as impressed with this model for running on my own laptop as I was with Qwen3-Coder-30B-A3B-Instruct or GLM-4.5 Air.
But... how extraordinary is it that another Chinese AI lab has been able to produce a competitive model, this time with far less fanfare than we've seen from Qwen and Moonshot AI and Z.ai.
Trying out Qwen3 Coder Flash using LM Studio and Open WebUI and LLM
Qwen just released their sixth model(!) of this July called Qwen3-Coder-30B-A3B-Instruct—listed as Qwen3-Coder-Flash in their chat.qwen.ai interface.
[... 1,390 words]Qwen3-30B-A3B-Instruct-2507. New model update from Qwen, improving on their previous Qwen3-30B-A3B release from late April. In their tweet they said:
Smarter, faster, and local deployment-friendly.
✨ Key Enhancements:
✅ Enhanced reasoning, coding, and math skills
✅ Broader multilingual knowledge
✅ Improved long-context understanding (up to 256K tokens)
✅ Better alignment with user intent and open-ended tasks
✅ No more<think>blocks — now operating exclusively in non-thinking mode🔧 With 3B activated parameters, it's approaching the performance of GPT-4o and Qwen3-235B-A22B Non-Thinking
I tried the chat.qwen.ai hosted model with "Generate an SVG of a pelican riding a bicycle" and got this:

I particularly enjoyed this detail from the SVG source code:
<!-- Bonus: Pelican's smile -->
<path d="M245,145 Q250,150 255,145" fill="none" stroke="#d4a037" stroke-width="2"/>
I went looking for quantized versions that could fit on my Mac and found lmstudio-community/Qwen3-30B-A3B-Instruct-2507-MLX-8bit from LM Studio. Getting that up and running was a 32.46GB download and it appears to use just over 30GB of RAM.
The pelican I got from that one wasn't as good:

I then tried that local model on the "Write an HTML and JavaScript page implementing space invaders" task that I ran against GLM-4.5 Air. The output looked promising, in particular it seemed to be putting more effort into the design of the invaders (GLM-4.5 Air just used rectangles):
// Draw enemy ship ctx.fillStyle = this.color; // Ship body ctx.fillRect(this.x, this.y, this.width, this.height); // Enemy eyes ctx.fillStyle = '#fff'; ctx.fillRect(this.x + 6, this.y + 5, 4, 4); ctx.fillRect(this.x + this.width - 10, this.y + 5, 4, 4); // Enemy antennae ctx.fillStyle = '#f00'; if (this.type === 1) { // Basic enemy ctx.fillRect(this.x + this.width / 2 - 1, this.y - 5, 2, 5); } else if (this.type === 2) { // Fast enemy ctx.fillRect(this.x + this.width / 4 - 1, this.y - 5, 2, 5); ctx.fillRect(this.x + (3 * this.width) / 4 - 1, this.y - 5, 2, 5); } else if (this.type === 3) { // Armored enemy ctx.fillRect(this.x + this.width / 2 - 1, this.y - 8, 2, 8); ctx.fillStyle = '#0f0'; ctx.fillRect(this.x + this.width / 2 - 1, this.y - 6, 2, 3); }
But the resulting code didn't actually work:

That same prompt against the unquantized Qwen-hosted model produced a different result which sadly also resulted in an unplayable game - this time because everything moved too fast.
This new Qwen model is a non-reasoning model, whereas GLM-4.5 and GLM-4.5 Air are both reasoners. It looks like at this scale the "reasoning" may make a material difference in terms of getting code that works out of the box.
How to run an LLM on your laptop. I talked to Grace Huckins for this piece from MIT Technology Review on running local models. Apparently she enjoyed my dystopian backup plan!
Simon Willison has a plan for the end of the world. It’s a USB stick, onto which he has loaded a couple of his favorite open-weight LLMs—models that have been shared publicly by their creators and that can, in principle, be downloaded and run with local hardware. If human civilization should ever collapse, Willison plans to use all the knowledge encoded in their billions of parameters for help. “It’s like having a weird, condensed, faulty version of Wikipedia, so I can help reboot society with the help of my little USB stick,” he says.
The article suggests Ollama or LM Studio for laptops, and new-to-me LLM Farm for the iPhone:
My beat-up iPhone 12 was able to run Meta’s Llama 3.2 1B using an app called LLM Farm. It’s not a particularly good model—it very quickly goes off into bizarre tangents and hallucinates constantly—but trying to coax something so chaotic toward usability can be entertaining.
Update 19th July 20205: Evan Hahn compared the size of various offline LLMs to different Wikipedia exports. Full English Wikipedia without images, revision history or talk pages is 13.82GB, smaller than Mistral Small 3.2 (15GB) but larger than Qwen 3 14B and Gemma 3n.
LM Studio is free for use at work. A notable policy change for LM Studio. Their excellent macOS app (and Linux and Windows, but I've only tried it on Mac) was previously free for personal use but required a license for commercial purposes:
Until now, the LM Studio app terms stated that for use at a company or organization, you should get in touch with us and get separate commercial license. This requirement is now removed.
Starting today, there's no need to fill a form or contact us. You and your team can just use LM Studio at work!
model.yaml. From their GitHub repo it looks like this effort quietly launched a couple of months ago, driven by the LM Studio team. Their goal is to specify an "open standard for defining crossplatform, composable AI models".
A model can be defined using a YAML file that looks like this:
model: mistralai/mistral-small-3.2 base: - key: lmstudio-community/mistral-small-3.2-24b-instruct-2506-gguf sources: - type: huggingface user: lmstudio-community repo: Mistral-Small-3.2-24B-Instruct-2506-GGUF metadataOverrides: domain: llm architectures: - mistral compatibilityTypes: - gguf paramsStrings: - 24B minMemoryUsageBytes: 14300000000 contextLengths: - 4096 vision: true
This should be enough information for an LLM serving engine - such as LM Studio - to understand where to get the model weights (here that's lmstudio-community/Mistral-Small-3.2-24B-Instruct-2506-GGUF on Hugging Face, but it leaves space for alternative providers) plus various other configuration options and important metadata about the capabilities of the model.
I like this concept a lot. I've actually been considering something similar for my LLM tool - my idea was to use Markdown with a YAML frontmatter block - but now that there's an early-stage standard for it I may well build on top of this work instead.
I couldn't find any evidence that anyone outside of LM Studio is using this yet, so it's effectively a one-vendor standard for the moment. All of the models in their Model Catalog are defined using model.yaml.
Mistral-Small 3.2. Released on Hugging Face a couple of hours ago, so far there aren't any quantizations to run it on a Mac but I'm sure those will emerge pretty quickly.
This is a minor bump to Mistral Small 3.1, one of my favorite local models. I've been running Small 3.1 via Ollama where it's a 15GB download - these 24 billion parameter models are a great balance between capabilities and not using up all of the available RAM on my laptop. I expect Ollama will add 3.2 imminently.
According to Mistral:
Small-3.2 improves in the following categories:
Interestingly they recommend running it with a temperature of 0.15 - many models recommend a default of 0.7. They also provide a suggested system prompt which includes a note that "Your knowledge base was last updated on 2023-10-01".
It's not currently available via Mistral's API, or through any of the third-party LLM hosting vendors that I've checked, so I've not been able to run a prompt through the model myself yet.
Update: I downloaded one of first GGUF quantizations to show up on Hugging Face, gabriellarson/Mistral-Small-3.2-24B-Instruct-2506-GGUF by Gabriel Larson. I ran it using Ollama and llm-ollama like this:
ollama pull hf.co/gabriellarson/Mistral-Small-3.2-24B-Instruct-2506-GGUF:Q4_K_M
llm install llm-ollama
llm -m hf.co/gabriellarson/Mistral-Small-3.2-24B-Instruct-2506-GGUF:Q4_K_M \
"Generate an SVG of a pelican riding a bicycle"
This one is pretty good for a 15GB model!

Here's the full transcript - it doesn't quite work in the actual image but I was delighted to see the model attempt to add this detail:
<!-- Basket with fish -->
<rect x="250" y="190" width="25" height="15" rx="5" fill="#FFA500"/>
<circle cx="260" cy="200" r="3" fill="#FF4500"/> <!-- Fish -->
Here's what you get if you isolate just that part of the generated SVG:

I had Mistral Small 3.2 describe the full image to me, since it's a vision-LLM:
llm -m hf.co/gabriellarson/Mistral-Small-3.2-24B-Instruct-2506-GGUF:Q4_K_M \
'describe image' \
-a https://static.simonwillison.net/static/2025/mistral-3.2-pelican.jpg
And it gave me the following:
The image depicts a cartoonish illustration of a duck that is being lifted off the ground by a hook. The duck appears to be in mid-air, with its wings spread slightly as if it's surprised or reacting to being picked up. The hook is attached to an arm or a mechanism and seems to be connected to a vehicle below—perhaps a truck or a platform with wheels. The background of the image is light blue, indicating an outdoor setting. Overall, the scene is whimsical and playful, possibly suggesting a humorous or unusual situation where the duck is being transported in this manner.
Update 2: It's now available as an official Ollama model:
ollama pull mistral-small3.2
LM Studio has a community quantization too: lmstudio-community/Mistral-Small-3.2-24B-Instruct-2506-GGUF.
Gemma 3 QAT Models. Interesting release from Google, as a follow-up to Gemma 3 from last month:
To make Gemma 3 even more accessible, we are announcing new versions optimized with Quantization-Aware Training (QAT) that dramatically reduces memory requirements while maintaining high quality. This enables you to run powerful models like Gemma 3 27B locally on consumer-grade GPUs like the NVIDIA RTX 3090.
I wasn't previously aware of Quantization-Aware Training but it turns out to be quite an established pattern now, supported in both Tensorflow and PyTorch.
Google report model size drops from BF16 to int4 for the following models:
- Gemma 3 27B: 54GB to 14.1GB
- Gemma 3 12B: 24GB to 6.6GB
- Gemma 3 4B: 8GB to 2.6GB
- Gemma 3 1B: 2GB to 0.5GB
They partnered with Ollama, LM Studio, MLX (here's their collection) and llama.cpp for this release - I'd love to see more AI labs following their example.
The Ollama model version picker currently hides them behind "View all" option, so here are the direct links:
- gemma3:1b-it-qat - 1GB
- gemma3:4b-it-qat - 4GB
- gemma3:12b-it-qat - 8.9GB
- gemma3:27b-it-qat - 18GB
I fetched that largest model with:
ollama pull gemma3:27b-it-qat
And now I'm trying it out with llm-ollama:
llm -m gemma3:27b-it-qat "impress me with some physics"
I got a pretty great response!
Update: Having spent a while putting it through its paces via Open WebUI and Tailscale to access my laptop from my phone I think this may be my new favorite general-purpose local model. Ollama appears to use 22GB of RAM while the model is running, which leaves plenty on my 64GB machine for other applications.
I've also tried it via llm-mlx like this (downloading 16GB):
llm install llm-mlx
llm mlx download-model mlx-community/gemma-3-27b-it-qat-4bit
llm chat -m mlx-community/gemma-3-27b-it-qat-4bit
It feels a little faster with MLX and uses 15GB of memory according to Activity Monitor.
QwQ-32B: Embracing the Power of Reinforcement Learning (via) New Apache 2 licensed reasoning model from Qwen:
We are excited to introduce QwQ-32B, a model with 32 billion parameters that achieves performance comparable to DeepSeek-R1, which boasts 671 billion parameters (with 37 billion activated). This remarkable outcome underscores the effectiveness of RL when applied to robust foundation models pretrained on extensive world knowledge.
I had a lot of fun trying out their previous QwQ reasoning model last November. I demonstrated this new QwQ in my talk at NICAR about recent LLM developments. Here's the example I ran.
{kind=link}
LM Studio just released GGUFs ranging in size from 17.2 to 34.8 GB. MLX have compatible weights published in 3bit, 4bit, 6bit and 8bit. Ollama has the new qwq too - it looks like they've renamed the previous November release qwq:32b-preview.
olmOCR (via) New from Ai2 - olmOCR is "an open-source tool designed for high-throughput conversion of PDFs and other documents into plain text while preserving natural reading order".
At its core is allenai/olmOCR-7B-0225-preview, a Qwen2-VL-7B-Instruct variant trained on ~250,000 pages of diverse PDF content (both scanned and text-based) that were labelled using GPT-4o and made available as the olmOCR-mix-0225 dataset.
The olmocr Python library can run the model on any "recent NVIDIA GPU". I haven't managed to run it on my own Mac yet - there are GGUFs out there but it's not clear to me how to run vision prompts through them - but Ai2 offer an online demo which can handle up to ten pages for free.
Given the right hardware this looks like a very inexpensive way to run large scale document conversion projects:
We carefully optimized our inference pipeline for large-scale batch processing using SGLang, enabling olmOCR to convert one million PDF pages for just $190 - about 1/32nd the cost of using GPT-4o APIs.
The most interesting idea from the technical report (PDF) is something they call "document anchoring":
Document anchoring extracts coordinates of salient elements in each page (e.g., text blocks and images) and injects them alongside raw text extracted from the PDF binary file. [...]
Document anchoring processes PDF document pages via the PyPDF library to extract a representation of the page’s structure from the underlying PDF. All of the text blocks and images in the page are extracted, including position information. Starting with the most relevant text blocks and images, these are sampled and added to the prompt of the VLM, up to a defined maximum character limit. This extra information is then available to the model when processing the document.
![Left side shows a green-header interface with coordinates like [150x220]√3x−1+(1+x)², [150x180]Section 6, [150x50]Lorem ipsum dolor sit amet, [150x70]consectetur adipiscing elit, sed do, [150x90]eiusmod tempor incididunt ut, [150x110]labore et dolore magna aliqua, [100x280]Table 1, followed by grid coordinates with A, B, C, AA, BB, CC, AAA, BBB, CCC values. Right side shows the rendered document with equation, text and table.](https://static.simonwillison.net/static/2025/olmocr-document-anchoring.jpg)
The one limitation of olmOCR at the moment is that it doesn't appear to do anything with diagrams, figures or illustrations. Vision models are actually very good at interpreting these now, so my ideal OCR solution would include detailed automated descriptions of this kind of content in the resulting text.
Update: Jonathan Soma figured out how to run it on a Mac using LM Studio and the olmocr Python package.
Qwen2.5-1M: Deploy Your Own Qwen with Context Length up to 1M Tokens (via) Very significant new release from Alibaba's Qwen team. Their openly licensed (sometimes Apache 2, sometimes Qwen license, I've had trouble keeping up) Qwen 2.5 LLM previously had an input token limit of 128,000 tokens. This new model increases that to 1 million, using a new technique called Dual Chunk Attention, first described in this paper from February 2024.
They've released two models on Hugging Face: Qwen2.5-7B-Instruct-1M and Qwen2.5-14B-Instruct-1M, both requiring CUDA and both under an Apache 2.0 license.
You'll need a lot of VRAM to run them at their full capacity:
VRAM Requirement for processing 1 million-token sequences:
- Qwen2.5-7B-Instruct-1M: At least 120GB VRAM (total across GPUs).
- Qwen2.5-14B-Instruct-1M: At least 320GB VRAM (total across GPUs).
If your GPUs do not have sufficient VRAM, you can still use Qwen2.5-1M models for shorter tasks.
Qwen recommend using their custom fork of vLLM to serve the models:
You can also use the previous framework that supports Qwen2.5 for inference, but accuracy degradation may occur for sequences exceeding 262,144 tokens.
GGUF quantized versions of the models are already starting to show up. LM Studio's "official model curator" Bartowski published lmstudio-community/Qwen2.5-7B-Instruct-1M-GGUF and lmstudio-community/Qwen2.5-14B-Instruct-1M-GGUF - sizes range from 4.09GB to 8.1GB for the 7B model and 7.92GB to 15.7GB for the 14B.
These might not work well yet with the full context lengths as the underlying llama.cpp library may need some changes.
I tried running the 8.1GB 7B model using Ollama on my Mac like this:
ollama run hf.co/lmstudio-community/Qwen2.5-7B-Instruct-1M-GGUF:Q8_0
Then with LLM:
llm install llm-ollama
llm models -q qwen # To search for the model ID
# I set a shorter q1m alias:
llm aliases set q1m hf.co/lmstudio-community/Qwen2.5-7B-Instruct-1M-GGUF:Q8_0
I tried piping a large prompt in using files-to-prompt like this:
files-to-prompt ~/Dropbox/Development/llm -e py -c | llm -m q1m 'describe this codebase in detail'
That should give me every Python file in my llm project. Piping that through ttok first told me this was 63,014 OpenAI tokens, I expect that count is similar for Qwen.
The result was disappointing: it appeared to describe just the last Python file that stream. Then I noticed the token usage report:
2,048 input, 999 output
This suggests to me that something's not working right here - maybe the Ollama hosting framework is truncating the input, or maybe there's a problem with the GGUF I'm using?
I'll update this post when I figure out how to run longer prompts through the new Qwen model using GGUF weights on a Mac.
Update: It turns out Ollama has a num_ctx option which defaults to 2048, affecting the input context length. I tried this:
files-to-prompt \
~/Dropbox/Development/llm \
-e py -c | \
llm -m q1m 'describe this codebase in detail' \
-o num_ctx 80000
But I quickly ran out of RAM (I have 64GB but a lot of that was in use already) and hit Ctrl+C to avoid crashing my computer. I need to experiment a bit to figure out how much RAM is used for what context size.
Awni Hannun shared tips for running mlx-community/Qwen2.5-7B-Instruct-1M-4bit using MLX, which should work for up to 250,000 tokens. They ran 120,000 tokens and reported:
- Peak RAM for prompt filling was 22GB
- Peak RAM for generation 12GB
- Prompt filling took 350 seconds on an M2 Ultra
- Generation ran at 31 tokens-per-second on M2 Ultra